论文阅读【16】Pretrained Generalized Autoregressive Model with Adaptive Probabilistic Label Clusters for E
论文十问十答:
Q1论文试图解决什么问题?
Q2这是否是一个新的问题?
Q3这篇文章要验证一个什么科学假设?
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
Q5论文中提到的解决方案之关键是什么?
Q6论文中的实验是如何设计的?
Q7用于定量评估的数据集是什么?代码有没有开源?
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
Q9这篇论文到底有什么贡献?
Q10下一步呢?有什么工作可以继续深入?
论文相关
论文标题:基于自适应概率标签聚类的极端多标签文本分类的预训练广义自回归模型
发表时间:2020年
领域:自然语言处理
相关代码:https://github.com/huiyegit/APLC_XLNet.
摘要
极端多标签文本分类(XMTC)是一项任务,它是用来自超大标签集中的最相关的标签来标记给定的文本。我们提出了一种新的深度学习方法,称为APLC-XLNet。我们的方法对最近发布的广义自回归预训练模型(XLNet)进行了微调,以学习输入文本的密集表示。我们提出了自适应概率标签簇(APLC),利用不平衡的标签分布形成明确减少计算时间的簇,以近似交叉熵损失。我们在5个基准数据集上进行的实验表明,我们的方法在4个基准数据集上取得了新的最先进的结果。
1.引言
极端分类是指学习一个分类符来从一个非常大的标签集中用最相关的标签来注释每个实例的问题。极端分类发现应用程序在不同的领域,如估计的单词表示数百万的单词,标签的维基百科文章与最相关的标签,并提供一个产品描述或广告登陆页面在动态搜索广告。极端多标签文本分类(XMTC)是极端分类的一项基本任务,其中实例和标签都是以文本格式的。
XMTC的第一个挑战是如何获得有效的特性来表示文本。一种传统的方法就是使用词袋模型进行文本特征表示,其中,一个向量表示在一个预定义的词汇表中的一个单词的频率。然后,向机器学习算法输入由特征和标签组成的训练数据来训练分类模型。然而,传统的基于BOW或其变体的方法,忽略了单词的位置信息,不能捕获文本的上下文和语义信息。
另一方面,随着单词嵌入技术的发展,深度学习方法在从原始文本中学习文本表示方面取得了巨大的成功。这些有效的模型包括卷积神经网络(CNN),循环神经网络(RNN),CNN和RNN的结合(DPCNN),带有注意机制的CNN,具有注意机制和Transformer的RNN。
在过去两年中,几种迁移学习方法和架构被提出,并在广泛的自然语言处理(NLP)任务上取得了最先进的成果,包括智能问答、情感分析、文本分类和信息检索。迁移学习的基本机制是将一个预先训练过的模型的知识转移到一个新的下游任务中,模型通常在非常大的语料库上进行训练。广义自回归预训练方法(XLNet)代表了这一领域的最新发展。XLNet采用置换语言建模目标,在几个大型语料库上进行模型训练。然后,可以对预先训练好的模型进行微调,以处理各种NLP任务。
XMTC的另一个挑战是如何有效地处理极端输出。特别是,对于极端分类,标签的分布是臭名昭著的遵循Zipf定律。大部分的概率质量只被标签集的一小部分所覆盖。为了训练参数模型来使用非常大的词汇表进行语言建模,已经提出了许多有效地近似softmax的方法,包括分层软max(HSM),负采样,噪声对比度估计,自适应软最大值。然而,这些技术被提出用于处理多类分类,因此不能直接应用于XMTC。概率标签树(PLT)将HSM推广到处理多标签分类问题。
