[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
文章目录
- 视频资料:
- 思维导图
- 一、Spark基础入门(环境搭建、入门概念)
- 第二章:Spark环境搭建-Local
-
- 2.1 课程服务器环境
- 2.2 Local模式基本原理
- 2.3 安装包下载
- 2.4 Spark Local模式部署
- 第三章:Spark环境搭建-StandAlone
-
- 3.1 StandAlone的运行原理
- 3.2 StandAlone环境安装操作
- 3.3 StandAlone程序测试
- 3.4 Spark程序运行层次结构
- 3.5 总结
- 第四章:Spark环境搭建-StandAlone-HA
-
- 4.1 StandAlone HA运行原理
- 4.2 基于Zookeeper实现HA
- spark配置双master时一直处于standby的情况
-
- 4.3 总结
- 第五章:Spark环境搭建-Spark On YARN
-
- 5.1 Spark On YARN的运行原理
- 5.2 Spark On YARN部署和测试
- 5.3 部署模式DeployMode
- 5.4 两种部署模式的演示和总结
- 5.5 两种模式任务提交流程
- 5.6 总结
- 第六章:PySpark库
-
- 6.1 框架 VS 类库
- 6.2 PySpark类库介绍
- 6.3 PySpark安装
- 6.4 总结
- 第七章:本机开发环境搭建
-
- 7.1 本机配置Python环境
- 7.2 PyCharm本地和远程解释器配置
- 7.3 编程入口SparkContext对象以及WordCount演示
- 7.4 WordCount代码流程解析
- 7.5 提交WordCount到Linux集群运行
- 7.6 总结
- 第八章:分布式代码执行分析
-
- 8.1 Spark运行角色回顾
- 8.2 分布式代码执行分析
- 8.3 Python On Spark执行原理
- 8.4 总结
- 2.Spark核心
-
- 学习目标
- 第一章:RDD详解
-
- 1.1 什么是RDD
- 1.2 RDD五大特性-特性1
- 1.3 RDD五大特性-特性2
- 1.4 RDD五大特性-特性3
- 1.5 RDD五大特性-特性4
- 1.6 RDD五大特性-特性5
- 1.7 WordCount结合RDD特性进行执行分析
- 1.8 第一章总结
- 第二章:RDD编程入门
-
- 2.1 程序执行入口SparkContext对象
- 2.2 RDD的创建
-
- 方式一:通过并行化集合创建(本地对象转分布式RDD)
- 方式二:读取外部数据源
- 2.3 RDD算子概念和分类
- 2.4 常用转换算子
-
- 转换算子-map
- 转换算子-flatMap
- 转换算子-reduceByKey
- 转换算子-mapValues
- WordCount案例回顾
- 转换算子-groupBy
- 转换算子-filter
- 转换算子-distinct
- 转换算子-union
- 转换算子-join
- 转换算子-intersection
- 转换算子-glom
- 转换算子-groupByKey
- 转换算子-sortBy
- 转换算子-sortByKey
- RDD算子-案例
- RDD算子-案例-提交到YARN执行
- 2.5 常用Action算子
-
- Action算子-countByKey
- Action算子-collect
- Action算子-reduce
- Action算子-fold-了解
- Action算子-first
- Action算子-take
- Action算子-top
- Action算子-count
- Action算子-takeSample
- Action算子-takeOrdered
- Action算子-foreach
- Action算子-saveAsTextFile
- 2.6 分区操作算子
-
- 转换算子-mapPartitions
- Action算子-foreachPartition
- 转换算子-partitionBy
- 转换算子-repartition
- 面试题:groupByKey和reduceByKey的区别
- 2.7 第二章总结
- 第三章:RDD的持久化
-
- 3.1 RDD的数据是过程数据
- 3.2 RDD缓存
- 3.3 RDD CheckPoint
- 3.4 第三章总结
- 第四章:Spark案例练习
-
- 4.1 搜索引擎日志分析案例
- 4.2 提交到集群运行
- 4.3 第四章作业和总结
-
- 作业
- 总结
- 第五章:共享变量
-
- 5.1 广播变量
- 5.2 累加器
- 5.3 广播变量累加器综合案例
- 5.4 第五章总结
- 第六章:Spark内核调度(重点理解)
-
- 6.1 DAG
- 6.2 DAG的宽窄依赖和阶段划分
- 6 .3 内存迭代计算
- 6.4 Spark并行度
- 6.5 Spark任务调度
-
- DAG调度器
- Task调度器
- 6.6 拓展-Spark概念名称大全
- 6.7 第六章总结
- 3.SparkSQL
-
- 学习目标
- 第一章:SparkSQL快速入门
-
- 1.1 什么是SparkSQL
- 1.2 为什么要学习SparkSQL
- 1.3 SparkSQL特点
- 1.4 SparkSQL发展历史
- 1.5 第一章总结
- 第二章:SparkSQL概述
-
- 2.1 SparkSQL和Hive的异同
- 2.2 SparkSQL的数据抽象
- 2.3 SparkSQL数据抽象的发展
- 2.4 DataFrame数据抽象
- 2.5 SparkSession对象
- 2.6 SparkSQL HelloWorld
- 2.7 第二章总结
- 第三章:DataFrame入门
-
- 3.1 DataFrame的组成
- 3.2 DataFrame的代码构建
-
- 基于RDD方式1-通过createDataFrame方法
- 基于RDD方式2-通过StructType对象
- 基于RDD方式3-使用toDF方法
- 基于Pandas的DataFrame
- 读取外部数据
-
- 读取Text文件
- 读取json文件
- 读取csv文件
- 读取parquet文件
- 3.3 DataFrame的入门操作
-
- DSL风格
- SQL风格
- 3.4 词频统计案例
- 3.5 电影数据分析
-
-
- 遇到问题:
-
- 3.6 SparkSQL Shuffle 分区数目
- 3.7 SparkSQL 数据清洗API
- 3.8 DataFrame数据写出
- 3.9 DataFrame通过JDBC读写数据库(MySQL示例)
- 3.10 第三章总结
- 第四章:SparkSQL函数定义
-
- 4.1 SparkSQL定义UDF函数
-
- sparksession.udf.register()
- pyspark.sql.functions.udf
- 注册一个ArraryType返回类型的UDF
- 注册一个字典返回类型的UDF
- 拓展-通过RDD代码模拟UDAF效果
- 4.2 SparkSQL使用窗口函数
- 4.3 第四章总结
- 第五章:SparkSQL的运行流程
-
- 5.1 SparkRDD的执行流程回顾
- 5.2 SparkSQL的自动优化
- 5.3 Catalyst优化器
- 5.4 SparkSQL的执行流程
- 5.5 第五章总结
- 第六章:Spark On Hive
-
- 6.1 原理
- 6.2 配置
- 6.3 在代码中集成
- 6.4 第六章总结
- 第七章:分布式SQL执行引擎
-
- 7.1 概念
- 7.2 客户端工具连接
-
- 配置
- 数据库工具连接ThriftServer
- 7.3 代码JDBC连接
-
- Pycharm软件连接ThriftServer
- 7.4 第七章总结
- 4.Spark综合案例
- 需求分析
-
- 需求1:
- 需求2:
- 需求3:
- 需求4:
- 5.Spark新特性+核心回顾
-
- 学习目标
- 第一章:Spark Shuffle
-
- 1.1 Spark Shuffle
- 1.2 HashShuffleManager
- 1.3 SortShuffleManager
- 1.4 第一章总结
- 第二章:Spark3.0新特性
-
- 2.2 Adaptive Query Execution自适应查询(SparkSQL)
- AQE总结
- 2.3 Dynamic Partition Pruning动态分区裁剪(SparkSQL)
- 2.4 增强的Python API:PySpark和Koalas
- 2.5 Koalas入门演示-Koalas DataFrame构建
视频资料:
黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
思维导图
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第1张图片](http://img.e-com-net.com/image/info8/9bb9f845a5f141e69c5aa9a9a0c1bc42.jpg)
一、Spark基础入门(环境搭建、入门概念)
学习目标:
1.[了解]Spark诞生背景
2.[了解]Saprk的应用场景
3.[掌握]Spark环境的搭建
4.[掌握]Spark的入门案例
5.[了解]Spark的基本原理
第一章:Spark框架概述
1.1 Spark是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
1.2 Spark风雨十年
1.3 扩展阅读:Spark VS Hadoop
1.4 Spark四大特点
1.5 Spark框架模型-了解
1.6 Spark运行模式
1.7 Spark架构角色
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第2张图片](http://img.e-com-net.com/image/info8/da095e6d95294e0dbd691343a04bba32.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第3张图片](http://img.e-com-net.com/image/info8/7a2d880592374199a1385928aaeaa9fb.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第4张图片](http://img.e-com-net.com/image/info8/1260a392dac2432b85a8d3363381a9c9.jpg)
Spark解决什么问题?
