Flink的端对端精准一次处理(Exactly-Once)
文章目录
-
- Flink的Exactly Once
- 从Flink和Kafka组合来理解Exactly_Once
- Two-Phase Commit(两阶段提交协议)
- 两阶段提交Flink中应用
Flink的Exactly Once
端对端精确一次处理的意义是:每条消息只会影响最终结果一次即只会影响应用状态异一次,而非被处理一次,即使出现机器故障或者软件崩溃,Flink也要保证不会有数据被重复处理或者没被处理的情况来影响到状态。
Flink 1.4 版本之前,精准一次处理只限于 Flink 应用内,也就是所有的 Operator 完全由 Flink 状态保存并管理的才能实现精确一次处理。但 Flink 处理完数据后大多需要将结果发送到外部系统,比如 Sink 到 Kafka 中,这个 过程中 Flink 并不保证精准一次处理。
在 Flink 1.4 版本正式引入了一个里程碑式的功能:两阶段提交 Sink,即 TwoPhaseCommitSinkFunction 函数。该 SinkFunction 提取并封装了两阶段提交协议中的公共逻辑,kafka 0.11之后,Producer的send操作现在是幂等的,在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次,

实现精确一次处理语义(英文简称:EOS,即 Exactly-Once Semantics)。 在 Flink 中需要端到端精准一次处理的位置有三个:
Source端:数据从上一阶段进入到 Flink 时,需要保证消息精准一次消 费。
Flink 内部端:Flink 分布式快照保存数据计算的状态和消费的偏移量,保证程序重启之后不丢失状态和消费偏移量(也就是利用 Checkpoint 机制,把状态存盘, 发生故障的时候可以恢复,保证内部的状态一致性)

Sink端:将处理完的数据发送到下一阶段时,需要保证数据能够准确无 误发送到下一阶段
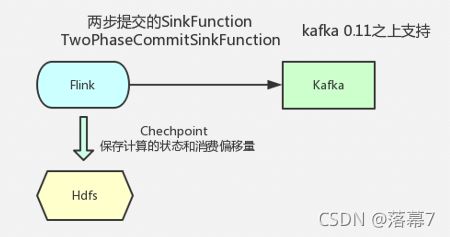
从Flink和Kafka组合来理解Exactly_Once
如上图所示,Flink 中包含以下组件:
- 一个 Source,从 Kafka 中读取数据(即 KafkaConsumer)
- 一个时间窗口化的聚会操作(Window)
- 一个 Sink,将结果写入到 Kafka(即 KafkaProducer)
若要 Sink 支持精准一次处理语义(EOS),它必须以事务的方式写数据到 Kafka, 这样当提交事务时两次 Checkpoint 间的所有写入操作当作为一个事务被提交。 这确保了出现故障或崩溃时这些写入操作能够被回滚。 当然了,在一个分布式且含有多个并发执行 Sink 的应用中,仅仅执行单次提交或 回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得 到一个一致性的结果。Flink 使用两阶段提交协议以及预提交(Pre-commit)阶段来 解决这个问题。
Two-Phase Commit(两阶段提交协议)
两阶段提交协议(Two-Phase Commit,2PC)是很常用的解决分布式事务问题的方式,它可以保证在分布式事务中,要么所有参与进程都提交事务,要么都取消,即 实现 ACID 中的 A (原子性)。 在数据一致性的环境下,其代表的含义是:要么所有备份数据同时更改某个数值, 要么都不改,以此来达到数据的强一致性。 两阶段提交协议中有两个重要角色,协调者(Coordinator)和参与者(Participant), 其中协调者只有一个,起到分布式事务的协调管理作用,参与者有多个。
两阶段提交将提交过程划分为连续的两个阶段:
- 表决阶段(Voting)
- 提交阶段(Commit)

第一阶段:表决阶段
- 1.协调者向所有参与者发送一个 VOTE_REQUEST 消息。
- 2.当参与者接收到 VOTE_REQUEST 消息,向协调者发送 VOTE_COMMIT 消息 作为回应,告诉协调者自己已经做好准备提交准备,如果参与者没有准备 好或遇到其他故障,就返回一个 VOTE_ABORT消息,告诉协调者目前无法 提交事务。
第二阶段:提交阶段
- 1.协调者收集来自各个参与者的表决消息。如果所有参与者一致认>为可以提交事务,那么协调者决定事务的最终提交,在此情形下协调者向所有参与 者发送一个GLOBAL_COMMIT消息,通知参与者进行本地提交;如果所有 参与者中有任意一个返回消息是 VOTE_ABORT,协调者就会取消事务,向所 有参与者广播一条
