【深度学习】MAT: Mask-Aware Transformer for Large Hole Image Inpainting
论文:https://arxiv.org/abs/2203.15270
代码:https://github.com/fenglinglwb/MAT
文章目录
- PS
- Abstract
- Introduction
- Related Work
- Method
-
- 总体架构
- 卷积头
- Transformer主体
-
- Adjusted Transformer Block
- Multi-Head Contextual Attention
- Style Manipulation Module
-
- Loss Functions
- Experiments
-
- Datasets and Metrics
- Implementation Details
- Ablation Study
- Comparison with State of the Arts
- MAT: Mask-Aware Transformer for Large Hole Image Inpainting (Supplementary Material)
-
- Pluralistic Generation
- Limitations and Failure Cases
- Conclusion
- 补充材料
-
- Network Architecture
- Free-Form Mask Sampling and Statistics
- Tokenization
- 模型配置
- CelebA-HQ 256×256结果
- LPIPS结果
- 高分辨率的泛化能力
- 多样性-保真度权衡
- 其他定性结果
PS
Generator 参数统计:
Generator Parameters Buffers Output shape Datatype
--- --- --- --- ---
mapping.fc0 262656 - [1, 512] float32
mapping.fc1 262656 - [1, 512] float32
mapping - 512 [1, 12, 512] float32 随机噪声mapnet
synthesis.first_stage.conv_first:0 6660 16 [1, 180, 512, 512] float32
synthesis.first_stage.conv_first:1 - - [1, 180, 512, 512] float32 ConV特征提取
synthesis.first_stage.enc_conv.0:0 291780 16 [1, 180, 256, 256] float32
synthesis.first_stage.enc_conv.0:1 - - [1, 180, 256, 256] float32
synthesis.first_stage.enc_conv.1:0 291780 16 [1, 180, 128, 128] float32
synthesis.first_stage.enc_conv.1:1 - - [1, 180, 128, 128] float32
synthesis.first_stage.enc_conv.2:0 291780 16 [1, 180, 64, 64] float32
synthesis.first_stage.enc_conv.2:1 - - [1, 180, 64, 64] float32 encoder token化
synthesis.first_stage.tran.0:0 942660 262160 [1, 4096, 180] float32
synthesis.first_stage.tran.0:1 - - [1, 4096, 180] float32
synthesis.first_stage.tran.1:0 1559880 262176 [1, 1024, 180] float32
synthesis.first_stage.tran.1:1 - - [1, 1024, 180] float32
synthesis.first_stage.tran.2 1885320 32 [1, 256, 180] float32 Swin Transformer
synthesis.first_stage.ws_style 92340 - [1, 180] float32
synthesis.first_stage.to_square 46336 - [1, 256] float32
synthesis.first_stage.down_conv 1167120 64 [1, 180, 1, 1] float32
synthesis.first_stage.to_style 65160 - [1, 360] float32 SMM模块
synthesis.first_stage.tran.3 1559880 262176 [1, 1024, 180] float32
synthesis.first_stage.tran.4 1234440 262176 [1, 4096, 180] float32 Swin Transformer
synthesis.first_stage.dec_conv.0:0 876243 64 [1, 180, 128, 128] float32
synthesis.first_stage.dec_conv.0:1 - - [1, 180, 128, 128] float32
synthesis.first_stage.dec_conv.1:0 876243 64 [1, 180, 256, 256] float32
synthesis.first_stage.dec_conv.1:1 - - [1, 180, 256, 256] float32
