k8s 读书笔记 - 深入掌握 Pod 扩缩容

Pod 扩缩容的应用场景
在实际生产环境中通常会遇到某个服务需要扩缩容的场景:
- 某个
Service服务 资源紧张,需要对其进行扩容。比如服务请求的负载突然增加,原本一个 Pod 副本开始吃不消,此时需要多扩展几个 Pod 副本来分担突发的负载。 - 某个
Service服务 工作负载降低,需要减少服务实例数量。比如服务请求的负载高峰期过后,为了降低没必要的资源开销,此时就可以满足当前服务需求的资源前提下,对该服务的副本资源进行收缩。
对于上面这些场景,可利用 k8s 的 Deployment/RS 的 Scale 机制来实现服务的扩缩容工作。
Pod 扩缩容操作方式
k8s 实现 Pod 的扩缩容操作提供了两种方式:
- 手动模式,通过命令行
kubectl scale或者通过编程方式调用RESTful API操作Deployment/RS进行 Pod 副本数量的设置,还可编辑对应的YAML文件直接修改spec.replicas参数设置。 - 自动模式,需要依据某个性能指标或者自定义业务指标,并指定 Pod 副本数量的范围,系统将自动在该 Pod 的副本范围内依据相关性能指标的变化动态调整。
Pod 手动扩缩容机制
下面是一个 Deployment 示例。其中创建了一个 ReplicaSet,负责启动三个 nginx Pod, nginx-deployment.yaml 文件定义示例如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
# 设置 Pod 副本数量
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
创建 Deployment 对象:
kubectl create -f nginx-deployment.yaml
查看 Deployment 是否创建:
kubectl get deployments
相关 Deployment 的 创建过程 及 上线状态 这里不再详述,当前 Deployment 对象 Pod 的副本资源数量是 3 ,我们将其副本数调整为 5 ,命令行操作方式如下:
kubectl scale deployment nginx-deployment --replicas=5
或者直接修改上面的 nginx-deployment.yaml 文件中 spec.replicas 参数设置,然后执行如下命令:
kubectl apply -f nginx-deployment.yaml
说明:参数 --replicas 设置为比当前数量大,Pod 副本数就会进行扩容;反之比当前数量小,系统将会 “杀死/kill” 一些运行中的 Pod,实现集群应用的缩容。
关于 Deployment 更多信息,请查看:https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/deployment/
Pod 自动扩缩容机制
在 k8s 中从 v1.1 版本新增了一个重量级特性 —— HPA(HorizontalPodAutoscaler) 的控制器,即 Pod 水平扩缩容。
HPA 工作原理
HPA 控制器基于 Master 的 kube-controller-manager 服务启动参数 --horizontal-pod-autoscaler-sync-period 定义探测周期(默认 15s),周期性的监测目标 Pod 的资源性能指标,获取监视指标后将与 HPA 资源对象中的扩缩容条件进行对比,当满足条件时对 Pod 副本数量进行调整。
HPA 控制器依据 Metrics Server 获取资源性能监控指标调整工作负载副本和资源。
Metrics API 提供了一组基本的指标,以支持自动伸缩和类似的用例。 该 API 提供有关节点和 Pod 的资源使用情况的信息, 包括 CPU 和 Memory/内存 的指标。如果将 Metrics API 部署到集群中, 那么 Kubernetes API 的客户端就可以查询这些信息,并且可以使用 Kubernetes 的访问控制机制来管理权限。
除了 HPA 之外,VerticalPodAutoscaler (VPA) 也使用 metrics API 中的数据调整工作负载副本和资源,以满足实际需求。
关于 VPA 更多信息,请查看:https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler#readme
通过 kubectl top 命令来查看资源指标,其架构图如下所示:
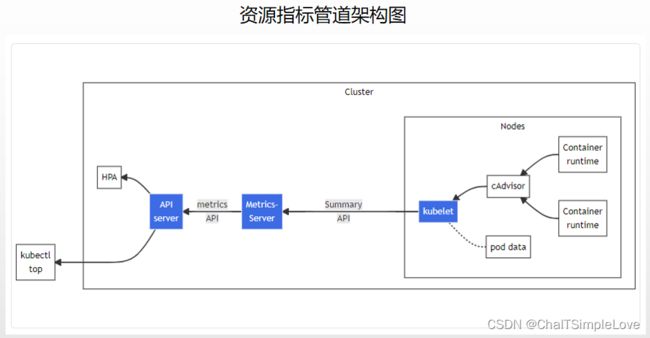
图中从右到左的架构组件包括以下内容:
cAdvisor:用于收集、聚合和公开kubelet中包含的容器指标的守护程序。kubelet:用于管理容器资源的节点代理。 可以使用/metrics/resource和/stats kubelet API端点访问资源指标。Summary API:kubelet提供的 API,用于发现和检索可通过/stats端点获得的每个节点的汇总统计信息。metrics-server:集群插件组件,用于收集和聚合从每个kubelet中提取的资源指标。 API 服务器提供Metrics API以供HPA、VPA和kubectl top命令使用。Metrics Server是Metrics API的参考实现。Metrics API:Kubernetes API 支持访问用于工作负载自动缩放的CPU和Memory/内存。 要在你的集群中进行这项工作,你需要一个提供Metrics API的 API 扩展服务器。
