【论文笔记】Efficient Learning of Goal-Oriented Push-Grasping Synergy in Clutter
文章目录
- 【论文笔记】Efficient Learning of Goal-Oriented Push-Grasping Synergy in Clutter
-
- Abstract
-
- Index Terms
- I. INTRODUCTION
- II. RELATED WORK
-
- A. Grasping
- B. Pushing Assisted Grasping
- III. METHOD
-
- A. Goal-Conditioned Grasping Training
- B. Goal-Conditioned Pushing Training
- C. Alternating Training
- D. Implementation Details
- IV. EXPERIMENT
-
- A. Evaluation Metrics
- B. Simulation Experiments
- C. Real-World Experiments
- 自己跑的实验
【论文笔记】Efficient Learning of Goal-Oriented Push-Grasping Synergy in Clutter
Abstract
【研究内容】我们关注目标导向抓取任务,即机器人在杂乱中抓取预先分配的目标对象,需要一些预抓动作,如推动,来实现稳定的抓取。
【研究问题】存在三个问题:
- 机器人只有在成功抓住目标对象时,才能从环境中获得正向的奖励(存在稀疏奖励的特性)。
- 机器人联合推握和抓握延长了动作序列,加剧了奖励延迟的问题。
- 这样的任务中,样本效率低下仍然是这项任务中的一个主要挑战。
【解决思路】本文提出了一种具有高样本效率的目标条件存在下的分层强化学习范式,来学习在杂乱无章物体中,抓取特定对象的推抓取策略。
【具体技术路线】解决样本效率问题具体以下方式实现。
- 通过目标重新标记(relabeling),使用目标条件机制(goal-conditioned mechanism)来丰富经验池。
- 将推握策略和抓握策略分别视为生成器(generator)和鉴别器(discriminator),在抓握鉴别器的监督下对推握策略进行训练,从而强化推握奖励。
- 为了解决两种策略的不同训练背景导致的分布不匹配问题,增加了一个交替训练阶段,依次学习推取和抓取。
【实验过程】在仿真和现实世界中进行的一系列实验。此外还验证了系统也可以更好适应与目标无关的条件。系统可以被转移到现实世界中,而不需要进行任何微调。
【实验指标】任务完成率、目标抓取成功率
【实验链接】 https://github.codm/xukechun/Effificient_goaloriented_push-grasping_synergy
Index Terms
- deep learning in grasping and manipulation
- grasping
- reinforcement learning
I. INTRODUCTION
-
研究背景?
在这些任务中,机器人通常面临一个杂乱的场景,在目标物体周围的紧密包装可能会严重退化成功的抓取。
受到人类行为的启发,推动和抓握之间的协同作用成为了处理这种情况的解决方案。通过推动杂乱无章的物体,可以在目标物体周围有空间提供给机械臂夹持器插入其中。
-
在推抓协同背景下,关键科学问题?
制定推抓协同操作策略,这样用更少的推力步骤就可以获得高成功率的抓取。
-
在(无特定目标)推抓协同背景下,前人是如何解决这样的问题?
-
使用两个并行网络进行推和抓,学习推和抓策略。
Learning synergies between pushing and grasping with self-supervised deep reinforcement learning
-
一个层次化的框架,通过评估执行当前的推步骤后机器人是否可以抓取。
[4] Deep reinforcement learning for robotic pushing and picking in cluttered environment
https://blog.csdn.net/m0_48948682/article/details/125618937
[5] Combining reinforcement learning and rule-based method to manipulate objects in clutter
https://blog.csdn.net/m0_48948682/article/details/123644227
这篇文章的奖励函数只是设置了 “能抓取就有奖励,有推动一小段距离就有奖励”,并非针对特定物体,因此是没有目标的。
作者认为:这些方法的一个缺点是不能指定抓取对象,因此只适用于目标不可知的任务。
-
-
在(特定目标)推抓协同背景下,前人是如何解决这样的问题?
