YOLOv5图像和视频对象生成边界框的目标检测实践(GPU版本PyTorch错误处理)
识别图像和视频里面的对象,在计算机视觉中是一个很重要的应用,比如无人驾驶,这个就需要实时的检测到周边环境的各种对象,并及时做出处理。目标检测在以往的文章中有重点讲解过几种,其中Faster R-CNN的源码解读,本人做了一个系列,有兴趣的可以查阅:
MXNet的Faster R-CNN(基于区域提议网络的实时目标检测)《10》(尾) https://blog.csdn.net/weixin_41896770/article/details/128764171
https://blog.csdn.net/weixin_41896770/article/details/128764171
另外,单发多框检测SSD的学习,也有一个系列,有兴趣的可以去了解下:计算机视觉之SSD改进版本(平滑L1范数损失与焦点损失)《4》https://blog.csdn.net/weixin_41896770/article/details/128246764
只不过上面的方法在速度方便做不到实时,直到YOLO的出现,YOLO:You Only Look Once,你只需看一眼。意思就是它的效果跟人眼一样,只需要看一眼就可以识别图片中的各种对象。目前最新版本是YOLOv8,先拿YOLOv5版本试试效果。YOLO是永久免费且广泛被使用到各个地方的模型,无人驾驶中检测目标基本都是用到这个吧。
1、安装与测试
1.1、下载yolov5源码
克隆仓库,下载yolov5源码:git clone https://github.com/ultralytics/yolov5
切换到所在目录:cd yolov5
安装相关库:pip install -r requirements.txt -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
这里需要注意的是,强烈建议加上豆瓣镜像来安装相关库,不然requirements.txt里面的库很多的情况,很容易出现某个库下载超时等情况发生,造成安装不成功。
1.2、图片目标检测
我们来检测试下,除了单个图片检测之外,还可以直接指定图片所在目录,这样可以将整个目录(data/images)下面的图片都可以进行检测:
python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images
(pygpu) C:\Users\Tony\yolov5>python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images
detect: weights=['yolov5s.pt'], source=data/images, data=data\coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 v7.0-185-g2334aa7 Python-3.7.12 torch-1.13.1+cpu CPUDownloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt..
如果没有yolov5s.pt权重参数文件的情况,就会自动下载,这个可能需要科学上网或者很慢,不方便的朋友,我这里已经上传到了CSDN,可直接点击下载:yolov5s.pt,下载好了之后,放入到yolov5目录里面即可,其余的四种预训练模型如图:

上面是一些检测参数配置:权重、源、数据集、图像大小、置信度、交并比、检测数量等等,这里安装的CPU版本。
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
image 1/2 C:\Users\Tony\yolov5\data\images\bus.jpg: 640x480 4 persons, 1 bus, 183.1ms
image 2/2 C:\Users\Tony\yolov5\data\images\zidane.jpg: 384x640 2 persons, 2 ties, 134.1ms
Speed: 1.5ms pre-process, 158.6ms inference, 5.3ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp2
然后结果就是将标注对象的图片,保存在了自动新建的runs/detect/exp2目录里面,如图:


这两张是自带的,我重新放两张本人照片看下效果,检测标注的速度非常快:

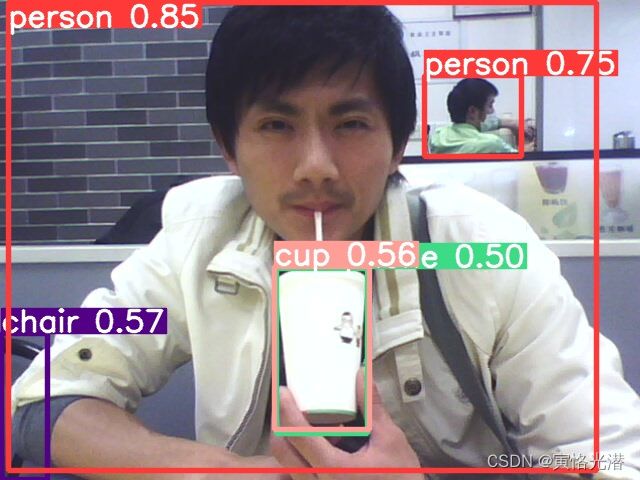
1.3、视频帧目标检测
除了检测图片之外,还可以检测视频,同样的可以指定视频,也可以指定视频所在目录:
python detect.py --weights yolov5s.pt --conf 0.25 --source data/videos
大家可以看下视频效果,基本上,人物、冷藏柜的瓶子这些都检测到了一些,速度非常快,而且检测的不错。YOLO对视频帧的检测
2、Inference推理
使用YOLOv5中的PyTorch Hub推理,将会自动下载最新版本的YOLOv5模型,也可以指定预训练模型,比如我们这节使用的yolov5s是常用的一种轻便快速的型号。
import torch
model = torch.hub.load("ultralytics/yolov5", "yolov5s")
#file, Path, PIL, OpenCV, numpy, list
img = "https://tenfei03.cfp.cn/creative/vcg/veer/1600water/veer-327742747.jpg"
results = model(img)
results.print() # or .show(), .save(), .crop(), .pandas(), etc.这里results的显示方法还是挺多的,分别来了解下:
2.1、results.print()
打印一些摘要信息,层数和参数数量,检测图片的宽高,检测到的对象等
Using cache found in C:\Users\Tony/.cache\torch\hub\ultralytics_yolov5_master
YOLOv5 2023-6-22 Python-3.7.12 torch-1.13.1+cpu CPUFusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
Adding AutoShape...
image 1/1: 720x1280 2 persons, 2 ties
Speed: 2480.2ms pre-process, 138.2ms inference, 2.0ms NMS per image at shape (1, 3, 384, 640)
2.2、results.show()
show方法显示目标检测并标注的图片:

2.3、results.save()
将生成标注的图片保存起来,地址是当前运行的目录:
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
Adding AutoShape...
Saved 1 image to runs\detect\exp
当然这个目录名exp,会随着每次新的生成而递增新建目录的,如exp2,exp3,exp4...
2.4、results.crop()
这个将会给检测到的每个对象进行分割,并分别保存到各自的目录中:

 2.5、results.pandas()
2.5、results.pandas()
使用表格形式显示坐标、置信度、类别等这样相关的信息,results.pandas().xyxy[0]:

比如显示坐标和宽高,results.pandas().xywh:
[ xcenter ycenter width height confidence class name
0 942.523499 384.171814 398.466187 671.656372 0.879861 0 person
1 469.287354 573.686462 54.595459 272.699463 0.675119 27 tie
2 418.870941 456.504700 591.639587 526.533203 0.666693 0 person
3 1002.146362 364.552826 46.313049 101.946716 0.261517 27 tie]
3、多GPU运行
YOLOv5模型可以通过线程推理并行加载到多个GPU上,提高运行速度,这里就需要用到GPU版本的了,下面将会重点介绍,需要安装GPU匹配版本来覆盖(自动卸载并安装)前面的CPU版本。
import torch
import threading
def run(model, im):
results = model(im)
results.save()
model0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)
model1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)
img1='https://tenfei03.cfp.cn/creative/vcg/veer/1600water/veer-327742747.jpg'
img2='https://tenfei01.cfp.cn/creative/vcg/veer/1600water/veer-419516485.jpg'
threading.Thread(target=run, args=[model0, img1], daemon=True).start()
threading.Thread(target=run, args=[model1, img2], daemon=True).start()如果你是在正确安装了CUDA、cuDNN、torch与torchvision之后,将可以正常处理图片了,当然我这里只有一块GPU,所以就只测试了device=0,如下图:
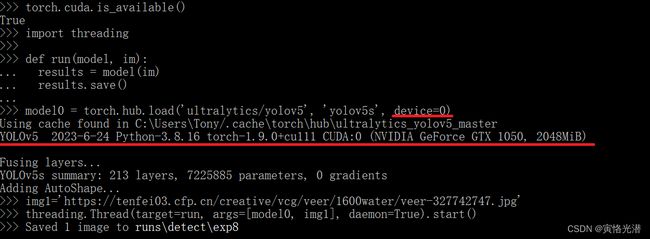
4、各种错误处理
在安装GPU版本的过程中,遇到了很多的错误需要处理,主要是一些安装版本匹配问题,对于这些安装存在的问题,只有通过不断的尝试,不断的出错,不断的思考,处理解决,这样后期对于安装的各种问题就会迎刃而解了。
4.1、Invalid CUDA
AssertionError: Invalid CUDA '--device 0' requested, use '--device cpu' or pass valid CUDA device(s)
CUDA是否正确安装,如下图使用命令测试下(nvcc --version和set cuda): 
如果上述命令不可用的,print(torch.cuda.is_available()),不出所料显示结果为:False
安装命令:conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
安装之后,再次查看就是True了,这个时候就可以使用到GPU设备了。但是别急,可能跟你的版本不一定匹配,看完之后再进行安装。
4.2、缺少模块
ModuleNotFoundError: No module named 'yaml'
如果缺少这个模块,注意了,安装的时候是pyyaml这个名称。
pip install pyyaml或conda install pyyaml
ModuleNotFoundError: No module named 'cv2'
这个名称为opencv-python
其余有缺少的情况,名称一样,安装即可。
当然这些模块(requirements.txt里面)都在最前面已经安装过了,只是换了虚拟环境忘记安装,来测试的时候出现这些情况,对于单独安装或缺失模块的可以这样进行。
4.3、安装GPU版本PyTorch
新建虚拟环境来安装,避免版本冲突。以下是安装的参考:
conda create -n torchgpu python=3.8
activate torchgpu
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
大块头的CUDA和cuDNN,下载地址:
CUDA:https://developer.nvidia.com/cuda-toolkit-archive
cuDNN:https://developer.nvidia.com/rdp/cudnn-download
PyTorch:https://pytorch.org/get-started/locally/
比如:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
当然这个有2G多,也是建议迅雷下载下来之后安装要好点
(个人推荐)版本匹配:https://download.pytorch.org/whl/torch_stable.html
比如本人的Python3.8版本,所以选择下载为cp38,这个torch2.0试过有问题然后更换到1.9。
pip install torch-2.0.1+cu118-cp38-cp38-win_amd64.whl
pip install torch-1.9.0+cu111-cp38-cp38-win_amd64.whl -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
这个根据自己版本来选择下载即可,1.9没有问题,有时候最新版本,造成其他的库不能匹配。
安装好了之后,测试下CUDA是否可用:
import torch
torch.cuda.is_available()
torch.cuda.get_device_name(0)如果分别显示True和显卡型号,就说明安装成功了。
4.4、NotImplementedError
如果出现下面这样的错误:
NotImplementedError: Could not run 'torchvision::nms' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'torchvision::nms' is only available for these backends: [CPU, QuantizedCPU, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradMPS, AutogradXPU, AutogradHPU, AutogradLazy, AutogradMeta, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
版本高了,不匹配,降低版本重新安装:
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html -i http://pypi.douban.com/simple
同样建议迅雷下载:https://download.pytorch.org/whl/cu111/torch-1.9.0%2Bcu111-cp38-cp38-win_amd64.whl
4.5、Python无法找到入口
出现弹框错误提示:
Python无法找到入口,无法定位程序输入点
ModuleNotFoundError: No module named 'torch.ao.quantization'
pip list查看,原来是torchvision还是原来的安装版本
torch 1.9.0+cu111
torchvision 0.15.2
进入站点:https://download.pytorch.org/whl/torch_stable.html 下载对应版本的torchvision
我这里对应的是:torchvision-0.10.0+cu111-cp38-cp38-win_amd64.whl
下载之后安装即可:pip install torchvision-0.10.0+cu111-cp38-cp38-win_amd64.whl
再次pip list查看torchvision的版本是否已更改
torch 1.9.0+cu111
torchvision 0.10.0+cu111
这样显示就说明版本已匹配
5、卸载虚拟环境
有时候这个安装会因为版本等问题,而新建了比较多的虚拟环境,为了清爽,可以将一些不需要的虚拟环境给卸载了,这样也可以节省不少空间出来。
退出虚拟环境:deactivate
删除xxx里面所有的目录与包:conda remove -n xxx --all
更多细节和源码:
github:https://github.com/ultralytics/yolov5