力扣高频|算法面试题汇总(二):字符串
力扣高频|算法面试题汇总(一):开始之前
力扣高频|算法面试题汇总(二):字符串
力扣高频|算法面试题汇总(三):数组
力扣高频|算法面试题汇总(四):堆、栈与队列
力扣高频|算法面试题汇总(五):链表
力扣高频|算法面试题汇总(六):哈希与映射
力扣高频|算法面试题汇总(七):树
力扣高频|算法面试题汇总(八):排序与检索
力扣高频|算法面试题汇总(九):动态规划
力扣高频|算法面试题汇总(十):图论
力扣高频|算法面试题汇总(十一):数学&位运算
力扣高频|算法面试题汇总(二):字符串
力扣链接
目录:
- 1.验证回文串
- 2.分割回文串
- 3.单词拆分
- 4.单词拆分 II
- 5.实现 Trie (前缀树)
- 6.单词搜索 II
- 7.有效的字母异位词
- 8.字符串中的第一个唯一字符
- 9.反转字符串
1.验证回文串
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
示例 1:
输入: “A man, a plan, a canal: Panama”
输出: true
示例 2:
输入: “race a car”
输出: false
思路:使用两个指针,一个从左边开始,一个从右边开始,挨着比较,需要处理的是:1.大写变小写。2. 如果不是字母或者数字,则跳过。
C++
class Solution {
public:
bool isPalindrome(string s) {
// 转换成小写字母
transform(s.begin(),s.end(), s.begin(), ::tolower);
int length = s.size();
int i = 0;
int j = length -1;
while(i < j){
// 判断是否是数字和英文字符
if(!isalnum(s[i])){//!(s[i]<='9' && s[i] >= '0' && s[i] <= 'z' && s[i] >= 'a')
++i;
continue;
}else if(!isalnum(s[j])){
--j;
continue;
}
// 转换大小写
char a = s[i];
char b = s[j];
if(a == b){
++i;
--j;
}else{
return false;
}
}
return true;
}
};
Python
class Solution:
def isPalindrome(self, s: str) -> bool:
pl = 0
pr = len(s) - 1
while pl < pr:
if not s[pl].isalnum():
pl += 1
continue
elif not s[pr].isalnum():
pr -= 1
continue
if s[pl].lower() == s[pr].lower():
pl += 1
pr -= 1
else:
return False
return True
2.分割回文串
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例:
输入: “aab”
输出:
[
[“aa”,“b”],
[“a”,“a”,“b”]
]
参考回溯法
总结一下:
- 1.把字符串“aab”,按长度n(n <= 字符串的长度)进行分割。
- 2.n从1开始。
- 3.start=0,n=1时,按顺序对字符串进行分割,首先得到”a“,判断满足回文要求,进行回溯,end=1。
- 4.下一次开始,start=1,得到”a“,判断满足回文要求,进行回溯,end=2。
- 5.下一次开始,start=2,得到”b“,判断满足回文要求,进行回溯,end=3。
- 6.下一次开始,start=3,已经>=字符串的长度(3),得到分割结果,进行保存,结束回溯,return到上次回溯的的地方,即start=2,然后把res中保存的最后一个结果弹出,此时res中为[“a”, “a”],并依次回溯到start=0,end=1的地方,此时res中的元素已经全部弹出,为空。
- 7.进行下一次for循环,end=2,即分割长度为2,依次进行判断…
C++
class Solution {
public:
// 保存所有的分割结果:
vector<vector<string>> split_results;
vector<vector<string>> partition(string s) {
if(s.size() == 0)
return split_results;
// 单次分割成回文串的结果
vector<string> res;
// 使用回溯法进行结果查找
back(s, 0, res); // s: 完整的字符串, 0: 开始的位置, res: 单次分割的结果
return split_results;
}
void back(string s, int start, vector<string> res){
// 首先判断回溯停止条件
if( start >= s.size()){
// 保存单次分割结果
split_results.push_back(res);
return ;
}
for(int end = start + 1; end < s.size() + 1; ++end){
// 截取字符串
string split_s = s.substr(start, end - start);
// 回文串判断
if (isPalindrome(split_s)){
// 添加当前符合要求的字符串
res.push_back(split_s);
// 回溯
back(s, end, res);
// 弹出栈顶
res.pop_back();
}
}
}
// 是否是回文串判断
bool isPalindrome(string s){
if(s.size() == 0)
return false;
int start = 0;
int end = s.size() -1;
while( start < end){
if(s[start] == s[end]){
++start;
--end;
}else{
return false;
}
}
return true;
}
};
Python
class Solution:
# def partition(self, s: str) -> List[List[str]]:
def partition(self, s):
# 保存分割下来的结果
self.split_results = []
if len(s) == 0:
return self.split_results
# 单次分割的结果
res = []
# 回溯法进行查找
self.back(s, 0, res) # s: 需要分割的字符串 0:起点位置 res:单次分割的结果
return self.split_results
