[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification
Contents
- Introduction
- Preliminary Study
-
- Performance Investigation of VPT (Visual Prompt Tuning)
- Analysis of Prompt Tuning
- Long-tailed Prompt Tuning (LPT)
-
- Phase 1: Shared Prompt Tuning
- Phase 2: Group Prompts Tuning
- Loss Function
- Experiments
-
- Comparison with State-of-The-Art Methods
- Robustness with Domain Shift
- Ablation Study
- References
Introduction
- 作者提出 Long-tailed Prompt Tuning (LPT),通过 prompt learning 来解决长尾问题,包括 (1) 使用 shared prompt 学习 general features 并将预训练模型 adapt 到 target domain;(2) 使用 group-specific prompts 学习 group-specific features 来提高模型的 fine-grained discriminative ability
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第1张图片](http://img.e-com-net.com/image/info8/3169bd49c26148fd9529ef168ad651db.jpg)
Preliminary Study
Performance Investigation of VPT (Visual Prompt Tuning)
- 作者首先通过对比 VPT (Visual Prompt Tuning) 和 linear probing 在 Places-LT 数据集上的精度来说明 prompt tuning 对长尾数据集是有效的 (VPT 的输入为 input tokens 加上 learnable prompts (tokens),同时和 linear probing 一样在预训练模型最后加上 linear classifier)
- 从下表中可以看出:a) prompt tuning 可以持续提高模型的 LTR 性能;b) prompt tuning 对长尾分布具有鲁棒性,能更好地学习尾部类别。同时也可以注意到,简单的 prompt tuning 并不能直接让模型在长尾数据集上达到 SOTA
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第2张图片](http://img.e-com-net.com/image/info8/bc68a99733854acfba60867b5a3ff4b4.jpg)
Analysis of Prompt Tuning
- 作者接下来分析了为什么 prompt tuning 适合长尾识别 (但仍然没有从原理上分析为什么)
- 由下图的 LDA 可视化可以看出 (use the pretrained ViT-B and the ViT-B fine-tuned by VPT on Places-LT to extract features of ImageNet val set and Places-LT val set),prompt tuning 可以很好地将下游任务数据分布 (Places-LT) 和预训练数据分布 (ImageNet) 对齐,可以更好地让预训练模型 adapt 到长尾任务的 target domain (from domain adaptation perspective)
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第3张图片](http://img.e-com-net.com/image/info8/e88615374dd4441da7d26eabd9195db1.jpg)
- 作者计算了 ViT-B 和 VPT 输出特征的平均类内距离、平均类间距离以及两者之商 γ \gamma γ,可以看到,VPT 的平均类内距离和 γ \gamma γ 都更小,KNN 分类准确率更高,说明 VPT 输出的特征更具有区分度
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第4张图片](http://img.e-com-net.com/image/info8/eaab7b7c46c548f0a6df81905ef662f2.jpg)
Long-tailed Prompt Tuning (LPT)
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第5张图片](http://img.e-com-net.com/image/info8/e4d09bfa8ef94e6ba02ee42eeba60389.jpg)
Phase 1: Shared Prompt Tuning
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第6张图片](http://img.e-com-net.com/image/info8/b9bc3c810980439a8fa4b32918672aa2.jpg)
- 类似于 VPT-Deep,给 ViT 的 L L L 层都各自加上额外的 prompts,因此 phase 1 需要优化 shared prompt u = [ u 1 , . . . , u L ] \mathbf u=[\mathbf u_1,...,\mathbf u_L] u=[u1,...,uL] 和 cosine classifier f f f,其中 shared prompt 用于学习所有类别的共同特征,并带来了上节讨论的 prompt tuning 的各种好处,包括 domain adaptation 和输出更具区分度的特征
- 每层里的前向过程为


 其中, c \mathbf c c 为 [CLS], z \mathbf z z 为 token embed. 新添加的 prompts 不需要计算对应的自注意力输出,只需要作为 key 和 value 与 token embed 做交互即可
其中, c \mathbf c c 为 [CLS], z \mathbf z z 为 token embed. 新添加的 prompts 不需要计算对应的自注意力输出,只需要作为 key 和 value 与 token embed 做交互即可 - 损失函数为


