【计算机视觉】OFA:通过一个简单的seq2seq的学习框架来统一架构、任务和模态
文章目录
- 一、导读
- 二、摘要
- 三、介绍
- 四、OFA
-
- 4.1 I/O & Architecture
-
- 4.1.1 I/O
- 4.1.2 Architecture
- 4.2 Tasks & Modalities
- 4.3 预训练数据集
- 4.4 训练与推理
- 4.5 缩放模型
- 五、实验结果
-
- 5.1 跨模态任务的结果
- 5.2 单模态任务的结果
- 5.3 zero-shot学习和任务迁移
- 六、测试结果
- 七、总结
一、导读
OFA: UNIFYING ARCHITECTURES, TASKS, AND MODALITIES THROUGH A SIMPLE SEQUENCE-TO-SEQUENCE LEARNING FRAMEWORK
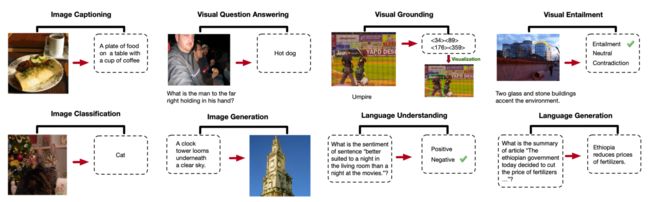
OFA支持的各种任务的示例:
论文地址:
https://arxiv.org/abs/2202.03052

代码开源的地址:
https://github.com/OFA-Sys/OFA
二、摘要
在这项工作中,我们追求多模态预训练的统一范式,以打破复杂任务/特定模态定制的框架。
我们提出OFA,一个支持任务全面性的任务不可知论和模态不可知论框架。
OFA在一个简单的序列到序列学习框架中统一了一系列不同的跨模式和单模式任务,包括图像生成、视觉基础、图像字幕、图像分类、语言建模等。OFA在预训练和调优阶段都遵循基于指令的学习(instruction-based learning),下游任务不需要额外的任务特定层。
与最近最先进的视觉和语言模型(依赖于超大的跨模态数据集)相比,OFA仅在2000万公开可用的图像-文本对上进行了预训练。尽管其简单且训练数据相对较小,但OFA在一系列跨模态任务中实现了新的sota,同时在单模态任务中获得了极具竞争力的性能。我们进一步的分析表明,OFA也可以有效地转移到不可见的任务和不可见的领域。
本篇论文的关键词为:
统一框架、多模态预训练、多任务学习、Zero-Shot 学习
三、介绍
在人工智能领域,建立一个无所不能的模型来处理和人类一样多的任务和模式是一个很有吸引力的目标。实现这一目标的可能性可能在很大程度上取决于能否仅用几种可以由单一模式或系统统一和管理的形式来表示大量不同的模式、任务和训练制度。
Transformer架构的最新发展显示了它作为通用计算引擎的潜力。在监督学习的环境中,“预训练-微调”范式在许多领域取得了卓越的成功。在少/零次学习机制下,具有提示/指令调优的语言模型证明了强大的零/少次学习器。
这些进步为全方位模式的出现提供了比以往任何时候都重要的机会。
为了在保持多任务性能和易用性的同时更好地支持开放式问题的泛化,我们主张一个全能模型应该具有以下三个属性:
- 任务不可知论(task - agnostic, TA):统一的任务表示,支持不同类型的任务,包括分类、生成、自我监督的借口任务等,对预训练和微调都不可知。
- 模态不可知(MA):在所有任务之间共享统一的输入和输出表示,以处理不同的模态。
- 任务全面性:任务种类足够丰富,能够稳健性地积累归纳能力。
然而,在满足这些特性的同时,在下游任务中保持优越的性能是具有挑战性的。
当前的语言和多模态预训练模型很容易在这些属性的部分上失败,因为它们的设计选择如下:
- 额外可学习的微调组件,例如,task-specific heads,adapters,soft prompts。