synthesis.first_stage.dec_conv.2:0 876243 64 [1, 180, 512, 512] float32
synthesis.first_stage.dec_conv.2:1 - - [1, 180, 512, 512] float32 decoder
synthesis.first_stage - - [1, 3, 512, 512] float32 粗略图
synthesis.enc.EncConv_Block_512x512 37440 32 [1, 64, 512, 512] float32
synthesis.enc.EncConv_Block_256x256 221440 32 [1, 128, 256, 256] float32
synthesis.enc.EncConv_Block_128x128 885248 32 [1, 256, 128, 128] float32
synthesis.enc.EncConv_Block_64x64 3539968 32 [1, 512, 64, 64] float32
synthesis.enc.EncConv_Block_32x32 4719616 32 [1, 512, 32, 32] float32
synthesis.enc.EncConv_Block_16x16 4719616 32 [1, 512, 16, 16] float32 U-Net encoder
synthesis.to_square 131328 - [1, 256] float32
synthesis.to_style.conv 7079424 48 [1, 512, 2, 2] float32
synthesis.to_style.pool - - [1, 512, 1, 1] float32
synthesis.to_style.fc 525312 - [1, 1024] float32
synthesis.dec.Dec_16x16:0 6295044 320 [1, 512, 16, 16] float32
synthesis.dec.Dec_16x16:1 - - [1, 512, 16, 16] float32
synthesis.dec.Dec_32x32:0 7081989 2112 [1, 512, 32, 32] float32
synthesis.dec.Dec_32x32:1 - - [1, 512, 32, 32] float32
synthesis.dec.Dec_64x64:0 7081989 8256 [1, 512, 64, 64] float32
synthesis.dec.Dec_64x64:1 - - [1, 512, 64, 64] float32
synthesis.dec.Dec_128x128:0 3344645 32832 [1, 256, 128, 128] float32
synthesis.dec.Dec_128x128:1 - - [1, 256, 128, 128] float32
synthesis.dec.Dec_256x256:0 1229957 131136 [1, 128, 256, 256] float32
synthesis.dec.Dec_256x256:1 - - [1, 128, 256, 256] float32
synthesis.dec.Dec_512x512:0 504389 524352 [1, 64, 512, 512] float32
synthesis.dec.Dec_512x512:1 - - [1, 64, 512, 512] float32 U-Net decoder
synthesis - - [1, 3, 512, 512] float32 精细图
--- --- --- --- ---
Total 59986582 1748800 - -
Discriminator参数统计,用了VGG16.
Discriminator Parameters Buffers Output shape Datatype
--- --- --- --- ---
Dis.0.conv 320 16 [1, 64, 512, 512] float32
Dis.1.skip 8192 16 [1, 128, 256, 256] float32
Dis.1.conv0 36928 16 [1, 64, 512, 512] float32
Dis.1.conv1 73856 16 [1, 128, 256, 256] float32
Dis.1 - - [1, 128, 256, 256] float32
Dis.2.skip 32768 16 [1, 256, 128, 128] float32
Dis.2.conv0 147584 16 [1, 128, 256, 256] float32
Dis.2.conv1 295168 16 [1, 256, 128, 128] float32
Dis.2 - - [1, 256, 128, 128] float32
Dis.3.skip 131072 16 [1, 512, 64, 64] float32
Dis.3.conv0 590080 16 [1, 256, 128, 128] float32
Dis.3.conv1 1180160 16 [1, 512, 64, 64] float32
Dis.3 - - [1, 512, 64, 64] float32
Dis.4.skip 262144 16 [1, 512, 32, 32] float32
Dis.4.conv0 2359808 16 [1, 512, 64, 64] float32
Dis.4.conv1 2359808 16 [1, 512, 32, 32] float32
Dis.4 - - [1, 512, 32, 32] float32
