【多模态】21、BARON | 通过引入大量 regions 来提升模型开放词汇目标检测能力

文章目录
-
- 一、背景
- 二、方法
-
- 2.1 主要过程
- 2.2 Forming Bag of Regions
- 2.3 Representing Bag of Regions
- 2.4 Aligning bag of regions
- 三、效果
论文:Aligning Bag of Regions for Open-Vocabulary Object Detection
代码:https://github.com/wusize/ovdet
出处:CVPR2023
一、背景
传统目标检测器只能识别特定的类别,开放词汇目标检测由于不受预训练类别的限制,能够检测任意类别的目标,而受到了很多关注
针对 OVD 问题的一个典型解决方案就是基于蒸馏的方法,也就是从预训练的 vision-language 模型中蒸馏出丰富的特征来识别丰富的类别
VLM 是通过大量的 image-text pairs 来学习将两者对齐,如图 1a 所示
之前也有很多蒸馏的方法通过将每个 region embedding 和对应的从 VLM 中输出的特征进行对齐
本文作者提出【align the embedding of BAg of RegiONs】,来让模型不仅仅理解单个的目标,而是理解场景
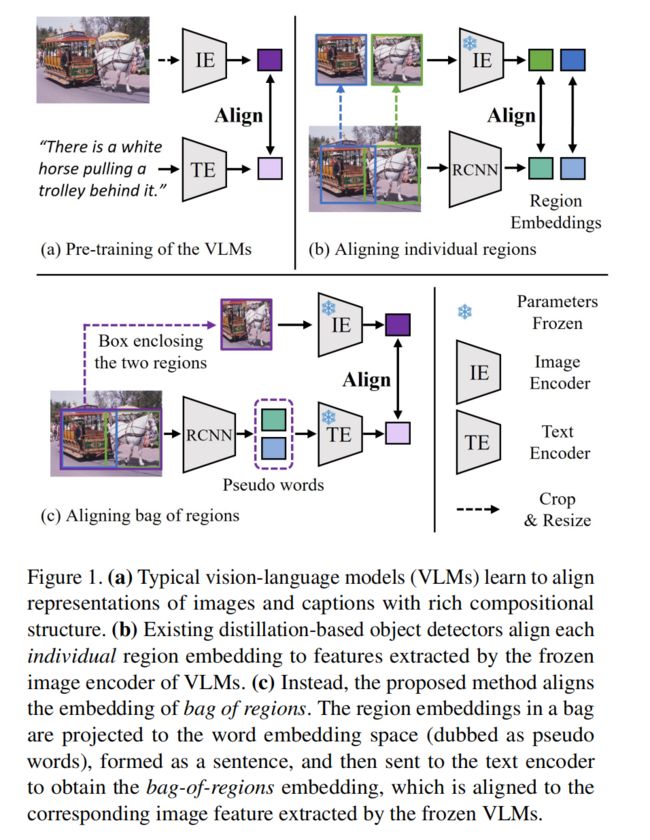
BARON 结构如图 1c 所示:
- 首先,从 bag 中抽取出和上下文相关的 region,由于 RPN 是需要能够提取出潜在的新类的,所以作者提出了 “neighborhood sampling strategy” 来抽取 region proposal 周围的框来帮助建模出共现的语义 concept
- 接着,BARON 通过将 region feature 投影到 word embedding space 得到 pseudo words,并且使用预训练好的 text encoder 来对这些 pseudo words 进行编码,得到一系列的 region embedding
- 投影到 word 空间的 pseudo words,就能够让 Text encoder 很好的抽取出共现的语义概念,并且理解整个场景
- 在送入 Text encoder 之前,为了保留 region box 的空间信息,会将 box shape 和 box center position 也投影到 embedding 中,驾到 pseudo word 上,然后再将 pseudo word 送入 Text encoder
- 训练 BARON 时,目标是将 bag-of-regions 的 embedding 和从教师 image encoder (IE)那里获得的 image crop 的 embedding 对齐,作者使用对比学习机制来学习 pseudo words 和 bag-of-regions embeddings,对比学习 loss 能够拉近成对儿的 pairs 的 student(detector)和 teacher(IE)embedding ,推远不成对儿的 pairs
二、方法
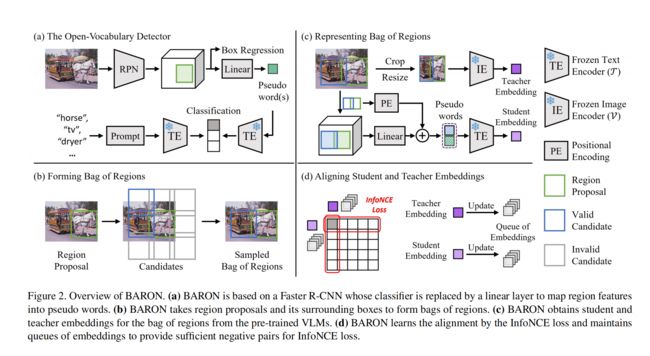
本文方法首次提出了对齐 bag of regions 的 embedding,之前的方法都是对齐单个 region 的 embedding
2.1 主要过程
本文方法主要基于 Faster R-CNN,为了让 Faster RNN 能够检测出任意词汇概念的目标,作者使用了一个线下映射层将原本的分类器代替了
线性映射层能够将 region features 映射到 word embedding space(即 pseudo words,如图 2a),这些 pseudo words 包含了每个目标更丰富的语义信息,类似于每个类别的名字包含了更多的单词(如 horse-driven trolley)
之后,将这些 pseudo words 输入 text encoder,计算和每个类别编码的相似性,然后得到类别结果
如图 2a 所示,给定 C 个目标类别,通过将类别名称转变为 prompt 模版 ‘a photo of {} in the scene’,并输入到 text encoder T 中来获得 embedding f c f_c fc
