【论文阅读】让数据库听懂人话(Text-to-SQL)
论文标题: 在跨领域数据库中引入中间表示来实现复杂Text2SQL
英文标题: Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation
论文下载链接: https://arxiv.org/abs/1905.08205
论文项目代码: GitHub@IRNet
序言
Text-to-SQL任务旨在直接通过口述的查询问题, 直接从数据库中执行对应的SQL语句得出结果, 是常见的对话系统, 问答系统设计中常常会运用到的方法; 然而本文作为目前最先进的方法, 仍然无法取得良好的结果, 事实上目前大部分的Text-to-SQL模型依然只能处理相对简单的SQL查询, 而一旦问题涉及复杂的嵌套查询, 目前还没有很好的解决方案, 从本文3.4节误差分析中可以看到, 高难度的嵌套查询的准确率是非常低的, 而且引入BERT增强也提升效果不显著, 这应该算是Text-to-SQL中值得攻克的一个难点。
关于项目代码,其预训练模型和数据都在googledrive上需要下载,没有数据可能还是很影响代码阅读的。
目录
- 序言
- 摘要
- 1 引入 Introduction
- 2 方法 Approach
-
- 2.1 中间表示 Intermediate Representation
- 2.2 结构链接 Schema Linking
- 2.3 模型 Model
- 3 实验 Experiment
-
- 3.1 实验配置 Experiment Setup
- 3.2 实验结果 Experimental Results
- 3.3 消融研究 Ablation Study
- 3.4 误差分析 Error Analysis
- 4 讨论 Discussion
- 5 相关工作 Related Work
- 6 结论 Conclusion
- 致谢 Acknowledgments
- 参考文献
- 附录: 7 补充材料 Supplemental Material
-
- 7.1 SemQL查询示例 Examples of SemQL Query
- 7.2 SQL查询接口 Inference of SQL Query
- 7.3 将SQL转为SemQL Transforming SQL to SemQL
- 7.4 粗颗粒度到细颗粒度的框架 Coarse-to-Fine Framework
- 7.5 BERT
- 7.6 开发集与测试集模型评估差距的分析 Analysis on the Performance Gap between the Development set and the Test set
- 附录: 图表汇总
摘要
本文提出一种名为IRNet的神经方法解决复杂的, 跨领域的(cross-domain) Text-to-SQL任务;
- IRNet旨在解决两个难题:
- ① 自然语言(Natural Language, 下简称为NL)中表达的意图与SQL实现细节上的不匹配;
- ② NLP中出现的大量领域外(out-of-domain)的单词导致难以预测所指向的数据库中表的字段;
- IRNet的创新点:
- 不同于使用端对端(end-to-end)的方法来合成(synthesize)一次结构化查询语言(Structural Query Language, 下简称为SQL)查询语句, IRNet将合成(synthesis)分解为三个阶段:
- ① 首先, IRNet在给定的问题和数据库结构(schema)执行一次结构链接(schema linking);
- ② 其次, IRNet采用一个基于语法的神经模型来合成SemQL查询;
- SemQL查询是一种设计来用于联系NL与SQL的中间表示(intermediate representation, 下简称为IR);
- ③ 最后, IRNet根据第②步中得到的SemQL生成最终的SQL查询语句;
- IRNet表现:
- 精确度: 46.7 46.7% 46.7(比目前最先进模型的精确度提升了 19.5 19.5 19.5个百分点);
- 截至本文发布IRNet的评分位于Spider leaderboard排行榜的榜首;
1 引入 Introduction
-
问题的定义: Text-to-SQL是通过一个问题来合成对应的SQL查询语句的自然语言处理(Natural Language Processing, 下简称为NLP)任务;
-
问题的挑战:
- 目前传统的端对端(end-to-end)神经网络方法可以在公开的Text-to-SQL数据集(ATIS, GeoQuery, WikiSQL)上取得超过 80 80% 80的精确度(参考文献[9, 19, 26, 42, 46, 47, 52, 56]);
- 但是有论文(参考文献[54])发现这些先进的模型在最新发布的跨领域的Text-to-SQL数据集Spider上的表现非常糟糕; 原因如下:
- ① Spider数据集中存在嵌套查询, 如包含GROUPBY和HAVING的从句, 比同跨领域的Text-to-SQL数据集WiKiSQL要复杂得多(参考文献[56]);

- 笔者注: 下面是Figure 1中地SQL查询语句, 查询意义是找到成绩高于5且有至少2个朋友的学生的名字;
SELECT T1.name FROM friend AS T1 JOIN highschooler AS T2 ON T1.student_id = T2.id WHERE T2.grade > 5 GROUP BY T1.student_id HAVING count(*) >= 2 - 以Figure 1中的示例而言, SQL语句中的
student_id字段并没有在NL中被提到过; - 原因在于NL只是在陈述查询问题, 而不会包含查询问题的具体查询实现方法, 这就给现有的Text-to-SQL传统方法带来了信息缺失的挑战, 即仅根据NL提供的上下文信息是不足以完成查询任务的;
- 这种挑战的本质(in essence)源于SQL是设计在关系型数据库中进行高效查询的语言, 而非与NL类似的表义语言(参考文献[22]), 因此NL所陈述的意图与SQL所表示的实现细节就会发生不匹配; 这种挑战本文称之为错误匹配问题(mismatch problem);
- 笔者注: 下面是Figure 1中地SQL查询语句, 查询意义是找到成绩高于5且有至少2个朋友的学生的名字;
- ② Spider数据集中存在大量领域外的(out-of-domain, 下简称为OOD)单词;
- 开发集(development set)中有 35 35% 35的单词没有在训练集中出现过; 这个比例在WikiSQL数据中只有 22 22% 22;
- 大量的OOD单词带来的直接挑战就是无法正确预测到NL中真实指向的数据库字段(参考文献[53]), 因为OOD单词在神经模型中通常缺少精确的表示(representation); 这种挑战本文称之为词汇问题(lexical problem);
- ① Spider数据集中存在嵌套查询, 如包含GROUPBY和HAVING的从句, 比同跨领域的Text-to-SQL数据集WiKiSQL要复杂得多(参考文献[56]);
- 本文的解决方案:
- 本文提出一种用于解决上文中提到的错误匹配问题和词汇问题的神经方法: IRNet;
- IRNet的两个关键创新点: 使用了中间表示(intermediate representation, 下简称为IR)与结构链接(schema linking); 具体而言, IRNet讲SQL语句合成过程分解为三个阶段(phases):
-
① 第一阶段: 在NL问题与数据库表的结构(schema)上进行执行结构链接(schema linking);
- 目的是识别出问题中提到的字段名和表名, 并且基于字段是如何在NL中被提及的给表中的字段赋予不同的类别标签;
- 笔者注: 所谓字段是如何在NL中被提及的, 笔者理解为字段是以何种词性出现的(如常见的名词, 或是以动词方式间接表示出的), 或者是以何种语法成分出现(如主语或宾语);
- 进行结构链接可以增强NL问题和数据库表结构的表示(representation)
- 目的是识别出问题中提到的字段名和表名, 并且基于字段是如何在NL中被提及的给表中的字段赋予不同的类别标签;
-
② 第二阶段: IRNet采用一个基于语法的神经模型(grammar-based neural model)来合成SemQL查询, 即本文设计来用于桥接NL与SQL的IR;
