ceph集群搭建
文章目录
-
- 理论知识
- 具体操作
-
- 搭建ceph本地源
- yum源及ceph的安装
- 配置NTP(解决时间同步问题)
- 部署ceph
- 自定义crush
理论知识
Ceph是一个分布式存储系统,并且提供了文件、对象、块存储功能。
- Ceph集群中重要的守护进程有:Ceph OSD、Ceph Monitor。
- Ceph OSD(Object Storage Device): OSD是数据存储的地方,该守护进程处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitors提供一些监控信息。 。
- Ceph Monitor: 是一个监视器,监视Ceph集群状态和维护集群中的各种关系。是集群的控制中心。同时ceph monitor还负责集群的指挥工作,将集群的状态同步给客户端。当集群状态有变化,比如OSD增加或故障时,monitor会负责更新集群的状态并反馈给客户端。为了保证高可用,monitor节点需要部署多个。比如3个,5个。。。
- Ceph存储集群至少需要一个Ceph Monitor和两个 OSD 守护进程。
集群的状态:
- Monitor Maps,集群Ceph Monitor集群的节点状态,通过ceph mon dump可以获取;
- OSD Maps,集群数据存储节点的状态表,记录集群中OSD状态变化,通过ceph osd dump可以获取;
- PGs Maps,PGs即placement group,表示在OSD中的分布式方式,通过ceph pg dump可以获取;
- Crush Maps,Crush包含资源池pool在存储中的映射路径方式,即数据是如何分布的;
- MDS Maps,CephFS依赖的MDS管理组件,可通过ceph mds dump获取,用于追踪MDS状态。
ceph集群把从客户端接收的数据(不管是ceph块设备、ceph对象存储还是ceph文件系统)切割成多个对象(object),然后将对象存储在osd设备上,由osd守护进程处理读写操作。
至于这些对象是如何选择对应的OSD设备呢?这就需要使用调度算法CRUSH。不管是客户端还是OSD守护进程都使用crush算法来计算对象在集群中OSD设备的位置信息。
以一个100G的文件为例,每个对象默认是4M,那么就会切割成25600个对象。如果一个文件或者OSD出现了异常,那么集群就需要对每个对象都进行调度,那么在一个大规模集群中crush算法调度任务就会变得非常繁重。因此,ceph集群引入了PG(Place Group,放置组)的概念。可以理解为放置对象的容器。 因此,可以将对象映射到PG,再通过crush算法将PG调度到某个osd。由于PG的数量相对是固定的,因此,调度任务没有那么繁重。同时,当某个OSD异常时,只需要将对应的PG调度到其他OSD上。

具体流程为:
- 一个文件将会切割为多个object(如1G文件每个object为4M将切割为256个),每个object会由一个由innode(ino)和object编号(ono)组成oid,即object id,oid唯一标识object对象;
- 针对object id做hash并做取模运算,从而获取到pgid,即place group id,通过hash+mask获取到PGs ID,PG是存储object的容器;
- Ceph通过CRUSH算法,将pgid进行运算,找到当前集群最适合存储PG的OSD节点,如osd1和osd2(假设为2个副本);
- PG的数据最终写入到OSD节点,完成数据的写入过程,当然这里会涉及到多副本,一份数据写多副本
其中还有pool的概念,存储池是用于存储对象的逻辑分区,可以实现不同数据的逻辑隔离。可以简单记作:文件分割成了一个个对象,若干对象则是存储在不同的PG里,而多个PG 构成了Pool。
上述只总结了ceph的基础知识,更全面的集群架构信息可以参考:https://www.cnblogs.com/hukey/p/12588436.html#%E5%89%8D%E8%A8%80
https://docs.ceph.com/en/pacific/architecture/
具体操作
Ceph集群搭建参考链接:https://cloud.tencent.com/developer/article/1006084
实验所用虚拟机均为Centos 7.6系统,8G内存,16核CPU:
Ceph-admin: 用作ntp server和ceph本地源
Ceph-1: 3个2T硬盘和一个800G硬盘,deploy、mon1、osd3
Ceph-2: 3个2T硬盘和一个800G硬盘,mon1、osd3
Ceph-3: 3个2T硬盘和一个800G硬盘,mon1、osd3
需要在每台主机上配置好域名解析