这使得模型结构具有任务特异性,并且在预训练和微调之间存在差异。这样的设计也不利于以Zero Shot的方式支持看不见的任务。
- 特定于任务的制定。对于目前的大多数方法,预训练、微调和零射击任务通常在任务形式和训练目标上有所不同。这违反了TA,并且为了实现TC而扩大任务数量是很麻烦的。
- 与下游任务纠缠模态表示。将检测到的物体作为图像输入特征的一部分是视觉语言模型的常见做法。虽然它在一些闭域数据集上展示了更好的下游任务性能,但它依赖于一个额外的对象检测器,而这个检测器通常在开放域数据上失败。
因此,探索了一个多模态预训练的全模型,并提出了OFA,希望是“One for All”,它实现了统一架构、任务和模态的目标,并支持上述三个属性。
通过手工制作的指令在统一的序列到序列抽象中制定预训练和微调任务,以实现任务不可知论。
采用Transformer作为模态不可知的计算引擎,它具有一个约束,即不能将可学习的任务或模态特定的组件添加到下游任务中。
它可用于在跨所有任务的全局共享多模态词汇表中表示来自不同模态的信息。
然后,我们通过对各种单模态和跨模态任务进行预训练来支持任务全面性。
总结如下:
- 我们提出了支持任务全面性的任务不可知论和模式不可知论框架OFA。OFA是第一次尝试通过一个简单的序列到序列的学习框架,通过统一的基于指令的任务表示,统一以下视觉和语言、纯视觉和纯语言任务,包括理解和生成,例如文本到图像的生成、视觉接地、视觉问答(VQA)、图像字幕、图像分类、语言建模等。
- 与最近依赖于更大规模配对数据的模型相比,OFA是在公开的2000万图像-文本对数据集上进行预训练的。OFA在图像字幕、视觉问答、视觉蕴涵、参考表情理解等一系列视觉和语言下游任务中取得了最先进的表现。
- OFA作为一个多模态预训练模型,在单模态任务上的表现与SOTA在语言或视觉上的预训练模型相当。
- 我们验证了OFA在Zero Shot学习中达到了有竞争力的性能。此外,它还可以通过新的任务指令转移到不可见的任务,并且无需微调即可适应域外信息。
下图演示了预训练任务,包括视觉接地,接地字幕,图像-文本匹配,图像字幕,VQA,目标检测,图像填充以及文本填充:

四、OFA
提出了OFA,一个统一的Seq2Seq框架,用于统一I/O和架构,任务和模式。具体框架如上所示。
4.1 I/O & Architecture
4.1.1 I/O
多模态预训练最常见的方法是在图像-文本对语料库上大规模地预训练Transformer模型。这需要数据预处理或特定于模态的适配器,以便使用Transformer体系结构对视觉和语言信息进行联合训练。
为了在没有特定任务输出模式的情况下处理不同的模式,必须将各种模式的数据表示在一个统一的空间中。
一种可能的解决方案是将文本、图像和对象离散化,并用统一词汇表中的符号表示它们。图像量化的最新进展已经证明了文本到图像合成的有效性,因此我们将此策略用于目标侧图像表示。稀疏编码在减少图像表示的序列长度方面是有效的。例如,分辨率为256 × 256的图像表示为长度为16 × 16的代码序列。每个离散码与相应的补丁强相关。
除了表示图像之外,还必须表示图像中的对象,因为有一系列与区域相关的任务。接下来,我们将对象表示为离散令牌序列。更具体地说,对于每个对象,我们提取其标签和边界框。边界框的连续角坐标(左上和右下)被统一离散为整数,作为位置标记 ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2)。
至于对象标签,它们本质上是单词,因此可以用BPE令牌表示。
最后,我们对所有语言和视觉标记使用统一的词汇表,包括子词、图像代码和位置标记。
4.1.2 Architecture
