torch.nn.init
torch.nn.init.uniform(tensor, a=0, b=1)
从均匀分布U(a, b)中生成值,填充输入的张量或变量
参数:
- tensor - n维的torch.Tensor
- a - 均匀分布的下界
- b - 均匀分布的上界
例子
# 均匀初始化
input = torch.Tensor(3,5) # 生成3*5大小的零矩阵
print(input)
init = torch.nn.init.uniform_(input,0,1) # 现在uniform_取代uniform了
print(init)
结果:
tensor([[1.0194e-38, 9.0919e-39, 8.4490e-39, 9.6429e-39, 8.4490e-39],
[9.6429e-39, 9.2755e-39, 1.0286e-38, 9.0919e-39, 8.9082e-39],
[9.2755e-39, 8.4490e-39, 8.9082e-39, 9.1837e-39, 1.0561e-38]])
tensor([[0.1387, 0.1260, 0.9661, 0.7919, 0.1921],
[0.8230, 0.0927, 0.0274, 0.3629, 0.7967],
[0.7510, 0.7023, 0.2343, 0.4486, 0.9307]])
torch.nn.init.normal(tensor, mean=0, std=1)
从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量
参数:
- tensor – n维的torch.Tensor
- mean – 正态分布的均值
- std – 正态分布的标准差
torch.nn.init.constant(tensor, val)
用val的值填充输入的张量或变量
参数:
- tensor – n维的torch.Tensor或autograd.Variable
- val – 用来填充张量的值
torch.nn.init.eye(tensor)
用单位矩阵来填充2维输入张量或变量。在线性层尽可能多的保存输入特性。
torch.nn.init.xavier_uniform(tensor, gain=1)
用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自U(-a, a),其中

fan_in = kernel_size[0] * kernel_size[1] * in_channels
fan_out = kernel_size[0] * kernel_size[1] * out_channels
该方法也被称为Glorot initialisation.
参数:
- tensor – n维的torch.Tensor
- gain - 可选的缩放因子

torch.nn.init.kaiming_uniform(tensor, a=0, mode=‘fan_in’)
用一个正态分布生成值,填充输入的张量或变量。结果张量中的值采样自均值为0,标准差为 s t d 2 std^2 std2的正态分布。
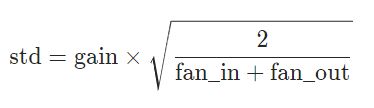
参数:
- tensor – n维的torch.Tensor或 autograd.Variable
- a -这层之后使用的rectifier的斜率系数(ReLU的默认值为0)
- mode -可以为“fan_in”(默认)或“fan_out”。“fan_in”保留前向传播时权值方差的量级,“fan_out”保留反向传播时的量级。

总结:针对于Relu的激活函数,基本使用He initialization,pytorch也是使用kaiming 初始化卷积层参数的