Machine Learning for Computer Systems and Networking:A Survey ---综述阅读 对于计算机系统和网络的机器学习
摘要:
Machine learning (ML) has become the de-facto approach for various scientific domains such as computervision and natural language processing. Despite recent breakthroughs, machine learning has only made its into the fundamental challenges in computer systems and networking recently. This article attempts to shed light on recent literature that appeals for machine learning-based solutions to traditional problems in computer systems and networking. To this end, we first introduce a taxonomy based on a set of major research problem domains. Then, we present a comprehensive review per domain, where we compare the traditional approaches against the machine learning-based ones. Finally, we discuss the general limitations of machine learning for computer systems and networking, including lack of training data, training overhead, real-time performance, and explainability, and reveal future research directions targeting these limitations.
CCS Concepts: • General and reference → Surveys and overviews; • Computer systems organization;
• Networks;
机器学习已经成了计算机视觉和自然语言处理等多个学科领域的主要方法.尽管最近取得了一些突破,机器学习仅仅在计算机视觉和网络领域进入了基本挑战.本文尝试阐明最近的尝试用ml解决计算机系统和网络的传统问题的文献.为了这一目标,我们首先介绍了一套研究问题领域的方法学,然后我们对每个领域进行了综合的回顾,并对这些领域进行了传统方法和ML方法的比较.最后,我们讨论了对计算机系统和网络的机器学习方法限制,的包括:训练数据不足,过拟合,实时性能,可解释性,并针对这些不足揭示出未来发展的方向.
CCS Concepts(核心概念):综述 计算机系统 网络 机器学习
1.INTRODUCTION
Revolutionary research in machine learning (ML) has significantly disrupted the scientific community by contributing solutions to long-lived challenges. Thanks to the continuous advancements in computing resources (e.g., cloud data centers) and performance capabilities of processing units (e.g., accelerators like GPUs and TPUs), ML, particularly its rather computation-expensive subset namely deep learning (DL), has gained its traction [120, 131]. In general, ML has established dominance in vision tasks such as image classification, object recognition [86], and more to follow [58,156]. Other remarkable examples where ML is thriving include speech recognition [52] and machine translation [155]. ML is also prevailing to a plethora of specialized tasks that prior work has been far out of reach to yield notable outcomes [2, 141]. For instance, it was not until recently that top professional Go players were beaten by a deep reinforcement learning (DRL) agent [141].ML已经在图像分类,物体识别以及更多后续任务重建立了主导地位.
ML领域的革命性研究通过为长期的挑战提供解决方案,极大地颠覆了科学界.由于计算机资源(如云数据中心)和处理单元(如GPU和TPU等加速器)性能的不算进步,ML,特别是其计算成本相当高的子集,即深度学习(DL),已经获得了它的关注.ML蓬勃发展的其它例子包括语音识别和机器翻译.机器学习也在大量的专门任务中盛行,以前的工作远远无法产生显著的结果. 例如知道最近, 顶级围棋选手才被深度强化学习DRL智能体击败
Considering this unprecedented growth of ML in various classification/control tasks, one begs the question, how can we apply ML to other domains that have long suffered from a sub-optimal performance that traditional solutions can offer at their best? One prominent example is the domain of computer systems and networking, where parameter tuning and performance optimization largely rely on domain expertise and highly-engineered heuristics. Essentially, it is of great interest to answer whether it is time to make machines learn to optimize their performance by themselves automatically. Putting it into perspective, there is a multitude of challenges for which ML can prove beneficial due to its innate ability to capture complex properties and extract valuable information that no human, even the domain expert, can master.
考虑到ML在各种分类/控制任务中的前所未有的增长,人们不禁要问,我们如何将ML应用到其他长期遭受传统解决方案所能提供的最佳性能的次优性能的领域一个突出的例子是计算机系统和网络领域,其中参数调优和性能优化在很大程度上依赖于领域专业知识和高度工程化的启发式
We observe two general challenges in the current research practice of applying ML in computer systems and networking. First, there is no consensus on a common guideline for using ML in computer systems and networking (e.g., when ML would be preferable over traditional approaches),with research efforts, so far, scattered in different research areas. The lack of a holistic view makes researchers difficult to gain insights or borrow ideas from related areas. Second, there have not been any recent efforts that showcase how to select an appropriate ML technique for each distinct problem in computer systems and networking. In particular, we observe that in some cases, only a certain ML algorithm is suitable for a given problem, while there exist also problems that can be tackled through a variety of ML techniques and it is nontrivial to choose the best one. The above challenges constitute major obstacles for researchers to capture and evaluate recent work sufficiently, when probing for a new research direction or optimizing an existing approach.
我们观测到在将ML应用于计算机系统和网络的实践中时会遇到两个主要的挑战:首先,对于在计算机系统和网络中使用ML的通用指南没有共识(例如,何时ML比传统方法更可取)到目前为止,研究工作分散在不同的研究领域.由于缺乏整体的观点,研究人员很难从相关领域获得见解或借鉴思路.其次,其次,最近还没有任何努力来展示如何为计算机系统和网络中的每个不同问题选择合适的ML技术.当探索一个新方向或者优化一个新方法时,上述挑战是对研究员去充分捕捉和估计最近工作的主要障碍.
In this article, we tackle these challenges by providing a comprehensive horizontal overview to the community. We focus on the research areas of computer systems and networking, which share similar flavor and have seen promising results through using ML recently. Instead of diving into one specific, vertical domain, we seek to provide a cross-cutting view for the broad landscape of the computer systems and networking field. Specifically, we make the following contributions:
— We present a taxonomy for ML for computer systems and networking, where representative works are classified according to the taxonomy.
— For each research domain covered in the taxonomy, we summarize traditional approaches and their limitations, and discuss ML-based approaches together with their pros and cons.
— We discuss the common limitations of ML when applied in computer systems and networking in general and reveal future directions to explore.
With these contributions, we expect to make the following impact: (1) introducing new researchers having no domain expertise to the broad field of ML for systems and networking, (2) bringing awareness to researchers in certain domains about the developments of applying ML on problems in neighboring domains and enabling to share and borrow ideas from each other.
本文通过向社区提供全面的水平概述来解决这些挑战。我们专注于计算机系统和网络的研究领域,这些领域具有相似的特点,并且最近通过使用机器学习取得了有希望的结果。我们不是深入研究一个特定的垂直领域,而是试图为计算机系统和网络领域的广阔景观提供横向视角。具体而言,我们做出以下贡献:- 我们为计算机系统和网络的ML提供了分类法,其中代表性作品根据分类法进行分类。
-我们为计算机系统和网络的ML提供了分类法,其中代表性作品根据分类法进行分类。
- 对于分类法中涵盖的每个研究领域,我们总结了传统方法及其局限性,并讨论了基于ML的方法及其优缺点。
- 我们讨论了ML在计算机系统和网络中应用时的共同限制,并揭示了未来探索的方向。
Related surveys. There has not been a survey that satisfies the objectives we aim at achieving in this article. Most of the related surveys are domain-specific, focusing on a narrow vertical overview. For example, Zhang et al. present a survey on leveraging DL in mobile and wireless networking [195]; hence, we will skip these areas in this survey. There are also surveys focusing on areas like compiler autotuning [6], edge computing [37], and Internet-of-Things [63]. While targeting different levels of concerns, these surveys can facilitate domain experts to gain a deep understanding of all the technical details when applying ML on problems from the specific domain. However, they miss the opportunity to show the broad research landscape of using ML in Machine Learning for Computer Systems and Networking
目前还没有一项调查满足我们在本文中旨在实现的目标。大多数相关调查都是针对特定领域的,侧重于狭窄的垂直概述。例如,张等人提出了一项关于在移动和无线网络中利用DL的调查[195];因此,在本次调查中,我们将跳过这些领域。还有一些调查专注于编译器自动调优[6]、边缘计算[37]和物联网[63]等领域。虽然针对不同层次的问题,这些调查可以帮助领域专家在应用ML解决特定领域问题时深入了解所有技术细节。然而,它们错过了展示使用ML在计算机系统和网络领域中广泛研究方向的机会。

the general computer systems and networking field. We aim at bridging such a gap in this work.The closest work to ours is [174]. Focusing on networking, this survey provides an overview of ML applied in networking problems but ignores the computer systems part. Besides, the article was published almost four years ago. Considering that significant progress has been made in recent years, we believe it is time to revisit this topic.
目前在计算机系统和网络领域中,ML的应用存在一定的差距。本文旨在弥合这种差距。最接近我们工作的是[174]。该调查侧重于网络,提供了应用于网络问题中的ML概述,但忽略了计算机系统部分。此外,该文章发表时间已经将近四年。考虑到近年来取得了显著进展,我们认为现在是重新审视这个主题的时候了。
2 TAXONOMY
We first categorize the existing work on ML for computer systems and networking. Figure 1 presents a taxonomy from two angles: the problem space and the solution space. The problem space covers fundamental problems that have been extensively studied in the traditional computer systems and networking research area. The solution space is constructed based on our experience,where the most important feature dimensions of ML-based solutions are included. We highlightover 150 articles proposed for the problems falling in the taxonomy where ML is mentioned. The article selection is based on a comprehensive approach to cover as broadly as possible the articles in each of the selected research domains. For each of the covered domains, we selectively pick the more notable works and we provide more elaboration on their contributions.
本文首先对计算机系统和网络中ML的现有工作进行分类。图1从问题空间和解决方案空间两个角度呈现了分类法。问题空间涵盖了传统计算机系统和网络研究领域中广泛研究的基本问题。解决方案空间是基于我们的经验构建的,其中包括基于ML的解决方案最重要的特征维度。我们强调了超过150篇文章,这些文章提出了在涉及ML的分类法中出现的问题。文章选择是基于全面方法进行的,旨在尽可能广泛地涵盖每个选定研究领域中的文章。
computer systems.
A computer system is broadly defined as a set of integrated computing devices that take, generate, process, and store data and information. Generally speaking, a computer system is built with at least one computing device.reliability, and security. In this survey, we focus on three fundamental problems in computer systems, each representing one level of the system abstractions:
计算机网络。
计算机网络是多种计算的互联可以在这些连接的设备之间发送/接收数据的设备(也称为主机)。除了主机、计算机网络涉及到负责在主机和计算机之间转发数据的设备主机,被称为网络设备,包括路由器和交换机。计算机网络一个长期的研究领域,我们已经看到了大量的人工制品和控制机制。我们将特别关注网络中的以下四个基本问题从包级到连接级,再到应用级:
—报文分类是几乎所有网络设备的基本组网功能。的网络数据包分类问题是根据数据包的分类来确定数据包的类别一些高效的预定义标准(高速度,低资源占用)。
-网络路由关注的是在给定的网络上寻找发送数据包的最佳路径一些性能指标,如延迟。
—拥塞控制是传输层的一种网络机制,基于尽力网络交付提供面向连接的服务。
-视频流媒体是目前最流行的网络应用之一,它大多是基于自适应比特率(ABR)的概念。ABR的宗旨是选择最合适的动态网络条件下视频段传输的比特率。
通常可以分为两种环境:集中式和分布式。集中式环境涉及单个实体,决策基于全局信息,而分布式环境涉及多个可能协调的自治实体。虽然在分布式环境中具有分布式解决方案是很自然的,但分布式学习通常比集中式学习更困难,主要是由于协调限制。联邦学习(FL)是一种分布式学习技术,其中客户端工作人员执行训练并与中央服务器通信以共享训练模型,而不是原始数据[7]。多智能体技术[121]是分布式学习的其他例子。在本调查中,我们根据解决方案是集中式还是分布式进行分类,但我们不会进一步详细介绍学习技术(例如FL)。有关FL系统的更多信息,请参阅最近发表的调查报告,例如[190]。

Table 1列出了不同领域中的机器学习问题。这些问题被分为四个主要类别:系统性能、网络性能、安全和隐私以及其他。每个类别下面列出了具体的问题,例如在系统性能类别中,包括资源管理、负载平衡和容错等问题。Table 1旨在提供一个概述,以帮助读者了解机器学习在计算机系统和网络领域中的应用。
这段文字解释了机器学习中的时间性学习可以根据其时间性分为两种方式:离线和在线。离线学习需要提前使用现有数据对机器学习模型进行预训练,然后在决策时应用已经训练好的模型,而不需要进一步的输入体验。在线学习涉及到机器学习模型的持续学习,在推理时,模型也会在经历给定输入后进行更新。根据具体情况,一个模型可能会先进行离线训练,然后再进行在线重新训练。
作者提供了一个横跨所有领域的分类视图,涵盖了主要的工作,并展示了如何根据上述解决方案空间对它们进行分类。这个分类视图在Table 1中提供。在接下来的章节中,作者将深入探讨每个问题领域,但首先提供这个横跨所有领域的分类视图,以帮助读者更好地理解机器学习在计算机系统和网络领域中的应用。
现代计算机系统通常使用多层内存设备,并涉及多个复杂的内存管理操作。尽管技术不断进步,例如过去几十年中存储成本的指数级降低和大小的反向扩展,但存储系统仍然是每个计算机系统性能瓶颈的难以驾驭的因素。Figure 2描述了现有计算机系统中与存储相关的主要问题。在内存操作的大体方案中,从CPU缓存中检索条目只需要几纳秒,但当发生缓存未命中并且必须从DRAM或磁盘中获取条目时,条件会提高数个数量级。多年来,已经有大量的工作致力于解决遍历各种内存层次结构的低效率和引起的延迟问题。在几种情况下,已经提出了复杂的机制来处理预防性操作。换句话说,目前正在研究如何从DRAM预取数据或指令到CPU缓存,并将热页从磁盘调度到DRAM。在网络系统层面上,也已经探索了复杂的缓存接纳和失效策略,以优化传递大型内容(例如视频数据)的性能。所有这些与存储相关的问题中共同面临的挑战是预测这些系统中数据模式变得越来越复杂。

大量的研究已经集中在缓解由内存引起的瓶颈上。其中一个例子是内存预取,它将内存内容预加载到寄存器或缓存中,以避免慢速内存访问。通常有两种实现内存预取的方法:基于软件和基于硬件。基于软件的预取器使用显式指令进行预取。虽然提供了灵活性,但基于软件的预取器会增加代码占用空间和延迟,并且准确性较低。因此,主流的内存预取器是通过集成在CPU中的硬件实现的。最先进的硬件预取器通常依赖于CPU的内存访问模式,并根据访问模式计算相应的增量进行预取[67, 116, 123, 140, 144, 192]。当内存访问高度不规则时,这种类型的预取器变得次优。另一方面,基于模式历史的预取器在捕获不规则性方面表现更好,但集成成本更高[194]。
页面调度旨在通过将经常访问的页面提供给计算单元(例如DRAM)来提高性能。页面调度具有很高的复杂性,已经进行了大量的研究以彻底解决这个问题[22、38、73、114、139、181、182]。通常,页面调度的常见方法涉及系统级集成,例如在操作系统或编译期间。目前最先进的技术利用历史信息来预测未来的内存访问。然而,性能瓶颈仍然存在[36]。针对更大规模的缓存,CDN专注于优化用户请求内容的延迟[80]。为此,CDN利用缓存接纳策略和失效策略来管理缓存中的内容,并尽可能地减少从源服务器获取内容所需的时间。
3.3 Discussion on ML-based Approaches
A common theme among most existing work is the use of RNNs and in particular LSTM neural net-works. This strikes as the de-facto consideration when it comes to memory-related challenges. The ability of RNNs to preserve state is what makes them powerful in problems involving predictions on sequences of data or data in a time series. This is in clear contrast to traditional approaches, which suffer poor predictions on the complex data pattern. Meanwhile, ML-based approaches have become more accessible due to various AutoML solutions and tools. Another similar trait lies in the selection of learning algorithms the authors have to make. We observe that most approaches rely on supervised learning and making predictions. Considering the nature of the problems they are targeting, this also comes naturally. Yet, we observe that despite the fitting-the-mould type of ap-proach that researchers follow at the infant stage when results are not significant, many authors at-tempt to solve the problem with an unorthodox methodology. For instance, RL-Cache leverages RL to construct a cache admission policy rather than following a statistical estimation approach [80]. However, this does not always translate to successful solutions, albeit it certainly denotes a pat-tern on how researchers apply learned solutions to traditional and emerging challenges. Overall, ML-based approaches have demonstrated their clear benefits for problems in memory systems when facing complex data patterns and provide multiple easy-to-generalize techniques to tackle these problems from different angles. However, if the underlying data pattern is simple and easy to obtain, using ML-based approaches would become an overkill.