GLOBAL_ABORT 消息通知所有的参与者取消事务。- 2.每个提交了表决信息的参与者等候协调者返回消息,如果参与者接收到一 个
GLOBAL_COMMIT 消息,那么参与者提交本地事务,否则如果接收到 GLOBAL_ABORT 消息,则参与者取消本地事务
两阶段提交Flink中应用
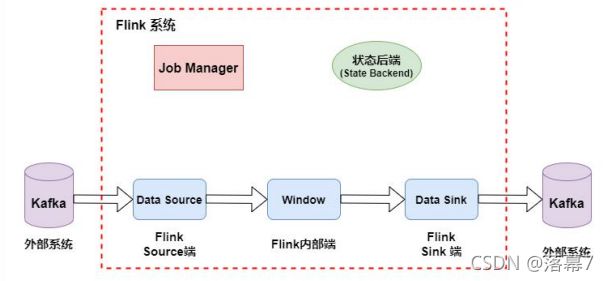
Flink的两阶段提交:从 Flink 程序启动到消费 Kafka 数据,最后到 Flink 将数据 Sink 到 Kafka 为止,来分析 Flink 的精准一次处理
1.当 Checkpoint 启动时,JobManager 会将检查点分界线(checkpoint battier)注入数据流,checkpoint barrier 会在算子间传递下去,如下 如所示
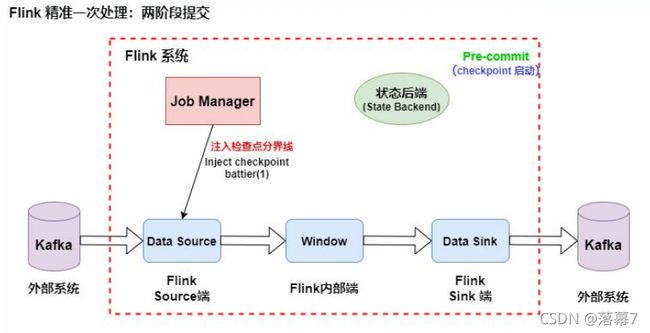
2.Source 端:Flink Kafka Source 负责保存 Kafka 消费 offset,当 Chckpoint 成功时 Flink 负责提交这些写入,否则就终止取消掉它们, 当 Chckpoint 完成位移保存,它会将 checkpoint barrier(检查点分界 线) 传给下一个 Operator,然后每个算子会对当前的状态做个快照,
保 存到状态后端(State Backend)。
对于 Source 任务而言,就会把当前的 offset 作为状态保存起来。下次从 Checkpoint 恢复时,Source 任务可以重新提交偏移量,从上次保存的位置 开始重新消费数据,如下图所示:

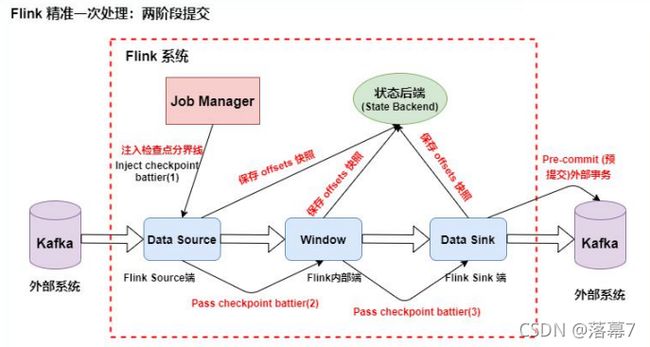
3.Slink 端:从 Source 端开始,每个内部的 transform 任务遇到 checkpoint barrier(检查点分界线)时,都会把状态存到 Checkpoint 里。 数据处理完毕到 Sink 端时,Sink
任务首先把数据写入外部 Kafka,这 些数据都属于预提交的事务(还不能被消费),此时的 Pre-commit 预提 交阶段下 Data Sink 在保存状态到状态后端的同时还必须预提交它的外部 事务,如下图所示:
4.当所有算子任务的快照完成(所有创建的快照都被视为是 Checkpoint 的 一部分),也就是这次的 Checkpoint 完成时,JobManager 会向所有任务 发通知,确认这次 Checkpoint 完成,此时 Pre-commit 预提交阶段才算完 成。才正式到两阶段提交协议的第二个阶段:commit 阶段。该阶段中 JobManager 会为应用中每个 Operator 发起 Checkpoint 已完成的回调 逻辑。
本例中的 Data Source 和窗口操作无外部状态,因此在该阶段,这两个 Opeartor 无需执行任何逻辑,但是 Data Sink 是有外部状态的,此时我 们必须提交外部事务,当 Sink 任务收到确认通知,就会正式提交之前的 事务,Kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费 了,如下图所示:
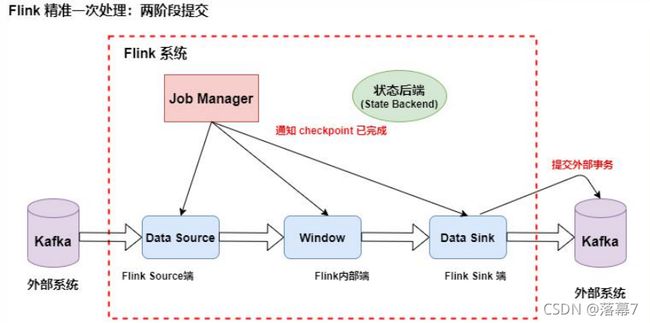
注:Flink 由 JobManager 协调各个 TaskManager 进行 Checkpoint 存储, Checkpoint 保存在 StateBackend(状态后端) 中,默认 StateBackend 是内存级 的,也可以改为文件级的进行持久化保存
总结:
1.Flink消费到Kafka数据之后,就会开启一个Kafka的事务,正常写入Kafka分区日志标记但未提交,也就是预提交(Per-commit)
2.一旦所有的Operator完成各自的Per-commit,他们会发起一个commit操作
3.如果有任意一个Per-commit失败,所有其他的Per-commit必须停止,并且Flink会回滚到最近成功完成的CheckPoint
4.当所有的Operator完成任务时,Sink端就收到checkpoint barrier(检查点分界线),Sink保存当前状态,存入Checkpoint,通知JobManager,并提交外部事物,用于提交外部检查点的数据
5.JobManager收到所有任务通知,发出确认信息,表示Checkpoint已经完成,Sink收到JobManager的确认信息,正式提交这段时间的数据