- 海量数据的计算,可以进行离线批处理、实时流计算、机器学习计算、图计算、通过SQL完成结构化数据的处理。
Spark有哪些模块?
- 核心SparkCore、SQL计算(SparkSQL支持离线批处理, 其上面也有structured streaming支持实时流计算)、流计算(SparkStreaming,有缺陷)、图计算(GraphX)、机器学习(MLlib)
Spark特点有哪些?
- 速度快、使用简单、通用性强、多种模式运行。
Spark的运行模式?
-
本地模式(Local模式,在一个
-
集群模式(StandAlone、YARN、K8S)
-
云模式
Spark的运行角色(对比YARN)?
Master:集群资源管理(类同ResourceManager)
Worker:单机资源管理(类同NodeManager)
Driver:单任务管理者(类同ApplicationMaster)
Executor:单任务执行者(类同YARN容器内的Task)
第二章:Spark环境搭建-Local
2.1 课程服务器环境
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第5张图片](http://img.e-com-net.com/image/info8/f40c1a20edfc43009f4e732863495120.jpg)
2.2 Local模式基本原理
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第6张图片](http://img.e-com-net.com/image/info8/d89c36061f5f431384d3f9b5ff4f86bf.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第7张图片](http://img.e-com-net.com/image/info8/49139692401944338f4f89acfa605a91.jpg)
2.3 安装包下载
PS:软连接与硬链接,参考资料:https://www.bilibili.com/video/BV1CZ4y1v7SR/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=c1627e67b359df87544f502955497bf7
配置环境变量:
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第8张图片](http://img.e-com-net.com/image/info8/c4e3f22849d44564b3a5f0ac2120c0b0.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第9张图片](http://img.e-com-net.com/image/info8/a174f8ec0c52493db1348859f1503b06.jpg)
2.4 Spark Local模式部署
- Local模式的运行原理?
Local模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境。Local模式可以通过spark-shell/pyspark/spark-submit等来开启。
- bin/pyspark是什么程序?
是一个交互式的解释器执行环境,环境启动后就得到了一个Local Spark环境,可以运行Python代码去进行Spark计算,类似Python自带解释器。
- Spark的4040端口是什么?
Spark的任务在运行后,会在Driver所在机器绑定到4040端口,提供当前任务的监控页面供查看。
PS:如果有多个Local模式下的Spark任务在一台机器上执行,则绑定的端口会依次顺延。
第三章:Spark环境搭建-StandAlone
3.1 StandAlone的运行原理
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第10张图片](http://img.e-com-net.com/image/info8/e410dd9ade7e477a9642ac0eafa9539b.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第11张图片](http://img.e-com-net.com/image/info8/eb1f2844c6d3402a9233f4084301b3ea.jpg)
3.2 StandAlone环境安装操作
详看视频
3.3 StandAlone程序测试
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第12张图片](http://img.e-com-net.com/image/info8/426693f01387473894d3a565e0425e0e.jpg)
3.4 Spark程序运行层次结构
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第13张图片](http://img.e-com-net.com/image/info8/ee185ca943954c57927136ee3a60e092.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第14张图片](http://img.e-com-net.com/image/info8/6aafae1564bc4c9a955ed5498fa7a638.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第15张图片](http://img.e-com-net.com/image/info8/f81be29f06414725a561c729b5fc4458.jpg)
3.5 总结
- StandAlone的原理?
Master和Worker角色以独立进程的形式存在,并组成Spark运行时环境(集群)
- Spark角色在StandAlone中的分布?
Master角色:Master进程
Worker角色:Worker进程
Driver角色:以线程运行在Master中
Executor角色:以线程运行在Worker中
- StandAlone如何提交Spark应用?
bin/spark-submit --master spark://server:7077
- 4040\8080\18080分别是什么?
4040是单个程序运行的时候绑定的端口可供查看本任务运行情况(4040和Driver绑定,也和Spark的应用程序绑定)。
8080是Master运行的时候默认的WebUI端口(Master进程是守护进程)。
18080是Spark历史服务器的端口,可供我们查看历史运行程序的运行状态。
- Job\State\Task的关系?
一个Spark应用程序会被分成多个子任务(Job)运行,每一个Job会分成多个Stage(阶段)来运行,每一个Stage内会分出来多个Task(线程)来执行具体任务。
第四章:Spark环境搭建-StandAlone-HA
4.1 StandAlone HA运行原理
Spark Standalone集群存在Master单点故障(SPOF)的问题。
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第16张图片](http://img.e-com-net.com/image/info8/18e586a04fdc4c0d9041d709a3611d74.jpg)
4.2 基于Zookeeper实现HA
spark配置双master时一直处于standby的情况
4.3 总结
- StandAloneHA的原理
基于Zookeeper做状态的维护,开启多个Master进程,一个作为活跃,其他的作为备份,当活跃进程宕机,备份的Master进行接管。
第五章:Spark环境搭建-Spark On YARN
5.1 Spark On YARN的运行原理
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第17张图片](http://img.e-com-net.com/image/info8/931e8d344db3450a9b764ab82cc296ec.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第18张图片](http://img.e-com-net.com/image/info8/11022e0ba4d640bfb50d566decd100c3.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第19张图片](http://img.e-com-net.com/image/info8/de193e67c49b4ee4ba91c7ced9b74f97.jpg)
5.2 Spark On YARN部署和测试
详见视频
5.3 部署模式DeployMode
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第20张图片](http://img.e-com-net.com/image/info8/1aca16e53a4f429a8289438d0fc3699e.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第21张图片](http://img.e-com-net.com/image/info8/1c9ed293454145b086e535a9489e205a.jpg)
5.4 两种部署模式的演示和总结
Cluster模式
bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100
需要通过下面命令打开Yarn的历史服务器(JobHistoryServer)
mapred --daemon start historyserver
Client模式
bin/spark-submit --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100

5.5 两种模式任务提交流程
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第22张图片](http://img.e-com-net.com/image/info8/cbd49223eb6e43b3aca720ce790f1a63.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第23张图片](http://img.e-com-net.com/image/info8/b818b5ab1b884510a8426e4eed927763.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第24张图片](http://img.e-com-net.com/image/info8/a6ebb010f24f4928b4547531f18d26d7.jpg)
5.6 总结
- SparkOnYarn本质?
Master由ResourceManager代替
Worker由NodeManager代替
Driver可以运行在容器内(Cluster模式)或客户端进程中(Client模式)
Executor全部运行在YARN提供的容器内
- Why Spark On YARN?
