RISC-V 向量指令集研究 (一)
目录
一、RISC-V向量指令集和SIMD
1、SIMD技术简介
2、 向量计算技术简介
3、Vector向量计算技术的优势
4、 Vector向量计算技术的劣势
二、RISC-V VECTOR spec1.0标准
1、简介
2、向量指令集的参数
3、向量扩展的编程模型
4、向量元素到向量寄存器的映射
5、向量指令格式
6、配置指令 (vsetvli、vsetivli、vsetvl)
7、 向量LS指令
8、 向量存储对齐约束
9、 向量存储一致性模型
10、向量算数指令格式
11、向量整数算数指令
12、 向量定点算数指令
13、 向量浮点算数指令
14、 向量减法
15、 向量掩码指令
16、 向量排列指令
17、 向量异常处理
18、 标准向量扩展
19、向量指令列表
三、玄铁c910中的向量指令集 (详情见 RISC-V 向量指令集研究 (二))
四、 github上的向量协处理器 (详情见 RISC-V 向量指令集研究 (二))
RISCV 向量指令集研究
一、RISC-V向量指令集和SIMD
1、SIMD技术简介
传统的通用处理器都是标量处理器,一条指令执行只得到一个数据结果。但对于图像、信号处理等应用,存在大量的数据并行性计算操作,这个时候,提高数据的并行性从而提高运算的性能就显得尤为重要。因此,SIMD技术应运而生。
SIMD的英文全称是Single Instruction Multiple Data,即单指令流多数据技术,SIMD的概念是相对于SISD(Single Instruction Single Data,单指令流单数据)提出的。
SIMD技术最初通过将64位寄存器的数据拆分成多个8位、16位、32位的形式来实现byte、half word、word类型数据的并行计算;在后续,为了进一步增加计算的并行度,SIMD技术开始通过增加寄存器位宽来满足应用对算力的需求。对于传统的SIMD技术,Intel的MMX、SSE系列、AVX系列,以及ARM的Neon架构都是其中的代表。
2、 向量计算技术简介
提高数据并行性的另一种方式就是向量计算技术。与传统的SIMD技术一样,其也是通过扩展寄存器位宽,来增加计算的并行度;但不同的是,向量寄存器是可变长度的寄存器,而不像SIMD那样嵌入在操作码中。向量技术的代表就是RISC-V V扩展指令集和ARM的SVE架构。
3、Vector向量计算技术的优势
相比于传统的SIMD技术,矢量计算技术是一种硬件软件更加解耦的技术,其对编程人员更加友好,是一种软硬件协同的技术典范。
4、 Vector向量计算技术的劣势
向量架构带来更灵活的使用本身也可能带来一些负面影响。由于操作数本身不指定操作数类型,需要通过vsetvli指令专门设置,则当出现频繁的数据类型切换时,必然会带来更多的指令数。
除了操作数据类型,向量长度(VL)也是通过vsetvli指令非显式的设置的,在超标量乱序处理器中,若频繁的更改向量长度,则可能带来潜在的性能损失。除此之外,RISC-V V指令集制定时间较短,相比于ARM Neon等发展多年的SIMD指令集,在指令功能的丰富性上尚有欠缺,因此,在碰到一些特定场景时,需要使用更多的指令去实现相应的功能,进一步降低了整体的性能。
二、RISC-V VECTOR spec1.0标准
本部分根据Spec进行介绍,spec共19个章节。
1、简介
1.0-版本为当前稳定版本,
2、向量指令集的参数
向量指令集的扩展必须有如下两个参数:
(1) ELEN:任何操作都可以产生或消耗的向量元素的最大位大小,ELEN≥8,它必须为2的幂。
(2) VLEN:单个向量寄存器中的位数,VLEN≥ELEN,它必须是2的幂,并且不能大于2的 16次方。
ELEN:element-length,处理器内部能够处理的一个向量元素的最大bit数,要求大于8且是2的整数次幂。
VLEN:vector-length,一个向量寄存器的总bit数(宽度),VLEN应该大于等于ELEN,也是2的整数次幂。risc-v sprc要求VLEN小于2^16。
标准的向量扩展会对ELEN和VLEN进行进一步的约束
3、向量扩展的编程模型
矢量扩展将32个架构矢量寄存器和七个非特权CSR(vstart、vxsat、vxrm、vcsr、vtype、vl、vlenb)添加到基本标量RISC-V ISA中,如下表所示
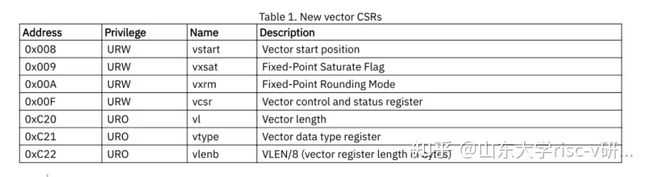
Vstart:向量指令要执行的第一个element的索引,任意一条向量指令执行时,vstart之前的向量将被忽略,该条向量执行结束后vstart被置0,所有向量指令包括vset{i}vl{i}执行结束后都会把该寄存器置零。
Vxsat:定点饱和标志
Vxrm:定点数四舍五入模式
vcsr :向量控制和状态寄存器
vl:实际执行的向量长度 ,只能在一条vset{i}vl{i}指令执行后自动更新
vtype:向量数据类型,用于说明向量元素的类型。这个寄存器很特殊,只能在一条vset{i}vl{i}指令执行后自动更新,而其标识了向量的实际宽度、组织方式、mask处理策略、tail处理策略等多种信息
vlenb:VLEN/8
1、 向量处理器添加了mstatus寄存器的位和vsstatus来表示向量指令执行的状态。
2、 向量指令添加了一个XLEN宽度的CSR类型寄存器vtype,这个寄存器只能通过vsetvl指令来更新。vtype决定了每个向量寄存器中元素的组织,以及多个向量寄存器如何分组。vtype寄存器还指示如何处理向量结果中超过当前向量长度的元素。


