matlab中resample重采样函数
resample函数
对时间序列进行重采样
格式:
1、y=resample(x,p,q)
x–待重采样的时间序列;
p–重采样之后目标频率;
q–待重采样的时间序列频率
采用多相滤波器对时间序列进行重采样,得到的序列y的长度为原来的序列的长度的p/q倍,p和q都为正整数。此时,默认地采用使用FIR方法设计的抗混叠的低通滤波器
2、y=resample(x,p,q,n)
n–滤波器长度与n成正比;
采用chebyshevIIR型低通滤波器对时间序列进行重采样,滤波器的长度与n成比例,n缺省值为10.
3、y=resample(x,p,q,n,beta)
beta为设置低通滤波器时使用Kaiser窗的参数,缺省值为5.
4、y=resample(x,p,q,b)
b为重采样过程中滤波器的系数向量。
5、[y,b]=resample(x,p,q)
输出参数b为所使用的滤波器的系数向量。
(1)在实际操作中当x端点处的值与零的偏差较大时,可能会导致y出现意外值;
如图
clc
clear
file= readmatrix("7777.csv");
data=[];
for i=1:size(file,2)
num=file(:,i);
data=[data;num];
end
data1=resample(data,1,10,10,5);
x=1:1:length(data);
x1=1:10:length(data);
figure;
plot(x,data,'b-')
hold on;
plot(x1,data1,'g-')
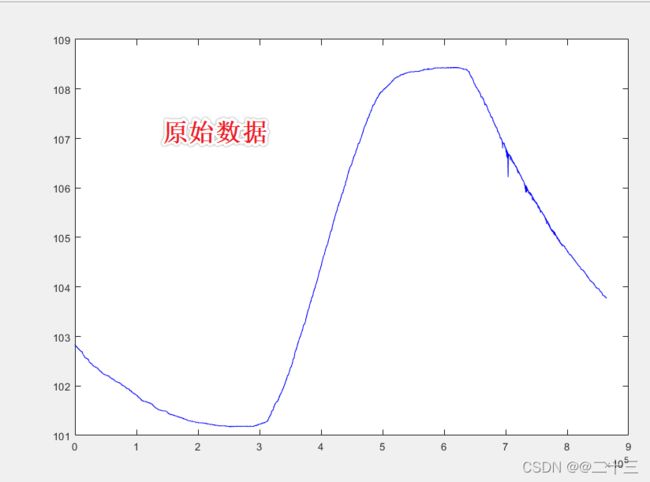

局部数据放大之后

上述问题,我查了一些资料,可以按照参考这个博主的解决方法:学习如何在matlab用带通滤波器进行滤波
我想的是,直接在开头和结尾添加少量数据,然后在最后的结果中将这些数据删除掉,,这样的话,虽然还是有一些问题,但应该问题不大。
clc
clear
file= readmatrix("7777.csv");
data=[];
for i=1:size(file,2)
num=file(:,i);
data=[data;num];
end
%在原始数据首尾都添加1000条数据,我的原始数据有86.4万条,所以去的比较多
data_1=[data(1:1000);data;data(length(data)-999:length(data))];
data1=resample(data_1,1,10,10,5);
%将重采样之后的数据,删除掉首尾添加的数据
data1_1=data1(101:length(data)/10+100);
x=1:1:length(data);
x1=1:10:length(data);
figure;
plot(x,data,'b-')
hold on;
plot(x1,data1_1,'g-')
绘图结果
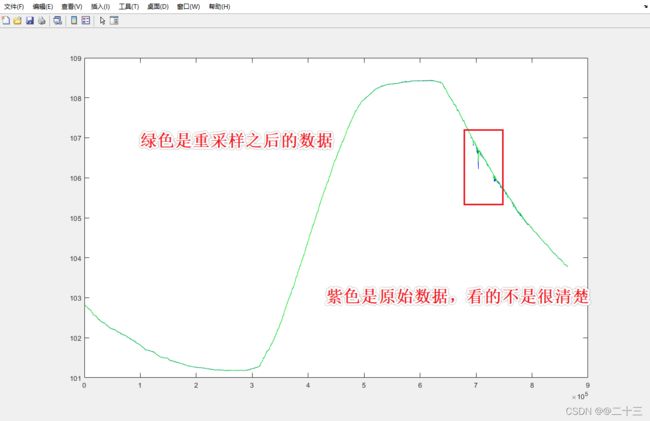
(2)当重采样的信号出现混叠效应时,这是由相对较大的主瓣和较低的旁瓣衰减导致的,此时增加n的值,可以削减这个现象,较长的窗口具有较窄的主瓣,并更好地衰减了混叠效果,同时也会衰减信号。
(3)当beta过大时,会产生较宽的主瓣,生成大量伪像。