提供资源利用率,在已有YARN的场景下让Spark收到YARN的调度可以更好的管控资源提高利用率并方便管理。
第六章:PySpark库
6.1 框架 VS 类库
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第25张图片](http://img.e-com-net.com/image/info8/7a656c1d291c477f823974eb33a441f0.jpg)
6.2 PySpark类库介绍
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第26张图片](http://img.e-com-net.com/image/info8/e56b633631984b9a8deef9f134d645c4.jpg)
6.3 PySpark安装
详见视频
6.4 总结
- PySpark是什么?和bin/pyspark程序有何区别?
PySpark是一个Python的类库,提供Spark的操作API
bin/pyspark是一个交互式的程序,可以提供交互式编程并执行Spark计算
- 本课程的Python运行环境由什么来提供?
由Anaconda提供,并使用虚拟环境,环境名称叫做:pyspark
第七章:本机开发环境搭建
7.1 本机配置Python环境
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第27张图片](http://img.e-com-net.com/image/info8/4aa3a4ed9a1748e79448c9859c2b8b18.jpg)
7.2 PyCharm本地和远程解释器配置
详见视频
7.3 编程入口SparkContext对象以及WordCount演示
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第28张图片](http://img.e-com-net.com/image/info8/326d268ace114447b9dd1bf9249c919c.jpg)
PS:解决WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform…警告

找了好几个都不行。
PS:解决
![]()
参考资料https://blog.csdn.net/weixin_51951625/article/details/117452855
https://blog.csdn.net/OWBY_Phantomhive/article/details/123088763
https://blog.csdn.net/qq_20540901/article/details/123499540

需要配置环境变量
7.4 WordCount代码流程解析
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第29张图片](http://img.e-com-net.com/image/info8/b89fee5cabfc4c8f8835c813e14af796.jpg)
7.5 提交WordCount到Linux集群运行
通过spark-submit yarn提交到集群的py文件中的地址,集群会默认去hdfs里面找。

![]()
在yarn模式或者standalone这样的集群下,访问的文件路径,要么是网络地址,要么是hdfs,这样每台机器都能访问到。
7.6 总结
- Python语言开发Spark程序步骤?
主要是获取SparkContext对象,基于SparkContext对象作为执行环境入口。
- 如何提交Spark应用?
将程序代码上传到服务器上,通过spark-submit客户端工具进行提交。
1.在代码中不要设置master,如果设置了,会以代码为准,spark-submit工具的设置就无效了。
2.提交程序到集群中的时候,读取的文件一定是各个机器都能访问到的地址。比如HDFS。
第八章:分布式代码执行分析
8.1 Spark运行角色回顾
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第30张图片](http://img.e-com-net.com/image/info8/fff7aaeb491643009eb1591eb7de4112.jpg)
8.2 分布式代码执行分析
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第31张图片](http://img.e-com-net.com/image/info8/f387dbdbec7f4aae8d7afbb5b1d9aa21.jpg)
8.3 Python On Spark执行原理
![]()
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第32张图片](http://img.e-com-net.com/image/info8/ebcb7c273300446a9c6b49051842f0f7.jpg)
8.4 总结
- 分布式代码执行的重要特征是什么?
代码在集群上运行,是被分布式运行的。
在Spark中, 非任务处理部分,由Driver执行(非RDD代码)。
任务处理部分由Executor执行(RDD代码)。
Executor的数量很多,所以任务的计算是分布式在运行的。
- 简述PySpark的架构体系。
Python On Spark:Driver端由JVM执行,Executor端由JVM做命令转发,底层由Python解释器进行工作。
2.Spark核心
学习目标
- 了解RDD产生背景
- 掌握RDD的创建
- 掌握RDD的重要算子
- 掌握RDD的缓存和检查点机制
- 熟悉Spark执行的基本原理
第一章:RDD详解
1.1 什么是RDD
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第33张图片](http://img.e-com-net.com/image/info8/d2882482858a43169cd742bbdc64c330.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第34张图片](http://img.e-com-net.com/image/info8/e587f6948938483db6f828d30fe44a8a.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第35张图片](http://img.e-com-net.com/image/info8/f06625da5c0a45168b468482f8e43156.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第36张图片](http://img.e-com-net.com/image/info8/33a37b62f95b4bef995d3844767a6df5.jpg)
1.2 RDD五大特性-特性1
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第37张图片](http://img.e-com-net.com/image/info8/9c82d3324e414577847b5bc1507375d8.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第38张图片](http://img.e-com-net.com/image/info8/b73246fd4d9242cf9b1a7537c7236263.jpg)
1.3 RDD五大特性-特性2
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第39张图片](http://img.e-com-net.com/image/info8/f6c6c53e356f47ffa9ef365d45d05f0b.jpg)
1.4 RDD五大特性-特性3
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第40张图片](http://img.e-com-net.com/image/info8/ee0a0785471b44c6bf4609aabd32c6db.jpg)
1.5 RDD五大特性-特性4
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第41张图片](http://img.e-com-net.com/image/info8/cb4abe4662d949368d4cd78df5f66896.jpg)
1.6 RDD五大特性-特性5
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第42张图片](http://img.e-com-net.com/image/info8/ca2d899e03944a01a772ba1394aceea4.jpg)
1.7 WordCount结合RDD特性进行执行分析
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第43张图片](http://img.e-com-net.com/image/info8/7c7a9f64ac7a4c9a93563114831d1f4d.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第44张图片](http://img.e-com-net.com/image/info8/7f257de40c6447118d5493dfa0962355.jpg)
1.8 第一章总结
- 如何正确理解RDD?
不可变、可分区、并行计算的弹性分布式数据集,分布式计算的实现载体(数据抽象)
- RDD五大特点分别是?