Dis.5.skip 262144 16 [1, 512, 16, 16] float32
Dis.5.conv0 2359808 16 [1, 512, 32, 32] float32
Dis.5.conv1 2359808 16 [1, 512, 16, 16] float32
Dis.5 - - [1, 512, 16, 16] float32
Dis.6.skip 262144 16 [1, 512, 8, 8] float32
Dis.6.conv0 2359808 16 [1, 512, 16, 16] float32
Dis.6.conv1 2359808 16 [1, 512, 8, 8] float32
Dis.6 - - [1, 512, 8, 8] float32
Dis.7.skip 262144 16 [1, 512, 4, 4] float32
Dis.7.conv0 2359808 16 [1, 512, 8, 8] float32
Dis.7.conv1 2359808 16 [1, 512, 4, 4] float32
Dis.7 - - [1, 512, 4, 4] float32
Dis.8 - - [1, 513, 4, 4] float32
Dis.9 2364416 16 [1, 512, 4, 4] float32
fc0 4194816 - [1, 512] float32
fc1 513 - [1, 1] float32
Dis_stg1.0.conv 160 16 [1, 32, 512, 512] float32
Dis_stg1.1.skip 2048 16 [1, 64, 256, 256] float32
Dis_stg1.1.conv0 9248 16 [1, 32, 512, 512] float32
Dis_stg1.1.conv1 18496 16 [1, 64, 256, 256] float32
Dis_stg1.1 - - [1, 64, 256, 256] float32
Dis_stg1.2.skip 8192 16 [1, 128, 128, 128] float32
Dis_stg1.2.conv0 36928 16 [1, 64, 256, 256] float32
Dis_stg1.2.conv1 73856 16 [1, 128, 128, 128] float32
Dis_stg1.2 - - [1, 128, 128, 128] float32
Dis_stg1.3.skip 32768 16 [1, 256, 64, 64] float32
Dis_stg1.3.conv0 147584 16 [1, 128, 128, 128] float32
Dis_stg1.3.conv1 295168 16 [1, 256, 64, 64] float32
Dis_stg1.3 - - [1, 256, 64, 64] float32
Dis_stg1.4.skip 65536 16 [1, 256, 32, 32] float32
Dis_stg1.4.conv0 590080 16 [1, 256, 64, 64] float32
Dis_stg1.4.conv1 590080 16 [1, 256, 32, 32] float32
Dis_stg1.4 - - [1, 256, 32, 32] float32
Dis_stg1.5.skip 65536 16 [1, 256, 16, 16] float32
Dis_stg1.5.conv0 590080 16 [1, 256, 32, 32] float32
Dis_stg1.5.conv1 590080 16 [1, 256, 16, 16] float32
Dis_stg1.5 - - [1, 256, 16, 16] float32
Dis_stg1.6.skip 65536 16 [1, 256, 8, 8] float32
Dis_stg1.6.conv0 590080 16 [1, 256, 16, 16] float32
Dis_stg1.6.conv1 590080 16 [1, 256, 8, 8] float32
Dis_stg1.6 - - [1, 256, 8, 8] float32
Dis_stg1.7.skip 65536 16 [1, 256, 4, 4] float32
Dis_stg1.7.conv0 590080 16 [1, 256, 8, 8] float32
Dis_stg1.7.conv1 590080 16 [1, 256, 4, 4] float32
Dis_stg1.7 - - [1, 256, 4, 4] float32
Dis_stg1.8 - - [1, 257, 4, 4] float32
Dis_stg1.9 592384 16 [1, 256, 4, 4] float32
fc0_stg1 1048832 - [1, 256] float32
fc1_stg1 257 - [1, 1] float32
--- --- --- --- ---
Total 36231618 736 - -
Abstract
最近的研究表明,在修复图像中存在长距离相互作用的建模非常重要。为了实现这个目标,现有的方法利用独立的注意力技术或transformers,但通常考虑到计算成本而采用较低的分辨率。在本文中,我们提出了一种新颖的基于transformer的大孔修复模型,它将transformers和卷积的优点结合起来,以高效地处理高分辨率图像。我们精心设计了框架的每个组件,以保证修复图像的高保真度和多样性。具体而言,我们定制了一个专门用于修复图像的transformer块,其中注意力模块仅从部分有效令牌(通过动态掩码指示)聚合非局部信息。大量实验证明了新模型在多个基准数据集上的最先进性能。代码已发布在https://github.com/fenglinglwb/MAT。