6.外部系统(Kafka)关闭事务,提交的数据可以正常消费了
一旦Per-commit完成,必须要确保commit也要成功,Operator和外部系统都需要对此进行保证。如果commit失败(例:网络崩溃导致等),Flink应用就会崩溃,然后根据用户重启策略进行重启,之后在重试commit。这个过程非常重要,因为如果commit无法顺利执行,就有可能出现数据丢失情况,因此,所有的Operator必须对Checkpoint最终结果达成共识:要么所有的Operator都认定数据提交执行成功,要么所有Operator认定数据提交失败,然后终止然后回滚
- FlinkSinktoKafka
package com.liu.core
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.StateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.Semantic
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer}
object Demo6SInkKafka {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(20000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
val config: CheckpointConfig = env.getCheckpointConfig
//任务失败后自动保留最新的checkpoint文件
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//设置状态后端,保存状态的位置
val stateBackend: StateBackend = new RocksDBStateBackend("hdfs://master:9000/flink/checkpoint", true)
env.setStateBackend(stateBackend)
val properties = new Properties()
properties.setProperty("bootstrap.servers", "master:9092")
properties.setProperty("group.id", "asdasdas")
//创建flink kafka 消费者
val flinkKafkaConsumer = new FlinkKafkaConsumer[String]("exactly_once", new SimpleStringSchema(), properties)
//如果有checkpoint,不是读取最新的数据,而是从checkpoint的位置读取数据
flinkKafkaConsumer.setStartFromLatest()
val kafkaDS: DataStream[String] = env.addSource(flinkKafkaConsumer)
val wordsDS: DataStream[String] = kafkaDS.flatMap(_.split(","))
//将数据写回到kafka中
//会导致数据重复
/* val myProducer = new FlinkKafkaProducer[String](
"master:9092", // broker 列表
"sink_kafka", // 目标 topic
new SimpleStringSchema) // 序列化 schema
*/
val properties1 = new Properties
properties1.setProperty("bootstrap.servers", "master:9092")
//事务的超时时间
properties1.setProperty("transaction.timeout.ms", 5 * 60 * 1000 + "")
//创建生产者
val myProducer = new FlinkKafkaProducer[String](
"sink_kafka", // 目标 topic
new SimpleStringSchema,
properties1,
null, //分区方法
Semantic.EXACTLY_ONCE, // 唯一一次
5
) // 序列化 schema
wordsDS.addSink(myProducer)
env.execute()
}
}