4 CLUSTER RESOURCE SCHEDULING
Resource scheduling concerns the problem of mapping resource demands to computing resources meeting set goals on resource utilization, response time, fairness, and affinity/anti-affinity constraints. Cloud-based solutions nowadays dominate the computing landscape, providing high Machine Learning for Computer Systems and Networking scalability, availability, and cost efficiency. Scheduling in the cloud environment goes beyond a single or multi-core computing node and needs to deal with a multitude of physical nodes, some-times also equipped with heterogeneous domain-specific accelerators. The scope of cloud resource scheduling can be within a single cloud data center or across geo-distributed cloud data centers. Cloud resource schedulers are typically built with a monolithic, two-level, or shared-state archi-tecture. Monolithic schedulers, e.g., YARN, use a single, centralized scheduling algorithm for all jobs in the system. This makes them hard to scale and inflexible to support sophisticated sched-uling policies. Two-level schedulers like Mesos [59] and Hadoop-on-Demand introduce a single active resource allocator to offer resources to scheduling frameworks and rely on these individual frameworks to perform fine-grained task scheduling. While being more scalable, the conservative resource visibility and locking make them hard to implement scheduling policies such as preemp-tion and gang scheduling that require a global view of the overall resources. Shared-state sched-ulers such as Omega [138] aim at addressing the problems of monolithic and two-level schedulers by allowing for lock-free control. Schedulers following such designs operate completely in parallel and employ optimistic concurrency control to mediate clashes between schedulers using concepts like transactions [138], achieving both flexibility in policy customization and scalability. Adopt-ing one of these architectures, many works have been done on the scheduling algorithm design. The heterogeneity of resources, together with the diversity of applications that impose different resource requirements, has rendered the resource scheduling problem a grand challenge for cloud computing, especially when scalability is of paramount importance.
资源调度涉及将资源需求映射到计算资源以满足资源利用率、响应时间、公平性和亲缘/反亲缘约束等设定的目标。云解决方案如今主导了计算领域,提供高可扩展性、可用性和成本效益。在云环境中进行调度不仅限于单个或多核计算节点,还需要处理众多物理节点,有时还可以配备异构领域特定加速器。云资源调度的范围可以在单个云数据中心内或跨地理分布的云数据中心之间进行。云资源调度程序通常采用单块、双层或共享状态体系结构构建。单块调度程序(如YARN)对系统中的所有任务使用单个集中式调度算法。这使它们难以扩展,并且无法灵活支持复杂的调度策略。类似Mesos(59)和Hadoop-on-Demand的双层调度程序引入了单个活动资源分配器,为调度框架提供资源,并依赖这些单独的框架执行精细的任务调度。虽然更具可扩展性,但保守的资源可见性和锁定使它们难以实现调度策略,如抢占和团队调度,这些策略需要全局视图的总体资源。共享状态调度程序(如Omega)旨在通过允许无锁控制来解决单块和双层调度程序的问题。遵循这些设计的调度程序完全并行操作,并采用乐观并发控制来调节使用类似交易的概念的调度程序之间的冲突[138],实现策略定制的灵活性和可扩展性。采用这些架构之一,已经对调度算法设计进行了许多工作。资源的异构性以及不同资源需求的多样性使得资源调度问题成为云计算的一大挑战,特别是当可扩展性至关重要时。
Existing scheduling algorithms generally fall into one of the three categories: centralized, dis-tributed, and hybrid. Centralized schedulers have been extensively studied, where the scheduler maintains a global view of the whole data center and applies a centralized algorithm for sched-uling [13, 49, 51, 65, 161, 163, 169]. For example, Quincy [65] and Firmament [51] transform the scheduling problem into a min-cost max-flow (MCMF) problem and use existing MCMF solvers to make scheduling decisions. Considering multiple resources including CPU, memory, disk, and network, schedulers like Tetris adapt heuristics for multi-dimensional bin packing problems to scheduling. Tetrisched takes explicit constraints with jobs as input and employs a constraint solver to optimize job placement [163]. Due to the global resource visibility, centralized schedulers normally produce efficient scheduling decisions, but require special treatments to achieve high scalability.
现有的调度算法通常可分为三类:集中式、分布式和混合式。已经广泛研究的是集中式调度程序,其中调度程序维护整个数据中心的全局视图,并应用集中式算法进行调度[13,49,51,65,161,163,169]。例如,Quincy [65]和Firmament [51]将调度问题转化为最小费用最大流(MCMF)问题,并使用现有的MCMF求解器进行调度决策。考虑到包括CPU、内存、磁盘和网络在内的多个资源,例如 Tetris 等调度程序采用了用于多维装箱问题的启发式算法进行调度。Tetrisched将作业的显式约束作为输入,并使用约束求解器来优化作业的位置[163]。由于全局资源可见性,集中式调度程序通常会产生高效的调度决策,但需要特殊处理才能实现高度可扩展性。
Distributed schedulers make stateless scheduling decisions without any central coordination, aiming to achieve high scalability and low latency [126, 132]. For example, Sparrow [126] employs multiple schedulers to assign tasks to servers using a variant of the power-of-two-choices load balancing technique. Each of the servers maintains a local task queue and adopts the FIFO queuing principle to process the tasks that have been assigned to it by the schedulers. Fully distributed schedulers are known for their high scalability but may make poor decisions in many cases due to limited visibility into the overall resource usage.
分布式调度程序在没有任何中央协调的情况下进行无状态调度决策,旨在实现高度可扩展性和低延迟[126,132]。例如,Sparrow [126]采用多个调度程序使用一种基于二的幂次选择负载平衡技术将任务分配给服务器。每个服务器维护一个本地任务队列,并采用先进先出(FIFO)排队原则来处理已由调度程序分配给它的任务。全分布式调度程序以其高度可扩展性而闻名,但由于对整体资源使用的可见性有限,在许多情况下可能会做出较差的决策。
Hybrid schedulers perform scheduling in a distributed manner with partial information about the global status of the data center [14, 27–29, 74]. Hawk schedules long-running jobs with a cen-tralized scheduler while using a fully distributed scheduler for short jobs [29]. Mercury introduces a programmatic interface to enable a full spectrum of scheduling from centralized to distributed, allowing applications to conduct tradeoffs between scheduling quality and overhead [74]. Recently, a number of resource schedulers have also been proposed targeting DL work-loads [103, 122, 183]. These schedulers are domain-specific, leveraging application-specific knowledge such as early feedback, heterogeneity, and intra-job predictability to improve cluster efficiency and reduce latency.
混合式调度程序以部分有关数据中心全局状态的信息以分布式方式进行调度[14,27-29,74]。Hawk使用集中式调度程序调度长时间运行的作业,同时使用全分布式调度程序调度短作业[29]。Mercury引入了一个编程接口,可以从集中式到分布式实现全谱调度,允许应用程序在调度质量和开销之间进行权衡[74]。最近,也提出了一些针对DL工作负载的资源调度程序[103,122,183]。这些调度程序是特定于领域的,利用应用程序特定的知识,例如早期反馈、异构性和作业内可预测性,以提高群集效率并降低延迟。
Limited attention has been paid to applying ML techniques in general cluster resource scheduling. Paragon [30] and Quasar [31] propose heterogeneity and interference-aware scheduling, employ-ing techniques in recommender systems, such as collaborative filtering, to match workloads to machine types while reducing performance interference. DeepRM is one of the earliest works that leverage DRL to pack tasks with multi-dimensional resource demands to servers [106]. It translates the task scheduling problem into a RL problem and employs a standard policy-gradient RL algo-rithm to solve it. Although it only supports static workloads and single-task jobs, DeepRM demon-strates the possibility and big potential of applying ML in cluster resource scheduling. Another attempt is on device placement optimization for TensorFlow computation graphs [118]. In partic-ular, a RNN policy network is used to scan through all nodes for state embedding and is trained to predict the placement of operations in a computational graph, optimizing job completion time us-ing policy gradient methods. While being effective, training the RNN is expensive when the state is large, leading to scalability issues and requiring human experts’ involvement for manually group-ing operations in the computational graph. In a follow-up work, a two-level hierarchical network is used where the first level is used for grouping and the second for operation placement [117]. The network is trained end-to-end, thus requiring no human experts involvement.
在一般集群资源调度中应用机器学习技术时的研究不足。Paragon[30]和Quasar[31]提出了异构和干扰感知调度的方法,采用推荐系统技术(例如协同过滤),以将工作负载与机器类型匹配,同时减少性能干扰。DeepRM是最早使用深度强化学习(DRL)将具有多维资源需求的任务打包到服务器中的研究之一。它将任务调度问题转化为强化学习问题,并采用标准的策略梯度强化学习算法来解决它。尽管DeepRM仅支持静态工作负载和单任务作业,但它展示了在集群资源调度中应用机器学习的潜力。另一项尝试是针对TensorFlow计算图的设备位置优化[118]。特别地,使用RNN策略网络扫描所有节点,嵌入状态并预测操作的位置,使用策略梯度方法优化作业完成时间。虽然有效,但当状态较大时训练RNN可能很昂贵,存在可扩展性问题,并需要人工专家参与手动对计算图中的操作进行分组。在随后的研究中,使用两级分层网络,第一级用于分组,第二级用于操作位置[117]。该网络采用端到端训练,因此无需人工专家参与。
More recent works choose to use directed acyclic graphs (DAGs) to describe jobs and employ ML methods for scheduling DAGs. Among them, Decima proposes new representations for jobs’dependency graphs, scalable RL models, and new RL training methods [108]. Decima encodes job stages and their dependencies as DAGs and adopts a scalable network architecture as a combi-nation of a graph neural network (GNN) and a policy network, learning workload-specific so-lutions. Decima also supports continuous streaming job arrivals through novel training methods. Similarly, Lachesis proposes a learning algorithm for distributed DAG scheduling over a heteroge-neous set of clusters, executors, differing from each other on the computation and communication capabilities [101]. The scheduling process is divided into two phases: (1) the task selection phase where a learning algorithm, using modified graph convolutional networks, is used to select the next task and (2) the executor selection phase where a heuristic search algorithm is applied to as-sign the selected task to an appropriate cluster and to decide whether the task should be duplicated over multiple clusters. Such a hybrid solution has shown to provide significant performance gain compared with Decima.
较新的工作选择使用有向无环图(DAG)来描述作业,并采用机器学习方法对DAG进行调度。其中,Decima提出了新的作业依赖图表示方法、可伸缩的RL模型和新的RL训练方法[108]。Decima将作业阶段及其依赖关系编码为DAG,并采用可伸缩的网络架构,由一个图神经网络(GNN)和一个策略网络组成,学习特定于工作负载的解决方案。Decima还通过新颖的训练方法支持连续的流式作业到达。类似地,Lachesis提出了一种分布式DAG调度学习算法,用于异构集群执行器之间的调度,这些执行器在计算和通信能力上彼此不同[101]。调度过程分为两个阶段:(1)任务选择阶段,在此阶段使用修改过的图卷积网络的学习算法来选择下一个任务;(2)执行器选择阶段,在此阶段应用启发式搜索算法将所选任务分配给适当的集群,并决定是否应将该任务复制到多个集群。这种混合解决方案已经证明与Decima相比可以显著提高性能。
ML approaches have also been attempted in GPU cluster scheduling. DL2 applies a DL technique for scheduling DL training jobs [128]. It employs an offline supervised learning mechanism is used at the beginning, with an online training mechanism at run time. The solution does not depend on explicit modeling of workloads and provides a solution for transiting from the offline to the online mechanism, whenever the latter outperforms the former.
在GPU集群调度方面也尝试了应用机器学习方法。DL2应用DL技术来调度DL训练作业[128]。它使用离线监督学习机制在开始时,使用在线训练机制在运行时。该解决方案不依赖于工作负载的明确建模,并提供了从离线到在线机制的过渡解决方案,每当后者表现优于前者时都会切换这种过渡方案。
4.3 Discussion on ML-based Approaches
While a significant amount of research has been conducted for cluster scheduling, only little focuses on applying learning techniques to fine-grained task scheduling. This could be in part explained by the complexity of modeling cluster scheduling problems in a learning framework, but also by the fact that the workloads related to the training of the scheduler need to be scheduled, possibly over the same set of resources, and that such training could be very costly. These all increase the complexity and should be included in the performance analysis and pros/cons studies of any ML-based cluster scheduling approach, which is so far widely ignored. Still, cluster scheduling can benefit from ML-based approaches, e.g., in heterogeneous settings or when the workload information is not known a priori.
已经有大量的研究在集群调度方向上进行,但是只有很少的研究专注于应用学习技术来进行精细的任务调度。这可以部分地解释为将集群调度问题建模在学习框架中的复杂性,同时还因为与调度器培训相关的工作负载需要被调度,可能是在同一组资源中,这种训练成本可能非常高。这些都增加了复杂性,并且应该包括在任何基于机器学习的集群调度方法的性能分析和优.
5 QUERY OPTIMIZATION IN DATABASE SYSTEMS
Involving either a well-structured relational systems with SQL support or non-tabular systems (e.g., NoSQL) and in-memory stores, database systems are always the epicenter of any meaningful transaction. Yet, the state-of-the-art database management systems (DBMS), being carefully designed, remain as the performance bottleneck for plenty of applications in a broad spectrum of scenarios.
A key factor to the performance of DBMS is query optimization—determining the most efficient way to execute a given query considering all possible query plans. Over the years, several query optimizers on different levels (e.g., execution plan optimization, optimal selection of index struc-tures) have been proposed. Most solutions rely on hand-tuned heuristics or statistical estimations. Surprisingly, case studies on query optimization reveal that the performance gains can be limited or such optimization even has a detrimental effect to the system performance, especially in the presence of estimation errors [90, 91].
在数据库系统中,无论是支持 SQL 的良好结构化关系系统,还是非表格系统 (如 NoSQL) 和内存存储,数据库系统总是任何有意义的交易的核心。然而,精心设计的高级数据库管理系统 (DBMS) 在许多场景下仍然成为性能瓶颈,为许多应用程序带来瓶颈。
对数据库管理系统性能至关重要的因素是查询优化,即考虑所有可能查询计划,确定执行给定查询的最高效方式。多年来,已经在不同级别上提出了多个查询优化器 (例如执行计划优化,最优选择索引结构等)。大多数解决方案依赖于手动调整的启发式或统计估计。令人惊讶地,查询优化的案例分析表明,性能提升可能有限,或者这样的优化甚至对系统性能有负面影响,特别是在估计误差存在时 [90, 91]。
5.1 Traditional Approaches and Limitations
Over the years, significant research efforts have been made on the optimization of DBMS and particularly on the query optimizer—a crucial component causally related to the query execution performance. Traditional query optimizers take as input an SQL query and generate an efficient query execution plan, or as advertised, an optimal plan. Optimizers are typically composed of sub-components, e.g., cardinality estimators and cost models, and typically involve a great deal of statistical estimations and heuristics. The main body of literature on query optimizers typically focuses on the direct optimization of a distinct component that performs better and col-lectively yields better results. Elaborate articles on query optimization have been published over time [18]. Nevertheless, query processing and optimization remain a continually active research domain.
An early work on query optimizers is LEO [151]. LEO gradually updates, in a process described as learning, cardinality estimates, and statistics, in turn for future use to produce optimized query execution plans. LEO utilizes a feedback loop to process history query information and adjust cost models appropriately for enhanced performance [151]. CORDS is another significant work on query optimizers, which reduces query execution time by exploring statistical dependencies between columns prior to query execution [64]. Another work Eddies supports adaptive query processing by reordering operators in a query execution plan dynamically [8]. Other contri-butions focus on the optimal selection of index structures [19, 53, 166]. More recent studies attempt to answer whether query optimizers have reached their peak, in terms of optimal per-formance, or suffer from limitations and potential performance degradation and how to mitigate them [91, 129].
