无监督学习方面的两篇巨作simclr与MoCo介绍
一、SIMCLR介绍
论文网址
代码链接
提出了一个简单的视觉表征对比学习框架SimCLR。简化了最近提出的对比自监督学习算法,而不需要专门的架构或内存库。为了了解是什么使得对比预测任务能够学习有用的表征,系统地研究了框架的主要组成部分。该文章发现:
(1)数据扩充的组合对定义有效的预测任务起着至关重要的作用。
(2)在表示和对比损失之间引入一种可学习的非线性变换,大大提高了学习表征的质量。
(3)与监督学习相比,对比学习具有更大的批量和更多的训练步骤。通过结合这些发现,能够在ImageNet上大大优于以前的自监督和半监督学习方法。利用SimCLR学习的自监督表示训练的线性分类器达到了76.5%的top-1准确率,比先前的技术水平提高了7%,与有监督ResNet-50的性能相当。当仅对1%的标签进行微调时,前5名准确率达到85.8%,比AlexNet少100个标签。
SimCLR不仅优于以前的工作,而且更简单,既不需要专门的架构,也不需要内存库。为了了解什么能使对比表征学习变得更好,系统地研究了框架的主要组成部分,并表明:
1.在定义对比预测任务时,多个数据扩充操作的组合产生有效的表达是至关重要的,此外,与有监督学习相比,无监督对比学习的数据增强能力更强。在表征和对比损失之间引入一种可学习的非线性变换,大大提高了学习表征的质量。
2.具有对比交叉熵损失的表征学习得益于标准化嵌入和适当调整的温度参数。
3.对比学习与监督学习相比,更大的批量和更长的训练时间有利于对比学习。与监督学习一样,对比学习得益于更深更广的网络。
SimCLR通过在潜在空间中的对比损失最大化同一数据示例的不同增强视图之间的一致性来学习表示。该框架包括以下几个主要组件。
1.一种随机数据扩充模块,它随机转换任何给定的数据实例,从而得到同一实例的两个相关视图。在这项工作中,依次应用了三个简单的增强:随机裁剪,然后调整到原始大小,随机颜色扭曲,随机高斯模糊。随机裁剪和颜色失真的结合是获得良好性能的关键。
使用TensorFlow进行颜色失真的伪代码如下所示。
import tensorflow as tf
#import random
def color_distortion(image, s=1.0):
# image is a tensor with value range in [0, 1].
# s is the strength of color distortion.
def color_jitter(x):
# one can also shuffle the order of following augmentations
# each time they are applied.
x = tf.image.random_brightness(x, max_delta=0.8*s)
x = tf.image.random_contrast(x, lower=1-0.8*s, upper=1+0.8*s)
x = tf.image.random_saturation(x, lower=1-0.8*s, upper=1+0.8*s)
x = tf.image.random_hue(x, max_delta=0.2*s)
x = tf.clip_by_value(x, 0, 1)
return x
def color_drop(x):
image = tf.image.rgb_to_grayscale(image)
image = tf.tile(image, [1, 1, 3])
