EfficientDet(BiFPN)(CVPR 2020)原理与代码解析
paper:EfficientDet: Scalable and Efficient Object Detection
official implementation:automl/efficientdet at master · google/automl · GitHub
third-party implementation:https://github.com/jewelc92/mmdetection/blob/3.x/projects/EfficientDet/efficientdet/bifpn.py
本文的创新点
本文受EfficientNet的启发,提出了一种用于目标检测模型的复合尺度变换方法,不仅可以同时对分辨率、网络深度、网络宽度三个维度进行统一缩放,而且可以对目标检测模型中的骨干网络、特征网络、分类/回归预测网络中的上述三个维度进行统一缩放。
此外,本文还提出了一种新的加权双向特征金字塔网络(bi-directional feature pyramid network,BiFPN),可以简单快速地进行多尺度特征融合。
基于上述两点,并入引入更好的backbone即EfficientNet,作者提出了一个新的检测模型系列 - EfficientDet,它在不同的计算资源限制下取得了比现有模型更好的效果。
方法介绍
BiFPN
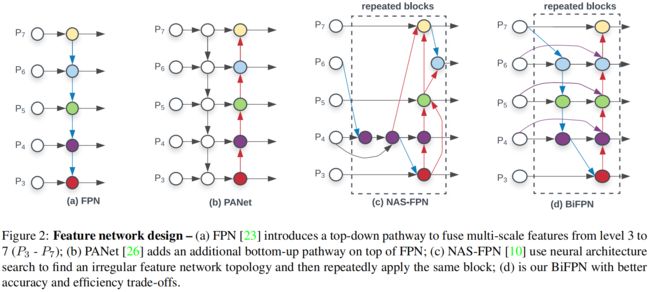
多尺度特征融合旨在融合不同分辨率的特征,给定多个不同尺度的特征 \(\vec{P}^{in}=(P^{in}_{l_{1}},P^{in}_{l_{2}},...)\),其中 \(P^{in}_{l_{i}}\) 表示 \(l_{i}\) 层的特征,我们的目标是找到一个转换 \(f\),它能有效的聚合不同尺度的特征并且输出多个聚合后的新特征 \(\vec{P}^{out}=f(\vec{P}^{in} ) \)。比如传统的FPN如图2(a)所示,它的输入为level 3-7的特征 \(\vec{P}^{in}=(P^{in}_{3},...,P^{in}_{7})\),它采用自上而下的方式融合多尺度特征
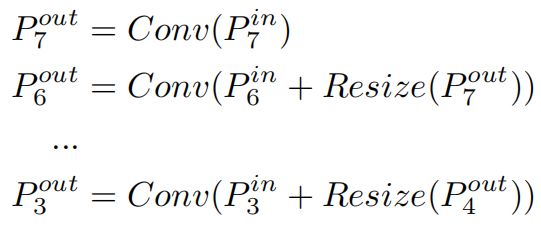
其中 \(Resize\) 是上采样或下采样操作,\(Conv\) 是卷积。
Cross-Scale Connections
传统的FPN受到单向信息流的限制,为了解决这个问题,PANet额外添加了一个自底向上的路径聚合网络,如图2(b)所示。NAS-FPN采用神经网络结构搜索来寻找更好的跨尺度特征网络拓扑结构,如图2(c)所示,但搜索代价极高,而搜索到的网络结构不规则,难以解释和修改。
本文提出了几种针对跨尺度连接的优化方法:
- 首先,删去那些只有一个输入的节点,因为如果一个节点只有一个输入没有特征融合的过程,那么它对旨在融合不同特征的网络的贡献就会比较小。
- 其次,如果原始输入和输出节点处于同一层级,增加一条额外的输入路径,从而在不增加太多计算成本的情况下融合更多的特征。
- 最后,与PANet只有一个自上而下和一个自下而上的路径不同,我们将每个双向路径视为一个特征网络层,并重复多次,从而实现更高级的特征融合。
基于上述三点,本文提出了双向特征金字塔网络,如图2(d)所示。
Weighted Feature Fusion
当融合不同分辨率的特征时,常见的方法是将它们的分辨率调整为相等大小,然后进行相加。之前的方法都平等的对待不同的输入特征,但作者观察到,由于不同的特征具有不同的分辨率,通常它们对于输出的贡献也不相同。因此本文提出对于每个输入添加一个额外的权重,让网络来学习每个输入特征的重要性。
作者仿照softmax-based融合方法提出了fast normalized fusion:\(O= {\textstyle \sum_{i}}\frac{w_{i}}{\epsilon + {\textstyle \sum_{j}}w_{j} } \cdot I_{i}\),其中在每个 \(w_{i}\) 后添加ReLU激活函数保证了 \(w_{i}\ge 0\),\(\epsilon=0.0001\) 用来避免数值不稳定。基于双向跨尺度连接和快速归一化融合,得到了最终的加权双向特征金字塔网络。举个具体的例子,图2(d)中level 6的特征融合如下所示