Phase 2: Group Prompts Tuning
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第7张图片](http://img.e-com-net.com/image/info8/c90befcad24a4132a5cd8f49c9579f45.jpg)
- 作者在 phase 2 加入了 m m m 组 group-specific prompts R = { ( k 1 , r 1 ) , . . . , ( k m , r m ) } \mathcal R=\{(\mathbf k_1,\mathbf r^1),...,(\mathbf k_m,\mathbf r^m)\} R={(k1,r1),...,(km,rm)} 用于学习 group-specific knowledge 从而增强模型的 fine-grained discriminative ability,其中 k i \mathbf k_i ki 为 i i i-th group 的 key, r i \mathbf r^i ri 为 i i i-th group 的 prompts,包含 L − K L-K L−K 个 prompt 序列 (只在后 L − K L-K L−K 层使用 group-specific prompts).
- Phase 2 包含两个步骤:(1) 冻住 shared prompts,经过 L L L 层推理得到 c L \mathbf c_L cL 作为 query q \mathbf q q 与 m m m 个 keys 计算余弦相似度,选出相似度最高的 k k k 个 groups
 然后对选出的 k k k 个 groups 的 prompts 进行 prompt ensembling
然后对选出的 k k k 个 groups 的 prompts 进行 prompt ensembling
 (2) 重新使用步骤 (1) 在前向传播中得到的 ( c K , z K ) (\mathbf c_K,\mathbf z_K) (cK,zK),在后 L − K L-K L−K 层重新进行前向传播,每层的输入包括 [CLS] embed c \mathbf c c、patch embed z \mathbf z z、shared prompt u \mathbf u u 和 group-specific prompt r \mathbf r r,每层里的前向过程为
(2) 重新使用步骤 (1) 在前向传播中得到的 ( c K , z K ) (\mathbf c_K,\mathbf z_K) (cK,zK),在后 L − K L-K L−K 层重新进行前向传播,每层的输入包括 [CLS] embed c \mathbf c c、patch embed z \mathbf z z、shared prompt u \mathbf u u 和 group-specific prompt r \mathbf r r,每层里的前向过程为


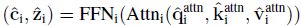
- 损失函数为

 其中, β \beta β 为 scale factor,第二项损失函数被用于增大 q \mathbf q q 和其匹配的 k k k 个 groups 的 keys 之间的余弦相似度,这是由于 Phase 1 生成的特征已经比较 compact 并且在 Phase 2 是不变的,因此该损失项可以使得 keys 靠近特征空间中的不同聚类中心,使得不同 groups 对应不同的 group-specific feature
其中, β \beta β 为 scale factor,第二项损失函数被用于增大 q \mathbf q q 和其匹配的 k k k 个 groups 的 keys 之间的余弦相似度,这是由于 Phase 1 生成的特征已经比较 compact 并且在 Phase 2 是不变的,因此该损失项可以使得 keys 靠近特征空间中的不同聚类中心,使得不同 groups 对应不同的 group-specific feature - Dual Sampling. class-balanced sampling 和 instance-balanced sampling 分别容易使得模型对尾部和头部类别过拟合,作者采用 Dual Sampling,从 instance-balanced sampler 和 class-balanced sampler 分别采样一个 mini-batch { I } ins \{\mathbf I\}_{\text{ins}} {I}ins 和 { I } bal \{\mathbf I\}_{\text{bal}} {I}bal. { I } bal \{\mathbf I\}_{\text{bal}} {I}bal 的损失函数对应 β = 1 \beta=1 β=1 时的 L P 2 \mathcal L_{\mathbf P_2} LP2, { I } ins \{\mathbf I\}_{\text{ins}} {I}ins 的损失函数对应 β = η ( E − e ) / E \beta=\eta(E-e)/E β=η(E−e)/E 时的 L P 2 \mathcal L_{\mathbf P_2} LP2,其中 η = 0.5 \eta=0.5 η=0.5 为 initialized weight, E E E 为总的训练 epoch 数, e e e 为当前 epoch 数
Loss Function
- phase 1/2 中使用的 L cls \mathcal L_{\text{cls}} Lcls 采用 asymmetric GCL loss L A-GCL \mathcal L_{\text{A-GCL}} LA-GCL.
- 首先根据 GCL 对 logits s ^ \hat {\mathbf s} s^ 进行加上 bias 和 rescale
 其中, α \alpha α 为 scaling factor, ϵ \epsilon ϵ 为从高斯分布中采样的随机变量 ( ∥ ϵ ∥ \|\epsilon\| ∥ϵ∥ 为取绝对值), n i n_i ni 为训练集中类别 i i i 的样本数, n m a x n_{max} nmax 为训练集中的最大类别样本数. 对应的 per-class probability 为
其中, α \alpha α 为 scaling factor, ϵ \epsilon ϵ 为从高斯分布中采样的随机变量 ( ∥ ϵ ∥ \|\epsilon\| ∥ϵ∥ 为取绝对值), n i n_i ni 为训练集中类别 i i i 的样本数, n m a x n_{max} nmax 为训练集中的最大类别样本数. 对应的 per-class probability 为

