【语义分割】Smoothed Dilated Convolutions for Improved Dense Prediction阅读笔记
论文地址:https://arxiv.org/abs/1808.08931
或:https://www.kdd.org/kdd2018/accepted-papers/view/smoothed-dilated-convolutions-for-improved-dense-prediction
代码:https://github.com/divelab/dilated
作者:Zhengyang Wang (Washington State University); Shuiwang Ji (Washington State University)
作者博客:http://people.tamu.edu/~zhengyang.wang/
参考资料:
https://zhuanlan.zhihu.com/p/46382257
目录
- 摘要
- 1.介绍
- 2.背景和相关工作
-
- 2.1扩张卷积
- 2.2扩张卷积中的Gridding
- 3.平滑扩张卷积
-
- 3.1扩张卷积的分解视图
- 3.2使用组交互层平滑扩张卷积
- 3.3使用可分离和共享的卷积平滑扩张卷积
- 3.4 两种方法之间的联系
- 4.实验分析
-
- 4.1基础步骤
- 4.2 PASCAL VOC2012
- 4.3 Cityscapes
- 4.4 有效感受野分析
- 5.结论
摘要
扩张卷积(dilated convolutions),又名空(孔)洞卷积( atrous convolutions),已经被广泛应用于深度神经网络(DCNNs)的多个任务中,如语义图像分割、目标检测、音频生成、视频建模和机器翻译。然而,扩张卷积会受网格伪影(gridding artifacts)的影响,这阻碍了使用扩张卷积的DCNN的性能。在本文,我们通过研究扩张卷积的分解提出两个简单但有效的degridding方法。与通过关注级联扩张卷积层来研究解决方案的现有模型不同,我们的方法是通过平滑扩张卷积本身来解决网格伪影(gridding artifacts)。通过在原始操作和分解视图中分析它们,我们进一步发现这两种degridding方法是内在相关的,并且我们定义了可分离和共享(separable and shared, SS)操作,这推广了我们所提出的方法。我们在两个数据集上评估我们的方法,并通过有效的感受野分析可视化平滑效果。实验结果表明,我们的方法对使用扩张卷积的DCNN的性能产生了显著和一致的改进,同时增加了可忽略不计的额外训练参数。
1.介绍
扩张卷积(dilated convolutions),又名空(孔)洞卷积( atrous convolutions),已经被广泛应用于深度神经网络(DCNNs)的多个任务中,如语义图像分割 [2, 3, 9–11, 18, 28–31],目标检测 [6, 15, 25, 26],音频生成[24]、视频建模[17],和机器翻译[16]。扩张滤波器的概念是在[14]中用于有效小波分解的算法中开发的,并且已经用于图像像素预测任务以允许有效计算 [10, 18, 25, 26]。通过在权重之间插入零后采样来扩张卷积滤波器,如图1所示。它扩大了感受野或视野[2,3,11],但不需要在DCNN中训练额外的参数。扩张卷积可以级联使用以构建多层网络[16,17,24]。扩张卷积的另一个优点是它们不会降低响应的空间分辨率。这是与下采样层的关键差异,例如池化层或步幅大于1的卷积,虽然他们也扩大了后续层的感受野,但也降低了空间分辨率。这样就允许通过移除下采样层,在后续层中应用扩张卷积的方式将在ImageNet[7,13]上训练的分类模型迁移到语义图像分割任务上[2,3,11,21,28-31]。与标准卷积相似,由具有激活函数的扩张卷积组成的层称为扩张卷积层。

dilation rate(为了方便,也叫作rate),表示0的填充多少。零的填充数量=dilation rate - 1
虽然具有扩张卷积的DCNN在各种深度学习任务中取得了成功,但已经观察到扩张导致所谓的“网格伪影”(gridding artifacts)[11,28,30]。对于扩张率大于1的扩张卷积,输出中的相邻单元由输入中完全独立的单元组计算得到。它导致局部信息不一致并妨碍了使用扩张卷积的DCNN的性能。由于扩张卷积层通常在DCNN中级联堆叠在一起,现有模型专注于平滑这种级联的扩张卷积层的gridding artifacts。在[11,30]中,通过在扩张卷积块之后添加具有数百万额外训练参数的更多层来减轻gridding问题。在[28]中提出了混合扩张卷积(HDC),其在连续扩张卷积层中应用不同的扩张率而不是一个相同的扩张率。
