搜索引擎技术Lucene
Lucene介绍
Lucene
Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具。Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品。Lucene 这个开源项目,使得 Java开发人员可以很方便地得到像搜索引擎google baidu那样的搜索效果。
JDK版本
至少使用JDK8版本
官网下载
Apache Lucene - Welcome to Apache Lucene
Lucene使用
导入依赖

1.准备分词器
IKAnalyzer analyzer = new IKAnalyzer();2.创建索引
(1).首先准备10条数据
List productNames = new ArrayList<>();
productNames.add("飞利浦led灯泡e27螺口暖白球泡灯家用照明超亮节能灯泡转色温灯泡");
productNames.add("飞利浦led灯泡e14螺口蜡烛灯泡3W尖泡拉尾节能灯泡暖黄光源Lamp");
productNames.add("雷士照明 LED灯泡 e27大螺口节能灯3W球泡灯 Lamp led节能灯泡");
productNames.add("飞利浦 led灯泡 e27螺口家用3w暖白球泡灯节能灯5W灯泡LED单灯7w");
productNames.add("飞利浦led小球泡e14螺口4.5w透明款led节能灯泡照明光源lamp单灯");
productNames.add("飞利浦蒲公英护眼台灯工作学习阅读节能灯具30508带光源");
productNames.add("欧普照明led灯泡蜡烛节能灯泡e14螺口球泡灯超亮照明单灯光源");
productNames.add("欧普照明led灯泡节能灯泡超亮光源e14e27螺旋螺口小球泡暖黄家用");
productNames.add("聚欧普照明led灯泡节能灯泡e27螺口球泡家用led照明单灯超亮光源"); (2).通过createIndex方法,把它加入到索引当中
private static Directory createIndex(IKAnalyzer analyzer, List products) throws IOException {
Directory index = new RAMDirectory();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(index, config);
for (String name : products) {
addDoc(writer, name);
}
writer.close();
return index;
}
(3).每条数据创建一个Document,并把这个Document放进索引里。
private static void addDoc(IndexWriter w, String name) throws IOException {
Document doc = new Document();
doc.add(new TextField("name", name, Field.Store.YES));
w.addDocument(doc);
}3.创建查询器
根据关键字 护眼带光源,基于 "name" 字段进行查询。 这个 "name" 字段就是在创建索引步骤里每个Document的 "name" 字段,相当于表的字段名。
String keyword = "护眼带光源";
Query query = new QueryParser("name", analyzer).parse(keyword);4.执行搜索
(1).创建索引 reader:
IndexReader reader = DirectoryReader.open(index);
(2).基于 reader 创建搜索器:
IndexSearcher searcher = new IndexSearcher(reader);(3).指定每页要显示多少条数据:
int numberPerPage = 1000;(4).执行搜索
ScoreDoc[] hits = searcher.search(query, numberPerPage).scoreDocs;5.显示查询效果
private static void showSearchResults(IndexSearcher searcher, ScoreDoc[] hits, Query query, IKAnalyzer analyzer)
throws Exception {
System.out.println("找到 " + hits.length + " 个命中.");
System.out.println("序号\t匹配度得分\t结果");
for (int i = 0; i < hits.length; ++i) {
ScoreDoc scoreDoc= hits[i];
int docId = scoreDoc.doc;
Document d = searcher.doc(docId);
List fields = d.getFields();
System.out.print((i + 1));
System.out.print("\t" + scoreDoc.score);
for (IndexableField f : fields) {
System.out.print("\t" + d.get(f.name()));
}
System.out.println();
}
} 6.运行结果

以上就是lucene最基本的使用,源码以及依赖包资源:
链接:https://pan.baidu.com/s/1BV3rGqtLfZo13fg2oehBpA?pwd=xe29
提取码:xe29
分词器

选中的IKAnalyzer就是java开源中文分词器。

编写TestAnalyzer
package com.how2java;
import java.io.IOException;
import org.apache.lucene.analysis.TokenStream;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class TestAnalyzer {
public static void main(String[] args) throws IOException {
IKAnalyzer analyzer = new IKAnalyzer();
TokenStream ts= analyzer.tokenStream("name", "护眼带光源");
ts.reset();
while(ts.incrementToken()){
System.out.println(ts.reflectAsString(false));
}
}
}
运行结果

