【论文】通过基准分析优化联邦人员重新识别的性能
论文链接
目录
- 摘要
- 1. 绪论
-
- 2. 相关工作
-
- 2.1 人员重新识别
- 2.2 联邦学习
- 3. 联邦 个人REID基准
-
- 3.1 数据集
- 3.2 联合方案
- 3.3 模型结构
- 3.4 联邦学习算法
- 3.5 性能指标
- 3.6 参考实现
- 4.1 通过相机联合方案
- 4.2 按数据集联合方案
- 5. 性能优化
-
- 5.1 知识蒸馏
- 5.2 权重调整
- 5.3 知识蒸馏和体重调整
- 6. 总结
- 代码
- 个人总结
-
- 1. 人员再识别任务是什么
- 2. 文本的目的是什么
- 3. 文本基准分析是什么
- 4. 文中的知识蒸馏是如何使用的
- 5. 文中的动态权重调整是如何实现的
- 6. 相机联合方案是什么
- 7. FedAvg算法是什么
- 8. FedPav算法是什么
- 9. 算法性能评估如何实现
摘要
联邦学习是一种保护隐私的机器学习技术,可在分散的客户端之间学习共享模型。它可以减轻个人重新识别的隐私问题,这是一项重要的计算机视觉任务。在这项工作中,我们实现了联邦学习到人重新识别(FedReID),并优化了其在现实世界场景中受统计异质性影响的性能。我们首先构建一个新的基准来调查FedReID的性能。该基准测试由 (1) 九个数据集组成,这些数据集具有来自不同领域的不同卷,用于模拟现实中的异构情况,(2) 两个联合场景,以及 (3) FedReID 的增强联合算法。基准分析表明,以数据集联合场景为代表的 客户端-边-云 架构比FedReID中的客户端-服务器架构具有更好的性能。这也揭示了FedReID在现实场景下的瓶颈,包括模型聚合权重不平衡导致大型数据集性能不佳以及收敛性挑战。然后我们提出了两种优化方法:(1)针对权重不平衡问题,我们提出了一种新的方法,根据每个训练轮次中客户端的模型变化尺度动态改变权重;(2)为了促进收敛,我们采用知识蒸馏来完善服务器模型,使用公共数据集上的客户端模型生成的知识。实验结果表明,我们的策略可以在所有数据集上实现更好的收敛,并具有卓越的性能。我们相信,我们的工作将激励社区进一步探索在现实场景中在更多计算机视觉任务上实施联邦学习。
关键词: 联邦学习,人员重新识别
1. 绪论

个人数据保护意识的提高[4]限制了个人重新识别(ReID)的发展。人员重新识别是一项重要的计算机视觉任务,可匹配图像库中的同一个人[31]。人员ReID的训练依赖于集中海量的个人图像数据,对个人信息施加潜在的隐私风险,甚至导致一些国家的个人ReID研究项目暂停。因此,有必要在隐私保护的前提下驾驭其发展。

联邦学习是一种保护隐私的机器学习框架,可以使用来自摄像头的分散数据来训练一个人员 ReID 模型。由于边缘与服务器共享模型更新而不是训练数据[21],因此联邦学习可以有效降低潜在的隐私泄露风险。多媒体研究人员和从业者也可以利用这一优势来完成多媒体内容分析任务[3,28]。除了隐私保护之外,联邦学习对于人 员ReID (FedReID) 的实施还具有其他优势:通过避免海量数据上传来减少通信开销 [21];启用适用于不同场景的整体模型;在边缘获取可以适应局部场景的局部模型。社区视频监控是FedReID的一个很好的用例[7]。不同的社区合作训练一个集中式模型,而不会有视频数据离开社区。尽管联邦学习具有优势,但很少有工作研究其对人员 ReID 的实现。Hao等人[8]只提到了这种实现的可能性。具有非独立同分布(非IID)和不平衡数据量是FedReID在现实场景中面临的主要挑战之一[12]。Zhao等人[29]表明,非IID数据会显著损害联邦学习的性能,Li等人[13]表示,这导致了收敛的挑战,但很少有工作研究FedReID中的统计异质性。
这项工作旨在通过执行基准分析来优化FedReID的性能。综合实验结果,对新构建基准和所提优化方法的分析证明了其实用性和有效性。据我们所知,这是对个人 ReID 的联合学习的首次实现。我们总结本文的贡献如下:
- 构建FedReID的新基准,并进行基准分析,以调查其瓶颈和见解。我们的基准测试FedReIDBench具有以下功能:(1)使用9个具有代表性的ReID数据集(如图1所示的样本)来模拟非IID和不平衡数据的真实情况,(2)为人员ReID定义代表性的联合场景,(3)为FedReID提出合适的算法,(4)标准化模型结构和性能评估指标,以及(5)创建参考实现来定义训练过程。基准分析结果为未来对该主题的研究奠定了良好的基线。
- 我们提出了两种优化性能的方法:知识蒸馏和动态权重调整。知识蒸馏[10]解决了由非IID数据引起的收敛问题。模型聚合中的动态权重调整解决了数据集不平衡导致的性能衰减问题。
我们提出了两种优化性能的方法:知识蒸馏和动态重量调整。知识蒸馏[10]解决了由非IID数据引起的收敛问题。模型聚合中的动态权重调整解决了数据集不平衡导致的性能衰减问题。本文的其余部分组织如下。在第 2 节中,我们回顾了有关人员 ReID 和联邦学习的相关工作。第3节介绍了FedReID的基准。我们分析基准测试结果,并在第 4 节中提供见解。在本节中,本文的其余部分组织如下。在第 2 节中,我们回顾了有关人员 ReID 和联邦学习的相关工作。第3节介绍了FedReID的基准。我们分析基准测试结果,并在第 4 节中提供见解。在第 5 节中,我们提出了提高 FedReID 性能的优化方法。第6节总结了本文,并提供了未来的方向。
2. 相关工作
2.1 人员重新识别
给定查询图像,人员 ReID 系统旨在根据图像的相似性从大型库中检索具有相同标识的图像。它具有广泛的应用,例如视频监控和基于内容的视频检索[31]。与传统的手工特征算子相比,深度神经网络能够更好地提取代表性特征,从而大大提高了ReID的性能[17,19,23,26]。人员 ReID 数据集包含来自不同相机视图的图像。训练人员 ReID 模型需要集中大量这些数据,这会增加潜在的隐私风险,因为这些图像包含个人信息和标识。因此,联邦学习有利于人员 ReID 保护隐私。
2.2 联邦学习
Federated Learning Benchmark Caldas等人在[2]中提出了LEAF,这是一个专注于图像分类和一些自然语言过程任务的基准框架。罗等。AL 在 [20] 中提出了用于对象检测的真实世界图像数据集。这两项工作都采用McMahan等人提出的联邦平均(FedAvg)算法[21]作为基线实现。在这项工作中,我们引入了联邦学习和人员ReID相结合的新基准,我们报告了全面的分析,以揭示问题并为模拟的真实场景提供见解。
联邦学习中的非IID数据 联邦学习面临着非IID数据的挑战[29],这与分布式深度学习不同,分布式深度学习使用集群中的IID数据通过并行计算训练大规模深度网络[5,22]。Zhao等人[29]建议与客户共享代表全球分布的数据,以提高非IID的性能。Yao等人[27]提出了FedMeta,这是一种使用从自愿客户端获取的元数据在聚合后微调服务器模型的方法。Li等人在[13]中提供了FedProx,这是一种通过添加近端项来限制本地更新更接近全局模型来改善FedAvg收敛性的算法。我们还为ReID任务中的非IID数据导致的问题提供了两种解决方案。受数据共享策略 [29] 和 FedMeta [27] 的启发,其中一个解决方案采用知识蒸馏和额外的未标记数据集来促进融合。
3. 联邦 个人REID基准
在本节中,我们将介绍FedReIDBench,这是一个用于对个人ReID实施联邦学习的新基准。它包括 9 个数据集(第 3.1 节)、联合方案选择(第 3.2 节)、模型结构(第 3.3 节)、联合训练算法(第 3.4 节)、性能指标(第 3.5 节)和参考实现(第 3.6 节)。
3.1 数据集
为了模拟FedReID的真实场景,我们选择了9个不同的数据集,其属性如表1所示。这些数据集在图像数量、身份号码、场景(室内或室外)和相机观看次数方面存在显著差异,导致彼此之间存在巨大的域差距[18]。这些方差模拟了现实中的统计异质性。图像量的差异模拟了边缘之间数据点的不平衡,域间隙导致非IID问题。模拟的统计异质性使FedReID场景更具挑战性,更接近现实世界的情况。
3.2 联合方案
我们设计了两种不同的方法,代表了将联邦学习应用于人员 ReID 的两种真实场景(图 2)。

图 2:按相机联合方案与按数据集联合方案。(a) 表示由摄像机联合方案:摄像机与服务器协作执行联合学习。(b) 表示按数据集联合方案:边缘服务器在执行联合学习之前从多个摄像头收集数据。
相机联合方案表示标准客户端服务器体系结构。每个相机都被定义为一个单独的客户端,直接与服务器通信以执行联邦学习过程。在这种情况下,将图像保留在客户端中可显著降低隐私泄露的风险。然而,这种场景对相机训练深度模型的计算能力提出了很高的要求,这使得实际部署更加困难。现实世界中一个很好的例子是一个社区,它部署了多个摄像头来训练一个人的 ReID 模型。
按数据集联合方案表示客户端-边缘-云体系结构,其中客户端定义为边缘服务器。边缘服务器从多个摄像头构建数据集,然后与中央服务器协作进行联邦学习。实际场景可能是几个社区协作训练 ReID 模型,边缘服务器连接到每个社区中的多个摄像头。