Vsew:选择向量元素的宽度
vlmul[2:0]:多个向量寄存器可以分组在一起,因此单个向量指令可以在多个向量寄存器上操作。向量体系结构包括使用多个具有不同元素宽度、但具有相同元素数量的源和目标向量操作数的指令。每个向量操作数的有效LMUL(EMUL)由保存元素所需的寄存器数量决定。
Vill:当先前的vsetvl{i}指令试图写入一个不被支持的值到vtype寄存器,vtype的vill域置1,同时vtype的其他域均清0。后面其他依赖于vtype寄存器执行的指令,将会引发非法指令异常。
Vta:用于指示“tail elements”的填充方法(尾部元素)。
Vma:用于指示被mask元素的填充方法。


VMUL:必须支持的LMUL值为1,2,4,8。用向量寄存器组可以实现单指令的单操作数,从不同的向量寄存器中取数。VMUL也支持小数,可以在多个寄存器上各取部分数。
一般来说,LMUL≥SEWmin/ELEN,其中SEWmin是最小支持的SEW值,而ELEN是最宽支持的SEW值。在标准扩展中,SEWMIN=8。对于使用ELEN=32的标准向量扩展,必须支持1/2和1/4的分数lmul。对于使用ELEN=64的标准向量扩展,必须支持1/2、1/4和1/8的分数lmul。
当LMUL < SEWMIN/ELEN时,不能保证实现在分数向量寄存器中有足够的位来存储至少一个元素,因为VLEN=ELEN是一个有效的实现选择。例如,对于VLEN=ELEN=32和SEWmin=8, 1/8的LMUL在一个向量寄存器中只提供4位的存储。

VLMAX = LMUL*VLEN/SEW表示给定当前SEW和LMUL设置,可以使用单个向量指令操作的元素的最大数量。
4、向量元素到向量寄存器的映射
Mapping for LMUL = 1