- 然后根据 ASL 进行 Asymmetric Focusing
L A − G C L = − y j ( 1 − p j ) λ + log ( p j ) − ∑ 1 ≤ i ≤ C , i ≠ j y i ( p i ) λ − log ( p i ) \mathcal{L}_{\mathrm{A}-\mathrm{GCL}}=-\mathbf y_{\mathrm j}\left(1-\mathbf{p}_{\mathrm{j}}\right)^{\lambda_{+}} \log \left(\mathbf{p}_{\mathrm{j}}\right)-\sum_{1 \leq \mathrm{i} \leq \mathrm{C}, \mathrm{i} \neq \mathrm{j}}\mathbf y_{\mathrm i}\left(\mathbf{p}_{\mathrm{i}}\right)^{\lambda_{-}} \log \left(\mathbf{p}_{\mathrm{i}}\right) LA−GCL=−yj(1−pj)λ+log(pj)−1≤i≤C,i=j∑yi(pi)λ−log(pi)其中, j j j 为输入样本的标签类别, λ + = 0 , λ − = 4 λ_+=0,λ_−=4 λ+=0,λ−=4 为 focusing parameter, y \mathbf y y 为 label smoothing 后的类别标签向量,即 y j = 0.9 + 0.1 / C , y i = 0.1 / C \mathbf y_{\mathrm j}=0.9+0.1/C,\mathbf y_{\mathrm i}=0.1/C yj=0.9+0.1/C,yi=0.1/C (疑问:ASL 本来是 BCE 上用的,但这里是 CE + label smoothing 之后再加上 ASL 的动态加权, ( 1 − p j ) λ + \left(1-\mathbf{p}_{\mathrm{j}}\right)^{\lambda_{+}} (1−pj)λ+ 的意义和 ASL 一样,都是筛选出难样本,但感觉 ( p i ) λ − \left(\mathbf{p}_{\mathrm{i}}\right)^{\lambda_{-}} (pi)λ− 的意义已经和 ASL 完全不同了,可以等进一步理解 label smoothing 为什么有用之后再来看)
Experiments
- Model. ViT-B/16 with ImageNet-21k pretrained model.
- Shared Prompt. default length of prompt as 10.
- Group-specific Prompts. shared layer number K = 6 K = 6 K=6 and the size of prompt size m = 20 m = 20 m=20; for each prompt in the set, the prompt length is also set as 10 (Note that setting K = 6 K = 6 K=6 may lead to 1.5x inference cost compared to VPT). prompt ensemble number k = 2 k = 2 k=2.
Comparison with State-of-The-Art Methods
- Comparison on Places-LT.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第8张图片](http://img.e-com-net.com/image/info8/cd029d0a649344aab976b76145864a1f.jpg)
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第9张图片](http://img.e-com-net.com/image/info8/6b0b59dd0ccf4f9d80fb24cf69f3816a.jpg)
- Comparison on CIFAR100-LT.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第10张图片](http://img.e-com-net.com/image/info8/a068199bb8be4f3ebbddeda9b875ffbd.jpg)
- Comparison on iNaturalist 2018.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第11张图片](http://img.e-com-net.com/image/info8/a5fc90feaad54f0584555f8c88fde0dd.jpg)
Robustness with Domain Shift
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第12张图片](http://img.e-com-net.com/image/info8/b50c9d39c4f74421a5f1c8dd72345c44.jpg)
Ablation Study
-
Different Model Size and Pretrained Models.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第13张图片](http://img.e-com-net.com/image/info8/84d728d10c04478ca4b1f38a24f7268f.jpg)
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第14张图片](http://img.e-com-net.com/image/info8/357d3be5adc4493bbc8c18e1b6a2d398.jpg)
-
Effect of Each Phase.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第15张图片](http://img.e-com-net.com/image/info8/5365498d414345f48b926226d824c379.jpg)
-
Decoupled Training. during joint training, the shared prompt is still updated simultaneously, thus the query function is sub-optimal during training, resulting in worse matching results.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第16张图片](http://img.e-com-net.com/image/info8/91c227b1deab403cacd5249774695b62.jpg)
-
Query Function and Group Size m m m.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第17张图片](http://img.e-com-net.com/image/info8/a69e06d1ca8c46a0b69d56b09083e174.jpg) when we further increase the size to 40, the final accuracy declines to 49.87%. A possible reason is that, some classes in the dataset may share some similar group-specific feature or knowledge
when we further increase the size to 40, the final accuracy declines to 49.87%. A possible reason is that, some classes in the dataset may share some similar group-specific feature or knowledge![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第18张图片](http://img.e-com-net.com/image/info8/2570ce64c54a429085bb8cf5442652f7.jpg)
-
Effect of K K K. K K K 过大会导致无法学得有效的 group-specific knowledge,过小会导致 Phase 2 匹配 groups 时无法充分利用 Phase 1 得到的 adapted feature representation
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第19张图片](http://img.e-com-net.com/image/info8/916c482721b1413eb6cc3be8184ff167.jpg)
-
Effect of Ensemble Number k k k.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第20张图片](http://img.e-com-net.com/image/info8/a20dd4b72fe844f79f8483f2c8727a1b.jpg)
-
Effect of Asymmetric GCL Loss.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第21张图片](http://img.e-com-net.com/image/info8/0a50d03cb2d5490ebc27e431e26902fb.jpg)
-
Statistic of Prompt Matching.
![[ICLR 2023] LPT: Long-tailed Prompt Tuning for Image Classification_第22张图片](http://img.e-com-net.com/image/info8/e5a923eda0f3459cbf5b8d46f071bd5d.jpg)
References
- Dong, Bowen, et al. “LPT: Long-tailed Prompt Tuning for Image Classification.” (ICLR 2023).
- code: https://github.com/DongSky/LPT