3.3 模型结构
深度 人员 ReID 的常见基准是 ID 判别嵌入模型 (IDE) [31]。我们使用带有骨干 ResNet-50 [9] 的 IDE 模型作为我们的模型结构来执行联邦学习。但是,并非所有客户端中的模型结构都相同,其标识分类器可能不同。在第 3.2 节中介绍的两个联合方案中,客户端具有不同数量的标识,并且模型中标识分类器的维度取决于标识的数量,因此它们可能具有不同的模型结构。这种差异会影响我们在下一节(第 3.4 节)中讨论的联合算法。
3.4 联邦学习算法
在本节中,我们将介绍联邦学习的关键算法FedAvg,并概述了我们提出的FedReID联合部分平均(FedPav)方法。
联邦平均 (FedAvg) [21] 是一种标准的联邦学习算法,包括服务器和客户端上的操作:客户端使用其本地数据集训练模型并将模型更新上传到服务器;服务器负责初始化网络模型,并按加权平均值聚合来自客户端的模型更新。FedAvg 要求服务器和客户端中的模型具有相同的网络体系结构,而如第 3.3 节所述,客户端的身份分类器可能不同。因此,我们为FedReID引入了一种增强的联邦学习算法:联邦部分平均。
联合部分平均 (FedPav) 支持与具有部分不同模型的客户端进行联合训练。它在整个训练过程中与 FedAvg 类似,只是每个客户端仅将更新模型的一部分发送到服务器。图 3 描述了 FedPav 到 FedReID 的实现过程。客户端中的模型共享相同的主干,从而改变标识分类器,因此客户端仅将主干的模型参数发送到服务器进行聚合。
我们描述训练过程如下:(1)在新一轮训练开始时,服务器从N个客户端中选择K个参与训练,并将全局模型发送给客户端。(2)每个客户端将全局模型与上个训练轮次的身份分类器串联起来以形成新模型。然后,它使用随机梯度下降对本地数据进行 E 次本地时期的训练,批量大小为 B,学习率为 η。(3) 每个客户端保留分类器层并上传主干的更新模型参数。(4)服务器聚合这些模型更新,得到一个新的全局模型。我们在算法 1 中总结了 FedPav。
FedPav 旨在获得优于本地训练的模型,本地训练表示在单个数据集上训练的模型。FedPav 为每个客户端输出高质量的全局模型 w T w^T wT 和本地模型 w k T w^T_k wkT。
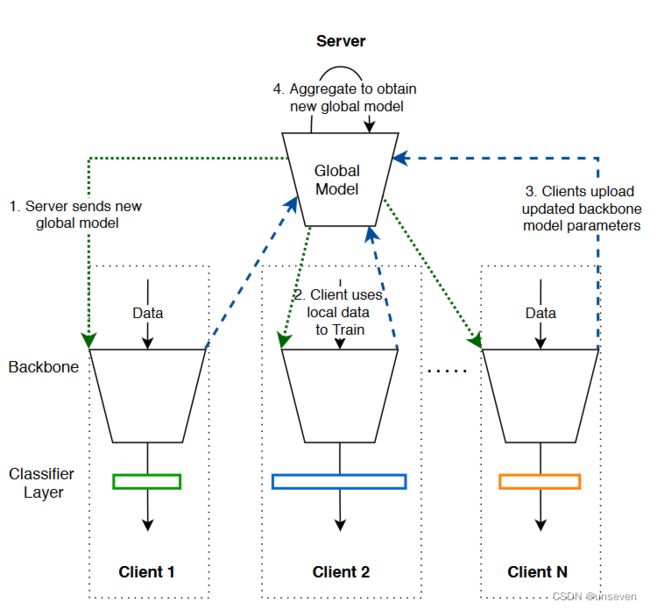
图3:插图的联合局部平均(FedPav)。全球模型是其支柱产业。每一轮的培训包括以下步骤:(1)服务器向客户发送全局模型。(2)客户使用本地数据训练分类器模型。(3)客户向服务器上传骨干参数。(4)服务器通过加权平均聚合客户端的模型更新,以获取新的全局模型。
在第4.2节中,这些模型将进行评估并与本地培训进行比较。由于ReID评估使用图像作为查询来搜索库中的类似图像,因此我们可以在评估中省略身份分类器。
3.5 性能指标
为了评估FedReID的性能,我们需要衡量算法的准确性和通信成本,因为联邦学习环境限制了通信带宽。
我们使用标准的人物ReID评估指标来评估我们算法的准确性:累积匹配特征(CMC)曲线和平均平均精度(mAP)[31]。 CMC用于对身份查询与所有图库图像的相似性进行排序; Rank-k表示图库中排名前k的图像包含查询身份的概率。我们在排名1、5和10处测量CMC。mAP计算所有查询中平均精度的平均值。
通信成本 我们用通信轮数乘以模型大小(上传和下载)的两倍来衡量通信成本。如果模型大小恒定,则较大的通信轮次会导致更高的通信成本。
3.6 参考实现
为了促进可重复性,FedReIDBench提供了一组参考实现,包括FedPav和优化方法。它还包括用于预处理 ReID 数据集的脚本。

4.1 通过相机联合方案
由于现有的 ReID 数据集包含来自多个相机的图像,因此我们考虑将每个相机作为客户端实现联邦学习。我们假设相机有足够的计算能力来训练神经网络模型。业内一些相机已经具备了这样的功能。
我们通过两个数据集来衡量相机联合场景中的性能:包含来自 6 个相机视图的训练数据的 Market-1501 [30] 数据集和包含来自 2 个相机视图的图像的 CUHK03-NP [16] 数据集。我们将Market1501数据集拆分为6个客户端,将CUHK03-NP数据集拆分为2个客户端,每个客户端包含一个摄像头视图的数据。为了与按相机联合方案的性能进行比较,我们通过将数据集拆分为多个客户端来定义按标识联合的方案,每个客户端具有来自不同相机视图的相同数量的标识。数据集联合方案中的客户端数等于相机视图数。例如,我们按身份将 Market-1501 拆分为 6 个客户端,因此每个客户端包含 125 个非重叠身份。我们还在比较中添加了本地训练。我们在同一设置下在相机联合和按身份联合的方案中实现 FedPav,并在表 2 中总结了结果。
