mysql的sql语句调优_记一次MySQL的SQL语句调优
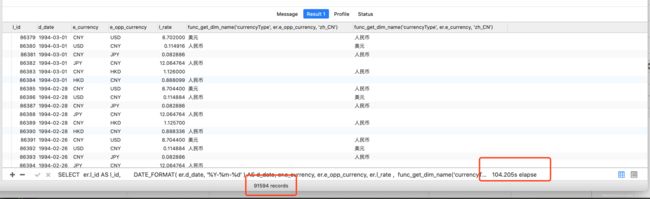
最近同事反映汇率功能查询太慢,上司让我去看下这个问题,关于汇率,系统里抓取了很多年的数据,目前表里一起是91594条,粗略查询下耗费了104s,这nm客户能忍?

表结构DDL如下,可以看到无任何索引
CREATE TABLE `d_exchange_rate` (
`l_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`d_date` date NOT NULL COMMENT '日期',
`e_currency` varchar(200) NOT NULL COMMENT '本币code',
`e_opp_currency` varchar(200) NOT NULL COMMENT '外币code',
`l_rate` decimal(15,6) NOT NULL COMMENT '汇率值',
PRIMARY KEY (`l_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=177973 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC;
又来生意了

优化思路
首先从业务上,精简SQL的范围,由于这是汇率模块,原来的查询逻辑将日元、韩元等都查询了出来,造成了不必要的耗时,所以我们可以根据系统使用了哪些币种就查询对应该币种的汇率转换记录,本币和外币的逻辑都如此,主SQL如下
SELECT
er.l_id AS l_id,
DATE_FORMAT( er.d_date, '%Y-%m-%d' ) AS d_date,
func_get_dim_name ( 'currencyType', er.e_currency, 'zh_CN' ) ,
func_get_dim_name ( 'currencyType', er.e_opp_currency, 'zh_CN' ),
er.l_rate
FROM
d_exchange_rate er
func_get_dim_name 是用来查询币种对应的名称,如CNY==>人民币

关于in 和 exists 的区别
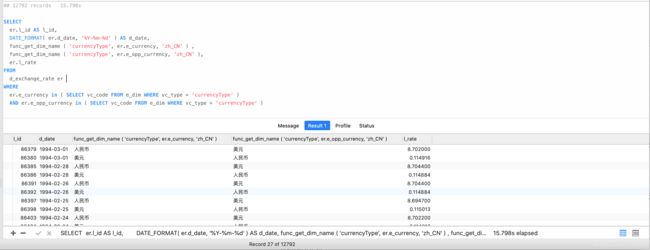
由于这里是很多个国家的币种,那么我们可以根据当前系统使用的币种过滤掉部分数据,我这里只有CNY和USD,过滤完后的数据12792条,分别用in和exists来初步查询,结果如下
数据量
in
exists
12792
15.798s
40.127s
in:
exists:

由此我们可以看出 in适合子查询结果数量较少时有优势,因为我这里就返回了CNY和USD,但是15s也还是太慢了,这种东西怎么能入上司的眼

尝试通过追加索引优化,但是由于SQL中使用in作为条件查找,索引是不起作用的,加了等于白加,而我缩小范围暂只能通过in来查找,所以这条路子走不通,卡在了15s,开始上路了
ALTER TABLE d_exchange_rate ADD INDEX index_currency ( e_currency )
ALTER TABLE d_exchange_rate ADD INDEX index_opp_currency ( e_opp_currency )

尝试使用表连接(join)代替子查询的方式替换in,效果还是不尽人意,不知不觉走到头了

所以就这样躺下了?不,我觉得还能挣扎一下,思来想去总觉得这件事没那么复杂,优化SQL我们还可以从字段方面入手,尽可能少查询不必要的字段,避免使用select * from table 全字段查询,于是乎首当其冲开刀的就是func_get_dim_name 函数
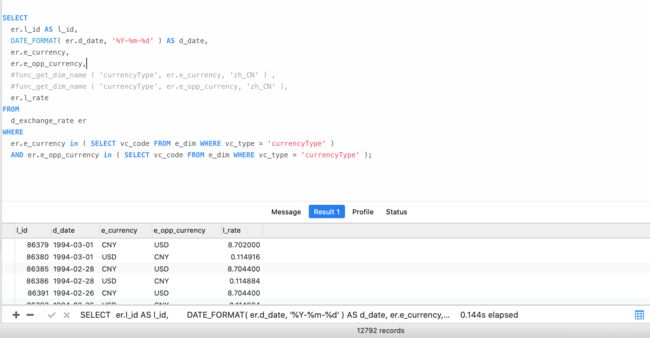
0.144s !!!是的,你没有看错,同样用exists去掉币种名称查找耗时25.063s
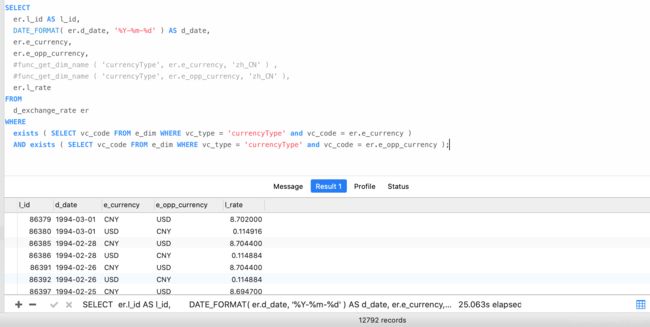
可以看到都比原来各自减少15s多,由此可以看出这15s是查询币种对应名称所用的耗时,由于有2个币种,需要查询2次,那么也就是12792*2=25584次的查询,耗时在15s,可以得知单个在7s左右,后面通过我的实践证明了猜想是正确的

。。。别封棺

实验结果汇总如下
数据量
是否查询币种名称
in
exists
12792
是
15.798s
40.127s
12792
否
0.144s
25.063s
问题找到了,后面决定将币种名称放入Java代码中实现,通过查一次然后遍历对比赋值,问题姑且解决
结论
SQL调优可以从很多方面入手,这篇文章主要试验了其中字段数量多少以及in和exists 的适用场景,实际业务中我们会更加复杂,所以优先从业务下手,缩减范围,然后考虑通过建立适当的索引以及SQL语句写法等方式进行优化,这里边有很多讲究的,比如索引类型的选择,字段存储的值的长度,前缀索引等等,如果想知道SQL的执行计划和顺序,我们还可以借助explain来帮助分析 Explain SQL执行计划,相信我,你在有过一次实际操作后会有较深入的理解
前面封棺的,你过来

附上部分连接