基于这些任务的特点,我们提出了一种新的深度学习方法,即具有自适应概率标签簇的预训练广义自回归模型(APLC-XLNet)。我们对广义自回归预训练模型(XLNet)进行了微调,以学习功能强大的文本表示,以实现较高的预测精度。据我们所知,XLNet是第一次成功地应用于XMTC问题。受自适应Softmax的启发,我们提出了自适应概率标签簇(APLC),利用不平衡的标签分布形成明确减少计算时间的簇来近似交叉熵损失。APLC可以足够灵活,通过调整其参数来实现预测精度和计算时间之间的理想平衡。此外,APLC可以足够通用,可以作为输出层有效地处理极端分类问题。在五个数据集上进行的实验表明,我们的方法已经在四个基准数据集上取得了新的最先进的结果。
2.相关工作
许多有效的方法已经被提出来解决XMTC的挑战。根据用于特征表示的方法,它们通常可以分为两种类型。一种传统的类型是使用BOW作为特性。它包含三种不同的方法:一对一的方法、基于嵌入的方法和基于树的方法。另一种类型是现代的深度学习方法。深度学习模型已经被提出来从原始文本中学习强大的文本表示,并在不同的NLP任务上取得了巨大的成功。
2.1 一对多的方法
一对一方法将每个标签作为一个二元分类问题,学习每个标签的分类器。一对一的方法已经被证明可以实现较高的精度,但当标签的数量非常大时,它们会面临昂贵的计算复杂度。PDSparse为每个标签学习一个单独的线性分类器。在训练过程中,对分类器进行优化,以区分每个训练样本的所有正标签和少数活跃的负标签。PPDSparse将PDSparse扩展为在大规模分布式设置中并行化。DiSMEC提出了一种分布式和并行的训练机制,它会尽可能的使用计算资源。此外,它还可以通过修剪伪权值来显式地诱导稀疏性,从而减少模型的大小。Slice(Jain et al.,2019)将每个标签的分类器训练在最令人困惑的负面标签上,而不是所有的负面标签。Slice将每个标签的分类器训练在最令人困惑的负标签上,而不是所有的负标签。这是通过一种新的负采样技术有效地实现的。
2.2 基于emberdding的方法
基于嵌入的方法通过利用标签相关性和稀疏性,将高维标签空间投影到低维标签空间中。由于压缩阶段的信息丢失,嵌入方法可能会在预测精度方面付出巨大的代价。SLEEC通过只保留最近的标签向量之间的成对距离,将高维标签空间投影到低维标签空间。回归变量可以在低维标签空间上学习。AnnexML通过使用一个近似的k-最近邻图作为弱监督来划分数据点。然后采用成对学习到秩的方法来学习低维标签空间。
2.3 基于树的方法
基于树的方法学习分层树结构,将实例或标签划分为不同的组,以便相似的组可以在同一个组中。整个集合,最初被分配给根节点,然后被划分为一个固定数的k个子集,对应于根节点的k个子节点。重复这个分区过程,直到在子集上满足一个停止条件为止。在预测阶段,输入实例向下传递到树中,直到它到达叶节点。
对于一个实例树,预测是由对叶实例进行训练的分类器给出的。对于标签树,对给定标签的预测是由被遍历的节点分类器从根节点到叶节点所确定的概率。
FastXML通过优化归一化的Discounted Cumulative Gain(nDCG),在特征空间上学习树状结构。为每个内部节点训练一个二值分类器。对给定实例的预测是在相应叶节点中的训练实例上计算出的标签分布。- 基于
FastXML,PfastreXML引入了倾向得分损失,优先预测少数相关标签而不是大量不相关标签,促进了不频繁但有益的尾部标签的预测。 Parabel学习了三种标签树的集合。标签树通过递归地将标签划分为两个平衡组来训练的。叶节点包含线性的一对一分类器,叶中的每个标签对应一个。- 一对多分类器用于计算与测试点相关的相应标签的概率。