-
(基于物理特性)使用基于物理的分析来计算已知的目标对象三维模型的推和抓取。
Physics-based grasp planning through clutter
-
(基于前人模型改进)简单地将这些方法应用于目标导向的任务,就是在抓取地图上应用一个目标对象的掩模
但结果并不令人满意
A deep learning approach to grasping the invisible
-
(通过设计网络结构)稀疏奖励环境下训练的工作。
Robust object grasping in clutter via singulation
Split deep q-learning for robust object singulation
https://blog.csdn.net/m0_48948682/article/details/125256153
主要做的是对特定物体的分离,定义了两个q学习过程:对障碍物推 和 对目标物的推
作者认为:这些方法的既定背景都是在人为参与较多的 / 稀疏奖励的环境下进行。
-
(通过设计手工奖励函数)通过手工设计奖励函数来开发更密集的奖励,来鼓励机器人通过移动物体和消除杂乱来进行抓取
A deep learning approach to grasping the invisible
论文作者认为推握和抓握之间的关系是复杂的和耦合的,导致手工设计的最佳推握奖励功能非常困难
Linear push policies to increase grasp access for robot bin picking
-
-
推抓协同任务的难点是?
机器人在目标导向的任务中更难从环境中获得正向的奖励,导致训练的样本效率较低。
无定向目标 ⟶ \longrightarrow ⟶ 抓取即能获得奖励;目标导向任务 ⟶ \longrightarrow ⟶ 会抓取且抓的对;
-
作者的工作概述?
- 将该任务描述为一个目标条件的分层强化学习问题,并从头开始学习该模型。
- 通过利用目标条件的学习机制,可以获得更密集的奖励来加速学习。(区别前人手工设计的奖励函数)
- 如果成功抓取除指定对象以外的对象,我们将经验池中相应经验的目标重新标记到抓取的目标,以提高采样效率。
- 通过反向应用对抗性训练来设计推动奖励,以建立推与抓之间的协同作用。以抓取作为鉴别器,对抗性训练鼓励机器人推动杂乱无章物体,生成目标对象可高概率捕获的场景。这个我没看懂,要加强理解。
- 交替训练抓取网和推网,以缓解分布不匹配的问题,最终发展了两种行动之间的协调。(区别前人并行网络,解决前人并行网络出现的潜在的问题)
II. RELATED WORK
A. Grasping
数据驱动方法专注于从视觉观察到行动的直接映射。前提假设是:场景足够分散,其中物体是很孤立的。
机器人在杂乱环境下抓取的学习。但是杂乱环境下只有抓取动作。
需要设置一些预抓取操作,如一些必要的推动操作。
B. Pushing Assisted Grasping
作者详细介绍了在==(无特定目标)和(特定目标)==推抓协同背景下的工作。
- 首先,有些方法完全通过手工设计了推送奖励函数,这可能需要多次迭代来调优,并且缺乏对新场景的泛化。相比之下,数据驱动的奖励将通过机器人的经验自动优化自己,以学习超越人类直觉的洞察力,这也更节省时间和有效。
我们的方法主要是从一个数据驱动的神经网络中获得推动奖励,该神经网络预测成功抓取的概率,从后验经验中学习,并结合智能体手工制作的推动奖励作为重要的先验知识。
- 其次,以往的目标导向抓取或单一工作没有利用非目标对象的抓取或单一经验,因此需要更多的样本来训练策略。
受目标重标记(后视经验回放)算法(Hindsight Experience Replay)的启发,我们使用目标条件学习机制将推和抓取体验与抓取目标重新标记,以提高样本效率,并将推和抓取目标扩展为相应的抓取目标。
III. METHOD
这部分介绍的是建模过程,增加了特定目标 g g g。
策略、奖励函数、Q函数分别是: π ( s t ∣ g ) \pi(s_{t}|g) π(st∣g)、 R ( s t , a t , g ) R(s_t,a_t,g) R(st,at,g)、 Q π ( s t , a t , g ) Q_{\pi}(s_t,a_t,g) Qπ(st,at,g)
-
系统的图像输入?
