预处理的补充知识
️作者:@malloc不出对象
⛺专栏:《初识C语言》
个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐

目录
- 一、宏的补充知识
-
- 1.1 宏定义充当注释符号
- 1.2 宏定义多行代码
- 二、命令行定义
- 三、条件编译
-
- 3.1 常见的条件编译指令
- 3.2 #undef
-
- 3.2.1 例题
- 四、头文件的补充知识
-
- 4.1 头文件的重复包含
- 4.2 头文件被包含的方式
一、宏的补充知识
1.1 宏定义充当注释符号
demo1:重点讨论预处理阶段,去注释和宏替换(预处理指令)先后顺序问题.
首先我们来看这段代码,大家觉得最终会得出什么答案呢?

如果是先进行宏替换,那么printf这一行会被注释掉,所以最终我们只能看到下一条printf打印的结果;而先进行去注释的话,那么大家觉得又会出现什么情况呢?下面我们来揭晓答案,输入gcc test.c此时这条指令就默认产生了一个可执行程序a.out,接下来我们输入./a.out打开这个程序。

我们发现hello world被打印出来了,这说明我们的宏并没有将// 替换出来将printf注释掉。那么是先去注释还是先进行宏替换就一目了然了,在进行宏替换之前我们先将注释去掉了用空格替代,所以其实我们表现的是#define BSC 这种形式,BSC替换的是空格,所以printf打印hello world不受任何影响。
下面我们输入gcc -E test.c -o test.i,vim test.i进入test.i观察文件内容与源文件test.c做一个对比,我们发现处理过后的test.c文件,宏BSC替换的是空格,并且编译器做了相应的一些处理使得printf前的空格不见了,这些细节我们就不需要关心了这时编译器做的优化处理。

最终我们得出一个小结论:
预处理期间先执行去注释,再进行宏替换。
那么趁热打铁我们来看看下面这个例子,大家觉得会打印出什么结果呢?

还是一样我们输入gcc test.c来运行a.out看看得出什么答案。

结果我们发现运行这个程序发生了错误,error显示找不到EMC这个变量名。好了,接下来我们通过对比预处理过后的文件与test.c文件,我们之前讲过预处理阶段不进行语法语意等的检查,这个是在编译阶段进行的,所以我们能得到预处理之后的文件test.i。

vim test.i进入test.i文件之后与test.c做对比,我们之前已经得出结论是先去注释再进行宏替换,所以细心的读者也可以发现绿色部分其实已经被注释掉了,那么我们进行去注释之后就没有EMC的替换了,BMC替换的是空格。

1.2 宏定义多行代码
首先我们来看这段代码,大家觉得能运行成功吗?
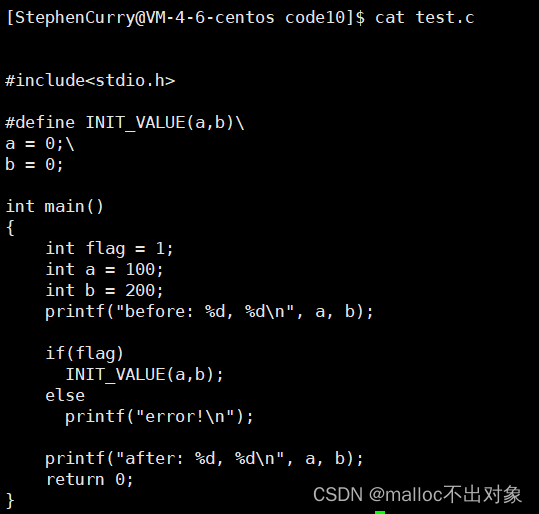
我们来运行一下,发现编译过程中出现了错误,我们打开预处理之后的文件test.i进行观察,我们发现原来是if else这里出现了问题,当if else没有带大括号时只能放一条语句,因此else不能与if成功配对导致错误。