RDD有分区;RDD的方法会作用在所有分区上;RDD之间有依赖关系;KV型的RDD是有分区器的;RDD的分区规划,会尽量靠近数据所在服务器。
第二章:RDD编程入门
2.1 程序执行入口SparkContext对象
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第45张图片](http://img.e-com-net.com/image/info8/6a3ad56e73ba4477853e39889244ad79.jpg)
2.2 RDD的创建
方式一:通过并行化集合创建(本地对象转分布式RDD)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第46张图片](http://img.e-com-net.com/image/info8/586eaae357df4660b4ba0616e14c0369.jpg)
在local[*]方法下,parallelize方法,没有给定分区数的情况下,默认分区数是根据CPU核心数来定。
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第47张图片](http://img.e-com-net.com/image/info8/81af558adc9848df96599fa14245f283.jpg)
方式二:读取外部数据源
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第48张图片](http://img.e-com-net.com/image/info8/82d103b86d5d4255a9789c44bc1cbefa.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第49张图片](http://img.e-com-net.com/image/info8/f3a28b80e2ea42e0aa16a76bd0481177.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第50张图片](http://img.e-com-net.com/image/info8/cdbc09fa784947c59645737725ef23b7.jpg)
2.3 RDD算子概念和分类
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第51张图片](http://img.e-com-net.com/image/info8/7f41a83a9128419fb2643a5f2efb4ad4.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第52张图片](http://img.e-com-net.com/image/info8/be217837f5f8406a886607cc342e031a.jpg)
2.4 常用转换算子
转换算子-map
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第53张图片](http://img.e-com-net.com/image/info8/c5df27bef1e04b71b1474e9c075b7e69.jpg)
转换算子-flatMap
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第54张图片](http://img.e-com-net.com/image/info8/c77a2d287a2249b7bdc8c6e9142ca80d.jpg)

转换算子-reduceByKey
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第55张图片](http://img.e-com-net.com/image/info8/4f5ed01ac90e4518a01e4b86a38bfb68.jpg)
PS:报错:UserWarning: Please install psutil to have better support with spilling
参考资料:https://blog.csdn.net/sqlserverdiscovery/article/details/102936203
![]()
PS:未正确退出conda环境,会报错
参考资料:https://blog.csdn.net/weixin_44211968/article/details/122483304
conda deactivate
转换算子-mapValues
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第56张图片](http://img.e-com-net.com/image/info8/8bfc21fa338d4aff8d6bf81b607d0cf9.jpg)
WordCount案例回顾
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第57张图片](http://img.e-com-net.com/image/info8/e321a3d6795d40fcbeb7c7315d0caec3.jpg)
转换算子-groupBy
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第58张图片](http://img.e-com-net.com/image/info8/a77f6815e83f4371b9e27625623e302c.jpg)
转换算子-filter
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第59张图片](http://img.e-com-net.com/image/info8/4072fc2c4110406d90ed7fab303cd64f.jpg)
转换算子-distinct
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第60张图片](http://img.e-com-net.com/image/info8/fbd98cb6ca8140139e38bd09e82cbcf7.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第61张图片](http://img.e-com-net.com/image/info8/720bcf5ee22f46dc81ad7ea8eae8dae1.jpg)
转换算子-union
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第62张图片](http://img.e-com-net.com/image/info8/fd6624c365d64cbeb1f39245461ef27a.jpg)
转换算子-join
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第63张图片](http://img.e-com-net.com/image/info8/d17ee275debb45d2967ffe7958cdf5d0.jpg)
转换算子-intersection
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第64张图片](http://img.e-com-net.com/image/info8/dbabcb1f69c14bcfbe8db8ba0729c1df.jpg)
转换算子-glom
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第65张图片](http://img.e-com-net.com/image/info8/1587c4d9adaa4be2b9d891c08c46ddad.jpg)
转换算子-groupByKey
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第66张图片](http://img.e-com-net.com/image/info8/f42ba7e532ca4f3ca0c879c44ab7e1df.jpg)
groupByKey只保留同组的值,而groupBy还保留key。
转换算子-sortBy
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第67张图片](http://img.e-com-net.com/image/info8/40596237267f4e37b162bbe35642d6c1.jpg)
注意:如果选择多个分区来进行排序,那么就意味着有多个excutor,每个excutor只能保证局部有序。所以如果要全局有序,排序分区的并行任务数请设置为1
转换算子-sortByKey
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第68张图片](http://img.e-com-net.com/image/info8/cf481e7ff7974c1da82ea5988aa0bd2b.jpg)
RDD算子-案例
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第69张图片](http://img.e-com-net.com/image/info8/adc12490ac3e464bbcf2845ff950ae24.jpg)
RDD算子-案例-提交到YARN执行
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第70张图片](http://img.e-com-net.com/image/info8/38a32c2b1d3a475fb60777485003f8be.jpg)
2.5 常用Action算子
Action算子-countByKey
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第71张图片](http://img.e-com-net.com/image/info8/c9261134e07d44d683d05cfcbc2667b6.jpg)
Action算子-collect
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第72张图片](http://img.e-com-net.com/image/info8/bb94f9b1384d457e969db5c2a2902fc8.jpg)
Action算子-reduce
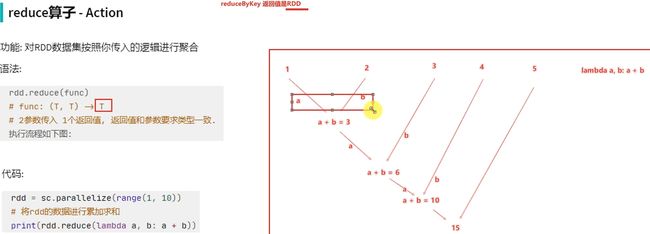
Action算子-fold-了解
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第73张图片](http://img.e-com-net.com/image/info8/c934dc08d09f43d09648960e1f9a6833.jpg)
Action算子-first
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第74张图片](http://img.e-com-net.com/image/info8/2e89cff092b34cbf87971174b7fc0ff6.jpg)
Action算子-take
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第75张图片](http://img.e-com-net.com/image/info8/7ba9225e7f4a47b5a6419aeaa3fa5305.jpg)
Action算子-top
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第76张图片](http://img.e-com-net.com/image/info8/edddcd5d8bd9404fb962a6f947858f5e.jpg)
Action算子-count
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第77张图片](http://img.e-com-net.com/image/info8/6cbce3f2bb85427a8dd6405ef49aa74c.jpg)
Action算子-takeSample
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第78张图片](http://img.e-com-net.com/image/info8/2a62a7a1c43f4925961c691b8e5c898e.jpg)
Action算子-takeOrdered
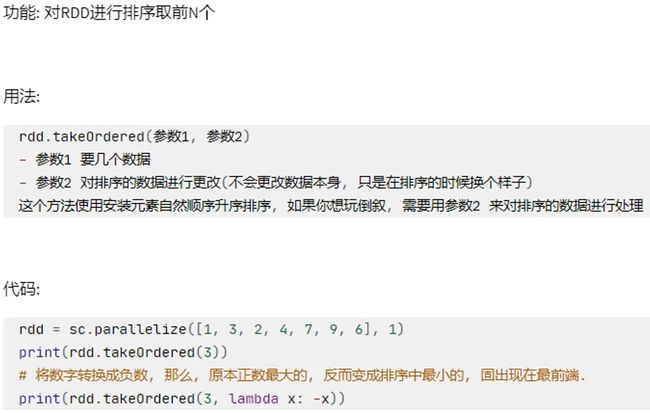
Action算子-foreach
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第79张图片](http://img.e-com-net.com/image/info8/87519f9a5a184f879cbd53b40af8435a.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第80张图片](http://img.e-com-net.com/image/info8/aeaf29bee94c43f19270bd0a5230b62c.jpg)
Action算子-saveAsTextFile
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第81张图片](http://img.e-com-net.com/image/info8/aa94ac0d468c4f0b97e642da606aae6e.jpg)
rdd有几个分区,写出的数据就有几个"part-xxxx"文件
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第82张图片](http://img.e-com-net.com/image/info8/50ac9fbc8bf0417c957401152d4c7fec.jpg)
2.6 分区操作算子
转换算子-mapPartitions
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第83张图片](http://img.e-com-net.com/image/info8/dea8dc42c3ee4ee7a0f39ab8fd7b0db6.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第84张图片](http://img.e-com-net.com/image/info8/dfbf33a674764a69b7055283e87ccb6b.jpg)
mapPartitions并没有节省CPU执行层面的东西,但节省了网络管道IO开销,所以他的性能比map好。
Action算子-foreachPartition
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第85张图片](http://img.e-com-net.com/image/info8/5dd4e50e23204905a841aa4f04c70774.jpg)
转换算子-partitionBy
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第86张图片](http://img.e-com-net.com/image/info8/763b870a2a8f400cba51afbc6e2e65b2.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第87张图片](http://img.e-com-net.com/image/info8/976e6e55ab3d4f11a833016e70fe2065.jpg)
转换算子-repartition
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第88张图片](http://img.e-com-net.com/image/info8/3a82ec2e579844e29f0255479d621e4f.jpg)
shuffle是有状态计算,有状态计算涉及到状态的获取,就会导致性能下降。而没有shuffle,大部分都是无状态计算,可以并行执行,效果很快。
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第89张图片](http://img.e-com-net.com/image/info8/410d5b07a0d3493a98a04038fbe4f874.jpg)
coalesce有安全机制,当增加分区但没有设置shuffle参数为True时,分区并不会增加
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第90张图片](http://img.e-com-net.com/image/info8/1ce0fdd0fa564d92b27b316e61463c2c.jpg)
repartition底层调用的是coalesce,只是参数shuffle默认设置为True
面试题:groupByKey和reduceByKey的区别
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第91张图片](http://img.e-com-net.com/image/info8/1d2200cf361d46e0848052dff64b8b21.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第92张图片](http://img.e-com-net.com/image/info8/7f6bd2bd69614fc3b00262cf510bb287.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第93张图片](http://img.e-com-net.com/image/info8/6a0ab1ab269544bd8c13a9ad12e22ec8.jpg)
2.7 第二章总结
- RDD创建有哪几种方法?