在这项工作中,我们通过平滑扩张卷积本身而不是堆叠扩张卷积层来解决网格伪影(gridding artifacts)。我们的方法享有独特的优势,即能够替换现有网络中的任何单个扩张卷积层,因为它们不依赖于其他层来解决网格化(gridding)问题。更重要的是,我们的方法为模型添加了最少量的额外参数,而其他一些降级方法则显着增加了模型参数[11,30]。我们的方法基于扩张卷积运算[1,2,27]的一个有趣观点,它可以从操作的分解中获益。基于这种对扩张卷积的新颖解释,我们提出了两种简单而有效的方法来平滑网格伪影(gridding artifacts)。通过在原始操作和分解视图中分析这两种方法,我们进一步注意到它们本质上是相关的,并且定义了可分离和共享(SS)操作,这些操作推广了所提出的方法。实验结果表明,我们的方法显著和一致地改善了当前使用扩张卷积的DCNN,而只增加了几百个额外的参数。我们还利用有效感受野(ERF)分析[22]来可视化使用我们扩张卷积的DCNN的平滑效果。
2.背景和相关工作
在本节中,我们描述扩张卷积与DCNN的背景和相关工作。 然后,我们将详细讨论gridding问题和当前解决方案。
2.1扩张卷积
在一维情况下,给定1-D输入 f f f,扩张卷积的输出 o o o上位置 i i i处的值与大小为 S S S的flter w w w被定义为: (1) o [ i ] = ∑ s = 1 S f [ i + r ∗ s ] ∗ w [ i ] o[i]=\sum_{s=1}^S f[i+r*s]*w[i] \tag{1} o[i]=s=1∑Sf[i+r∗s]∗w[i](1)
其中 r r r被称为扩张率。更高维度的情况可以很容易地推广。 当 r = 1 r=1 r=1时,扩张的卷积对应于标准卷积。理解扩张卷积的直观且直接的方法是在标准卷积滤波器中的每两个相邻权重之间插入r-1个零。扩张卷积也被称为孔洞卷积,其中“trous”意味着法语中的漏洞。 图1包含二维情况下的扩张卷积的图示。
如第1节所述,在大多数情况下,DCNN使用级联的扩张卷积,这意味着几个扩张卷积层堆叠在一起。使用这种级联模式的原因在不同的任务中都不相同。在语义图像分割[2,3,11,21,28-31]的任务中,为了在保持感受野大小的同时具有更大尺寸的输出特征图,在删除下采样层之后使用扩张的卷积来代替层中的标准卷积。例如,如果我们将标准卷积视为扩张率为 r = 1 r = 1 r=1的扩张卷积,则当移除子采样率为2的下采样层时,所有后续卷积层的扩张率应乘以2。这就是扩张卷积层扩张率为 r = 2 , 4 , 8 r = 2,4,8 r=2,4,8等的原因。在其他任务中,例如音频生成[24],视频建模[17]和机器翻译[16],扩张卷积的使用旨在扩大输出的感受野。如[17,24,29]所指出的那样,级联的扩张卷积层在DCNN中的层数中以指数方式而不是线性地扩大了感受野。在这些研究中, the dilation rate is doubled for every forward layer, starting from 1 up to a limit before the pattern is repeated.(翻译不通,不翻了(╯‵□′)╯︵┻━┻)
请注意,在级联中使用扩张卷积时,网格伪影(gridding artifacts)会更显著地影响模型。这是因为连续堆叠层的扩张率在所有这些使用级联的扩张卷积层的DCNN中具有共同的因子2,如[28]和第2.2节中所讨论的。在[2,3]中,探索了并行形成输出层的扩张卷积。
2.2扩张卷积中的Gridding
扩张率大于1的扩张卷积将产生所谓的网格伪影(gridding artifacts); 也就是说,输出中的相邻单位是从输入中完全独立的单位集计算出来的,因此具有完全不同的实际感受野。为了清楚地查看gridding问题,我们首先研究单个扩张卷积。以图1中的第二种情况为例,内核尺寸为3×3且扩张率为r = 2的二维扩张卷积具有5×5的感受野。然而,实际参与计算的像素数量仅为25个中的9个,这意味着实际的感受野仍然是3×3,但是稀疏地分布。如果我们进一步考虑输出中的相邻单元,则可以从图2中看到网格问题。假设我们有两个连续的扩张卷积层,两个扩张的卷积的核大小为3×3,扩张率为r = 2。对于由层 i i i中的不同颜色指示的四个相邻单元,我们使用相同的颜色在层 i − 1 i-1 i−1和 i − 2 i-2 i−2中显示它们的实际感受域。我们可以看到,层 i − 1 i-1 i−1中的四个完全独立的单元组计算得到层 i i i中的四个单元。 此外,由于两层的扩张率均为2,其公因子为2,因此网格问题也存在于层 i − 2 i-2 i−2中。实际上,只要级联中的扩张卷积层的扩张率具有共同因子关系,例如2,2,2或2,4,8,gridding问题就会传播到所有层,如[28]中所指出的那样。对于有这样层的块,块的相邻输出是从完全不同的输入集计算的。这导致局部信息的不一致并且妨碍具有扩张卷积的DCNN的性能。