根据之前在多模态预训练中的成功实践,我们选择Transformer作为主干架构,并采用编码器-解码器框架作为所有预训练、微调和零射击任务的统一架构。
具体来说,编码器和解码器都是Transformer层的堆栈。Transformer编码器层由自注意和前馈网络(FFN)组成,而Transformer解码器层由自注意、FFN和交叉注意组成,用于在解码器和编码器输出表示之间建立连接。
为了稳定训练并加速收敛,我们在自注意中加入了头部缩放、后注意层归一化(LN),以及FFN第一层之后的LN。对于位置信息,我们分别对文本和图像使用两个绝对位置嵌入。我们不是简单地添加位置嵌入,而是将token嵌入和patch嵌入的位置相关性解耦。此外,我们还对文本使用1D相对位置偏差,对图像使用2D相对位置偏差。
4.2 Tasks & Modalities
统一的框架旨在提供跨不同模式和下游任务的体系结构兼容性,以便有机会推广到同一模型中未见过的任务。然后,我们必须在一个统一的范式中表示涉及不同模态的可能的下游任务。因此,预训练任务设计的一个要点是考虑多任务和多模态。
为了统一任务和模式,我们设计了一个统一的序列到序列学习范式,用于对所有涉及不同模式的任务进行预训练、微调和推理。无论是预训练任务,还是跨模态和单模态理解和生成的下游任务,都形成为Seq2Seq生成。可以对多模态和单模态数据进行多任务预训练,使模型具备综合能力。具体来说,我们在所有任务中共享相同的模式,同时我们指定了手工制作的区分指令。
对于跨模态表示学习,我们设计了5个任务,包括 visual grounding (VG)、grounded captioning (GC)、 image-text matching (ITM)、image captioning (IC)和 visual question answering (VQA)。
对于VG,模型根据图像的输入和“文本 x t x_t xt描述的是哪个区域”的指令,学习生成指定区域位置的位置令牌。,其中 x t x_t xt为区域标题。
GC是VG的逆任务。区域: ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2) "对于ITM,我们使用每个原始图像-文本对作为正样本,并通过将图像与随机替换的标题配对来构建一个新的图像-文本对作为负样本。
模型根据输入图像 x i x_i xi和“图像描述 x t x_t xt吗?”的指令,通过学习生成“是”或“否”来区分给定的图像和文本是否配对。
对于图像字幕,这个任务可以自然地适应序列到序列的格式。
该模型根据给定的图像和指令学习生成标题"这个图像的描述是什么?"。
对于VQA,我们将图像和问题作为输入发送,并要求模型学习生成正确的答案。
对于单模态表示学习,我们分别设计了2个视觉任务和1个语言任务。利用图像填充和目标检测对模型进行预训练,用于视觉表征学习。计算机视觉生成式自监督学习的最新进展表明,masked image model是一种有效的预训练任务。
在实践中,我们将图像的中间部分作为输入。该模型根据损坏的输入和指定的指令“中间部分的图像是什么?”来学习生成图像中心部分的稀疏代码。我们还在以下预训练中加入了目标检测。该模型学习基于输入图像和文本“图像中的对象是什么?”生成人类注释的对象表示,即对象位置和标签序列。作为指示。这两个任务都在像素和对象层面上加强了表征学习。对于语言表示学习,在纯文本数据上使用文本填充预训练统一模型。
通过这种方式,我们将多个模式和多个任务统一到一个单一的模型和预训练范式中。OFA与这些任务和数据一起进行预训练。因此,它可以执行不同的任务,包括自然语言、视觉和跨模态。