Cratyml引入了一种具有快速划分策略的基于随机森林的方法。首先,它将特征向量和标签向量随机投影到低维向量中。然后采用基于k-means的划分方法将实例从低维标签向量中分割为k个临时子集。内部节点中的多类分类器可以被训练为来自低维特征向量的相关子集。Bonsai通过结合输入和输出表示,开发了一种广义的标签表示。然后通过k-means聚类构建了一个浅树体系结构。Bonsai已经展示了处理超大数据集的快速速度。ET采用了与FastText相同的架构,但它使用概率标签树作为输出层来处理多标签分类,而不是层次的Softmax。ET具有模型尺寸小、预测时间长等优点。但是,由于FastText的体系结构不能捕获文本丰富的上下文信息,因此预测精度不太高。
2.4 深度学习的方式
与传统方法作为文本表示的BOW不同,深度学习模型已经有效地利用了原始文本来学习密集表示,从而可以捕获文本的上下文和语义信息。基于CNN-Kim,XML-CNN通过将文本通过卷积层传递来学习一些特征表示。在池化层和输出层之间增加了一个隐藏的瓶颈层,以提高预测精度,减小模型的规模。然而,由于XML-CNN的输出层是一个线性结构,所以当应用于有数百万个标签的情况时,它可能会是无效的。
受信息检索(IR)视角的启发,XBERT提出了一种分三个步骤组成的方法。首先,它通过将标签集划分为k个集群来构建标签索引系统。然后,它对来Transformers的双向编码器表示(BERT)模型进行微调,以匹配输入文本的标签集群。在最后一步中,训练线性分类器对相应聚类中的标签进行排序。X-BERT成功地微调了BERT模型,并在预测精度方面显示出了显著的提高。然而,X-BERT并不是一个完整的端到端深度学习模型,因此它为改进结果留下了潜在的空间。AttionXML通过双向长短期记忆(BiLSTM)模型和注意机制捕获文本的顺序信息。提出了一种浅而宽的概率标签树来处理大规模的标签。AttentionXML在准确性和效率方面都取得了出色的性能。然而,采用三种概率标签树的集成来提高预测精度,这在深度学习方法中是不常见的。
3. APLC-XLNet
在本节中,我们将详细说明针对XMTC问题的APLC-XLNet模型。我们的模型体系结构有三个组件:XLNet模块、隐藏层和APLC输出层(图1)。
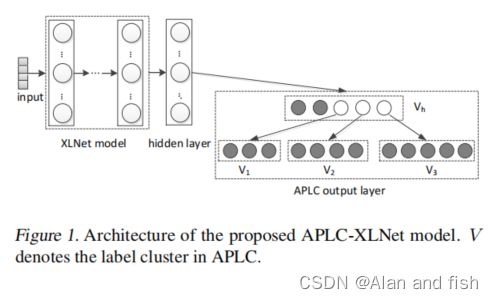
3.1.XLNet模块
近年来,自然语言处理的迁移学习取得了许多重大进展,其中大多数是基于语言建模。语言建模是预测前一个单词中的下一个单词。XLNet是一种广义自回归的训练前语言模型,它通过最大化因子分解顺序的所有排列的期望似然来捕获双向上下文。其排列语言建模目标可表示为:
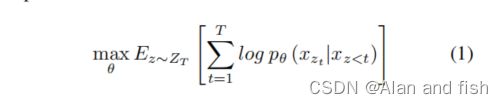
其中,θ为该模型的参数, Z T Z_T ZT是长度为T的序列的所有可能排列的集合, z t z_t zt是第t个元素,z
除了排列语言建模外,XLNet还采用了transformer XL作为其基础架构。XLNet在大量的文本数据语料库上对语言模型进行了预训练,然后在下游任务上对预训练后的模型进行了微调。虽然预训练的模型在句子分类、问题回答和序列标记等许多下游任务上都取得了最先进的性能,但它在极端多标签文本分类的应用中仍未被探索。我们在模型体系结构中采用了预训练的XLNet Base模型,并对其进行了微调,以学习强大的文本表示。遵循XLNet的方法,我们从预先训练的带一个嵌入层的XLNet模型开始,然后是由12个transformer块组成的模块。我们将与特殊的[CLS]标记对应的最后一个标记的最终隐藏向量作为文本表示。
3.2 隐藏层