-
③ 第三阶段: IRNet利用领域知识(domain knowledge)最终根据合成的SemQL查询推断出一个SQL查询;
-
- IRNet利用IR来建模的思路来自于以下一些前人的研究:
- lambda caculus: 参考文献[7];
- FunQL: 参考文献[23];
- DCS: 参考文献[30];
- 各种语义解析任务(semantic parsing tasks): 参考文献[5, 31, 41, 55];
- 前人在设计IR用于从数据库结构(data schema)和数据库管理系统(database management system)分隔(decouple)NL的语义表示(meaning representations): 参考文献[1, 2, 45];
- 笔者注: 这三篇文献都是相当古老的研究了;
- 本文的成果:
- 在Spider数据集上比基线(参考文献[54])提升了 19.5 19.5 19.5个百分点, 达到了 46.7 46.7% 46.7的精确性;
- 截至本文发布, IRNet的模型评估结果位于Spider排行榜榜首;
- 通过增加BERT模型, IRNet的模型评估结果可以提升到 54.7 54.7% 54.7的精确性;
- 此外, 本文实验证明, 通过学习合成SemQL查询而非直接合成SQL查询可以大大提升(substantially benefit)其他Text-to-SQL的神经方法, 如SQLNet(参考文献[46]), TypeSQL(参考文献[52]), SyntaxSQLNet(参考文献[53]); 这意味着建立IR是有效的, 并且是一个用于处理复杂跨领域Text-to-SQL任务的具有研究前景的方向;
2 方法 Approach
本节主要详细介绍IRNet的方法, 就如何解决错误匹配问题(mismatch problem)和词汇问题(lexical problem)以及如何使用神经模型合成SemQL查询;
2.1 中间表示 Intermediate Representation
- 定义: SemQL即所谓用于桥接SQL与NL的IR, 是提出用于消除错误匹配问题;
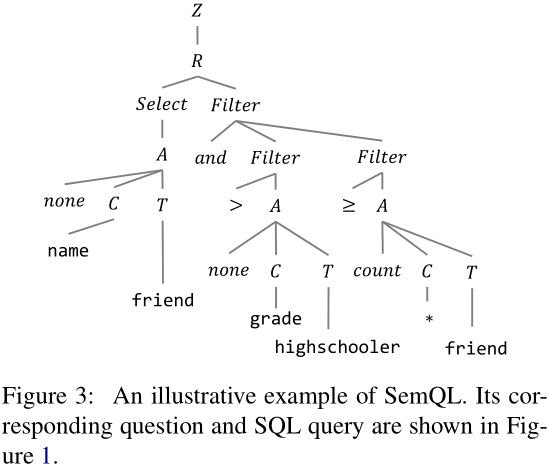
- Figure 2中展示了SemQL与上下文无关的语法(context-free grammar), Figure 3则是对Figure 1中的SemQL语句所作的树状图解释;

-
笔者注:
SELECT T1.name FROM friend AS T1 JOIN highschooler AS T2 ON T1.student_id = T2.id WHERE T2.grade > 5 GROUP BY T1.student_id HAVING count(*) >= 2- Figure 2中所描述的语法规则:
- Z Z Z: 表示是两个查询集 R R R的集合操作(交集, 并集, 差集等)或直接保留单个查询集 R R R而不作任何操作;
- R R R: 表示查询集, 包括单纯查询字段( S e l e c t Select Select), 以及附加按照排序结果( O r d e r Order Order), 条件过滤后的结果( F i l t e r Filter Filter), 聚合结果( S u e r l a t i v e Suerlative Suerlative)后的查询集;
- S e l e c t Select Select: 若干个通过查询得到的字段;
- O r d e r Order Order: 按照字段升序( a s c asc asc)或降序排列( d e s c desc desc);
- S u e r l a t i v e Suerlative Suerlative: 对聚合函数的结果取最值( m o s t most most和 l e a s t least least);
- 这个 S u e r l a t i v e Suerlative Suerlative似乎不是很常用, 也不是很实用;
- F i l t e r Filter Filter: 若干 F i l t e r Filter Filter条件的与( a n d and and)和或( o r or or)逻辑运算的结果;
- A A A: 聚合函数如对某字段或整个数据表的取最大值( max \max max), 取最小值( min \min min), 计数值( c o u n t count count), 累和( s u m sum sum), 取平均值( a v g avg avg), 不作任何聚合操作( n o n e none none);
- C C C: 某个字段;
- T T T: 某个数据表;
- 根据Figure 2中的语法规则, 对比上面地SQL语句, Figure 3中的树状结构可以被容易的解释清楚; 自顶向下地遍历这棵SemQL树:
- 由于该SQL查询没有对多个查询集进行集合操作, 因此树根的 Z Z Z就是保留 R R R不作任何操作;
- R R R显然是一种 S e l e c t F i l t e r Select Filter SelectFilter:
- S e l e c t Select Select是从
friend表中获取name字段, 不作任何聚合函数操作( n o n e none none); - F i l t e r Filter Filter包含两个由与连接的条件:
- ① 第一个条件是关于
highschooler中的grade值需要大于某个数值; - ② 第二个条件是关于
friend中任意字段的计数值( c o u n t count count)需要不小于某个数值;
- ① 第一个条件是关于
- S e l e c t Select Select是从
- Figure 2中所描述的语法规则:
-
启发于前人研究(参考文献[23])中的lambda DCS模型, SemQL被设计成是一种树状结构, 这样有两种好处:
- ① 在合成查询SQL语句可以高效地限制搜索空间
- ② 由于SQL天生具有树状结构的特性, 这使得从SemQL转换到SQL会更加容易;
- 如何利用IR解决错误匹配问题:
- 错误匹配问题的本质是SQL查询中的实现逻辑细节(如HAVING与GROUP BY从句)未能在NL问题中具体描述出来, 所以自然地会想到在SemQL中隐藏掉实现逻辑细节;
- 从Figure 3中可以看到:
- ① SQL中的HAVING, GROUP BY, FROM从句都没有在SemQL中出现;
- ② WHERE和HAVING中包含的条件语句都统一在SemQL树状结构的Filter节点子树中表示;
- 从Figure 3中可以看到:
- 在之后结合领域知识(domain knowledge)的推断阶段(inference phase)中, SQL查询的具体实现逻辑细节可以根据SemQL的结构很快被构造出来;
- 例如出现在SQL查询GROUPBY从句中的字段往往会出现在SELECT从句中, 或者该字段本身就是某个数据表的主键, 而在SQL查询中对这个数据表中的某个非主键字段执行了聚合函数;
- 笔者注:
- 比如需要按照班级分类汇总(GROUPBY)时, 班级这个字段一般会出现在最后的查询结果中, 因为很可能是想查询关于每个班级某个统计量的结果;
- 否则班级大概率就是某个数据表的主键(其实也可以理解为是外键, 用于表的连接), 然后对另一个字段作了聚合筛选; 如Figure 1中的
GROUP BY T1.student_id HAVING count(*) >= 2,student_id就是充当highschoolers表和friend表连接时的主键和外键, 然后对另一个字段(*)做聚合(count)筛选;
- 笔者注:
- 例如出现在SQL查询GROUPBY从句中的字段往往会出现在SELECT从句中, 或者该字段本身就是某个数据表的主键, 而在SQL查询中对这个数据表中的某个非主键字段执行了聚合函数;
- SemQL推断SQL的几个必要的前提假设:
- SemQL要求必须指定字段所在的数据表名称;
- 笔者注:
- SQL中有时在SELECT从句中可以省略字段所属的数据表名称, 若该字段只在一个数据表出现过;