4.3 预训练数据集
我们通过合并视觉和语言数据(即图像-文本对),视觉数据(即原始图像数据,对象标记数据)和语言数据(即纯文本)来构建预训练数据集。对于复制,我们只使用公开可用的数据集。我们仔细过滤预训练数据,排除下游任务验证和测试集中出现的图像,以避免数据泄漏。
4.4 训练与推理
我们用交叉熵损失来优化模型
对于推理,我们应用解码策略,例如beam search,以提高生成的质量。
然而,这种范式在分类任务中存在几个问题。
- 对整个单词表进行优化是不必要的,也是低效的;
- 在推理过程中,模型可能从封闭的标签集中生成无效的标签。
为了克服这些问题,我们引入了一种基于前缀树(Trie)的搜索策略。实验结果表明,基于Trie的搜索可以提高OFA在分类任务上的性能。
4.5 缩放模型
为了研究不同模型规模的OFA在下游任务中的表现,开发了5个版本的OFA模型,参数规模从33M到940M,我们在表1中列出了它们的详细超参数。

更具体地说,建立了 Base 和 Large 尺寸的基本模型,即 OFABase 和 OFALarge。由于我们的网络配置与BART相似,它们的大小与BARTBase和BARTLarge相似。
此外,还开发了更大尺寸的OFA,将其命名为OFAHuge,或者在表格中没有具体提及的OFA。其规模与SimVLMHuge或ViTHuge相当。为了研究更小的OFA是否还能达到令人满意的性能,继续开发了OFAMedium和OFATiny,它们的大小只有OFBase的一半左右和不到20%。

五、实验结果
5.1 跨模态任务的结果
我们在不同的跨模态下游任务上评估了我们的模型,包括跨模态理解和生成。
具体来说,我们在多模态理解数据集上进行了实验,包括用于视觉问答的VQAv2和用于视觉蕴含的SNLI-VE,以及多模态生成,包括用于图像字幕的MSCOCO Image Caption、用于引用表达理解的RefCOCO / RefCOCO+ / RefCOCOg,因为该任务可被视为bounding boxes生成,以及用于文本到图像生成的MSCOCO Image Caption。
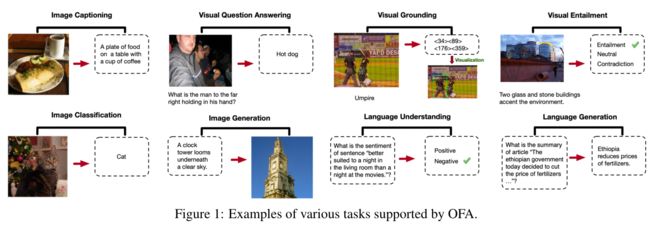
下表显示了OFA和基线模型在VQA和SNLI-VE上的表现。总的来说,OFA在这两项任务中都取得了最好的表现,在VQA测试-std集上取得了82.0分,在SNLI-VE测试集上取得了91.2分。对于较小的模型,OVALarge可以超过最近的SOTA,例如VLMo和SimVLM,而OFBase可以在两个任务中击败上述两个模型之前的SOTA。这表明OFA可以在跨模态理解任务上取得优异的表现,而且扩大OFA的规模可以带来明显的改进,反映了大规模预训练模型的强大潜力。
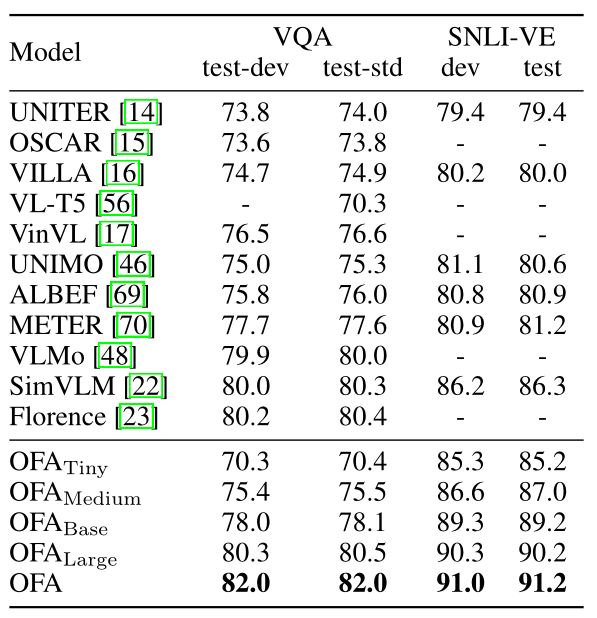
下表展示了OFA和基线模型在MSCOCO图像字幕数据集上的表现。
我们报告了Karpathy测试分割的结果,我们展示了用交叉熵优化和另外用基于强化学习的CIDEr优化训练的模型的性能。与之前的SOTA SimVLMHuge的交叉熵优化相比,OFA在CIDEr评估中优于它约2分。对于CIDEr优化,3种规模的OFA都超过了巨大规模的LEMON,OFA展示了一个新的SOTA,即154.9的CIDEr得分。到2022年5月31日,单一型号的OFA已经在MSCOCO图像字幕排行榜上名列前茅。
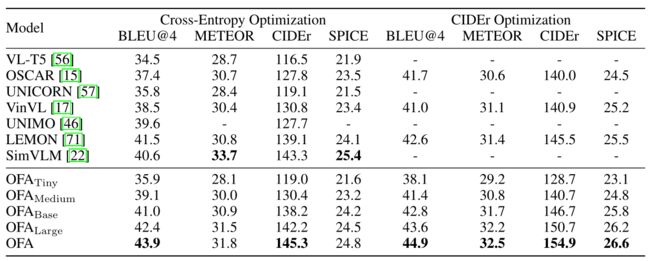
为了评估视觉定位的能力,我们对RefCOCO、RefCOCO+和RefCOCOg进行了实验。
