transformer 笔记
目录
目前在NLP领域当中,主要存在三种特征处理器——CNN、RNN 以及 Transformer,当前Transformer的流行程度已经大过CNN和RNN,它抛弃了传统CNN和RNN神经网络,整个网络结构完全由Attention机制以及前馈神经网络组成。
Transformer模型主要分为两大部分:Encoder和Decoder。Encoder负责把输入(语言序列)隐射成隐藏层,然后解码器再把隐藏层映射为自然语言序列。模型架构如下:
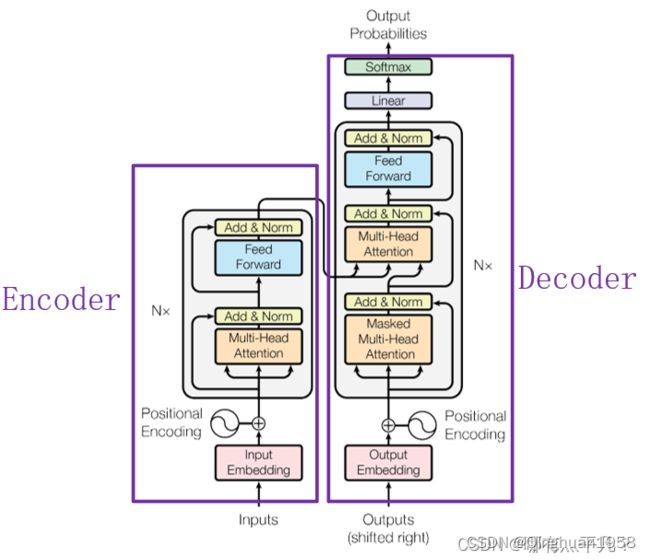
1.Input Embedding
编码方式:
- One-Hot Encoding
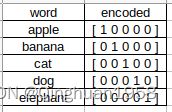
在 CV 中,输入图片通常表示为4维(batch, channel, height, weight)张量,而在 NLP 中,可以将输入单词用 One-Hot 形式编码成序列向量。向量长度是预定义的词汇表中拥有的单词量,向量在这一维中的值只有一个位置是1,其余都是0,1对应的位置就是词汇表中表示这个单词的地方。
例如词汇表中有5个词,那么第3个词cat对应的 one-hot 编码即为 00100(第3个位置为1,其余为0)
code
def one_hot(token_start,length):
one_hot_encode = torch.zeros(token_start.shape[0],length.int())
for i in range(token_start.shape[0]):
one_hot_encode[i,token_start[i].iterm()] = 1
return one_hot_encode
One-Hot 的形式看上去很简洁优美,但劣势在于它很稀疏,而且还可能很长。比如词汇表如果有 10k 个词,那么一个词向量的长度就需要达到 10k,而其中却仅有一个位置是1,其余全是0,太“浪费”!
更重要的是,这种方式无法体现出词与词之间的关系。比如 “爱” 和 “喜欢” 这两个词,它们的意思是相近的,但基于 one-hot 编码后的结果取决于它们在词汇表中的位置,无法体现出它们之间的关系。
因此,我们需要另一种词的表示方法,能够体现词与词之间的关系,使得意思相近的词有相近的表示结果,这种方法即 Word Embedding。
- Word Embedding
那该如何设计此Embedding呢?最方便的途径是设计一个可学习的权重矩阵 W,将词向量与这个矩阵进行点乘,即得到新的表示结果。
假设 “爱” 和 “喜欢” 这两个词经过 one-hot 后分别表示为 10000 和 00001,权重矩阵设计如下:
[ w00, w01, w02
w10, w11, w12
w20, w21, w22
w30, w31, w32
w40, w41, w42 ]
两个词点乘后的结果分别是 [w00, w01, w02] 和 [w40, w41, w42],在网络学习过程中权重矩阵的参数会不断进行更新(在翻译场景中它们被翻译的目标意思也相近,它们要学习的目标一致或相近),从而使得 [w00, w01, w02] 和 [w40, w41, w42] 的值越来越接近。
另一方面,对于以上这个例子,我们还把向量的维度从5维压缩到了3维。因此,word embedding 还可以起到降维的效果。
###在 Pytorch 框架下,可以使用 torch.nn.Embedding来实现 word embedding:
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
###vocab 代表词汇表中的单词量,即 one-hot 编码后词向量的长度;d_model代表权重矩阵的列数,通常为512,就是要将词向量的维度从 vocab 编码到 d_model。
https://zhuanlan.zhihu.com/p/372279569
2.position embedding
 因为 Transformer 摈弃了 RNN 的结构,因此需要一个东西来标记各个字之间的时序 or 位置关系,也就是位置嵌入。
因为 Transformer 摈弃了 RNN 的结构,因此需要一个东西来标记各个字之间的时序 or 位置关系,也就是位置嵌入。
如果让我们从 0 开始设计一个 Positional Encoding,比较容易想到的第一个方法是取 [0,1] 之间的数分配给每个字,其中 0 给第一个字,1 给最后一个字,具体公式为PE = pos / (T-1)
但问题在于,假设在较短文本中任意两个字位置编码的差为 0.1,同时在某一个较长文本中也有两个字的位置编码的差是 0.1。假设较短文本总共 10 个字,那么较短文本中的这两个字其实是相邻的;假设较长文本总共 20 个字,那么较长文本中这两个字中间实际上隔了两个字。这显然是不合适的,因为相同的差值,在不同的句子中却不是同一个含义。
另一个想法是线性的给每个时间步分配一个数字,也就是说,第一个单词被赋予 1,第二个单词被赋予 2,依此类推。这种方式也有很大的问题:1. 它比一般的字嵌入的数值要大,难免会抢了字嵌入的「风头」,对模型可能有一定的干扰;2. 最后一个字比第一个字大太多,和字嵌入合并后难免会出现特征在数值上的倾斜。
所以在理想情况下,位置嵌入的设计应该满足以下条件:
它应该为每个字输出唯一的编码
不同长度的句子之间,任何两个字之间的差值应该保持一致
它的值应该是有界的
作者设计的位置嵌入满足以上的要求。首先,它不是一个数字,而是一个包含句子中特定位置信息的
维向量。其次,这种嵌入方式没有集成到模型中,相反,这个向量是用来给句子中的每个字提供位置信息的,换句话说,我们通过注入每个字位置信息的方式,增强了模型的输入(其实说白了就是将位置嵌入和字嵌入相加,然后作为输入)
https://wmathor.com/index.php/archives/1453/
由于 Transformer 是并行地处理句子中的所有词,因此需要加入词在句子中的位置信息,结合了这种方式的词嵌入就是 Position Embedding 了。
那么具体该怎么做?我们通常容易想到两种方式:
1、通过网络来学习;
2、预定义一个函数,通过函数计算出位置信息;
Transformer 的作者对以上两种方式都做了探究,发现最终效果相当,于是采用了第2种方式,从而减少模型参数量,同时还能适应即使在训练集中没有出现过的句子长度。
论文中使用了sin和cos函数的线性变换来提供给模型位置信息:
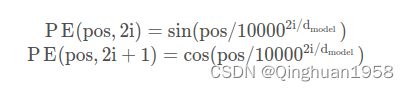
ques:为何使用三角函数呢?
由于三角函数的性质: sin(a+b) = sin(a)cos(b) + cos(a)sin(b)、 cos(a+b) = cos(a)cos(b) - sin(a)sin(b),于是,对于位置 pos+k 处的信息,可以由 pos 位置计算得到,作者认为这样可以让模型更容易地学习到位置信息。

为何使用这种方式编码能够代表不同位置信息呢?
由公式可知,每一维都对应不同周期的正余弦曲线: 时是周期为 的 函数, 时是周期为 的 函数…对于不同的两个位置 和 ,若它们在某一维 上有相同的编码值,则说明这两个位置的差值等于该维所在曲线的周期,即 。而对于另一个维度 ,由于 ,因此 和 在这个维度 上的编码值就不会相等,对于其它任意
也是如此。
综上可知,这种编码方式保证了不同位置在所有维度上不会被编码到完全一样的值,从而使每个位置都获得独一无二的编码。
就像论文原文中第六页讲的,位置嵌入函数的周期从 2 π 到 10000 ∗ 2 π 变化,而每一个位置在embedding dimension维度上都会得到不同周期的 sin 和 cos 函数的取值组合,从而产生独一的纹理位置信息,最终使得模型学到位置之间的依赖关系和自然语言的时序特性
下图是一串序列长度为50,位置编码维度为128的位置编码可视化结果:
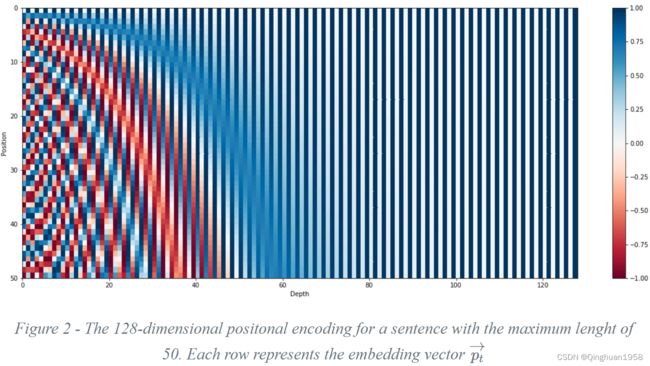 可以发现,由于sin/cos函数的性质,位置向量的每一个值都位于[-1, 1]之间。同时,纵向来看,图的右半边几乎都是蓝色的,这是因为越往后的位置,频率越小,波长越长,所以不同的t对最终的结果影响不大。而越往左边走,颜色交替的频率越频繁。
可以发现,由于sin/cos函数的性质,位置向量的每一个值都位于[-1, 1]之间。同时,纵向来看,图的右半边几乎都是蓝色的,这是因为越往后的位置,频率越小,波长越长,所以不同的t对最终的结果影响不大。而越往左边走,颜色交替的频率越频繁。
https://zhuanlan.zhihu.com/p/454482273
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
ques:Transformer 是以字作为输入,将字进行字嵌入之后,再与位置嵌入进行相加(不是拼接,就是单纯的对应位置上的数值进行加和),position embedding为什么是加法?
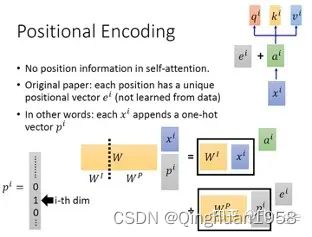
有上图可见,在原输入上 concat 一个代表位置信息的向量在经过线性变换后 等同于 将原输入经线性变换后直接加上位置编码信息。
3.selt attention & multi attention
self attention有什么优点呢,这里引用谷歌论文《Attention Is All You Need》里面说的,第一是计算复杂度小,第二是可以大量的并行计算,第三是可以更好的学习远距离依赖。
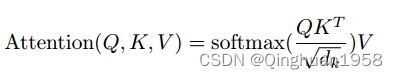
以两种图示说明其过程:
1.输入单词表示向量,比如可以是词向量。
2.把输入向量映射到q、k、v三个变量,如下图:
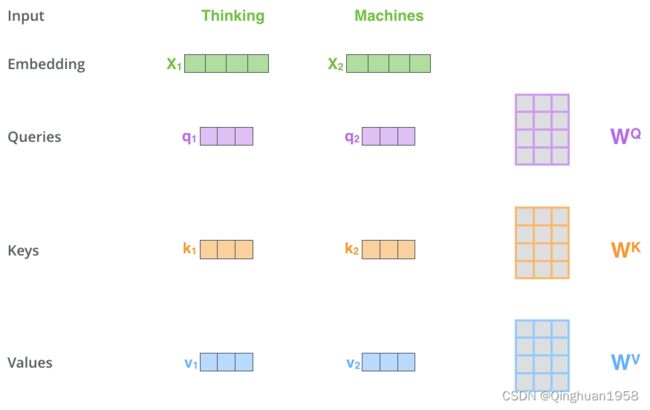
X1和X2分别是Thinking和Machines这两个单词的词向量,q1和q2被称为查询向量,k称为键向量,v称为值向量。Wq,Wk,Wv都是随机初始化的映射矩阵。
3.计算Attention score,即某个单词的查询向量和各个单词对应的键向量的匹配度,匹配度可以通过加法或点积得到。减小score,并将score转换为权重。
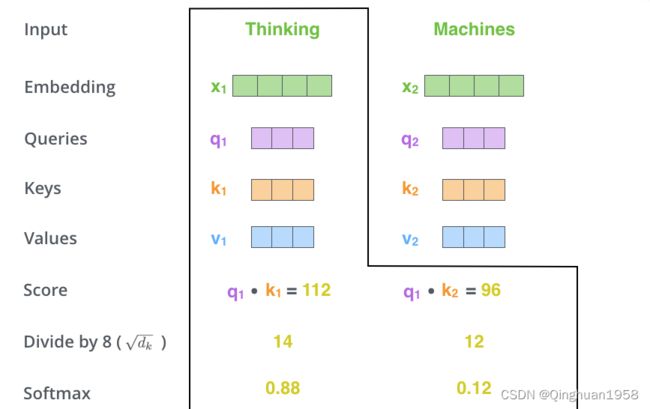
其中dk是q k v的维度。score可以通过点积和加法得到,当dk较小时,这两种方法得到的结果很相似。但是点积的速度更快和省空间。但是当dk较大时,加法计算score优于点积结果没有除以dk^0.5的情况。原因可能是:the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients。所以要先除以dk^0.5,再进行softmax。
4.权重乘以v,并求和。
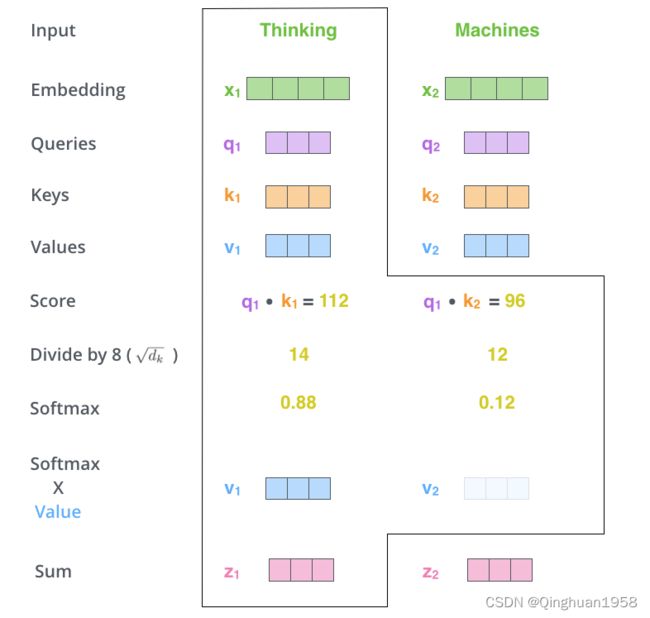
最终的结果z1就是x1这个单词的Attention向量。
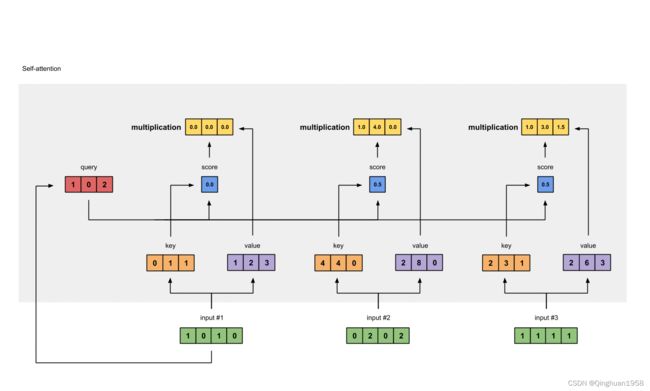
当同时计算所有单词的Attention时,图示如下:
1将输入词向量转换为Q、K、V.
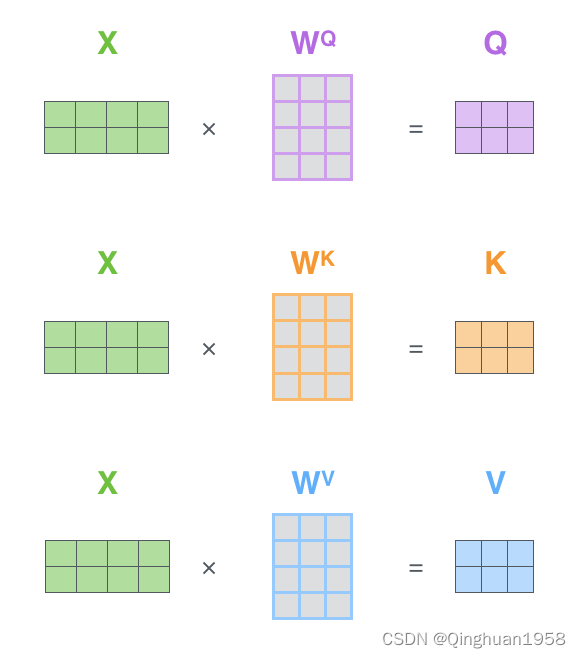
2. 直接计算Z
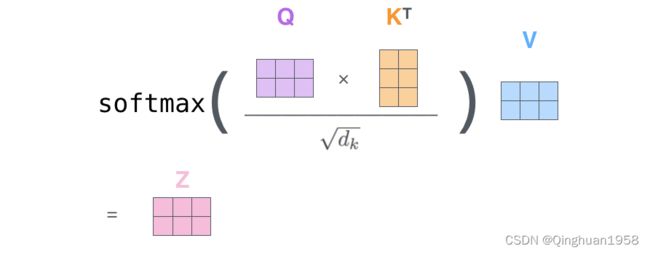 第二种 动图解释
第二种 动图解释
 详细介绍
详细介绍
Multi-Head Attention原理
不同的随机初始化映射矩阵Wq,Wk,Wv 可以将输入向量映射到不同的子空间,这可以让模型从不同角度理解输入的序列。因此同时几个Attention的组合效果可能会优于单个Attenion,这种同时计算多个Attention的方法被称为Multi-Head Attention,或者多头注意力。
每个“Head”都会产生一个输出向量z,但是我们一般只需要一个,因此还需要一个矩阵把多个合并的注意力向量映射为单个向量。
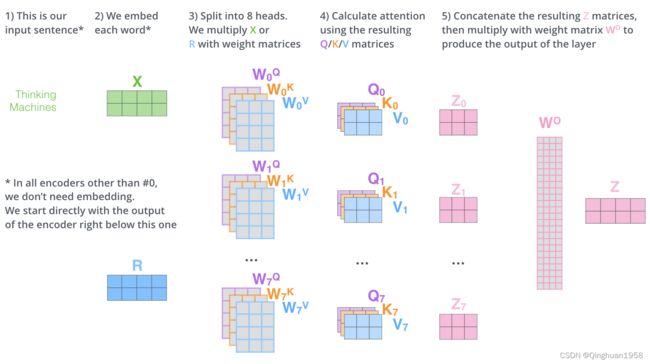
第二种解释
(不知道怎么去下标,引用自【霹雳吧啦)
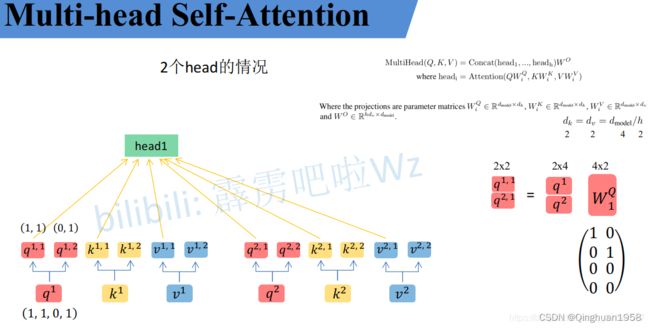


 multi head :首先还是和Self-Attention模块一样将 a i 分别通过 W q , W k , W v到对应的 q i , k i , v i ,然后再根据使用的head的数目 h h h进一步把得到的 q i , k i , v i 均分成 h份。比如下图中假设 h=2然后 q 1 拆分成 q 1 , 1 q1,2,那么 q 1 , 1 就属于head1, q 1 , 2 属于head2.
multi head :首先还是和Self-Attention模块一样将 a i 分别通过 W q , W k , W v到对应的 q i , k i , v i ,然后再根据使用的head的数目 h h h进一步把得到的 q i , k i , v i 均分成 h份。比如下图中假设 h=2然后 q 1 拆分成 q 1 , 1 q1,2,那么 q 1 , 1 就属于head1, q 1 , 2 属于head2.
但论文中写的通过 映射得到每个head的 Q i , K i , V i :
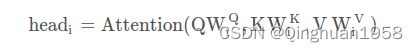
在github上一些源码中就是简单的进行均分,其实也可以将 W i Q , W i K , W i V 设置成对应值来实现均分。
ques:为什么要除以sqrt dk
论文中给出了解释:在 d k比较小的时候,不加缩放的效果和加性attention的效果差不多,但当 d k比较大的时候,不加缩放的效果就明显比加性attention的效果要差,怀疑是当 d k增长的时候,内积的量级也会增长,导致softmax函数会被推向梯度较小的区域,为了缓解这个问题,加上了这个缩放项进行量级缩小。
Softmax
为什么要加 softmax() ,因为权重必须为概率分布即和为1。softmax() 里面 Q 部分算的就是注意力的原始分数,通过计算Q(query)与K(key)的点积得到相似度分数,其中 [公式] 起到一个调节作用,不至于过大或过小,导致 softmax() 里面 dk 部分之后就非0即1。因此这种注意力的形式也叫放缩的点积注意力
如果仔细观察刚刚讲的Self-Attention和Multi-Head Attention模块,在计算中是没有考虑到位置信息的。假设在Self-Attention模块中,输入 a 1 , a 2 , a 3 得到 b 1 , b 2 , b 3 。对于 a 1 而言, a 2和 a 3离它都是一样近的而且没有先后顺序。假设将输入的顺序改为 a 1 , a 3 , a 2 对结果 b 1是没有任何影响的,为了引入位置信息,在原论文中引入了位置编码positional encodings。


引用链接在这里
4.残差连接和Layer Normalization
残差连接
我们在上一步得到了经过self-attention加权之后输出,也就是 A t t e n t i o n ( Q , K , V ) 然后把他们加起来做残差连接Xembedding+Self Attention(Q, K, V)
Layer Normalization
Layer Normalization的作用是把神经网络中隐藏层归一为标准正态分布,也就是 i . i . d i.i.d i.i.d独立同分布,以起到加快训练速度,加速收敛的作用
https://blog.csdn.net/qq_37236745/article/details/107352167
5. 前馈网络
这部分是整体架构图中的Feed Forward模块,其实就是一个简单的全连接前馈网络。它由两层全连接及ReLU激活函数构成,计算公式如下:
![]()
这里的全连接是Position-wise逐位置的,即设前面的attention输出的维度为 B ∗ L e n g t h ∗ d model 则变换时,实际上是只针对 d model 进行变换,对于每个位置(Length维度)上,都使用同样的变换矩阵。
在论文中,这里的d model 仍然是512,两层全连接的中间隐层单元数为 d f f =2048。
6.Masked Self-Attention
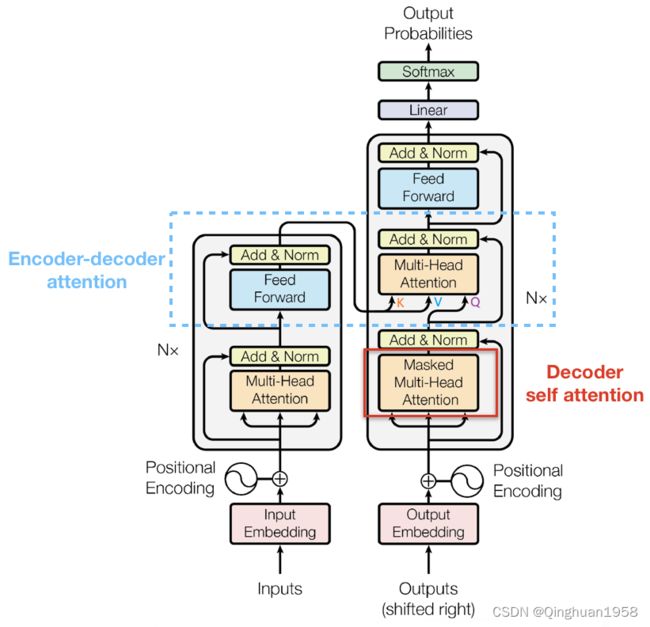
具体来说,传统Seq2Seq中Decoder使用的是RNN模型,因此在训练过程中输入t时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当t时刻运算结束了,才能看到 t + 1 时刻的词。而Transformer Decoder抛弃了RNN,改为Self-Attention,由此就产生了一个问题,在训练过程中,整个ground truth都暴露在Decoder中,这显然是不对的,我们需要对Decoder的输入进行一些处理,该处理被称为Mask
举个例子,Decoder的ground truth为" I am fine",我们将这个句子输入到Decoder中,经过WordEmbedding和Positional Encoding之后,将得到的矩阵做三次线性变换( W Q , W K , W V)。然后进行self-attention操作,首先通过 Q × K T /gendk
得到Scaled Scores,接下来非常关键,我们要对Scaled Scores进行Mask,举个例子,当我们输入"I"时,模型目前仅知道包括"I"在内之前所有字的信息,即""和"I"的信息,不应该让其知道"I"之后词的信息。道理很简单,我们做预测的时候是按照顺序一个字一个字的预测,怎么能这个字都没预测完,就已经知道后面字的信息了呢?
Mask非常简单,首先生成一个下三角全0,上三角全为负无穷的矩阵,然后将其与Scaled Scores相加即可
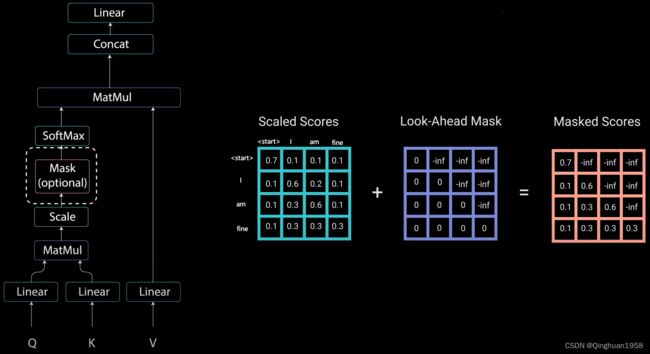
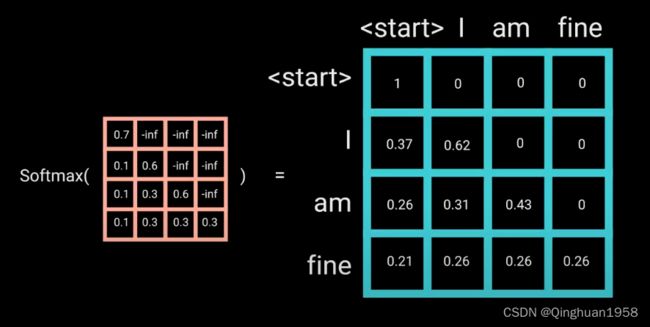
之后再做softmax,就能将-inf变为0,得到的这个矩阵即为每个字之间的权重
 Multi-Head Self-Attention无非就是并行的对上述步骤多做几次
Multi-Head Self-Attention无非就是并行的对上述步骤多做几次
Masked Encoder-Decoder Attention
其实这一部分的计算流程和前面Masked Self-Attention很相似,结构也一摸一样,唯一不同的是这里的 K , V K,V K,V为Encoder的输出,Q为Decoder中Masked Self-Attention的输出
 https://blog.csdn.net/qq_37236745/article/details/107352167
https://blog.csdn.net/qq_37236745/article/details/107352167
常见问题总结
ques: Transformer为什么需要进行Multi-head Attention?
原论文中说到进行Multi-head Attention的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。其实直观上也可以想到,如果自己设计这样的一个模型,必然也不会只做一次attention,多次attention综合的结果至少能够起到增强模型的作用,也可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息
注解:简单回答就是,多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。
个人理解为类以于CNN中权重矩阵
Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
使用Q/K/V不相同可以保证在不同空间进行投影,增强了表达能力,提高了泛化能力。
两个向量的点乘表示两个向量的相似度, 如果在同一个向量空间里进行点乘,理所应当的是自身和自身的相似度最大,那会影响其他向量对自己的作用,
https://www.zhihu.com/question/319339652
Transformer计算attention的时候为何选择点乘而不是加法?
为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。
https://www.zhihu.com/tardis/bd/art/366993073?source_id=1001
为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
这取决于softmax函数的特性,如果softmax内计算的数数量级太大,会输出近似one-hot编码的形式,导致梯度消失的问题,所以需要scale
那么至于为什么需要用维度开根号,假设向量q,k满足各分量独立同分布,均值为0,方差为1,那么qk点积均值为0,方差为dk,从统计学计算,若果让qk点积的方差控制在1,需要将其除以dk的平方根,是的softmax更加平滑
https://blog.csdn.net/zhuzyibooooo/article/details/126063398
https://blog.csdn.net/qq_37430422/article/details/105042303
上面计算相似度s=
对于两个d维向量q,k,假设它们都采样自“均值为0、方差为1”的分布。Attention是内积后softmax,主要设计的运算是 e^ q⋅k,我们可以大致认为内积之后、softmax 之前的数值在 − 3sqrt{d}
到 3 sqrt{d}这个范围内,由于d通常都至少是64,所以 e^ 3 sqrt{d}比较大而 e ^ −3 sqrt{d}比较小,softmax 函数进入饱和区。这样会有两个影响:
1 带来严重的梯度消失问题,导致训练效果差。
2 softmax 之后,归一化后计算出来的结果a要么趋近于1要么趋近于0,Attention的分布非常接近一个one hot分布了,加权求和退化成胜者全拿,则解码时只关注注意力最高的(attention模型还是希望别的词也有权重)
相应地,解决方法就有两个:(参考苏剑林《浅谈Transformer的初始化、参数化与标准化》)
像NTK参数化那样,在内积之后除以 sqrt d,使q⋅k的方差变为1,对应 e ^3 , e ^−3都不至于过大过小,这也是常规的Transformer如BERT里边的Self Attention的做法。对公式s=
另外就是不除以 sqrt{d}, 但是初始化q,k的全连接层的时候,其初始化方差要多除以一个d,这同样能使得使q⋅k的初始方差变为1,T5采用了这样的做法。
https://blog.csdn.net/qq_56591814/article/details/119759105Transformer
Transformer相比于RNN/LSTM,有什么优势?为什么?
RNN系列的模型,无法并行计算,因为 T 时刻的计算依赖 T-1 时刻的隐层计算结果,而 T-1 时刻的计算依赖 T-2 时刻的隐层计算结果
Transformer的特征抽取能力比RNN系列的模型要好
为什么说Transformer可以代替seq2seq?
这里用代替这个词略显不妥当,seq2seq虽已老,但始终还是有其用武之地,seq2seq最大的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失Encoder端的很多信息,而且这样一股脑的把该固定向量送入Decoder端,Decoder端不能够关注到其想要关注的信息。Transformer不但对seq2seq模型这两点缺点有了实质性的改进(多头交互式attention模块),而且还引入了self-attention模块,让源序列和目标序列首先“自关联”起来,这样的话,源序列和目标序列自身的embedding表示所蕴含的信息更加丰富,而且后续的FFN层也增强了模型的表达能力,并且Transformer并行计算的能力远远超过了seq2seq系列模型
在计算attention score的时候如何对padding做mask操作?
padding位置置为负无穷(一般来说-1000就可以)。
为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息
基本结构:Embedding + Position Embedding,Self-Attention,Add + LN,FN,Add + LN
为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
简单介绍一下Transformer的位置编码?有什么意义和优缺点?
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
你还了解哪些关于位置编码的技术,各自的优缺点是什么?(参考上一题)
相对位置编码(RPE)1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
Transformer中的残差结构以及意义。
就是ResNet的优点,解决梯度消失
为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
LN:针对每个样本序列进行Norm,没有样本间的依赖。对一个序列的不同特征维度进行Norm
CV使用BN是认为channel维度的信息对cv方面有重要意义,如果对channel维度也归一化会造成不同通道信息一定的损失。而同理nlp领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
简答讲一下BatchNorm技术,以及它的优缺点。
优点:
第一个就是可以解决内部协变量偏移,简单来说训练过程中,各层分布不同,增大了学习难度,BN缓解了这个问题。当然后来也有论文证明BN有作用和这个没关系,而是可以使损失平面更加的平滑,从而加快的收敛速度。
第二个优点就是缓解了梯度饱和问题(如果使用sigmoid激活函数的话),加快收敛。
缺点:
第一个,batch_size较小的时候,效果差。这一点很容易理解。BN的过程,使用 整个batch中样本的均值和方差来模拟全部数据的均值和方差,在batch_size 较小的时候,效果肯定不好。
第二个缺点就是 BN 在RNN中效果比较差。
简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
ReLU
Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
Cross Self-Attention,Decoder提供Q,Encoder提供K,V
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
让输入序列只看到过去的信息,不能让他看到未来的信息
Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
Encoder侧:模块之间是串行的,一个模块计算的结果做为下一个模块的输入,互相之前有依赖关系。从每个模块的角度来说,注意力层和前馈神经层这两个子模块单独来看都是可以并行的,不同单词之间是没有依赖关系的。
Decode引入sequence mask就是为了并行化训练,Decoder推理过程没有并行,只能一个一个的解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题),传统词tokenization方法不利于模型学习词缀之间的关系”
BPE(字节对编码)或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。后期使用时需要一个替换表来重建原始数据。
优点:可以有效地平衡词汇表大小和步数(编码句子所需的token次数)。
缺点:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 1在测试的需要有什么需要注意的吗?
Dropout测试的时候记得对输入整体呈上dropout的比率
引申一个关于bert问题,bert 的mask为何不学习transformer在attention处进行屏蔽score的技巧?
BERT和transformer的目标不一致,bert是语言的预训练模型,需要充分考虑上下文的关系,而transformer主要考虑句子中第i个元素与前i-1个元素的关系。