Flink Standalone HA集群的安装配置
Flink集群有两种部署的模式,分别是Standalone以及YARNCluster模式。
Standalone模式:Flink必须依赖于ZooKeeper来实现JobManager的HA(Zookeeper 已经成为了大部分开源框架HA必不可少的模块)。在Zookeeper的帮助下,一个Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于Standby状态。当工作中的JobManager失去连接(如宕机或Crash),ZooKeeper会从Standby中选举新的JobManager来接管Flink集群。
YARN Cluaster模式:Flink就要依靠YARN本身来对JobManager做HA了。其实这里完全是YARN的机制。对于YARNCluster模式来说,JobManager和TaskManager都是启动在YARN的Container中。此时的 JobManager,其实应该称之为Flink Application Master。也就说它的故障恢复,就完全依靠着YARN中的ResourceManager(和 MapReduce的AppMaster一样)。由于完全依赖了YARN,因此不同版本的YARN可能会有细微的差异。
目录
Local模式
Standalone模式
Standalone HA模式
提交job
Local模式
1、解压flink安装包并重命名
tar -zxf flink-1.9.3-bin-scala_2.11.tgz
mv flink-1.9.3 flink
2、配置flink环境变量

#需要配置 HADOOP_CONF_DIR 环境变量,否则会有提示
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
3、配置文件flink/conf说明

需要配置的文件有:masters、slaves、flink-conf.yaml文件,其中masters文件是用来配置HA的,只要我们不配置HA(高可 用性)的话,就不需要配置masters文件;slaves是用来配置从节点个数(flink也是master/slave结构);flink-conf.yaml文件 用来配置集群其他相关信息
4、Local模式中JobManager和TaskManager共用一个JVM来完成WorkLoad。如果验证一个简单的应用,Local 模式是最方便的,实际应用中大多使用Standalone或者Yarn Cluster。Local模式只需要将安装包解压,使用./bin/start-cluster.sh启动即可,看到有如下两个进程即启动成功,使用stop-cluster.sh即可关闭集群

Standalone模式
1、配置master文件(主节点地址和端口)
vim masters
#设置主节点,非HA模式只配置一个即可
westgis181:8081
2、配置slaves文件
vim slaves
#设置从节点
westgis182
westgis183
3、配置flink-conf.yaml文件
vim $FLINK_HOME/conf/flink-conf.yaml
修改设置如下即可

其中jobmanager.rpc.address的值为主机名;taskmanager.numberOfTaskSlots的值为slot个数,即Work进程可以同时运行 的Task数,通常是 CPU 的核心数或一半
注意:flink-conf.yaml中配置key/value时候在“:”后面需要有一个空格,否则配置不会生效。
4、分发给其他节点
scp -r flink/ westgis182:~/bigdata/
scp -r flink/ westgis183:~/bigdata/
5、启动
在flink/bin目录下执行./start-cluster.sh命令
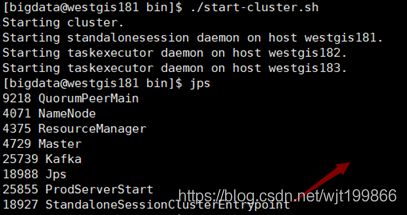
在主节点出现StandaloneSessionClusterEntrypoint进程
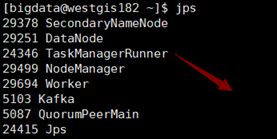
在从节点出现TaskManagerRunner进程
主节点:
从节点:
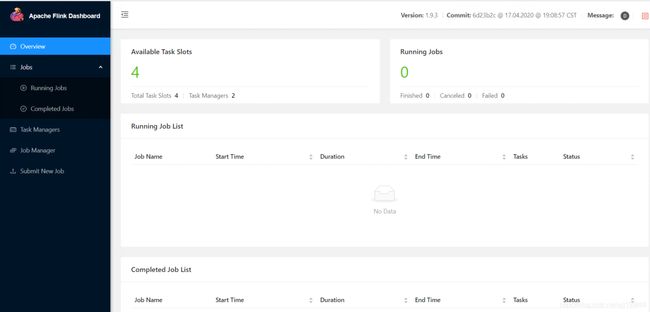
6、web界面
在浏览器输入:主节点ip地址:8081(我这里是:10.103.104.181:8081)
7、关闭
在flink/bin目录下执行./stop-cluster.sh命令
Standalone HA模式
1、配置master文件(主节点地址和端口)
vim $FLINK_HOME/conf/masters
# 设置主节点,HA 设置active及standby两个
westgis181:8081
westgis182:8081
2、配置slaves文件
vim $FLINK_HOME/conf/slaves
#设置从节点
westgis181
westgis182
westgis183
3、配置flink-conf.yaml文件
vim $FLINK_HOME/conf/flink-conf.yaml
配置如下:
# 基础配置
jobmanager.rpc.address: westgis181
jobmanager.heap.size: 1024m
taskmanager.heap.size: 1024m
taskmanager.numberOfTaskSlots: 3
parallelism.default: 5
# 指定使用 zookeeper 进行 HA 协调
high-availability: zookeeper
high-availability.storageDir: hdfs://westgis181:9000/flink/ha/
high-availability.zookeeper.quorum: 10.103.104.181:2181,10.103.104.182:2181,10.103.104.183:2181
high-availability.zookeeper.client.acl: open
# 指定 checkpoint 的类型和对应的数据存储目录
state.backend: filesystem
state.checkpoints.dir: hdfs://westgis181:9000/flink/flink-checkpoints
jobmanager.execution.failover-strategy: region
# Rest和网络配置
rest.port: 8081
rest.address: westgis181
# 高级配置,临时文件目录
io.tmp.dirs: /tmp
# 配置 HistoryServe
jobmanager.archive.fs.dir: hdfs://westgis181:9000/flink/completed-jobs/
historyserver.web.address: westgis182
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://westgis181:9000/flink/completed-jobs/
historyserver.archive.fs.refresh-interval: 1000
4、拷贝Zookeeper及HDFS配置文件及hadoop依赖包![]()
Hadoop依赖jar包下载地址:
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.6.5-10.0/
根据自身hadoop版本和flink版本下载相应的依赖包,然后上传到$FLINK_HOME /lib目录下
5、分发给其他节点
scp -r flink/ westgis182:~/bigdata/
scp -r flink/ westgis183:~/bigdata/
6、启动
在flink/bin目录下执行./start-cluster.sh命令
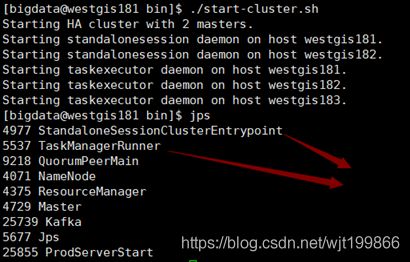
主节点的进程为StandaloneSessionClusterEntrypoint
从节点的进程为TaskManagerRunner
主节点:
standby节点:
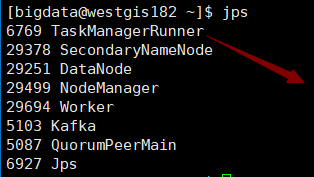
从节点:
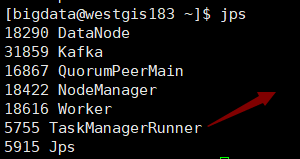
7、web界面
在浏览器输入:主节点ip地址:8081(我这里是:10.103.104.181:8081)