虽然我们将位置统一到单词表上,但视觉定位可以被看作是一个序列生成任务。由于每个查询只有一个目标,我们将生成长度限制为4,以便通过< x1, y1, x2, y2>生成一个bounding boxes。
下表的实验结果显示,OFA在3个数据集上达到了SOTA的性能。与之前的SOTA UNICORN相比,OFA在RefCOCO和RefCOCO+的testA集以及RefCOCOg的test-u集上获得了3.61、6.65和4.85分的显著改善。
即使对于经过预训练的模型,文本到图像的生成也是一项具有挑战性的任务。由于我们用 "图像填充 "任务对OFA进行了预训练,即通过生成相应的代码来恢复被masked的碎片,因此OFA能够生成代码。
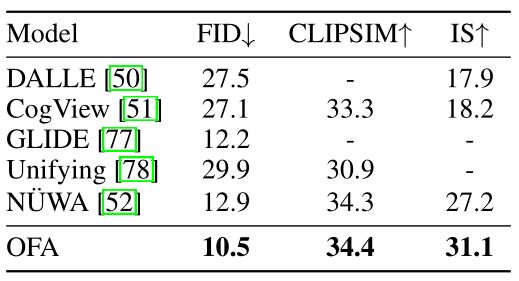
因此,我们在MSCOCO图像字幕数据集上直接对OFA进行微调,以实现文本到代码的生成。在推理阶段,我们另外用代码解码器将生成的代码转换为图像。具体来说,我们使用来自VQGAN的代码,遵循。实验结果表明,OFA在所有指标上都优于基线。需要注意的是,在推理过程中增加抽样大小预计会给FID和IS带来明显的改善。与DALLE、CogView和NÜWA相比,其采样规模分别为512、60和60,OFA在FID和IS上的表现优于这些SOTA方法,采样规模小得多24。这说明OFA在查询文本、图像和图像代码之间学会了更好的对应关系。
我们将OFA与CogView和GLIDE在正常和反事实查询的生成质量上进行了比较。正常查询描述了现实世界中的现有事物,而反事实查询指的是那些描述只能存在于我们想象中的事物。对于正常的查询,CogView和OFA都能生成与给定文本语义一致的图像,与GLIDE相比。从我们的模型中生成的例子可以提供更复杂的目标细节,例如马和双层巴士。对于反事实的查询,我们发现OFA是唯一能够生成三个想象中的场景的,这表明它的想象力是基于其强大的将文本与图像对齐的能力。
与最先进的文本-图像生成任务模型的定性比较:
5.2 单模态任务的结果
由于OFA的设计统一了不同的模态,我们对其在单模态任务上的表现进行评估,即自然语言和计算机视觉的任务。对于自然语言任务,我们在GLUE基准的6个自然语言理解任务和Gigaword抽象总结的自然语言生成任务中评估OFA。
对于计算机视觉,我们在经典的ImageNet-1K数据集上评估OFA,用于图像分类。
由于OFA已经在纯文本数据上进行了预训练,它可以直接迁移到自然语言的下游任务。
对于自然语言生成,它基本上是一个seq2seq的生成任务,对于自然语言表6:GLUE基准数据集的实验结果。
为便于比较,我们列出了多模态预训练模型以及最近只在自然语言数据上预训练的SOTA模型的性能。我们从MNLI上微调的checkpoint开始微调RTE和MRPC。
在理解方面,典型的是文本分类,我们把它们视为生成任务,其中标签基本上是单词序列。此外,对于每个任务,我们设计了一个手动指令,以表明模型应该回答什么类型的问题。
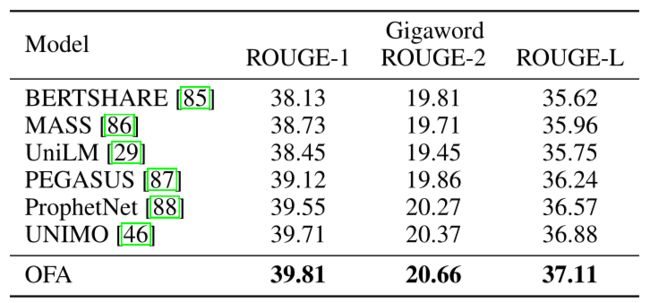
我们证明,即使是一个统一的多模态预训练模型也能在自然语言任务中取得极具竞争力的表现。具体来说,在自然语言理解的评估中,OFA在所有任务中都以较大的优势超过了多模态预训练模型。与最先进的自然语言预训练模型,包括RoBERTa、XLNET、ELECTRA和DeBERTa相比,OFA达到了相当的性能。在自然语言生成的评估中,OFA甚至在Gigaword数据集上达到了新的最先进的性能。
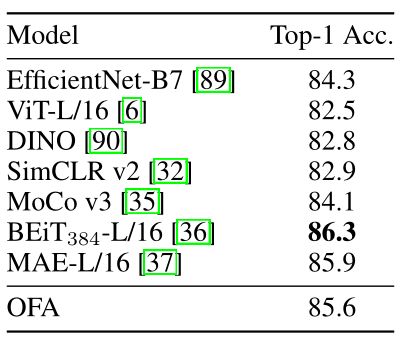
