基于TPU-MLIR实现UNet模型部署-决赛答辩02
队伍:AP0200023
目录
初赛
一、 模型导出优化
1.1 直接倒出原始模型并转换
1.2 导出模型前处理
1.2.1 导出Resize
1.2.2 导出归一化
1.3导出模型后处理
1.3.1导出 Resize 与
1.3.2导出 ArgMaxout
1.3.3导出特征转RGB
复赛
一、 确定baseline
二、优化模型
复赛结果总结
三、遇到的问题总结
1. ONNX转MLIR
2. MLIR转bmodel
3. MLIR推理代码 BUG 【已经解决了】
四、 一些想法和建议
初赛
一、 模型导出优化
1.1 直接倒出原始模型并转换
报错Pad节点输入问题,修改源码报错解决
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2], mode="constant",
value=0)1.2 导出模型前处理
1.2.1 导出Resize
x = F.interpolate(x, (h // 2, w // 2), mode='bilinear')
原始Unet在UINT8输入下做Resize,但是这个操作不能直接导出到ONNX,因此测试了FP32 Resize和FP32归一化Resize,还有Resize模式bicubic bilinear。
工具链不支持bicubic。最终使用bilinear结果差距很大。
1.2.2 导出归一化
x = x / 255.0 # 1.导出除法
x = x * (1.0 / 255.0) # 2.导出乘法
param = self.unet.inc.double_conv[0].weight / 255.0
self.unet.inc.double_conv[0].weight = torch.nn.Parameter(param,
requires_grad=False) # 3.首层卷积权重/ 255.0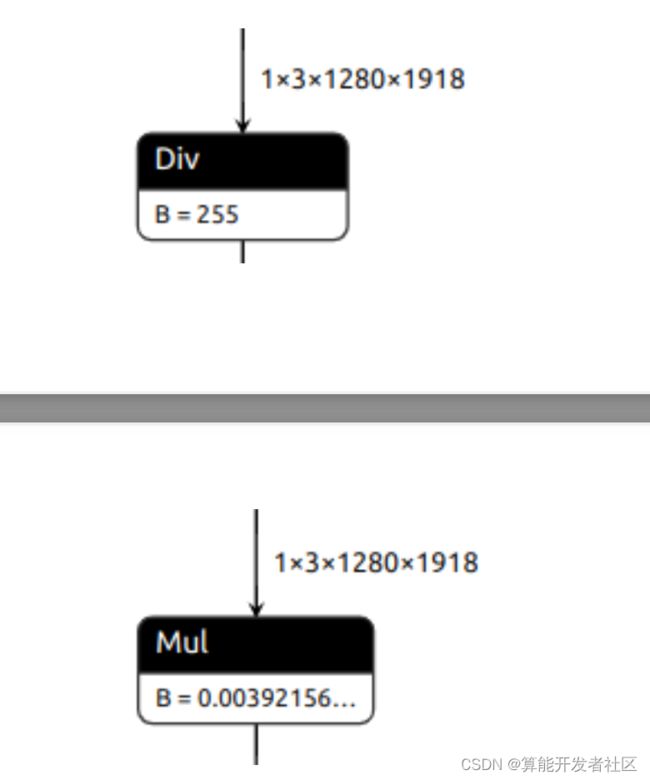
上述三中归一化操作对整体耗时影响很小,第三种方法FP32速度最快,但是可能INT8量化有问题。
1.2.3导出BGR2RGB
经过测试 OpenCV +切片比 PillowSkimage 读图速度快,因此考虑将BGR2RGB转出到 ONNX ,使用 Gather 算子实现。
param = param[:, [2, 1, 0], ...]
使用 Gather 会造成额外的拷贝,后面又改进成把首层卷积核顺序反转,这样的速度最快,且没有任何负面影响。
1.3导出模型后处理
1.3.1导出 Resize 与
前处理相似。
1.3.2导出 ArgMaxout
out = out.argmax(-1)模型转换报错不支持 ArgMax ,换如下实现:
out = torch.lt(out[0, 0], out[0, 1]) # Gather + Less
out = self.conv(out) > 0 # Conv + Greater
尝试构造 Conv 用来实现两个 Channel 做差, Conv 有可能以INT8运行,速度比较快。
conv = nn.Conv2d(2, 1, kernel_size=1, stride=1, padding=0, bias=False)
conv.weight = nn.Parameter(
torch.tensor([-1, 1]).to(conv.weight).reshape(conv.weight.shape),
requires_grad=False)
1.3.3导出特征转RGB
out = out.to(torch.uint8) * 255
out = torch.cat([out, out, out], -1)复赛
一、 确定baseline
复赛的比赛说明中以模型运行速度为准,因此初赛的很多工作都用不上了。转而变成了纯 UNET 模型优化。
我使用 UNET -Scale1.0输入1918x1280进行模型转换量化,最终作为 BaseLine ,结果如下:
flops: 3604915801600, runtime: 204.196060ms, ComputationAbility: 17.654188T
195.027445 0.992235 204.196060 1.675526e+09 2023-02-04模型 DICE 分数很高,将该模型预测的结果作为 GT。
二、优化模型
1.经过观察发现模型中下采样16倍导致1918的输入无法整除,造成了额外的 Padding ,所以我尝试输入1920x1280测试模型速度。由于输入图片为1918x1280,如果直接 Resize 会造成失真,我们选择在最下面Padding2个像素,结果如下:
0.992251 199.453278 1.675657e+09 2023-02-06可以看到模型 DICE 分数提升,并且检测速度变快,最终得分200。
2.优化反卷积
同样为了解决下采样16倍产生额外的 Padding 问题,尝试将 Padding 移动到 ConvTranspose 中,查阅 ONNXop 介绍可知 output _ padding 属性可以设置。
0.742231 199.346721 1.675677e+09 2023-02-063.公布第一轮成绩时我发现其他队伍分数很高,模型的 DICE 分数在98-99做有,推理分数30-40左右,最终的得分比我高很多,所以我同样选择降低分辨率。
使用Scale1.0和640x959640x960得到如下结果:
0.776212 42.033154 1.675665e+09 2023-02-06
0.777545 39.177540 1.675695e+09 2023-02-06速度分很好,但是 DICE 分数很低,怀疑是Scale1.0模型导致的,然后使用Scale0.5模型继续测试。
0.990611 41.376142 1.676272e+09 2023-02-13
0.990987 39.177540 1.676293e+09 2023-02-13速度分和精度分都上来了,达到了360分。
4. 继续缩小输入尺寸
为了保证输入宽高比例为3:2同时尽量满足16倍数,我测试了下面几个组合