在过去的几年中,数据库管理系统的优化方面进行了大量研究,特别是查询优化器——它与查询执行性能密切相关的关键组件。传统查询优化器以 SQL 查询为输入,并生成高效的查询执行计划,即所谓的最佳计划。优化器通常由子组件组成,如 cardinality 估计器和成本模型,通常涉及大量的统计估计和启发式算法。查询优化器的文献通常专注于直接优化表现更好的组件,并产生更好的结果。随着时间的推移,发表了许多关于查询优化的详细文章 [18]。然而,查询处理和优化仍然是一个持续活跃的研究领域。
查询优化器的先驱工作之一是 LEO[151]。LEO 通过一个称为学习的过程逐步更新,以未来使用为目标,生成优化的查询执行计划。LEO 使用反馈循环处理历史查询信息,并适当调整成本模型以提高性能 [151]。CORDS 是另一个重要的查询优化器工作,它在查询执行前利用列之间的统计依赖来减少查询执行时间 [64]。另一个工作 Eddies 支持动态地重新排列查询执行计划中的操作符,以支持自适应查询处理 [8]。其他贡献专注于最佳索引结构的选择 [19,53,166]。更近期的研究试图回答查询优化器是否已经达到了其最佳性能的极限,或者是否受到了限制和潜在性能下降的影响,以及如何减轻它们 [91,129]。
It is generally true that ML models are more capable of capturing a complex intuition regarding the data schemes. Thus, leveraging ML for query optimization seems a natural fit, as the exploratory nature of ML can assist in building complex estimation and cost models. Furthermore, the innate ability of ML to adapt to different environments via continuous learning can be a beneficial factor to execution plan optimizations.
这是一般而言的真实情况,即机器学习模型更能够捕捉数据模式的复杂直觉。因此,在查询优化中利用机器学习似乎是一种自然的选择,因为机器学习的探索性质可以帮助构建复杂的估计和成本模型。此外,机器学习模型通过持续学习适应不同环境的能力是查询执行计划优化的有益因素。然而,值得注意的是,在查询优化中实施机器学习需要仔细考虑数据质量、模型精度和计算资源等因素。
5.2.1 Index Structure Optimization. Kraska et al. introduce a revolutionary approach where they investigate the overhauling of existing indexes with learned ones, based on deep learning [84]. The authors leverage a hybrid mixture of ML models to replace optimized B-trees, point indices (i.e., hash-maps), and Bloom filters. The hybrid mixture, namely Recursive Model Index (RMI), is composed of neural networks in a layered architecture and is capable of predicting index po-sitions for B-trees and hash-maps. The simplest structure of zero hidden layers resembles linear regression, an inexpensive and fast model. Inference of the output models is done in a recursive fashion, where the top-layer neural network points to the next, and the same process is repeated until one of the base models, predicts the actual index position.
在索引结构优化方面,Kraska等人提出了一种革命性的方法,他们研究了利用深度学习学习现有索引的方法[84]。作者利用一种混合的机器学习模型组合来替换优化的B树、点索引(即哈希映射)和Bloom过滤器。这个混合模型被称为递归模型索引(RMI),由分层神经网络组成,能够预测B树和哈希映射的索引位置。零隐藏层的最简单结构类似于线性回归,是一种廉价快速的模型。输出模型的推理以递归方式进行,顶层神经网络指向下一个,重复这个过程,直到其中一个基本模型预测出实际的索引位置。
For Bloom filters, RMI does not fit. Thus, a more complex neural network with a sigmoid ac-tivation function is proposed, which approximates the probability that a key exists in the data-base. Comparisons with state-of-the-art approaches highlight ML as a strong rival. There are cases where reported execution speed is significantly higher, and memory footprint is sharply reduced. The novelty of the approach is a key step towards automation of data structures and optimization of DBMS, as it sets the pace for further exploration and exploitation of ML in a domain where performance is critical. ALEX extends the approach of Kraska’s et al. to provide support for write operations and dynamic workflows [33].
对于Bloom过滤器,RMI不适用。因此,提出了一种更复杂的神经网络,具有sigmoid激活函数,用于近似估计键存在于数据库中的概率。与最先进的方法进行比较,强调了机器学习作为一种强有力的竞争对手。在某些情况下,所报告的执行速度显著提高,内存占用明显减少。该方法的新颖性是实现数据结构自动化和数据库管理系统优化的关键步骤,为在性能至关重要的领域进一步探索和应用机器学习奠定了基础。ALEX将Kraska等人的方法扩展到提供支持写操作和动态工作流程的领域[33]。
5.2.2 Cardinality Estimation.
A slightly different attempt for alleviating wrongly predicted cost models and query cardinalities is presented in [125]. The authors seek to overcome the simplifying assumptions about the underlying data structure and patterns with the respective cost estimations, which are employed through hand-tuned heuristics. To do so, a deep neural network (DNN) is utilized that learns to output the cardinality of an input query, step by step, through division into smaller sub-queries. Moving forward, the authors utilize the estimated cardinalities to produce an optimal policy via Q-learning to generate query plans. The learning agent selects query operations based on the sub-queries, which incrementally result in a complete query plan.
在基数估计方面,[125]提出了一种稍微不同的尝试,以缓解错误预测成本模型和查询基数的问题。作者试图克服手调启发式算法通过对应的成本估计所应用的基础数据结构和模式的简化假设。为此,利用深度神经网络(DNN),通过将查询分解成较小的子查询,逐步学习输出查询的基数。接着,作者利用估计的基数通过Q-learning生成查询计划的最优策略。学习代理根据子查询选择查询操作,这些操作逐步导致完整的查询计划。
Kipf et al. focus on the prediction of join-crossing data correlations towards mitigating the drawbacks of current sampling-based cardinality estimation in query optimization [79]. The authors treat the problem with supervised learning by utilizing a DNN, defined as a multi-set convolutional network (MSCN), which in turn is integrated by a fully-connected multi-layer neural network. The MSCN learns to predict query cardinalities on unseen queries. Using unique samples, the model learns to generalize well to a variety of cases. More specifically, in a tough scenario with zero-tuples, where traditional sampling-based optimizers suffer, MSCN is able to provide a better estimation. Yang et al. take an unsupervised approach to cardinality and selectivity estimation with Naru [187]. Naru utilizes deep auto-regressive models to provide high-accuracy selectivity estimators produced in an agnostic fashion, i.e., without relying on assumptions, heuristics, specific data structures, or previously executed queries.
Kipf等人致力于预测查询优化中的跨表数据相关性,以减轻当前基于抽样的基数估计的缺点[79]。作者采用监督学习来解决这个问题,利用一个定义为多集合卷积网络(MSCN)的DNN,MSCN再由一个全连接的多层神经网络组成。MSCN学习使用未见过的查询预测查询基数。使用唯一的样本,该模型学习到了广泛的情况下的通用性。更具体地说,在一个零元组的困难情况下,传统的基于抽样的优化器出现问题,而MSCN能够提供更好的估计。Yang等人采用无监督的方式进行基数和选择性估计,并使用Naru[187]。Naru利用深度自回归模型以不带偏见的方式提供高精度的选择性估计器,即不依赖于假设、启发式算法、特定的数据结构或已执行的查询。
5.2.3 Join Ordering.
A more recent work called SkinnerDB targets adaptive query processing through optimization of join ordering [162]. SkinnerDB is based on a well-known RL algorithm, UTC [81]. Novelty lies on the fact that learning is done in real-time, during query execution, by slicing the query into small-time batches. It proceeds to select a near-optimal join order based on a qualitative measure, regret-bounded ratio, between anticipated execution time and time for an optimal join order [162]. SkinnerC, perhaps the most impactful variation of SkinnerDB, is able to outperform MonetDB, a specialized database engine for analytics, in the single-threaded mode, due to its ability to achieve highly reduced execution time in costly queries.
最近出现的一项研究名为SkinnerDB,旨在通过优化连接顺序实现自适应查询处理[162]。SkinnerDB基于一个众所周知的强化学习算法UTC [81]。其新颖之处在于,学习是在查询执行期间实时完成的,通过将查询分成小批次进行。它根据一种质量度量——预期执行时间与最佳连接顺序时间之间的遗憾有界比值——选择一个接近最优的连接顺序[162]。SkinnerC或许是SkinnerDB最有影响力的变体,在单线程模式下能够超越专门用于分析的数据库引擎MonetDB,因为它能够在代价高的查询中实现极大的执行时间缩短。
ReJOIN aims at addressing the difficulties in join order selection with a DRL approach [109]. Re-JOIN formulates the RL minimization objective as the selection of the cheapest join ordering with respect to the optimizer’s cost model. Each incoming query represents a discreet time-step, upon which the agent is trained on. For the task, ReJOIN employs a neural network trained on a policy gradient method. ReJOIN performs comparably or even better than the optimizer of PostgreSQL. The evaluation is conducted on a dataset specifically designed for measuring the performance of query optimizers, namely the join order benchmark (JOB) [91].
ReJOIN旨在通过DRL方法解决连接顺序选择中的困难问题[109]。ReJOIN将RL最小化目标表述为选择最便宜的连接顺序,以优化器的成本模型为基础。每个传入的查询表示离散时间步,代理在此进行训练。为了完成任务,ReJOIN采用一种基于策略梯度方法训练的神经网络。ReJOIN的性能与甚至优于PostgreSQL的优化器相当。评估是在一个特别设计用于评估查询优化器性能的数据集上进行的,即连接顺序基准测试(JOB)[91]。
Another notable attempt is DQ [85], a DRL optimizer that exploits Q-learning in a DNN archi-tecture to learn from a sampled cost model to select the best query plan, in terms of an optimal join sequence. To mitigate failures in cardinality estimation regarding the cost model, DQ initially converges on samples collected from the optimizer’s cost model [85]. Then, weights of the neural network are stored and DQ trains again on samples gathered from real execution runs. In terms of execution, the relative Q-function is utilized to obtain the optimal join operation. Extensive eval-uation indicates that DQ is remarkably more effective than ReJOIN and in a wider scope of JOB queries. Further, DQ is able to scale by incorporating more features in an effort to achieve more accurate join cost prediction.
另一个值得注意的尝试是DQ [85],它是一个DRL优化器,利用DNN体系结构中的Q-learning从采样成本模型中学习,选择最佳的查询计划,以得到最优的连接顺序。为了缓解成本模型中基数估计的失败,DQ最初汇聚自优化器成本模型中收集的样本[85]。然后,神经网络的权重被存储下来,DQ再次针对来自实际执行运行收集的样本进行训练。在执行方面,相对Q函数被用于获得最优的连接操作。广泛的评估表明,DQ比ReJOIN在JOB查询的更广泛范围内更有效。此外,DQ能够通过合并更多的特征来扩展,以努力实现更准确的连接成本预测。
In adaptive query processing, an early approach picks off from Eddies [8], and leverages RL to train optimal eddy routing policies [164]. The authors focus is on join and conjunctive selection queries. Additionally, the proposed framework incorporates various join operators and constraints from the state-of-the-art literature. Overall, the results indicate significance in learning an optimal query execution plan and fast reactions to changes. This work can be considered an infant step towards learned query optimizers.
在自适应查询处理中,早期的一种方法是从Eddies [8]中提取并利用RL来训练最优的eddy路由策略[164]。作者的重点是连接和合取选择查询。此外,所提出的框架还包括来自最新文献的各种连接运算符和约束条件。总的来说,结果表明,学习最优查询执行计划以及对变化做出快速反应具有重要意义。这项工作可以被视为向学习的查询优化器迈出的第一步。
5.2.4 End-to-end Query Optimization. Different from the above works that focus on distinct components of query optimizers, Neo builds an end-to-end query optimizer based on ML [110]. Neo, short for Neural Optimizer, utilizes different DL models to replace each of the components of a common optimizer. Neo relies on prior knowledge to kick-start but continues learning when new queries arrive. This approach makes Neo robust to dynamic environments, regarding unfore-seen queries, albeit Neo cannot generalize to schema and data changes. Neo’s contributions are manifold. Besides adaptation to changes, Neo is able to decide between three different common operations, namely join ordering, index selection, and physical operator selection [110]. Moreover, Neo integrates easily with current execution engines and users can specify their optimization objectives. Evaluations show that Neo outperforms simple optimizers and exhibits comparable performance to long-lived commercial ones.
与上述聚焦于查询优化器不同的工作不同,Neo基于ML构建了一种端到端的查询优化器[110]。Neo代表神经优化器,利用不同的DL模型来替代常见优化器的每个组件。Neo依赖于先前的知识来启动,但在新的查询到达时继续学习。这种方法使得Neo对于动态环境具有鲁棒性,包括无法预见的查询,尽管Neo无法泛化到模式和数据的变化。Neo的贡献是多方面的。除了适应变化外,Neo能够在连接顺序选择、索引选择和物理操作符选择这三个常见操作之间做出决策[110]。此外,Neo与当前的执行引擎集成容易,用户可以指定他们的优化目标。评估表明,Neo优于简单的优化器,并表现出与长期商用优化器相当的性能。
Another notable attempt is DQ [85], a DRL optimizer that exploits Q-learning in a DNN archi-tecture to learn from a sampled cost model to select the best query plan, in terms of an optimal join sequence. To mitigate failures in cardinality estimation regarding the cost model, DQ initially converges on samples collected from the optimizer’s cost model [85]. Then, weights of the neural network are stored and DQ trains again on samples gathered from real execution runs. In terms of execution, the relative Q-function is utilized to obtain the optimal join operation. Extensive eval-uation indicates that DQ is remarkably more effective than ReJOIN and in a wider scope of JOB queries. Further, DQ is able to scale by incorporating more features in an effort to achieve more accurate join cost prediction.
另一个值得注意的尝试是DQ [85],它是一个利用强化学习(DRL)的优化器,可以在DNN架构中从样本代价模型中学习并选择最佳查询计划,以获得最优联接顺序。为了减轻与成本模型相关的基数估计失败,DQ最初会在优化器的成本模型中收集样本并收敛[85]。然后,神经网络的权重被存储下来,DQ再次训练从实际执行运行中收集的样本。在执行方面,相对Q函数被利用来获得最佳联接操作。广泛的评估表明,与ReJOIN相比,DQ在更广泛的JOB查询范围内显著更有效。此外,DQ能够通过加入更多特征来扩展,从而实现更准确的联接成本预测。总体来说,这似乎是一个优化查询计划的有用工具。
In adaptive query processing, an early approach picks off from Eddies [8], and leverages RL to train optimal eddy routing policies [164]. The authors focus is on join and conjunctive selection queries. Additionally, the proposed framework incorporates various join operators and constraints from the state-of-the-art literature. Overall, the results indicate significance in learning an optimal query execution plan and fast reactions to changes. This work can be considered an infant step towards learned query optimizers.
在自适应查询处理中,早期的方法是基于Eddies [8]并利用强化学习(RL)来训练最优Eddy路由策略[164]。作者的重点是联接和选择查询。此外,所提出的框架还结合了最新文献中的各种联接操作符和约束条件。总体而言,结果表明学习最优查询执行计划和快速应对变化的意义显著。这项工作可以被视为学习查询优化器的初步尝试。
5.2.4 End-to-end Query Optimization. Different from the above works that focus on distinct components of query optimizers, Neo builds an end-to-end query optimizer based on ML [110]. Neo, short for Neural Optimizer, utilizes different DL models to replace each of the components of a common optimizer. Neo relies on prior knowledge to kick-start but continues learning when new queries arrive. This approach makes Neo robust to dynamic environments, regarding unfore-seen queries, albeit Neo cannot generalize to schema and data changes. Neo’s contributions are manifold. Besides adaptation to changes, Neo is able to decide between three different common operations, namely join ordering, index selection, and physical operator selection [110]. Moreover, Neo integrates easily with current execution engines and users can specify their optimization objectives. Evaluations show that Neo outperforms simple optimizers and exhibits comparable performance to long-lived commercial ones.
5.2.4 端到端查询优化。
不同于以上关注查询优化器各个组成部分的工作,Neo基于ML构建了一个端到端查询优化器[110]。Neo(神经优化器)利用不同的DL模型来替代常见优化器的每个组件。Neo依赖于先前的知识来启动学习,但当新查询到来时继续学习。这种方法使得Neo对于动态环境的意外查询具有鲁棒性,尽管Neo无法推广到模式和数据变化。Neo的贡献是多方面的。除了对变化的适应能力,Neo能够在三个不同的常见操作之间决定,即联接排序,索引选择和物理操作符选择[110]。此外,Neo与当前执行引擎集成容易,用户可以指定优化目标。评估结果表明,Neo优于简单优化器,并且表现出与长寿商业优化器相当的性能。
Around the same time with Neo, SageDB conceptualizes the vision for a DBMS where crucial components, including the query optimizer, are substituted with learned ones [83]. Overall, the
article describes the design of such a system and how would all components tie together in a complete solution. Two approaches that concern optimization of queries in a distributed setting are Lube [172] and its sequel, Turbo [173]. Both techniques leverage ML models that concern query execution in clusters. More specifically, Lube regards minimization of response times for a query by identifying and resolving bottlenecks [172]. On the other hand, Turbo, aims at optimizing query execution plans dynamically [173].