# randomly apply transformation with probability p.
image = random_apply(color_jitter, image, p=0.8)
image = random_apply(color_drop, image, p=0.2)
return image
2.一种基于神经网络的编码器,从扩充的数据示例中提取表示向量。框架允许在没有任何约束的情况下选择各种网络架构。

3. 不使用内存库训练模型。相反,将批训练大小N从256变为8192。批处理大小为8192,从两个增强视图来看,每对正样本都有16382个。当使用标准SGD/Momentum和线性学习率缩放时,大批量训练可能不稳定。为了稳定训练,对所有批次使用LARS优化器尺寸。使用云TPU训练模型,根据批量大小使用32到128个核心。

图4。所研究的数据扩充算子图解。每一种增广方法都可以随机地对数据进行一些内部参数(如旋转度、噪声级)的变换。注意,只在烧蚀中测试这些操作符,用于训练模型的增强策略只包括随机裁剪(带翻转和调整大小)、颜色失真和高斯模糊。
表6。基于不同自监督方法学习的线性分类器的ImageNet精度。 显示了 SimCLR 与之前方法在线性估计方面的对比。从表中可以看出,用 SimCLR 方法使用 ResNet-50 (4×) 架构能够得到与监督预训练 ResNet-50 相媲美的结果。

表 7 显示了 SimCLR 与之前方法在半监督学习方面的对比。从表中可以看出,无论是使用 1% 还是 10% 的标签,该文提出的方法都显著优于之前的 SOTA 模型。
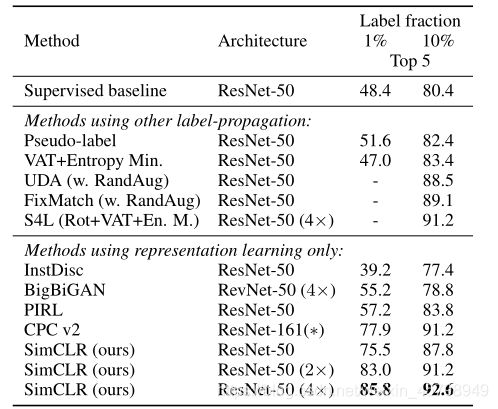
表8。在ImageNet上预训练的ResNet-50(4×)模型下,自监督方法与监督基线在12个自然图像分类数据集上的传输学习性能比较。结果不明显差于最佳(p>0.05,排列检验)以粗体显示。关于标准ResNet-50的实验细节和结果,
二、MoCo 介绍
moco1
moco2
代码
Facebook AI 研究团队的何恺明等人提出了一种名为动量对比(MoCo)的无监督训练方法。在 7 个与检测和分割相关的下游任务中,MoCo 可以超越在 ImageNet 上的监督学习结果,在某些情况下其表现甚至大大超越后者。
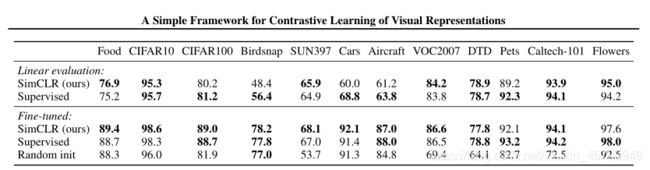
摘要:在无监督的视觉表征学习上,近来的一些研究通过使用对比损失(constrative loss)的方法取得了不错的效果。这些方法都可以被认为和动态词典(dynamic dictionary)相关。在词典中,键(token)是通过从数据(如图像等)中进行采样得到的,然后使用一个编码器网络转换为表征。无监督学习则训练编码器,用于词典的查找工作,即一个编码的「查询(query)」应该和与之匹配的键相似,与其他键不相似。这样的一个学习过程可以被构建为减少对比损失。在本次研究中,何恺明等研究者提出了一种名为动量对比(Momentum Contrast,简称 MoCo)的方法。这种方法旨在通过对比损失为无监督学习建立大型、一致的词典(如下图 1所示)。研究者将词典维护为一个数据样本队列:当前 mini-batch 编码表征将进入队列,而最老的将退出队列。该队列将词典大小与 mini-batch 大小解耦,从而允许词典变大。此外,由于词典键来自前面的几个 mini-batch,因此研究者提出使用一个缓慢前进的键编码器,作为基于动量的查询编码器的移动平均值,以保持一致性。