当在多个精度值不同的向量上操作时,推荐的软件策略是动态修改vtype以保持SEW/LMUL恒定(因此VLMAX恒定)。
下表显示了具有混合宽度操作的循环的每个可能的常数SEW/LMUL操作。每一列代表一个恒定的SEW/LMUL操作点。表中的条目是生成该行上数据宽度的SEW/LMUL值的LMUL值。在每一列中,数据宽度的LMUL设置表明它可以与同一列中同样具有LMUL设置的其他数据宽度对齐,这样所有的数据宽度都具有相同的VLMAX。

VLMAX = LMUL*VLEN/SEW表示在给定当前SEW和LMUL设置下,可以使用单个向量指令操作的最大元素数量
表中的表项是lmul,
如,SEW/LMUL=1时, SEW=8,那么LMUL也是8,来保证VLMAX恒定。
5、向量指令格式
一、在原有的load-FP和store-FP上添加了一种新的操作码(OP-V)
1:VL,类似load-fp
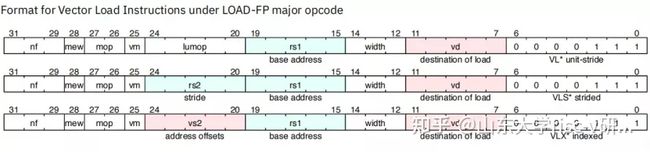
2、VS,类似store FP

3 、VECOTOR 操作指令,包括数学计算类和配置类



二、操作数:
1、标量操作数
标量操作数可以是立即数,或者是x寄存器,f寄存器的值,或者v寄存器的0值。
2、向量操作数
每个向量操作数都有一个有效元素宽度(EEW)和一个有效LMUL(EMUL),该宽度用于确定向量寄存器组中所有元素的大小和位置。默认情况下,对于大多数指令中的大多数操作数,使用EEW=SEW和EMUL=LMUL。
一些向量指令的源操作数和目的操作数,有相同元素数但宽度不同,因此EEW和EMUL分别不同于SEW和LMUL,而是EEW/EMUL = SEW/LMUL。例如,大多数扩展算术指令都有一个具有EEW=SEW和EMUL=LMUL的源组,也有一个具有EEW=2*SEW和EMUL=2*LMUL的目标组。缩小指令的源操作数EEW=2*SEW和EMUL=2*LMUL,但其目的操作数满足EEW=SEW和EMUL=LMUL。
根据EMUL,向量操作数或结果可能占据一个或多个向量寄存器,但总是使用组中编号最小的向量寄存器。使用非最低编号的向量寄存器来指定一个向量寄存器组是一个保留编码。
一个指令使用的最大向量寄存器组不能大于8个向量寄存器(即EMUL≤8),如果一个向量指令需要在一个组中超过8个向量寄存器,则保留指令编码。例如,当LMUL=8被保留时,扩展操作产生扩大的矢量寄存器组结果,因为这将意味着结果EMUL=16。
一个指令使用的最大向量寄存器组不能大于8个向量寄存器(即EMUL≤8),如果一个向量指令需要在一个组中超过8个向量寄存器,则保留指令编码。例如,当LMUL=8被保留时,扩展操作产生扩大的矢量寄存器组结果,因为这将意味着结果EMUL=16。
6、配置指令 (vsetvli、vsetivli、vsetvl)
处理大量元素的一种常见方法是“条状挖掘”,即循环的每次迭代都处理一些元素,迭代继续,直到所有元素都被处理完毕。
(1)vtype

(2)AVL编码应用向量长度(AVL)应用程序特性将要处理的元素总数(应用程序向量长度或AVL)