几乎与 Neo 同时,SageDB 提出了一种数据库管理系统 (DBMS) 的愿景,其中关键组件,包括查询优化器,将被学习所取代 [83]。总体而言,文章描述了这样的系统的设计方案,以及所有组件如何在整个解决方案中紧密协作。在分布式环境中优化查询的两个方法是 Lube 和其续集 Turbo。两种方法都利用集群中查询执行的 ML 模型。具体而言,Lube 通过识别和解决瓶颈来最小化查询响应时间 [172]。另一方面,Turbo 旨在动态优化查询执行计划 [173]。
5.3 Discussion on ML-based Approaches
Despite the decades of active research on DBMS and query optimization, it remains a fact that performance is far from optimal [90, 91, 129]. Yet, the pivotal role of databases in modern sys-tems calls for further scrutiny. Similar to the problems in memory systems, query optimization in databases also heavily relies on the prediction of the data pattern on which ML-based approaches have demonstrated clear benefits over traditional approaches in complex scenarios. We witness the quest to yield better performance by leveraging ML in query optimization schemes. Moreover, we observe how multi-faceted those approaches are. For instance, ReJoin [109] and DQ [85] utilize DRL to tackle the selection of optimal join sequences, while Kipf et al. focus on cardinality esti-mation through supervised learning [79]. Additionally, when traditional approaches suffer and as modern computational units migrate to more distributed settings, we notice significantly broader approaches that target query processing accordingly (e.g., Turbo). More interestingly, we are per-ceiving the progress of research and how it essentially dissolves into unified schemes as recent works conceptualize end-to-end solutions (e.g., Neo and SageDB) by leveraging ML.
尽管数据库管理系统和查询优化已经进行了数十年的积极研究,但仍然存在性能远远没有达到最佳状态的事实 [90, 91, 129]。然而,现代系统中数据库的关键作用要求进一步审查。与内存系统类似,数据库中的查询优化也在很大程度上依赖于数据模式的预测,其中基于 ML 的方法在复杂的场景中比传统方法显示出明显的优势。我们在利用 ML 在查询优化方案中追求更好的性能方面见证了努力。此外,我们观察到这些方法有多么多方面。例如,ReJoin [109] 和 DQ [85] 使用 DRL 解决最佳连接序列的选择问题,而 Kipf 等人则通过监督学习关注 cardinality 估计 [79]。此外,当传统方法受到困扰,现代计算单元向更分布式的设置迁移时,我们注意到针对查询处理显著更为广泛的方法 (例如 Turbo)。更有趣的是,我们发现研究的进展实际上已经转化为统一的方案,随着最近的作品利用 ML 概念化端到端解决方案 (例如 Neo 和 SageDB)。
6 NETWORK PACKET CLASSIFICATION
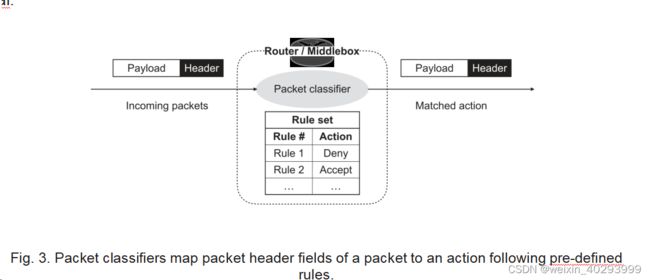
Packet classification is a crucial and fundamental networking task, which enables a variety of network services. Typical examples of such network services include traffic engineering (e.g., flow scheduling and load balancing), access control, and firewall [55, 158]. A high-level overview of packet classification is depicted in Figure 3. Given a collection of rules, packet classification matches a packet to one of the given rules. Rule matching is based on certain criteria typically applied on the fields in the packet header such as source and destination IP addresses, protocol type (often including flags), and source and destination port numbers. Matching conditions in-clude prefix-based matching, range-based matching, and exact matching. Considering the ever-increasing network traffic, packet classification dictates the need for high performance in terms of classification speed and memory efficiency. These traits need to include also a high level of classi-fication accuracy, since mismatches can result in serious network issues such as security breaches.
网络数据包分类是一项关键和基本的网络任务,它为各种网络服务提供了基础。这些网络服务的典型例子包括交通工程 (如流调度和负载均衡)、访问控制和防火墙 [55,158]。在图 3 中,提供了一个高层次的概述,描述了数据包分类的过程。给定一组规则,数据包分类将一个数据包匹配到一个给定的规则。规则匹配基于一些标准,通常在数据包头部的字段上应用,如源和目标 IP 地址、协议类型 (常常包括标志),以及源和目标端口号。匹配条件包括前缀匹配、范围匹配和精确匹配。考虑到不断增加的网络流量,数据包分类要求在分类速度和内存效率方面具有高性能。这些特征还需要包括高级别的分类准确性,因为不匹配可能会导致严重的网络问题,如安全漏洞。
6.1 Traditional Approaches and Limitations
6.1 对传统方法和限制的分析
The solution space for packet classification can be generally divided into hardware- and software-based approaches. Hardware-based approaches typically leverage ternary content addressable memories (TCAMs) and are considered the standard in industrial high-performance routers and middleboxes. TCAM is a specialized type of high-speed memory, which stores matching rules as a massive array of fixed-width entries [89] and is able to perform multi-rule matching in constant time. Early work also extends TCAMs to increase performance on lookups and reduce power consumption by utilizing a special storage block that is indexed before resolving to subsequent lookups [146]. Although the use of TCAMs significantly boosts classification speed, these solutions have inherit limitations including poor scalability (e.g., in-range expansion), high cost, and high power consumption [89].
对于包分类的解决方案,可以总体上分为硬件和软件两种方法。硬件方法通常利用三态内容可寻址存储器 (TCAMs),并在工业高性能路由器和中间件中被视为标准。TCAM 是一种高速存储器,它以大规模固定宽度数组的形式存储匹配规则,并能够在常数时间内执行多规则匹配。早期的工作还扩展了 TCAMs,以在查找性能方面增加性能,并利用一个特殊的索引存储块,在解决后续查找之前进行索引 [146]。尽管使用 TCAMs 显著地提高了分类速度,但这些解决方案存在继承的局限性,包括糟糕的可扩展性 (例如范围扩展),高成本,和高功耗 [89]。
On the other hand, software-based approaches offer greater scalability but suffer performance-wise in general. A representative family of software-based approaches is based on tuple space in-troduced in [148]. These approaches partition rules into tuple categories and leverage hashing keys for accessing the tuple space of a particular filter [158]. While yielding fast queries, the hashing induces non-deterministic speeds on look-ups or updates [54]. Another family of software-based approaches is based on decomposition. A noteworthy work in this family is DCFL [159], which takes a distributed approach to filter searching. In particular, independent search engines match the filter fields and aggregate the results in an arbitrary order [158]. However, this technique man-dates multiple table accesses, thus impacting performance [167].
另一方面,基于软件的方法具有更大的可扩展性,但通常性能不佳。一种典型的基于软件的方法是基于元组空间的 [148]。这些方法将规则分为元组类别,并使用特定的哈希键来访问特定过滤器的元组空间 [158]。虽然这种方法会导致快速的查询,但哈希会导致查找或更新时的非确定性速度 [54]。另一种基于软件的方法是基于分解的。在这个家族中,值得注意的是 DCFL[159],它采用分布式方法进行过滤器搜索。特别是,独立的搜索引擎匹配过滤器字段,并按任意顺序聚合结果 [158]。然而,这种方法要求多次表访问,因此会影响性能 [167]。
Most software-based packet classification approaches are based on decision trees. The idea is to classify packets by traversing a set of pre-built decision trees and selecting the highest priority rule among all matched rules in one or more decision trees. To reduce the classification time and mem-ory footprint, decision trees are optimized to have small depths and sizes based on hand-tuned heuristics like node cutting or rule partitioning [54, 142]. EffiCuts, which builds on its predeces-sors HiCuts [54] and HyperCuts [142], significantly reduces memory footprint by employing four heuristics: separable trees, selective tree merging, equi-dense cuts, and node co-location [167]. A more recent work, CutSplit, optimizes decision trees on the premises of reducing rule overlap-ping, unoptimized yet faster first stage cuttings, and by effective pre-cutting and post-splitting actions [94]. Another work leverages decision trees and TCAMs in a hybrid approach [82].
大多数基于软件的包分类方法都基于决策树。这种方法是通过遍历一组预先构建的决策树,并在所有匹配的决策树中选择最高优先级的规则来进行分类的。为了降低分类时间和内存占用,决策树通过手动调整的启发式算法 (如节点切割或规则分割) 进行优化,以小的深度和大小为目标 [54, 142]。EffiCuts,建立在其前身 HiCuts[54] 和 HyperCuts[142] 之上,通过采用四种启发式算法:可分离树、选择性树合并、等密度切割和节点共放置,显著减少了内存占用,采用了分离树、选择性树合并、等密度切割和节点共放置等有效前缀切割和后分割操作 [167]。最近,CutSplit 提出了一种新的方法,旨在减少规则重叠,同时对未优化但更快的第一级切割进行预处理和后分割操作 [94]。另一个工作采用了决策树和 TCAM 的混合方法 [82]
Limitations of traditional approaches: Current hardware- and software-based solu-tions pose strong limitations to effective packet classification. As discussed, hardware ap-proaches fall short in terms of scalability and exhibit significant monetary and power costs, while software solutions rely on hand-tuned heuristics. Heuristics can be either too general to exploit the characteristics of a given rule set or too specific to achieve good performance on other rule sets. In addition, the lack of a specific, global optimization objective in the heuristic design can result in sub-optimal performance. Finally, the incorporation of differ-ent heuristics into a single solution can incrementally increase the overall complexity of the approach, hindering optimization due to difficulty in unders.
传统方法的限制:当前的硬件和软件解决方案对有效的数据包分类提出了强烈的限制。正如讨论的那样,硬件方法在可扩展性和成本方面表现不佳,而软件解决方案则依赖于手工调整的启发式算法。启发式算法可能过于通用,无法利用给定规则集的特点,或者过于特定,无法在其他规则集上实现良好的性能。此外,启发式设计缺乏特定的全球优化目标,可能会导致较差的性能。最后,将不同的启发式算法整合到单个解决方案中可以增加整体解决方案的复杂性,从而阻碍优化,因为难以理解它们。
ML for packet classification typically replaces the classifier with a model pre-trained with super-vised learning. However, with the recent advances in DRL, the solution space of packet classifica-tion approaches broadens. In general, there are three categories: (1) using supervised learning to replace the classifier with a trained model, (2) using RL agents to generate suitable decision trees at runtime according to the given set of rules, and (3) leveraging unsupervised learning to cluster unforeseen traffic.
用于数据包分类的机器学习通常将监督学习预训练的模式替换为 Classifier。然而,随着最近深度学习技术的进步,数据包分类方法的解决方案空间扩大了。总的来说,有三个类别:(1) 使用监督学习将训练模型替换为 Classifier,(2) 使用强化学习代理根据给定的规则集在运行时生成适当的决策树,(3) 利用无监督学习将未预见的流量分组。
Approach (1) fits naturally since packet classification is by definition a classification task. These approaches commonly utilize a traditional supervised learning setting where information concern-ing incoming traffic is known a priori and traffic is classified into distinct labeled sets. Traditional supervised learning proposals for packet classification have also been reviewed extensively in [124]. Yet, the first remarkable work in this direction that leverages DL targeting traffic classifica-tion is only recently introduced with Deep Packet [100]. This work leverages convolutional neu-ral networks (CNNs) to construct a traffic classifier that is able to characterize traffic and identify applications without given advanced intelligence (i.e., hand-tuned features). Despite the promis-ing results, the accuracy requirement of packet classification renders the neural network-based approach impractical. This is because neural networks cannot guarantee the correct matching of rules. Moreover, the size of the neural network has to be big enough in order to handle a large set of rules. Thus, achieving high performance is very unlikely without hardware accelerators like GPUs [97]. Further, supervised learning schemes are generally limited by design as supervised learning necessitates certain information is known in advance [130].
方法 (1) 自然地适合,因为分组分类本身就是一种分类任务。这些方法通常使用传统的监督学习方法,其中输入流量的信息事先已知,并将流量分类为不同的标记组。在 [124] 中详细介绍了传统监督学习方法用于分组分类的建议。然而,第一个利用深度学习 (DL) 针对流量分类进行优化的工作直到最近才出现,即 Deep Packet[100]。这项工作利用卷积神经网络 (CNNs) 构建一个流量分类器,可以特征化流量并识别应用程序,而不需要高级智能 (即手动调整特征)。尽管结果令人鼓舞,但分组分类的准确性要求使得基于神经网络的方法不实用。这是因为神经网络不能保证规则的正确匹配。此外,神经网络的大小必须足够大,以处理大型规则集。因此,没有像 GPU 这样的硬件加速器,实现高性能非常不太可能 [97]。此外,监督学习方法通常被设计为有限制的,因为监督学习需要事先知道一些信息。
Approach (2) learns at the meta-level where we learn to generate appropriate decision trees and use the resulting decision trees for actual packet classification. This way, ML methods are out of the critical path so performance is no longer an issue. NeuroCuts is to the best of our knowledge the first work that employs a DRL method for decision tree generation [97]. NeuroCuts employs a DRL approach in a multi-agent learning setting by utilizing an actor-critic algorithm based on Proximal Policy Optimization (PPO) [137]. An agent executes an action in each discrete time step with the target of obtaining a maximized reward. The action depends on the observed en-vironment state. Following the same footsteps, Jamil et al. introduce a classification engine that leverages DRL to generate an optimized decision tree [70]. In detail, the derived tree concentrates the essential bits for rule classification into a compact structure that can be traversed in a sin-gle memory access [70]. Then, the outcome of the traversal of the generated tree is utilized in the original tree to classify packets. This results in a lower memory footprint and higher packet classification speed.
方法 (2) 在元级别学习,即学习生成适当的决策树,并使用生成的决策树进行实际分组分类。这种方式下,机器学习方法不再处于关键路径上,因此性能不再是问题。据我们所知,NeuroCuts 是第一项使用 DRL 方法生成决策树的研究工作 [97]。NeuroCuts 使用基于 Proximal Policy Optimization (PPO) 的 actor-critic 算法,在多代理学习环境中使用 DRL 方法。在每个离散时间步中,代理执行目标获得最大化奖励的动作。动作取决于观察到的环境状态。仿照同一步伐,Jamil 等人介绍了一种分类引擎,利用 DRL 生成优化的决策树 [70]。具体而言,生成的树将规则分类的 essential bits 集中在一个可一次内存访问的紧凑结构中 [70]。然后,生成的树的遍历结果应用于原始树,以分类数据包。这导致更低的内存占用和更高的分组分类速度。
Finally, following approach (3), Qin et al. leverage an unsupervised learning scheme to miti-gate drawbacks of prior supervised learning solutions [130]. As mentioned in their work, existing supervised approaches fail to adjust to network changes as unforeseen traffic arrives and classifi-cation performance deteriorates. Besides, the authors advocate in favor of link patterns as a crucial property on network knowledge, while most approaches utilize only packet-related features. They propose a novel combinatorial model that considers both sources of information (packet and link patterns), in a clustering setting [130]. The approach is evaluated against several baselines of su-pervised and clustering algorithms and is able to outperform all of them, building a strong case for traffic classification with unsupervised learning.