Introduction
图像补全(也称为修复)是计算机视觉中的一个基本问题,其目标是使用合理的内容填充缺失的区域。它有许多应用,包括图像编辑[23]、图像重新定位[9]、照片修复[53, 54]和对象移除[3]。
在图像修复中,建模上下文信息是至关重要的,特别是对于大的遮罩(mask)。为缺失区域创建合理的结构和纹理需要对图像中的非局部先验[4, 7, 38, 56] 进行上下文理解。先前的工作使用堆叠卷积来达到大的感受野,并对长距离关系进行建模,这在处理对齐的数据(例如,面部,身体)和纹理密集的数据(例如,森林,水域)时效果良好。然而,在处理具有复杂结构的图像时(例如,图1第2行的第一个示例),对于完全卷积神经网络(CNN)来说,很难表征远距离区域之间的语义对应关系。这主要是由于CNN的固有属性,即有效感受野的缓慢增长和邻近像素的不可避免的主导性。为了明确地模拟图像修复中的长距离依赖关系,一些研究[61, 65, 66] 提出在基于CNN的生成器中使用注意力模块。然而,由于二次计算复杂性的限制,注意力模块仅应用于相对小规模的特征图,其效果没有充分利用长距离建模的潜力。
与将注意力模块应用于CNN不同,Transformer [52] 是一种自然的架构,用于处理非局部建模,在每个块中都使用了注意力机制。最近的研究[55,68,77] 采用Transformer结构来解决图像修复问题。然而,受复杂性问题的影响,现有的方法只使用Transformer来推断低分辨率(例如32×32)的预测结果,因此产生的图像结构较粗糙,特别是在处理大规模遮罩时,影响最终图像质量。
在本文中,我们开发了一种新的修复Transformer,能够为大遮罩修复生成高分辨率的结果。由于某些区域缺乏有用信息(当给定的遮罩排除了大多数像素时,这是常见情况),我们发现通常使用的Transformer块(LN→MSA→LN→FFN)在对抗性训练中表现较差。因此,我们对传统的层归一化[1]进行了自定义修改,并使用特征拼接替换了残差学习,以增加优化的稳定性并提高性能。我们分析了这些修改为何对学习至关重要,并在经验上证明了它们的非平凡性。另外,为了处理从高分辨率输入提取的所有标记之间可能的大量交互作用,我们提出了一种新型的多头自注意力(MSA),称为多头上下文注意力(MCA)。它只使用部分有效的标记来计算非局部关系。采用的标记选择由动态遮罩指示,该遮罩由输入遮罩初始化,并通过空间约束和长距离交互进行更新,从而在不损失效果的情况下提高了效率。此外,我们在提出的框架中加入了一种新颖的样式操作模块,从根本上支持多样性生成。如图1所示,我们的方法成功地使用视觉上逼真且非常多样的内容填补了大空洞。我们的贡献总结如下:
• 我们开发了一种新颖的修复框架MAT。它是第一个能够直接处理高分辨率图像的基于Transformer的修复系统。
• 我们精心设计了MAT的组件。提出的多头上下文注意力通过利用有效的标记有效地进行了长距离依赖建模,标记由动态遮罩指示。我们还提出了修改后的Transformer块,使得对大遮罩进行训练更加稳定。此外,我们设计了一种新颖的样式操作模块以增加多样性。
• MAT在多个基准数据集,包括Places [78] 和CelebA-HQ [25] 上取得了新的技术水平。它还实现了多样的修复效果。
Related Work
图像修复一直是计算机视觉中一个长期存在的问题。早期的扩散方法[2,6]将邻近未损坏的信息传播到空洞中。
在内部或外部搜索空间内,基于补丁或示例的方法[10–12,19,28,30,50]根据人工定义的距离度量,借用具有相似外观的补丁来完成缺失区域。PatchMatch [3] 提出了一种多尺度补丁搜索策略,以加速修复过程。此外,在文献中还广泛研究了偏微分方程[5, 17]和全局或局部图像统计[14, 15, 31]。虽然传统方法通常可以获得视觉上逼真的结果,但缺乏高层次的理解使它们无法生成语义上合理的内容。
近年来,深度学习在图像修复上取得了巨大成功。Pathak等人[42]将对抗性训练[16]引入到修复中,并利用基于编码器-解码器的架构来填补空洞。此后,针对图像修复开发了许多U-Net结构[45]的变体[34, 57, 64, 69]。
此外,还提出了更复杂的网络或学习策略来生成高质量的图像,包括全局和局部判别[22]、上下文注意力[35, 61, 65, 66]、部分[33]和门控[67]卷积等。多阶段生成也受到了广泛关注,其中包括利用中间线索,如物体边缘[40]、前景轮廓[63]、结构[44]和语义分割图[49]。
为了实现高分辨率图像修复,一些尝试已经开始发展逐步生成系统,例如[18, 32, 41, 71, 72]。最近,研究人员将注意力转向更具挑战性的设置,其中最具代表性的问题是多样性生成和大空洞填充。
对于前者,郑等人[76]提出了一个具有两个并行路径的概率框架,能够产生多个合理的解决方案。UCTGAN [74]通过优化KL散度将实例图像空间和遮罩图像空间投影到共同的低维流形空间,以实现缺失内容的多样性生成。随后,[55]和[68]利用双向注意力或自回归Transformer来实现这一目标。尽管这些方法提高了多样性,但由于变分训练和光栅扫描顺序生成,它们的修复和推理性能有限。另一方面,一些方法[37, 51, 75, 77]被提出来解决大空洞修复问题。例如,CoModGAN [75]利用调制技术[8, 26, 27]来处理大范围的缺失区域。在本研究中,我们开发了一种新的框架,同时实现高质量的多样性生成和大空洞填充,将长距离上下文交互和无条件生成的优势带入图像修复任务中。
Method
给定一个遮罩图像,表示为IM = I ⊙ M,图像修复的目标是为缺失区域生成视觉吸引人且语义合理的内容。在本研究中,我们提出了一种面向大遮罩修复的mask-aware transformer(MAT),支持条件下的长距离交互。此外,考虑到图像修复问题的不适定性,即可能有许多合理的解来填补大空洞,我们的方法旨在支持多样性生成。
总体架构
如图2所示,我们提出的MAT架构包括一个卷积头,一个具有五个阶段变分分辨率(不同数量的tokens)的transformer主体,一个卷积尾部和一个样式操作模块,充分发挥transformer和卷积的优势。
具体来说,卷积头用于提取tokens,然后主体由五个阶段的transformer块组成,用于通过提出的多头上下文注意力(MCA)对长距离交互进行建模。对于主体输出的tokens,采用基于卷积的重构模块将空间分辨率上采样到输入大小。
此外,我们采用另一个Conv-U-Net来细化高频细节,依靠CNN的局部纹理细化能力和高效性。最后,我们设计了一个样式操作模块,通过调节卷积的权重使模型能够生成多样性的预测。我们方法中的所有组件将在下面详细介绍。