如代码所示,使用IKAnalyzer 中文分词器就会把 护眼带光源 分为这么如图所示的3个小关键字进行匹配。
Lucene的高级使用
高亮显示
目的是让我们的关键词变得更加醒目,例如给所有关键字加上一个HTML标签。
修改 TestLucene
package com.how2java;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class TestLucene {
public static void main(String[] args) throws Exception {
// 1. 准备中文分词器
IKAnalyzer analyzer = new IKAnalyzer();
// 2. 索引
List productNames = new ArrayList<>();
productNames.add("飞利浦led灯泡e27螺口暖白球泡灯家用照明超亮节能灯泡转色温灯泡");
productNames.add("飞利浦led灯泡e14螺口蜡烛灯泡3W尖泡拉尾节能灯泡暖黄光源Lamp");
productNames.add("雷士照明 LED灯泡 e27大螺口节能灯3W球泡灯 Lamp led节能灯泡");
productNames.add("飞利浦 led灯泡 e27螺口家用3w暖白球泡灯节能灯5W灯泡LED单灯7w");
productNames.add("飞利浦led小球泡e14螺口4.5w透明款led节能灯泡照明光源lamp单灯");
productNames.add("飞利浦蒲公英护眼台灯工作学习阅读节能灯具30508带光源");
productNames.add("欧普照明led灯泡蜡烛节能灯泡e14螺口球泡灯超亮照明单灯光源");
productNames.add("欧普照明led灯泡节能灯泡超亮光源e14e27螺旋螺口小球泡暖黄家用");
productNames.add("聚欧普照明led灯泡节能灯泡e27螺口球泡家用led照明单灯超亮光源");
Directory index = createIndex(analyzer, productNames);
// 3. 查询器
String keyword = "护眼带光源";
Query query = new QueryParser("name", analyzer).parse(keyword);
// 4. 搜索
IndexReader reader = DirectoryReader.open(index);
IndexSearcher searcher = new IndexSearcher(reader);
int numberPerPage = 1000;
System.out.printf("当前一共有%d条数据%n",productNames.size());
System.out.printf("查询关键字是:\"%s\"%n",keyword);
ScoreDoc[] hits = searcher.search(query, numberPerPage).scoreDocs;
// 5. 显示查询结果
showSearchResults(searcher, hits, query, analyzer);
// 6. 关闭查询
reader.close();
}
private static void showSearchResults(IndexSearcher searcher, ScoreDoc[] hits, Query query, IKAnalyzer analyzer)
throws Exception {
System.out.println("找到 " + hits.length + " 个命中.");
System.out.println("序号\t匹配度得分\t结果");
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
for (int i = 0; i < hits.length; ++i) {
ScoreDoc scoreDoc= hits[i];
int docId = scoreDoc.doc;
Document d = searcher.doc(docId);
List fields = d.getFields();
System.out.print((i + 1));
System.out.print("\t" + scoreDoc.score);
for (IndexableField f : fields) {
TokenStream tokenStream = analyzer.tokenStream(f.name(), new StringReader(d.get(f.name())));
String fieldContent = highlighter.getBestFragment(tokenStream, d.get(f.name()));
System.out.print("\t" + fieldContent);
}
System.out.println("
");
}
}
private static Directory createIndex(IKAnalyzer analyzer, List products) throws IOException {
Directory index = new RAMDirectory();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(index, config);
for (String name : products) {
addDoc(writer, name);
}
writer.close();
return index;
}
private static void addDoc(IndexWriter w, String name) throws IOException {
Document doc = new Document();
doc.add(new TextField("name", name, Field.Store.YES));
w.addDocument(doc);
}
}
增加了两段代码
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query)); TokenStream tokenStream = analyzer.tokenStream(f.name(), new StringReader(d.get(f.name())));
String fieldContent = highlighter.getBestFragment(tokenStream, d.get(f.name())); 第一段代码是给关键词增加高亮格式,并实例化高亮工具。
第二段代码是用高亮工具处理普通的查询结果。
运行结果:
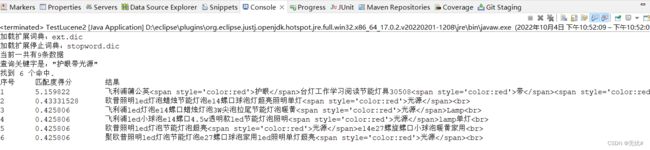
这样看并不明显,将它复制到html文件中查看:
