论文推荐:DCSAU-Net,更深更紧凑注意力U-Net
这是一篇23年发布的新论文,论文提出了一种更深、更紧凑的分裂注意力的U-Net,该网络基于主特征守恒和紧凑分裂注意力模块,有效地利用了底层和高层语义信息。
DCSAU-Net
1、架构
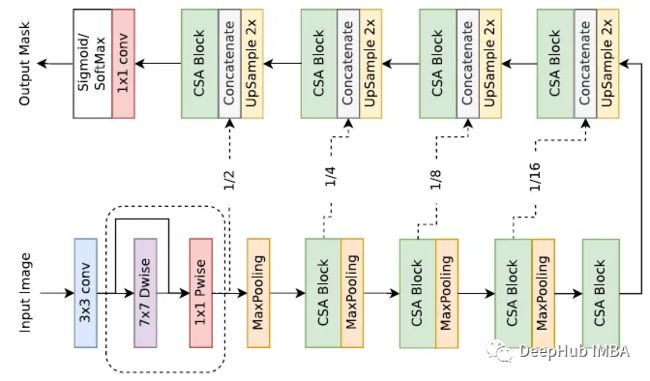
- DCSAU-Net 的编码器首先使用 PFC 策略从输入图像中提取低级语义信息。
- CSA 块应用具有不同卷积数和注意机制的多路径特征组。
- 每个CSA块后面跟着一个步长为 2 的 2×2 最大池化,用于执行下采样操作。
- 解码器通过采样逐步恢复输入图像的原始大小。
- skip connections 用于将这些特征图与来自相应编码层的特征图连接起来,混合低级和高级语义信息以生成精确的掩码。
- 最后 1×1 卷积后接一个 sigmoid 或 softmax 层被用来输出二进制或多类分割掩码。
- 训练的损失函数为 Dice loss。
2、PFC (Primary Feature Conservation)策略
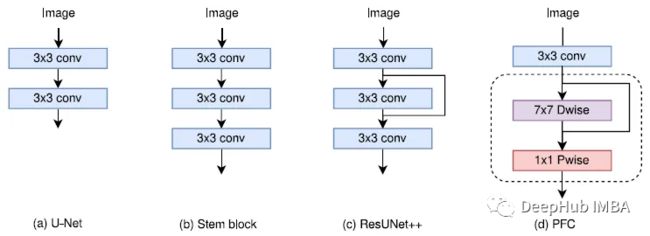
上图的4个PFC策略介绍
(a) U-Net:使用两个3×3卷积进行底层特征提取。
(b) Stem Block[44]:使用3个3×3卷积获得与7×7卷积相同的接受域,减少参数数量。
© resunet++[27]:使用三个3×3卷积和跳过连接来减轻梯度消失的潜在影响。
(d) 一种新的策略(PFC)。该模块的主要改进采用了深度可分离卷积,如MobileNetV1,由7×7深度卷积和1×1点卷积组成。
3、CSA (Compact Split-Attention) Block
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5n2pGTKS-1681007652112)(null)]
ResNeSt利用大通道分割组进行特征提取。论文采用2组(N=2)来减少参数的数量。这两组都包含一个1×1卷积和一个3×3卷积。
为了改进跨通道的表示,另一组(2)的输出特征图将第一组(1)的结果求和,并进行另一个3×3卷积,可以接收来自两个分裂组的语义信息,扩大网络的接受场。F1和F2的和(中间的和)为:
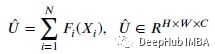
通过global average pooling(GAP)生成的通道统计数据收集全局空间信息:

channel-wise soft attention 用于聚合由基数组表示的加权融合,其中拆分加权组合可以捕获特征图中的关键信息。第通道的特征图计算为:
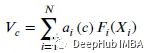
这里的是一个(软)赋值权重,计算方式如下:

Gci表示全局空间信息对 th通道的权重,并使用两次1×1卷积(BatchNorm和ReLU激活)进行量化。最后,完整的CSA块使用标准残差架构(ResNet),输出使用跳过连接计算:=+X。
结果
1、SOTA比较