最后,按照方法 (3),Qin 等人利用无监督学习方案来缓解先前监督学习解决方案的缺点 [130]。在他们的工作中,现有的监督学习方法无法适应网络变化,因为意想不到的流量到达时,分类性能会恶化。此外,作者主张支持链接模式作为网络知识的关键属性,而大多数方法只使用数据包相关的特性。他们提出了一种新颖的组合模型,考虑了两种信息来源 (数据和链接模式),在聚类设置中 [130]。该方法与多个监督和聚类算法的基线进行比较,能够优于它们,为使用无监督学习进行流量分类建立了强有力的例子。
6.3 Discussion on ML-based Approaches
Recent works in packet classification provide us with several useful insights. First, we observe that technological advancements in ML drive stimuli in the way researchers approach now the chal-lenge of packet classification. For instance, typical solutions that used to solely focus on training packet classifiers have now diverged to more radical, unorthodox approaches. Second, we can see that significant effort has been put towards leveraging DRL-based solutions, perhaps the most re-cently advanced and trending research domain for the past few years. Third, we observe that ML often entails more performance metrics than common approaches. For example, classification accu-racy is a critical metric in packet classification with supervised learning, whereas hardware-based Machine Learning for Computer Systems and Networking approaches (e.g., TCAMs) do not impose such constraints. Finally, we can deduce that as the scope of work widens, more and more works that target similar directions will be explored and proposed. For example, Li et al. propose a novel way of caching rules into memory with LSTM neural net-works, which can be directly exploited for packet classification [93]. Overall, ML-based approaches address the limitations of traditional approaches by being more generalizable, being able to incor-porate complex optimization goals, and reducing the design complexity. However, they still fall short for critical scenarios due to the lack of guarantee in results and explainability. In scenarios where accuracy is of critical importance, traditional approaches would still be preferable.
最近在数据包分类方面的研究为我们提供了几个有用的见解。首先,我们观察到机器学习技术的进步推动了研究人员现在处理数据包分类挑战的方式。例如,传统的解决方案只关注训练数据包分类器,现在已经发展为更激进、非常规的方法。其次,我们可以看到,重要的努力已经投入到利用基于深度强化学习的解决方案中,这可能是过去几年中最先进和最流行的研究领域。第三,我们观察到,机器学习通常涉及的性能指标比常规方法更多。例如,监督学习中的分类准确性对于基于硬件的机器学习计算机系统和网络方法(例如TCAM)并不施加限制。最后,我们可以推断出,随着工作范围的扩大,将探索和提出越来越多的针对类似方向的工作。例如,Li等人提出了一种利用LSTM神经网络将规则缓存到内存中的新方法,这可以直接用于数据包分类[93]。总体而言,基于机器学习的方法通过更具通用性、能够融合复杂的优化目标和降低设计复杂性来解决传统方法的局限性。但是,在关键场景中仍然存在结果保证和可解释性不足的问题。在关键性能准确性至关重要的场景中,传统方法仍然更可取。
7 NETWORK ROUTING
Traffic Engineering (TE) is the process of optimizing performance in traffic delivery [175]. Per-haps the most fundamental task of TE is routing optimization, a path selection process that takes place between or across networks. More specifically, packet routing concerns the selection of a path from a source to a destination node through neighboring nodes. In each traversing node, routing aims at answering the question of which adjacent node is the optimal node to send the packet. Common objectives of packet routing involve optimal time to reach the destination, max-imization of throughput, and minimum packet loss. It should be applicable to a broad variety of network topologies.
流量工程(TE)是在交付流量方面优化性能的过程[175]。也许TE最基本的任务是路由优化,这是一个在网络之间或跨越网络之间发生的路径选择过程。更具体地说,数据包路由涉及从源节点到目标节点的路径选择,通过相邻节点。在每个传输节点中,路由的目标是回答哪个相邻节点是发送数据包的最优节点。数据包路由的常见目标是达到目的地的最佳时间、最大吞吐量以及最小的数据包丢失率,它应该适用于各种各样的网络拓扑。
7.1 Traditional Approaches and Limitations
Routing is a broad research subject with a plethora of differing solutions and approaches proposed over the years. Routing commonly differentiates between intra- and inter-domain. The former concerns packets being sent over the same autonomous system (AS) in contrast with the latter, which regards sending packets between ASes. Routing can also be classified based on enforcement mechanisms or whether it concerns offline/online schemes, and furthermore on the type of traffic per se [175]. Based on this wide taxonomy, which only expands with emergent network topolo-gies, there are distinct types of proposed solutions, as well as research that typically considers a more fine-grained domain of routing optimization. As our interests lies mostly in computer sys-tems, we concentrate mainly on intra-domain traffic engineering. A comprehensive survey that covers routing optimization in a coarse-grained manner that concerns traditional networks and topologies is presented in [175]. For surveys on routing in wireless sensor networks and ad-hoc mobile networks, we refer the readers to [5].
路由是一个广泛的研究主题,多年来提出了大量不同的解决方案和方法。路由通常区分为域内和域间。前者涉及在同一自治系统(AS)中发送数据包,而后者涉及在AS之间发送数据包。路由也可以根据强制执行机制或其是否涉及在线/离线方案以及流量类型而进行分类[175]。基于这种广泛的分类法,随着新的网络拓扑的出现,存在不同类型的解决方案,以及通常考虑更细粒度的路由优化领域的研究。由于我们的兴趣主要集中在计算机系统方面,主要集中在域内流量工程方面。一部涵盖传统网络和拓扑结构的粗粒度路由优化综述可以在[175]中找到。关于无线传感器网络和自组织移动网络中路由的综述,我们建议读者参考[5]。
Regarding intra-domain traffic engineering, open shortest path first (OSPF) solutions are prevalent favoring simplicity but often suffer in performance. OSPF solutions cope well with scala-bility as network growth has reached an all-time high, but have pitfalls when it comes to resources utilization [115]. As in the case of packet classification, common OSPF proposals are based on hand-tuned heuristics [147]. Moreover, most of existing literature that aims at meditating the per-formance boundaries set by OSPF approaches, have seen rare actual implementation [115].
关于域内交通工程,开放最短路径优先 (OSPF) 解决方案普遍存在,倾向于简单性,但往往性能不佳。当网络增长达到历史新高时,OSPF 解决方案能够很好地应对可扩展性,但在资源利用率方面存在陷阱 [115]。就像 packet classification 一样,常见的 OSPF 提案基于手动调节的经验法则 [147]。此外,旨在反思 OSPF 方法所设定的性能边界的大部分现有文献,都罕见实际实施 [115]。
In addition, we find it necessary to add some notes about software-defining networking (SDN). Conventional, non-SDN, network devices embed dedicated software to implement network-ing logic, such as packet routing, and are characterized by long and costly evolution cycles. SDN reduces networking devices to programmable flow-forwarding machines, with networking logic now running at a logically centralized controller, adding more flexibility in programming the net-working behaviors [112]. SDN can therefore be seen as a way to implement routing decisions at network devices, but it does not change the nature of the routing problem, which now needs to be solved by the controller. We do not go further into such implementation details and refer the readers to published surveys in this area, e.g., [42].
此外,我们认为有必要对软件定义网络 (SDN) 添加一些注释。传统上,非 SDN 网络设备嵌入专用软件以实现网络逻辑,例如 Packet routing),并且具有漫长和昂贵的进化周期。SDN 将网络设备减少为可编程的流量转发机器,网络逻辑现在在逻辑上集中的控制器上运行,增加编程网络行为的自由度 [112]。因此,SDN 可以被视为在网络设备上实现路由决策的一种方式,但它不改变路由问题的本质,这需要控制器来解决。我们不再深入探讨这些实现细节,并读者参考已发表的调查,例如 [42]。
Limitations of traditional approaches: The main challenge of network routing consists in the ever-increasing dynamics of the networks, including the traffic loads as well as the network characteristics (e.g., topology, throughput, latency, and reliability), and the multi-faceted optimization goals (reflecting the user quality of experience ultimately), which are hard to be interpreted as a simple formula for handcrafted heuristics to optimize. The im-plementation complexity of network routing optimization is also a practical concern.
传统方法的局限性:网络路由的主要挑战是网络不断增长的动力学,包括流量负载和网络特征 (如拓扑、吞吐量、延迟和可靠性),以及多方面的优化目标 (最终反映用户服务质量)。这些目标很难用简单的手工启发式方法进行优化。此外,网络路由优化的实现复杂性也是一个实际问题。
The first work involving ML on the challenge of traffic engineering dates back to 1994, namely Q-Routing [15]. Leveraging a fundamental RL algorithm, Boyan et al. propose a learning-based ap-proach to tackle the problem. Q-Routing derives from Q-learning [177], and is able to generate an efficient policy with a minimization objective—the total time to deliver a packet from source to des-tination. By conducting a series of experiments on different network topologies and dynamic net-works, Q-Routing exhibits significant performance gains, especially on congested network links, over static approaches. More importantly, Q-Routing establishes RL as a natural fit to the problem and paved the way for research on learnt systems for traffic engineering.
第一项涉及机器学习 (ML) 的交通工程挑战工作可以追溯到 1994 年,即 Q-Routing [15]。利用一项基本强化学习算法,Boyan 等人提出了一种基于学习的解决方案,以解决该问题。Q-Routing 源自 Q-learning [177],能够生成以最小化目标 (从源到目的的总时间) 为优化目标的高效策略。通过在不同网络拓扑和动态网络中进行一系列实验,Q-Routing 展示了在静态方法之上显著的性能提升,特别是在网络拥堵的链接上。更重要的是,Q-Routing 确立了强化学习适用于该问题,并为交通工程领域的学习系统研究铺平了道路。
Since the introduction of Q-Routing, several works have emerged that utilize alternative RL methods or study various network topologies and scope of applications. A comprehensive survey of these solutions w.r.t. all known network topologies, i.e., from static to dynamic vehicular and ad-hoc networks, is provided in [104]. However, it is clear from the survey that when it comes to implementation, the tremendous state and action space quickly becomes a hefty burden in learning and thus results in sub-optimal solutions. The application of DL to network traffic control and essentially routing optimization has been studied in [44, 105, 165]. In detail, Fadlullah et al. take a high-level overview of what is comprised as a supervised learning scheme with deep belief networks (DBNs) [26], which predicts on a node basis the next path (i.e., router) to deliver to and in turn, the destination node does the same and so forth [44]. In this approach, each node is solely responsible for outputting the next node and the full delivery path is uncovered in a hop-by-hop manner. Interestingly enough, Mao et al. take a similar supervised approach with Deep Belief Architectures (DBAs) in their work [165]. Even though both approaches are novel and interesting first-steps, they are applied in a constrained static setting raising questions that come naturally as how supervised learning can be scaled and applied efficiently into dynamic and large network topologies.
自从 Q-Routing 提出以来,已经出现了一些利用其他强化学习方法或研究各种网络拓扑和应用范围的工作。在 [104] 中提供了对这些解决方案的全面调查,特别是对于所有已知网络拓扑,包括静态、动态车辆和自组织网络等。然而,调查表明,在实施时,巨大的状态和行为空间很快成为学习的负担,从而导致次优解决方案。深度学习 (DL) 应用于网络交通控制和实质上是路由优化已经研究了 [44, 105, 165]。具体而言,FADLULLAH 等人提出了一种高层次的概述,描述了使用深度信念网络 (DBNs) 的受监督学习方案,该方案对节点进行预测,确定下一个路径 (即路由器),并以此类推,目的地节点也是如此 [44]。在此方案中,每个节点仅负责输出下一个节点,并逐跳地揭示完整的传输路径。有趣的是,MAO 等人在他们的工作中也采用了类似的受监督方法,使用了深度信念架构 (DBAs)。尽管这两种方法都是新颖和有趣的第一步,但它们在受约束的静态环境中应用,自然引发了如何对受监督学习进行有效扩展和应用于动态和大型网络拓扑的问题。
Mao et al. bring RL back on the table in [165]. Initially, the authors evaluate a supervised learning scheme through varying DNN architectures. By observing past Demand Matrices (DMs) the neural network learns to predict the DM which is then leveraged to calculate the optimal routing strategy for the next epoch. The evaluation results, however, show that supervised learning is not a suitable approach for dynamic settings. The authors therefore employed DRL and interchanged the prediction of DMs to learn a good mapping policy. Also, the design shifts to a more constrained setting, focusing on destination-based routing strategies. The agent’s reward is now based on max-link-utilization, and the algorithm of choice is Trust Region Policy Optimization (TRPO) [136]. As the large action space can cripple the learning process, the number of output parameters is reduced by shifting learning to per-edge weights. While this DRL-based mechanism yields better results, compared with the supervised solution, the proposed solution is not significant enough to alter the domain of routing as it is.
MAO 等人在 [165] 中把强化学习 (RL) 重新引入到讨论中。最初,作者通过使用不同的深度神经网络 (DNN) 架构进行评估,以进行受监督学习评估。通过观察过去的流量矩阵 (DMs),神经网络学会预测 DM,然后被用于计算下一时代的最优路由策略。然而,评估结果表明,受监督学习不适于动态环境。因此,作者采用了深度强化学习 (DRL),并交换了 DM 的预测,以学习良好的映射策略。此外,设计转移到更具约束的环境,重点着眼于基于目的地的路由策略。现在,代理的奖励基于最大链接利用率,所选算法是信任区域策略优化 (TRPO)。由于大动作空间可能会瘫痪学习过程,因此将学习转移到每个边权值上进行输出参数的减少。虽然这种基于 DRL 的机制相对于受监督解决方案取得了更好的结果,但提出的解决方案并没有显著到足以改变路由的领域。
To mitigate the risk of state space explosion and significant overhead of globally updating a sin-gle agent, a distributed, multi-agent approach is applied in [191]. In particular, You et al. pick up
where [15] left off. As a first step, they upgrade the original Q-Routing contribution by exchanging the Q-Table with a DNN, namely deep Q-Routing (DQR), but leaving the remainder of the algo-rithm pristine. In contrast to the semantics of the approach, the authors differentiate their proposal by specifying a multi-agent learning environment. As such, every network node holds its own agent, and each agent is able to make local decisions deriving from an individual routing policy.
为了减轻状态空间爆炸的风险和全球更新单个代理的显著开销,[191] 采用了分布式、多代理的方法。特别是,You 等人继承了 [15] 的工作。作为第一步,他们升级了原始的 Q-Routing 贡献,通过将 Q-Table 与 DNN(深 Q-Routing,DQR) 交换,但保留了算法的其余部分。与方法语义不同,作者通过指定多代理学习环境来区分他们的提案。因此,每个网络节点拥有自己的代理,每个代理都能根据个体路由策略进行本地决策。
Limitations of the proposed ML and DL schemes to revolutionize the domain of routing led Varela et al. to argue that simply applying state-of-the-art algorithms and techniques is not suf-ficient when it comes to networking challenges [153]. Instead, Varela et al. shift their focus on feature engineering and further outline that a complete yet simple state representation might be the key to overcome the hurdles [153]. Furthermore, Varela et al. propose a DRL scheme that integrates telemetry information alongside path level statistics to provide a more accurate repre-sentation for the purpose of learning [153]. Reportedly, their proposed scheme integrates better to various network configurations.
针对路由领域革命性的 ML 和 DL 方案的局限性,Varela 等人认为,简单地应用最先进的算法和技术并不足够解决网络挑战 [153]。相反,Varela 等人将注意力集中在特征工程上,并进一步指出,一个完整的但简单的状态表示可能是克服障碍的关键 [153]。此外,Varela 等人提出一种 DRL 方案,将传感器信息与路径级别统计信息相结合,以提供更准确的学习表示 [153]。据称,他们提出的方案更好地适应了各种网络配置。
Other recent works also base their ideas on feature engineering and argue that achieving gen-eralization is the key to success [99, 134], especially when dealing with network dynamics. Rusek et al. take a supervised learning approach with GNNs introducing RouteNet that aims at gen-eralizing over any given network topology by making meaningful predictions on performance metrics [134]. Using these predictions, it is able to select a suitable routing scheme that abides by the environment constraints. Meanwhile, DRL-R contributes a novel combinatorial model that integrates several networks metrics to address shortcomings of existing DRL schemes [99].
其他近期工作也基于特征工程,并认为实现泛化是成功的关键 [99, 134],特别是在处理网络动态性时。Rusek 等人使用 GNNs 进行受监督学习,介绍了 RouteNet,旨在通过对性能指标进行有意义的预测来泛化任何给定的网络拓扑 [134]。使用这些预测,它能够选择符合环境约束的适当的路由方案。同时,DRL-R 提出了一种新的组合模型,将多个网络指标集成起来,以解决现有 DRL 方案的缺点 [99]。
7.3 Discussion on ML-based Approaches
While a lot of effort has been made on the fundamental challenge of routing optimization, we are confident to say that the task is far from complete and continues to remain an active research do-main. Purely from an ML perspective, we can obtain several useful insights for aspiring scholars and researchers. For one, while routing optimization fits naturally to RL-based approaches, this does not strictly bind that achieving optimal results is a matter of learning paradigm. We saw sev-eral works attempting to leverage supervised learning techniques for that matter. On the other hand, taking into consideration that most DL approaches initiated with supervised learning and then shifted to RL, evidence might suggest otherwise. Besides, we observe the great potential of applying distributed, multi-agent, DRL-based approaches, as they can effectively mitigate the risk of state and action space explosion and improve the generalization properties of the learned algo-rithms. These traits make them a better fit to address the routing problems in large and dynamic environments such as carrier networks.
尽管在路由优化的基本挑战上已经投入了很多努力,但我们有信心说任务远远没有完成,并且仍然是一个活跃的研究领域。纯粹从机器学习的角度来看,我们可以为有志学者和研究人员提供一些有用的启示。首先,虽然路由优化与基于强化学习的方法天然匹配,但这并不严格意味着实现最佳结果是学习范式的问题。我们看到一些工作试图利用监督学习技术解决这个问题。另一方面,考虑到大多数深度学习方法都是从监督学习开始,然后转向强化学习的,证据可能表明并非如此。此外,我们发现应用分布式、多代理、基于深度学习的方法有很大的潜力,因为它们可以有效地缓解状态和行为空间爆炸的风险,并提高学习算法的泛化性能。这些特点使得它们更适合解决大型、动态的环境,例如运营商网络中的路由问题。
8 CONGESTION CONTROL
Congestion Control can be characterized as a remedy for crowded networks [66]. It concerns ac-tions that occur in event of network changes as a response to avoid collisions and thus network collapse. Network changes in this domain regularly refer to changes in the traffic pattern or config-uration, resulting in packet losses. A typical action to avoid collapse is for the sender to decrease its sending rate, e.g., through decreasing its congestion window. TCP, the de facto network transport protocol that the Internet relies on for decades, suffers from many limitations. With TCP being architecturally designed at 1980s, it is natural that the original specification contains network be-haviors observed at the time [178]. It is also the case that emerging ad-hoc and wireless networks are being hampered by the lack of flexibility inherited by TCP [9]. That being said, it has been shown that the congestion control scheme of TCP is often the root cause for degraded performance. Interesting literature has displayed the symptoms of current congestion control mechanisms, such as bufferbloat [48] and data-center incast [20].
拥塞控制可以被描述为针对拥挤的网络的一种治疗方法。它涉及在网络发生变化时采取的行动,以避免碰撞,从而避免网络崩溃。在网络这个领域中,网络变化通常指的是流量模式或配置的变化,从而导致数据包丢失。为了防止崩溃,发送者通常会通过减小拥塞窗口的大小来减小发送速率。TCP 是数十年来互联网依赖的实际网络传输协议,但它存在一些限制。由于 TCP 在 1980 年代进行架构设计,因此原设计包含当时观察到的网络行为 [178]。此外,新兴的自组织和无线网络受到 TCP 缺乏灵活性的妨碍 [9]。尽管如此,已经表明 TCP 的拥塞控制方案常常是性能下降的根本原因。有趣的文献展示了当前拥塞控制机制的症状,如缓冲区膨胀 [48] 和数据中心内嵌 [20]。
Congestion control has drawn a lot of research attention in the past decades and is still a very active domain. Various techniques have been proposed, mainly relying on human expert designed heuris-tics. In particular, IETF has proposed a series of guidelines to aid network designers in meditating TCP’s innate drawbacks [75]. These mechanisms usually apply end-to-end techniques, altering TCP by tuning the congestion window rolling as a mean to achieve better performance. This is done based on a number of factors and often simplifying or constraining assumptions about net-work conditions. Placing significant approaches in a chronological order we display quite a long list of literature: Vegas [16], NewReno [61], FAST TCP [157], CUBIC [56], and BBR [17]. Other more recent approaches with a focus on subsets of congestion control such as short-flows or data-centers are found in [92, 119, 180, 193]. Extension of congestion control to multipath scenarios, i.e., multipath TCP [46], have been explored in various studies, notably [77] and [127]. As it is not feasible to cite all the related work, we refer the readers to [88] for further discussion about congestion control of TCP and its many different variants.
在过去几十年中,拥塞控制吸引了很多研究注意力,仍然是一个非常活跃的领域。各种方法已被提出,主要依赖于人类专家设计的诀窍。特别是,IETF 已提出一系列指南,以帮助网络设计师考虑 TCP 的天然缺陷 [75]。这些机制通常采用端到端技术,通过调整拥塞窗口滚动来调节 TCP,以实现更好的性能。这种做法基于多种因素,并通常简化或约束网络条件。按时间顺序列出重要的方法,我们列出了相当长一串文献:Vegas [16],NewReno [61],FAST TCP [157],CUBIC [56],和 BBR [17]。其他更近期的方法,重点关注拥塞控制的某些子集,如短流或数据中心,可以在 [92, 119, 180, 193] 中找到。将拥塞控制扩展到多路径场景,即多路径 TCP [46],已在许多研究中进行探索,特别是 [77] 和 [127]。由于无法引用所有相关工作,我们向读者推荐 [88],以进一步讨论 TCP 及其多种变体的拥塞控制。
In the congestion control scenario, ML is capable of setting clear and direct optimization objectives to eliminate the rather unknown goals that the current setting holds. Additionally, with ML we can generate online learning control algorithms that are able to adjust to constantly changing network conditions. To incrementally progress towards our goal, existing domain knowledge can be incorporated to arrive at better learning solutions.
在拥塞控制场景中,机器学习具有设定明确和直接优化目标的能力,以消除当前设置中的较为未知的目标。此外,通过机器学习,我们可以生成在线学习控制算法,以适应不断改变的网络条件。为了逐步朝着我们的目标前进,可以利用现有的领域知识,以获得更好的学习解决方案。
To the best of our knowledge, Remy [179] is the first to utilize ML for learning a congestion control algorithm. Remy formulates an offline learning environment, in a decentralized manner, similar to what we have seen already in Section 7.2 as POMDPs. Agents sit on the endpoints and every time step takes a decision between send and abstain. Remy is trained under millions of sampled network configurations, through which it is able to come along with the optimal control strategy within a few hours of training. RemyCC, the output control algorithm, is employed on the current TCP stack and the evaluation suggest that it is able to outperform several state-of-the-art solutions. However, Remy does not manage to escape the pitfall of underlying assumptions. The training samples that Remy builds upon place constraints on RemyCC due to assumed network configurations under which they are sampled. This limits Remy’s state-action space, and can heavily affect performance when those conditions are not met.
据我们所知,Remy 是最早利用机器学习来学习拥塞控制算法的研究之一。Remy 采用分布式方式制定离线学习环境,类似于我们在第 7.2 节中所见到的 POMDP。代理坐在端点处,每个时间步态都在发送和等待之间做出决策。Remy 在数百万个采样的网络配置下进行训练,通过训练可以在短时间内提出最佳的控制策略。RemyCC 是输出控制算法,当前应用于 TCP 栈中,评估表明它可以优于几种先进的解决方案。然而,Remy 未能摆脱基础假设的缺陷。Remy 基于训练样本建立起来的训练数据对 RemyCC 施加了限制,因为这些样本是假定的网络配置下采样得到的。这限制了 Remy 的状态 - 行动空间,当这些条件不满足时,性能会受到严重影响。
In contrast to Remy, PCC Allegro [34] attempts to tackle inherit limitations of predefined assumptions on the network by conducting micro-experiments. In each experiment, an appro-priate control action is taken based on which the learner optimizes towards a “high throughput, low loss” objective named utility. Then, Allegro learns empirically to make better decisions by adjusting to control actions that yield higher utility. Following Remy’s example, each sender in Allegro makes decisions locally based on the outcome of the micro-experiments [34]. Allegro scheme does not make assumptions about network configurations. This translates to sharplygreater performance in real-network scenarios. Despite the effort, Allegro’s convergence speed and towards-TCP-aggressiveness frame it as prohibitive for deployment [35].
与 Remy 不同,PCC Allegro 通过进行微实验来尝试解决预先定义的网络限制。在每次实验中,学习者基于适当的控制行动进行优化,以达成“高吞吐量、低损失”的目标,该目标被称为效用。然后,Allegro 通过调整产生更高效用的控制行动来经验性地学习做出更好的决策。仿照 Remy 的例子,每个 Allegro 发送者在当地根据微实验结果做出决策。Allegro 方案不对网络配置做出假设,这意味着在真实网络场景中,Allegro 的性能显著更好。尽管如此,Allegro 的收敛速度和对 TCP 的激进性使其在部署方面颇具争议。
In an attempt to eliminate Allegro’s limitations, Dong et al. introduce Vivace [35]. Vivace re-places the two key components of Allegro: (1) the utility function and (2) the learning algorithm of rate-control. For the utility function, Vivace integrates RTT estimations via linear regression to penalize for high latency and loss [35]. Through latent-aware utility, Dong et al. show that Vivace can achieve fairness while mitigating bufferbloat and remaining TCP-friendly. For the rate-control algorithm, Vivace employs gradient-ascent-based no-regret online optimization [199]. The no-regret part translates to a minimum guarantee towards performance. Further, Vivace’s rate-control scheme enables faster convergence and subsequently faster reaction to network changes [35]. Pantheon was initiated as a playground with a focus on congestion control, where researchers can benchmark their proposals with other state-of-the-art literature and evaluate performance on shared metrics and measurements [186]. Pantheon leverages transparency by keeping a public record of results. Besides the shared platform for knowledge, the authors introduced Indigo—an offline neural network-based approach to congestion control. Indigo utilizes an LSTM RNN [60] and trains it with an imitation learning algorithm called DAgger [133]. Indigo employs generated data from optimal solutions that display correct mappings from state to action. Based on this training, Indigo is able to adjust its congestion window once an ACK is received [186]. Indigo exhibits relatively comparable performance to other schemes in Pantheon’s platform.
为消除 Allegro 的限制,Dong 等人提出了 Vivace。Vivace 替换了 Allegro 的两个关键组件:(1) 效用函数和 (2) 速率控制学习算法。对于效用函数,Vivace 使用线性回归将 RTT 估计集成起来以惩罚高延迟和丢失。通过潜在意识效用,Dong 等人表明,Vivace 可以实现公平,同时减轻缓冲区膨胀并保持 TCP 友好。对于速率控制学习算法,Vivace 采用梯度上升基于无后悔 online 优化算法。无后悔部分转换为性能的最低保证。此外,Vivace 的速率控制方案实现更快的收敛和随后更快的网络变化反应。Pantheon 是一个旨在关注拥塞控制的游乐场,研究人员可以与其他最先进的文献比较其提议,并共享指标和测量来评价性能。Pantheon 通过保持结果的公共记录来强调透明度。除了共享知识平台之外,作者还介绍了 Indigo,一种基于离线神经网络的拥塞控制方法。Indigo 使用 LSTM RNN,并使用称为 DAgger 的仿生学习算法对其进行训练。Indigo 使用从最优解生成的数据,以正确的状态 - 行动映射为目标进行训练。基于这一训练,Indigo 能够在收到 ACK 时调整其拥塞窗口。Indigo 在 Pantheon 平台上的其他方案中表现出相当相当的性能。
Aurora employs DRL to extend Allegro and Vivace [71]. Similarly to these solutions, it controls the sending rate per time-step, but the learning scheme incorporates into its observed history both latency gradient and ratio from [34, 35] respectively, as well as sending ratio which is specified as the ratio of packets sent to packets acknowledged by the receiver. The reward setting praises throughput and penalizes latency and packet loss, with packet loss referring to packets that have not been acknowledged. A RL agent is trained with a utilization of an algorithm first introduced in Section 6.2, namely PPO. With a relatively simple neural network configuration, Aurora is able to generalize well to a good mapping of sending rates outside of its environment scope. This es-tablishes Aurora as a robust solution which can be applied to dynamic networks which exhibit unpredictable traffic conditions. In contrary to its robustness, Aurora is comparably similar in terms of performance to other state-of-the-art schemes.
aurora 使用 DRL 来扩展 Allegro 和 Vicace [71]。与这些解决方案类似,它在每一时间步控制发送速率,但学习方案将其观察到的历史延迟梯度和比率,以及发送比率 (指定为发送的包与接收的包的比率) 包含在内。奖励设置赞扬吞吐量并惩罚延迟和包丢失,其中包丢失指未被确认的包。使用在第六章中首次介绍的算法 (PPO) 训练的 RL 代理。采用相对较简单的神经网络配置,aurora 能够在其环境范围之外良好地泛化,以实现发送速率的良好映射。这使得 aurora 成为一种适用于具有不可预测流量条件的动态网络的鲁棒解决方案。与它的鲁棒性相反,aurora 在性能方面与其他先进的方案相当。
Most recent studies tackle issues related to generalization and convergence speed. Specifically, a practical, hybrid approach is proposed in [1], which combines classic congestion control techniques with DRL techniques, improving the generalization toward unseen scenarios. The idea is to have two levels of controls: fine-grained control using classic TCP algorithms, e.g., BBR, to adjust the congestion window, and hence the sending rate, of a user, and coarse-grain control using DRL to calculate and enforce a new congestion window periodically, observing environment statistics. The proposed solution, therefore, has more predictable performance and better convergence properties, showing how learning from an expert, e.g., BBR algorithm, can improve the performance, in terms of convergence speed, adaptation to newly seen network conditions, and average throughput [41].
最近的研究表明,涉及泛化和收敛速度的问题得到了解决。具体来说,在 [1] 中提出了一种实用的混合方法,该方法将经典拥塞控制技术与 DRL 技术相结合,以提高对未知场景的泛化能力。该思想是两个级别的控制:使用经典的 TCP 算法,例如 BBR,进行细粒度控制,以调整用户的拥塞窗口,并因此调整发送速率;使用 DRL 进行粗粒度控制,以定期计算并强制新的拥塞窗口,并观察环境统计。因此,提出的解决方案具有更可预测的性能和良好的收敛特性,展示了如何从专家 (例如 BBR 算法) 学习如何提高收敛速度、适应新的网络条件以及平均吞吐量 [41]。
Applying DRL to multipath scenarios is also getting a boost. Notably, a centralized solution is proposed in [184], with a single agent trained to perform congestion control for all the MPTCP flows in the network. Such centralized solutions, however, are not scalable, as they require a global view of all available resources and active MPTCP flows in the network. A distributed solution is proposed in [95], where multiple MPTCP agents, each running at a sender node, are learning a set of congestion rules that enable them to take appropriate actions observing the environment. The learning is performed in an asynchronous manner, where each node requires only local environ-ment, state, and information. Further, as state is defined in a continues, high-dimensional space,
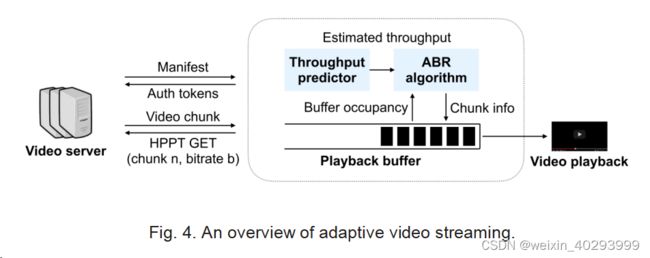
tile coding methods are applied to discretize the state dimension, addressing the scalability issue. The proposed solution, however, relies on offline learning and hence has limited generalization capabilities. In contrast, an online convex optimization is explored in [50], which extends PCC to multipath settings, showing through theoretical analysis and experimental evaluation that the proposed online-learning solution is scalable and that it can significantly outperform traditional solutions and better adjust to the changes in the network conditions. However, no comparison among these DRL methods is provided.
将 DRL 应用于多路径场景也得到了推动。值得注意的是,在 [184] 中提出了一种中央解决方案,其中单个代理被训练为在网络中的所有 MPTCP 流中进行拥塞控制。然而,这样的中央解决方案并不具有可扩展性,因为它们需要对整个网络可用资源和活跃 MPTCP 流的全球视图。在 [95] 中,提出了一种分布式解决方案,其中多个 MPTCP 代理,每个在发送节点上运行,学习一组拥塞规则,以便根据环境观察做出适当的行动。学习是异步进行的,每个节点只需要本地环境和状态信息。此外,由于状态定义在一个连续的、高维的空间中,因此可以更好地处理复杂的多路径场景。所提出的解决方案依赖于离线学习,因此具有限制性的泛化能力。相比之下,[50] 探索了在线凸优化,将该方法扩展到多路径设置中,通过理论和实验评估表明,提出的在线学习解决方案具有可扩展性,可以显著优于传统解决方案,并更好地适应网络条件的变化。然而,没有对这些 DRL 方法进行比较。
Finally, DeePCCI [135] proposes a novel classification scheme for identification of congestion control variants using DL. The authors solely-regard the packet arrival time of a flow as their input arguing on the fact that congestion control is strongly associated with packet timings. Addition-ally, fewer features directly translate to the ease of adaptation and applicability to other congestion control schemes. The classifier is trained and evaluated against CUBIC, RENO, and BBR with gen-erated labeled data as necessitated for supervised learning.
最后,DeePCCI [135] 提出了一种利用深度学习 (DL) 进行阻塞控制变体的新颖分类方案。作者仅将流量的包到达时间作为其输入,并指出阻塞控制与包时间有强烈的相关性。此外,较少的特征直接转化为对其他阻塞控制方案的易于适应和适用性。分类器使用生成标记数据进行训练和评估,以满足监督学习的要求。
8.3 Discussion on ML-based Approaches
As one of the oldest and most established areas in networking, congestion control has attracted rich research attention, in both traditional and ML-based domains, with many articles published re-cently to adopt DL techniques. These studies show the capability of DL techniques, and specifically DRL techniques, to overcome the limitations of traditional solutions. By learning adaptive mech-anisms, these ML-based solutions are able to adjust to constantly changing network conditions and hence better utilize the resources. The majority of these solutions, however, focus on central-ized or off-line learning, with only very few tackling online learning in a distributed setting—the case for TCP. More work should be done in this direction. Besides, most of these studies focus on proposing solutions that outperform current mechanisms, without really changing the objectives and the goals.
作为网络通信中最古老的和最稳定的领域之一,拥塞控制吸引了传统和机器学习领域的丰富研究注意力。许多最近发表的文章采用了深度学习技术。这些研究表明,深度学习技术特别是深度强化学习技术有能力克服传统解决方案的限制。通过学习自适应机制,这些机器学习解决方案能够适应不断改变的网络条件,从而更好地利用资源。然而,这些解决方案的大部分关注集中中央或离线学习,只有很少的研究在分布式设置中处理在线学习,例如 TCP。更多的工作应该在这个领域进行。此外,大多数这些研究都关注提出比当前机制表现更好的解决方案,而并没有真正改变目标和目标。
9 ADAPTIVE VIDEO STREAMING
As multimedia services such as video-on-demand and live streaming have witnessed tremendous growth in the past two decades, video delivery, nowadays, holds a dominant percentage of overall network traffic on the Internet [170]. Current video streaming services are mostly based on ABR, which splits a video into small chunks (a few seconds long) that are pre-encoded with various bitrates and streams each of the chunks with a suitable bitrate based on the real-time network condition. ABR is behind many mainstream HTTP-based video streaming protocols including Mi-crosoft Smooth Streaming (MSS), Apple’s HTTP Live Streaming (HLS), and more recently Dynamic Adaptive Streaming over HTTP (DASH) standardized by MPEG [143].
过去二十年来,随着视频点播和实时流媒体服务等多媒体服务的快速发展,视频传输在互联网中占据了主导地位。目前,大多数视频流媒体服务都基于 ABR,该协议将视频分成小块 (一般为几秒钟),并使用不同的比特率进行预编码,并根据实时网络条件选择合适的比特率传输每个小块。ABR 是许多主流的 HTTP based 视频流媒体协议的背后,如 Microsoft 的 Smooth Streaming(MSS)、苹果的 HTTP Live Streaming(HLS) 以及最近由 MPEG 标准化的 Dynamic Adaptive Streaming over HTTP(DASH)。
An overview of adaptive video streaming is depicted in Figure 4. The bitrate selection for each chunk is dictated by an ABR algorithm running on the client side, which takes real-time throughput estimations and/or local buffer occupancy as input and optimizes for the quality of experience defined as a combination of metrics including re-buffering ratio (the percentage of time the video playback is stalled because of drained buffer), average bitrate, bitrate variability (to improve playback smoothness), and sometimes also the startup delay (the time spent between user clicking and the playback starts). Considering that the network status suffers from high dynamics, designing a good ABR algorithm is non-trivial. This has been confirmed in an early measurement study which shows significant inefficiencies of commercial and open-source ABR algorithms [3]. As a result, many new ideas have been explored to improve adaptive video streaming. Here, we focus on the advancements on client-side ABR algorithms.
图 4 提供了自适应视频流媒体的概述。每个小块的比特率选择由运行在客户端上的 ABR 算法决定,该算法接受实时吞吐量估计或本地缓冲占用为输入,并优化用户体验的质量,定义为包括重缓冲比 (视频播放因耗尽缓冲而停滞的时间百分比)、平均比特率、比特率变化 (以提高播放流畅性) 和有时也包括启动延迟 (用户点击后播放开始所需的时间) 的复合指标。考虑到网络状态具有高度动态性,设计良好的 ABR 算法非易事。这已被早期测量研究证实,该研究显示商业和开源 ABR 算法具有显著不效率 [3]。因此,许多新思想已被探索以改善自适应视频流媒体。在这里,我们关注客户端侧 ABR 算法的进展。
9.1 Traditional Approaches and Limitations
Early ABR algorithms can be generally categorized into two families: rate-based and buffer-based (including the hybrid ones). Rate-based ABR algorithms typically rely on estimating network throughput based on past chunk downloads information [72, 96, 171, 200]. The ABR algorithm then selects the highest possible bitrate that can be supported by the predicted network through-put. To reduce prediction variability, ABR algorithms usually smooth out the predictions. For exam-ple, FESTIVE uses the experienced throughputs of the past 20 samples to predict the throughput for the next chunk and adopts the harmonic mean to reduce the bias of outliers [72]. Noticing that the measured TCP throughput may not reflect precisely the available real network through-put, PANDA proposes a “probe and adapt” method, similar to TCP’s congestion control, but at the chunk granularity to stress test the real network throughput [96]. SQUAD takes running esti-mates for the network throughput which acknowledges the impact of the underlying TCP control loop and takes into account the time scale to improve smoothness and reliability. It then uses a spectrum-based adaptation algorithm for the bitrate selection [171].
早期的 ABR 算法通常可分为两类:基于速率和基于缓冲的 (包括混合算法)。基于速率的 ABR 算法通常依赖于基于过去块下载信息的网络吞吐量估计 [72, 96, 171, 200]。然后,ABR 算法选择可以由预测网络吞吐量支持的最高比特率。为了降低预测不确定性,ABR 算法通常平滑预测。例如,FESTIVE 使用过去 20 个样本的体验到的网络吞吐量来预测下一个块的网络吞吐量,并采用调和平均值以减少异常值的影响 [72]。注意到测量的 TCP 吞吐量可能不准确地反映可用的真实网络吞吐量,PANDA 提出了一种“探测和适应”方法,类似于 TCP 的拥塞控制,但在块粒度上实施,以压力测试真实网络吞吐量 [96]。SQUAD 采用网络吞吐量的滚动估计,承认底层 TCP 控制环路的影响,并考虑时间尺度以改善平滑性和可靠性。然后,它使用一种频谱基于的适应算法来进行比特率选择 [171]。
Buffer-based ABR algorithms leverage the buffer occupancy as an implicit feedback signal for bitrate adaptation [62, 160], often also in combination with throughout prediction [189]. Huang et al. advocate for a pure-buffer-based design, which incorporates bandwidth estimation whenever needed (e.g., during the session startup). They model the dynamic relationship between the buffer accuracy and bitrate selection and propose a buffer-based ABR algorithm called BBA [62]. Similarly, BOLA is solely buffer-based, where the bitrate adaptation problem is formulated as a utility maximization problem and solved by an online control algorithm based on Lyapunov optimization techniques [145]. Model predictive control (MPC) is a hybrid approach that integrates both the throughput and the buffer occupancy signals [50]. More specifically, MPC models bitrate selection as a stochastic optimal control problem with a moving look-ahead hori-zon and leverages MPC to perform bitrate selection. To reduce the high computation, FastMPC proposes to use a table enumeration approach instead of solving a complex optimization problem as in MPC. ABMA+ pre-computes a buffer map which defines the capacity of the playout buffer required under a given segment download condition to meet a predefined rebuffering threshold and uses the map to make bitrate adaptation decisions [10].
缓冲基的 ABR 算法利用缓冲占用作为隐式反馈信号来进行比特率自适应,通常也与全程预测相结合 [189]。黄等人倡导纯缓冲基设计,即无论何时都需要结合带宽估计 (例如在会话启动时)。他们建模缓冲精度和比特率选择之间的动态关系,并提出了一种名为 BBA 的缓冲基 ABR 算法 [62]。类似地,BOLA 是完全基于缓冲的算法,它将比特率自适应问题表示为效用最大化问题,并使用基于 Lyapunov 优化技术的在线控制算法进行求解 [145]。模型预测控制是一种混合方法,它将 throughput 和缓冲占用信号融为一体 [50]。具体而言,MPC 将比特率选择建模为具有移动展望窗口的随机最优控制问题,并利用 MPC 进行比特率选择。为了减少高计算量,FastMPC 提出了使用表格枚举方法代替解决复杂优化问题的方法。ABMA+ 预先计算一个缓冲映射,该映射定义了在特定段下载条件下,满足预先定义的重缓冲阈值所需的播放缓冲容量,并使用该映射进行比特率自适应决策 [10]。
Limitations of traditional approaches: ABR algorithms typically rely on accurate band-width estimation which is hard to achieve with simple heuristics or statistical methods. Also, ARB algorithms make adaptation decisions based on the bandwidth estimation with a complex relationship between the two, rendering simple heuristic approaches general to all scenarios ineffective.
传统方法的限制:ABR 算法通常依赖于准确的带宽估计,这通常需要通过简单的启发式或统计方法实现。此外,ARB 算法基于带宽估计做出适应决策,且两者之间存在复杂的关系,因此简单的启发式方法对于所有场景都无效。
As discussed above, ABR algorithms typically involve bandwidth estimation, a complex control logic, or both, where we can leverage existing ML methods: the bandwidth estimation problem can be treated as a general regression problem, while the control problem can be treated as a decision-making problem. In fact, existing work on applying ML in adaptive video streaming can be generally divided into these two lines. We will discuss these two lines separately.
以上讨论的 ABR 算法通常涉及带宽估计和复杂的控制逻辑,或者两者都有。我们可以利用现有的机器学习方法来解决这些难题:带宽估计问题可以被视为一般性回归问题,而控制问题可以被视为决策问题。事实上,已经在自适应视频流媒体领域应用机器学习的工作可以分为两类。我们将分别讨论这两类工作
The first research line aims at achieving better accuracy in bandwidth estimation. Bandwidth estimation is a general and well-studied problem that has its presence in many of the Internet applications [68, 69]. Existing ML-based approaches for bandwidth estimation mainly focus on using methods like Kalman filter [40] or neural networks [43, 78] to perform the prediction. In the context of adaptive video streaming, CS2P aims at improving bitrate adaptation by adopting data-driven approaches in throughput prediction [154]. The authors make two important observa-tions: (1) There are similarities in the throughput pattern across video streaming sessions. (2) The throughput variability within a video streaming session exhibits stateful nature. Based on the first observation, the authors cluster similar sessions and use the clustering result to predict the initial throughput of a session. Using the second observation, they propose a Hidden-Markov-Model-based method to explore the stateful nature of throughput variability to predict the throughput. The second line of research focuses on leveraging ML, RL in particular, techniques for adapta-tion decision making. By penalizing on detrimental factors that negatively affect the optimization objectives, RL can learn from expererience an optimal strategy for bitrate selection, and replace existing heuristic-based schemes that suffer in generalizing to dynamic networks. RL can exploit the low level system signals that are essential for ABR algorithm design but are hard to be modeled and considered due to the inherent complexity. Besides, RL-based approaches are typically more flexible and can be generalized to different network conditions.
第一条研究路线旨在实现更好的带宽估计准确性。带宽估计是一个普遍且受研究关注的问题,它在许多互联网应用中都存在 [68, 69]。现有的基于机器学习的带宽估计方法主要采用如 kalman 滤波器 [40] 或神经网络 [43, 78] 等方法进行预测。在自适应视频流媒体的背景下,CS2P 方法旨在通过采用数据驱动的方法来改善比特率适应性,从而提高吞吐量预测的准确性 [154]。作者做出了两个重要观察:(1) 视频流媒体会话之间的吞吐量模式存在相似之处。(2) 视频流媒体会话内部的吞吐量变化表现出状态依赖性。基于第一个观察,作者对相似的会话进行聚类,并使用聚类结果来预测会话的初始吞吐量。基于第二个观察,他们提出了一种基于隐马尔可夫模型的方法,以探索吞吐量变化状态依赖性的预测方法。第二条研究路线聚焦于利用机器学习 (特别是强化学习) 技术来进行适应决策。通过惩罚影响优化目标的敌人因素,强化学习可以从经验中学习最优的比特率选择策略,并取代现有的基于启发式的方案,这些方案在应对动态网络时表现不佳。强化学习可以利用对于 ABR 算法设计至关重要的低级别系统信号,但这些信号由于固有的复杂性而难以建模和考虑。此外,基于强化学习的方法通常更加灵活,可以适用于不同的网络条件。
Claeys et al. try to replace used heuristics in the HTTP adaptive streaming client by an adaptive Q-learning-based algorithm [25]. Q-learning is a model-free RL algorithm that can make bitrate adaptation decisions by calculating the Q-value representing the quality (i.e., QoE) of decisions un-der varying network conditions. While showing promising results, this initial attempt is bounded by an explosive state-action space that burdens the convergence speed, resulting in slow responses to network variations. In a follow-up work [24], the authors apply several optimizations using a variant of Frequency Adjusted (FA) Q-learning. The new method alters Q-value calculation leading to quicker fitting in network fluctuations. In addition, the authors significantly reduce the environment state parameters and manage to achieve faster convergence.
claeys 等人尝试使用一种自适应的 Q-学习算法来替换 HTTP 自适应流媒体客户端中使用过的经验规则。Q-学习是一种无模型的强化学习算法,可以在不断变化的网络条件下,通过计算 Q 值来做出比特率适应决策。尽管该初始尝试表现出了积极的结果,但该方法受到了状态 - 行动空间爆炸的限制,这会减缓收敛速度,导致对网络变化的缓慢响应。在后续的研究中 [24],作者使用了频率调整 (FA)Q-学习的变体,并采用多种优化方法。新方法改变了 Q 值的计算方式,以更快地适应网络波动。此外,作者还大大减少了环境状态参数的数量,并实现了更快的收敛。
Several studies formulate the bitrate adaptation problem as a Markov Decision Process (MDP) with a long-term reward defined as a combination of video quality, quality fluctuations, and re-buffering events [21, 47, 107, 198]. As one example, mDASH proposes a greedy algorithm to solve the MDP, which results in suboptimal adaptation decisions but is efficient and lightweight [198]. Chiariotti et al. [21] propose a learning-based approach leveraging RL to solve the MDP. To boost learning speed, the proposed learning approach utilizes Post-Decision States (PDSs) [111]. In combination with what is known as off-policy learning and softmax policy, the proposed approach is able to converge fast enough to react to network changes.
几项研究将比特率适应问题表述为马尔可夫决策过程 (MDP),其中长期奖励被定义为视频质量、质量波动和重新缓冲事件的组合 [21, 47, 107, 198]。例如,mDASH 提出一种贪心算法来解决 MDP,这种方法会导致次优适应决策,但高效、轻量级 [198]。Chiariotti 等人 [21] 提出了一种基于学习的方法,利用强化学习来解决 MDP。为了提高学习速度,该学习方法利用了后决策状态 (PDSs) [111]。结合所谓的离线学习和 softmax 策略,该方法能够足够快速地收敛,以应对网络变化。
To combat the innate limitations of Q-learning, D-DASH leverage DL where instead of enumerat-ing all the Q-values a DNN is used to approximate the Q-values [47]. Tradingoff performance with converge speed, D-Dash employed four variations of DNN architectures, and tested under several environments. Comparable to the state-of-the-art and fairly fast, D-Dash definitely sets the pace for more DL approaches in upcoming research. Another DL-based approach is called Pensieve [107], which differentiates from the herd by utilizing a DNN that is trained with state-of-the-art A3C algorithm [120]. Pensieve is trained offline in a multi-agent setting that speeds up learning on a plethora of network traces. Besides evaluations in a simulated environment, Pensieve is also tested against real network conditions. Pensieve is able to outperform baseline ABR algorithms on shared QoE metrics. Moreover, Pensieve’s ability to incorporate throughput history is a key aspect. The above list of ABR algorithms is far from complete. For a comprehensive survey of existing ABR algorithms please refer to [11]. Apart from designing new ABR algorithms, researchers have also explored how to tune a given ABR algorithm under various network conditions. For example, Oboe is such a method that auto-tunes ABR algorithms according to the stationarity of the network throughput [4]. In [168] the authors propose to leverage RL to configure the parameters in existing ABR algorithms, achieving better bandwidth awareness.
为了解决 Q-学习的天然限制,D-DASH 利用深度学习 (DL),而不是枚举所有 Q-值,使用深度神经网络 (DNN) 来近似 Q-值 [47]。将性能与收敛速度平衡,D-DASH 使用了四种不同的 DNN 架构,并在多个环境中进行了测试。D-DASH 的性能与现有技术相当,且相当快速,它肯定会为未来的 DL 方法设定节奏。另一种基于深度学习的方法是 Pensieve [107],它通过使用训练有素的 A3C 算法 (最先进的深度学习算法之一) 的 DNN,与羊群不同地进行分类。Pensieve 在多代理设置中 Offline 训练,以加速在大量网络 traces 上的学习。除了模拟环境的评估外,Pensieve 还进行了与真实网络条件的对比测试。Pensieve 在共享 QoE 指标上优于基线 ABR 算法,此外,Pensieve 的能力纳入吞吐量历史是关键方面。上述列表中的 ABR 算法远非完整。如需全面了解现有的 ABR 算法,请参考 [11]。除了设计新的 ABR 算法外,研究人员还探索了如何在各种网络条件下调整给定的 ABR 算法。例如,Oboe 是一种自动调整 ABR 算法的方法,以适应网络吞吐量的静态性 [4]。在 [168] 中,作者提出了利用 RL 来配置现有 ABR 算法的参数,以实现更好的带宽意识。
9.3 Discussion on ML-based Approaches
Adaptive video streaming is a well-formulated problem that has attracted tremendous research efforts in the past decade. Both traditional approaches based on heuristics or control theory and ML-based approaches have been explored. It is evident that DRL-based approaches have a great potential for bitrate adaptation due to its innate advantage of capturing complex variability in net-work bandwidth [107]. Choosing the right data set and allowing for enough training seem critical to the performance of DRL-based approaches, and it is unclear if solutions like Pensieve can be gen-eralized to any network environments with varying conditions. Overall, DRL-based approaches are more capable of capturing the network dynamics and the complex relationship between bandwidth estimation and adaptation decisions than traditional heuristics-based approaches. Yet, DRL-based approaches require a lot of data and resources to train an accurate model, which can be an intim-idating factor for many video streaming service providers. In such cases, traditional approaches based on control theory might be a better option.
基于机器学习的方法在自适应视频流媒体方面具有很大的潜力。在过去的十年中,这种方法已经得到了广泛的研究。传统的方法基于启发式或控制理论,而机器学习的方法则被探索。显然,基于深度强化学习的方法在捕捉网络带宽的复杂性方面具有巨大的潜力,这是其天然的优势之一。选择正确的数据集并允许足够的训练对于基于深度强化学习的方法的性能至关重要,但不清楚类似 Pensieve 的解决方案是否可以应用于任何具有不同条件的网络环境。总的来说,基于深度强化学习的方法比传统的启发式方法更能够捕捉网络动态和带宽估计与适应决策之间的复杂关系。然而,基于深度强化学习的方法需要大量数据和资源来训练准确的模型,这对于许多视频流媒体服务提供商来说可能是一个威慑因素。在这种情况下,基于控制理论的传统方法可能是最好的选择。
10 DISCUSSION AND FUTURE DIRECTIONS
Despite all the praise and recent remarkable publications that regard the application of ML in computer systems, ML is not panacea and should not be treated as such. There are still challenges that lie ahead before deploying learned systems in real-world scenarios. So far, we have witnessed mostly the beneficial progress of reviewed applications and albeit this is sufficient to intrigue re-searchers to investigate more, we also ought to raise awareness when it comes to integration of ML techniques in complex systems. That being said, in this section, we aim at outlining and dis-cussing current known limitations in the literature we have reviewed, whilst, offering approaches that might assist in future research.
尽管人们对机器学习在计算机系统中的应用给予了高度评价,但机器学习并不是万能的,不应该被视为替代品。在部署机器学习系统之前,仍然存在许多挑战。到目前为止,我们只看到了评估应用有益的进展,尽管这足以引起研究人员进一步研究的兴趣,但我们也必须在复杂系统的集成中提高意识。因此,在本节中,我们将概述并讨论我们已经审查的文献中已知的当前限制,同时提供可能有助于未来的研究方法。
Explainability. Some recent studies [32, 197] try to shed light on the limitations of ML systems. Interestingly, both address ML-based solutions as “black-box approaches” and focus on the lack of interpretability of ML models. Especially in DNNs with multiple hidden layers, we cannot sufficiently capture, or better yet rationalize, the logic behind the decision-making process of these complex models and architectures. As further discussed in [197], this leads to several ambiguities and trust issues, especially when it comes to the process of debugging such complex structures. On the other hand, simpler and intuitive models are burdened with deteriorated performance and poor generalization [32]. Moreover, DNNs are subjective to unreliable predictions when input does not match the expectations assumed on training [197]. Specific research questions to explore include: (1) How to come up with clear guidelines (e.g., for determining DNN architectures and hyper-parameters) on the design of ML-based solutions? (2) How to open up the black box of DNNs and incorporate domain expertise in the decision-making process?
可解释性。一些最近的研究 [32,197] 试图揭示机器学习系统的局限性。有趣的是,它们都将基于机器学习的解决方案称为“黑盒方法”,并关注机器学习模型的可解释性不足。特别是在具有多个隐藏层的深度神经网络中,我们不能完全捕获或更好地解释这些复杂模型和架构的决策过程背后的逻辑。进一步讨论 [197] 表明,这导致了许多模糊和信任问题,特别是在处理这些复杂结构的调试过程中。另一方面,更简单和直观的模型的性能恶化,泛化能力差 [32]。此外,当输入与训练时期望的输入不匹配时,深度神经网络容易出现不可信预测。探索的具体研究问题包括:(1) 如何制定明确的指南 (例如,确定深度神经网络结构和超参数) 来设计基于机器学习的解决方案?(2) 如何打开深度神经网络的黑盒,并将领域专业知识融入决策过程中?
Training overhead. Besides explainability, training times and the associated costs are another significant drawback. For instance, as we have seen in [188], where each video is trained separately for efficient delivery, it requires approximately ten minutes of training per minute of video or in cost-wise, 0.23 dollar. Putting it into perspective, consider the well-known YouTube platform. YouTube, the de facto platform for video streaming is estimated to have around 500 hours of videos uploaded every minute [150]. In combination with training time, it would be impossible to handle the training for all videos with such tremendous growth. In terms of cost efficiency, consider that only a relatively small amount of videos from the total uploads will convert into revenue, hence, we can deduct that supporting such a large-scale content-aware delivery system is practically impossible. The following research questions would be interesting to explore: (1) Can we train the DNNs with just a small amount of data? (2) How to apply transfer learning to reuse DNNs in scenarios that are similar in structure but different in detail?
训练开销。除了解释性之外,训练时间和与之相关的成本也是另一个显著缺点。例如,正如我们在 [188] 中看到的,为了高效传输每个视频都需要单独训练,每分钟视频大约需要十分钟的训练,或者成本为 0.23 美元。将其置于背景下,考虑著名的 YouTube 平台。YouTube 是视频流媒体的事实上的平台,据估计每分钟大约有 500 小时的视频上传 [150]。结合训练时间,处理所有视频的训练是不可能的。在成本效率方面,考虑仅相当小的一部分上传视频会转化为收入,因此,我们可以推断支持这样的大规模内容感知传输系统是实际上不可能的。以下有趣的研究问题值得探索:(1) 我们能够使用少量数据训练深度神经网络吗?(2) 如何应用迁移学习来重用在结构相似但细节不同的场景中训练的深度神经网络?
Lack of training data. Related to training times, lies also the concern of training data. Due to the fact that sufficient and effective training necessitates large volumes of data, many of the exist-ing studies rely on generated samples or existing datasets to train their models. For instance, both Wrangler [185] and CODA [196] train on datasets composed of traces that stem from production-level clusters. On the other hand, MSCN [79] generates training data from sampled queries that are based on “schema and data information”. This results into two major concerns. First, it has to be ensured that training samples are sufficient and cover the whole problem space [76]. Oth-erwise, we might be looking into a solution that does not generalize well in real-world scenarios. Second, as mentioned in [197], there are adversarial inputs that can be the root cause of degraded performance. The following research questions need to be answered: (1) Can we build a common training ground for DNN training without leaking sensitive data to the public? (2) How to achieve scalable incremental training so the system can learn on the fly over time?
缺乏训练数据。与训练时间相关的问题也包括训练数据的问题。由于充分的和有效的训练需要大量数据,许多现有的研究依赖于生成样本或现有的数据集来训练模型。例如,Wrangler [185] 和 CODA [196] 都在生产级别的集群 traces 组成的数据集上训练模型。另一方面,MSCN [79] 从基于“schema 和数据信息”采样的查询中生成训练数据。这导致了两个主要问题。首先,必须确保训练样本足够充足并覆盖整个问题空间 [76]。否则,我们可能会在现实世界场景中不泛化良好的解决方案上浪费时间。其次,正如 [197] 所述,存在可以导致性能下降的恶意输入。以下研究问题需要回答:(1) 我们能够建立一个 DNN 训练的共同训练场地,而不向公众泄露敏感数据吗?(2) 如何实现可扩展的增加训练,以便系统可以随着时间的推移进行在线学习?
Energy efficiency. Training a large DNN could also has substantial environmental impacts. A recent study [152] shows that the carbon emission of training a BERT model on current GPUs is roughly equivalent to a trans-American flight. To reduce the carbon emission of such training, one can improve the hardware design or the algorithm, to reduce the complexity or training time. Harvesting green energy resources, such as solar cells or wind turbines, for training is another way to make such training greener and hence more sustainable. But this requires advances in distributed learning technologies, where the training of a large DNN can be distributed all over the network, and closer to the edges where green energy resources are available. Despite some advances in the field of distributed learning, e.g., by proposing FL [113], the green learning aspect of it has not yet been covered. We identify the following specific research questions: (1) How to design more energy-efficient ML methods (for both training and inference)? (2) How to use distributed learning techniques to avoid bulky energy consumption in central places?
能源效率。训练大型 DNN 也可能对环境产生重大影响。最近的一项研究表明 [152],使用当前 GPU 的 BERT 模型训练产生的碳排放大致相当于一次跨美国飞行。为了降低此类训练的碳排放,可以改进硬件设计和算法,以减少训练的复杂性或时间。训练绿色能源资源,如太阳能电池或风力涡轮机,也是一种使此类训练更加可持续的方法。但这需要分布式学习技术的进步,以便将大型 DNN 的训练分布在网络的各个角落,并更接近可用绿色能源资源的边缘。尽管在分布式学习领域已经取得了一些进展,例如提出了 FL [113],但其绿色的方面仍未得到覆盖。我们确定了以下具体的研究问题:(1) 如何设计更加能源高效的机器学习方法 (包括训练和推理)?(2) 如何使用分布式学习技术以避免中心地方庞大能源消耗?
Real-time performance. A final implication of ML approaches is that of inference time. Real-time applications require fast inference of ML models, as in the case of autonomous driving, where hardware accelerators are employed so the system can make safety-critical decisions locally [98]. This hurdle composes also the main idea and contribution of [176], where supervised learning is applied to enhance vision analytics tasks on cloud operations. Expanding to other domains where speed is crucial, e.g., routing and congestion control, we can understand how slow inference of models, especially in DNNs, can reduce the performance gains significantly. This can add up to an overall comparable performance with traditional solutions, in which an operator will prefer the tra-ditional solution for simplicity and better understanding [197]. Specific research questions include: (1) How to make ML-based methods lightweight when applied in the critical path of computer sys-tems and networks? (2) Can we use a lightweight method on the critical path while leveraging ML-based methods on the non-critical path?
实时性能。机器学习方法的最终影响是推理时间。实时应用程序需要快速推理的机器学习模型,例如自动驾驶系统,其中使用硬件加速器以确保系统能够在当地做出安全关键决策 [98]。这也成为了 [176] 的主要思想和贡献,其中监督学习被应用于增强云计算中的视觉分析任务。扩展到其他关键领域,例如路由和拥塞控制,我们可以理解模型缓慢的推理,特别是在 DNN 中,可以显著降低性能收益。这可以导致与传统解决方案相当的 overall 性能,其中操作员更倾向于传统解决方案,因其简单性和更好地理解 [197]。具体研究问题包括:(1) 如何应用于计算机系统和网络的关键路径上时,使基于机器学习的方法轻量化?(2) 能够在关键路径上使用轻量化方法,同时利用基于机器学习的方法的非关键路径吗?
Taking all aforementioned limitations into account, it is safe to suggest that ML for computer systems and networking is still at an infant stage. Even though we have witnessed remarkable progress, we need to tread lightly when it comes to deploying systems that heavily depend their operation on ML approaches, due to the fact that we might end up with a sub-optimal solution, compared to the one we are seeking to alleviate. While it is unclear how to integrate existing domain knowledge [32], it is argued that this is the key to overcome current drawbacks [197]. Do-ing so, the authors suggest that commons limitations, and in particular transferability, robustness and training overhead will be essentially mitigated. Furthermore, a recent work from Kazak et al. proposes a novel system to verify DRL systems [76]. Verily, the aforementioned system is a first step towards formal verification of DRL models. The author’s contribution aims at verifying that learned systems deliver what they advocate for. Verily has been evaluated already on Pensive [107], DeepRM [106], and Aurora [71], and constitutes a first step towards alleviating current limitations.
考虑到上述限制,可以安全地认为计算机系统和网络中的机器学习仍处于婴儿期。尽管我们取得了显著进展,但在部署严重依赖机器学习方法进行操作的系统时,我们需要小心谨慎,因为与我们寻求缓解的问题相比,我们可能会得出优化不足的解决方案。虽然不清楚如何整合现有领域知识 [32],但有人认为这是克服当前缺点的关键 [197]。这样做时,作者建议常见的限制,特别是可移植性、鲁棒性和训练开销,将得到本质上的缓解。此外,Kazak 等人最近的工作提出了一种用于验证深度强化学习的新方法 [76]。显然,上述系统是深度强化学习模型的正式验证的第一步。作者的贡献旨在验证学习系统是否实现了它们倡导的东西。Verily 已经在 Pensive、DeepRM 和 Aurora 等平台上进行了评估,并构成了缓解当前限制的第一步。
11 SUMMARY
In this survey, we summarize research work regarding ML on computer systems and networking. Whether it concerns achievements or comes with limitations, we attempt to present an overall picture that exhibits current progress and exploits how ML can blend in various contexts and set-tings, and above all, motivate researchers to conceptualize and utilize ML in their field of research. We first formulate a taxonomy divided into distinct areas and sub-areas of expertise, in a quest to familiarize the reader with the greater picture. Eventually, we discuss each sub-domain separately. Per se, we formulate a short description of the problem and present the traditional approaches up to date and discuss the limitations of the traditional approaches. Then, we proceed to present the state-of-the-art of ML-based approaches and analyze significance of their results, limitations, and how far we are from an actual implementation in systems. We conclude the survey by discussing future directions to explore.
在本次调查中,我们总结了计算机系统和网络中的机器学习研究工作。无论是关于成就还是涉及限制,我们都试图呈现一幅展示当前进展以及如何在各种上下文和环境中融合机器学习的整体画面,最重要的是,激励研究人员在他们的研究领域中概念化和利用机器学习。我们首先制定一种分类法,将其分为不同的专业领域和子领域,以帮助读者了解更大的画面。最终,我们分别讨论每个子领域。本身,我们提出一个问题,并介绍传统方法的最新版本,并讨论传统方法的限制。然后,我们介绍基于机器学习的方法的当前状态,并分析它们的结果、限制以及我们离在系统中实现它们还有多远。最后,我们讨论未来探索的方向。