通过并行化集合的方式(本地集合转分布式集合)
或者读取数据的方式创建(TextFile\WholeTextFile)
- RDD分区数如何查看?
通过getNumPartitions API查看,返回Int
- Transformation和Action的区别?
转换算子的返回值100%是RDD,而Action算子的返回值100%不是RDD。
转换算子是懒加载的,只有遇到Action才会执行。Action就是转换算子处理链条的开关。
- 哪两个Action算子的结果不经过Driver,直接输出?
foreach和saveAsTextFile直接由Executor执行后输出,不会将结果发送到Driver上去(foreachPartition也是)
- reduceByKey和groupByKey的区别?
reduceByKey自带聚合逻辑,groupByKey不带
如果做数据聚合reduceByKey的效果更好,因为可以先聚合后shuffle再最终聚合,传输的IO小
- mapPartitions和foreachPartition的区别?
mapPartitions带有返回值,是个转换算子;foreachPartition不带返回值,是个Action算子
- 对于分区操作有什么要注意的地方?
尽量不要增加分区,可能破坏内存迭代的计算管道
第三章:RDD的持久化
3.1 RDD的数据是过程数据
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第94张图片](http://img.e-com-net.com/image/info8/280250791f014409a7bb98b3a50dd361.jpg)
3.2 RDD缓存
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第95张图片](http://img.e-com-net.com/image/info8/5195e0f2dc7047fd8ee86af624c8b478.jpg)
PS:linux下kill -9不能强制杀死spark-submit进程
参考资料:https://blog.csdn.net/intersting/article/details/84492999(原因分析)
https://blog.csdn.net/qq_41870111/article/details/126068306
https://blog.csdn.net/agonysome/article/details/125722926(如何清理僵尸进程)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第96张图片](http://img.e-com-net.com/image/info8/fdf584f4dcb14aaeb24a76588a1fe7f0.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第97张图片](http://img.e-com-net.com/image/info8/a3c3d14e26084a0da102fe8b255a0eaa.jpg)
3.3 RDD CheckPoint
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第98张图片](http://img.e-com-net.com/image/info8/1b3112a7b9554212aa8b82789912ebac.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第99张图片](http://img.e-com-net.com/image/info8/fd3489f290e84b689ea63a62e46cc903.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第100张图片](http://img.e-com-net.com/image/info8/be2125806ebc4ad1a0e93fde8f668669.jpg)
3.4 第三章总结
- Cache和Checkpoint区别
Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)
CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)
- Cache和CheckPoint的性能对比?
Cache性能更好,因为是分散存储,各个Executor并行,效率高,可以保存到内存中(占内存),更快
CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储在HDFS上更加安全(多副本)
第四章:Spark案例练习
4.1 搜索引擎日志分析案例
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第101张图片](http://img.e-com-net.com/image/info8/cd1dd3400dea41b79b014be4aa72a174.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第102张图片](http://img.e-com-net.com/image/info8/d91b86519620410a8d98e097efd10e45.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第103张图片](http://img.e-com-net.com/image/info8/d9f2aa8a38d643a4acdbd9370a1faf79.jpg)
4.2 提交到集群运行
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第104张图片](http://img.e-com-net.com/image/info8/8d1309f5587f4d85b57fd29b750677cb.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第105张图片](http://img.e-com-net.com/image/info8/ed3f347ad12845b085a27e4532c5d47c.jpg)
4.3 第四章作业和总结
作业
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第106张图片](http://img.e-com-net.com/image/info8/3db1249a158b4fe49c22b29e7b8607c7.jpg)
总结
- 案例中使用的分词库是?
jieba库
- 为什么要在全部的服务器安装jieba库?
因为YARN是集群运行,Executor可以在所有服务器上执行,所以每个服务器都需要有jieba库提供支撑
- 如何尽量提高任务计算的资源?
计算CPU核心和内存量,通过–executor-memory指定executor内存,通过–executor-cores指定executor的核心数
通过–num-executors指定总executor数量
第五章:共享变量
5.1 广播变量
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第107张图片](http://img.e-com-net.com/image/info8/5cecb4a873fe45d0a85d083e314a413e.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第108张图片](http://img.e-com-net.com/image/info8/06191c81b44d4f689ab165e0c6c5ce0f.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第109张图片](http://img.e-com-net.com/image/info8/613a60bf1f9d4aa894aa400a80cb452c.jpg)
5.2 累加器
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第110张图片](http://img.e-com-net.com/image/info8/f09a3139f79f4c7fb66efeda4e38f394.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第111张图片](http://img.e-com-net.com/image/info8/2463eceefc9a4d088d98857ee0a5fb8e.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第112张图片](http://img.e-com-net.com/image/info8/ff0237364c364bf0be92d13d16b3c2db.jpg)
5.3 广播变量累加器综合案例
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第113张图片](http://img.e-com-net.com/image/info8/19ee9345d73e40ed88d40cf19adba154.jpg)
5.4 第五章总结
- 广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络IO传输,提高性能。
- 累加器解决了什么问题?
分布式代码执行中,进行全局累加。
第六章:Spark内核调度(重点理解)
6.1 DAG
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第114张图片](http://img.e-com-net.com/image/info8/8fb8093d87f24213bfef6240ed63a78e.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第115张图片](http://img.e-com-net.com/image/info8/544c75afa46c4c59bdcabbd30aa7386e.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第116张图片](http://img.e-com-net.com/image/info8/0e33c4c30f374b34b3ccc987431d7611.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第117张图片](http://img.e-com-net.com/image/info8/b69d1f0240d84d02ac37f031777920dd.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第118张图片](http://img.e-com-net.com/image/info8/b501f18c5eda4f90b98558a101ced8f3.jpg)
6.2 DAG的宽窄依赖和阶段划分
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第119张图片](http://img.e-com-net.com/image/info8/2c67f71ee6244758a289e1389135ef05.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第120张图片](http://img.e-com-net.com/image/info8/f369e467178441a291dc5de264291e60.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第121张图片](http://img.e-com-net.com/image/info8/a323b7b9723244f885e3259efbac3bed.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第122张图片](http://img.e-com-net.com/image/info8/f29c375d031b4a2fa5a47d74db24bbe9.jpg)
6 .3 内存迭代计算
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第123张图片](http://img.e-com-net.com/image/info8/119c48303f8c468d91c708c343f0fddb.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第124张图片](http://img.e-com-net.com/image/info8/6cb88bc7e2654e55916aac5b89552b47.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第125张图片](http://img.e-com-net.com/image/info8/b4bbd8978cc94c4687f0f36426578e56.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第126张图片](http://img.e-com-net.com/image/info8/e7ca2224edc64ed89710217a003435cd.jpg)
6.4 Spark并行度
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第127张图片](http://img.e-com-net.com/image/info8/c7329985423d4173bc46a23cea078f78.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第128张图片](http://img.e-com-net.com/image/info8/feb69ce6b30247a6af88edac58d6fe58.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第129张图片](http://img.e-com-net.com/image/info8/7a7d1d5e8c344b5cb23cacabd10fc482.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第130张图片](http://img.e-com-net.com/image/info8/37fd547ab9bd45d3be1c3bfe808bb0d3.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第131张图片](http://img.e-com-net.com/image/info8/b6e8ea587d58468a870b0c282f9bac26.jpg)
6.5 Spark任务调度
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第132张图片](http://img.e-com-net.com/image/info8/241dc74760db4db6bda9ead0988cc59d.jpg)
DAG调度器
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第133张图片](http://img.e-com-net.com/image/info8/1e0ecb4473fa4f028cb3023b57aac653.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第134张图片](http://img.e-com-net.com/image/info8/1608d058726e4972a4b5e8c84f232b95.jpg)

如果一台服务器内开多个executor,会进行进程间的通信(所以建议一台服务器就开一个executor)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第135张图片](http://img.e-com-net.com/image/info8/b3e1114183294617a8defcc73fcd8d43.jpg)
Task调度器

6.6 拓展-Spark概念名称大全
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第136张图片](http://img.e-com-net.com/image/info8/0ca4c020fde042dfbbf7448e480951a6.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第137张图片](http://img.e-com-net.com/image/info8/66cb911d27684e2c94f5d8ff497b3b72.jpg)
6.7 第六章总结
- DAG是什么有什么用?