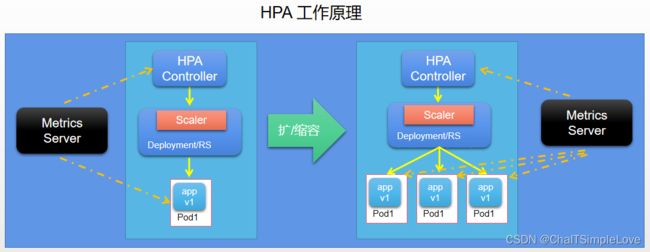
metrics-server实现了Metrics API。该 API 允许你访问集群中 Node 节点和 Pod 的 CPU 和 Memory/内存使用情况。metrics-server的主要作用是 将资源使用指标提供给 K8s 自动缩放器(Scale)组件。
关于 Metrics API 的更多信息,请查看:https://kubernetes.io/zh-cn/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/#the-metrics-api
工作量规模的稳定性
在使用 HPA 管理一组副本的规模时,由于评估的指标的动态特性, 副本的数量可能会经常波动。这有时被称为 抖动(thrashing) 或 波动(flapping)。它类似于控制论中的 滞后(hysteresis) 概念。
指标类型
Master 的 kube-controller-manager 服务持续监测目标 Pod 的某些性能指标,和当前工作负载对比,计算是否需要调整副本数量。目前 k8s 支持的指标类型如下:
- Pod 资源使用率:Pod 级别的性能指标,通常是一个比率值,例如
CPU使用率,Memory/内存使用量。 - Pod 自定义指标:Pod 级别的性能指标,通常是一个数值,例如接收的
Request Per Second(简称RPS,每秒请求数量)。 - Object 自定义或外部自定义指标:通常是一个数值,需要容器应用以某种方式提供,例如通过
HTTP URL /metrics提供,或者使用外部服务提供的指标采集URL
Metrics Server 将采集到的 Pod 性能指标数据通过 Aggregated API(聚合 API ,例如: metrics.k8s.io、custom.metrics.k8s.io、external.metrics.k8s.io)提供给 HPA 控制器进行查询。
关于 Aggregated API(聚合 API )和 API Aggregator (API 聚合器)更多信息请查看:
- Kubernetes API 聚合层,https://kubernetes.io/zh-cn/docs/concepts/extend-kubernetes/api-extension/apiserver-aggregation/
- 扩展 Kubernetes / 配置聚合层,https://kubernetes.io/zh-cn/docs/tasks/extend-kubernetes/configure-aggregation-layer/
K8s 中组件的指标示例
通过系统组件指标可以更好地了解系统组件内部发生的情况。系统组件指标对于构建 仪表板 和 告警 特别有用。
Kubernetes 组件以 Prometheus 格式 生成度量值。 这种格式是结构化的纯文本,旨在使人和机器都可以阅读。
kube-controller-manager,https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kube-controller-manager/kube-proxy,https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kube-proxy/kube-apiserver,https://kubernetes.io/zh-cn/docs/concepts/overview/components/#kube-apiserverkube-scheduler,https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kube-scheduler/kubelet,https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kubelet/
关于 k8s 系统组件指标的更多信息,请查看:
- 集群管理 / Kubernetes 系统组件指标,https://kubernetes.io/zh-cn/docs/concepts/cluster-administration/system-metrics/
- Prometheus 格式,https://prometheus.io/docs/instrumenting/exposition_formats/
扩缩容算法详解
Autoscaler 控制器从 Aggregated API(聚合 API)获取到 Pod 性能指标数据之后,基于下面的算法计算出目标 Pod 副本数量,与当前运行的 Pod 副本数量进行对比,决定是否需要进行扩缩容操作。
算法计算公式:
desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMericValue)]
即:期望 Pod 副本数为【当前 Pod 副本数 × (当前指标值 / 期望指标值)】的结果再 ceil 向上取整。