表2:市场1501数据集和CUHK03-NP数据集上摄像头联合场景、身份联合场景和本地训练的性能对比。由摄像机联合方案的精度最低。

4.2 按数据集联合方案
在本节中,我们分析了按数据集联合场景的结果,并研究了批量大小 B 的影响、局部纪元 E 的影响、与本地训练的性能比较以及 FedPav 的收敛性。我们对 9 个客户进行了以下所有实验,每个客户在 9 个数据集中的一个上进行训练。在每一轮沟通中,我们选择了所有客户进行聚合
批量大小的影响 批量大小是 FedPav 中的一个重要超参数,它会影响客户端中的计算。在相同数量的本地 epoch 和固定大小的数据集下,较小的批量大小会导致每轮训练中客户端的计算量更高。我们在图 9 中将不同批次大小的性能与设置 E = 1 和总共 300 轮通信进行比较。随着我们通过将批大小从 128 更改为 32 来添加更多计算,大多数数据集的性能都会提高。因此,我们使用B = 32作为其他实验的默认批量大小设置。
通信成本 FedPav 中的本地纪元数表示通信成本和性能之间的权衡。图 10 比较了局部纪元数 E = 1、E = 5 和 E = 10 与 B = 32 和 300 总训练轮数的秩 1 精度。尽管在少数数据集中,E = 10 的性能优于 E = 5,但降低 E 通常会提高性能,并且在所有数据集中,E = 1 的性能大大优于 E = 5 和 E = 10。它指示了 FedReID 中性能和通信成本之间的权衡。较少的本地纪元可实现更好的性能,但会导致更高的通信成本。
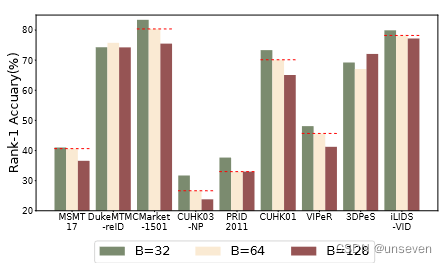 图 4:不同批次大小的性能(rank-1)比较,固定局部纪元 E = 1。批量大小 B = 32 在大多数数据集中具有最佳性能。
图 4:不同批次大小的性能(rank-1)比较,固定局部纪元 E = 1。批量大小 B = 32 在大多数数据集中具有最佳性能。
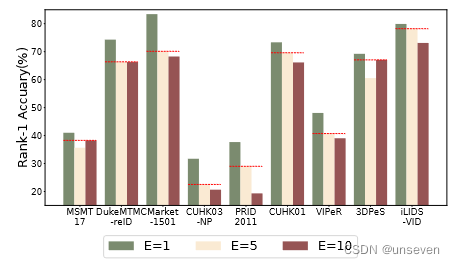 图 5:不同数量的局部 epoch 的性能比较,固定批次大小 B = 32,总训练轮数 ET = 300。局部纪元 E = 1 在所有数据集中具有最佳性能。
图 5:不同数量的局部 epoch 的性能比较,固定批次大小 B = 32,总训练轮数 ET = 300。局部纪元 E = 1 在所有数据集中具有最佳性能。
FedPav 的上限 我们将从 FedPav 算法获得的模型的性能与本地训练进行比较。根据前面的讨论,E = 1 和 B = 32 是 FedPav 算法的最佳设置。因此,我们将此设置用于 FedPav 算法。
我们在图 6 中总结了结果。尽管联合模型在大型数据集(如 MSMT17 [25] 和 Market-1501 [30])上的表现比本地训练差(图 6a),但它的性能优于在较小的数据集(如 CUHK01 [15] 和 VIPeR [6])上的本地训练(图 6b)。这些结果表明,在较小数据集上训练的模型可以更有效地从其他客户那里获得知识。有两个原因可以解释这些结果:在较大数据集上训练的模型在聚合中占主导地位,因此这些客户端从其他客户端吸收的知识较少;在小数据集上训练的模型泛化能力较弱,因此从较大的数据集中获取更多知识可以提高其能力。
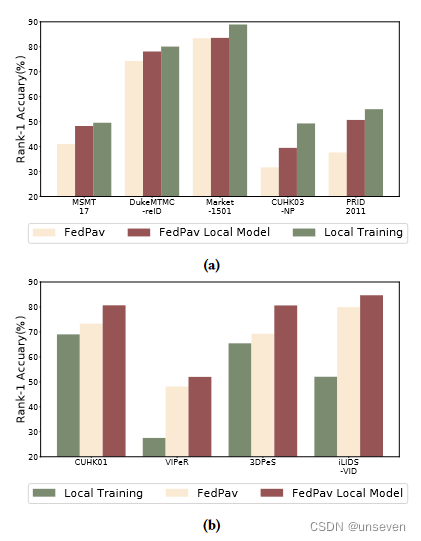
图 6:FedPav 和本地训练(单个数据集上的训练)的性能比较。尽管联合模型和本地模型在 (a) 中对大型数据集的性能都差于本地训练,但它们的性能优于 (b) 中对小型数据集的本地训练。聚合前的本地模型在所有数据集上都优于联合模型。
本地模型,即在上传到服务器之前在客户端中训练的模型,是衡量客户端 n FedReID 最佳性能的代理。服务器聚合会导致比较本地模型和图 6 中联合模型性能的所有数据集的性能下降。这表明服务器有可能更好地整合来自客户端的知识。此外,在大型数据集中,局部训练的性能优于局部模型(图6a),这表明FedPav算法存在瓶颈。