5个数据集用于训练和评估。Dice Score (DSC)是用来测试的。
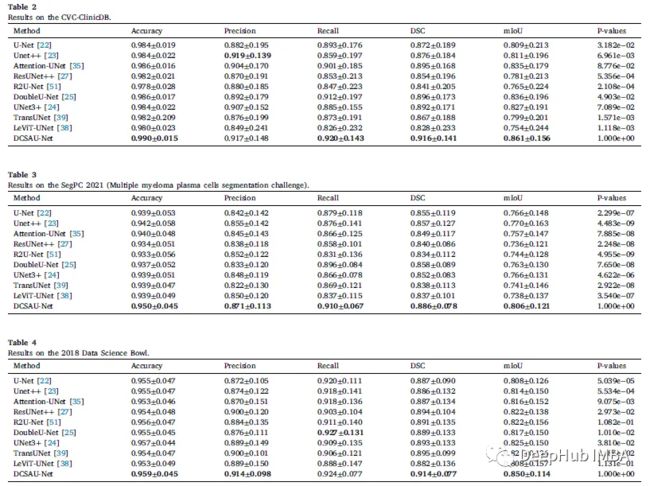
在CVC-ClinicDB 表2中,DCSAU-Net的DSC为0.916,mIoU为0.861,优于DoubleU-Net 2.0%, mIoU优于DoubleU-Net 2.5%。还有需要说明的是模型相对于最近的两种基于transformer的架构有了显著的改进,其中mIoU比TransUNet和LeViTUNet分别高6.2%和10.7%。
SegPC-2021 表3中,与其他SOTA模型相比,DCSAU-Net在所有定义的指标中显现了最佳性能。该方法产生的mIoU分数为0.8048,比unet++提高了3.6%,在DSC上比DoubleU-Net提高了2.8%。
2018 data science bowl 表4中,DCSAU-Net的DSC为0.914,比TransUNet高1.9%,mIoU为0.850,比UNet 3+高2.5%。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l9KUDbG3-1681007652488)(null)]
ISIC-2018 表6中,DCSAU-Net 在指标上比levite提高了2.4%,DSC比UNet 3+增加了1.8%。该模型的recall 为0.922,accuracy 为0.960,优于其他基线方法。特殊说明:高recall更有利于临床应用。
BraTS 2021 表7,DCSAU-Net 的DSC为0.788,mIoU为0.703,分别比ResUnet++高1.7%和2.1%。
2、消融实验
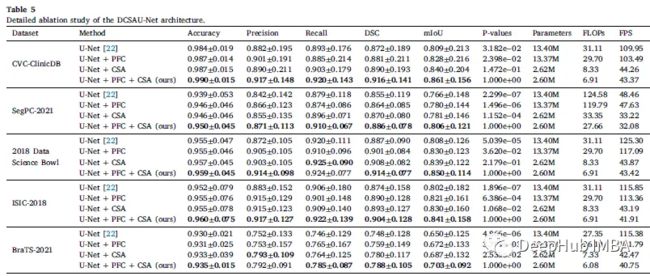
虽然 U-Net 的推理时间比 DCSAU-Net 模型短,但论文的方法在相等的输出特征通道中使用更少参数,更适合部署在内存有限的机器上(也就是时间换空间)
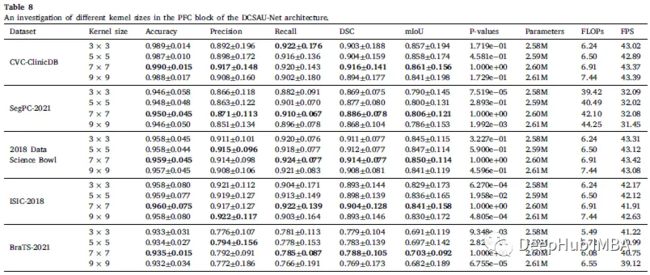
论文研究了不同核大小对深度卷积的影响。7×7获得最佳性能。
3、结果可视化

其他SOTA模型对五种不同医疗分割数据集挑战性图像的定性比较结果。
从定性结果来看,模型生成的分割掩码能够从不完全着色或模糊等低质量图像中捕捉到更合适的前景信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h1UCWrlD-1681007652161)(null)]
上图为在5个医学图像分割数据集上,模型无法从图像中分割出目标的情况。DCSAU-Net也会因为细胞核尺寸小,或者前景与背景相似度高而失败。
下图为5个医学图像分割任务的测试数据集上的前20个epoch的可视化。

可以看到模型收敛速度明显快于其他SOTA方法。
论文地址:https://avoid.overfit.cn/post/80c002a556cf4397aff76edfa62f16d0
本文作者:Sik-Ho Tsang