8、关闭
在flink/bin目录下执行./stop-cluster.sh命令
9、测试
$FLINK_HOME/bin/start-scala-shell.sh是flink提供的交互式client,可以用于代码
片段的测试,方便开发工作,它有两种启动方式,一种是工作在本地,另一种是工作到集群。
本地连接:
${FLINK_HOME}/bin/start-scala-shell.sh local
集群连接:
${FLINK_HOME}/bin/start-scala-shell.sh remote
添加依赖包连接:
${FLINK_HOME}/bin/start-scala-shell.sh [local|remote
这里,我们使用集群模式去验证
使用./start-scala-shell.sh remote 10.103.104.181 8081命令启动集群连接
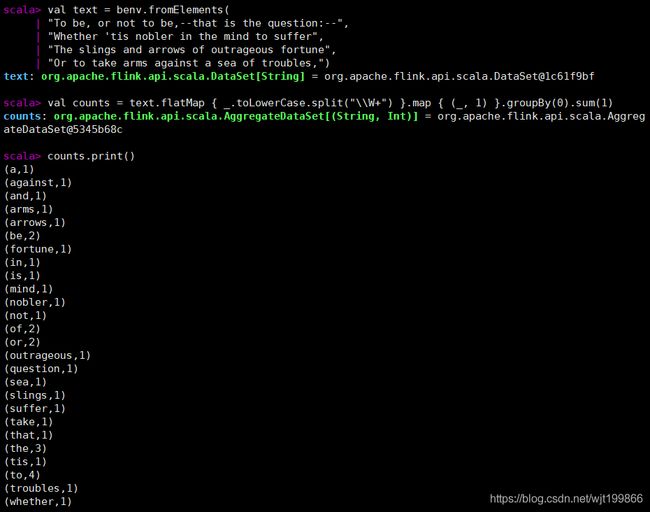
案例代码如下:
Scala>val text = benv.fromElements(
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,")
Scala>val counts = text.flatMap { _.toLowerCase.split("\\W+") }.
map { (_, 1) }.groupBy(0).sum(1)
Scala>counts.print()
运行结果:
web界面也可以看到详细的信息:

提交job
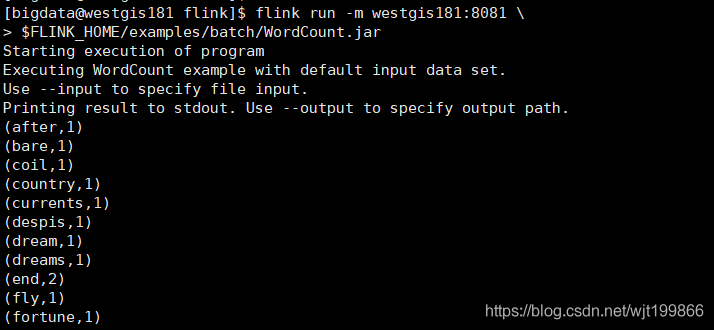
运行flink自带的wordcount程序
不指定输入输出目录:
flink run -m westgis181:8081 \
$FLINK_HOME/examples/batch/WordCount.jar
指定输入输出目录:
flink run -m westgis181:8081 \
$FLINK_HOME/examples/batch/WordCount.jar \
--input hdfs:///flink/flinkinput/ \
--output hdfs:///flink/flinkoutput