卷积头
卷积头接收未完成的图像IM和给定的遮罩M,并产生用于tokens的1/8大小的特征图。它包含四个卷积层,一个用于改变输入维度,其他用于降低分辨率。
我们主要采用卷积头有两个原因。
首先,早期视觉处理中的局部归纳先验的整合对于更好的表示[43]和优化性能[60]仍然至关重要。另一方面,它被设计用于快速降采样,以减少计算复杂性和内存成本。此外,我们经验性地发现这种设计比ViT [13]中使用的线性投影头更好,这在补充材料中得到验证。
Transformer主体
Transformer主体通过建立长距离对应关系来处理tokens。它包含了五个阶段的提出的调整过的transformer块,其中包含了一个有效的注意力机制,并由额外的遮罩引导。
Adjusted Transformer Block
我们提出了一种新的transformer块变体,以处理带有大空洞遮罩的优化问题。具体而言,我们移除了层归一化(LN)[1],并采用融合学习(使用特征拼接)代替残差学习。如图3所示,我们将注意力的输入和输出进行了拼接,并使用一个全连接(FC)层:
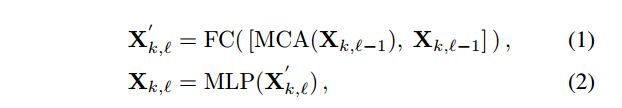
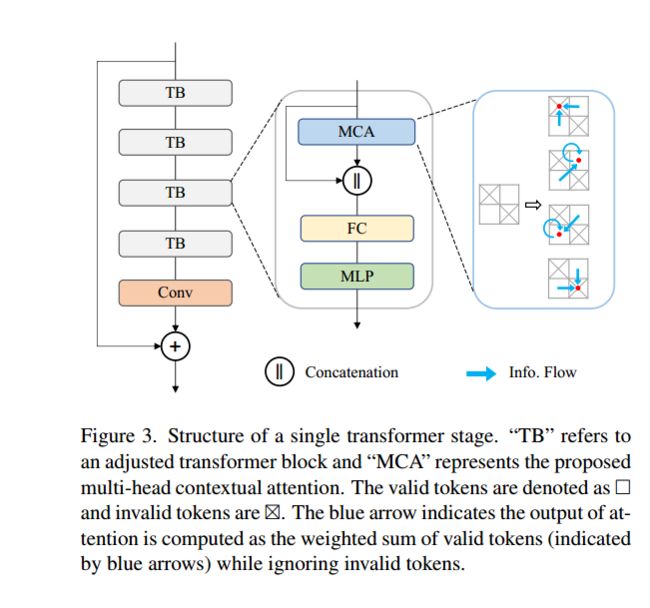
其中,Xk,ℓ是第k个阶段中第ℓ个块的MLP模块的输出。在经过几个transformer块后,如图3所示,我们采用一个带有全局残差连接的卷积层。值得注意的是,我们在transformer块中放弃了位置嵌入,因为研究[59, 62]表明3×3卷积足以为transformers提供位置信息。因此,信息的传递仅依赖于特征相似性,从而促进了长距离交互。
分析。Transformer [52] 的通用架构包含两个子模块,一个是多头自注意力(MSA)模块,另一个是MLP模块。在每个模块之前都应用了层归一化,并在每个模块之后使用了残差连接[20]。然而,我们观察到当处理大规模遮罩时,使用通用的块进行优化时会出现不稳定的问题,有时甚至会导致梯度爆炸。我们将这个训练问题归因于无效标记(其值接近零)的比例较大。在这种情况下,层归一化可能会过分放大无用的标记,导致训练不稳定。此外,残差学习通常鼓励模型学习高频内容。然而,考虑到开始时大部分标记都是无效的,在GAN训练中没有适当的低频基础的情况下,直接学习高频细节是困难的,这使得优化变得更加困难。用拼接取代这种残差学习导致了明显优越的结果,这在第4.3节中得到了验证。
Multi-Head Contextual Attention
为了处理大量的标记(对于512×512的图像,最多有4096个标记)和给定标记的低保真度(最多90%的标记是无用的),我们的注意力模块采用了位移窗口[36]和动态遮罩,能够利用少量可行的标记进行非局部交互。输出是有效标记的加权和,如图3所示,其数学表达式为:

遮罩更新策略。遮罩(M’)指示一个标记是否有效或无效,它由输入遮罩初始化,并在传播过程中自动更新。更新遵循一个规则,即在注意力后,只要一个窗口中至少有一个有效标记,该窗口中的所有标记都将被更新为有效。如果一个窗口中的所有标记都是无效的,在注意力后它们仍然保持无效。如图4所示,在从(a)到(b)的注意力传播中,左上角窗口中的所有标记变为有效,而其他窗口中的标记仍然无效。经过几次窗口的移动和注意力传播后,遮罩被更新为完全有效。
分析。对于由缺失区域主导的图像,缺省的注意力策略不仅无法利用可见信息填充空洞,而且还会损害有效像素的有效性。为了减少颜色差异或模糊度,我们提议仅使用有效标记(由动态遮罩选择)来计算关联。我们的设计的有效性在第4.3节中得到了体现。

Style Manipulation Module

Loss Functions

Experiments
Datasets and Metrics
我们在512×512分辨率下对Places365-Standard [78]和CelebA-HQ [25]数据集进行了实验。
具体来说,在Places数据集上,我们使用180万张训练集图像和3.65万张验证集图像来分别训练和评估我们的模型。在训练过程中,图像被随机裁剪或填充到512×512大小,而在评估过程中则进行中心裁剪或填充。对于CelebA-HQ数据集,我们有24,183张训练集图像和2,993张验证集图像。尽管我们在512×512图像上进行训练,但在补充材料中我们展示了我们的模型在更大分辨率上也表现良好。
在大空洞设置方面,我们遵循[75]的方法,选择了感知度量,包括FID [21]、P-IDS [75]和U-IDS [73]来进行评估。我们建议不要使用像素级的L1距离、PSNR和SSIM [58]等指标,因为初步研究[29,47]表明,这些指标与人类对图像质量的感知关系较弱,尤其对于不适定的大规模图像修复问题。虽然我们计算了LPIPS [73],但在视觉质量评估中,这个指标的表现也不理想。
Implementation Details
在我们的框架中,我们将卷积通道数和全连接维度都设置为180,分别用于卷积头部、主体和重构模块。5级transformer组的块数和窗口大小分别为{2, 3, 4, 3, 2}和{8, 16, 16, 16, 8}。最后的Conv-U-Net首先将分辨率下采样到1/32,然后再上采样到原始大小,其中卷积层数和不同尺度的通道数取自[27]。映射网络由8个全连接层组成,样式操作模块由卷积层和AvgPool层实现。与[55, 68, 77]不同,我们的transformer架构没有进行预训练。
所有实验在8块NVidia V100 GPU上进行。
按照[75]的方法,我们在Places365-Standard上训练了5000万张图像,在CelebA-HQ上训练了2500万张图像。批大小为32。我们采用Adam优化器,其中β1 = 0,β2 = 0.99,并将学习率设置为1 × 10−3。自由形式的遮罩在补充文件中有详细描述。
Ablation Study
在本节中,我们分析了我们框架中哪些组件对最终性能的贡献最大。为了快速探索,我们只使用Places [78]数据集中的100,000张训练图像(约占全部图像的5.6%),分辨率为256×256,并对模型进行了500,000次样本的训练(相当于完整设置的10%)。我们采用前10,000张验证图像进行评估。定量比较结果如表1所示。
Conv-Transformer Architecture. 我们探索了transformer所建模的远程上下文关系是否有助于填充大空洞。将transformer块替换为卷积块(表1中的“B”模型),我们发现在所有指标上都出现了明显的性能下降,尤其是在P-IDS和U-IDS上,表明修复后的图像失去了一些保真度。此外,在图5中我们展示了一些视觉示例。与完全卷积网络相比,我们的MAT充分利用了远程上下文来很好地重建了网络结构和恐龙骨架的纹理,表现出了远程交互的有效性。
调整后的Transformer块。在我们的框架中,我们开发了一种新的transformer块,因为传统设计很容易导致不稳定的优化,这种情况下我们需要降低transformer主体的学习率。如表1所示,我们的设计(“A”模型)在FID上的性能比具有原始transformer块的模型“C”提高了0.39。如图5所示,我们注意到我们的设计产生了更具吸引力的结果,支持高质量的图像修复。特别是对于第一个示例,尽管缺失区域非常大,我们的方法仍然可以恢复出一个在语义上一致且在视觉上逼真的室内场景。
多头上下文注意力。为了快速填充缺失区域,我们提出了多头上下文注意力(MCA)。为了更深入地了解其效果,我们构建了一个没有从有效标记进行部分聚合的模型。定量结果如表1中的模型“D”所示。值得注意的是,FID下降了0.1,但其他指标变化不大。我们认为所提出的上下文注意力有助于保持颜色一致性并减少模糊。如图5所示,没有MCA的模型为第一个示例生成了颜色不正确的内容,同时为第二个示例产生了模糊的伪影。定量和定性结果都验证了我们的MCA的强大能力。
样式操作模块。为了处理大遮罩,在条件性远程交互之外,我们还引入了无条件生成。为了量化我们的框架的无条件生成能力,我们去掉了噪声样式操作。从表1中的模型“E”的结果中,我们发现在P-IDS和U-IDS上有很大的差距,表明随机噪声样式的调制进一步提高了修复图像的自然性。
重建中的高分辨率。由于计算复杂度的二次增加,现有的方法[55,68, 77]采用transformer来合成低分辨率结果,通常是32×32,用于后续处理。相比之下,我们的MAT架构利用其计算效率,使得在重建阶段可以输出高分辨率的结果。如表1所示,我们完整的“A”模型相比于模型“F”显著提高,证明了高分辨率预测的重要性。