搭建ceph本地源
下面操作均是在ceph-admin节点上:
1、安装httpd和createrepo
yum install httpd createrepo -y
2、创建ceph源目录,
mkdir -p /var/www/html/ceph/10.2.2
3、下载所有文件【选择并下载你需要安装的ceph版本,这里选择的是/rpm-jewel/el7/x86_64/,然后把所有的包含10.2.2的rpm包都下下来,除了那个ceph-debuginfo,1G多太大了,可以不下。最后再加上ceph-deploy的rpm链接】
cd /var/www/html/ceph/10.2.2
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-base-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-common-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-devel-compat-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-fuse-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-libs-compat-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-mds-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-mon-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-osd-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-radosgw-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-selinux-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ceph-test-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/cephfs-java-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/libcephfs1-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/libcephfs1-devel-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/libcephfs_jni1-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/libcephfs_jni1-devel-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/librados2-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/librados2-devel-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/libradosstriper1-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/libradosstriper1-devel-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/librbd1-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/librbd1-devel-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/librgw2-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/librgw2-devel-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/python-ceph-compat-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/python-cephfs-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/python-rados-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/python-rbd-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/rbd-fuse-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/rbd-mirror-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/rbd-nbd-10.2.2-0.el7.x86_64.rpm
wget http://mirrors.aliyun.com/ceph/rpm-hammer/el7/noarch/ceph-deploy-1.5.36-0.noarch.rpm
4、创建源
createrepo /var/www/html/ceph/10.2.2

5、开启httpd服务
systemctl start httpd
yum源及ceph的安装
在ceph-1节点、ceph-2节点、ceph-3节点上执行:
yum clean all
rm -fr /etc/yum.repos.d/*.repo
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
sed -i '/aliyuncs/d' /etc/yum.repos.d/CentOS-Base.repo
sed -i 's/$releasever/7/g' /etc/yum.repos.d/CentOS-Base.repo
sed -i '/aliyuncs/d' /etc/yum.repos.d/epel.repo
增加ceph的源:
scp ceph-admin:/etc/yum.repos.d/ceph.repo /etc/yum.repos.d/
安装ceph客户端和ntp:
yum makecache
yum install ceph ceph-radosgw ntp -y
关闭火墙
sed -i 's/SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
配置NTP(解决时间同步问题)
ceph-admin 节点、ntp-1节点、ntp-2 节点、ntp-3节点都需要安装 ntp:
yum install ntp -y
将 ceph-admin 节点作为 NTP server
将ntp-1节点、ntp-2 节点、ntp-3节点作为 NTP client
下述操作在ceph-admin 节点上:
vim /etc/ntp.conf
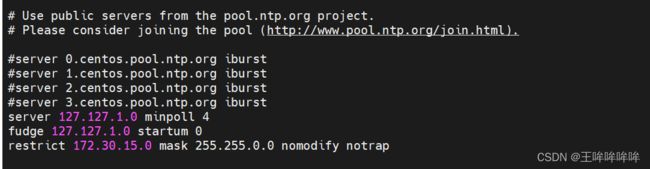
vim /etc/ntp/step-tickers

开启服务:
systemctl enable ntpd
systemctl start ntpd

只有当命令的下一行是 * 时,才是正常的。
至此,NTP server端已经配置完毕,下面开始配置client端。
在ceph-1、ceph-2、ceph-3三个节点上:
修改/etc/ntp.conf,注释掉四行server,添加一行server指向ceph-admin:
vim /etc/ntp.conf
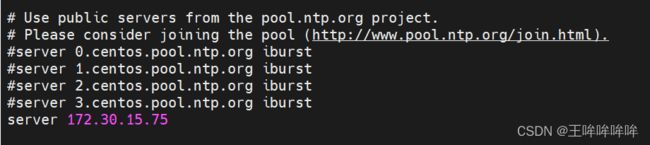
开启服务:
systemctl enable ntpd
systemctl start ntpd

观察client 已经正确连接到server端,同样正确连接的标准是ntpq -p的最下面一行以*号开头。
如果还没显示 * 号,就等一会,估计5分钟就好了。
一定要确定server和所有的client端的NTP都正确连接才能继续搭建ceph 。
部署ceph
在 ceph-1 节点(部署节点)上执行如下:
安装 ceph-deploy :
yum install ceph-deploy -y