实验发现当尺寸在560x368附近时,模型尚可保持精度,当尺寸更小的时候精度掉的较多。
5. 改进分割前后处理
比赛最后几天榜单更新,然后为了冲榜继续缩小输入尺寸,最终定为304x208,满足16的倍数和长宽比3:2。
经过本地测评发现精度丢失非常严重,然后开始优化前后处理。
(1) 前处理
由于图片尺寸太小, Resize 方法带来的结果有所不同。

使用 INTER _ CUBICINTER _ LINEARINTER _ NEAREST 得到的结果均类似左图,噪声的面积较大,使用 INTER _ AREA 则如右图,噪声叫小。
(2) 后处理
由于后处理时网络对噪声预测的分数较高使用 ArgMax 后会有一定混淆,因此我使用类似 SoftMax 的操作,对检测数值接近且在一定范围内的预测结果置为背景,代码如下:
bg, qg = out[..., 0], out[..., 1]
diff = bg - qg
flag = diff < 0
mi = np.abs(out).min(axis=2)
new_flag = diff[flag] / mi[flag] < -thres
diff[flag] = -new_flag.astype(np.float32)(3) 去除多余联通域
经过过滤一定范围内的差值,可以减少对噪声的检测。经过多组实验最终确认 thres 为2.2。除此之外,预测的结果存在多余区域,如图:

通过过滤除了最大联通域区域以外的区域可以避免多余区域。
def remove_no_connected_gray(gray):
num_labels, labels, stats, centroids =
cv2.connectedComponentsWithStats(gray, connectivity=8)
quyuId, pixNums = np.unique(labels, return_counts=True)
mask_background = quyuId != 0
quyuId, pixNums = quyuId[mask_background], pixNums[mask_background]
if quyuId.shape[0] == 1:
return np.ones_like(gray)
else:
maxId = quyuId[pixNums.argmax()]
mask = (labels == maxId).astype(np.uint8)
return mask(4) 对于边缘不平滑的预测,如图:

使用形态学开运算和高斯滤波可以让边缘平滑,去除突起:
out = cv2.medianBlur(opening, 9)实验多种滤波核大小,3/6/9/11/13发现核较大精度较高,最终选择9达到了较好的分数。
(5) 形态学运算去除其他噪声
经过滤波等操作后的图像仍然存在边缘突出,分割图内部空洞,边缘异常等问题,最终采用形态学运算进行改善。使用腐蚀去除边缘突出,使用膨胀填充图像空洞。

kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (k, k))
# kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (k, k))
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, 1)同样,滤波核(十字椭圆圆形),滤波核尺寸3/6/9/11/13等通过多组实验确认。
前面有很多超参如 thres 和滤波 kernel 大小形状均是通过本地实验,使用 BaseLine 得到的 GT 计算 dice 分数确定的最优解。最终最后一次提交的结果如下:
391.288683 0.952803 3.991613 1.677598e+09 2023-02-28复赛结果总结
经过几次提交得到的结果可以分析出,在模型 DICE 分数上差距较小,均在95-99分之间,上下浮动不超过5分,但是时间分数上不同尺寸的输入可以带来1-200的差距,因此只能在输入尺寸上下文章。由于前后处理不计算耗时,因此我最终选择304x208输入尺寸,并改进后处理模块实现了本次比赛模型速度最快,总分第4的成绩。
三、遇到的问题总结
1. ONNX转MLIR
1.1在 ONNX 注册了预处理后需要同时改变--mean0,0,0--scale1,1,1- pixel -formatbgr1.2ONNX中的 Resize / ArgMax 在 MLIR 中不支持,更换其他算子1.3ONNX中的 Pad 缺少参数报错,修改 PyTorch 模型1.4不支持UINT8数据格式,这部分生成图片放到 CPU 做。
2. MLIR转bmodel
2.1编译对称量化模型时-- tolerance 设置太高会导致编译失败,降低分数为0.80.42.2编译非对称量化模型时分数很低也会报错,速度提升也很小,放弃了。2.3编译模型时尺寸大的耗时严重,并且推理耗时也很大,最后选择小尺寸。
3. MLIR推理代码 BUG 【已经解决了】
比赛初始阶段提供的 MLIR 推理代码有问题,导致有一次提交没结果,后来官方修改更新的代码正常了。
四、 一些想法和建议
1.希望 model _ transform 工具实现 TPU 支持的常用的数据预处理 OP ,如果归一化和通道转换,作为单独的 OP ,这样就不需要写 CPU 的实现了。
2.希望 model _ transform 在遇到报错的 OP 能给出 OP 名字等信息,方便定位问题,报错能够详细一点。
3.希望 run _ calibration 和 model _ deploy 工具可以充分利用多核 CPU 的优势,在使用上述工具时某些阶段 CPU 利用率很高,某些阶段只有一个核心在用,猜测这部分是 Python 代码受到了 GIL 限制,可以尝试Pybind11改进一下。
4.希望编译后的模型可以把 fusion 和 pass 再反向生成一个 tpuop 的 onnx ,用于可视化模型结构。
5.希望 CPU 模拟 TPU 推理时也可以充分利用多核,大尺寸图像推理耗时太严重了,几个小时起步。
6.希望测试 bmodel 得到的 profile 文件可以通过网页或者其他形式可视化出结果,目前分析只能一行行的看。
7.希望未来复赛能像初赛一样可以自定义很多 trick ,复赛太单调了,并且用处也不太大。