无监督表征学习在自然语言处理中是非常成功的,如GPT和BERT所示。但是,有监督的预训练在计算机视觉中仍然占主导地位,而无监督的方法通常落后于后者。原因可能是它们各自信号空间的差异。语言任务有离散的信号空间(单词、子词单元等),用于构建符号化词典,无监督学习可以基于这些空间。相比之下,计算机视觉更关注词典的构建,因为原始信号是在一个连续的高维空间中,并且不是为人类交流而构建的。
最近的几项研究提出了使用与对比丢失相关的方法进行无监督视觉表征学习的有希望的结果。这些方法虽然受到各种动机的驱动,但可以看作是构建动态词典。字典中的“键”(令牌)是从数据(例如,图像或补丁)中采样的,并由编码器网络表示。无监督学习训练编码器执行字典查找:一个编码的“查询”应该与其匹配的密钥相似,而与其他查询不同。学习被定义为最小化对比损失。
对比学习可以推动各种各样的 pretext 任务。该文的重心并不是重新设计新的 pretext 任务,而是根据以前的实例辨别任务建立起一个新的任务。
根据之前研究所实例辨别任务,研究者考虑将一对查询和键作为正样本对(positive sample pair),如果它们出自同一图像,否则将它们作为负样本对(negative sample pair)。研究者在随机数据增强下从同一图像中提取两个随意的「视图」,以构建正样本对。查询和键分别由各自对应的编码器 f_q 和 f_k 进行编码。编码器可以是任何架构的卷积神经网络。
下面算法 提供了该 pretext 任务所需的 MoCo 伪代码。对于当前的 mini-batch,研究者编码了查询以及对应的键,这些查询和键形成了正样本对。负样本对则来自队列(queue)。
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
实验方法:
研究者在以下数据集上进行了无监督训练。
ImageNet-1M (IN-1M):这是一个 ImageNet 上的训练集,有 128 万张图像,分成 1000 个类。计算图像数量,因为无监督学习不会利用类)。这个数据集的类分布非常均衡,它的图像通常包含对象的图标视图。
Instagram-1B (IG-1B):这是一个有着近 10 亿图像的公开图像数据集,来自 Instagram。这些图像有 1500 个和 ImageNet 分类相关的标签。这一数据集相比 ImageNet 是更无标注的,有着长尾、不平衡的数据分布。此数据集包含图标对象和场景级图像。
训练方法上,研究者使用了 SGD 作为优化器,权重下降值设为 0.0001,动量则设为 0.9。在 (IN-1M)数据集上,批大小为 256的小批量,使用 8 个 GPU 训练,初始学习率是 0.03。研究者训练了 200 个 epoch,并在 120 和 160 个 epoch 的时候,将学习率乘以 0.1。这一训练使用的是 ResNet-50 网络,用了 53小时。