- 但是显然这里SemQL没有那么智能, 所以Figure 3中所有出现字段名( C C C)的地方必然紧跟着所属数据表的名称( T T T);
- 特别地, 为了便于后续从SemQL推断出SQL, 本文将
*视为一种特殊字段;
- 笔者注:
- 从SemQL推断SQL时, 要求数据表的结构(schema)必须时完整的;
- 如某个数据表中某个字段实际上是另一个数据表中主键的外键, 则必须要求建表时有声明该外键约束(foreign key constraint);
- 一般来说设计严谨的数据表都应当具备该性质; 而Spider数据集中有超过 95 95% 95的训练样本都满足该假设;
- SemQL推断SQL的流程:
- 以推断SQL的FROM从句为例, 分为两步:
- ① 首先确定SemQL中声明的所有数据表在数据库结构(schema)中的最短路径;
- 笔者注: 关系型数据库结构(schema)可以视为一张无向图, 节点为数据表, 边为联系各个表的外键字段;
- ② 然后将所有在路径(path)上的数据表表都连接(joining)起来就得到了FROM从句;
- 笔者注: 这其实很符合常识, 我们在写SQL语句时一般都会先在FROM从句中把所有要用到的数据表全都连接起来, 再在WHERE从句中作筛选操作后, 最后在SELECT取出需要的字段;
- ① 首先确定SemQL中声明的所有数据表在数据库结构(schema)中的最短路径;
- 附录: 7 补充材料 Supplemental Material中有关于从SemQL推断SQL的详细步骤以及各种举例;
2.2 结构链接 Schema Linking
- 定义:
- 所谓结构链接是为了识别出NL问题中提到的字段和数据表, 并基于这些字段是如何在NL问题中被提及, 来给这些字段附上不同的类型(types);
- 结构链接是Text-to-SQL上下文(context)中的实体链接(entity link)实例化(instantiation);
- 笔者注: 这句话似乎很难理解;
- 实体(entity)代表数据库中的, 字段(columns), 数据表(tables)以及单个数值(cell values);
- 本质就是构建抽象的SQL元素与形象的NL问题中的单词的链接;
- 笔者注: 这句话似乎很难理解;
- 结构链接的实现方法: 本文使用字符串匹配的方法来解决结构链接, 虽然很简单但是很管用;
-
① 首先定义三种可能在NL问题中被提及的实体(entities)标签: table, column, value; 并枚举出一个NL问题中所有长度不大于的6的 n n n-gram短语;
- 笔者注: 即1-gram到6-gram的单词组合全部都枚举一遍, 其实也不多, 若NL问题中一个有 t t t个单词, 穷举总共也就 6 t − 15 6t-15 6t−15个 n n n-gram短语;
-
② 如果某个 n n n-gram短语恰好匹配上了某个字段名称, 或者只是某个字段名称的子串, 那么就识别该 n n n-gram短语是一个column;
- 同理可以用相似的方法识别出某个 n n n-gram短语是一个table;
- 如果某个 n n n-gram短语同时被识别为column和table则优先认定为column;
-
③ 如果某个 n n n-gram短语以单引号(single quote)开头并以单引号(single quote)结尾, 那么识别为一个value;
-
④ 一旦某个 n n n-gram短语被指定了识别结果, 那么所有与该 n n n-gram短语字符串有重叠部分的 n n n-gram短语全部被移除, 不再被考虑;
-
⑤ 最后将所有识别出的实体序列与剩余的1-gram短语按原先NL问题中单词的顺序排列起来, 就可以得到一个互不重叠的实体序列;
- 笔者注: 这其实就是做了一个分词工作;
-
⑥ 根据⑤中得到的实体序列, 给序列中的每个 n n n-gram短语分别附上table, column, value标签, 这里本文称序列中的每个 n n n-gram短语为一个span(注意这个span在后文中会常常被提到);
- 识别结果为column的短语, 根据是否为完全匹配可以分为exact match与partial match两种类别标签;
- 关于如何链接一个value到它对应的column, 可以使用参考文献[36]中提出的ConceptNet, 这是一个开源的大型知识图谱;
- 本文只考虑ConceptNet两种返回结果: is the type of和related term, 因为一般来说column和value的关系就是这两种;
- 如果有结果精确地或部分地匹配了某个字段名称, 则本文给它赋上value exact match或value partial match的类别标签;
- 笔者注: 常见的想法是把value输入知识图谱获取返回的value上位词, 因为value和column的关系就是下位词和上位词的关系, 然后在数据库结构(schema)中搜索哪个column与返回的上位词结果最匹配即可; 当然似乎按照文中的说法ConceptNet的返回结果是很丰富的, 这是个开源的知识图谱倒是很值得去学习一下;
-
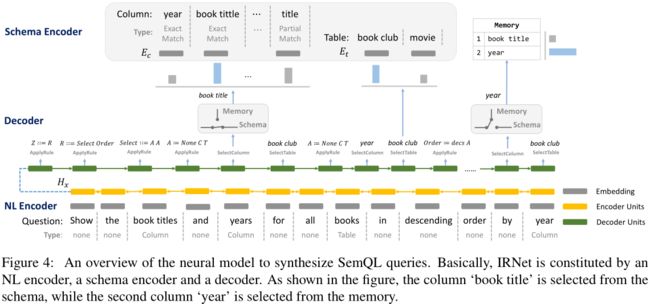
下面的Figure 4给出了详细的一个结构链接示例, 以及如何使用神经模型合成SemQL, 一些未知的模型构件可以在下一节中看到:
2.3 模型 Model
(1) 为了解决词汇问题(lexical problem), 本文在构建问题表示(representation)和数据库结构(schema)中的字段表示时考虑使用结构链接结果;
(2) 本文设计一个内存增强指向网络(memory augmented pointer network)来在合成过程(synthesis)中进行字段选择(selecting columns); 当一个字段被选到时, 该网络首先决定是否要在内存(memory)中选出, 这一点与vanilla pointer network(参考文献[40])时不一样的, 这里创新的动机源于作者通过观察发现, vanilla pointer network更倾向于选择相同的字段, 所以如果先决定是否要在内存(memory)中选择, 就可以改善这种情况;
- 自然语言编码器: NL Encoder
- 令 x = [ ( x 1 , τ 1 ) , . . . , ( x L , τ L ) ] x=[(x_1, \tau_1), ..., (x_L, \tau_L)] x=[(x1,τ1),...,(xL,τL)]表示NL问题中不重叠的span序列, 其中 x i x_i xi表示第 i i i个span, τ i \tau_i τi表示 x i x_i xi在结构链接中被赋上的类别标签;
- NL Encoder网络架构:
- ① 首先NL Encoder接受输入整个 x x x, 并将其编码成一个隐层状态序列 H x \bm{H}_x Hx;
- ① 每个 x i x_i xi中的单词先转为词向量, 每个 τ i \tau_i τi也可以转为一个嵌入向量(如one-hot向量);
- ② 将每个span, 即 ( x i , τ i ) (x_i, \tau_i) (xi,τi)的向量表示全部取均值作为该span的嵌入向量 e x i \bm{e}_x^i exi;
- 笔者注: 这里似乎有些迷惑, 按照文中的说法应该是 x i x_i xi中每个单词的词向量与 τ i \tau_i τi的嵌入向量一起取均值, 可能是对 x i x_i xi中每个单词的词向量取均值然后拼接 τ i \tau_i τi的嵌入向量是比较合理的做法;
- ③ 最后NL Encoder将所有span的嵌入向量输入到一个Bi-LSTM中, Bi-LSTM中正向和反向的输出隐层状态都要和 H x \bm{H}_x Hx拼接起来(concatenate);
- 笔者注: 此处有点迷, 需要结合代码实现理解;
- 结构编码器: Schema Encoder
- 令 s = ( c , t ) s=(c, t) s=(c,t)表示一个数据库结构(schema), 其中:
- c = { ( c 1 , ϕ i ) , . . . , ( c n , ϕ n ) } c=\{(c_1, \phi_i), ..., (c_n, \phi_n)\} c={(c1,ϕi),...,(cn,ϕn)}是所有不同字段和它们在结构链接中被赋予的类别标签集合;