以 CPU 的请求数量为例,如果当前指标值为 200m,而期望值为 100m,则副本数将加倍, 因为 200.0 / 100.0== 2.0 如果当前值为 50m,则副本数将减半, 因为 50.0 / 100.0 == 0.5。如果比率足够接近 1.0(在全局可配置的容差范围内,默认为 0.1), 则控制平面会跳过扩缩操作。
当计算结果与1非常接近时,可以设置一个容忍度让系统不做扩缩容操作。容忍度通过 kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-tolerance 进行设置,默认值为 0.1(即10%),表示基于上述算法得到的结果在[-10%-+10%]区间内,即 [0.9-1.1],控制器都不会进行扩缩容操作。
也可以将 期望指标值 (desiredMetricValue) 设置为指标的平均值类型,例如 targetAverageValue 或targetAverageUtilization,此时 当前指标值 (currentMetricValue)的算法为所有 Pod 副本当前指标值的总和除以 Pod 副本数量得到的平均值。
当前指标值(currentMetricValue) = 所有 Pod 副本当前指标值的总 / Pod 副本数量,即平均值。
特别说明:在计算
“当前指标值/期望的指标值”(currentMetricValue / desiredMetric Value)时将不会包括几种 Pod 异常的情况,如下所述。
几种 Pod 异常的情况:
- Pod 正在被删除(设置了删除时间戳):将不会计入目标 Pod 副本数量。
- Pod 的当前指标值无法获得:本次探测不会将这个 Pod 纳入目标 Pod 副本数量,后续的探测会被重新纳入计算范围。
- 如果指标类型是 CPU 使用率,则对于正在启动但是还未达到 Ready(就绪)状态的 Pod。也暂时不会纳入目标副本数量范围。
可以通过 kube-controller-manager 服务的启动参数进行设置:
- 启动参数
--horizontal-pod-autoscaler-initial-readiness-delay设置首次探测 Pod 是否Ready的延时时间,默认值为30s。 - 另一个启动参数
--horizontal-pod-autoscaler-cpu-initialization-period设置首次采集 Pod 的CPU使用率的延时时间。
当存在缺失指标的 Pod 时,系统将更保守的重新计算平均值。系统会假设这些 Pod 在需要缩容(Scale Down)时消耗了期望值指标的 100%,在需要扩容(Scale UP)时消耗了期望值的 0%,这样可以抑制的扩容操作。
另外,如果存在末达到 Ready 状态的 Pod ,并且系统原本在不考虑缺失指标或 NotReady 的 Pod 情况下进行扩展,则系统仍然会保寸地假设这些 Pod 消耗期望指标值的 0%,从而进一步抑制扩容操作。
如果在 HPA 中设置了多个指标,系统就会对每个指标都执行上面的算法,在全部结果中以期望副本数的最大值为最终结果。如果这些指标中的任意一个都无法转换为期望的副本数(例如无法获取指标的值),系统就会跳过扩缩容操作。
最后,在 HPA 控制器执行扩/缩容操作之前,系统会记录扩缩容建议信息(Scale Recommendation)。控制器会在操作时间窗口(时间范围可以配置)中考虑所有的建议信息,并从中选择得分最高的建议。这个值可通过 kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-downscale-stabilization-window 进行配置,默认值为 5min。这个配置可以 让系统更为平滑地进行缩容操作,从而消除短时间内指标值快速波动产生的影响。
HPA 配置详解
HorizontalPodAutoscaler (简称 HPA) 是 Kubernetes autoscaling API 组中的 API 资源。 当前的稳定版本可以在 autoscaling/v2 API 版本中找到,其中包括对基于 Memory/内存 和 Custom Metrics(自定义指标)执行扩缩的支持。 在使用 autoscaling/v1 时,autoscaling/v2 中引入的新字段作为注释保留。
API 对象
查看 HPA 版本信息
$ kubectl api-versions | grep autoscal
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
autoscaling/v2
| APA 版本 | 描述 |
|---|---|
| autoscaling/v1 | 只支持基于 CPU 指标(CPU 使用率)的缩放。 |
| autoscaling/v2beta1 | 支持 Resource Metrics(资源指标,如 pod 的 CPU)和 Custom Metrics(自定义指标)的缩放。 |
| autoscaling/v2beta2 | 支持 Resource Metrics(资源指标,如 pod 的 CPU)和 Custom Metrics(自定义指标)和 ExternalMetrics(外部指标)的缩放。 |
| autoscaling/v2 | 基本同上,稳定优化 |
HorizontalPodAutoscaler v2 autoscaling