APLC-XLNet在XLNet的池化层和APLC输出层之间有一个完全连接的层。我们选择将这一层的神经元数量设置为超参数dh。当输出标签的数量不大时,dh可以与池化层相同,以获得最佳的文本表示。另一方面,在处理极端标签的情况下,可以比池化层更小,从而大幅减小模型大小,提高计算效率。在这种情况下,这一层可以被称为瓶颈层,因为神经元的数量都小于池化层和输出层。
3.3 自适应概率标签簇
3.3.1 动机
在极端分类中,标签的分布是出了名地遵循Zipf定律。大部分的概率只被标签集的一小部分所覆盖。在一个基准数据集Wiki-500k中,频繁的标签占标签词汇表的20%,但它们覆盖了约75%的概率。如图2所示:
这句话的意思我是这么理解的,在标签中频繁出现的这几个标签只占有标签库中的20,但是在所有需要预测的文本中,预测为这些标签的文本占有75%。这就存在一个数据集不平衡问题,即一个伪标签问题。

图2:数据集Wiki-500k的标签分布遵循Zipf定律。标签id按在数据集中出现的次数按降序排序。
与分层的Softmax和自适应的Softmax类似,可以利用该属性来减少计算时间。
3.3.2 结构
我们将标签集划分为一个头部聚集和几个尾部聚集,其中头部聚集由最常见的标签组成,不常见的标签被分组为尾部聚集(如图3所示)。

图3:3个集群APLC的体系结构,h表示隐藏层。 V h V_h Vh表示头部聚集, V 1 V_1 V1 和 V 2 V_2 V2表示2个尾部聚集。叶节点的大小表示标签出现的频率。
包含少量标签的聚集对应于较少的计算时间,因此通过频繁访问它将大大提高计算效率。集群的结构可以通过两种不同的方式来发展。一种方法是生成一个级树,而另一种方法是保持头集群作为根节点中的一个短列表。根据经验,将所有的聚集放在叶子中会导致性能的下降。就像自适应softmax,我们选择将头集群放在根节点中。为了进一步减少计算时间,我们采用隐状态的降维数作为聚类的输入。对于分类器经常访问的头部聚类,一个大维数的隐藏状态可以保持较高的预测精度。对于尾部簇,由于分类器很少访问它们,我们通过除以因子q来降低维数(q>=1).
这样,就可以显著减少集群的模型大小,但模型仍然可以保持良好的性能。
讲解一下这个部分的思想:首先将所有的标签按照频率进行排序,然后根据频率将其分成几个组,第一个组在文中称为头聚集,以此中间聚集、尾聚集,当然可以根据自己的需求设置几个聚集。然后分别为头聚集之后的聚集设置一个线性层,设置一个衰减因子,根据衰减因子创建一个线性层,以此衰减线性层的输出。如图所示:
h1和h2是2个线性层,是根据聚集的位置进行设计输出结果的。
其中的第一个关键:降幂分组
h0是所有的标签序列,当时所有的标签的序列都是按照出现的评率进行降幂排列的,然后将这些标签按照降幂进行分组,分为头聚集gh、中间聚集g1、尾部聚集g2
len(gh)>len(g1)>len(g2)
其中的第二个关键:根据评率设计线性层
设置了一个影响因子q,输出层的维度=输出层维度//q**2
h1(768,384)
h2(768,192)
然后XNLent输出结果依存通过这些线性层得到输出vh,v1,v2,然后通过一个分类器得到对应聚集的预测结果。
3.3.3 目标函数
我们假设标签集被划分为 V = V h ∪ V 1 ∪ . . . . . . . . ∪ V k V=V_h∪V_1∪........∪V_k V=Vh∪V1∪........∪Vk,其中 V h V_h Vh是头聚集, V i V_i Vi是第尾部聚集, V h ∩ V i = ∅ V_h∩V_i=∅ Vh∩Vi=∅,如果i≠j,K是尾聚集的数量,则 V i ∩ V j = ∅ V_i∩V_j=∅ Vi∩Vj=∅。根据概率链规则,一个标签的概率可以表示为:
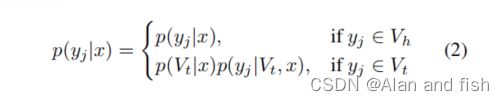