准确的说是除了kernel中间的unit之外

在几个最近的语义图像分割研究中观察并解决了网格伪影(gridding artifacts)[11,28,30]。如第2.1节所述,扩张的卷积主要在DCNN中级联使用。 因此,这些研究集中于根据堆叠的扩张卷积层来解决网格问题。具体而言,在[28]中提出了混合扩张卷积(HDC),其将几个扩张卷积层组合并应用没有共同因子关系的扩张率。例如,对于扩张率为 r = 2 r = 2 r=2的扩张卷积块,每三个连续层被分组在一起,并且相应的扩张率变为1,2,3而不是2,2,2。对于具有扩张率 r = 4 r = 4 r=4的类似块,应用相同的分组原理并且扩张率变为3,4,5,而不是4,4,4。当与他们提出的密集上采样卷积(DUC)一起使用时,该方法改进了用于语义图像分割的DCNN。这种策略在最近的工作[3]中也被采用为“多重网格”方法。 在[28]之前,主要通过在膨胀卷积层块之后添加更多层来进行degridding[11,30]。在[30]中提出增加两个没有残差连接的标准卷积层,而[11]提出增加一个有扩张卷积层的块,并降低该块中扩张率。这种方法的主要缺点是需要学习大量额外参数。
3.平滑扩张卷积
在本节中,我们将讨论扩张卷积的分解视图。 然后,我们提出了两种平滑网格伪影(gridding artifacts)的方法。我们还分析了所提出的两种方法之间的关系,并定义了可分离和共享(SS)操作来概括它们。
3.1扩张卷积的分解视图
有两种方法可以理解扩张的卷积。 正如2.1节所介绍的那样,第一种更直观的方法是通过在扩张率为 r r r的扩张卷积filters上插入零(孔)来将其视为标准的上采样卷积filters[25]。查看扩张卷积的另一种方法是基于操作的分解[27]。扩张率为 r r r的扩张卷积可以分解为三个步骤。首先,输入特征图通过因子 r r r周期性地进行下采样。结果,输入被解交织到 r d r^{d} rd组降低分辨率的特征图,其中 d d d是输入的空间维度。其次,这些中间特征图组被送入标准卷积。 在去除所有插入的零之后,该卷积具有与原始扩张卷积相同的权重。更重要的是,它被所有组共享,这意味着每组降低分辨率的特征图都经历相同的标准卷积。第三步是将 r d r^{d} rd组特征映射重新连接到原始分辨率,并产生扩张卷积的输出。
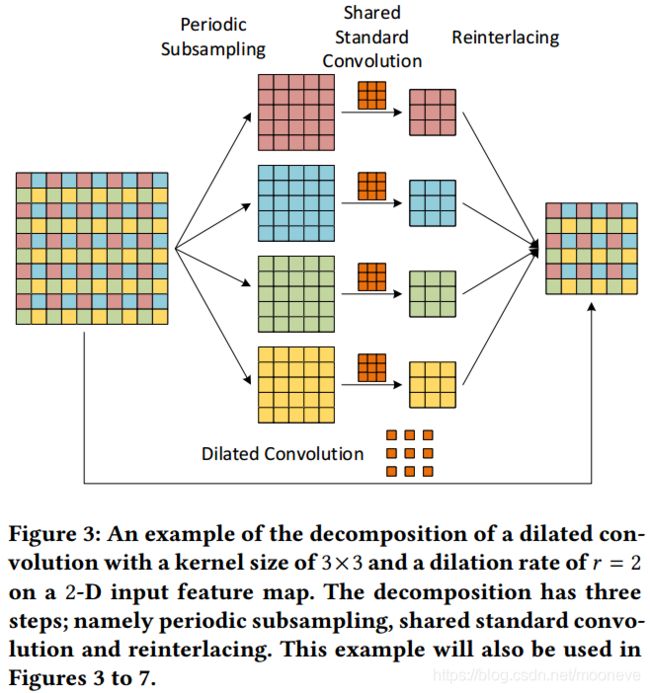
图3给出了2-D情况下的分解示例。为简化讨论,我们假设输入通道和输出通道的数量均为1。给定10×10特征映射,内核大小为3×3且扩张率为 r = 2 r = 2 r=2的扩张卷积没有任何padding将输出6×6特征映射。在该扩张卷积的分解中,输入特征图被周期性地采样为 2 2 = 4 2^{2} = 4 22=4组,分辨率降低为5×5的特征图。然后,将共享的标准卷积应用于这4组特征映射,其具有与没有填充的扩张卷积相同的权重,并获得4组3×3特征映射。最后,它们被重新交换到原始分辨率并产生与原始扩张卷积完全相同的6×6输出特征图。这种分解将扩张卷积减少为标准卷积,并允许更有效的实现[1,2,10,26]。
我们注意到分解视图提供了网格伪像的清晰解释;也就是说,在共享标准卷积之前或之后, r d r^{d} rd中间特征映射组彼此之间没有依赖性,因此采集到可能不一致的局部信息。基于这种观点,我们通过在分解的不同步骤中添加 r d r^{d} rd组之间的依赖性来克服网格化(gridding)。我们在接下来的两节中提出了两种有效的方法。
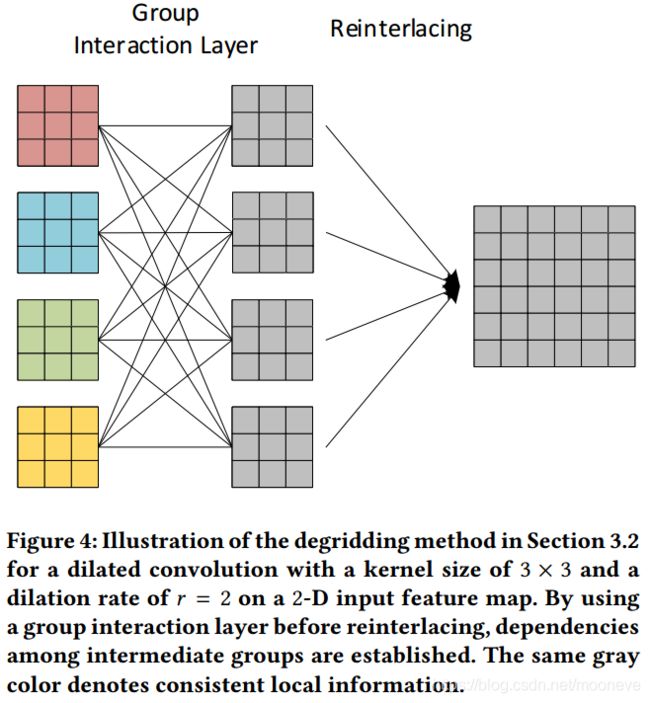
3.2使用组交互层平滑扩张卷积
我们的第一个degridding方法试图在分解的第三步中建立不同组之间的依赖关系。我们提出在将中间特征映射重新处理为原始分辨率之前添加组交互层(Group Interaction Layers)。对于在d维输入特征图上进行扩张率为 r r r的扩张卷积,分解的第二步产生 r d r^{d} rd组的降低分辨率的特征图,在共享卷积之后表示为 { f i } i = 1 r d \{f_i\} _{i=1} ^{r^{d}} {fi}i=1rd。请注意,每个 f i f_i fi表示一组特征映射,而不是单个特征映射。我们用权重矩阵 W ∈ R r d × r d W∈\mathbb{R}^{r^{d}×r^{d}} W∈Rrd×rd来定义组交互层:
(2) W = [ w 11 w 12 w 13 ⋯ w 1 , r d w 21 w 22 w 23 ⋯ w 2 , r d ⋮ ⋮ ⋮ ⋱ ⋮ w r d , 1 w r d , 2 w r d , 3 ⋯ w r d , r d ] W= \left[\begin{matrix} w_{11} & w_{12} & w_{13} &\cdots&w_{1,r^d}\\ w_{21} & w_{22} & w_{23} &\cdots&w_{2,r^d}\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ w_{r^d,1} & w_{r^d,2} & w_{r^d,3} &\cdots&w_{r^d,r^d} \end{matrix}\right] \tag{2} W=⎣⎢⎢⎢⎡w11w21⋮wrd,1w12w22⋮wrd,2w13w23⋮wrd,3⋯⋯⋱⋯w1,rdw2,rd⋮wrd,rd⎦⎥⎥⎥⎤(2)
该层的输出仍然是 r d r^d rd组的特征映射,表示为 { f ^ i } i = 1 r d \{\hat{f}_i\} _{i=1} ^{r^{d}} {f^i}i=1rd,由以下计算得到:
(3) f ^ i = ∑ j = 1 r d w i j ⋅ f j \hat{f}_i=\sum_{j=1}^{r^d}w_{ij}\cdot f_j\tag{3} f^i=j=1∑rdwij⋅fj(3)
其中 i = 1 , 2 , … , r d i=1,2,\dots,r^d i=1,2,…,rd。请注意,该层的连接位于组之间,而不是特征映射之间。事实上,每个 f ^ i \hat{f}_i f^i都是 { f i } i = 1 r d \{f_i\} _{i=1} ^{r^{d}} {fi}i=1rd的线性组合,由权重矩阵W加权。通过这一层,每个 f ^ i \hat{f}_i f^i收集来自所有 r d r^d rd特征映射组的局部信息,这增加了不同组之间的依赖关系。在组交互层之后, r d r^d rd组被重新交织到原始分辨率并形成扩张卷积的最终输出。这种平滑的扩张卷积中的额外训练参数的数量是 r 2 d r^{2d} r2d,与输入和输出通道的数量无关。具有扩张卷积的DCNN通常用于一维或二维情况,这意味着 d = 1 , 2 d = 1,2 d=1,2。实践中, r r r的选择通常为2,4,8。所提出的组交互层仅需要在最坏情况下学习数千个额外参数,而原始扩张卷积通常具有数百万个训练参数。
我们在图4中使用3.1节中的相同示例来说明想法。给定分解中第二步的输出,4组中间特征映射通过组交互层建立彼此之间的依赖关系,其权重数量仅为 2 2 ⋅ 2 = 16 2^{2·2} = 16 22⋅2=16,由16个连接表示。我们使用灰色来表示degridding后的特征图。
3.3使用可分离和共享的卷积平滑扩张卷积
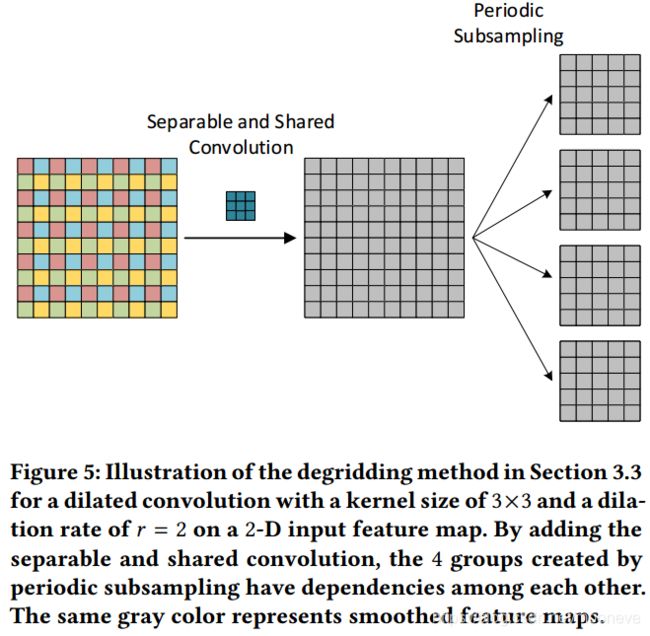
我们进一步探索了在分解的第一步中建立不同组之间依赖关系的方法;也就是说,在对输入特征映射进行逐行扫描之前。考虑到在 d d d维输入特征映射上进行扩张率为r的扩张卷积时,会在逐行周期性下采样期间将输入中大小为 r d r^d rd的局部区域的每个单元分配到单独的组。因此,对于特定组中的单元,它所有原本相邻的单元处于其他独立的 r d − 1 r^d-1 rd−1组中,从而导致局部不一致。如果可以在周期采样之前合并局部信息,则可以减轻网格伪影(gridding artifacts)。为了实现这一点,我们提出了基于可分离卷积[4,23]的可分离和共享(SS)卷积。给定 C C C通道的输入和 C C C通道的相应输出,可分离卷积与标准卷积相同,除了可分离卷积分别处理每个通道。标准卷积将输入中的所有 C C C通道连接到输出中的所有 C C C通道,从而导致 C 2 C^2 C2个不同的flters。相反,可分离卷积仅将第 i i i个输出通道连接到第 i i i个输入通道,仅产生 C C C个flters。在所提出的SS卷积中,“共享”意味着,基于可分离卷积, C C C个滤波器是相同的并且由所有输入和输出通道对共享。对于 C C C通道的输入和输出,SS卷积仅有一个flter扫描所有空间位置并在所有通道上共享该滤波器。在平滑扩张卷积方面,我们应用SS卷积以在输入特征图中合并每个单元的相邻信息。具体地,在逐行扫描之前插入内核大小为 ( 2 r − 1 ) d (2r-1)^d (2r−1)d的SS卷积,从而将彼此之间的依赖性添加到由周期性下采样产生的 r d r^d rd组特征映射中。