- t = { t i , . . . , t m } t=\{t_i, ..., t_m\} t={ti,...,tm}是数据表集合;
- Schema Encoder接受整个 s s s作为输入, 输出所有字段的表示 E c \bm{E}_c Ec和所有数据表的表示 E t \bm{E}_t Et;
- 这里以字段表示的构建为例, 数据表表示的构建是类似的, 只是数据表区别于字段, 前者没有结构链接中赋予的类别标签:
- ① 首先 c i c_i ci中的每个单词转换为词向量, 类别 ϕ i \phi_i ϕi也转换位嵌入向量 Φ i \bm{\Phi}_i Φi;
- ② 然后Schema Encoder将词向量的均值作为字段的初始表示(initial representations) e ^ c i \hat{\bm {e}}_c^i e^ci;
- ③ 进一步, Schema Encoder在span嵌入向量上执行一个注意力机制, 从而获得一个上下文向量(context vector) c c i \bm{c}_c^i cci;
- ④ 最后, Schema Encoder将(1)初始嵌入(initial embedding), (2)上下文向量, (3)类别嵌入(type embedding)三者之和作为字段表示 e c i \bm{e}_c^i eci;
- 以上流程的数学公式如下所示:
g k i = ( e ^ c i ) ⊤ e x k ∥ e ^ c i ∥ ∥ e x k ∥ c c i = ∑ k = 1 L g k i e x k e c i = e ^ c i + c c i + Φ i g_k^{i} = \frac{(\hat{\bm{e}}_c^i)^{\top}\bm{e}_x^k}{\|\hat{\bm{e}}_c^i\|\|\bm{e}_x^k\|}\\ \bm{c}_c^i = \sum_{k=1}^Lg_k^i\bm{e}_x^k\\ \bm{e}_c^i = \hat{\bm{e}}_c^i + \bm{c}_c^i + \bm{\Phi}_i gki=∥e^ci∥∥exk∥(e^ci)⊤exkcci=k=1∑Lgkiexkeci=e^ci+cci+Φi
- 解码器: Decoder
- 解码器的目的是合成SemQL查询;
- 给定SemQL的树状结构, 本文根据一个基于语法的(grammar-based)解码器(参考文献[50, 51]), 通过行动的序列应用(via sequential applications of actions)来利用(leverages)一个LSTM来建模SemQL查询的生成过程;
- 很难明白上一句话是什么意思, 可以直接看下面生成SemQL查询 y y y的公式表达:
p ( y ∣ x , s ) = ∏ i = 1 T p ( a i ∣ x , s , a < i ) p(y|x, s) = \prod_{i=1}^Tp(a_i|x, s, a_{- 其中 a i a_i ai是在时间点 i i i处采取的一个行为(action), a < i a_{
- 其中 a i a_i ai是在时间点 i i i处采取的一个行为(action), a < i a_{
- 解码器根据三种行为类别(ApplyRule, SelectColumn, SelectTable)来生成SemQL查询:
- ApplyRule( r r r): 讲一个生产规则(production rule) r r r应用到一个SemQL查询的当前生成树(current derivation tree);
- SelectColumn( c c c): 从数据库结构(schema)中选择一个字段 c c c;
- SelectTable( t t t): 从数据库结构(schema)中选择一个数据表 t t t;
- 下面本文详细说明SelectColumn( c c c)和SelectTable( t t t)行为的细节, 关于ApplyRule( r r r)行为的细节可以参考文献[50];
- 正如上文提到的, 本文设计了一个内存增强指向网络(memory augmented pointer network)来实现SelectColumn行为; 这里的内存(memory)是用来记录被选择的字段, 这与参考文献[28]中的内存机制(memory machanism)是类似的;
- 当解码器将要选择一个字段时, 它先决定是否需要在内存中选择, 还是直接到数据库结构(schema)中选择;
- 一旦字段被选择, 该字段就会从数据库结构(schema)中被移除, 然后记录在内存中;
- 选择字段 c c c的概率分布可以用下面的公式来描述:
p ( a i = S e l e c t C o l u m n [ c ] ∣ x , s , a < i ) = p ( M e m o r y ∣ x , s , a < i ) p ( c ∣ x , s , a < i , M e m o r y ) + p ( S c h e m a ∣ x , s , a < i ) p ( c ∣ x , s , a < i , S c h e m a ) p ( M e m o r y ∣ x , s , a < i ) = s i g m o i d ( w m ⊤ v i ) p ( S c h e m a ∣ x , s , a < i ) = 1 − p ( M e m o r y ∣ x , s , a < i ) p ( c ∣ x , s , a < i , M e m o r y ) ∝ e x p ( v i ⊤ E c m ) p ( c ∣ x , s , a < i , S c h e m a ) ∝ e x p ( v i ⊤ E c s ) p(a_i={\rm SelectColumn}[c]|x,s,a_{ - 其中:
- S c h e m a \rm Schema Schema和 M e m o r y \rm Memory Memory分别表示从数据库结构(schema)中选择和从内存中选择字段;
- v i v_i vi表示通过在 H x \bm{H}_x Hx上执行一个注意力机制得到的上下文向量(context vector);
- E c m \bm{E}_c^m Ecm表示内存中字段的嵌入表示(embedding);
- E c s \bm{E}_c^s Ecs表示数据库结构(schema)中从未被选择过的字段嵌入表示(embedding);
- w m \bm{w}_m wm是训练参数;
- 以上是SelectColumn的逻辑, SelectTable的逻辑基本类似, 如下所示:
p ( a i = S e l e c t T a b l e [ t ] ∣ x , s , a < i ) ∝ e x p ( v i ⊤ E t ) p(a_i={\rm SelectTable}[t]|x,s,a_{
- 正如Figure 4中所示, 解码器首先预测出一个字段, 然后再预测出该字段所属的数据表; 最后我们就可以使用(leverage)上面得出的字段和数据表的关系来剪除(prune)无关的数据表;
- 粗粒度到细粒度: Coarse-to-fine
- Coarse-to-fine框架: 参考文献[6, 9, 35]; 该框架是用来将SemQL查询的解码过程分解成两个阶段:
- ① 第一阶段: 一个框架(skeleton)解码器输出SemQL查询的框架(skeleton);
- ② 第一阶段: 一个细节(detail)解码器通过选择字段和数据表来
向第一阶段输出中填写缺失的细节;
- 附录: 7 补充材料 Supplemental Material有关于Coarse-to-fine的细节描述;
3 实验 Experiment
3.1 实验配置 Experiment Setup
- 数据集: Dataset
- Spider: 一个大规模的, 人工标注的, 跨领域的Text-to-SQL任务检测数据集(参考文献[54]);
- 根据参考文献[53]的做法, 我们将206个数据库分割成146个训练数据集, 20个开发数据集, 40个测试数据集;
- 训练集, 开发集, 测试集中分别有8625, 1034, 2147个NL问题对应SQL查询的样本对;
- 注意Spider测试集的标签是不公开的, 所以是需要线上评测;