- 参考文档:https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.25/#horizontalpodautoscaler-v2-autoscaling
| apiGroup | Version | Kind |
|---|---|---|
| autoscaling | v2 | HorizontalPodAutoscaler |
-
HorizontalPodAutoscaler is the configuration for a horizontal pod autoscaler, which automatically manages the replica count of any resource implementing the scale subresource based on the metrics specified.
-
译文:HorizontalPodAutoscaler 是水平 Pod 自动缩放器的配置,它根据指定的指标自动管理实现缩放子资源的任何资源的副本计数。
| 字段 | 描述说明 |
|---|---|
apiVersion string |
apiVersion 定义该对象当前的版本化架构。 服务器应将已识别的架构转换为最新的内部值,并可能拒绝无法识别的值。 更多信息:https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
kind string |
kind 是一个字符串值,表示该对象的 REST 资源类型。 服务器可以从客户端向其提交请求的端点推断这一点。无法更新。在 CamelCase。 更多信息:https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
metadata ObjectMeta |
metadata 元数据是标准的对象元数据。 更多信息:https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
spec HorizontalPodAutoscalerSpec |
spec 是自动定标器行为的规范。 更多信息:https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status |
status HorizontalPodAutoscalerStatus |
status 状态是有关自动缩放器的当前信息。 |
创建 HPA 对象时,需要确保所给的名称是一个 合法 的 DNS 子域名:
- 不能超过 253 个字符。
- 只能包含小写字母、数字,以及 ‘-’ 和 ‘.’。
- 必须以字母数字开头。
- 必须以字母数字结尾。
kubectl 对 HPA 的支持
与其他 API 资源类似,kubectl 以标准方式支持 HPA。
- 通过
kubectl create命令创建一个 HPA 对象。 - 通过
kubectl get hpa命令来获取所有 HPA 对象。 - 通过
kubectl describe hpa命令来查看 HPA 对象的详细信息。 - 通过
kubectl delete hpa命令删除对象。
此外,还有个简便的命令 kubectl autoscale 来创建 HPA 对象。
举例,为名为 foo 的 ReplicationSet 创建一个 HPA 对象, 目标 CPU 使用率为 80%,副本数量配置为 2 到 5 之间。命令操作如下:
kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80
HPA 定义示例说明
以 Deployment 为例,HPA 的定义文件 aspnetcore-nginx-hpa.yaml 如下:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: aspnetcore-nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: aspnetcore-nginx
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second # 指标名称
target:
type: AverageValue
averageValue: 1k # 在目标指标平均值为 1000 时触发扩缩容操作
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
status:
observedGeneration: 1
lastScaleTime: -time>
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
current:
value: 10k
上面的 aspnetcore-nginx-hpa.yaml 文件中主要参数说明:
scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController/RC或ReplicaSet/RS。minReplicas & manReplicas:Pod 副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个 Pod 的 CPU 使用率为 50%。metrics:目标指标值,在metrics中通过参数type定义指标的类型;通过target定义相应的目标指标值,系统将在指标数据达到目标值时(考虑 容忍度 的区间,详见上面【扩缩容算法详解】说明)触发扩缩容操作。