文章中给出的SS卷积的kernel size的计算公式为kernel size= ( 2 r − 1 ) d (2r-1)^d (2r−1)d,观察figure 1 中第三个卷积的中心点就很好理解
图5中的示例说明了插入SS卷积的方法。这里插入的SS卷积的内核大小是 ( 2 ⋅ 2 − 1 ) 2 = 3 × 3 (2\cdot 2-1)^2 = 3\times3 (2⋅2−1)2=3×3。请注意,因为输入只有一个通道,所以SS卷积,可分离卷积和标准卷积在本例中是等效的。但是,如果输入具有 C > 1 C> 1 C>1通道,则它们变得不同。重要的是,对于具有多个通道的输入,与其他两种卷积相反,SS卷积的训练参数的数量不会改变。这意味着所提出的degridding方法具有 ( 2 r − 1 ) d (2r-1)^d (2r−1)d个参数,与通道数无关,在实践中最多只对应数十个额外参数。
3.4 两种方法之间的联系
所提出的两种方法都源自扩张卷积的分解视图。现在我们结合所有步骤并根据原始操作进行分析。对于3.3节中的第二种方法,它是直截了当的,因为在分解的第一步之前插入了可分离和共享(SS)卷积,实际上并没有影响原始的扩张卷积。因此,它相当于在扩张卷积之前添加SS卷积,如图7所示。但是,3.2节中的第一种方法通过在分解的第二步和第三步之间加入分组全连接层进行degridding。要了解如何执行组合,我们参考图4中的示例。在最后一步之前,我们有四组特征图,每组只有一个特征图。考虑四个特征映射左上角的单元,如果没有组交互层,这四个单元在重新隔行后形成输出特征映射的左上2×2块。如果我们插入分组全连接层,则左上角的四个新单元将成为前四个单元的线性组合,而且形成输出特征图的左上角2×2块。结果,输出特征图上新的左上2×2块是在前一个上的全连接操作来计算的。通过stride=2扫描输出特征映射来检查其他单元,我们发现每个非重叠的2×2块共享全连接的操作。图6提供了一个说明。通过推广这个例子,我们可以看到degridding方法等效于扩张卷积进行以下操作:使用大小为 r d r^d rd的窗口用步幅 r r r扫描输出特征图并获得非重叠块;对于每个块,执行相同的全连接操作,输出相同空间大小的块。请注意,如果输出具有多个通道,则操作将在各个通道之间共享。此操作类似于SS卷积,因为它们都使用在所有通道上共享的单个内核扫描空间位置。因此,我们将其命名为SS 块式(block-wise)全连接层。基于它以及SS卷积,我们进一步定义在所有通道上使用共享的单个flter扫描输入的空间位置的操作为SS操作。
对于相同颜色的unit,融合采用的权重是一样的,不同颜色的 unit融合采用的权重是不一样的。这一点回想一下前面figure4就很容易理解了。
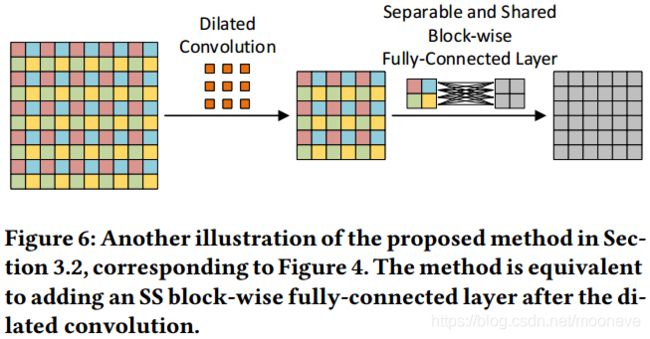
第二种方法是在input 上采用separate and shared convolution,并且通道间的kernel是共享的,相当于是对相邻的九个unit之间进行了融合
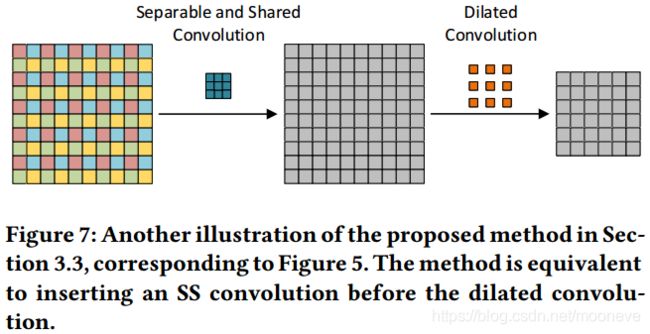
由于DCNN通常采用级联的扩张卷积层,因此我们也在这种情况下研究我们提出的方法。如上所述,第一种降级方法相当于在扩张卷积之后添加SS块式全连接层,而第二种降级对应于在扩张卷积之前插入SS卷积。然而,对于具有相同扩张率的级联扩张卷积层,扩张卷积和SS操作之间的顺序仅影响第一层和最后层。因此,两种提出的degridding方法可以概括为将适当的SS操作与扩张的卷积相结合。
设想这两种方式进行串联。那么在串联的中间部分,都是dilated - ss conv - dilated - ss conv交叉出现,不同之处只在首尾。第一种方法是后做dilated conv,第二种方法是先做dilated conv所以这两种方式可以一般化并且与dilated convolution结合起来使用。
4.实验分析
在本节中,我们在PASCAL VOC 2012 [8]和Cityscapes [5]数据集上评估我们的方法。我们提出的方法导致具有扩张卷积的DCNN的显著且一致的改进。我们还进行了有效的感受野(ERF)分析[22]来可视化平滑效果。