那么既然是括号的问题我们就手动添加一个大括号,我们发现这时就能达到我们的目的了。
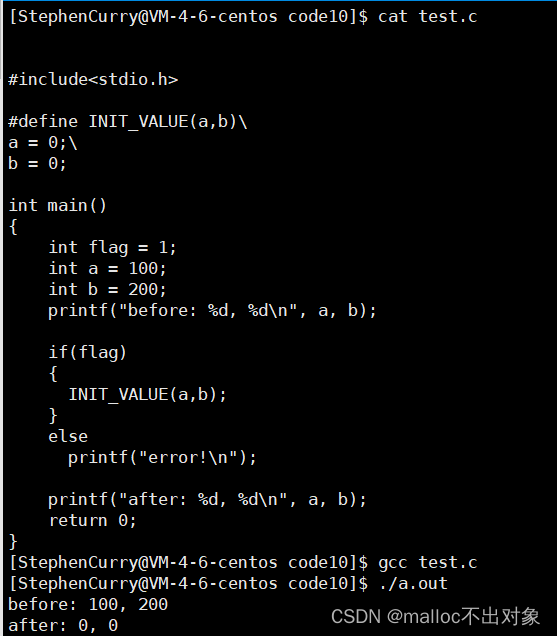
虽然我们经常讲if和else后不管有多少条语句都应该保持良好的代码习惯在后面添加大括号,但是如果有人没有这样的编码习惯呢?
那么作为一个优秀的代码编写者我们应将每一种情况考虑在内,让代码在通常任何情况下都能适用。好,既然我们定义的宏有多行代码,那么我们用大括号将这段代码括起来,这样在每次进行宏替换时我们都自动加上了大括号不用我们手动进行添加。
那么接下来看看这样能否达到我们的目的呢?这个宏比上述的宏只是多加了一个括号,并没有实质上的区别哈,只是为了方便阅读我写成了这样。

我们发现这样还是达不到目的,程序在编译阶段出现了错误,接下来我们进入test.i文件进行观察,我们发现是if代码块后多加了一个分号,这样else就跟if匹配不起来了。

那么接下来我们想的是怎么去掉这个分号,那我们直接去掉INIT_VALUE(a,b);这行代码的分号吗?虽然对于这个程序来说是能够解决问题,但是这符合我们的编码习惯吗?一条语句、表达式的结束标志应该由一个分号来完成。
那么接下来我们来看看优秀的程序员是如何解决这个问题的吧

采用do while循环就完美的解决了这个问题,不管是你本身编码习惯好还是不好,每次看到if else语句都带上花括号,还是像上图一样随便放都能达到我们的目的。

这次采用if else好的编码习惯来进行展示,我们发现都是没有任何问题的。接下来我们想一个问题为什么一定要采用do while语句呢?它巧妙在哪里?
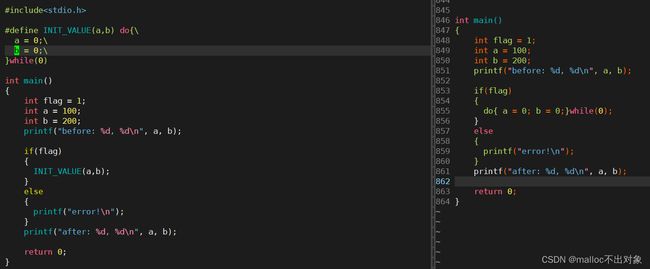
其一,因为它自身有一个花括号可以插入多段代码;
其二,我们不想让它进行循环操作只是想让它执行一次就行了所以while里面放的是0;
其三,因为do while循环是以;结束的,而这完美的解决了前面多出;的问题。
所以你明白这个do while结构巧妙之处了嘛
二、命令行定义
许多C 的编译器提供了一种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出一个程序的不同版本的时候,这个特性有点用处 。(假定某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外一个机器
内存大些,我们需要一个数组能够大些。)
下面我们来看一个例子:
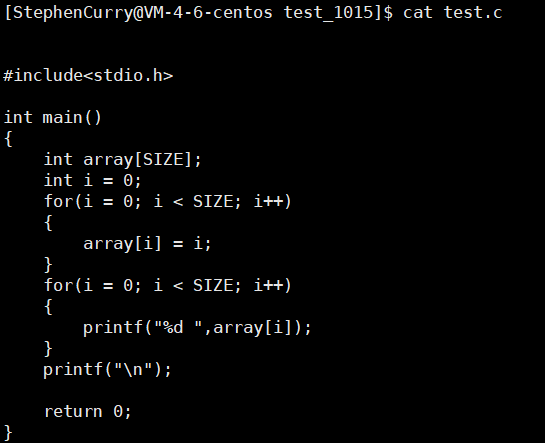
你觉得这段程序可以运行成功吗?答案肯定是不行的,因为我们的SIZE根本没有被定义,我们来编译看看:

那么我们怎么才能做到不修改代码然后给初始化SIZE呢?此时我们就需要用到命令行定义了,下面我们来看看:

我们输入指令gcc test.c -D SIZE=10,此时就在命令行给SIZE初始化了,并且也打印出了正确答案,下面我再将数组开大一点试试:
![]()
我们也成功的实现了我们的功能,这就是命令行定义的好处:做到不修改代码而随时可以改变我们的数值范围。
三、条件编译
在编译一个程序的时候我们如果要将一条语句(一组语句)编译或者放弃是很方便的,因为我们有条件编译指令。
比如说:调试性的代码,删除可惜,保留又碍事,所以我们可以选择性的编译,在各种头文件中、大型项目中以及内核源码中我们经常会看到里面包含大量的条件编译。
例如:像我们大部分小伙伴使用的VS是免费版的,还有一种是企业版是需要收费的,那么你觉得这两者之间有什么联系没有?我们用的免费版其实很多功能和收费版是相似的,但既然有收费版肯定是有些功能是我们免费版使用不了的,那么这意味着什么?我们要设计两份源码来设计免费版和收费版吗?
并不是这样的,这样大大的增大了我们的维护成本,我们只需要设计一份源码就行了,这时候就需要用到我们的条件编译了,如果你是收费版就开放下面的功能否则就只能使用免费版的功能,这样就减少了我们的维护成本。其实说的再通俗一点:条件编译的本质就是代码裁剪。
3.1 常见的条件编译指令
1. 判断是否被定义
#if defined(symbol)
#ifdef symbol
#if !defined(symbol)
#ifndef symbol
我们来看下面这个栗子,大家觉得能打印出东西吗?

答案是不能的因为DEBUG未被定义,我们来看看运行之后没有任何东西:

我们进入预处理过后的test.i文件中查看一番,我们发现DEBUG没有被定义那么printf就不会执行,并且我们发现这块代码在预处理之后全部用空格替换掉了,类似于注释删除:

接着我们定义一下DEBUG看看能不能达到目的:

此时果然打印出了我想对各位大佬们想说的话

其他三个也是类似的用法,我再给大家举下栗子吧,大家认为会打印出哪几句呢?

结果如下图所示:

相信大家都没有问题,不过我要提一点:以上指令只关注宏是否被定义,而不关注表达式条件是否为真假,在上图已经体现出来了,我们对比一下test.c和test.i观察一下:

2. 条件编译
2.
#if 常量表达式
//...
#endif
3.多个分支的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
以上俩个指令的用法跟if else语句类型,相信大家都应该明白,那么这点跟#ifdef…的区别是,它不仅关注条件表达式的真假也关注宏是否被定义。
我们来看下面栗子,大家觉得能打印成功吗?

我们看到报错信息是#if DEBUG之后没有表达式,接下来我们将宏进行替换一下,结果显示成功:

4. 嵌套指令
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif
关于这一点就不给大家一一演示了,原理跟if else语句一样,大家下去可以自己试一试。
讲完条件编译我想问大家一个问题:为什么我们有了注释还要使用条件编译呢?注释不也一样能够起到作用吗?
这样做在测试产品时很有好处,我们可以在不同版本中测试这份代码,还可以在发布产品时,我们可以不修改代码,而是直接利用条件编译来实现对一些功能的控制,直接编译出“不执行或部分执行这些宏环境”内的代码。大家也可以看看这位大佬的博客,写的十分详细。
3.2 #undef
首先我们先来想两个问题:
1.宏只能在main上面定义吗?
2.在一个源文件内,宏的有效范围是什么?
我们来看一个例子:



由此我们得出一个结论:源文件的任何地方,宏都可以定义,与是否定义在函数内外无关。
下面我们来看第二个例子,大家觉得它能完成替换嘛?

我们运行一下发现编译过程出现了错误提示,error:M没有被定义,我们vim test.i进入test.i文件查看一下,我们发现在#define下面我们的M成功的进行了替换,而上方却没有替换,所以提示M未被定义找不到M。


由此,我们可以还可以得出一个结论:宏的作用范围是从定义处开始的,往后都是有效的。
下面就来介绍一下#undef这个预处理命令,它是取消宏的意思(相当于undefine),可以用来限定宏的有效范围。
大家想想下面的代码经过预处理之后将会是什么情形?