其中x是一个样本的特征, y j y_j yj是第j个标签, V t V_t Vt是第t个尾聚集。
在训练过程中,我们访问头聚集,在那里我们计算每个训练样本的每个标签的概率。相比之下,我们访问尾聚集 V t V_t Vt,其中只有当在 V t V_t Vt中存在一个训练样本的正标签时,我们才计算每个标签的概率。设 Y i Y_i Yi是第i个实例的正标签集, V y k V_{yk} Vyk是 Y i Y_i Yi中第k个标签的对应聚集,聚集 S i S_i Si相当于 Y i Y_i Yi被表达如下:
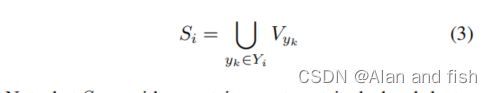
注意, S i S_i Si可以包含或不包含头聚集 V h V_h Vh,但我们需要为每个训练样本访问 V h V_h Vh。我们将 V h V_h Vh添加到 S i S_i Si中, Y i Y_i Yi对应的聚集 S ^ i \hat{S}_i S^i可以表示如下:
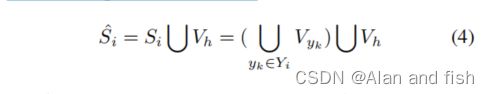
设 Y ^ i \hat{Y}_i Y^i是对应于 S ^ i \hat{S}_i S^i的标签集,我们用 L i L_i Li来表示 Y ^ i \hat{Y}_i Y^i的基数,用 I i I_i Ii来表示 Y ^ i \hat{Y}_i Y^i的标签索引集。APLC对多标签分类的客观损失函数可以表示为:
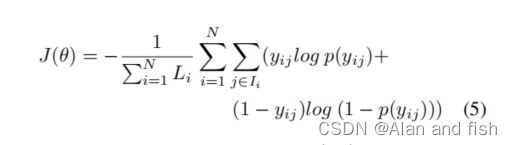
式中,N为样本数, p ( y i j ) p(y_{ij}) p(yij)为公式2计算出的预测概率, y i j y_{ij} yij∈{0,1}为真值,指数i和j分别表示第i个样本和第j个标签。
3.3.4 模型大小
让我们对APLC的模型大小进行分析。设d表示 V h V_h Vh的隐藏状态的维数,q(q≥1)表示衰减因子, l h l_h lh和 l i l_i li表示头聚集和第i个尾聚集的基数。APLC的参数 N p a r N_{par} Npar数可以表示如下:
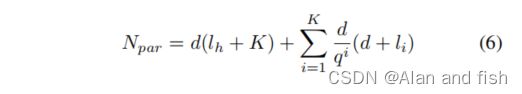
实际上,K << l h l_h lh和d << l i l_i li,因此式6可以表示为:

其中 l 0 l_0 l0表示 l h l_h lh。如式7所示,最后一个尾簇的系数最小。让我们考虑d和q是固定的情况;减少模型大小的策略是将很大比例的标签分配给尾部聚集。
让我们与原始的线性输出层进行一个比较。线性结构的模型尺寸可以表示为:
![]()
其中,L表示标签集的基数。结合公式7和公式8,我们有一个公式表达他们之间的概率:
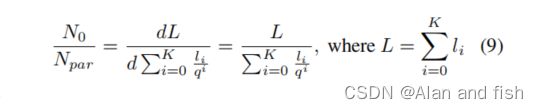
3.3.5 计算的复杂度
预计的计算成本C可以描述如下:
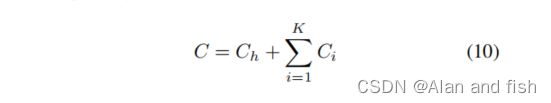
其中, C h C_h Ch和 C i C_i Ci分别表示头聚集和第i个尾聚集的计算代价。我们让 N b N_b Nb表示批大小, p i p_i pi表示一批样本中至少有一个正标签在尾聚集 V i V_i Vi中,模型访问 V i V_i Vi的概率。我们有以下表达式:
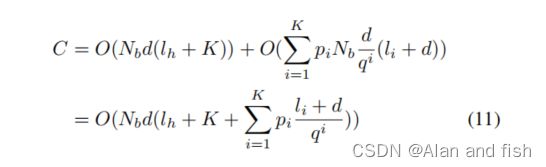
在实践中,K<< l h l_h lh和d<< l i l_i li,因此计算成本C可以表示为:
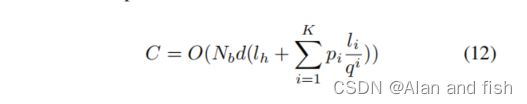