FedPav 的收敛 非 IID 数据集会影响 FedReID 训练的收敛。图 7 显示了 FedPav 在 DukeMTMC-reID [32] 和 CUHK03-NP [16] 上训练的联邦模型在 300 轮通信中的排名精度为 1,评估每 10 轮计算一次,固定 E = 1 和 B = 32。FedPav 在两个数据集上的排名 1 准确度在整个训练过程中波动。基准测试中9个数据集的非IID导致在汇总来自客户的模型时难以收敛,因为Li等人[13]指出了非IID数据的负面影响。为了更好地衡量训练性能,我们在实验中平均了来自不同时期的三个最佳联合模型的性能。
5. 性能优化
基于基准分析的见解,我们进一步研究了优化FedReID性能的方法。我们在 5.1 节中采用知识蒸馏法,在第 5.2 节中提出权重调整,并在第 5.3 节中介绍这两种方法的组合。
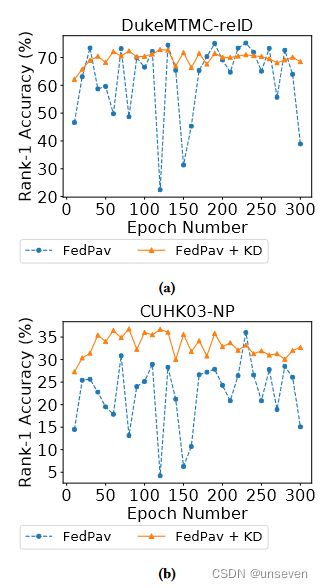
图 7:FedPav 与知识蒸馏 (KD) 的收敛性,局部纪元 E = 1,批次大小 B = 32,评估每 10 轮计算一次。(a)和(b)显示了DukeMTMC-reID和CUHK03-NP的趋同性改进。
5.1 知识蒸馏
我们将知识蒸馏应用于FedPav算法,以提高其在本节中的性能和收敛性。如第 4.2 节所述,FedPav 算法难以收敛,局部模型的性能优于联合模型。知识蒸馏(KD)[10]是一种将知识从一个模型(教师模型)转移到另一个模型(学生模型)的方法。我们采用知识蒸馏将知识从客户端转移到服务器:每个客户端都是老师,服务器是学生。
为了进行知识蒸馏,我们需要一个公共数据集来生成来自客户的软标签。我们以未标记的CUHK02 [14]数据集为例,将知识蒸馏应用于联邦学习。CUHK02 [14] 数据集扩展了 CUHK01 [15] 数据集,增加了四对相机视图。它在 7264 张图像中有 1816 个身份。
算法 2 通过知识蒸馏总结了训练过程:(1) 在训练开始时,我们将 CUHK02 [14] 数据集 D s h a r e d D_{shared} Dshared与初始化模型 w 0 w^0 w0 一起分发给所有客户端。(2) 每个客户端使用共享数据集 D s h a r e d D_{shared} Dshared在其本地数据集上训练后生成软标签 l k l_k lk。这些软标签 l k l_k lk 是包含客户端模型知识的特征。(3) 每个客户端将模型更新 w k w_k wk和软标签 l k l_k lk上传到服务器。(4) 服务器将这些软标签平均为 l = 1 k ∑ k ∈ C t l k l= \cfrac{1}{k}\sum_{k \in C_t}l_k l=k1∑k∈Ctlk (5) 服务器使用共享数据集 D s h a r e d D_{shared} Dshared和平均软标签 l l l训练联合模型 w。最后一步是微调联合模型,以减轻聚合的不稳定性,并推动聚合更好地收敛。
图 7 比较了 FedPav 和 FedPav +KD的排名 1 准确度性能与 DukeMTMC-reID [32] 数据集(图 7a)和 CUHK03-NP [16] 数据集(图 7b)。它表明,知识蒸馏降低了波动性,并有助于训练收敛。然而,知识蒸馏并不能保证性能的提高:它提高了CUHK03-NP [16]的排名1精度,而这一优势在DukeMTMC-reID [32]数据集中尚不清楚。我们认为,共享公共数据集的域分布对每个数据集上联合模型的最终性能有实质性影响。CUHK02 [14] 数据集与 CUHK03-NP [16] 数据集之间的域差距较小,因此知识蒸馏显著提升了 CUHK03-NP [16] 数据集的性能。我们在补充材料中提供了其他数据集的结果和mAP的准确性。


5.2 权重调整
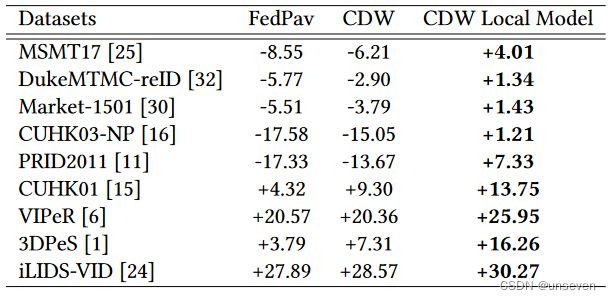
在本节中,我们提出了一种调整模型聚合权重的方法,以减轻数据集大小巨大差异带来的不平衡影响。FedPav 中的这些权重与数据集的大小成正比:具有 MSMT17 [25] 等大型数据集的客户端约占总权重的 40%,而具有 iLIDS-VID [24] 等小型数据集的客户端仅占 0.3%,这对联合模型的贡献可以忽略不计。尽管具有较大数据集的客户在聚合中具有较大的权重是合理的,但我们预计具有小型数据集和大型数据集的客户端之间的权重存在巨大差异,这会阻碍具有大型数据集的客户有效地从其他客户获取知识。因此,我们为模型聚合提出了更合适的权重。