# 回溯法
def back(self, s, start, res):
# 回溯的截止条件
if start >= len(s):
# 一次回溯结束
# 对res进行拷贝,防止弹出时,split_results数据变化
resCopy = res.copy()
self.split_results.append(resCopy)
return
# 以start开始,截取字符串进行判断
# end + 1是为 star > len(s) 创造结束条件
for end in range(start + 1, len(s) + 1):
# 截取字符串
split_s = s[start: end]
# 回文判断
if s[start: end] == split_s[::-1]: # 逆转字符串
# 是回文串,则继续对 end 后面的字符串进行判断
# 首先保存单词结果
res.append(split_s)
self.back(s, end, res)
# 回溯完 弹出最后一个元素
res.pop()
3.单词拆分
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
示例 1:
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以被拆分成 “leet code”。
示例 2:
输入: s = “applepenapple”, wordDict = [“apple”, “pen”]
输出: true
解释: 返回 true 因为 “applepenapple” 可以被拆分成 “apple pen apple”。
注意你可以重复使用字典中的单词。
示例 3:
输入: s = “catsandog”, wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出: false
亲测使用暴力法会超时,即把字符串分成两个部分,分别判断能否被拆分,依次遍历。
参考思路
总结:
1.本题判断是的字符串能否有单词字典中的值组成,不需要判断如何组成。
2.基本思路是把整个字符串挨个拆分,但是拆分过的字符串就已经判断过能否被拆分,则不需要再重复判断,暴力法会重复判断导致超时。
3.根据第2点,可以创建一个数组isBreak,来保存整个数组能否被拆分,但注意的是isBreak的长度是是字符串s的长度+1。
4.解释第3点,当判断字符串索引为i的位置时(即得到从0开始到位置i的字符串),即只需要判断在i之前所有能被分割的位置j到i的子字符串能否被分割,C++写法:s.substr(j, i-j),Python写法:s[j: i],这两种写法都是左闭右开,所以需要默认isBreak[0] = true,以及isBreak的长度必须是字符串s的长度+1。
C++:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
// 暴力拆分会超时
// 只需要关系能否被分割,不需要关心怎么被分割
// 从头开始遍历判断,记录每个位置是否能被分割。
// 只需要判断从i之前所有可以被切分的位置j到i的子串能否在字典中找到即可
int length = s.size();
if(length == 0)
return false;
// 用一个变量记录位置i能否被分割
vector<bool> isBreak(length + 1, false);
// isBreak表示从0开始,相隔n的字符串能否被分割
// 这是要和s.substr(j, i - j)含义对应起来, 分割从j开始的i-j的字符串
isBreak[0] = true;// id = 0 空字符串默认为true
for(int i = 1; i <= length; ++i){
for(int j = 0; j< i; ++j){
if(isBreak[j] && find(wordDict.begin(), wordDict.end(), s.substr(j, i - j)) != wordDict.end())
isBreak[i] = true; // 当i之前所有可以被切分的位置j开始,切割子字符串,能找到,则isBreak[i] = true
}
}
// 要判断整个字符串能不能被分割,返回最后一个判断即可
return isBreak[length];
}
};
Python:
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
length = len(s)
if length == 0:
return False
isBreak = [False] * (length + 1)
isBreak[0] = True
for i in range(1, length + 1):
for j in range(0, i):
if (isBreak[j] == True) and ( s[j: i] in wordDict):
isBreak[i] = True
return isBreak[length]
4.单词拆分 II
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
说明:
分隔时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
示例 1:
输入:
s = “catsanddog”
wordDict = [“cat”, “cats”, “and”, “sand”, “dog”]
输出:
[
“cats and dog”,
“cat sand dog”
]
示例 2:
输入:
s = “pineapplepenapple”
wordDict = [“apple”, “pen”, “applepen”, “pine”, “pineapple”]
输出:
[
“pine apple pen apple”,
“pineapple pen apple”,
“pine applepen apple”
]
解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:
s = “catsandog”
wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出:
[]
我首先尝试了一下回溯法,成功超时。。
class Solution {
public:
vector<string> results;
vector<string> wordBreak(string s, vector<string>& wordDict) {
int length = s.size();
vector<string> result;
// 使用回溯法进行记录
// s:完整的字符串 result: 单次处理的结果 0:开始的位置 wordDict:单词字典
back(s , result, 0, wordDict);
return results;
}
void back(string s, vector<string> result, int start, vector<string>& wordDict){
int length = s.size();
// 边界条件
if( start >= length){
// 对结果进行处理
string res;
for(auto itear = result.begin(); itear != result.end(); ++itear)
if( itear != result.end() - 1)
res += *itear + " ";
else
res += *itear;
// 添加答案
results.push_back(res);
return ; //结束
}
for(int end = start + 1; end < length + 1; ++end){
// 判断能否被分割
if( find(wordDict.begin(), wordDict.end(), s.substr(start, end - start))!=wordDict.end()){// 能被分割
result.push_back( s.substr(start, end - start)); // 添加到结果中
// 回溯
back(s, result, end, wordDict);
result.pop_back();
}
}
}
};
思路一:
使用带记忆的回溯法。
在之前的方法中,可以看出许多子问题的求解都是冗余的,造成了大量的重复计算。
为了避免这种情况,使用一个哈希表[ k e y : v a l u e key:value key:value]来表示结果。其中 k e y key key是子字符串, v a l u e value value则是所有分割句子的结果。使用的回溯函数为:vector,表示字符串s使用单词字典wordDict分割句子的结果
整体流程:
- 1.首先在字符串
s中查找单词字典的结果,如果找到了,则切割该字符串,并对剩下的子字符串s.substr(word.size()) , wordDict继续进行查找。 - 2.一直查找,直到把字符串切割为空
"",则开始回溯:if(s.empty()) return {""};和vector。temp = back(s.substr(word.size()) , wordDict); - 3.比如输入
s="catsand",字典wordDict={"cat","cats","sand","and"}。第一次查找时,发现"cat"在字符串中,切割字符串之后s="sand",继续查找,发现"sand"在字符串中,切割字符串之后s="",继续查找,达到边界条件:if(s.empty()) return {""};,回溯:vector,此时temp = back(s.substr(word.size()) temp="",通过result.push_back(word+(tmp.empty()?"":" "+tmp));把回溯结果放在result中,此时result=" sand"。依次回溯到查找到"cat"结果中,此时result="cat sand"。根据for(auto word : wordDict)得指完成"cat"为首的切割之后,查找下个单词字典"cats"是否在字符串s中,依此类推。 - 4.其中
if(hashWords.count(s)) return hashWords[s];// 如果有则返回结果可以省去重新分割的结果,大量节省时间。
C++
class Solution {
public:
vector<string> results;
// 构造哈希表,存储当字符串为s时,可以分割的结果
map<string, vector<string>> hashWords;
vector<string> wordBreak(string s, vector<string>& wordDict) {
int length = s.size();
vector<string> result;
// 使用回溯法进行记录
// s:字符串 wordDict:单词字典
// 返回值:s字符串所有分割成句子的结果
return back(s , wordDict);
}
vector<string> back(string s, vector<string>& wordDict){
// 首先判断哈希表中有没有字符串s分割的结果,避免重复计算
if(hashWords.count(s)) return hashWords[s];// 如果有则返回结果
// 边界条件,s为空
if(s.empty()) return {""};
// 使用result来保存字符串s分割的所有结果
vector<string> result;
// 按个使用单词字典对字符串进行判断
for(auto word : wordDict){
// 如果当前字符串s(从左往右找,避免重复查找)找到对应的单词:
if(s.substr(0, word.size()) == word){
// 找到了,则进行回溯继续查找
vector<string> temp = back(s.substr(word.size()) , wordDict);
for(auto tmp : temp){
result.push_back(word+(tmp.empty()?"":" "+tmp));
}
}else{
continue;
}
}
hashWords[s] = result;
return hashWords[s];
}
};
Python:
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> List[str]:
# 哈希表 字典
self.hashWords = {}
length = len(s)
if length == 0:
return [""]
# 回溯查找
return self.back(s, wordDict)
def back(self, s, wordDict):
# 首先查找哈希表,判断有无结果
if s in self.hashWords:
return self.hashWords[s]
if len(s) == 0:
return [""]
results = []
for i in range(len(s) + 1):
if s[:i] in wordDict:
temp = self.back(s[i:], wordDict)
for tmp in temp:
results.append(s[:i] +("" if len(tmp)== 0 else " ") +tmp)
self.hashWords[s] = results
return self.hashWords[s]
思路二:
动态规划,暂时不会,等会了再补上。
5.实现 Trie (前缀树)
实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。
示例:
Trie trie = new Trie();
trie.insert(“apple”);
trie.search(“apple”); // 返回 true
trie.search(“app”); // 返回 false
trie.startsWith(“app”); // 返回 true
trie.insert(“app”);
trie.search(“app”); // 返回 true
说明:
你可以假设所有的输入都是由小写字母 a-z 构成的。
保证所有输入均为非空字符串。
参考这篇的思路:
1.构建类似于链表的结构,一个根节点有26个分支(对应26个小写字母)。
2.插入的时候,在对应位置进行插入,位置索引为:a-'a',全部插入完之后,给一个标志表明是单词:isWord = true
3.寻找的时候,首先判断该索引位置是否为NULL,如果不是则继续搜索,否则返回false,只是需要判断isWord的值。
4.查询开头和寻找单词基本一致。
C++
// 新建一个数据集结果,表示树的结点
class TrieNode{
public:
// 26个小写字母 所以有26个分支
TrieNode * children[26];
bool isWord; // 表示是否是一个单词
// 构造函数
TrieNode() : isWord(false){
for (auto &child : children) child = NULL;
}
};
class Trie {
public:
/** Initialize your data structure here. */
Trie() {
// 根结点
root = new TrieNode();
}
/** Inserts a word into the trie. */
void insert(string word) {
TrieNode* p = root;
for(auto a : word){
int i = a - 'a';
// 如果不存在做个前缀,则新建一个
if(!p->children[i])
p->children[i] = new TrieNode();
// 移动位置
p = p->children[i];
}
// 标记
p->isWord = true;
}
/** Returns if the word is in the trie. */
bool search(string word) {
TrieNode* p = root;
// 遍历word
for(auto a: word){
int i = a - 'a';
// 如果不存在做个前缀
if(!p->children[i]) return false;
// 移动位置
p = p->children[i];
}
// 成功遍历完之后
return p->isWord; // 比如单词有apple ,但搜索app,app不是单词
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
TrieNode* p = root;
// 遍历word
for(auto a: prefix){
int i = a - 'a';
// 如果不存在做个前缀
if(!p->children[i]) return false;
// 移动位置
p = p->children[i];
}
// 成功遍历完之后
return true;
}
private:
TrieNode* root;
};
/**
* Your Trie object will be instantiated and called as such:
* Trie* obj = new Trie();
* obj->insert(word);
* bool param_2 = obj->search(word);
* bool param_3 = obj->startsWith(prefix);
*/
Python
class TrieNode:
def __init__(self):
self.isWord = False
self.children = [None]*26
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = TrieNode()
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
p = self.root
for a in word:
# 需要转换成ascii码
index = ord(a) - ord('a')
if p.children[index] == None:
# 新建结点
p.children[index] = TrieNode()
# 跳转链接
p = p.children[index]
# 全部插值完毕 修改flag
p.isWord = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
p = self.root
for a in word:
index = ord(a) - ord('a')
if p.children[index] == None:
return False
p = p.children[index]
return p.isWord
def startsWith(self, prefix: str) -> bool:
"""
Returns if there is any word in the trie that starts with the given prefix.
"""
p = self.root
for a in prefix:
index = ord(a) - ord('a')
if p.children[index] == None:
return False
p = p.children[index]
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
6.单词搜索 II
给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例:
输入:
words = [“oath”,“pea”,“eat”,“rain”] and board =
[
[‘o’,‘a’,‘a’,‘n’],
[‘e’,‘t’,‘a’,‘e’],
[‘i’,‘h’,‘k’,‘r’],
[‘i’,‘f’,‘l’,‘v’]
]
输出: [“eat”,“oath”]
说明:
你可以假设所有输入都由小写字母 a-z 组成。
提示:
你需要优化回溯算法以通过更大数据量的测试。你能否早点停止回溯?
如果当前单词不存在于所有单词的前缀中,则可以立即停止回溯。什么样的数据结构可以有效地执行这样的操作?散列表是否可行?为什么? 前缀树如何?如果你想学习如何实现一个基本的前缀树,请先查看这个问题: 实现Trie(前缀树)。
参考力扣官方实现
使用的是带前缀树的回溯。
为了更好地理解回溯过程,在下面的动画中演示如何在 Trie 中找到 dog,来自力扣官方。
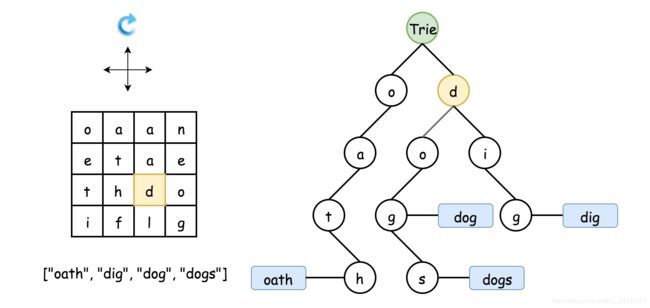
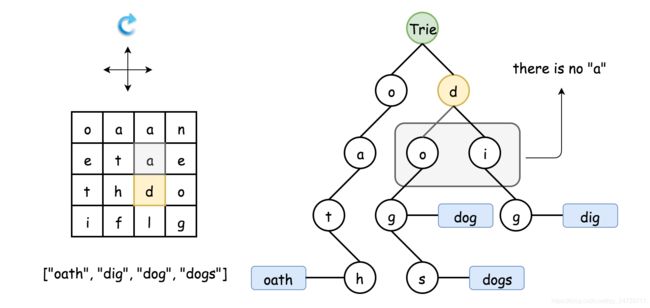
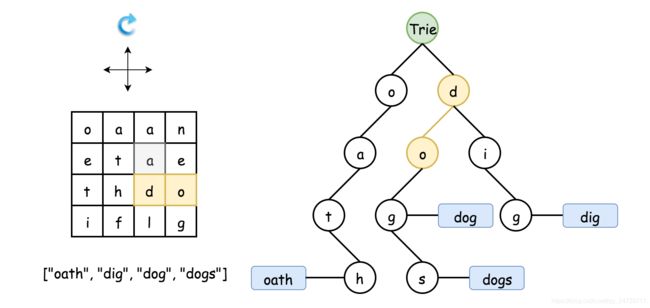


优化:
- 沿着 Trie 的节点回溯。
可以简单地使用 Trie 作为字典来快速找到单词和前缀的匹配,即在回溯的每一步,我们都从Trie 的根开始。 - 在回溯过程中逐渐剪除 Trie 中的节点(剪枝)。

Python:
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
# 在字典中记录单词
WORD_KEY = '$'
# 构建前缀树方便遍历
Trie = {}
# 遍历单词字典,建立前缀树
for word in words:
# 遍历单词
node = Trie
for letter in word:
# 如果没有这个前缀,则构建,返回键值,作为下个字典的前缀(键)
node = node.setdefault(letter, {})
# 遍历完单词后,在该层记录一个单词标记
node[WORD_KEY] = word
# 用来保存所有遍历查找的结果
matchWords = []
# 矩阵的行和列
rows, cols = len(board), len(board[0])
# 准备进行回溯
def back( node, rowID, colID):
# 获取当前坐标的值
letter = board[rowID][colID]
# 获取当前结点
curNode = node[letter]
# 首先考虑边界条件
# 查找当前能不能构成一个单词
wordFind = curNode.pop(WORD_KEY, False)
# 如果查找到了,放进结果中
if wordFind:
matchWords.append(wordFind)
# 标记当前结点
board[rowID][colID] = '#'
for rowOffset, colOffset in [[0,1],[1,0],[-1,0],[0,-1]]:
newRow = rowID + rowOffset
newCol = colID + colOffset
# 越界跳过
if newRow < 0 or newRow >= rows or newCol < 0 or newCol >= cols:
continue
# 已经访问跳过或者不存在前缀树的结点中
if not board[newRow][newCol] in curNode:
continue
# 遍历
back(curNode, newRow, newCol)
# 回溯
board[rowID][colID] = letter
# 优化:增量地删除Trie中匹配的叶子节点
# 访问过最后一个结点,遍历完就可以删除剪枝
if not curNode:
node.pop(letter)
# 遍历
for row in range(rows):
for col in range(cols):
# 以board[row][col]为起点遍历, 首先要判断前缀树中是否有这个jiedian
if board[row][col] in Trie:
# Tire: 前缀树 board: 矩阵 row、col:坐标
back(Trie, row, col)
return matchWords
7.有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
示例 2:
输入: s = “rat”, t = “car”
输出: false
说明:
你可以假设字符串只包含小写字母。
进阶:
如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
思路1:
比较暴力的方法,对字符串进行排序,再挨个比较。
C++
class Solution {
public:
bool isAnagram(string s, string t) {
int lenS = s.length();
int lenT = t.length();
if(lenS != lenT){
return false;
}
sort(s.begin(), s.end());
sort(t.begin(), t.end());
for(int i = 0; i < lenS; ++i){
if(s[i] != t[i])
return false;
}
return true;
}
};
Python:
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
return sorted(s) == sorted(t)
思路2:
使用哈希表,统计字符串s和t中各个字符出现的次数,使用一个哈希表足够,第一次遍历s统计各字符次数。第二次遍历t,减去各字符出现的次数,最后再统计哈希表是否都为0。
C++
class Solution {
public:
bool isAnagram(string s, string t) {
int lenS = s.length();
int lenT = t.length();
if(lenS != lenT){
return false;
}
map<char, int> idCount;
for(int i = 0; i < lenS; ++i){
++idCount[s[i]];
--idCount[t[i]];
}
for(auto itear = idCount.begin(); itear != idCount.end(); ++itear){
if(itear->second != 0)
return false;
}
return true;
}
};
Python:
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
idHash = {}
for i in range(len(s)):
# 字符第一次出现
if not s[i] in idHash:
idHash[s[i]] = 1
else :
idHash[s[i]] += 1
if not t[i] in idHash:
idHash[t[i]] = -1
else :
idHash[t[i]] -= 1
for value in idHash.values():
if value != 0:
return False
return True
8.字符串中的第一个唯一字符
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
案例:
s = “leetcode”
返回 0.
s = “loveleetcode”,
返回 2.
注意事项:您可以假定该字符串只包含小写字母。
思路:
构建哈希表,第一次遍历,统计每个字符出现的次数,第二次遍历,找到只出现一次的字符。
C++
class Solution {
public:
int firstUniqChar(string s) {
map<char, int> idHash;
for(int i = 0; i < s.length(); ++i){
// 字符第一次找到
if( idHash.find(s[i]) == idHash.end())
idHash[s[i]] = 1;
else
--idHash[s[i]];
}
// 第二次遍历,找到第一个哈希表值为1的字符
for(int i = 0; i < s.length(); ++i){
if(idHash[s[i]] == 1)
return i;
}
return -1;
}
};
Python:
class Solution:
def firstUniqChar(self, s: str) -> int:
idHash = {}
for i in range(len(s)):
# 第一次遇到字符
if not s[i] in idHash:
idHash[s[i]] = 1
else:
idHash[s[i]] -= 1
for i in range(len(s)):
if idHash[s[i]] == 1:
return i
return -1
9.反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
示例 1:
输入:[“h”,“e”,“l”,“l”,“o”]
输出:[“o”,“l”,“l”,“e”,“h”]
示例 2:
输入:[“H”,“a”,“n”,“n”,“a”,“h”]
输出:[“h”,“a”,“n”,“n”,“a”,“H”]
思路:使用两个指针,分别指向字符串的开始和结尾,使用中间变量temp完成前后字符交换。
C++
class Solution {
public:
void reverseString(vector<char>& s) {
int pStart = 0;
int pEnd = s.size()-1;
char temp;
while(pStart < pEnd){
temp = s[pStart];
s[pStart] = s[pEnd];
s[pEnd] = temp;
++pStart;
--pEnd;
}
}
};
Python
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
pStart = 0
pEnd = len(s) - 1
while pStart < pEnd:
s[pStart], s[pEnd] = s[pEnd], s[pStart]
pStart += 1
pEnd -= 1