《阿里大数据之路》研读笔记(2)维度表
前面的笔记地址:
《阿里大数据之路》研读笔记(1)_后季暖的博客-CSDN博客

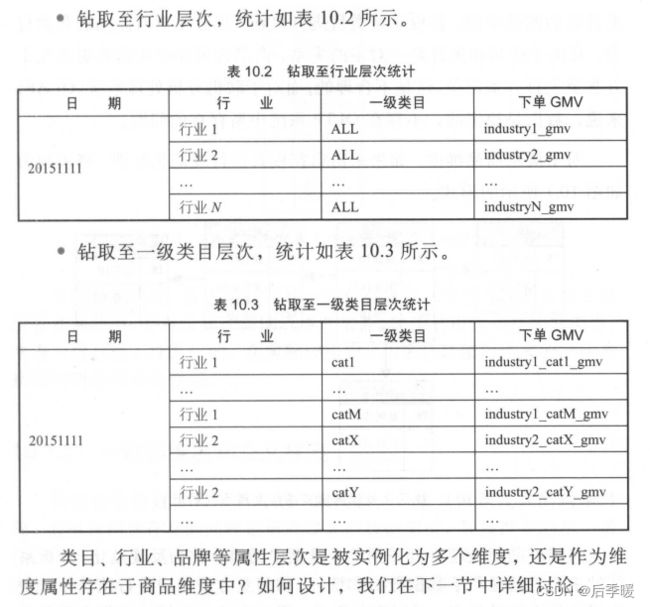




规范化和反规范化总结就是 规范化让总的单一维度变成多个维度 然后每个维度就是一张表这样 适合OLTP 可以参考三范式 这样是为了减少冗余 比如一个商品有多个类目(类目还有一些相关的字信息字段) ,属于多个行业(行业也带有相关的信息字段)这样可以直接把类目和行业各拆分成一张表 然后在商品表用两张维表的主键引用即可 这样能减少冗余 但是查询会比较缓慢 因为要join
所以反规范化在一定条件下适合OLAP 把这些需要的字段都放在一个表中 冗余就冗余 因为存储成本相对不高


这里解释下一致性上卷 比如一个类目对应多个商品 那么往往类目维度就是商品维度的子集 因为类目维度的字段可能更少 商品维度的字段可能更细一些 但是商品肯定包含它这个类目的所有属性 所以说类目是商品的子集 如果类目维度是公共的 基于类目维度 也可以 大概是这个意思

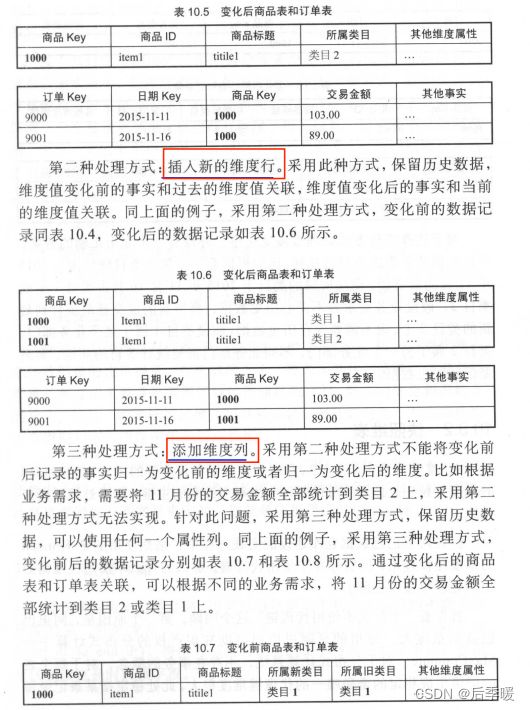
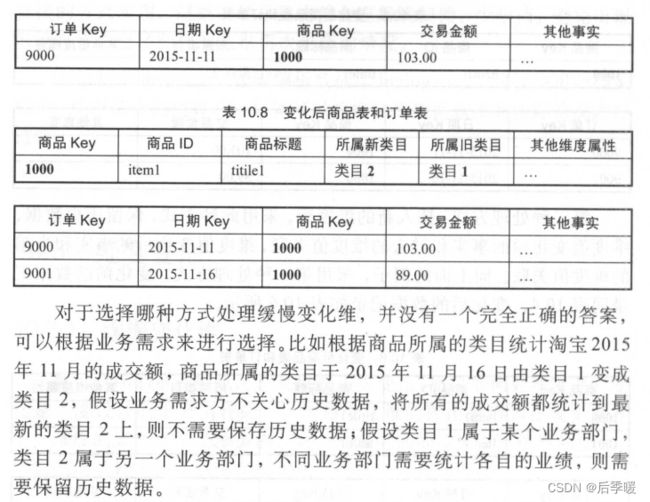
实际生产中常见的用拉链表处理缓慢变化维:
(2条消息) 拉链表与缓慢变化维_缓慢变化维和拉链表_码皮精的博客-CSDN博客