4.1基础步骤
为了进行我们的实验,我们选择了语义图像分割的任务,因为网格伪影(gridding artifacts)主要是在这项任务的研究中观察到的[11,28,30]。局部信息的一致性对于图像上的这种像素预测任务是重要的。此外,平滑效果易于在二维数据上可视化。
我们实验中的baseline模型是带有ResNet-101[13]的DeepLabv2 [2] 。从三个方面评估我们的平滑扩张卷积是一个公平的benchmark。首先,它使用扩张卷积来调整在ImageNet上预训练的ResNet [7]; 即从图像分类到语义图像分割。大多数语义图像分割模型采用了这种迁移学习策略[2,3,10,11,18,21,28-31],ResNet是用于图像分类的最准确的DCNN之一,并且具有可用的预训练模型。其次,最近在分割任务中实现最先进技术的模型[3,28,31]是由DeepLab v2开发的。在[31]中,输出层被金字塔池化模块替换。[28]也改变了输出层,并另外建议改变扩张率,如2.2节所述。目前最好的模型[3]遵循[28]的建议,同时使用更多的扩张卷积块探索更深层。最后,我们打算将我们的degridding方法与现有方法进行比较[11,28,30]。虽然[11,30]通过添加更多层来大大增加训练参数的数量来处理网格伪影(gridding artifacts),但我们的方法只需要学习数百个额外的参数。因此,我们与[28]中提出的基于DeepLabv2的方法进行了比较。
DeepLabv2由两部分组成:编码器和输出层。编码器是经过预先训练的采用扩张卷积修改的ResNet-101模型,它从原始图像中提取特征图。如2.1节所述,ResNet-101中的最后两个下采样层被移除,随后的标准卷积层被扩张卷积层取代,扩张率分别为r = 2,4。具体而言,在修改之后,最后两个块是23个堆叠的扩张卷积层的块,其具有r = 2的扩张率,接着是具有r = 4的扩张率的3个级联扩张卷积的块。输出层通过聚合来自编码器的输出特征映射的信息来进行逐像素分类。
我们在Tensorflow中复现了DeepLabv2,并根据我们的实施进行实验研究。我们的代码是公开的。我们通过解决编码器最后两个块中的网格伪影(gridding artifacts)来改善baseline。为了使对比独立于输出层,我们使用不同的输出层进行实验。为了消除不同数据集的偏差,我们在两个数据集上评估我们的方法。通过联合像素交叉(IoU)评估所有模型,其定义为:
(4) I o U = t r u e _ p o s i t i v e t r u e _ p o s i t i v e + f a l s e _ p o s i t i v e + f a l s e _ n e g a t i v e IoU = \frac{true\_positive}{true\_positive+false\_positive+false\_negative} \tag{4} IoU=true_positive+false_positive+false_negativetrue_positive(4)
4.2 PASCAL VOC2012
PASCAL VOC 2012语义图像分割数据集[8]提供按像素标注的自然图像。它已被分为训练集,验证集和测试集,分别为1464,1449和1456个图像。标注包括21个类,它们是20个前景对象类和1个背景类。带有额外标注的增强版[12]将训练集的大小增加到10,582。在我们的实验中,我们使用增强的训练集训练所有模型,并在验证集上进行评估。在重现baseline DeepLabv2时,由于我们有限的GPU内存,我们没有在多尺度输入上使用最大融合进行测试。我们不执行任何后处理,如条件随机场(CRF)[2],这与我们的目标无关。与DeepLabv2一样,我们使用随机裁剪大小为321×321,batch size为10的批数据训练模型。通过随机缩放训练输入来应用数据增强。我们将初始学习率设置为0.00025并采用“poly”学习率策略[20]:
(5) c u r r e n t _ l r = ( 1 − i t e r m a x _ i t e r ) p o w e r ⋅ i n i t i a l _ l r current\_lr=(1-\frac{iter}{max\_iter})^{power}\cdot initial\_lr \tag{5} current_lr=(1−max_iteriter)power⋅initial_lr(5)