Comparison with State of the Arts
我们将提出的MAT与一些最先进的方法进行了比较。为了公平比较,我们使用公开可用的模型对相同的遮罩进行测试。如表2所示,MAT在CelebA-HQ和Places上实现了最先进的性能。特别是,即使我们只使用Places365-Standard的一个子集(180万张图像)来训练我们的模型,远远少于CoModGAN [75](800万张图像)和Big LaMa [51](450万张图像),MAT仍然取得了有希望的结果。此外,我们的方法在参数效率上远远优于第二名的CoModGAN和基于transformer的ICT [55]。如图8所示,与其他方法相比,我们提出的MAT恢复出更多具有照片般真实感的图像,并且产生较少的伪影。例如,我们的方法成功恢复了视觉上令人愉悦的花朵和规则的建筑结构。

MAT: Mask-Aware Transformer for Large Hole Image Inpainting (Supplementary Material)

Pluralistic Generation
我们框架固有的多样性主要来源于样式操作。如图6所示,样式变体导致不同的填充结果。在图6的第一个示例中,我们观察到从一个微笑变为一个露齿笑。而第二个示例展示了不同的脸部轮廓和外观。至于最后一个示例,我们发现了不同的窗户和屋顶结构。

Limitations and Failure Cases
在没有语义标注的情况下,MAT通常在处理具有各种形状的对象时遇到困难,例如奔跑的动物。如图7所示,由于缺乏语义上下文的理解,我们的方法未能恢复出猫和汽车。另外,受到注意力中的下采样和预定义窗口大小的限制,我们需要对图像进行填充或调整大小,使其大小成为512的倍数。

Conclusion
我们提出了一种面向遮罩的变换器(MAT),用于多样化的大空洞图像修复。通过利用所提出的调整后的变换器架构和部分注意机制,我们的MAT在多个基准测试中实现了最先进的性能。此外,我们设计了一个样式调制模块来提高生成的多样性。广泛的定性比较已经证明了我们的框架在图像质量和多样性方面的优势。
补充材料