让我们考虑以下情况,即我们将标签集划分为聚集,其中每个聚集的基数是固定的。在式12中,除了每个尾聚集的概率 p i p_i pi外,所有的值都是固定的。为了使 p i p_i pi取一个较小的值,我们应该将最频繁的标签分配到头部聚集中。另一方面,由于我们已经将隐藏状态的降维数分配给了尾聚集,所以我们应该通过将频率降低到尾簇来划分标签,以获得较高的预测精度。
让我们也与原始的线性输出层进行一个比较。线性结构的预期计算成本可以表示为:
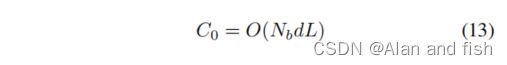 结合式12和式13,两者之间的比值可表示如下:
结合式12和式13,两者之间的比值可表示如下:

4.训练APLC-XLNet的技术
4.1.歧视性微调
APLC-XLNet由三个模块组成,XLNet模块、隐藏层和APLC输出层。当处理具有数百万个标签的极端分类问题时,APLC输出层中的参数数量甚至可以大于XLNet模型。因此,训练如此大的模型是一个重大的挑战。我们采用判别微调方法对模型进行训练。由于预先训练好的XLNet模型已经捕获了下游任务的通用信息,所以我们应该将学习率 η x η_x ηx分配给一个较小的值。我们为APLC输出层设置了一个更大的 η a η_a ηa值,以激励模型快速学习。对中间隐藏层进行 η h η_h ηh分级,我们在XLNet模型和APLC层之间赋值一个值。实际上,在我们的实验中,我们发现这种方法对于有效地训练模型是必要的。对整个模型用相同的学习率来训练模型是不可行的。
这是一个很新颖的训练方式,给每一层不同的学习率。
4.2.倾斜的三角形学习率
斜面三角形学习率是一种使用动态学习率来训练模型的方法。目的是激励模型在开始时快速收敛到合适的空间,然后细化参数。学习率首先呈线性增加,然后根据该策略逐渐衰减。学习率η可以表示为:

其中 η 0 η_0 η0为原始学习率,t为当前训练步,超参数 t w t_w tw为热身步阈值, t a t_a ta为训练步总数。
5.实验
在本节中,我们将报告我们所提出的方法在标准数据集上的性能,并将其与最先进的基线方法进行比较。
5.1 数据集
我们在5个标准的基准数据集上进行了实验,包括3个中等规模的数据集。
- EURLex-4k,
- AmazonCat-13k
- Wiki10-31k
- Wiki-500k
- Amazon-670k
表1显示了这些数据集的统计数据。这五个数据集的术语频率-逆文档频率(tf-idf)特征可以在极端分类存储库上公开获得。我们使用了来自极端分类存储库的3个数据集的原始文本,包括亚马逊catk-13k、Wiki10-31k和亚马逊-670k。我们从公共网站上获得了EURLex2和Wiki-500k3的原始文本。

表1:数据集的统计信息。 N t r a i n N_{train} Ntrain是训练样本的数量, N t e s t N_{test} Ntest是测试样本的数量,D是特征向量的维数,L是标签集的基数, L ‾ \overline{L} L是每个样本的平均标签数, L ^ \hat{L} L^是每个标签的平均样本, W t r a i n W_{train} Wtrain是每个训练样本的平均单词数, W t e s t W_{test} Wtest是每个测试样本的平均单词数。
5.2 实施细节
我们需要使用一个特定的标记器(tokenizer)来预处理原始文本,这是基于句子片段标记器(tokenizer)。在标记化过程中,句子中的每个单词都被分解成小的标记。然后我们选择句子长度 L s e q L_{seq} Lseq,填充和截断每个输入序列的相同长度。表2显示了APLC的实现细节。