- 本文根据参考文献[54]提出的方法来评估IRNet以及其他Text-to-SQL方法(如使用SQL Exact Matching和Component Matching);
- 基线: Baselines
- 本文评估了前人研究的其他模型作为比对:
- 参考文献[27]: (2014年)seq2seq模型;
- 参考文献[4]: (2014年)seq2seq模型 + 神经注意力机制增强;
- 参考文献[13]: (2016年)seq2seq模型 + 复制机制增强;
- 参考文献[46]: (2017年)SQLNet模型;
- 参考文献[52]: (2018年)TypeSQL模型;
- 参考文献[53]: (2018年)SyntaxSQLNet模型;
- 后两篇都是目前最先进的Text-to-SQL模型
- 实现: Implementations
- 神经网络框架基于PyTorch实现:
- 笔者注: PyTorch是在参考文献[32]中被提出, 有兴趣可以看看;
- 词向量, 类别嵌入(type embedding), 隐层向量的维度都设置为300;
- 词向量由GloVe初始化生成(参考文献[33]);
- 词向量在NL Encoder与Schema Encoder间共享, 且词向量是静态的, 值不会在训练中发生变化;
- 行为嵌入(action embedding)与节点类型嵌入(node type embedding)分别设置为128和64;
- 网络丢失比例(dropout)为0.3;
- 优化器为Adam(参考文献[24]), 参数为默认值;
- 批训练量(Batch size)为64;
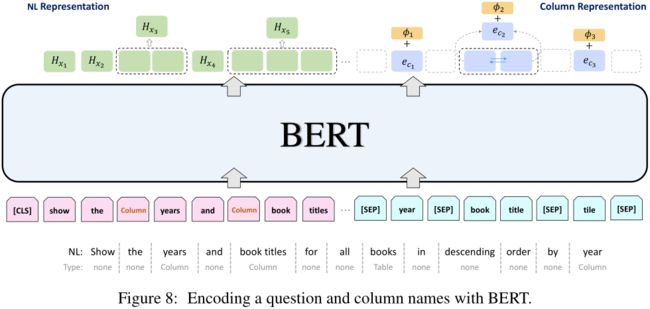
- BERT: 语言模型预训练
- 本文使用BERT来对NL问题, 数据库结构(schema), 结构链接(schema linking)结果进行编码;
- 这种做法启发于参考文献[19]中的SQLova模型设计;
- 解码器保持与IRNet中的一样;
- NL问题中的span序列和所有结构(schema)中不同的字段名拼接;
原文: the sequence of spans in the question are concatenated with all the distinct column names in the schema.
- 每个字段名用**[SEP]标记来隔开, 然后就可以将上一步中的拼接结果输入到BERT**模型中了;
- NL问题中的span表示(representation)被拿来当作该span中的单词和类别的隐层状态均值;
原文: The representation of a span in the question is taken as the average hidden states of its words and type
- 如何构建一个字段(column)的表示:
- 首先在该字段的组成单词的隐层状态上运行一个Bi-LSTM;
- 然后将该字段的类别嵌入(type embedding)和最终的Bi-LSTM隐层状态加和得到该字段的表示;
- 如何构建一个数据表(table)的表示: 与构建字段表示类同;
- 附录: 7 补充材料 Supplemental Material中有关于编码器(encoder)结构详细的图文解释;
- 另外为了构建基线模型(baseline), 本文也对先进的SyntaxSQLNet模型进行了BERT增强;
- 几个注意点说明:
- 本文只使用了BERT模型的基础版本(base version), 因为计算资源的限制无法跑通大规模的BERT模型;
- 本文没有进行任何数据增强, 目的是为了确保对比实验的公正性;
3.2 实验结果 Experimental Results
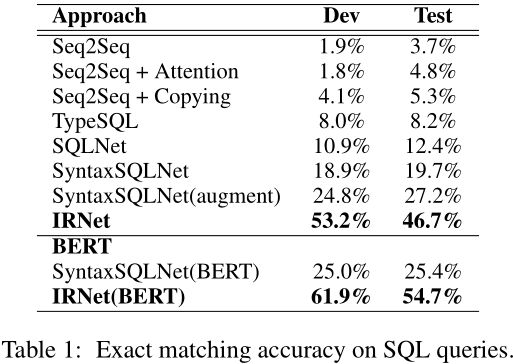
- Table 1中展示了IRNet以及各种基线模型(baseline)在开发集与测试集上的精确匹配度(exact matching accuracy):
- 显然IRNet是最棒的;
- 测试集上IRNet领先SyntaxSQLNet高达 27.0 27.0% 27.0;
- 测试集上IRNet领先经过大规模数据增强的SyntaxSQLNet高达 19.5 19.5% 19.5;
- 通过BERT增强后, IRNet与SyntaxSQLNet的评估结果都有所提升, 但是IRNet相对于SyntaxSQLNet的优势扩大;

- 为了研究IRNet的性能, 根据参考文献[53]中的评估手段, 本文测算了在测试集上不同SQL成分(components)平均的F1-score值, 结果在Figure 5中可见;
- IRNet在每一个SQL成分上领先SyntaxSQLNet, 而且除了KEYWORDS每个SQL成分都领先至少 18.2 18.2% 18.2;
- 引入BERT增强后IRNet在WHERE从句上的效果大大提升;

- Table 2中为不同难度级别的Text-to-SQL任务上IRNet与SyntaxSQLNet之间的性能比较;

- Table 3中为各个基线模型经过SemQL方法增强后的效果;
- 即让基线模型学习SemQL而非SQL;
- 每个模型的效果都有所提升:
- SyntaxSQLNet的提升效果甚至超过了其数据增强后的版本;
- TypeSQL和SQLNet的提升很少是因为它们自身的特性只能适用于SemQL的一部分;
- 总之SemQL方法很有前途;
3.3 消融研究 Ablation Study
本文的消融研究对象是IRNet和IRNet(BERT)上, 使用开发集(development set)上进行验证;
首先准备一个没有使用结构链接(schema linking, 下简称为SL)和粗粒度到细粒度框架(coarse-to-fine framework, 下简称为CF), 并将内存增强指向网络(memory augmented pointer network, 下简称为MEM)替换为vanilla pointer network的基线模型;
然后再往基线模型上依次添加各个组件(component);
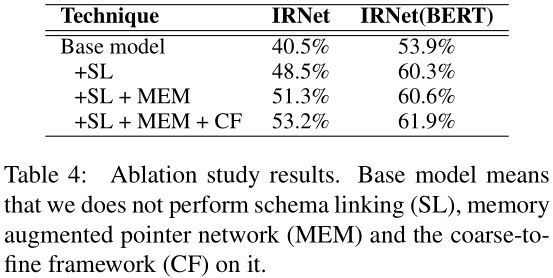
- Table中为消融实验结果:
- +SL:
- 给IRNet和**IRNet(BERT)**分别带来 8.5 8.5% 8.5和 6.4 6.4% 6.4的加成;
- WHERE从句是被认为最难以正确预测的部分, 而这里整整提升了 12.5 12.5% 12.5;
- +MEM和**+CF大致类似, 提升的要比+SL**少一些;
3.4 误差分析 Error Analysis
为了理解误差的来源, 本文分析了483个IRNet再开发集上预测失败的案例, 得出了以下三种主要的失败原因;
- 字段预测: Column Prediction
- 字段预测发生错误, 占比 32.3 32.3% 32.3;
- 即正确的字段名称根本没有再问题中出现, 但是提到了正确的字段下所属的某个cell value(即数据表中的某个值);
- 改进方案是直接改进结构链接以及其中的字符串匹配算法(如可以将词向量引入进来辅助进行匹配);
- 嵌套查询: Nested Query
- 无法应对复杂的嵌套查询, 占比 23.9 23.9% 23.9;
- 注意到训练集中Extra Hard级别的难题占比 20 20% 20, 比Easy级别(占比 23 23% 23)的还要少, 因此解决该问题只能通过数据增强, 否则很难解决这种超难的问题;
- 运算符: Operator
- 错误使用运算符(需要常识性的知识), 占比 12.4 12.4% 12.4;
- 示例问题: Find the name and membership level of the visitors whose membership level is higher than 4, and sort by their age from old to young;
- 显然from old to young表示降序排列, 但是机器是无法识别出来的;
- 笔者注: 其实这里whose membership level is higher than 4也是有歧义的, 这个有点模棱两可;
- 其他:
- FROM从句中存在一些错误, 原因是数据库结构(schema)中缺少相应的外键约束, 导致没有能够找到正确的信息;