其中 p o w e r = 0.9 power=0.9 power=0.9, i t e r iter iter表示当前迭代次数, l r lr lr表示学习率,与[2,3,28]相同。该模型训练为 m a x _ i t e r = 20 , 000 max\_iter = 20,000 max_iter=20,000次迭代,动量为0.9,权重衰减为0.0005。
我们通过在每个扩张卷积之前或之后插入适当的可分离和共享(SS)操作来实现我们提出的方法,如图6和7所示。一个重要的步骤是改变每个实验中详细的初始学习率。为了使对比稳定,我们还使用不同的初始学习率训练baseline,并观察到0.00025的原始设置产生最佳性能。SS操作的初始化是将它们设置为identity操作。 具体地,对于扩张率为r = 2的组交互层,初始滤波器为:
(6) W = [ 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 ] W= \left[\begin{matrix} 1 & 0 & 0 &0\\ 0 & 1 & 0 &0\\ 0 & 0 & 1 &0\\ 0 & 0 & 0 &1 \end{matrix}\right] \tag{6} W=⎣⎢⎢⎡1000010000100001⎦⎥⎥⎤(6)
而对于扩张率为r = 2的SS卷积,则为:
(7) W = [ 0 0 0 0 1 0 0 0 0 ] W= \left[\begin{matrix} 0 & 0 & 0 \\ 0 & 1 & 0\\ 0 & 0 & 0 \end{matrix}\right] \tag{7} W=⎣⎡000010000⎦⎤(7)
最初的DeepLabv2在MS-COCO上使用了预训练[19],从而获得更多的训练数据和更高的性能。我们的实验是在两种设置下进行的; 即有和没有MS-COCO预训练。结果分别在表1和2中给出。在表中,“G Interact”表示具有组交互层的degridding方法,即在扩张卷积之后添加SS块状全连接层,“SS Conv”表示在扩张卷积之前插入SS卷积的层。在使用MS-COCO预训练的这些实验中,“G Interact”和“SS Conv”的初始学习率均为0.001。或者,它们分别设置为0.001和0.00075。显然,两种方法都提高了大多数类的IoU以及两种设置下baseline的平均IoU(mIoU)。值得注意的是,“G Interact”仅需要训练1,136(= 16×23 + 256×3)额外参数,“SS Conv”需要354(= 9×23 + 49×3)个额外参数,这些参数与模型中的参数总数进行比较可忽略不计 。


我们还将我们的方法与[28]中提出并在[3]中使用的现有的“multigrid” degridding方法进行了比较。如2.2节所述,该想法是将几个扩张卷积层分组并改变扩张因子。据我们所知,对于具有扩张卷积的改进的ResNet-101,最后两个块是23个堆叠的扩张卷积层的块,其中扩张率为r = 2,随后是3个级联扩张卷积的块,扩张率为r = 4。对于第一个块,我们将每3个层组合在一起并将膨胀率从r = 2,2,2替换为r = 1,2,3。对于剩余2层,我们保持r = 2,2。对于第二个块,3个扩张因子r = 4,4,4变为r = 3,4,5。我们进行修改并在与baseline相同的设置下训练模型。表示为“Multigrid”的结果显示在表1和2的第二行中。令人惊讶的是,我们的实现表明该方法不会提高性能。对结果的解释是该方法应该与其他修改一起应用,因为[28]和[3]都与DeepLabv2上的其他变化一起进行实验,例如密集上采样卷积(dense upsamling convolution,DUC)和更深层编码器。
当我们解决编码器的最后两个块中的网格伪影(gridding artifacts)时,我们还使用不同的输出层进行实验,以使比较结果独立于输出层。我们用大视野(LargeFOV)层替换DeepLabv2的原始空间金字塔池(ASPP)输出层,这在[2]中已经应用过。我们使用上述相同的设置训练模型,使用和不使用MS-COCO预训练,并分别在表3和表4中显示结果。同样,所提出的degridding方法导致一致的显著改进。


4.3 Cityscapes
我们进一步在Cityscapes[5]数据集上比较了我们提出的方法。Cityscapes从50个不同的城市收集了5,000张2048×1024的街景图像,并提供了19个类别的高质量像素注释。将5,000幅图像分别分为2975,500和1,552个图像,分别为train,test和val。同样,我们在训练集上训练模型并对验证集进行评估。 batch size为3,其中每批包含随机裁剪的大小为571×571的patches。所有模型的初始学习率均设为0.0005。 所有其他设置与4.2节中的设置相同。
