多线程下HashMap死锁问题源码分析
欢迎大家关注公众号“爪哇缪斯”\(^o^)/~ 「干货分享,每周更新」

在JDK8之前,当我们采用多线程的方式向HashMap中插入元素的时候,会有一定的概率造成线程死锁。这个问题在面试中也是比较常见的,那么原因是什么呢?“面试宝典”里面常常会给出如下极简的答案:“在数据迁移过程中,因为会采用头插法,所以会造成多线程死锁。而jDK8之后(包含8)则采用了尾插法,所以,可以有效的避免这个问题”。那么,本篇小短文就带着大家来到JDK7的源码中去深入的寻找更完整的答案。
put方法基本流程
首先,判断table数组是否为空(即:{}),如果为空,则调用inflateTable(threshold)方法初始化一个默认长度为16的数组。源码如下所示:
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}其次,如果key等于null,则将其放入table[0]所在元素的链表中。源码如下所示:
if (key == null) {
return putForNullKey(value);
}第三,通过key进行rehash操作,计算出待插入到table数组中的位置i,如果这个元素之前插入过,则更新value值,并将旧的value值返回出去。源码如下所示:
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
} 最后,如果这个元素没插入过,则调用addEntry进行添加。源码如下所示:
addEntry(hash, key, value, i);addEntry(hash, key, value, i);
在addEntry方法中,会涉及到table数组扩容&数据迁移操作。那么在这个场景下,我就可以看到多线程下如何会造成死锁。
相关的代码就在addEntry方法中的resize(2 * table.length)方法里,如下所示:
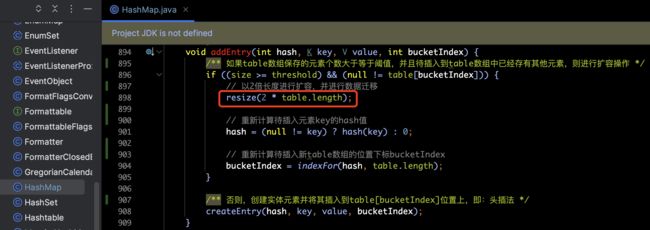
 数据迁移逻辑概述
数据迁移逻辑概述
数据迁移真正逻辑就在transfer(Entry[] newTable, boolean rehash) 方法中,源码和注释如下所示:
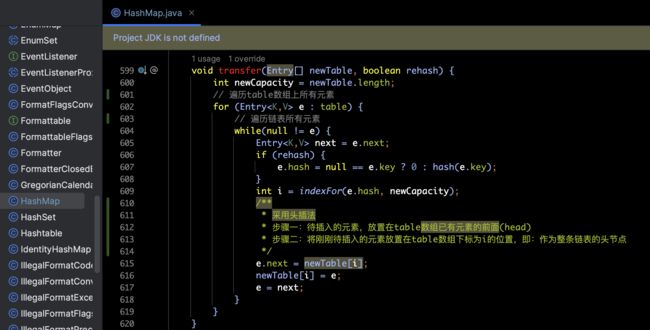
当然,这么看起来不是那么直观,下面我会以图示的方式演示如何数据迁移的。
首先,我们需要知道的知识点就是,JDK7中采取的是头插法进行数据迁移,那么迁移后的新旧链表顺序其实就是相反的。如下图所示:
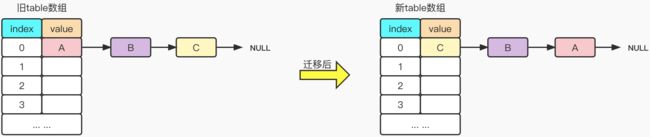
数据迁移详解
在上一节内容中,我们已经看到了transfer方法的源码,那么下面我们就根据源码的内容,演示每一步的数据迁移操作。迁移的场景就是原有数组下标0处有一条链表A->B->C,对其进行迁移。迁移详细步骤如下所示:
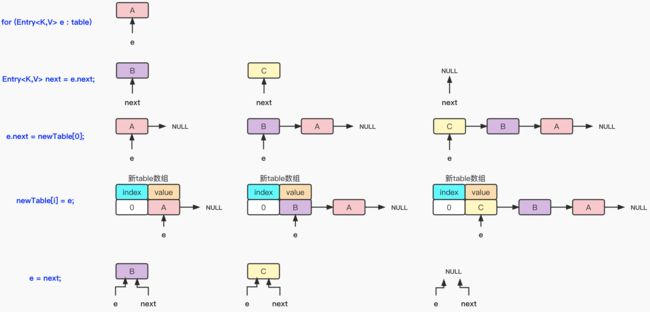
从上图中,已经演示了如何通过transfer方法中关键的代码内容执行数据迁移了。
多线程死锁场景
既然数据迁移的整个过程我们已经介绍过了,那么还是假设一个场景:有线程A和线程B这两条线程。同时对HashMap进行数据迁移操作。那么,线程A是正常执行的,线程B执行过程中慢了些。那么为何会产生死锁呢?详情请看下图:
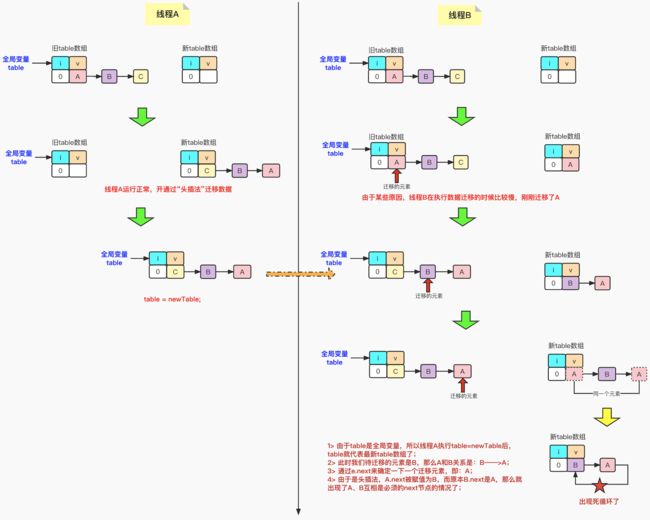
总结
如上的代码是针对于JDK7的解析,从JDK8开始,HashMap源码改进的内容还是蛮大的,从rehash的方式再到加入红黑树再到尾插法等等。
所以,在面试过程中,面试官想要考察面试者是否有看源码的习惯或者能力时,都会考察变更前和变更后的区别。当然,本篇文章只是举了一个特定的例子,会造成死锁,由于HashMap不是线程安全的,所以在多线程场景下问题还是比较多的。
如果想要更加详细的了解非线程安全的JDK8版本的HashMap源码解析,请跳到公众号【爪哇缪斯】搜索这篇文章。
如果想更详细的了解JDK8版本线程安全的ConcurrentHashMap源码解析,请跳到公众号【爪哇缪斯】搜索这篇文章。