- 使用BERT后, 30.5 30.5% 30.5的问题得到了解决, 大多数解决的问题都是字段预测错误和运算符误用, 但是复杂嵌套查询的改善是很低的;
- 笔者注: 我想这种复杂的嵌套查询可能需要一些预处理, 比如需要一个模型将查询问题分成多个嵌套子查询, 这样可能会容易一些, 直接来似乎太不理智了, 理论上机器也不应该有复杂嵌套查询的能力;
4 讨论 Discussion
- 评估差距: Performance Gap
- Table 1中可以看到开发集与测试集上有性能评估的差距;
- 可以解释为开发集(1034个样本)与测试集(2147个样本)的分布有所区别; 因为数据量真的很小;
- 且大概率这种差距来自于Extra Hard与Hard级别的查询;
- 前人的其他模型之所以没有出现很大的评估差距, 原因可能是它们在Extra Hard级别上的表现太差(比如SyntaxSQLNet仅仅只有 4.6 4.6% 4.6的准确率);
- 本文还从训练集随机取了一些数据来评测, 发现与开发集也有评估差距; 所以上面所述开发集与测试集的分布不一样是具有说服力的;
- 笔者注: 这不是废操作么?
- SemQL的局限性: Limitation of SemQL
- ① SemQL不能支持FROM从句中表的自连接(self join); 为了支持自连接, 需要参考文献[7]中的variable mechanism in lambda calculus或者参考文献[21]中的scope mechanism in Discourse Representation Structure;
- 笔者注: 这两篇文献也是老古董了;
- ② SemQL没有完全消除NL与SQL之间的错误匹配问题;
- 比如INTERSECT从句就经常用于取交集的条件, 但是当具体到需求时, 用户往往很少关心两个条件是否是取交集的;
- 总之研究IR很关键, SemQL有改进的空间;
5 相关工作 Related Work
- 数据库的自然语言接口: Natural Language Interface to Database
- NLIDB自上世纪七十年代就已经开始进行研究了(参考文献[3, 11, 15, 34, 43]), 但是大部分都是对特定数据库进行的研究, 很难移植到跨领域数据库中(参考文献[16, 44, 45]);
- 之后有一些研究是关于介入一定的人力工作, 使得模型能够适应不同数据库(参考文献[3, 12, 39]);
- 近期的研究主要是基于神经方法, 进行语义解析(Semantic Parsing), 以及一些大规模的跨领域的数据集的提出, 如WikiSQL(参考文献[56])与Spider(参考文献[54]); 在这些数据集上有很多最新的研究成果(参考文献[10, 14, 19, 20, 37, 42, 46, 52, 53]);
- 数据库的自然语言接口中的中间表示: Intermediate Representation in NLIDB
- 早期的系统LUNAR(参考文献[45])和MASQUE(参考文献[3])也提出了IR的概念;
- 参考文献[27]提出一种查询树来对NL问题进行表征, 起到的也是IR的作用;
- 实体链接: Entity Linking
- 本文中所用的结构链接(SL)是受在基于知识的问答以及语义解析任务中成功引入实体链接的研究(参考文献[17, 25, 26, 49, 52])启发而来的;
- 参考文献[26]提出一种神经实体链接模块, 在半结构化的(semi-structured)数据表的基础上, 回答作曲问题(compositional questions);
- 参考文献[52]提出的TypeSQL提出使用类别信息来识别NL问题中少见的实体与数量信息;
6 结论 Conclusion
We present a neural approach SemQL for complex and cross-domain Text-to-SQL, aiming to address the lexical problem and the mismatch problem with schema linking and an intermediate representation. Experimental results on the challenging Spider benchmark demonstrate the effectiveness of IRNet.
致谢 Acknowledgments
We would like to thank Bo Pang and Tao Yu for evaluating our submitted models on the test set of the Spider benchmark. Ting Liu is the corresponding author.
参考文献
[1] Hiyan Alshawi. 1992. The core language engine. MIT press.
[2] I. Androutsopoulos, G. Ritchie, and P. Thanisch. 1993. Masque/sql: An efficient and portable natural language query interface for relational databases. In Proceedings of the 6th International Conference on Industrial and Engineering Applications of Artificial Intelligence and Expert Systems, pages 327–330. Gordon & Breach Science Publishers.
[3] Ion Androutsopoulos, Graeme D Ritchie, and Peter Thanisch. 1995. Natural language interfaces to databases–an introduction. Natural language engineering, 1:29–81.
[4] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473. Version 7.
[5] Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533–1544. Association for Computational Linguistics.
[6] James Bornholt, Emina Torlak, Dan Grossman, and Luis Ceze. 2016. Optimizing synthesis with metasketches. In Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, pages 775–788. ACM.
[7] Bob Carpenter. 1997. Type-logical semantics. MIT press.
[8] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. Version 1.
[9] Li Dong and Mirella Lapata. 2018. Coarse-to-fine decoding for neural semantic parsing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pages 731–742. Association for Computational Linguistics.
[10] Catherine Finegan-Dollak, Jonathan K. Kummerfeld, Li Zhang, Karthik Ramanathan, Sesh Sadasivam, Rui Zhang, and Dragomir Radev. 2018. Improving text-to-sql evaluation methodology. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pages 351–360. Association for Computational Linguistics.