仍然在两种设置下进行实验,即使用和不使用MS-COCO预训练,结果分别在表5和6中给出。我们可以看到,所提出的两种方法都增加了baseline上的mIoU,这表明这些改进与数据集无关。


4.4 有效感受野分析
由于我们在解决网格伪影(gridding artifacts),我们进行有效的感受野(ERF)分析[11,22]来可视化我们方法的平滑效果。这些实验进一步验证了所提出的方法的改进来自degridding。给定DCNN中的块,ERF分析是一种方法用于表征块输入中的每个单元在数学上对块的特定输出单元的影响程度[22],而不是理论上的。
按照[11,22]中的步骤,我们分析了PASCAL VOC 2012上使用ASPP输出层和MS-COCO预训练的模型。我们计算所选baseline中的块和所提出方法的ERF。具体地,假设块的输入和输出特征映射分别是 x x x和 y y y。特征图的空间位置由 ( i , j ) (i,j) (i,j)索引,其中(0,0)表示中心。ERF由偏导数 ∂ y 0 , 0 / ∂ x i , j ∂y_{0,0}/∂x_{i,j} ∂y0,0/∂xi,j测量。为了在没有显式损失函数的情况下计算它,我们将误差梯度相对于 y 0 , 0 y_{0,0} y0,0设置为1,而对于 y i , j y_{i,j} yi,j, i ≠ 0 i\neq0 i̸=0或 j ≠ 0 j\neq0 j̸=0,我们将其设置为0。然后误差梯度可以反向传播到 x x x,并且相对于 x i , j x_{i,j} xi,j的误差梯度等于 ∂ y 0 , 0 / ∂ x i , j ∂y_{0,0}/∂x_{i,j} ∂y0,0/∂xi,j[22]。但是,结果取决于输入。因此,对验证集中的所有图像计算 ∂ y 0 , 0 / ∂ x i , j ∂y_{0,0}/∂x_{i,j} ∂y0,0/∂xi,j,并对它们的绝对值求平均值。最后,我们将 x x x的所有通道上的值相加,以获得ERF的可视化。
在我们的实验中,我们选择两块DCNN来可视化平滑效果,并将可视化的空间大小放大十倍以进行显示。第一个块是编码器的最后一层,它是一个扩张卷积,内核大小为3×3,扩张率为r = 4。ERF分析结果如图8所示。baseline中原始扩张卷积的ERF是显而易见的。它对应于3×3滤波器,在非零权重之间插入零。 这种过滤器导致gridding问题。对于我们提出的degridding方法,我们可以看到它们使ERF平滑从而达到degridding。此外,由于SS操作,两种方法都扩展了ERF的矩形大小。第二个选择的块是由扩张卷积层组成的整个块,其包括编码器的最后两个块。 图9显示了ERF可视化。在两种提出的方法中,网格伪影(gridding artifacts)都得到了清晰的平滑。实际上,只有baseline的最左侧可视化具有表示零权重的黑色像素。特别是,我们注意到“SS FC”仍然具有类似网格的可视化。这样的一个原因是block-wise 操作可能导致块的grides更大。然而,它减轻了逐像素局部信息的不一致性,并且改善了有扩张卷积的DCNN。


Figure 8是对网络的最后一个block 进行ERF,Figure 9 是对网络的最后两个block进行ERF。白色部分越大说明效果越好。
5.结论
在这项工作中,我们提出了两种基于扩张卷积分解的简单而有效的degridding方法。所提出的方法在两个方面不同于现有的degridding方法。首先,我们根据单个扩张卷积运算而不是级联中的多个层来解决网格伪影(gridding artifacts)。其次,我们的方法只需要学习可忽略不计的额外参数。实验结果表明,它们显着且一致地改善了扩张卷积的DCNNs。平滑效应也在有效感受野(ERF)分析中可视化了。通过进一步分析,我们将两种提出的方法联系在一起,并定义为可分离和共享操作。新定义的可分离和共享卷积操作是通用的神经网络操作,因此可能成为通用的degridding策略。我们将在未来的工作中探索这个方向。 目前的研究主要集中在二维情况下的degridding,但这些方法是通用的,可以应用于其他设置。我们将在文本分析的背景下探索他们在一维案例中的应用。
优点是增加的参数数量较少,没有加重计算负担,并且结构新颖、简单,与数据集和output layer无关,可以广泛应用。缺点是效果提升不是特别高。文中对于效果提升不高的原因也没有详细解释