其中 \(P^{td}_{6}\) 是top-down路径中level 6的中间特征,\(P^{out}_{6}\) 是bottom-up路径中level 6的输出特征,这里的 \(Conv\) 是深度可分离卷积,并且每个卷积后都添加了BN和激活函数。
EfficientDet
受EfficientNet的启发,本文提出使用一个复合系数 \(\phi\) 来统一缩放backbone、BiFPN、class/box network的深度和宽度以及输入大小。和EfficientNet不同,目标检测模型比分类模型有更多的缩放维度,因此本文没有采用网格搜索的方法而是选择基于启发式的方法。
Backbone network
骨干网络采用和EfficientNet B0~B6相同的缩放系数,从而可以使用它们在ImageNet上的预训练模型。
BiFPN network
对于BiFPN的深度 \(D_{bifpn}\) 采用线性变换的方式因为深度需要向下取整。对于宽度 \(W_{bifpn}\) 采用指数变换的方式,在{1.2, 1.25, 1.3, 1.35, 1.4, 1.45}中采用网格搜索确定1.35作为宽度的缩放因子,完整的缩放公式如下
![]()
Box/class prediction network
宽度固定为和BiFPN的宽度相等即 \(W_{pred}=W_{bifpn}\),深度按下式进行线性变换
![]()
Input image resolution
因为BiFPN中用到了level 3-7的特征,因此输入大小需要能被 \(2^{7}=128\) 除尽,因此输入分辨率按下式进行线性变换
![]()
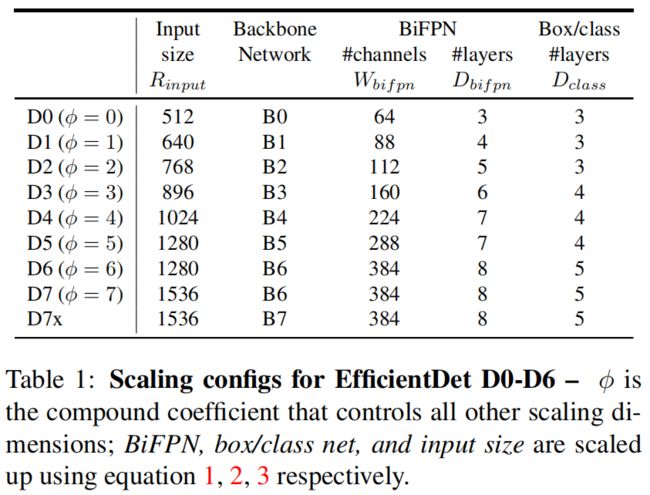
根据式(1)-(3)和不同的 \(\phi\) 值,EfficientDet-D0(\(\phi=0\))到D7(\(\phi=7\))的具体结构如下表所示
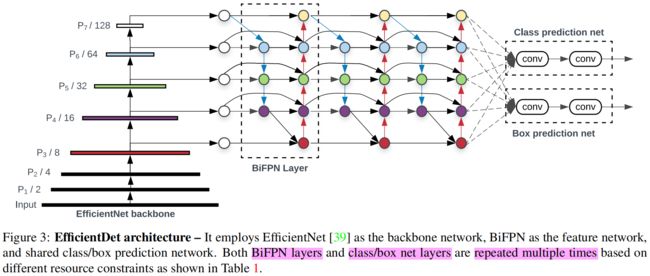
EfficientDet的结构如下图所示
代码解析
这里只对BiFPN部分的实现进行解析。以mmdetection_3.x/projects中实现的EfficientDet为例。
骨干网络EfficientDet的输出p3,p4,p5进入到class BiFPNStage()中的forward()函数中,因为是BiFPN的第一次迭代,需要对backbone的输出进行一些处理。首先通过self.p5_to_p6()即1x1卷积降低通道数然后通过stride=2的maxpool下采样得到p6_in,然后self.p6_to_p7()通过stride=2的maxpool下采样得到p7_in,最后对p3,p4,p5进行down_channel操作将通道数统一为64,得到了BiFPN的完整输入p3_in,p4_in,p5_in,p6_in,p7_in。
接下来进行bifpn中top-down路径的计算,以中间的第一个节点为例。首先p6_w1 = self.p6_w1_relu(self.p6_w1)是一个有两个参数的可学习权重,加relu保证权重大于0。接着weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)通过本文提出的fast normalize方法进行归一化,然后p7_in上采样并通过学习到的权重weight与p6_in进行加权融合,然后经过swish激活函数,最后经过深度可分离卷积self.conv6_up()就得到了top-down路径的第一个节点p6_up。代码如下
# Weights for P6_0 and P7_0 to P6_1
p6_w1 = self.p6_w1_relu(self.p6_w1)
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
# Connections for P6_0 and P7_0 to P6_1 respectively
p6_up = self.conv6_up(