Network Architecture
如第3.1节所示,我们提出的MAT是一个两阶段的框架,其中第一阶段包括一个卷积头部、一个变换器主体和一个卷积重建尾部,而第二阶段是一个Conv-U-Net。鉴别器的设计遵循CoModGAN [75]的设计。
给定一个H×W的输入,头部首先应用一个卷积将通道数从4(图像3 + 掩码1)改变为180,然后采用三个步幅为2的卷积来将特征大小下采样到H 8×W 8。特征被转换为令牌,作为变换器主体的输入。主体由五个阶段的变换器块组成,其中块数分别为{2, 3, 4, 3, 2},相应的特征大小为{H 8×W 8, H 16×W 16, H 32×W 32, H 16×W 16, H 8×W 8}。下采样和上采样都是通过卷积实现的。变换器块的详细结构在第3.3节中展示。
然后,来自主体的输出令牌被转换为2D特征,传递给重建尾部。卷积尾部将特征大小从H 8×W 8上采样到H×W,并生成完整的图像,在此过程中,对所有层进行样式调制以实现多样化的生成。
第二阶段的Conv-U-Net接收粗糙预测和输入的掩码,用于后续高保真度细节渲染。它首先将特征大小下采样到H 32×W 32,然后再将大小上采样回H×W。每个分辨率都采用了快捷连接。编码器中的卷积通道数从64开始,并在每次下采样后加倍,最多为512,而解码器使用对称的设置。此外,所有解码层都由图像条件和噪声非条件样式表示进行调制。
Free-Form Mask Sampling and Statistics
参考DeepFill v2 [67],我们使用随机大小、形状和位置来生成自由形式的掩码,包括矩形和画笔笔画。在训练期间,我们采用了大掩码采样策略。完整尺寸或半尺寸矩形的数量在[0, 3]或[0, 5]范围内均匀采样。笔画的数量在[0, 9]范围内随机采样,笔刷宽度在[12, 48]范围内随机,顶点数量在[4, 18]范围内随机。在测试期间,除了大掩码设置外,我们还引入了小掩码采样策略,其中完整尺寸或半尺寸矩形的数量在[0, 2]或[0, 3]范围内,笔画的数量在[0, 4]范围内,而其他设置保持不变。请注意,我们的模型是在大掩码上进行训练,并在小掩码和大掩码设置下进行评估。如图A.2所示,我们展示了用于评估的Places Val数据集 [78]上的掩码统计信息。可以观察到,大掩码非常多样和复杂。

Tokenization
如在附录A中所述,我们采用了一堆卷积(卷积头部)来提取用于变换器主体的令牌,这是专门针对修复问题设计的。与ViT [13]的线性投影相比,我们的设计具有两个优点。首先,堆叠卷积可以逐渐填充缺失区域,生成更有效的令牌。其次,多尺度下采样特征可以通过快捷连接传递给解码器,改善优化过程。如表C.1和图C.3所示,堆叠卷积获得了明显优于线性投影的结果。使用线性投影的模型更容易生成不好的伪影,并且无法借用周围纹理来填充缺失区域,而我们的MAT成功地恢复了高保真度的内容。定量和定性结果都证明了我们MAT的有效性。

模型配置
在与消融研究相同的实验设置下,我们探索了几种模型变体,包括变换器主体的特征宽度、块数和窗口大小,Conv-U-Net保持不变。结果如表D.2所示。性能与模型容量和注意范围呈正相关。
CelebA-HQ 256×256结果
我们提供了256×256 CelebA-HQ [25]的定量结果。如表F.3所示,相比其他方法,我们的MAT在FID [21]、P-IDS [75]和U-IDS [73]指标上取得了显著改进。
LPIPS结果
如在第4.1节中讨论的,LPIPS [73]不是用于大掩码修复,特别是对于多样性生成系统来说,因为填充缺失区域可能有很多合理的解决方案。因此,我们仅提供LPIPS结果供参考。如表F.4所示,我们的方法在CelebA-HQ [25]和Places [78]数据集上实现了优越或可比的性能。请注意,我们只使用了完整数据的22.5%来训练我们的Places模型。

高分辨率的泛化能力
尽管我们是在512×512的图像上进行训练的,但我们的模型对更大的分辨率也有良好的泛化能力。例如,我们将在512×512分辨率下训练的模型和Big LaMa [51] 迁移到1024×1024分辨率。与Big LaMa相比(FID降低6.31%,PIDS提高4.98%),我们的模型(FID降低5.83%,P-IDS提高9.51%)在大掩码设置下在Places数据集上获得了更优秀的结果。
我们建议在训练和测试过程中保持分辨率一致,以获得更好的视觉质量。
多样性-保真度权衡
为了评估保真度和多样性,除了使用FID(同时考虑多样性和保真度),我们还遵循[?,?]使用改进的精度和召回率分别衡量样本的保真度(精度)和多样性(召回率)。如表H.5所示,与CoModGAN相比,在Places数据集上,我们的方法获得更好的FID,更高的召回率,但略低于CoModGAN的精度。值得注意的是,我们使用了更少的训练数据。

其他定性结果
我们在Places [78]数据集上展示了更多MAT与其他最先进方法的视觉比较结果。如图J.4和图J.5所示,我们的方法产生了更多的照片逼真的结果,并且几乎没有瑕疵,显示了MAT的有效性。由于CelebA-HQ [25]可能涉及版权问题,我们不在该数据集上提供视觉比较结果。如果需要的话,您可以使用提供的代码和模型处理CelebAHQ图像,或者与作者联系。