其中 metrics 的参数 type (指标类型)可以设置为以下三种,可以设置一个或多个组合(上面示例就是多个组合),指标类型设置如下:
Resource:基于资源的指标值,可以设置的资源为CPU和Memory/内存。Pods:基于 Pod 的指标,系统将对全部 Pod 副本的指标值进行平均值计算。Object:基于某种资源对象(如Ingress)的指标或应用系统的任意自定义指标。
Resource 类型的指标可以设置 CPU 和 Memory/内存:
- CPU 使用率
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- Memory/内存资源
metrics:
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 200Mi
Pods 类型和 Object 类型都属于 自定义指标类型,指标的数据通常需要搭建自定义 Metrics Server 和 监控工具进行采集和处理。指标数据可以通过 API custom.metrics.k8s.io 进行查询,要求预先启动 Metrics Server 服务。
Pods 类型的指标数据来源于 Pod 对象本身,其 target 指标类型只能使用 AverageValue,如上所示。
Object 类型的指标数据来源于其他资源对象或任意自定义指标,其 target 指标类型可以使用 Value 或 AverageValue(根据 Pod 副本数计算平均值)进行设置。
几种常见的自定义指标示例和说明
下面是几种常见的自定义指标示例和说明:
- 【示例1】 设置指标的名称为
requests-per-second,该值来源于 Ingressmain-route,将目标值(value)设置为 2000,即在 Ingress 的每秒请求数量达到 2000 个时触发扩缩容操作。
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
- 【示例2】 设置指标的名称为
http_requests,并且该资源对象具有标签"verb=GET",在 http 请求指标平均值达到 500 个时触发扩缩容操作。
metrics:
- type: Object
object:
metric:
name: http_requests
selector: "verb=GET"
target:
type: AverageValue
value: 500
说明:当 HPA 资源对象中定义了多个类型的指标,系统将针对每种类型的指标都计算 Pod 副本的目标数量,以最大值为准进行扩缩容操作。
k8s 从 v1.10 版本开始,引入了对外部系统指标的支持。例如,用户使用了公有云服务商提供的消息服务或外部负载均衡器,希望基于这些外部服务的性能指标(如 消息服务的队列长度、负载均衡器的QPS)对自己部署在 Kubernetes 中的服务进行自动扩缩容操作。这时,就可以在 metrics 参数部分设置 type 为 External 来设置自定义指标,然后就可以通过 APl “external.metrics.k8s.io” 查询指标数据了。前提条件,要求自定义 Metrics Server 服务已正常工作。
- 【示例3】 设置指标的名称为
queue_messages_ready,具有queue=worker_tasks标签在目标指标平均值为 30 时触发自动扩缩容操作:
metrics:
- type: External
external:
metric:
name: queue_messages_ready
selector: "queue=worker_tasks"
target:
type: AverageValue
averageValue: 30
注意:在使用外部服务的指标时,要安装、部署能够对接到 k8s HPA 模型的监控系统,并且完全了解监控系统采集这些指标的机制,后续的自动扩缩容操作才能完成。
k8s 推荐 尽量使用 type 为 Object 的 HPA 配置方式,这可以通过使用 Operator 模式,将外部指标通过CRD(自定义资源)定义为 API 资源对象来实现。

总结
谷歌对 k8s 的定位是能够 “智能化、自动化” 的对资源编排管理,其中 Pod 的扩缩容操作就是很好的体现,对于手动扩缩容的方式是达不到谷歌对 k8s 的定位的,而 Pod 的自动扩缩容机制就是为了达到这一目标而提出的方案。
参考文档:
- Pod 水平自动扩缩,https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
- HorizontalPodAutoscaler 演练,https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
- 监控、日志和调试 / 集群故障排查 / 资源指标管道,https://kubernetes.io/zh-cn/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/#the-metrics-api