余弦距离权重 我们提出了一种方法,余弦距离权重(CDW),根据模型的变化动态分配权重:较大的变化应该在模型聚合中贡献更多(即具有更大的权重),以便更多新学习的知识可以反映在联合模型中。我们通过余弦距离测量每个客户端k的模型变化,步骤如下:(1)客户端随机选择一批训练数据 D b a t c h D_{batch} Dbatch。(2)当客户端在新一轮训练t中从服务器接收到模型时,它使用 D b a t c h D_{batch} Dbatch和由全局模型和本地身份分类器串联形成的局部模型 ( w t k , v t k ) (w_t^k,v_t^k) (wtk,vtk)生成logits f k t f_k^t fkt。(3)客户进行训练以获得新模型 ( w k t + 1 , v k t + 1 ) (w^{t+1}_k,v^{t+1}_k) (wkt+1,vkt+1)。(4) 它生成 ( w k t + 1 , v k t + 1 ) (w^{t+1}_k,v^{t+1}_k) (wkt+1,vkt+1) 和 D b a t c h D_{batch} Dbatch 的logits f k t + 1 f^{t+1}_k fkt+1。(5) 客户端通过平均批处理中每个数据点的余弦距离来计算权重 m k t + 1 = m e a n ( 1 − c o s i n e _ s i m i l a r i t y ( f k t , f k t + 1 )) m^{t +1}_k = mean(1 − cosine\_similarity(f^t_k,f^{t+1}_k )) mkt+1=mean(1−cosine_similarity(fkt,fkt+1))。(6)客户端向服务器发送 m k t + 1 m^{t +1}_k mkt+1,服务器用它替换FedPav中的权重。我们在算法 3 中总结了这种新算法。
我们尝试FedPav余弦距离相同重量下设置如图6所示。表3显示,余弦距离在所有数据集重量显著地提高了性能。它表明,我们获得一个更全面的模型,概括了在不同的领域。FedPav的面部模型聚合之前,当地最好的本地dataset-performs精度比当地的培训(培训个人数据集的最佳精度)大型数据集。然而,当地FedPav余弦相似性体重优于模型训练数据集。它表明所有客户提供不同大小的数据集参与联合学习有益,因为他们可以获得betterquality模型与最佳模型训练当地的数据集。
表3:增加1级精度比较当地的培训。当地FedPav模型与余弦距离重量(CDW)比当地的训练数据集。
5.3 知识蒸馏和体重调整
在本节中,我们实现动态权重调整和知识FedPav蒸馏。我们的目标是实现更高的性能和更好的融合与这种组合获得的优势。
图8显示的性能了解蒸馏和余弦距离FedPav重量在两个数据集。这种组合提高了性能和训练的收敛这两个数据集。我们提供补充材料的其他数据集的结果。
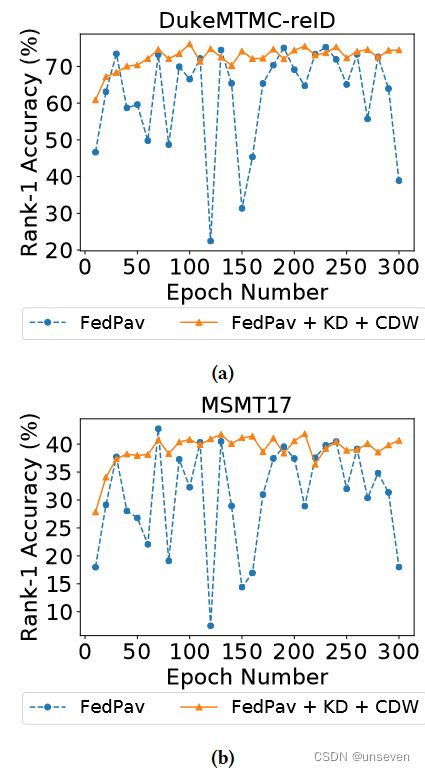
图8:性能改进(a)和(b) MSMT17运用知识蒸馏(KD)和体重(CDW) FedPav余弦距离,计算每10轮与评价。
6. 总结
在本文中,我们调查了统计学异质性的挑战实现联合学习人鉴定,通过新建基准执行基准分析的情况,模拟了真实的场景。这个基准定义联合场景和介绍学习algorithm-FedPav联合。基准分析提出瓶颈和有用的见解,为未来的研究和产业化是有益的。然后,我们提出了两种优化方法提高FedReID的性能。解决融合的挑战,我们采用蒸馏来调整服务器模型与知识生成的客户额外的公共数据集。大型数据集的提升性能,我们动态调整权重模型聚合取决于模型的规模客户的变化。数值结果表明,这些优化方法能有效促进融合,实现更好的性能。本文只关注的统计学异质性FedReID在真实的场景中。对于未来的工作,系统异构性的挑战将会考虑。
代码
他们团队实现了easyfl框架,并利用框架能实现,其中每个客户端包含一个数据集。
from django.test import TestCase
# Create your tests here.
import easyfl
import os
from torchvision import transforms
from easyfl.datasets import FederatedImageDataset
TRANSFORM_TRAIN_LIST = transforms.Compose([
transforms.Resize((256, 128), interpolation=3),
transforms.Pad(10),
transforms.RandomCrop((256, 128)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
