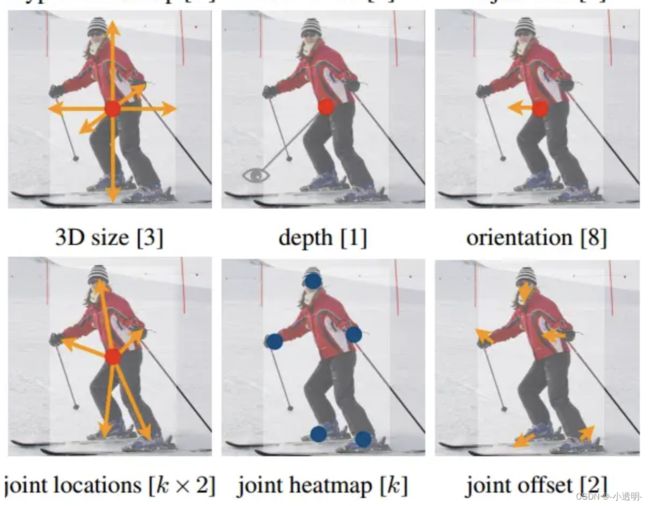
Anchor Free目标检测方法
faster rcnn anchor:尺寸比例固定
yolo anchor尺寸确定:通过聚类
Anchor Free方法
anchor的简单理解:在特征图上的模板,含有的信息为检测框的大小和尺度

Anchor based 方法小结
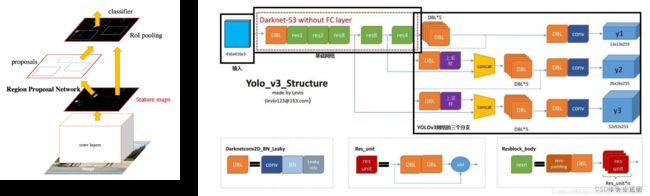

-
Faster rcnn(左上)
-
yolo v3(右上)
-
ssd (中)
-
retinaNet(下)
虽然Anchor based的方法取得了大量成功,但依然存在一些不足:
-
anchor box的参数需要手动调整
-
anchor box的采样数量太多,降低效率
-
anchor box的样本不均衡(负样本过多)
如何绕开anchor框?
Anchor free类方法
anchor free的方法大致可以分成两种:
-
以中心点为基准点的方法(center net)
优点:快
缺点:1)当目标重叠时,只能检测出一个;
2)大目标中的小目标难以检测出
-
以左上+右下为基准点的方法 (corner net)

CornerNet
核心思想:对于一个目标,构建一个目标框只需要得知其左上角与右下角两个关键点即可。
要达到这个目标,需要解决什么问题?
-
为每个目标都找到两个点(找点)
-
分类点(左上还是右下)
-
为得到的点进行匹配(匹配点)匹配同个物体一对点
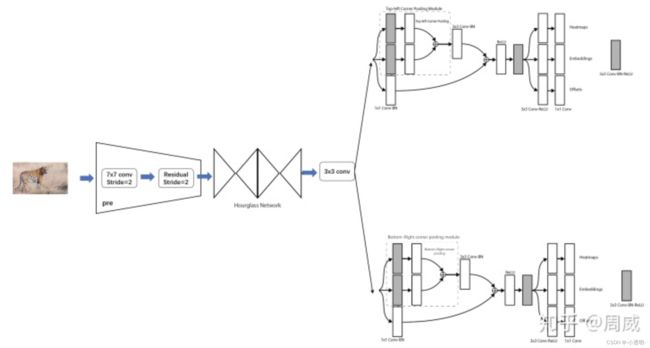
总体框架
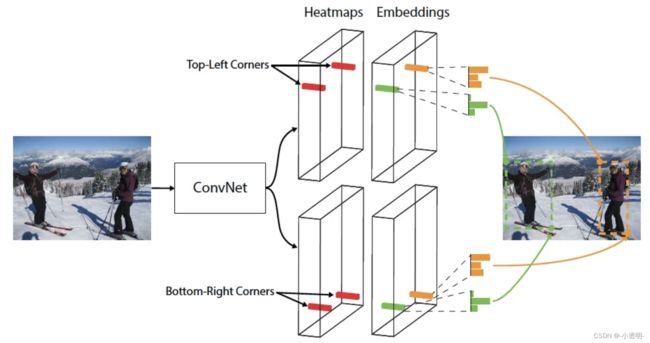
-
图像输入convNet,提取特征
-
特征分为两路,分别送入两个支路(分类)
- 上路由heatmap(热力图:找点)+embedding(匹配)组成,预测左上点
- 下路组成与上路相同,预测右下点
-
结合上下路的预测结果,得到目标检测结果
每个模块的内容
- hourglass net (沙漏网络)
hourglass net用于姿态检测,基本结构如下