在部署节点上创建部署目录,开始部署
cd
mkdir cluster
cd cluser
ceph-deploy new ceph-1 ceph-2 ceph-3
在部署节点ssh-copy-id到各个其他节点。
ssh-copy-id ceph-2
ssh-copy-id ceph-3
此时在 cluster 目录下有文件:
ceph.conf
ceph-deploy-ceph.log
ceph.mon.keyring
vim ceph.conf :

其中,osd_crush_update_on_start=false 表示启动 osd 时不自动更新 crush,后续将自定义 crush 。
osd_journal_size=20480 表示设置日志盘为20G
开始部署 monitor :
ceph-deploy mon create-initial
下面开始部署OSD:
先需要理清楚各个主机磁盘:
ceph-1主机:
| /dev/vdc | 2T 【假设为sata硬盘】 |
|---|---|
| /dev/vdd | 800G 【ssd硬盘】 |
| /dev/vde | 2T 【假设为sata硬盘】 |
| /dev/vdf | 2T 【假设为sata硬盘】 |
ceph-2以及ceph-3 主机:
| /dev/vdc | 800G【ssd硬盘】 |
|---|---|
| /dev/vdd | 2T 【假设为sata硬盘】 |
| /dev/vde | 2T 【假设为sata硬盘】 |
| /dev/vdf | 2T 【假设为sata硬盘】 |
先从SATA硬盘开始部署OSD:
[root@ceph-1 cluster]# ceph-deploy --overwrite-conf osd prepare ceph-1:/dev/vdc ceph-1:/dev/vde ceph-1:/dev/vdf ceph-2:/dev/vdd ceph-2:/dev/vde ceph-2:/dev/vdf ceph-3:/dev/vdd ceph-3:/dev/vde ceph-3:/dev/vdf
然后激活创建的OSD,
注意,这里osd activate后面的参数格式为:HOSTNAME:data-disk1,需要注意的是,刚刚的/dev/vdc这里需要写成/dev/vdc1,因为分了区。
[root@ceph-1 ~]# ceph-deploy --overwrite-conf osd activate ceph-1:/dev/vdc1 ceph-1:/dev/vde1 ceph-1:/dev/vdf1 ceph-2:/dev/vdd1 ceph-2:/dev/vde1 ceph-2:/dev/vdf1 ceph-3:/dev/vdd1 ceph-3:/dev/vde1 ceph-3:/dev/vdf1
然后可以使用 ceph -s 查看集群状态,能看到osd的状态为 9 up, 9 in。
再部署3个ssd:
[root@ceph-1 ~]# ceph-deploy --overwrite-conf osd prepare ceph-1:/dev/vdd ceph-2:/dev/vdc ceph-3:/dev/vdc
[root@ceph-1 ~]# ceph-deploy --overwrite-conf osd activate ceph-1:/dev/vdd1 ceph-2:/dev/vdc1 ceph-3:/dev/vdc1
然后 ceph -s 查看集群状态,能看到有12个 osd 是 up 的。
自定义crush
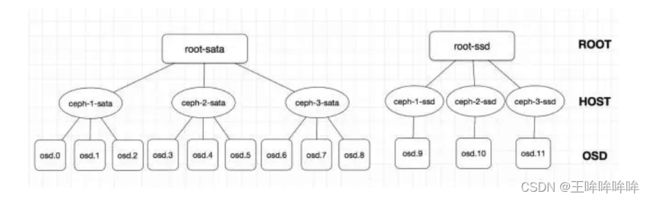
创建对应的Bucket
在 ceph-1 节点执行如下命令:
ceph osd crush add-bucket root-sata root
ceph osd crush add-bucket root-ssd root
ceph osd crush add-bucket ceph-1-sata host
ceph osd crush add-bucket ceph-2-sata host
ceph osd crush add-bucket ceph-3-sata host
ceph osd crush add-bucket ceph-1-ssd host
ceph osd crush add-bucket ceph-2-ssd host
ceph osd crush add-bucket ceph-3-ssd host
再将对应的host移到root下,然后把OSD移到对应的host下面,注意添加OSD时的weight是该OSD的实际大小(2T为2 ,800G为0.8),
ceph osd crush move ceph-1-sata root=root-sata
ceph osd crush move ceph-2-sata root=root-sata
ceph osd crush move ceph-3-sata root=root-sata
ceph osd crush move ceph-1-ssd root=root-ssd
ceph osd crush move ceph-2-ssd root=root-ssd
ceph osd crush move ceph-3-ssd root=root-ssd
ceph osd crush add osd.0 2 host=ceph-1-sata
ceph osd crush add osd.1 2 host=ceph-1-sata
ceph osd crush add osd.2 2 host=ceph-1-sata
ceph osd crush add osd.3 2 host=ceph-2-sata
ceph osd crush add osd.4 2 host=ceph-2-sata
ceph osd crush add osd.5 2 host=ceph-2-sata
ceph osd crush add osd.6 2 host=ceph-3-sata
ceph osd crush add osd.7 2 host=ceph-3-sata
ceph osd crush add osd.8 2 host=ceph-3-sata
ceph osd crush add osd.9 0.8 host=ceph-1-ssd
ceph osd crush add osd.10 0.8 host=ceph-2-ssd
ceph osd crush add osd.11 0.8 host=ceph-3-ssd
查看 ceph osd tree:
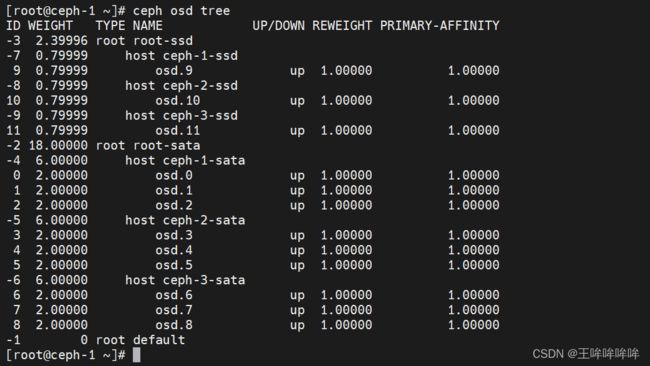
导出 crushmap,并添加rule :
cephosd getcrushmap -o /tmp/crush
crushtool -d /tmp/crush -o /tmp/crush.txt
# -d 的意思是decompile,导出的crush是二进制格式的。
vim /tmp/crush.txt :
# rules
rule rule-sata {
ruleset 0 #rule的编号
type replicated
min_size 1
max_size 10
step take root-sata #设置sata的root名称
step chooseleaf firstn 0 type host
step emit
}
rule rule-ssd {
ruleset 1
type replicated
min_size 1
max_size 10
step take root-ssd #设置ssd的root名称
step chooseleaf firstn 0 type host
step emit
}
编译 /tmp/crush.txt,并注入集群中:
[root@ceph-1 cluster]# crushtool -c /tmp/crush.txt -o /tmp/crush.bin
[root@ceph-1 cluster]# ceph osd setcrushmap -i /tmp/crush.bin
查看 ceph -s:

如果health HEALTH_WARN,那么增加rdb的pg数,即可。
cephosd pool set rbd pg_num 256
ceph osd pool set rbd pgp_num 256
然后就能看到状态变成HEALTH_OK 了。
一些用法:
查看rbd池的情况
[root@ceph-1cluster]# ceph osd pool ls detail
将rbd池是ruleset设置为1,即由osd.9-osd.11组成的结构,rbd池的所有数据将会保存在这三个SSD上
[root@ceph-1cluster]# ceph osd pool set rbd crush_ruleset 1
创建不同的pool:
[root@ceph-1cluster]# ceph osd pool create sata-pool 256 rule-sata pool 'sata-pool' created
[root@ceph-1 cluster]# ceph osd pool create ssd-pool 256 rule-ssd pool 'ssd-pool' created
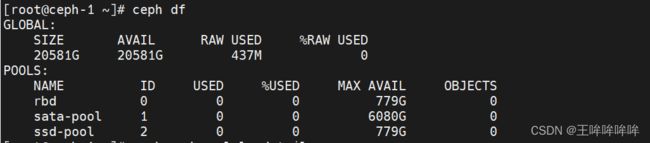

模拟了将同一台主机上的SATA和SSD分开使用,在一批次同样结构的主机上,构建出两种不同速度的pool,CRUSH的自定义性,给ceph提供了极大的可塑性。