DAG有向无环图,用以描述任务执行流程,主要作用是协助DAG调度器构建Task分配用以做任务管理。
- 内存迭代/阶段划分?
基于DAG的宽窄依赖划分阶段,阶段内部都是窄依赖可以构建内存迭代的管道。
- DAG调度器是?
构建Task分配用以做任务管理。
3.SparkSQL
学习目标
- 了解SparkSQL框架模块的基础概念和发展历史
- 掌握SparkSQL DataFrame API开发
- 理解SparkSQL的运行流程
- 掌握SparkSQL和Hive的集成
第一章:SparkSQL快速入门
1.1 什么是SparkSQL

1.2 为什么要学习SparkSQL
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第138张图片](http://img.e-com-net.com/image/info8/b89e4beee4fd4707b82d26d432ed4f40.jpg)
1.3 SparkSQL特点
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第139张图片](http://img.e-com-net.com/image/info8/3f3ef26fa152481d806c6c0051997ee4.jpg)
1.4 SparkSQL发展历史
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第140张图片](http://img.e-com-net.com/image/info8/211217840ae341bd849e8a06ea3f74ae.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第141张图片](http://img.e-com-net.com/image/info8/cb1206bd29b14d3daaa0cc4fbca46afc.jpg)
1.5 第一章总结
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第142张图片](http://img.e-com-net.com/image/info8/6b049da44f6e446aa85398faeedaf427.jpg)
第二章:SparkSQL概述
2.1 SparkSQL和Hive的异同
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第143张图片](http://img.e-com-net.com/image/info8/6bdd03fadb8b4f4c8eefbcffa2b86289.jpg)
2.2 SparkSQL的数据抽象
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第144张图片](http://img.e-com-net.com/image/info8/a8d54085b05e460c9e6b28eae4cea28d.jpg)
2.3 SparkSQL数据抽象的发展
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第145张图片](http://img.e-com-net.com/image/info8/4440db07df1b454988f9b9d9e4a53620.jpg)
2.4 DataFrame数据抽象
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第146张图片](http://img.e-com-net.com/image/info8/44f07bd3241c458ba4730454495d24fa.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第147张图片](http://img.e-com-net.com/image/info8/7f9af0971fd049889b7828158d80a308.jpg)
2.5 SparkSession对象
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第148张图片](http://img.e-com-net.com/image/info8/8c6860d3fc3d4c3d9aac1e5a4d950d4a.jpg)
2.6 SparkSQL HelloWorld
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第149张图片](http://img.e-com-net.com/image/info8/d945aa2f13e748dfa411322ae542bfba.jpg)
2.7 第二章总结
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第150张图片](http://img.e-com-net.com/image/info8/66d6201a3b234bd1ab91752ef5cb2d4a.jpg)
第三章:DataFrame入门
3.1 DataFrame的组成
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第151张图片](http://img.e-com-net.com/image/info8/bdf8e6cdf30746b99ef892d818b9ca48.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第152张图片](http://img.e-com-net.com/image/info8/5e52b53724d74b5797847305d20e9ad2.jpg)
3.2 DataFrame的代码构建
基于RDD方式1-通过createDataFrame方法
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第153张图片](http://img.e-com-net.com/image/info8/c015a6d9051d414f819e37b4e766e40d.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第154张图片](http://img.e-com-net.com/image/info8/4ac806edbfa042c9a13b45d337eda087.jpg)
基于RDD方式2-通过StructType对象
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第155张图片](http://img.e-com-net.com/image/info8/f8f9c14750b44663ac319e2c243b7171.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第156张图片](http://img.e-com-net.com/image/info8/f5b45b3e86cf423194e4911f55de2d43.jpg)
基于RDD方式3-使用toDF方法
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第157张图片](http://img.e-com-net.com/image/info8/c339f44e3ce84c2f8f39d0a60b3a8916.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第158张图片](http://img.e-com-net.com/image/info8/b3cb420e2b8541d8b6c5f63ad2ee5e2f.jpg)
基于Pandas的DataFrame
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第159张图片](http://img.e-com-net.com/image/info8/d99cd89398c447839ce55d23e95e38dd.jpg)
读取外部数据
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第160张图片](http://img.e-com-net.com/image/info8/d0da917aa017405cbdcb936637e66dd4.jpg)
读取Text文件
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第161张图片](http://img.e-com-net.com/image/info8/d8914037a5f443f4927b72f0c4ce7914.jpg)
读取json文件
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第162张图片](http://img.e-com-net.com/image/info8/dbfcfbcc1a724155bf7807c29f7a4fda.jpg)
读取csv文件
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第163张图片](http://img.e-com-net.com/image/info8/e40ea6caaae744e089c580eea42b1710.jpg)
读取parquet文件
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第164张图片](http://img.e-com-net.com/image/info8/3c6e3e16a019456fa4ad5d0a89ca92d9.jpg)
3.3 DataFrame的入门操作
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第165张图片](http://img.e-com-net.com/image/info8/8295e0bc052846429c36897bc3853a72.jpg)
DSL风格
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第166张图片](http://img.e-com-net.com/image/info8/4883e7277346437693c031147c14b49f.jpg)
SQL风格
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第167张图片](http://img.e-com-net.com/image/info8/0eea7b1c15b34d5490de128aa37e0617.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第168张图片](http://img.e-com-net.com/image/info8/d58e4b899de04fb8ac33805be37e9758.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第169张图片](http://img.e-com-net.com/image/info8/7b4bf90b39b04ee7a0eedda929039275.jpg)
3.4 词频统计案例
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第170张图片](http://img.e-com-net.com/image/info8/488eda3e968a47ff9b711b1ff30d7f34.jpg)
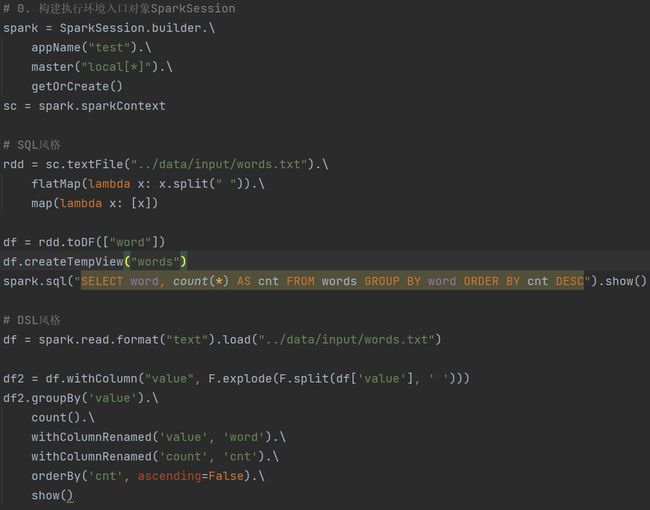
3.5 电影数据分析
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第171张图片](http://img.e-com-net.com/image/info8/d5314d1d6c1b4758b7f66168c75e4e8f.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第172张图片](http://img.e-com-net.com/image/info8/86286939803440c980ffdaa4fad483b4.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第173张图片](http://img.e-com-net.com/image/info8/b0acbe2ae4ce4d97befac1eef66bd791.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第174张图片](http://img.e-com-net.com/image/info8/236ac960917b4d42964b67a52b0b374e.jpg)
遇到问题:
1.dataframe对象经过多次.之后,IDE无法自动补全得到withColumnRenamed方法?