TRANSFORM_VAL_LIST = transforms.Compose([
transforms.Resize(size=(256, 128), interpolation=3),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
DATASETS = ["MSMT17", "Duke", "Market", "cuhk03", "prid", "cuhk01", "viper", "3dpes", "ilids"]
# Prepare customized training data
def prepare_train_data(data_dir):
client_ids = []
roots = []
for db in DATASETS:
client_ids.append(db)
data_path = os.path.join(data_dir, db, "pytorch")
roots.append(os.path.join(data_path, "train_all"))
data = FederatedImageDataset(root=roots,
simulated=True,
do_simulate=False,
transform=TRANSFORM_TRAIN_LIST,
client_ids=client_ids)
return data
# Prepare customized testing data
def prepare_test_data(data_dir):
roots = []
client_ids = []
for db in DATASETS:
test_gallery = os.path.join(data_dir, db, 'pytorch', 'gallery')
test_query = os.path.join(data_dir, db, 'pytorch', 'query')
roots.extend([test_gallery, test_query])
client_ids.extend([f"{db}_gallery", f"{db}_query"])
data = FederatedImageDataset(root=roots,
simulated=True,
do_simulate=False,
transform=TRANSFORM_VAL_LIST,
client_ids=client_ids)
return data
if __name__ == '__main__':
config = {...}
data_dir = "datasets/"
train_data, test_data = prepare_train_data(data_dir), prepare_test_data(data_dir)
easyfl.register_dataset(train_data, test_data)
easyfl.init(config)
easyfl.run()
个人总结
1. 人员再识别任务是什么
人员再识别是一项计算机视觉任务,旨在从多个监控摄像头中识别出同一人员。它通常涉及到从多个摄像头中获取大量的人员图像,然后将这些图像与已知身份的图像进行比较,以确定是否为同一人员。这项任务在安全监控、人员追踪和智能交通等领域有着广泛的应用。
2. 文本的目的是什么
这篇文章主要介绍了一种名为"FedReID"的新型联邦学习框架,用于解决人员再识别(Person ReID)中的隐私保护和数据分布不均、数据不符合独立同分布等问题。
3. 文本基准分析是什么
基准分析是对于联邦学习在人员再识别任务中的性能进行评估和优化的过程。作者构建了一个新的基准来研究FedReID的性能,包括9个不同的数据集、两种联邦场景、模型结构、联邦训练算法和性能指标等。通过基准分析,作者现了FedReID在现实场景中的瓶颈,提出了优化方法,并在各个数据集上取得了更好的性能。
4. 文中的知识蒸馏是如何使用的
在文章中,知识蒸馏被用来解决非独立同布(non-IID)数据引起的收敛困难问题。知识蒸馏是一种从教师模型到学生模型的知识传递方法,通过在公共数据集上生成软标签,将客户端的知识传递给服务器。在FedReID中,作者使用了一个未标记的CUHK02数据集来应用知识蒸馏到联邦学习中。通过知识蒸馏,客户端作为教师,服务器作为学生,从客户端生成软标签,然后将这些软标签用于联邦学习的模型训。通过这种方式,知识蒸馏可以帮助解决非IID数据引起的收敛困难问题。