很显然,这是一种有多尺度特征融合的网络
考虑到hourglass net是组合模块,corner中采用了两个hourglass net组成模型的convnet部分

- 二分输出
从hourglass net输出后,特征经过不同3*3卷积后,得到两路输出,分别送到top-left和bottom-right中。
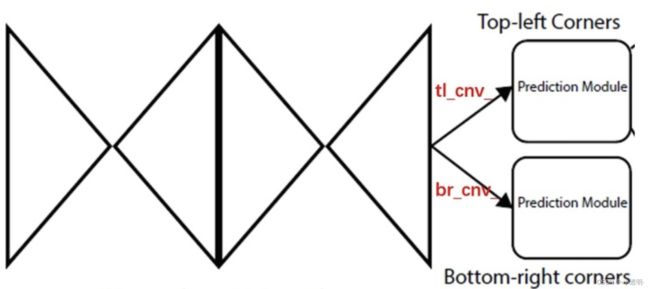
tl:top left br:bottom right
- 特征进入分支后,面临以下问题:
-
如何检测点?
-
如何确定检测的点是左上还是右下?
-
如何将同一个物体的左上角和右下角联系起来?
将一个特征图可视化后,我们希望关键点的位置应当比其他位置有着更高的响应。
也就是说,特征图中响应最大的点(相当于进行了一次nms)作,即关键点。
那么问题在于:如何判断所检测的关键点是左上角还是右下角?

如果一个点是左上角的话,那么他右下方应当是目标;
反之,右下角的左上方应当是目标。
考虑到上述问题,则可以设计一个不同方向的池化层,目的在于保留预期区域的特征,删除非预期区域的特征。
corner pooling

右面最大的值和下面最大的值导致左上角响应最高==>相当于将右下的内容转移到左上点:
计算时,反方向求一遍,求完之后加起来。
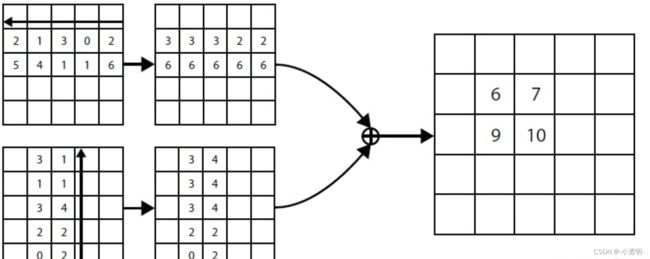

三个支路是并行的
如何将左上点和右下点联系起来?
在取得两个关键点位置的同时,为两个关键点提取特征。
特征越接近的,即说明他们是同一个物体。
因此,在上下两个支路中,lt支路进入lt的corner pooling的模块,分别输出:
- heatmaps (位置)
- embedings (目标)
- offsets (位置纠偏)
综上,corner net的整体结构图如图所示
损失函数
- heatmaps输出损失(尺寸: batch_size(bs)×128×128(feature map尺寸)×80(类别数)×2(有的网络输出1和0,有的没有))
ycij:第c张热力图(i,j)位置为第c类的角度
focal loss(交叉熵损失多了一个a次方)
Focal Loss 是一种用于解决类别不平衡问题的损失函数,由Lin et al.在论文"Focal Loss for Dense Object Detection"中提出。它通过减少易分类的样本对损失函数的贡献,来提高难分类样本的权重,从而改善模型在类别不平衡情况下的性能。
Focal Loss的公式如下:(热力图的损失)
FL(p_t) = -α_t(1-p_t)^γ * log(p_t)
其中,p_t为模型预测的概率值,α_t为类别权重,γ为调节难易样本权重的因子。当γ=0时,Focal Loss等价于交叉熵损失;当γ>0时,Focal Loss会降低易分类样本的权重,提高难分类样本的权重。
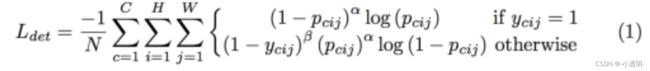
- offset损失 (尺寸: bs×128×128×80×2(deta x,deta y))
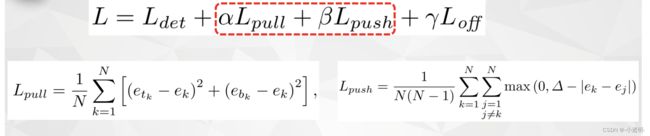
pull:令相同的物体的两个点尽可能相近
push:令不同物体的两个点尽可能相远
- offsets损失 (尺寸: bs×128×128×2)