仍未解决。
其他解决方案:使用AI代码补全插件
2.需要安装pytest模块
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第175张图片](http://img.e-com-net.com/image/info8/dec040a0ac79447995edb08f6ce62183.jpg)
解决方案:在虚拟环境中安装pytest
3.6 SparkSQL Shuffle 分区数目
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第176张图片](http://img.e-com-net.com/image/info8/633bee8a86bd46128569c45e656ed7c2.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第177张图片](http://img.e-com-net.com/image/info8/c7fb6f41882c4d6ba0f8eb503b4a8f39.jpg)
可以看出,速度变快了
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第178张图片](http://img.e-com-net.com/image/info8/c6f18a11a4ef47e59d1f3307a2580c0b.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第179张图片](http://img.e-com-net.com/image/info8/df784ee7c56c4caeb671ddc31e949401.jpg)
3.7 SparkSQL 数据清洗API
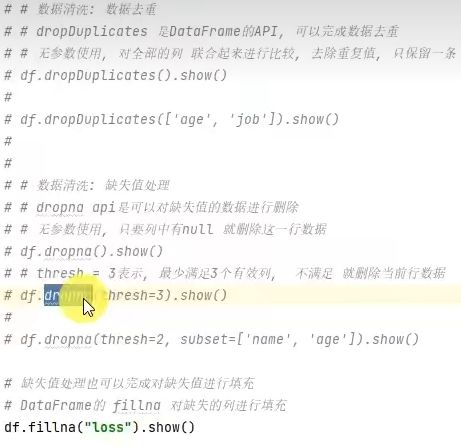
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第180张图片](http://img.e-com-net.com/image/info8/e0bb1746584a440abc8e016cd67314a5.jpg)
3.8 DataFrame数据写出
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第181张图片](http://img.e-com-net.com/image/info8/2c69a8a44b8947bc80dc675ca4cc1e5f.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第182张图片](http://img.e-com-net.com/image/info8/9677d7319dcd4198b59ff3729c8b9272.jpg)
3.9 DataFrame通过JDBC读写数据库(MySQL示例)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第183张图片](http://img.e-com-net.com/image/info8/175244e493ee4f319521b9fb49112d50.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第184张图片](http://img.e-com-net.com/image/info8/faff3cb6c1744008b86928029ab403d5.jpg)
3.10 第三章总结
- DataFrame在结构层面上由StructField组成列描述,由StructType构造表描述。在数据层面上,Column对象记录列数据,Row对象记录行数据。
- DataFrame可以从RDD转换、Pandas DF转换、读取文件、读取JDBC等方法构建
- spark.read.format()和df.write.format()是DataFrame读取和写出的统一化标准API
- SParkSQL默认在Shuffle阶段200个分区,可以修改参数获得最好性能
- dropDuplicates可以去重,dropna可以删除缺失值、fillna可以填充缺失值
- SparkSQL支持JDBC读写,可用标准API对数据库进行读写操作
第四章:SparkSQL函数定义
4.1 SparkSQL定义UDF函数
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第185张图片](http://img.e-com-net.com/image/info8/c859e747d99a402db1606de78733bb34.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第186张图片](http://img.e-com-net.com/image/info8/53d8bc289b8344d2ae2b474ddc0a4919.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第187张图片](http://img.e-com-net.com/image/info8/a4011e819ad84baf99fa2310e523914d.jpg)
sparksession.udf.register()
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第188张图片](http://img.e-com-net.com/image/info8/9d26a70f3cec480498db5029b723dfe4.jpg)
pyspark.sql.functions.udf

注册一个ArraryType返回类型的UDF
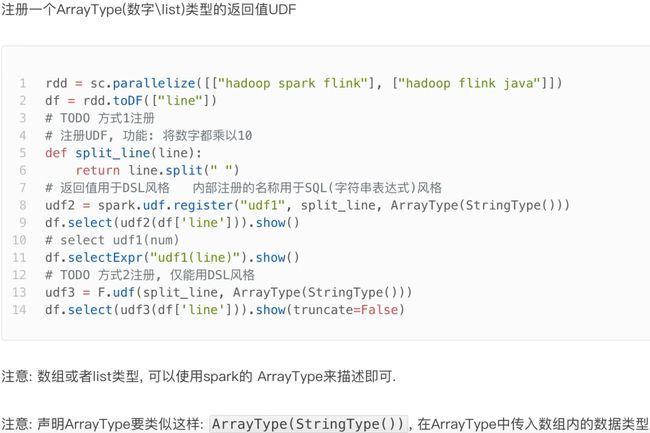
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第189张图片](http://img.e-com-net.com/image/info8/435d3cb1332e4969b3884f08cbe129e3.jpg)
注册一个字典返回类型的UDF
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第190张图片](http://img.e-com-net.com/image/info8/d74bd0850bdf437e8ed2a88cf2b934f6.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第191张图片](http://img.e-com-net.com/image/info8/ee194287595e42aa80dcc4f275db0dc5.jpg)
拓展-通过RDD代码模拟UDAF效果
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第192张图片](http://img.e-com-net.com/image/info8/46d43342c9c34d2b9d07821c366b78d5.jpg)
4.2 SparkSQL使用窗口函数
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第193张图片](http://img.e-com-net.com/image/info8/38fc8312d21947969848051e0d799d67.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第194张图片](http://img.e-com-net.com/image/info8/41d79e3cad7c4003b55059c603e5faa3.jpg)
4.3 第四章总结
- SparkSQL支持UDF和UDAF定义,但在Python中,暂时只能定义UDF
UDAF可以通过rdd的mapPartitions算子模拟实现
UDTF可以通过返回array或者dict类型来模拟实现
- UDF定义支持2种方式,1:使用SparkSession对象构建。2:使用functions包种提供的UDF API构建。要注意,方式1可用DSL和SQL风格,方式2仅可用DSL风格
- SparkSQL支持窗口函数使用,常用SQL中的窗口函数均支持,如聚合窗口\排序窗口\NTILE分组窗口等
第五章:SparkSQL的运行流程
5.1 SparkRDD的执行流程回顾
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第195张图片](http://img.e-com-net.com/image/info8/433c88ab064a49bd8de113086326eba0.jpg)
5.2 SparkSQL的自动优化
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第196张图片](http://img.e-com-net.com/image/info8/7ec0586e18e64981a8ffebea06194f07.jpg)
5.3 Catalyst优化器
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第197张图片](http://img.e-com-net.com/image/info8/f97d6970c56e47f9932981fa07d6ff52.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第198张图片](http://img.e-com-net.com/image/info8/dc322dc969a84e2ea5eea9fcae998fe9.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第199张图片](http://img.e-com-net.com/image/info8/e7e4423a6f4043f29c1b2a592a4b8560.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第200张图片](http://img.e-com-net.com/image/info8/30a4b7d88c1c4b1ca577fbe77993aa50.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第201张图片](http://img.e-com-net.com/image/info8/bd48bf72f9d54b77bc54674cf501b54e.jpg)
5.4 SparkSQL的执行流程
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第202张图片](http://img.e-com-net.com/image/info8/e418a0f0e1154ae4ba1411c44fbdd089.jpg)
5.5 第五章总结
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第203张图片](http://img.e-com-net.com/image/info8/d82fbe648d6e40459fe69b3dc642d214.jpg)
第六章:Spark On Hive
6.1 原理
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第204张图片](http://img.e-com-net.com/image/info8/34eb249a8dc84c1a9d947a18534a62f5.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第205张图片](http://img.e-com-net.com/image/info8/0c0815413aa94402a9b6095c85805ffd.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第206张图片](http://img.e-com-net.com/image/info8/a1279b6fad254d6b807d1c5fe10c4f94.jpg)
6.2 配置
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第207张图片](http://img.e-com-net.com/image/info8/beb4714a2ba4404c98f3de5fc9159450.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第208张图片](http://img.e-com-net.com/image/info8/aef6bcaeebc04a33a42d09b0486ce001.jpg)
nohup /export/server/hive/bin/hive --service metastore 2>&1 >> /export/server/hive/metastore.log &
PS:2>&1的含义:将标准错误输出重定向到标准输出。
https://blog.csdn.net/icanlove/article/details/38018169
6.3 在代码中集成
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第209张图片](http://img.e-com-net.com/image/info8/ca3db86540524a8a90e133e04d35656f.jpg)
6.4 第六章总结
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第210张图片](http://img.e-com-net.com/image/info8/50b169a8bbda46f096c93ebae37eded9.jpg)
第七章:分布式SQL执行引擎
7.1 概念
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第211张图片](http://img.e-com-net.com/image/info8/35c9565dc7214df7ae0d293b5b2b02a3.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第212张图片](http://img.e-com-net.com/image/info8/3616b1cbd45c4b60825c745aa603465e.jpg)
7.2 客户端工具连接
配置
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第213张图片](http://img.e-com-net.com/image/info8/57485b7f4f8f4364ae919713e2485371.jpg)
数据库工具连接ThriftServer
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第214张图片](http://img.e-com-net.com/image/info8/484e758f5a184aaca72ff57d1ec52091.jpg)
7.3 代码JDBC连接
Pycharm软件连接ThriftServer
通过yum命令安装依赖
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make gcc-c++ python-devel cyrus-sasl-devel cyrus-sasl-devel cyrus-sasl-plain cyrus-sasl-gssapi -y
切换到pyspark虚拟环境,通过pip命令安装
pip install pyhive pymysql sasl thrift thrift_sasl
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第215张图片](http://img.e-com-net.com/image/info8/417ae38b4faa46f7b93812612fdf1dea.jpg)
7.4 第七章总结
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第216张图片](http://img.e-com-net.com/image/info8/110dc1ffc1d34eb3a8ff8b2eaaf3aa86.jpg)
4.Spark综合案例
需求分析
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第217张图片](http://img.e-com-net.com/image/info8/46eb7f6183554ad88c272be75585443f.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第218张图片](http://img.e-com-net.com/image/info8/ed87e8f9b6054c2ea6702e57a2da6183.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第219张图片](http://img.e-com-net.com/image/info8/acd4f41d12de413294953188fe409010.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第220张图片](http://img.e-com-net.com/image/info8/f6604bd5dca3414fa4fe27da65cbe160.jpg)
需求1:
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第221张图片](http://img.e-com-net.com/image/info8/92637efa54f54704b06823d8c82bc56c.jpg)
PS:
遇到问题:
![]()
解决方案:https://blog.csdn.net/debimeng/article/details/113101894
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第222张图片](http://img.e-com-net.com/image/info8/e9a9bddf74af484f8311442dc8646ba2.jpg)
# 1.查看数据库和表的编码
SHOW CREATE DATABASE mydb;
# 2.修改数据库和表的编码
ALTER DATABASE mydb DEFAULT CHARACTER SET utf8;
3.检查数据库和表的编码
SHOW CREATE DATABASE mydb;
需求2:
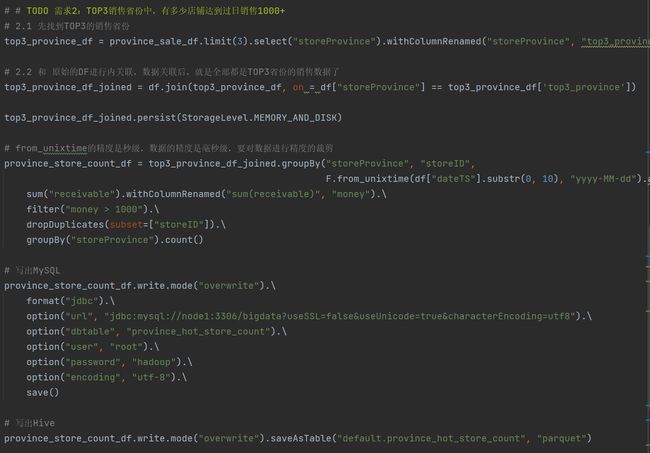
需求3:
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第223张图片](http://img.e-com-net.com/image/info8/ebdf15faafc9423ba0e1da81c8b880e5.jpg)
需求4:
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第224张图片](http://img.e-com-net.com/image/info8/81d43003aaf0464f9546a9aecbf2132a.jpg)
5.Spark新特性+核心回顾
学习目标
- 掌握Spark的Shuffle流程
- 掌握Spark3.0新特性
- 理解并复习Spark的核心概念
第一章:Spark Shuffle
1.1 Spark Shuffle
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第225张图片](http://img.e-com-net.com/image/info8/855a69fa3ddd45a4bac9c08c824fbe60.jpg)
1.2 HashShuffleManager
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第226张图片](http://img.e-com-net.com/image/info8/1cc7121acbc345ae994b9fc3d6f349eb.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第227张图片](http://img.e-com-net.com/image/info8/cf1f52afef14413ca796e6c71a5822a0.jpg)
1.3 SortShuffleManager
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第228张图片](http://img.e-com-net.com/image/info8/16233e83a19746209891577377599a6d.jpg)

![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第229张图片](http://img.e-com-net.com/image/info8/c69501365ed749ceaa84c457ed7a4ee1.jpg)
1.4 第一章总结
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第230张图片](http://img.e-com-net.com/image/info8/a7979d4903ff4606867987a8b98f19cd.jpg)
第二章:Spark3.0新特性
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第231张图片](http://img.e-com-net.com/image/info8/83313586a3e94add91c121fceb681e52.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第232张图片](http://img.e-com-net.com/image/info8/2bd5d1136551458e9bebe775762544ee.jpg)
2.2 Adaptive Query Execution自适应查询(SparkSQL)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第233张图片](http://img.e-com-net.com/image/info8/11ad7692dc4c4df1b676f80e0a4dda69.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第234张图片](http://img.e-com-net.com/image/info8/5decb9a8fb4d4d29aa911017e72b146b.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第235张图片](http://img.e-com-net.com/image/info8/4bc9edb276794a819e5a2b7f82ef3de1.jpg)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第236张图片](http://img.e-com-net.com/image/info8/74e83de88d30451f94ea5897bf6ce3c0.jpg)
AQE总结
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第237张图片](http://img.e-com-net.com/image/info8/43d188eaa0144dad83e12480852a6816.jpg)
2.3 Dynamic Partition Pruning动态分区裁剪(SparkSQL)
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第238张图片](http://img.e-com-net.com/image/info8/c47fa92d17804db192e34a2e170a452e.jpg)
2.4 增强的Python API:PySpark和Koalas
![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程_第239张图片](http://img.e-com-net.com/image/info8/18c4bbbe8a6147f282e435542f22eb3d.jpg)
2.5 Koalas入门演示-Koalas DataFrame构建
略