[11] Alessandra Giordani and Alessandro Moschitti. 2012. Generating sql queries using natural language syntactic dependencies and metadata. In Proceedings of the 17th International Conference on Applications of Natural Language Processing and Information Systems, pages 164–170. Springer-Verlag.
[12] Barbara J. Grosz, Douglas E. Appelt, Paul A. Martin, and Fernando C. N. Pereira. 1987. Team: An experiment in the design of transportable natural-language interfaces. Artificial Intelligence, 32:173–243.
[13] Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O.K. Li. 2016. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 1631–1640. Association for Computational Linguistics.
[14] Izzeddin Gur, Semih Yavuz, Yu Su, and Xifeng Yan. 2018. Dialsql: Dialogue based structured query generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pages 1339–1349. Association for Computational Linguistics.
[15] Catalina Hallett. 2006. Generic querying of relational databases using natural language generation techniques. In Proceedings of the Fourth International Natural Language Generation Conference, pages 95–102. Association for Computational Linguistics.
[16] Gary G. Hendrix, Earl D. Sacerdoti, Daniel Sagalowicz, and Jonathan Slocum. 1978. Developing a natural language interface to complex data. ACM Transactions on Database Systems, 3:105–147.
[17] Jonathan Herzig and Jonathan Berant. 2018. Decoupling structure and lexicon for zero-shot semantic parsing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1619–1629. Association for Computational Linguistics.
[18] Sepp Hochreiter and J¨urgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9:1735–1780.
[19] Wonseok Hwang, Jinyeung Yim, Seunghyun Park, and Minjoon Seo. 2019. A comprehensive exploration on wikisql with table-aware word contextualization. arXiv preprint arXiv:1902.01069. Version 1.
[20] Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, Jayant Krishnamurthy, and Luke Zettlemoyer. 2017. Learning a neural semantic parser from user feedback. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 963–973. Association for Computational Linguistics.
[21] Hans Kamp and U. Reyle. 1993. From Discourse to Logic Introduction to Modeltheoretic Semantics of Natural Language, Formal Logic and Discourse Representation Theory.
[22] Rohit Kate. 2008. Transforming meaning representation grammars to improve semantic parsing. In Proceedings of the Twelfth Conference on Computational Natural Language Learning, pages 33–40. Coling 2008 Organizing Committee.
[23] Rohit J. Kate, Yuk Wah Wong, and Raymond J. Mooney. 2005. Learning to transform natural to formal languages. In Proceedings of the 20th National Conference on Artificial Intelligence, pages 1062–1068. AAAI Press.
[24] Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. Version 9.
[25] Nikolaos Kolitsas, Octavian-Eugen Ganea, and Thomas Hofmann. 2018. End-to-end neural entity linking. In Proceedings of the 22nd Conference on Computational Natural Language Learning, pages 519–529. Association for Computational Linguistics.
[26] Jayant Krishnamurthy, Pradeep Dasigi, and Matt Gardner. 2017. Neural semantic parsing with type constraints for semi-structured tables. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1516–1526. Association for Computational Linguistics.
[27] Fei Li and H. V. Jagadish. 2014. Constructing an interactive natural language interface for relational databases. Proceedings of the VLDB Endowment, 8:73–84.
[28] Chen Liang, Jonathan Berant, Quoc Le, Kenneth D. Forbus, and Ni Lao. 2017. Neural symbolic machines: Learning semantic parsers on freebase with weak supervision. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 23–33. Association for Computational Linguistics.
[29] Percy Liang. 2013. Lambda dependency-based compositional semantics. arXiv preprint arXiv:1309.4408. Version 2.
[30] Percy Liang, Michael Jordan, and Dan Klein. 2011. Learning dependency-based compositional semantics. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 590–599. Association for Computational Linguistics.
[31] Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, pages 1470–1480. Association for Computational Linguistics.
[32] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. Automatic differentiation in pytorch. In NIPS-W.
[33] Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, pages 1532–1543. Association for Computational Linguistics.
[34] Ana-Maria Popescu, Alex Armanasu, Oren Etzioni, David Ko, and Alexander Yates. 2004. Modern natural language interfaces to databases: Composing statistical parsing with semantic tractability. In Proceedings of the 20th International Conference on Computational Linguistics. Association for Computational Linguistics.
[35] Armando Solar-Lezama. 2008. Program Synthesis by Sketching. Ph.D. thesis, Berkeley, CA, USA. AAI3353225.
[36] Robert Speer and Catherine Havasi. 2012. Representing general relational knowledge in conceptnet 5. In Proceedings of the Eighth International Conference on Language Resources and Evaluation, pages 3679–3686. European Language Resources Association.
[37] Yibo Sun, Duyu Tang, Nan Duan, Jianshu Ji, Guihong Cao, Xiaocheng Feng, Bing Qin, Ting Liu, and Ming Zhou. 2018. Semantic parsing with syntax- and table-aware sql generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pages 361–372. Association for Computational Linguistics.
[38] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, pages 3104–3112. MIT Press.
[39] Lappoon R. Tang and Raymond J. Mooney. 2000. Automated construction of database interfaces: Integrating statistical and relational learning for semantic parsing. In Proceedings of the 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora: Held in Conjunction with the 38th Annual Meeting of the Association for Computational Linguistics, pages 133–141. Association for Computational Linguistics.
[40] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer networks. In Advances in Neural Information Processing Systems 28, pages 2692–2700. Curran Associates, Inc.
[41] Chenglong Wang, Alvin Cheung, and Rastislav Bodik. 2017. Synthesizing highly expressive sql queries from input-output examples. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 452–466. ACM.
[42] Chenglong Wang, Kedar Tatwawadi, Marc Brockschmidt, Po-Sen Huang, Yi Mao, Oleksandr Polozov, and Rishabh Singh. 2018. Robust text-to-sql generation with execution-guided decoding. arXiv preprint arXiv:1807.03100. Version 3.
[43] David H. D. Warren and Fernando Pereira. 1981. Easily adaptable system for interpreting natural language queries. American Journal of Computational Linguistics, 8:110–122.
[44] David H. D. Warren and Fernando C. N. Pereira. 1982. An efficient easily adaptable system for interpreting natural language queries. Computational Linguistics, 8:110–122.
[45] W A Woods. 1986. Readings in natural language processing. chapter Semantics and Quantification in Natural Language Question Answering, pages 205–248. Morgan Kaufmann Publishers Inc.
[46] Xiaojun Xu, Chang Liu, and Dawn Song. 2017. Sqlnet: Generating structured queries from natural language without reinforcement learning. arXiv preprint arXiv:1711.04436. Version 1.
[47] Navid Yaghmazadeh, Yuepeng Wang, Isil Dillig, and Thomas Dillig. 2017. Sqlizer: Query synthesis from natural language. Proceedings of the ACM on Pro- gramming Languages, 1:63:1–63:26.
[48] Semih Yavuz, Izzeddin Gur, Yu Su, and Xifeng Yan. 2018. What it takes to achieve 100 percent condition accuracy on wikisql. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1702–1711. Association for Computational Linguistics.
[49] Wen-tau Yih, Matthew Richardson, Chris Meek, Mingwei Chang, and Jina Suh. 2016. The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 201–206. Association for Computational Linguistics.
[50] Pengcheng Yin and Graham Neubig. 2017. A syntactic neural model for general-purpose code generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 440–450. Association for Computational Linguistics.