5. 文中的动态权重调整是如何实现的
动态权重调整是通过一种名为Cosine Distance Weight(CDW)的方法实现的。该方法通过测量每个客户端的模型变化来动态分配权重,使更大的变化对模型聚合产生更大的影响,从而更好地反映新学习的知识。具体来说,CDW实现步骤如下:
(1)客户端随机选择一批训练数据 D b a t c h D_{batch} Dbatch。
(2)当客户端在新一轮训练t中从服务器接收到模型时,它使用 D b a t c h D_{batch} Dbatch和由全局模型和本地身份分类器串联形成的局部模型 ( w t k , v t k ) (w_t^k,v_t^k) (wtk,vtk)生成logits f k t f_k^t fkt。
(3)客户进行训练以获得新模型 ( w k t + 1 , v k t + 1 ) (w^{t+1}_k,v^{t+1}_k) (wkt+1,vkt+1)。
(4) 它生成 ( w k t + 1 , v k t + 1 ) (w^{t+1}_k,v^{t+1}_k) (wkt+1,vkt+1) 和 D b a t c h D_{batch} Dbatch 的logits f k t + 1 f^{t+1}_k fkt+1。
(5) 客户端通过平均批处理中每个数据点的余弦距离来计算权重 m k t + 1 = m e a n ( 1 − c o s i n e _ s i m i l a r i t y ( f k t , f k t + 1 )) m^{t +1}_k = mean(1 − cosine\_similarity(f^t_k,f^{t+1}_k )) mkt+1=mean(1−cosine_similarity(fkt,fkt+1))。
(6)客户端向服务器发送 m k t + 1 m^{t +1}_k mkt+1,服务器用它替换FedPav中的权重。
通过这种方法,CDW可以根据客户端模型的变化动态调整权重,从而更好地反映新学习知识。
动态权重调整的好处在于可以缓解数据集大小差异(数据集不平衡)带来的影响,使得数据集较小的客户端也能够更有效地从其他客户端中获取知识。通过根据每个客户端模型的变化程度动态调整权重,可以更好地反映新学到的知识,从提高联邦模型的性能和收敛速度。
6. 相机联合方案是什么
文中的相机联合方案是指将每个相机视角的数据视为一个客户端,使用联邦学习的方法进行模型训练。在这种方案下,每个客户端只使用其所拥有的相机视角的数据进行训练,而不使用其他相机视角的数据。作者使用了Market-1501和CUHK03-NP两个数据集进行实验,将Market-1501数据集分成6个客户端,每个客户端包含一个相机视角的数据,将CUHK03-NP数据集分成2个客户端,每个客户端包含一个相机视角的数据。实验结果表明,相机联合方案的性能较差,无法与本地训练和身份联合方案相比。这是因为在相机联合方案中,每个客户只使用一个相机视角的数据进行训练,模型无法泛化到多相机评估。因此,作者认为相机联合方不如身份联合方案和本地训练方案适合用于人物重识别任务。
7. FedAvg算法是什么
FedAvg是一种标准的联邦学习算法,由McMahan等人提出。它包括服务器和客户端上的操作:客户端使用其本地数据集训练模型并将模型更新上传到服务器;服务器负责初始化网络模型并通过加权平均聚合来自客户端的模型更新。FedAvg要求服务器和客户端的模型具有相同的网络架构,而如第3.3节所论,客户端的身份分类器可能不同。因此,我们为FedReID引入了一种增强的联邦学习算法:Federated Partial Averaging。
8. FedPav算法是什么
与标准的联邦平均(FedAvg)算法不同,FedPav允许具有部分不同模型的客户端进行联邦训练。在FedPav中,每个客户端仅向服务器发送更新模型的一部分,而不是整个模型。FedPav旨在获得优于本地训练的模型,即在单个数据集上训练的模型。FedPav输出一个高质量的全局模型和每个客户端的本地模型。
9. 算法性能评估如何实现
本文中的算法性能评估主要使用了两种指标:Cumulative Matching Characteristics (CMC)曲线和mean Average Precision (mAP)。其中,CMC曲线用于评估查询身份与图库中所有图像的相似度排名,而mAP则计算所有查询的平均精度。此外,为了考虑到联邦学习的通信带宽限制,本文还使用了通信成本作为评估指标,通信成本的计算方法是通信轮数乘以模型大小的两倍。