我们通过对比test.i和test.c发现在取消宏定义之后,M和N不再被编译器识别到。

3.2.1 例题
通过上述的例子,我们知道了undef的用法及作用,接下我们做几道题来巩固一下知识点,大家一起来做做吧,首先说明这几道题有点坑,不过你只要理解了其中一题其他的都没什么问题了

这道题的正确答案为
A,小伙伴们你做对了嘛?
宏定义是在编译器预处理阶段中就完成替换了,而这时候程序还没有编译运行,所以和在不在函数内无关(此阶段还没有出现函数),替换成什么只与#define和undefine的位置有关系。看向这道题从1~11行这段区间,a已经是全部替换成10的了,12行#define才重新定义标识符,那么答案就很显然了
根据这个例子,我对这段代码稍微改正了一下,请大家计算一下下面这两段代码的值吧。
//代码1
#include代码1打印出来的结果为
50,50,代码2打印出的结果为50,10,10.大家有没有做对呢,下面还是来分析一遍吧.代码1:从
3~9这块区域a是被替换成10的了,而从10行到文件结束这块区域a是被替换成50的,所以打印出来的结果为50,50.
代码2:从22\~38这块区间a被替换成10,39~文件结束这块区域a被替换成50了,所以进入main函数时首先调用22~38这块区域内所以打印出来是10,10.
为了让大家更清楚整个过程,我们在Linux环境中对比预处理过后的文件test.i和源文件test.c,首先看看第一个代码:

第二段代码:

大家下来好好想想,这部分不难的
四、头文件的补充知识
4.1 头文件的重复包含
首先我想问大家两个问题?
1. 为何所有头文件,都推荐写入下面代码?本质是为什么?
#ifndef XXX
#define XXX
//TODO //代码
#endif
2. #include究竟干了什么?
首先我先回答第二个问题,其实我在这篇博客的预处理部分已经得出了结论,这里我就不做过多的赘述了,想了解清楚的可以移步观看,我们直接上结论:#include本质是把头文件中相关内容,直接拷贝至源文件中!
那么接下来我们来想一个问题,我们在多文件包含中有没有可能存在头文件被重复包含,乃至被重复拷贝的问题呢?
这时候我们就配合第一个问题来进行测试。首先我们来看下例子,这是我们在头文件中加上了条件编译,在源文件中重复包含两份头文件的情况:

我们进入test.i文件中进行查看并与test.c进行对比,发现虽然源文件中包含了俩份头文件但show函数还是只声明了一份。

接下来我们将头文件中的条件编译去掉源文件还是不变,看看会出现什么现象

我们发现去掉头文件中的条件编译之后,在test.i文件中包含了俩份show函数的声明。

下面我再多包含几次头文件看看还是不是出现这种情况,结果确实是重复包含了多少头文件源文件中show函数就重复声明了多少次。
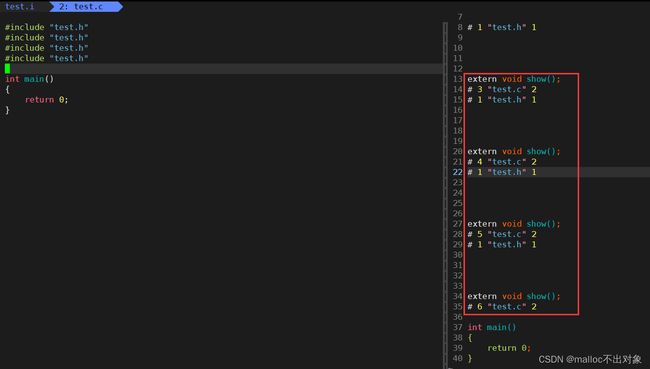
那么我们来看看条件编译是如何防止头文件被被重复包含的吧。

其实还有第二种解决方法:
加#pragma once在头文件前面,读者可以自行检测一下。
那么我说了这么多,大家认为头文件被重复包含就一定是错误的吗?
答案是不会的,重复包含是会引起多次拷贝(大多是函数、全局变量等的声明),但它主要是影响编译效率!虽然也可能引起一些未定义错误,但是特别少。
4.2 头文件被包含的方式
<> 查找策略:直接去库目录下查找
" "查找策略:
1.先去代码所在的路径下查找
2.如果第一步查不到,再去库目录下查找
库文件:#include < filename> 。
查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
本地文件:#include “filename”
先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。 如果找不到就提示编译错误。
注意:我们在使用库文件时也可使用" “的形式,但这样做降低了查找效率,因为” “是先去代码所在路径下去查找,而库头文件肯定是在库文件中啊,所以它又去库目录下查找。因此库文件使用” "的形式纯属多余了,假如你这个路径下的文件很多,那就大大降低了查找速率啊,而且这样也不容易区分是库文件还是本地文件了。
好了,今天的内容就分享到这里了,关于预处理部分的知识就全部给大家讲完了,觉得博主写的还不错就要点点赞哦,菜鸟需要大佬们的支持