总体损失

center net
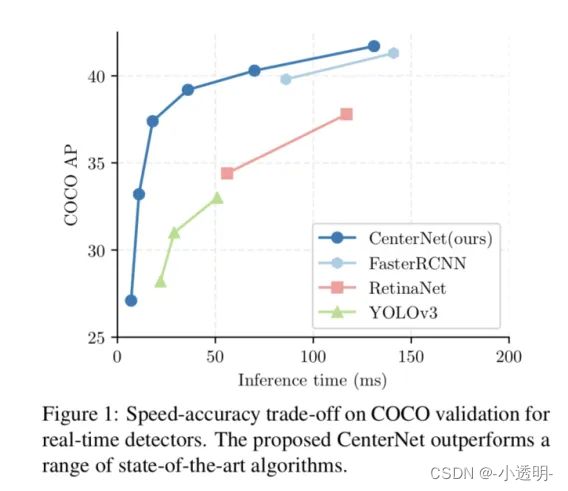
center net在速度和精度上超越了yolo v3

首先,图像输入bottel net进行下采样,得到feature map
其次,分三个支路进行预测。
与corner net不同,特征图不需要进行corner pooling
支路1: 预测中心点,根据feature map得到大致坐标
支路2: 估计出一个偏置,应对池化和padding等过程造成的位置偏移
支路3: 估计出一个框的尺寸,得到目标框。
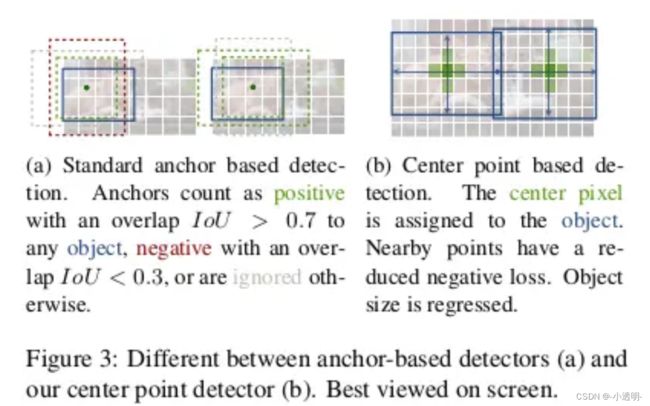
相比于之前的anchor based方法,对待有不同的ground truth方式。
anchor based 方法: 计算iou,IOU重合超过0.7的框即为正例,否则为负例
anchor free方法:中心点按高斯分布,逐渐降低权重向外扩散。
损失函数
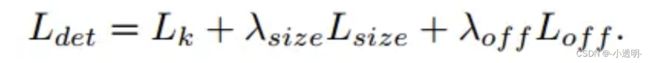
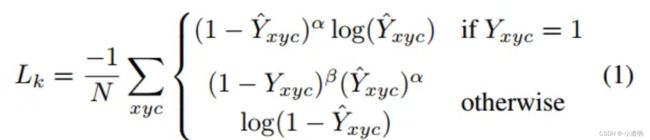

姿态检测
更进一步地,center net可以用于姿态检测。
也就是说预测人体的N个关键点,并对其进行合并识别,可以得到人体上的多个位置,从而得到姿态。