表2:APLC的实施细节。 d h d_h dh是输入隐藏层的维度,q是尾部聚集隐藏状态维数减小的因素, n c l n_{cl} ncl是聚集的数量, P n u m P_{num} Pnum是每个集群帐户中的标签数量的比例。
对于中等规模的数据集,我们选择将标签集均匀地划分为两个集群。对于大规模数据集Wiki-500k和Amazon-670k,我们将标签集分别平均划分为3个和4个集群。为了进一步减小大规模数据集Amazon670k的模型大小,我们将隐藏状态dh的维数设置为512。所有五个数据集的衰减因子q都是2。
表3给出了训练模型的超参数。设置序列长度 L s e q L_{seq} Lseq有几个因素需要考虑。首先,一个长序列包含更多的上下文信息,这有利于模型学习更好的文本表示。其次,它与计算时间成线性比例。对于具有少量训练样本的数据集,我们将 L s e q L_{seq} Lseq设置为最大值512。对于具有大量训练样本的数据集,我们选择较小的 L s e q L_{seq} Lseq值。我们选择了AdamW优化器,并设置了不同的学习速率。XLNet模型的学习速率 η x η_x ηx为1e-5级,APLC层的 η a η_a ηa为1e-3级,中间隐藏层的 η h η_h ηh在 η x η_x ηx和 η a η_a ηa之间。所有5个数据集的预热步骤tw均为0。
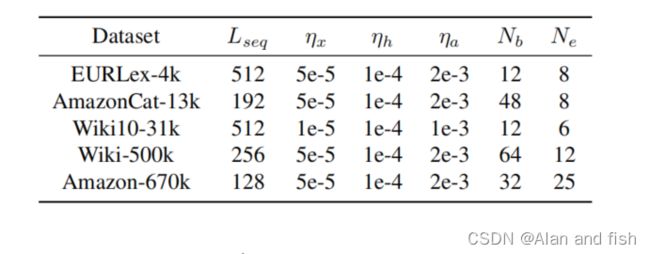
表3:训练模型的超参数。 L s e q L_{seq} Lseq是输入序列的长度。 η x η_x ηx、 η h η_h ηh、 η a η_a ηa分别表示XLNet模型、隐藏层和APLC层的学习速率, N b N_b Nb是批处理大小, N e N_e Ne是训练期的数量。
由这篇论文可见在对比模型的时候,不一定要所有的超参数都要一样,那个超参数效果好就使用那个
5.3 评估函数
我们选择了广泛使用的P@k作为评价度量,它通过计算前k个标签的精度来表示预测精度。P@k的定义如下:
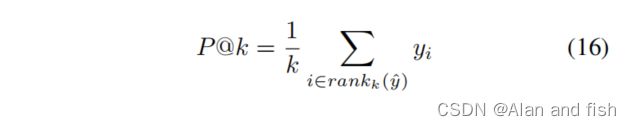
其中, y ^ \hat{y} y^为预测向量,i为 y ^ \hat{y} y^和y∈{0,1} L中第i个最高元素的指标。
5.4 基线模型
我们的方法与最先进的基线进行了比较,包括DisMEC中的一对一的比较,三种基于树的方法, PfastreXML、 Parabel、Bonsai,两种基于emberdding的方法,SLEEC和 AnnexML和两种深度学习方法, XML-CNN 和
AttentionXML。我们在本文中使用的5个数据集上运行 AttentionXML的源代码,它们与AttentionXML中的数据集不同。值得注意的是AttentionXML使用了三颗树的集合来提升性能。为了进行公平的比较,我们只选择了一棵树所产生的结果。我们已经在GitHub上公开发布了针对 AttentionXML的预处理数据集,以重现本文中的 AttentionXML的结果。
5.5 性能对比
表4显示了APLC-XLNet的实验结果和在五个数据集上的最先进的基线。根据之前对XMTC的工作,我们考虑了前k个预测精度,P@1、P@3和P@5。首先,我们将APLC-XLNet与两种基于嵌入的方法,SLEEC和AnnexML进行了比较。AnnexML在所有五个数据集上的性能都优于SLEEC。然而,APLC-XLNet在所有5个数据集上都优于AnnexML。在数据集EURLex-4k上是显著的,在P@1、P@3和P@5上分别增加了约8%、10%和10%。对于1-vs-all方法,DisMEC在数据集Wiki-500k上的所有方法中性能最好。APLC-XLNet在三个数据集上的性能都优于DisMEC,而在数据集Amazon-670k上的性能则略低于DisMEC,下降了1%。