在重力方向上架设深度相机,捕捉彩色高度图 c t c_{t} ct 和深度高度图 d t d_t dt ;
为了表示特定的目标物体,往系统里提供了掩膜图像 m t m_{t} mt ;
高度图表征图像沿着 z z z 轴旋转16次,每次 22.5 22.5 22.5 度;
最后整合成数据集,输入到系统中。
-
系统输出的动作定义?
- 推由 起始位置 和具有固定 推长度的推方向 参数化动作
- 抓取是定义的 中间位置 和 夹的平行颚的方向 与固定的宽度。
-
分层强化学习的设计?
-
for 高层网络:
高层抓取网 φ g φ_g φg 作为一个鉴别器,为目标对象抓取的当前状态进行评分。
如果抓取目标对象的得分超过一个阈值,机器人将执行 Q Q Q 值最大的抓取动作。
当得分没有超过阈值 → \rightarrow → 当前状态不适合抓取 → \rightarrow → 激活低层网络。
-
for 低层网络:
机器人执行推送动作来转移该状态
直到鉴别器(高层网络)能够认为这样的抓取状态合理(达到一定阈值)
-
分层强化学习的推抓导向?
推网和抓取网(即 φ p φ_p φp、 φ g φ_g φg)都将状态 s t s_t st 的高度图表征以及目标对象的掩模作为输入
输出与高度图表征具有相同的图像大小和分辨率的 Q Q Q 值的密集像素级映射
一个像素上的每个 Q Q Q 值都代表了在对应的三维位置执行原语的未来预期奖励
其深度分量是根据深度高度图计算出来的
-
-
分层强化学习的三个训练过程?
Stage I: Goal-conditioned Grasping Training.
为了提升样本效率,将已抓取成功的非特定目标物体的经验,标记为成功的经验。
作者认为:经过很长的 episodes 后,输出的 Q Q Q 值密集像素级映射,可以达到一个稳定的数值,可以通过设置阈值来过滤掉低的 Q Q Q 值,实现抓取
Stage II: Goal-conditioned Pushing Training.
在这一阶段对一个推网的训练,并且预先(第一阶段)训练的抓取网的参数是固定的。
推只有在协助未来的抓取时才被认为是有效的;
因此推式奖励功能是基于抓取网设计的,反向利用对抗性训练。
如果推动提高了抓取网预测的可抓概率,则将获得正奖励。
同时,还使用了目标条件机制,将抓取目标和顺序推动经验与抓取目标重新关联起来,以提高样本效率。
Stage III: Alternating Training.