对于 IG-1B,研究者使用了 1024 的批大小和 64 个 GPU 进行训练。学习率为 0.12,并在每 62.5k 次迭代后就衰减 0.9。在这个实验上研究者训练了 1.25M 次(大约 1.4 个 epoch)。使用的依然是 ResNet-50,花了 6 天时间。
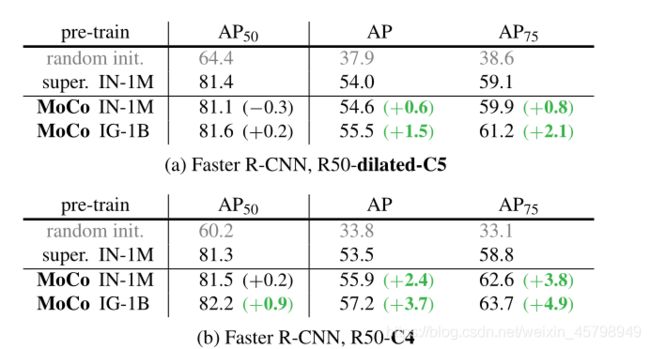
下图展示MoCo、end-to-end 和 memory bank 三种不同对比损失机制在 ImageNet 线性分类评价标准下的对比结果。

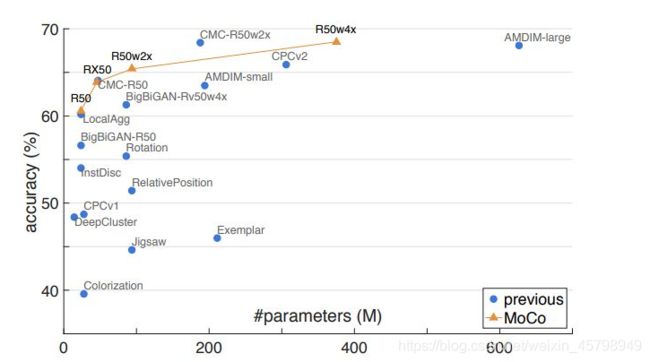
表 1:在 ImageNet 数据集上,MoCo 与其他方法在线性分类评价标准下的对比结果。
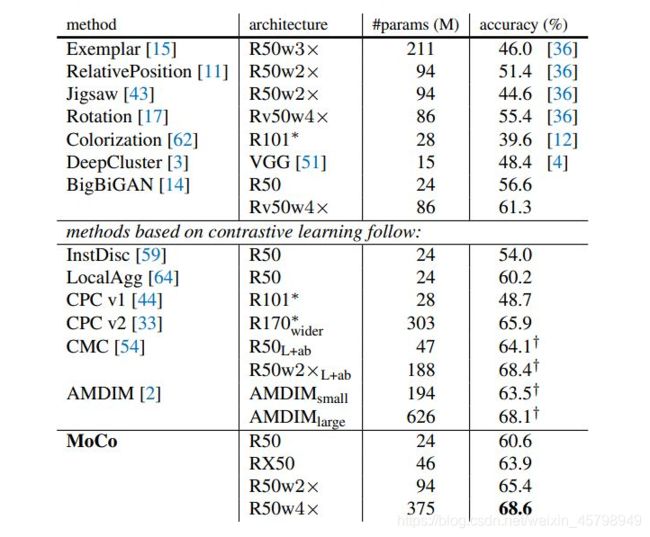
表2:在PASCAL VOC trainval07+12上微调目标检测。评估是在test2007:AP50(默认VOC指标)、AP(COCO风格)和AP75上进行的,平均5次试验。所有这些都针对24k次迭代(23个时期)进行了微调。括号中是与ImageNet监督的预培训对应方的差距。绿色表示间隙至少为+0.5点。
三、MOCO2介绍
摘要:对比无监督学习最近取得了令人鼓舞的进展,例如动量对比(MoCo)和SimCLR。在此文中,通过在MoCo框架中实现SimCLR的两个设计改进来验证它们的有效性。通过简单的修改tomoco,即使用MLP投影头和更多的数据扩充,建立了性能优于SimCLR的更强大的基线,并且不需要大量的训练批。希望这将使最先进的无监督学习研究更容易获得。
最近关于从图像中进行无监督表征学习的研究正在集中于一个被称为对比学习的中心概念。结果是有希望的:例如,动量对比(MoCo)表明,无监督预训练可以在多个检测和分割任务中优于其ImageNet监督的同类,SimCLR进一步缩小了无监督和有监督预训练表示之间在线性分类器性能上的差距。说明建立了在MoCo框架中建立的更强大和更可行的基线。报告了在SimCLR中使用的两个设计改进,即MLP投影和更强的数据增强,它们与MoCo和SimCLR框架是正交的,与MoCo一起使用可以获得更好的图像分类和目标检测传输学习结果。此外,MoCo框架可以处理大量的阴性样本,而不需要大量的训练批(图1)。与SimCLR需要TPU支持的4k∼8k大型批处理不同,“MoCo v2”基线可以在典型的8-GPU机器上运行,并获得比SimCLR更好的结果。希望这些改进后的基线能为今后无监督学习的研究提供参考。
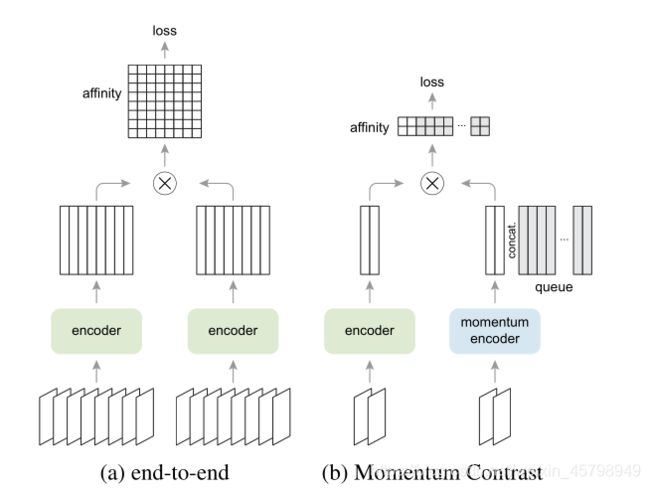
图1:两种对比学习优化机制的批处理视角。图像被编码到一个表示空间中,在这个空间中计算成对的仿射。

对simclr的改进:
SimCLR从三个方面改进了实例识别的端到端变体:
(i)大批量(4k或8k),可以提供更多的负样本;