self.combine(weight[0] * p6_in +
weight[1] * self.p6_upsample(p7_in))) # (1,64,8,8)同样的方法得到top-down路径的后两个节点输出p5_up和p4_up。
然后就要进行bottom-up路径的计算。首先是最下面的第一个红色节点p3_out,其输入为top-down路径的最后一个节点p4_up和原始输入的最下面一个节点p3_in,方法和上面top-down分支的计算一样。
接下来的实现我有些疑问,这里self.p4_level_connection()就是通过1x1卷积将通道数降为64,而在一开始已经通过self.p4_down_channel()将p4的通道数降为64了,为什么这里不直接用p4_in,p5_in,还要重新计算一遍?
if self.first_time:
# self.p4_level_connection和self.p4_down_channel是一样的,为什么不能直接用上面的p4_in?
p4_in = self.p4_level_connection(p4)
p5_in = self.p5_level_connection(p5)然后计算bottom-up路径的第二个节点p4_out,其输入包含三个节点p4_in,p4_up,p3_out,需要对p3_out进行下采样然后对三者通过可学习的权重进行加权融合,然后经过深度可分离卷积self.conv4_down()得到输出。
# Weights for P4_0, P4_1 and P3_2 to P4_2
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
self.combine(weight[0] * p4_in + weight[1] * p4_up +
weight[2] * self.p4_down_sample(p3_out))) # (1,64,32,32)然后同样的方法得到p5_out和p6_out。最后一个节点p7_out只有两个输入p7_in和p6_out。
到此,一个完整的BiFPN计算流程就完了,EfficientDet中迭代了三次bifpn,后一个bifpn的输入就是前一个的输出。
下面是bifpn部分的完整实现,其中做了一些注释。
# Copyright (c) OpenMMLab. All rights reserved.
# Modified from https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
from typing import List
import torch
import torch.nn as nn
from mmcv.cnn.bricks import Swish
from mmengine.model import BaseModule
from mmdet.registry import MODELS
from mmdet.utils import MultiConfig, OptConfigType
from .utils import (DepthWiseConvBlock, DownChannelBlock, MaxPool2dSamePadding,
MemoryEfficientSwish)
class BiFPNStage(nn.Module):
'''
in_channels: List[int], input dim for P3, P4, P5
out_channels: int, output dim for P2 - P7
first_time: int, whether is the first bifpnstage
num_outs: int, BiFPN need feature maps num
use_swish: whether use MemoryEfficientSwish
norm_cfg: (:obj:`ConfigDict` or dict, optional): Config dict for
normalization layer.