接下来先详细讲讲代理键的优劣 以及它为什么能处理缓慢变化维

代理键优缺点
优点
- 使用代理键能够使数据仓库环境对操作型环境的变化进行缓冲。也就是说,当数据仓库需要对来自多个操作型系统的数据进行整合时,这些系统中的数据有可能缺乏一致的关键字编码,即有可能出现重复,这时代理关键字可以解决这个问题。(在多个系统或者数据源的数据整合时,代理键能让每一条数据有一个唯一的id指代它,这样就可以避免整合时出现相同的数据没有覆盖还存在重复的情况。)
- 使用代理键可以带来性能上的优势。和自然关键字相比,代理关键字很小,是整型的,可以减小事实表中记录的长度。这样,同样的IO就可以读取更多的事实表记录。另外,整型字段作为外键连接的效率也很高。
- 使用代理键可以建立一些不存在的维度记录,例如“不在促销之列”,“日期待定”,“日期不可用”等维度记录。
- 使用代理键可以用来处理缓慢变化维。维度表数据的历史变化信息的保存是数据仓库设计的实施中非常重要的一部分。Kimball的缓慢变化维处理策略的核心就是使用代理键。
缺点
- 对于每个表的记录生成稳定的全局唯一的代理键难度很大,此处稳定指某条记录每一次生成的代理键都相同。(不同数据源假如相同的数据想让它们代理键相同比较困难)
- 第二个原因是,使用代理键会大大增加 ETL 的复杂性,对 ETL 任务的开发和维护成本很高。

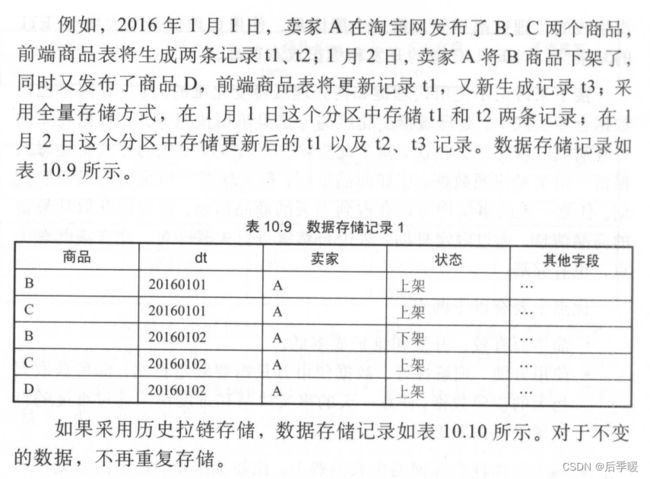
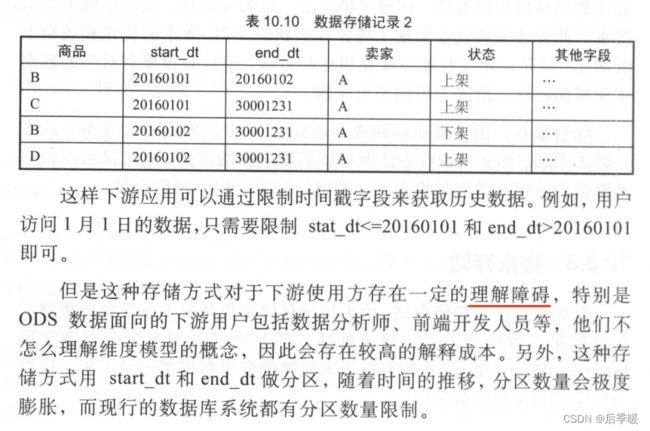



分月做历史拉链表如果这里理解不了 可以看:拉链表(一) - 知乎 (zhihu.com)
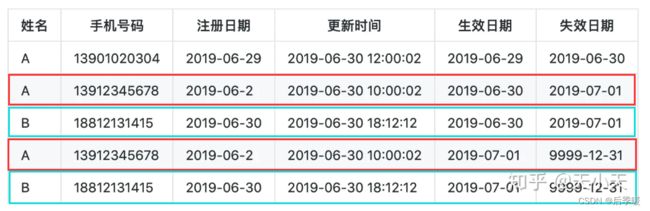
看完第一个可以看稍微复杂点的第二个(如何通过binlog采集MySQL的数据并且按月分区的方式实现拉链表):拉链表(二) - 知乎 (zhihu.com)
总结就是
每月2日:首先把上个月未失效的数据的end_date都改为这个月的1号(让它失效)
truncate table user_link_tmp;
-- 这里举例 此时是7月2日 要修正整个6月的数据
-- 把拉链表所有6月30日未失效的数据失效日期改为7月1日
insert into table user_link_tmp;
select
id,
name,
phone,
sing_up_date,
modify_time,
start_date,
'2019-07-01' as end_date
from user_link
where start_date<='2019-06-30'
and start_date>='2019-06-01'
and end_date='9999-12-31'然后再去查原表(原表不会因为上面的改动而变化!)把上一月的所有未失效的数据归并到这个月1日的分区中,把start_date改为1日,并且把end_date写成9999-12-31
-- 把6月未失效,并且今天也未失效的数据,改为开始日期7月1日,失效日期9999-12-31
insert into table user_link_tmp
select
id,
name,
phone,
sing_up_date,
modify_time,
'2019-07-01' as start_date,
'9999-12-31' as end_date
from user_link
where start_date<='2019-06-30'
and start_date>='2019-06-01'
and end_date='9999-12-31'
and id not in
(
select
id
from user_binlog
where pt_days='2019-07-01'
and type in ('update','delete')
group by id
); 并将1号新增的数据也写入start_date为1日,end_date为9999-12-31的分区
-- 把7月1日新的数据写入到临时表中
insert into table user_link_tmp
select
a.id,
a.name,
a.phone,
a.sing_up_date,
a.modify_time,
'2019-07-01' as start_date,
'9999-12-31' as end_date
from
(
select
id,
name,
phone,
sing_up_date,
modify_time
from user_binlog
where pt_days='2019-07-01'
) a
inner join
(
select
id,
max(modify_time)
from user_binlog
where pt_days='2019-07-01'
and type in ('insert','update')
group by id
) b
on a.id=b.id
and a.modify_time=b.modify_time这里就有个疑问 之前失效的数据怎么办呢?失效的数据当然还要 不用动就好
接下来把临时表的数据都重新覆盖到拉链表
最后删除上个月所有结束时间为9999-12-31分区的数据
-- 将临时表中的数据覆盖到拉链表中。
insert overwrite table user_link partition(start_date,end_date)
select
id,
name,
phone,
sing_up_date,
modify_time,
start_date,
end_date
from user_link_tmp;
-- 删除临时表中的数据
truncate table user_link_tmp;
-- 删除6月份所有结束时间为9999-12-31分区的数据
alter table user_link_tmp drop if exists partition(stat_date>='2019-06-01' , start_date<'2019-07-01', end_date='9999-12-31' );数据重跑
如果某个日期同步的数据出现问题需要重跑数据,则需要重跑从当日的同步SQL到当前日期所有的SQL才能保证数据准确。