[51] Pengcheng Yin and Graham Neubig. 2018. Tranx: A transition-based neural abstract syntax parser for semantic parsing and code generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 7–12. Association for Computational Linguistics.
[52] Tao Yu, Zifan Li, Zilin Zhang, Rui Zhang, and Dragomir Radev. 2018a. Typesql: Knowledge-based type-aware neural text-to-sql generation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 588–594. Association for Computational Linguistics.
[53] Tao Yu, Michihiro Yasunaga, Kai Yang, Rui Zhang, Dongxu Wang, Zifan Li, and Dragomir Radev. 2018b. Syntaxsqlnet: Syntax tree networks for complex and cross-domain text-to-sql task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1653–1663. Association for Computational Linguistics.
[54] Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018c. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3911–3921. Association for Computational Linguistics.
[55] John M. Zelle and Raymond J. Mooney. 1996. Learning to parse database queries using inductive logic programming. In Proceedings of the Thirteenth National Conference on Artificial Intelligence, pages 1050–1055. AAAI Press.
[56] Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103.
附录: 7 补充材料 Supplemental Material
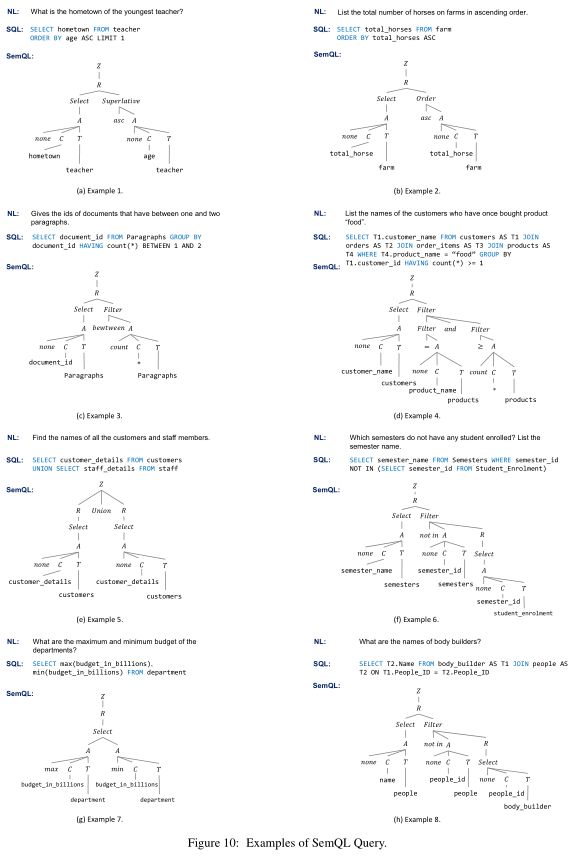
7.1 SemQL查询示例 Examples of SemQL Query
详见Figure 10中的举例:
7.2 SQL查询接口 Inference of SQL Query
如何从SemQL推导出SQL?
- 首先前序遍历SemQL树;
- 然后基于下面对于Figure 2中每种节点的生成规则来生成SQL语句:
- Z Z Z节点应用的生成规则表示是否SQL查询包含UNION, EXCEPT, INTERSECT三种成分;
- R R R节点代表单一SQL查询的起始, 它应用的生成规则表示是否SQL查询包含WHERE以及ORDERBY从句;
- S e l e c t Select Select节点应用的生成规则表示SELECT从句包含多少个字段;
- 每个 A A A节点表示一个字段或一个聚合函数对(aggregate function pair); 具体而言 A A A节点下的三个元素分别表示聚合函数, 字段名, 字段所在数据表名;
- S u p e r l a t i v e Superlative Superlative和 O r d e r Order Order节点下的子树映射到SQL中的ORDERBY从句;
- F i l t e r Filter Filter节点的生成规则表示不同的SQL条件运算符;
- 如果 F i l t e r Filter Filter节点下存在一个 A A A节点, 且该 A A A节点的聚合函数不为 N o n e None None, 那么就会生成一个HAVING从句, 否则的话就是WHERE从句;
- 如果 F i l t e r Filter Filter节点下存在一个 R R R节点, 那么就会发生嵌套查询;
- FROM从句的生成方式已经在正文提到, 即将关系型数据库中所有表当作一个无向图, 然后通过最短路径获取到所有表;
- 最后如果在字段上发生聚合函数, 那么就会出现GROUPBY从句;
7.3 将SQL转为SemQL Transforming SQL to SemQL
如何从SQL推导出SemQL?
- 笔者注: 这是上一节的逆操作, 笔者认为还是比较清晰易懂的; 这应该比从SemQL转为SQL要容易, 这里简单掠过, 附原文内容;


7.4 粗颗粒度到细颗粒度的框架 Coarse-to-Fine Framework

- SemQL的skeleton(骨架)可以直接通过移除 A A A节点下所有的节点来得到, 详见Figure 6;

- Figure 7中描述了使用CF框架来生成一个SemQL查询;
- 首先使用一个skeleton decoder输出SemQL的skeleton;
- 然后使用一个detailed decoder, 通过筛选字段和数据表来填充skeleton中缺失的信息;
- CF框架下生成一个SemQL查询 y y y的概率可以通过下面的公式表述:
p ( y ∣ x , s ) = p ( q ∣ x , s ) p ( y ∣ x , s , q ) p ( q ∣ x , s ) = ∏ i = 1 T s p ( a i = A p p l y R u l e [ r ] ∣ x , s , a < i ) p ( y ∣ x , s , q ) = ∏ i = 1 T c [ λ i p ( a i = S e l e c t C o l u m n [ c ] ∣ x , s , q , a < i ) + ( 1 − λ i ) p ( a i = S e l e c t C o l u m n [ t ] ∣ x , s , q , a < i ) ] p(y|x, s) = p(q|x, s)p(y|x, s, q) \\ p(q|x, s) = \prod_{i=1}^{T_s}p(a_i={\rm ApplyRule}[r]|x, s, a_{- 其中, q q q表示skeleton, 当第 i i i个行为类别(action type)是SelectColumn时有 λ i = 1 \lambda_i=1 λi=1, 否则 λ i = 0 \lambda_i=0 λi=0;
- 训练阶段, 模型的目标函数是最大化下面的对数似然函数(ground true action sequence):
max ∑ ( x , s , q , y ) ∈ D log p ( y ∣ x , s , q ) + γ log p ( q ∣ x , s ) \max \sum_{(x,s,q,y)\in \mathcal D}\log p(y|x, s, q) + \gamma\log p(q|x, s) max(x,s,q,y)∈D∑logp(y∣x,s,q)+γlogp(q∣x,s)- 其中 D \mathcal D D表示训练数据, γ \gamma γ表示 log p ( y ∣ x , s , q \log p(y|x, s, q logp(y∣x,s,q与 log p ( q ∣ x , s ) \log p(q|x, s) logp(q∣x,s)之间的缩放(scale), 默认设为1;
7.5 BERT
详见Figure 8中的描述:
7.6 开发集与测试集模型评估差距的分析 Analysis on the Performance Gap between the Development set and the Test set
笔者注: 笔者认为这部分完全是在为不合理的实验结果找说辞, 实在是没有什么营养, 直接跳过即可, 附原文截图:




![]()
![]()

附录: 图表汇总