在前一阶段,我们只考虑将抓取网作为专家,并在训练推网时固定其网络参数。
前一种抓取网是在一个相对分散的环境中训练的,在目标物体周围很少有遮挡,只有抓取动作。
在这一阶段,我们的目标是通过交替训练来进一步提高我们在混乱环境中的推动和抓取策略的性能,以缓解分布不匹配的问题。
A. Goal-Conditioned Grasping Training
在这个阶段,机器人只执行抓握动作,每次抓握都对应一个episode。
为了减少遮挡的影响,创建了一个相对分散的场景,通过在工作空间中随机放置对象。
R g = { 1 , if grasping goal object successfully 0 , otherwise (1) R_g=\begin{cases}1,\text{if grasping goal object successfully}\\0,\text{otherwise}\end{cases}\tag{1} Rg={1,if grasping goal object successfully0,otherwise(1)
通过利用这些错误的对象捕获样本,我们提高了样本的效率,从而加快了训练的速度。
经验重标记技术
作者思考:抓取失败对抓取性能完全有害,而抓取对象的错误可以作为提高样本获取效率的宝贵经验。
作者做法:当目标物体被其他物体遮挡时,机器人很可能会意外地抓住一个非目标物体 g ′ g^{\prime} g′。如果发生这种情况,我们在状态转移元组 ( s t , a t , r t , g ) (s_t,a_t,r_t,g) (st,at,rt,g) 中的 g g g 重新标记为 ( s t , a t , r t , g ′ ) (s_t,a_t,r_t,g^{\prime}) (st,at,rt,g′) ,其中 r t = R ( s t , a t , g ′ ) r_{t}=R(s_t,a_t,g^{\prime}) rt=R(st,at,g′),并将此经验保存到重放缓冲区中以训练我们的策略。
在接下来的阶段中,我们认为当目标掩模内的最高预测 Q Q Q 值超过 Q g ∗ Q^{\ast}_g Qg∗ 时,当前状态已经准备好进行目标对象抓取。
B. Goal-Conditioned Pushing Training
在这个阶段,我们的目标是学习推动,以使用尽可能少的步骤来实现未来的掌握。
在最后,将推数限制在 5 5 5 个。此外,如果目标掩模内的最高 Q Q Q 值超过阈值 Q g ∗ Q^{\ast}_g Qg∗ 时候,智能体将立即执行终端抓取动作。在一 episode 中, b b b 个不同的物体被随机地放置在场景中以产生混乱。
推和抓握之间的相互作用是复杂和耦合的,因此很难完全建模手工推奖励。
为了应对这一挑战,我们在抓取网的引导下,通过反向应用对抗性训练来训练我们的推动策略。
反向应用对抗性训练技术
作者思考:抓取是一步式的动作,因此抓取网可以用其预测的抓取 q q q 值来评估当前状态的可抓取概率。
作者做法:1. 将抓取网作为一种鉴别器,可以区分目标对象抓取的良好状态,具有 Q Q Q 值阈值 Q g ∗ Q^{\ast}_g Qg∗ ,推断出高可抓概率。2. 将推网建模为一个生成器,通过执行推动作重新排列目标对象,满足最大抓取 Q g ∗ Q^{\ast}_g Qg∗ 的 Q Q Q 值呼叫抓取鉴别器。
{ min ϕ p V ( D g , G P ) = E [ log ( 1 − D G ( G P ( s t , g ) ) ) ] s t + 1 = G P ( s t , g ) = T ( s t , arg max a t , ϕ P ( s t , a t , g ) ) D g ( s t ) = { 1 , δ > 0 ; − δ , δ < 0 δ = max a t ϕ g ( s t , a t , g ) − Q g ∗ \begin{cases} \min\limits_{\phi_{p}}V(D_{g},G_{P})=E[\log(1-D_{G}(G_{P}(s_t,g)))]\\ s_{t+1}=G_{P}(s_t,g)=T(s_{t},\arg\max\limits_{a_{t}},\phi_{P}(s_t,a_t,g))\\ D_{g}(s_{t})= \begin{cases} 1,\delta>0;\\ -\delta,\delta<0 \end{cases}\\ \delta=\max\limits_{a_{t}}\phi_{g}(s_t,a_t,g)-Q^{\ast}_{g} \end{cases} ⎩ ⎨ ⎧ϕpminV(Dg,GP)=E[log(1−DG(GP(st,g)))]st+1=GP(st,g)=T(st,argatmax,ϕP(st,at,g))Dg(st)={1,δ>0;−δ,δ<0δ=atmaxϕg(st,at,g)−Qg∗
推网络的奖励函数设置:
R p = { 0.5 , Q g i m p r o v e d > 0.1 and change detected ; − 0.5 , no change detected ; 0 , otherwise ; Q g i m p r o v e d = Q g after pushing − Q g before pushing R_{p}= \begin{cases} 0.5,Q_{g}^{improved}>0.1\text{ and change detected}; \\ -0.5,\text{no change detected}; \\ 0,\text{otherwise}; \end{cases} \\ Q_{g}^{improved}=Q_{g}^{\text{after pushing}}-Q_{g}^{\text{before pushing}} Rp=⎩ ⎨ ⎧0.5,Qgimproved>0.1 and change detected;−0.5,no change detected;0,otherwise;Qgimproved=Qgafter pushing−Qgbefore pushing
检测到的变化意味着目标对象周围的变化, o g decreased > 0.1 o_{g}^{\text{decreased}}> 0.1 ogdecreased>0.1,其中 o g o_{g} og 减少表示目标对象周围的占用比的减少,并从深度高度图计算出来。
同样,推也是用了经验重标记技术。
C. Alternating Training
在之前的阶段中,我们的抓取鉴别器只在分散的场景中用抓取动作训练,而推发生器在相对杂乱的场景中学习,这可能会导致分布不匹配问题。
抓取鉴别器在推式抓取协作中可能无法区分一些需要抓取的新场景。
由于我们的推奖励功能是基于抓网,抓网的训练对推网有很大的影响。
交替训练技术
通过固定其他网的参数交替训练,进行抓取和推送策略 ⟶ \longrightarrow ⟶ 推动和抓取策略限制了彼此的正样本。
还匹配了两种策略的数据分布的协同应用。
D. Implementation Details
| 变量和数值 | 含义 |
|---|---|
| a = 5 a = 5 a=5 | 抓取训练的随机掉落的物体数量 |
| b = 10 b = 10 b=10 | 推动训练的随机掉落的物体数量 |
| c = 10 c = 10 c=10 | 工作台下物体的数量 |
| e p o c h pushing = 500 epoch_{\text{pushing}}=500 epochpushing=500 | 推动训练的迭代次数 |
| e p o c h grasping = 1000 epoch_{\text{grasping}}=1000 epochgrasping=1000 | 抓取训练的迭代次数 |
| Q g ∗ = 1.8 Q_{g}^{\ast}=1.8 Qg∗=1.8 | 抓取 Q Q Q 值得阈值大小 |
| three parallel 121-layer pretrained on ImageNet \text{three parallel 121-layer pretrained on ImageNet} three parallel 121-layer pretrained on ImageNet | 目标掩膜网络 |
| learning rates \text{learning rates} learning rates | 1 × 1 0 − 4 1\times10^{-4} 1×10−4 |
| weight decays \text{weight decays} weight decays | 2 − 5 2^{-5} 2−5 |
| betas \text{betas} betas | ( 0.9 , 0.99 ) (0.9,0.99) (0.9,0.99) |
| ϵ \epsilon ϵ-greedy | from 0.5 to 0.1 \text{from }0.5\text{ to }0.1 from 0.5 to 0.1 |
| γ \gamma γ | 0.5 |
IV. EXPERIMENT
- 证明我们的培训方法能够有效地加快训练过程
- 证明我们的策略对于目标导向的随机和具有挑战性的排列是有效的
- 研究我们的方法是否可以扩展到目标不可知的条件
作者提出的三个 baselines:
- Grasping-only 是一种贪婪的确定性抓取策略,使用一个单一的FCN网络采用监督学习的二元分类进行抓取。
- Goal-conditioned VPG 是 VPG 的一个扩展版本,通过添加目标掩模作为输入来学习目标导向的抓取和推动策略。
- Grasping the Invisible 是一种面向目标的方法,它根据二值分类器选择推送或抓取,并应用DQN来训练推送抓取策略。也就是说,如果目标是不可见的,智能体执行推送来探索它,当目标可以被看到时,推送将与抓取协调以捕获它。
A. Evaluation Metrics
- Completion:在 n n n 次测试运行中,完成率的平均百分比。如果策略可以在运行中不连续10次尝试失败地抓取目标对象,则认为该任务已完成。
- Grasp success rate:每次完成的目标掌握成功率的平均百分比。
- Motion number:每次完成时的平均运动数。运动数反映了动作效率,特别是推动效率。
B. Simulation Experiments
-
Parameter Verifification.