(1)当rs1不是x0时,AVL的值是rs1中的无符号整数
(2) Rs1是x0但是rd不是x0时,最大的无符号整数值不是0,并且VLMAX的结果会写入vl且写入x寄存器
(3)当rd和rs1都是x0时,AVL的值为vl的值,并且结果值被写入vl,但不写入目标寄存器
(3)vl指令的约束
Vestvl指令首先设置VLMAX,然后设置vl
1. vl = AVL if AVL ≤ VLMAX
2. ceil(AVL / 2) ≤ vl ≤ VLMAX if AVL < (2 * VLMAX)
3. vl = VLMAX if AVL ≥ (2 * VLMAX)
4.对相同的输入AVL和VLMAX值的给定确定的实现
5.a. vl = 0 if AVL = 0
b. vl > 0 if AVL > 0
c. vl ≤ VLMAX
d. vl ≤ AVL
e. .当从vl读取作为AVL参数时,一个值在vl中得到相同的值,前提是生成的VLMAX等于读取vl时的VLMAX值
7、 向量LS指令
向量加载和存储在向量寄存器和内存之间移动值。向量加载和存储被掩码,并且不会对非活动元素引起异常。所有向量加载和存储都可以生成并接受一个非零的vstart值。
向量的load和store指令编码格式和浮点的load/store格式相同
8、 向量存储对齐约束
如果向量内存指令访问的元素与element大小不对齐,则引发地址不对齐异常。
9、 向量存储一致性模型
矢量内存指令在指令级别上遵循RVWMO,
10、向量算数指令格式
向量算术指令使用了一个新的主要操作码(OP-V = 10101112),它与OP-FP相邻,用func t3 定义具体的指令
11、向量整数算数指令
12、 向量定点算数指令
13、 向量浮点算数指令
标准向量浮点指令将元素视为IEEE-754/2008兼容的值。如果向量浮点操作数的EEW与所支持的IEEE浮点类型不对应,则保留指令编码。
14、 向量减法
15、 向量掩码指令
16、 向量排列指令
17、 向量异常处理
在向量指令期间的trap上(由同步异常或异步中断引起),现有的*epc CSR是用一个指向向量指令的指针编写的,而vstart CSR包含跟踪trap的元素索引。
18、 标准向量扩展
面向嵌入式的扩展为 zve
面向大算力的扩展为 V
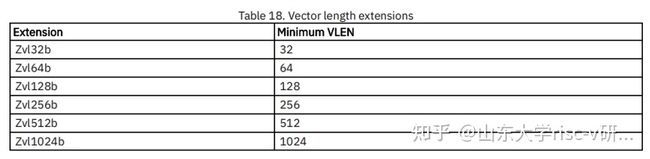
1、 zvl扩展:最小向量长度的标准扩展
所有的标准向量扩展都有一个最低要求的VLEN,如下所述。提供了一组向量长度扩展,以增加最小向量长度
2、zve扩展:面向嵌入式的扩展
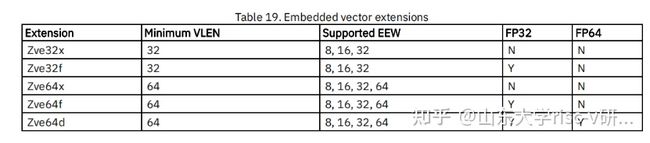
Zve支持:
1、 向量配置指令
2、 向量存储加载指令
3、 向量整数指令
4、 向量定点数指令
5、 向量整数单宽和扩大约简操作
6、 支持掩码
7、 向量排列指令
8、 Zve32f和Zve64f扩展要求标量处理器实现F扩展或者zfinx扩展
9、 Zve64d扩展要求标量处理器实现D扩展或提议的Zdinx扩展,并使用EEW=32或EEW=64实现浮点操作数的所有向量浮点指令
3、 V扩展:面向大算力
V扩展旨在用于应用程序处理器专业版。
V向量扩展需要Zvl128b。
V扩展支持EEW的8、16、32和64。
1、 向量配置指令
2、 V扩展支持所有向量加载和存储指令
3、 V扩展支持所有向量整数指令
4、 向量定点数指令
5、 V扩展支持所有矢量整数单宽和扩大整数约简操作
6、 V扩展支持所有矢量掩码指令
7、 V扩展支持所有的向量排列指令
8、 V扩展要求标量处理器实现F和D扩展,并使用EEW=32或EEW=64实现浮点操作数的所有向量浮点指令
19、向量指令列表
本文章仅供学习交流,如有引用请标注出处。