epsilon: float, hyperparameter in fusion features
'''
def __init__(self,
in_channels: List[int],
out_channels: int,
first_time: bool = False,
apply_bn_for_resampling: bool = True,
conv_bn_act_pattern: bool = False,
use_meswish: bool = True,
norm_cfg: OptConfigType = dict(
type='BN', momentum=1e-2, eps=1e-3),
epsilon: float = 1e-4) -> None:
super().__init__()
assert isinstance(in_channels, list)
self.in_channels = in_channels
self.out_channels = out_channels
self.first_time = first_time
self.apply_bn_for_resampling = apply_bn_for_resampling
self.conv_bn_act_pattern = conv_bn_act_pattern
self.use_meswish = use_meswish
self.norm_cfg = norm_cfg
self.epsilon = epsilon
if self.first_time:
self.p5_down_channel = DownChannelBlock(
self.in_channels[-1],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p4_down_channel = DownChannelBlock(
self.in_channels[-2],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p3_down_channel = DownChannelBlock(
self.in_channels[-3],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p5_to_p6 = nn.Sequential(
DownChannelBlock(
self.in_channels[-1],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg), MaxPool2dSamePadding(3, 2))
self.p6_to_p7 = MaxPool2dSamePadding(3, 2)
self.p4_level_connection = DownChannelBlock(
self.in_channels[-2],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p5_level_connection = DownChannelBlock(
self.in_channels[-1],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p6_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p5_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p4_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p3_upsample = nn.Upsample(scale_factor=2, mode='nearest')
# bottom to up: feature map down_sample module
self.p4_down_sample = MaxPool2dSamePadding(3, 2)
self.p5_down_sample = MaxPool2dSamePadding(3, 2)
self.p6_down_sample = MaxPool2dSamePadding(3, 2)
self.p7_down_sample = MaxPool2dSamePadding(3, 2)
# Fuse Conv Layers
self.conv6_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv5_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv4_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv3_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv4_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv5_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv6_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv7_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
# weights
self.p6_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p6_w1_relu = nn.ReLU()
self.p5_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p5_w1_relu = nn.ReLU()
self.p4_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p4_w1_relu = nn.ReLU()
self.p3_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p3_w1_relu = nn.ReLU()
self.p4_w2 = nn.Parameter(
torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p4_w2_relu = nn.ReLU()
self.p5_w2 = nn.Parameter(
torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p5_w2_relu = nn.ReLU()
self.p6_w2 = nn.Parameter(
torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p6_w2_relu = nn.ReLU()
self.p7_w2 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p7_w2_relu = nn.ReLU()
self.swish = MemoryEfficientSwish() if use_meswish else Swish()
def combine(self, x):
if not self.conv_bn_act_pattern:
x = self.swish(x)
return x
def forward(self, x):
if self.first_time:
p3, p4, p5 = x # [(1,40,64,64),(1,112,32,32),(1,320,16,16)]
# build feature map P6
p6_in = self.p5_to_p6(p5) # (1,64,8,8)
# build feature map P7
p7_in = self.p6_to_p7(p6_in) # (1,64,4,4)
p3_in = self.p3_down_channel(p3) # (1,64,64,64)
p4_in = self.p4_down_channel(p4) # (1,64,32,32)
p5_in = self.p5_down_channel(p5) # (1,64,16,16)
else:
p3_in, p4_in, p5_in, p6_in, p7_in = x
# Weights for P6_0 and P7_0 to P6_1
p6_w1 = self.p6_w1_relu(self.p6_w1)
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
# Connections for P6_0 and P7_0 to P6_1 respectively
p6_up = self.conv6_up(
self.combine(weight[0] * p6_in +
weight[1] * self.p6_upsample(p7_in))) # (1,64,8,8)
# Weights for P5_0 and P6_1 to P5_1
p5_w1 = self.p5_w1_relu(self.p5_w1)
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
# Connections for P5_0 and P6_1 to P5_1 respectively
p5_up = self.conv5_up(
self.combine(weight[0] * p5_in +
weight[1] * self.p5_upsample(p6_up))) # (1,64,16,16)
# Weights for P4_0 and P5_1 to P4_1
p4_w1 = self.p4_w1_relu(self.p4_w1)
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
# Connections for P4_0 and P5_1 to P4_1 respectively
p4_up = self.conv4_up(
self.combine(weight[0] * p4_in +
weight[1] * self.p4_upsample(p5_up))) # (1,64,32,32)
# Weights for P3_0 and P4_1 to P3_2
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
# Connections for P3_0 and P4_1 to P3_2 respectively
p3_out = self.conv3_up(
self.combine(weight[0] * p3_in +
weight[1] * self.p3_upsample(p4_up))) # (1,64,64,64)
if self.first_time:
# self.p4_level_connection和self.p4_down_channel是一样的,为什么不能直接用上面的p4_in?
p4_in = self.p4_level_connection(p4)
p5_in = self.p5_level_connection(p5)
# Weights for P4_0, P4_1 and P3_2 to P4_2
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
self.combine(weight[0] * p4_in + weight[1] * p4_up +
weight[2] * self.p4_down_sample(p3_out))) # (1,64,32,32)
# Weights for P5_0, P5_1 and P4_2 to P5_2
p5_w2 = self.p5_w2_relu(self.p5_w2)
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
p5_out = self.conv5_down(
self.combine(weight[0] * p5_in + weight[1] * p5_up +
weight[2] * self.p5_down_sample(p4_out))) # (1,64,16,16)
# Weights for P6_0, P6_1 and P5_2 to P6_2
p6_w2 = self.p6_w2_relu(self.p6_w2)
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
p6_out = self.conv6_down(
self.combine(weight[0] * p6_in + weight[1] * p6_up +
weight[2] * self.p6_down_sample(p5_out))) # (1,64,8,8)
# Weights for P7_0 and P6_2 to P7_2
p7_w2 = self.p7_w2_relu(self.p7_w2)
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
# Connections for P7_0 and P6_2 to P7_2
p7_out = self.conv7_down(
self.combine(weight[0] * p7_in +
weight[1] * self.p7_down_sample(p6_out))) # (1,64,4,4)
return p3_out, p4_out, p5_out, p6_out, p7_out
@MODELS.register_module()
class BiFPN(BaseModule):
'''
num_stages: int, bifpn number of repeats
in_channels: List[int], input dim for P3, P4, P5
out_channels: int, output dim for P2 - P7
start_level: int, Index of input features in backbone
epsilon: float, hyperparameter in fusion features
apply_bn_for_resampling: bool, whether use bn after resampling
conv_bn_act_pattern: bool, whether use conv_bn_act_pattern
use_swish: whether use MemoryEfficientSwish
norm_cfg: (:obj:`ConfigDict` or dict, optional): Config dict for
normalization layer.
init_cfg: MultiConfig: init method
'''
def __init__(self,
num_stages: int,
in_channels: List[int],
out_channels: int,
start_level: int = 0,
epsilon: float = 1e-4,
apply_bn_for_resampling: bool = True,
conv_bn_act_pattern: bool = False,
use_meswish: bool = True,
norm_cfg: OptConfigType = dict(
type='BN', momentum=1e-2, eps=1e-3),
init_cfg: MultiConfig = None) -> None:
super().__init__(init_cfg=init_cfg)
self.start_level = start_level
self.bifpn = nn.Sequential(*[
BiFPNStage(
in_channels=in_channels,
out_channels=out_channels,
first_time=True if _ == 0 else False,
apply_bn_for_resampling=apply_bn_for_resampling,
conv_bn_act_pattern=conv_bn_act_pattern,
use_meswish=use_meswish,
norm_cfg=norm_cfg,
epsilon=epsilon) for _ in range(num_stages)
])
def forward(self, x):
# [(1,40,64,64),(1,112,32,32),(1,320,16,16)]
x = x[self.start_level:]
x = self.bifpn(x)
return x