假设有 region 和其对应的 pseudo words w w w,该 region 是类别 c 的概率如下, < , > <,> <,> 表示 cosine 相似度, τ \tau τ 是温度系数
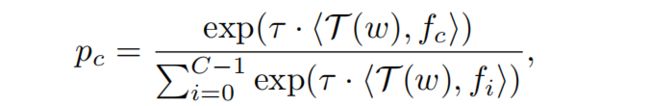
训练期间,只标注了基础类别,且也是使用基础类别来训练 Faster R-CNN 的回归和分类 loss 的
为了学习检测新类别(且没有 box 标注信息),之前的蒸馏方法都是只对齐单个的 region embedding 和其对应的从 VLMs 得到的特征
本文的方法为了捕捉更多的信息,将单个的 region 扩展到了 bag of regions
2.2 Forming Bag of Regions
本文中,也和其他方法一样使用 VLM 中的 image encoder 作者 teacher,来指导检测器的学习
不同的是,作者希望检测器能学习多个 concepts 的共现管辖,尤其是新目标的潜在出现的概率
为了效果和效率共存,作者将有如下两个属性的 regions 归到一个 bag 中去:
- 不同的 region 需要彼此距离接近
- 不同的 region 大小要相同
基于上面两个条件,作者使用 simple neighborhood sampling strategy,基于 RPN 预测得到的 region proposal,来构建 bag of regions
对每个 region proposal,作者都选取了其周围的 8 个相邻的 box 来作为候选,如图 2b 所示,此外,作者也会允许这些候选框之间有重叠,即 specific Intersection over Foreground (IOF) 来提高区域表达的连续性
为了平衡 bag 中 region 的 size,作者让着 8 个候选框的形状完全相同,且和该 region proposal 的大小也相同
2.3 Representing Bag of Regions
收集到 bag of regions 后, BARON 会从 student 和 teacher 中分别得到 bag-of-regions embeddings
假设第 i 个 groups 的第 j 个 region 为 b j i b_j^i bji,且 pseudo words 为 w j i w_j^i wji,用 T 表示预训练 VLM 的 文本编码器,V 表示图像编码器
1、student bag-of-regions embedding
由于region features 被投影到 word embedding space 且要和 text embedding 对齐,一个很直接的方法就是将这一系列的 pseudo words 进行 concat,然后输入 text encoder T 中,但是这样的话 region 的空间信息就会丢失,所以,作者将 bag 中的 regions 的中心位置、形状 都被编码了
位置编码会被夹到 pseudo word 上,然后再 concat
最终表达如下:
![]()
2、Teacher bag-of-regions embedding
使用 image encoder V 可以得到教师网络的编码,image feature 如下:
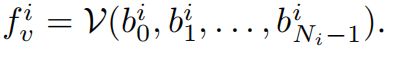
2.4 Aligning bag of regions
BARON 会将 teacher 的预测和 student 的学习结果进行对齐
给定 G 个 bag-of-regions,alignment InfoNCE loss 如下:

对齐单个 region:
单个 region 的 student 和 teacher embedding 的对齐对整个 bag-of-regions 的对齐很重要
所以,作者使用 individual-level distillation:
- teacher embedding:从 image encoder 的最后一个 attention 层使用 RoIAlign 获得
- 从 text encoder 的最后一个 attention layer 获得,对同一个 region 的所有 pseudo-word embedding 进行平均
- loss:使用 InfoNCE loss
三、效果