同时,OFA在图像分类方面也能达到一个有竞争力的性能。下表显示了OFA在图像分类上的表现。OFALarge比以前的主干模型如EfficientNet-B7和ViT-L取得了更高的准确性。
我们还将OFA与基于对比学习和masked图像建模的自监督预训练模型进行比较。OFA的性能优于基于对比的模型,如SimCLR和MoCo-v3,参数相似。与基于masked图像建模的预训练模型,如BEiT-L和MAE-L相比,OFA可以达到类似的性能。
上述在自然语言和视觉任务中的结果表明,一个统一的多模态预训练模型不仅在多模态任务中有效,而且还能处理单模态任务,在未来,这样的模型可能足以解决有关不同模态组合的复杂任务。
5.3 zero-shot学习和任务迁移
指令指导下的预训练使OFA能够进行zero-shot推理。继Uni-Perceiver之后,我们在GLUE基准的6个任务中评估我们的模型,包括单句分类和句对分类。下表显示,OFA总体上优于Uni-Perceiver。然而,两个模型在句对分类中都没有达到令人满意的表现(Acc. < 60%)。我们假设,预训练数据集中缺失的句对数据导致了性能的下降。

另外,我们发现模型的性能对指令的设计非常敏感。为了获得最好的结果,应该在可能的情况下从大量的候选指令库中寻找一个合适的指令模板。手动提示或模型参数的轻微变化可能会极大地影响模型的性能,这并不稳健。我们把这个问题留给未来的工作。
我们观察到,该模型可以通过新的任务指令很好地迁移到未见过的任务中。我们设计了一个新的任务,叫做定位的问答,并在下图中展示了例子。
在这种情况下,给定一个关于图像上某一区域的问题,模型应该提供一个正确的答案。我们发现,该模型在这个新任务中能取得令人满意的表现,这反映了其强大的可迁移性。此外,OFA可以解决域外输入数据的任务。例如,在域外图像的VQA中,不经过微调的OFA就取得了令人满意的性能。
下图中展示了一些例子。OFA还可以对域外图像,如动漫图片、合成图像等,进行准确的视觉定位。
对一个未见过的任务接地的QA的定性结果。我们设计了一个新的任务,叫做定位的问答,模型应该回答关于图像中某个区域的问题。

未见过的领域VQA的定性结果。在预训练期间,只有真实世界的照片被用于VQA。我们介绍了域外图像的VQA案例,即标志性的和科幻性的图像,并展示了它们迁移到未见域的能力。

文本到图像生成的例子。为了更好地演示,我们继续在LAION-400M的一个子集上对OFA进行微调。
更多关于未见过的领域的VQA任务的样本。答案是由预训练的OFA产生的,没有进行微调。用于VQA预训练任务的数据集只包含真实世界的照片。我们提出了更多关于域外(非照片)图像的VQA任务案例,并展示了将OFA迁移到这些未见域的能力。

未见过的定位问答任务的样本。在这个任务中,模型应该回答一个关于图像中某个特定区域的问题。这个任务在预训练中是未见过的。我们证明,直接将预训练的OFA迁移到这个新的任务,而不进行微调,效果很好。

六、测试结果




七、总结
在这项工作中,我们提出了OFA,一个支持任务全面性的任务无关和模态无关框架。OFA实现了架构、任务和模态的统一,因此能够实现多模态和单模态的理解和生成,而不需要额外的层或任务的规范。我们的实验表明,OFA在一系列的任务中创造了新的SOTA,包括图像字幕、VQA、视觉蕴含和指代表达理解。在单模态理解和生成任务中,例如GLUE、抽象概括和图像分类,OFA也表现出与语言/视觉预训练的SOTA模型相当的性能。我们提供了进一步的分析,以证明其在zero-shot学习和领域及任务迁移方面的能力,同时我们也验证了预训练任务的有效性。