(ii)用MLP替换输出fc投影;
(iii)更强的数据扩充。在MoCo框架中,大量的负样本是现成的;MLP和数据扩充与对比学习的实例化方式是正交的。
改进实验
设置:在1.28M ImageNet训练集上进行无监督学习。遵循两种常见的评估协议。 1.ImageNet线性分类:特征被冻结并训练一个有监督的线性分类器;研究者报告了1-crop(224×224),top-1验证精度。
2.转换为VOC目标检测:更快的R-CNN检测器(C4主干)在VOC 07+12 trainval集合1上进行端到端微调,并使用COCO度量套件对VOC 07测试集进行评估。使用与MoCo相同的超参数和代码库。所有结果都使用标准尺寸的ResNet-50。
MLP head:在simclr之后,将MoCo中的fc头替换为2层MLP头(隐藏层2048-d,使用ReLU)。注:这只影响无监督训练阶段;线性分类或转移阶段不使用此MLP头。:
使用默认τ=0.07,使用MLP头进行预训练将从60.6%提高到62.9%;切换到MLP的最佳值(0.2),准确度提高到66.2%。表1显示了它的检测结果:与ImageNet上的巨大飞跃相比,检测增益更小。
表1。消融MoCo基线,用ResNet-50评估(i)ImageNet线性分类,(ii)微调VOC目标检测(5次试验的平均值)。“MLP”:带MLP头;“aug+”:带额外模糊增强;“cos”:余弦学习速率计划。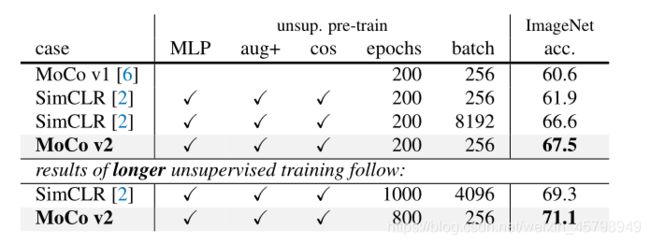
表2:MoCo与SimCLR:ImageNet线性分类器精度(ResNet-50,1-crop 224×224),根据无监督预训练的特征进行训练。SimCLR中的“aug+”包括模糊和更强的颜色失真。
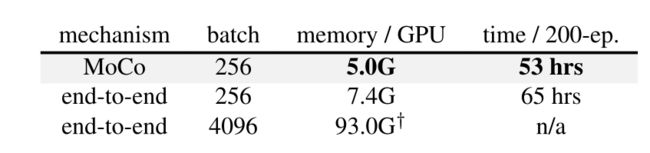
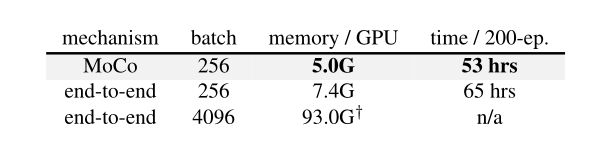
表3:在Pytorch中实现的8 V100 16G GPU内存和时间成本。
与SimCLR进行比较:
表2将SimCLR与MoCo v2进行了比较。为了公平比较,研究了SimCLR采用的余弦(半周期)学习速率调度。见表1(d、e)。使用200个时期和256个批次的预训练,MoCo v2在ImageNet上达到67.5%的准确率:在相同的时间段和批次大小下,这比SimCLR的大批量结果高5.6%,优于SimCLR的大批量结果66.6%。经过800个epoch的预训练,MoCo v2达到了71.1%,超过了SimCLR在1000个epoch时的69.3%。
计算成本。在表3中,研究者报告了实现的内存和时间开销。端到端案例反映了gpu中的SimCLR成本)。4k的批处理大小即使在高端的8-GPU机器中也是难以处理的。同样,在256的批处理大小下,端到端变量在内存和时间上仍然比较昂贵,因为它反向传播到q和k编码器,而MoCo只反向传播到q编码器。
表2和表3表明,为了获得良好的准确度,无需大批量生产,并且可以使最新的结果更容易获得。研究的改进只需要对mocov1进行几行代码更改。