抓握网的训练表现。经过大约600次训练后,目标对象的抓取成功率(左)稳定在 80 % 80\% 80% 以上,而抓取 Q Q Q 值(右)稳定在 Q g ∗ = 1.8 Q^{∗}_{g} = 1.8 Qg∗=1.8 以上。 -
Ablation Studies.
我们将我们的方法与几种消融方法进行了比较,以测试我们的技术是否可以提高样本效率,且交替训练是否可以缓解分布不匹配的问题。

这说明我们的对抗性训练和目标条件机制可以有效地提高样本效率,从而加快训练过程。
显示了交替训练前后在目标对象(紫色块)内的抓取Q值的示例分布在交替训练前(中间)和后(右)的目标对象(紫色块)内抓取 Q Q Q 值的示例分布。
我们选择了4个典型的抓取 Q Q Q 图,分别对应于抓取方向0◦、90◦、135◦和180◦来反映效果。随着 Q Q Q 值的增加,颜色趋于红色。在交替训练之前,一些不合理的抓取方法(用红色圆圈突出显示)显示出较高的 Q Q Q 值。这种低质量的抓握力在交替训练后大大减少。所选择的抓握由下巴方向和夹持的中点表示。
-
Comparisons to baselines.

比较了我们的方法与基线的训练性能。
值得注意的是,Grasping the Invisible 的抓取成功率,为 50 − 60 % 50-60\% 50−60%。这可能是由于当目标对象的边缘未被占用时,它倾向于抓取,但自由空间不足以插入夹持器。
-
Goal-agnostic Conditions.
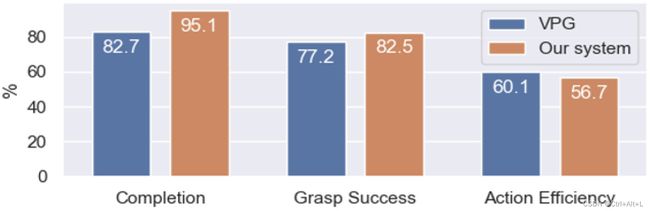
图8所示的结果表明,我们的策略在目标不可知的条件下也能表现良好。设计了实验指标: action efficiency = number of test objects number of actions before completion \text{action efficiency}=\frac{\text{number of test objects}}{\text{number of actions before completion}} action efficiency=number of actions before completionnumber of test objects
C. Real-World Experiments
在现实世界的实验中的测试安排。上面一行显示了4种随机排列,其中右上角显示的目标对象被部分或完全遮挡。
请注意,在第二种情况下的目标对象(即蓝色立方体)完全被棕色块完全遮挡。
下面一行显示了4个具有挑战性的设置,每个目标对象都用一个星号标记。

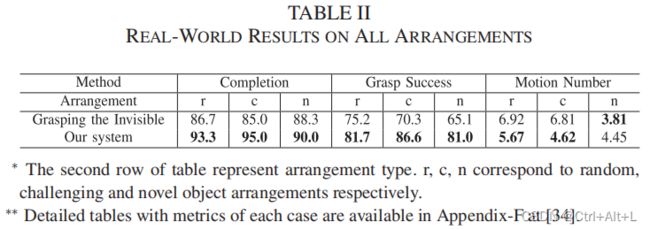
表二的结果证实,我们的方法可以推广到一些物体形状分布与训练物体形状相似的看不见的物体,并且比其他方法具有更好的性能。失败的案例涉及到捕捉一个完全看不见的复杂形状的物体,这可能是由于在训练过程中缺乏这种形状的抓取经验。

自己跑的实验
实验效果:单机单卡(4 GB)会报:Cuda out of memoty
在服务器上运行,截图如下: