模型构建——使用逻辑回归构建模型,lightGBM进行特征筛选
1、模型构建流程
1.1 实验设计
新的模型要跟原有方案对比,而且是通过实验证明,特别注意模型和策略不能同时调整。一般实验设计包含以下流程:

问题:业务稳定后,可以去掉人工审核吗?
答:不可以,一般模型上线后,高分段和低分段的表现较好,但中间段还是需要人工审核;而且即使模型完善后,我们只能减少人工审核,不可能完全舍弃人工审核。
1.2 样本设计
1.3 模型训练与评估
在进行模型选择与评估时,我们按照以下顺序进行模型评估:可解释性>稳定性>区分度。
区分度指标:AUC和KS
稳定性指标:PSI
AUC:ROC曲线下的面积,反映了模型输出的概率对好坏用户的排序能力,是模型区分度的平均状况。
KS:反映了好坏用户的分布的最大的差别,是模型区分度的最佳状况。
业务指标里,主要看通过率和逾期率。在合理逾期率的前提下,尽可能提高通过率。
A卡:更注重通过率,逾期率可以稍微低一些;
B卡:想办法降低逾期率,给好的用户提高额度。
2、逻辑回归模型构建
逻辑回归本质上还是一个回归问题,它的输出结果是[0,1]之间,那么这个结果可以对应到用户的违约概率上,我们可以将违约概率映射到评分上。
例如:
业内标准的评分卡换算公式 s c o r e = 650 + 50 l o g 2 ( P 逾期 / P 未逾期 ) score = 650+50log_{2}(P_{逾期}/P_{未逾期}) score=650+50log2(P逾期/P未逾期),那么这里怎么转化过去呢?我们来看以下的Sigmoid函数:
y = 1 1 + e − z = 1 1 + e − ( w T x + b ) y = \frac{1}{1+e^{-z}} = \frac{1}{1+e^{-(w^Tx+b)}} y=1+e−z1=1+e−(wTx+b)1
可以转化为以下公式:
l n ( y 1 − y ) = w T x + b ln(\frac{y}{1-y})=w^Tx+b ln(1−yy)=wTx+b
而我们评分换算公式可以进行以下变换:
l o g 2 ( P 逾期 / P 未逾期 ) = l n ( P 逾期 1 − P 逾期 ) / l n ( 2 ) = ( w T x + b ) / l n ( 2 ) log_{2}(P_{逾期}/P_{未逾期}) = ln(\frac{P_{逾期}}{1-P_{逾期}})/ln(2) = (w^Tx+b)/ln(2) log2(P逾期/P未逾期)=ln(1−P逾期P逾期)/ln(2)=(wTx+b)/ln(2)
所以我们只需要解出逻辑回归中每个特征的系数,然后将样本的每个特征值加权求和即可得到客户当前的标准化信用评分。其中评分换算公式中的650和50是举例的,实际需要根据业务进行调整。
逻辑回归构建评分卡代码
导入模型
# 导入所需要的模块
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
import numpy as np
import random
import math
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
查看数据基本信息
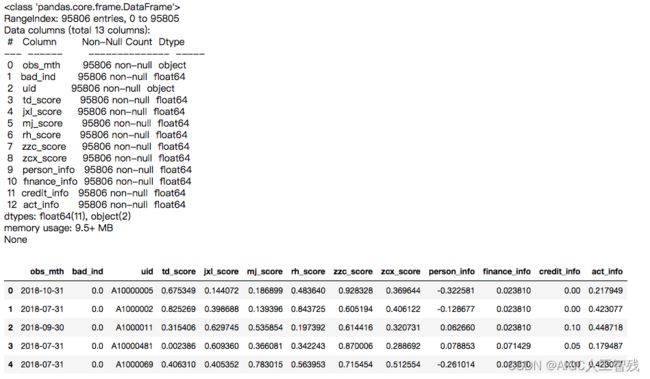
df = pd.read_csv('Bcard.txt', encoding='utf-8')
print(df.info())
df.head()
'''
bad_ind 为标签
外部评分数据:td_score,jxl_score,mj_score,rh_score,zzc_score,zcx_score
内部数据: person_info, finance_info, credit_info, act_info
obs_month: 申请日期所在月份的最后一天(数据经过处理,将日期都处理成当月最后一天)
'''
# 看一下申请日期的分布,我们将最后一个月作为测试集,其他作为训练集
print(df.obs_mth.unique())
print(df.bad_ind.describe())

划分训练集和测试集
train_df =df[df['obs_mth']!='2018-11-30'].reset_index()
test_df = df[df['obs_mth'] == '2018-11-30'].reset_index()
将所有特征进行模型训练
# 没有进行特征筛选的逻辑回归模型
feature_lst = df.columns.drop(['obs_mth','bad_ind','uid'])
train_X = train_df[feature_lst]
train_y = train_df['bad_ind']
test_X = test_df[feature_lst]
test_y = test_df['bad_ind']
lr_model = LogisticRegression(C=0.1)
lr_model.fit(train_X,train_y)
# 对模型进行评估,这里使用predict_proba返回概率值,左边为预测为0的概率,右边为预测为1的概率,我们取1的概率
# 测试集
y_prob = lr_model.predict_proba(test_X)[:,1]
auc = roc_auc_score(test_y,y_prob)
fpr_lr,tpr_lr,_ = roc_curve(test_y,y_prob)
test_KS = max(tpr_lr-fpr_lr)
# 训练集
y_prob_train = lr_model.predict_proba(train_X)[:,1]
auc_train = roc_auc_score(train_y,y_prob_train)
fpr_lr_train,tpr_lr_train,_ = roc_curve(train_y,y_prob_train)
train_KS = max(tpr_lr_train-fpr_lr_train)
plt.plot(fpr_lr,tpr_lr,label = 'test LR auc=%0.3f'%auc) #绘制训练集ROC
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR auc=%0.3f'%auc_train) #绘制验证集ROC
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
print('训练集的KS:%0.3f'%train_KS)
print('测试集的KS:%0.3f'%test_KS)

用lightgbm对特征进行筛选
# 对特征进行筛选,让模型更准确
import lightgbm as lgb
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_X, train_y, random_state = 0, test_size=0.2)
lgb_clf = lgb.LGBMClassifier(boosting_type='gbdt',
objective = 'binary',
metric = 'auc',
learning_rate=0.1,
n_estimators=24,
max_depth=5,
num_leaves=20,
max_bin=45,
min_data_in_leaf = 6,
bagging_fraction = 0.6,
bagging_freq = 0,
feature_fraction = 0.8)
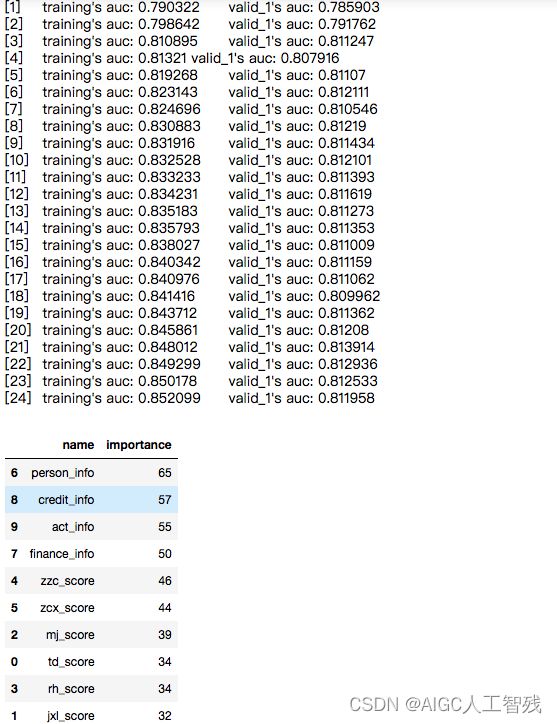
lgb_clf.fit(X_train, y_train,eval_set=[(X_train, y_train),(X_test, y_test)], eval_metric='auc')
lgb_auc = lgb_clf.best_score_['valid_1']['auc']
feature_importance = pd.DataFrame({'name':lgb_clf.booster_.feature_name(),
'importance':lgb_clf.feature_importances_}).sort_values(by='importance', ascending=False)
feature_importance
使用筛选后的四个特征构建模型
# 使用排名靠前的四个特征进行新的模型构建
feature_lst = feature_importance['name'][0:4]
train_X = train_df[feature_lst]
train_y = train_df['bad_ind']
test_X = test_df[feature_lst]
test_y = test_df['bad_ind']
lr_model = LogisticRegression(C=0.1)
lr_model.fit(train_X,train_y)
# 对模型进行评估,这里使用predict_proba返回概率值,左边为预测为0的概率,右边为预测为1的概率,我们取1的概率
# 测试集
y_prob = lr_model.predict_proba(test_X)[:,1]
auc = roc_auc_score(test_y,y_prob)
fpr_lr,tpr_lr,_ = roc_curve(test_y,y_prob)
test_KS = max(tpr_lr-fpr_lr)
# 训练集
y_prob_train = lr_model.predict_proba(train_X)[:,1]
auc_train = roc_auc_score(train_y,y_prob_train)
fpr_lr_train,tpr_lr_train,_ = roc_curve(train_y,y_prob_train)
train_KS = max(tpr_lr_train-fpr_lr_train)
plt.plot(fpr_lr,tpr_lr,label = 'test LR auc=%0.3f'%auc) #绘制训练集ROC
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR auc=%0.3f'%auc_train) #绘制验证集ROC
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
print('训练集的KS:%0.3f'%train_KS)
print('测试集的KS:%0.3f'%test_KS)
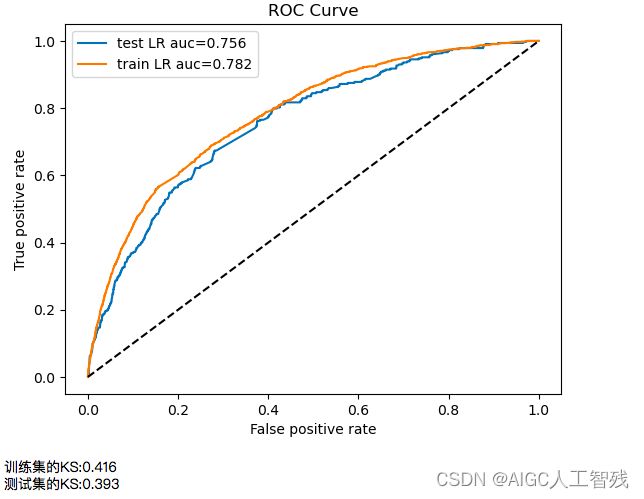
经过筛选后的模型针对测试集的数据,KS和AUC都更高,结果更加稳定。
打印回归系数
# 打印回归系数
print('变量名单:',feature_lst)
print('系数:',lr_model.coef_)
print('截距:',lr_model.intercept_)

生成报告
# 生成报告
# 计算出报告中所需要的字段:KS值、负样本个数、正样本个数、负样本累计个数、正样本累计个数、捕获率、负样本占比
temp_ = pd.DataFrame()
temp_['predict_bad_prob'] = lr_model.predict_proba(test_X)[:,1]
temp_['real_bad'] = test_y
temp_.sort_values('predict_bad_prob', ascending=False, inplace=True)
temp_['num'] = [i for i in range(temp_.shape[0])]
temp_['num'] = pd.cut(temp_.num, bins=20,labels=[i for i in range(20)])
temp_
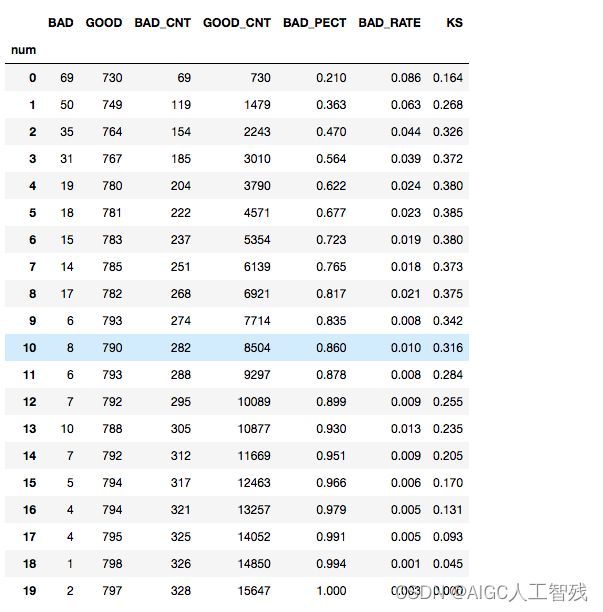
report = pd.DataFrame()
report['BAD'] = temp_.groupby('num').real_bad.sum().astype(int)
report['GOOD'] = temp_.groupby('num').real_bad.count().astype(int) - report['BAD']
report['BAD_CNT'] = report['BAD'].cumsum()
report['GOOD_CNT'] = report['GOOD'].cumsum()
good_total = report['GOOD_CNT'].max()
bad_total = report['BAD_CNT'].max()
report['BAD_PECT'] = round(report.BAD_CNT/bad_total,3)
report['BAD_RATE'] = report.apply(lambda x:round(x.BAD/(x.BAD+x.GOOD),3), axis=1)
# 计算KS值
def cal_ks(x):
ks = (x.BAD_CNT/bad_total)-(x.GOOD_CNT/good_total)
return round(math.fabs(ks),3)
report['KS'] = report.apply(cal_ks,axis=1)
report
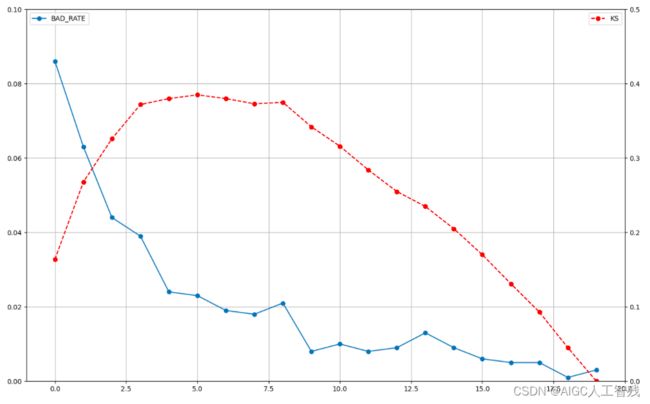
绘制BAD_RATE和KS的折线图
# 绘制出折线图badrate和ks图
fig = plt.figure(figsize=(16,10))
ax = fig.add_subplot(111)
ax.plot(report.index.values.to_list(), report.BAD_RATE, '-o', label='BAD_RATE')
ax2 = ax.twinx()
ax2.plot(report.index.values.to_list(), report.KS, '--o', color='red',label='KS')
ax.grid()
ax.set_xlim(-1,20,5)
ax.set_ylim(0,0.1)
ax2.set_ylim(0,0.5)
ax.legend(loc=2)
ax2.legend(loc=0)
构建评分公式,对每个客户进行评分
'''
6 person_info
8 credit_info
9 act_info
7 finance_info
Name: name, dtype: object
系数: [[ 2.48386162 1.88254182 -1.43356854 4.44901224]]
截距: [-3.90631899]
'''
# 计算每个客户的评分
def score(person_info,credit_info,act_info,finance_info):
xbeta = person_info*2.48386162+credit_info*1.88254182+act_info*(-1.43356854)+finance_info*4.44901224-3.90631899
score = 900+50*(xbeta)/(math.log(2))
return score
test_df['score'] = test_df.apply(lambda x:score(x.person_info,x.credit_info,x.act_info,x.finance_info), axis=1)
fpr_lr,tpr_lr,_ = roc_curve(test_y,test_df['score'])
print('val_ks:', abs(fpr_lr-tpr_lr).max())
![]()
根据评分划分等级,可以得到每个组别的逾期率
# 根据评分进行划分等级
def level(score):
level = ''
if score <= 600:
level = "D"
elif score <= 640 and score > 600 :
level = "C"
elif score <= 680 and score > 640:
level = "B"
elif score > 680 :
level = "A"
return level
test_df['level'] = test_df.score.map(lambda x:level(x))
test_df.level.groupby(test_df.level).count()/len(test_df)

结论
- 从报告中可以看出:
- 模型的KS最大值出现在第6箱(编号5),如将箱分的更细,KS值会继续增大,上限为前面通过公式计算出的KS值。
- 前4箱的样本占总人数的20%,捕捉负样本占所有负样本的56.4%。
- 从折线图可以看出:
- 模型在第8箱的位置出现了波动,即第8箱的负样本占比高于第7箱
- 虽然曲线图中有多处波动,但幅度不大,总体趋势较为平稳。因此模型的排序能力仍可被业务所接受。
- 从四个组别的逾期率来看C和D的逾期率相近。