在三个基于树的方法中,Bonsai在四个数据集上的性能最好。在 AmazonCat-13k中 Parabel的性能优于Bonsai。我们的方法在三个数据集上的性能大大优于三种基于树的方法- EURLex-4k, AmazonCat-13k 和 Wiki10-31k.深度学习方法 AttentionXML在数据集Amazon-670k上的性能是所有方法中最好的。APLC-XLNet在两个数据集亚马逊amzoncat-13k和Wiki10-31k上的性能优于AttentionXML。请注意,这三种深度学习方法都以原始文本作为输入,并可以利用文本的上下文和语义信息。然而,它们使用不同的模型来学习文本表示。

图4:数据集EURLex和Wiki10上的精度P@1,作为集群数量的函数。
5.6 消融实验
我们基于EURLex和Wiki10这两个数据集进行了消融研究,以了解APLC的不同设计选择的影响。具体来说,我们考虑了两个因素:
(1)集群数量的影响。
(2)方法对划分标签集的影响。
为了回答第一个问题,我们假设当给出集群的数量时,标签集被均匀地划分到每个集群中。其他参数的设置与表2、表3的设置相同。我们绘制了图4,precision P@1作为集群 N c l s N_{cls} Ncls数量的函数。当 N c l s N_{cls} Ncls为2时,数据集EURLex的P@1=87.72.随着 N c l s N_{cls} Ncls值的增加,精度P@1逐渐降低。当 N c l s N_{cls} Ncls达到6时,精度P@1为85.72,下降了2%。对于数据集Wiki10,随着 N c l s N_{cls} Ncls值的增加,精度P@1略有下降。我们认为,大量的集群往往会损害模型的性能;然而,影响的程度取决于数据集的特征。
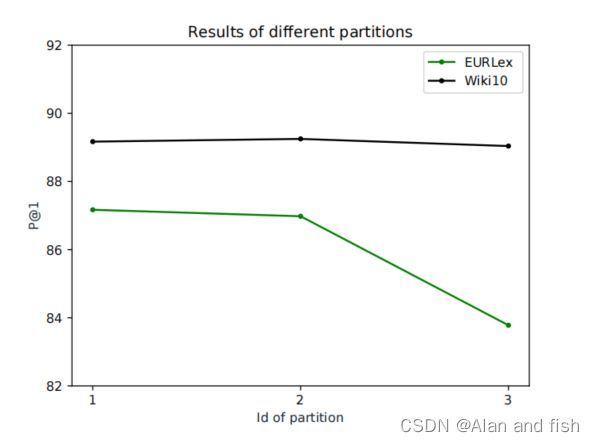
图5:数据集EURLex和Wiki10上不同分区的精度P@1。Id 1、2、3分别表示分区(0.7、0.2、0.1)、(0.33、0.33、0.34)和(0.1、0.2、0.7)。
为了回答第二个问题,我们假设集群 N c l s N_{cls} Ncls的数量是一个固定的值-3.设Vh、V1和V2表示头簇、第一尾簇和第二尾簇,Ph、P1、P2表示对应聚类账户中标签数量的比例。我们有三种不同的方法来划分标签集,对应的三种组合,(0.7、0.2、0.1)、(0.33,0.33,0.34)和(0.1、0.2、0.7)为(Ph、P1、P2)。其他参数的设置与表2和表3相同。我们绘制了图5,即数据集EURLex和Wiki10上不同分区的预测精度P@1。我们观察到,当更多的标签被划分到头部簇中时,两个数据集的精度P@1在两个数据集上都更高。这一趋势在数据集EURLex上更为重要,因为在第一个分区和第三个分区之间有大约3%的差异。然而,对数据集Wiki10的影响相对较小。
6.总结
在这篇论文中,我门提出了一种深度学习的方法解决极端多标签文本分类问题。用准确率做为评价指标,我们的模型在基准数据集上的性能表现是最好的,那表明经过XLNet预训练出来的模型更强大。因此,我们提出的APLC模型能有效的解决极端标签问题。我们在理论上分析了模型的大小以以及复杂程度。我们认为APLC能够应对普通的极端多标签问题,尤其是标签不平衡的分类问题。
我仔细阅读了这篇论文,发现这篇论文的工作主要在预测标签和计算损失这两个方面,我尝试使用这种方法去预测标签,但是效果并不是那么理想,我猜想主要发挥作用的是计算损失这个模块,因为作者给的模型中计算损失这个部分并没有与模型一一对应,所以对于我个人而言理解模型的损失计算模块还是有点困难。