The Past Mistake is the Future Wisdom: Error-driven ContrastiveProbability Optimization for Chinese
来源:acl2022 findings
链接:https://arxiv.org/pdf/2203.00991.pdf
代码:自己实现
![]()
目录
任务
动机
模型
Negative samples selection
Contrastive probability optimization
实验
数据集
实验结果
结论
实验分析
错误汉字的统计
可视化 Common/Confusing汉字的概率
损失权值的影响
负样本个数的影响
样例分析
一些思考
任务
中文拼写纠正(CSC):将文本的中错误汉字找出并纠正,一般是发音相似和字形相似的易混淆字
动机
预训练语言模型(PLMs)促进了CSC任务的发展。
然而,PLMs学习到的知识和CSC任务的目标之间存在着差距。PLMs关注文本中的语义,并倾向于将错误的字更正为语义正确或常用的字,而可能和原字并没有任何音近形近的关系。
这也是PLMs的预训练任务造成的,例如bert的预训练任务是 mask language model,待预测的汉字大部分输入都是[MASK], 模型根本不知道原汉字是什么。
如果仅仅只考虑的语义,不考虑与原汉字的发音和字形关系,则一个错误的字可以改正多个合适的字。如下图

论文提出了错误驱动的对比概率优化框架Error-driven Contrastive Probability Optimization (ECOPO),对PLMs中的知识表示进行了细化,并通过错误驱动的方式引导模型避免预测出常见汉字。
ECOPO是模型无关的,可与现有的CSC方法相结合以获得更好的性能。
模型
模型的结构如下图所示,PLMs以bert为例:

其实,就是增加了一个loss,将bert预测出来的常见汉字作为负样本,标签汉字作为正样本。
根据loss优化模型,使得bert避免预测出常见并且不是标签的汉字。
最终缩小预训练模型的知识与CSC目标之间的差距
包含两个步骤:
Negative samples selection
负样本的选择
每个位置,正确的汉字作为正样本,预测概率最高并且不是正确汉字的前k个汉字作为负样本
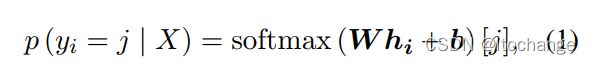
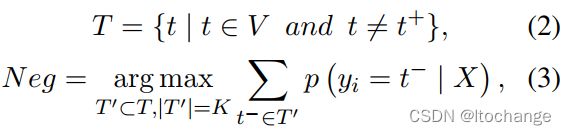
这里的概率使用的是未微调bert的概率呢?还是微调过程中的概率呢?论文似乎没有说清楚。
不过按照下文的推测应该是微调过程中的概率
Contrastive probability optimization
对比概率优化
对比学习的主要动机是在一定的空间内吸引正样本,排斥负样本。现有的NLP对比学习模型主要集中在表征空间(如词/句/语义表征)。论文提出的方法通过选择正/负样本及其原始预测概率,直接优化模型对不同汉字的概率空间
完成正负样本的选择及其对应的概率之后,论文通过对比概率优化(CPO)来训练模型
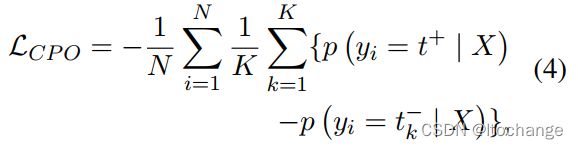
即最小化,正样本的概率 减去 所有负样本的概率的均值

最后,使用的loss为原有的ORI loss 和CPO loss的加权求和,实验结果发现![]() ,
,![]() =1时,结果最好。
=1时,结果最好。
原有的CSC任务,仅仅使用softmax和交叉熵损失函数来优化模型,为什么要用CPO损失呢?
1.动机不同:softmax是归一化模型输出到概率分布。CPO损失是在概率空间中,细化PLMs的知识表征(说啥,听不懂)
2.范围不同:softmax依赖于模型的logit输出,缺乏局部关注点。CPO损失通过负样本的选择,更加关注模型难以处理的样本
3.结果不同:softmax得到的是概率分布,CPO最终优化的是正负样本的相对顺序
实验
数据集
SIGHAN Bake-off 2013: SIGHAN Bake-off 2013: Chinese Spelling Check Task
SIGHAN Bake-off 2014: CLP-2014 Bake-off: Chinese Spelling Check Task
SIGHAN Bake-off 2015: SIGHAN Bake-off 2015: Chinese Spelling Check Task
Wang271K: https://github.com/wdimmy/Automatic-Corpus-Generation
sighan13,sighan14,sighan15 包含对应的训练集和测试集,Wang271K仅仅用来训练
具体可参考:https://github.com/DaDaMrX/ReaLiSe
实验结果

结论
1. ECOPO (BERT) 的结果在每个测试集上都比BERT本身的有较大的提高,尤其在sighan15上面,比现有的比较复杂的模型PLOME,REALISE的结果还好。
2. 由于ECOPO是模型无关的,也可加在现有的最好的模型REALISE之上,也取得了约一个点的提升
3. 先前的方法Faspel和spellgcn利用了混淆集外部信息,PLOME和REALISE则利用了拼音字形外部信息,而论文提出的方法没有使用
实验分析
错误汉字的统计
使用不同的loss训练模型,分析错误纠正的例子
如果预测出的汉字与输入汉字前后组成的2-gram出现的次数超过1000次,就被认为是Common;其他的错误被任务是Confusing

从上表可以看出,仅仅使用softmax,common错误的样例占比很高,当使用CPO或者ECOPO后,common错误的样例占比明显降低。
可视化 Common/Confusing汉字的概率

损失权值的影响
公式5中的权值
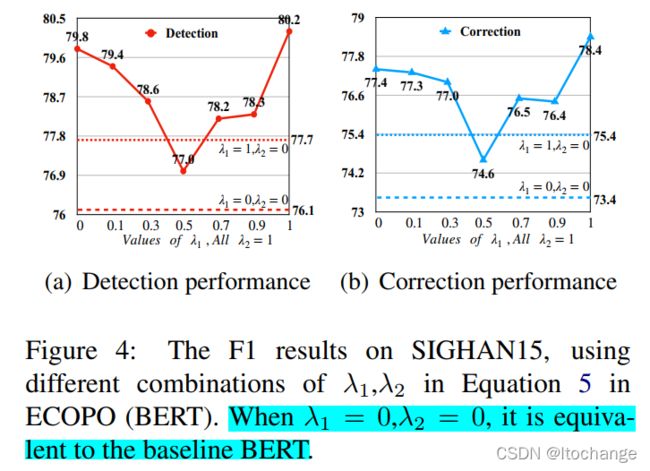
标蓝的部分应该写错了,应该是![]() ,
,![]() =0等同于baseline BERT
=0等同于baseline BERT
负样本个数的影响

样例分析

一些思考
1. 最好的csc模型,应该是选择和原字相似的汉字中,概率最高的。上面的方法会不会破坏bert语言模型的功能呢?有待进一步验证。
2. 负样本的选择还可以是什么?使用所有非正确的汉字,为什么不可以? 输入的错误汉字是否可以呢?
接下来会尝试复现一下论文的结果。
代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CpoLoss(nn.Module):
"""
CpoLoss.
from https://arxiv.org/pdf/2203.00991.pdf
"""
def __init__(self, k=5):
super(CpoLoss, self).__init__()
self.k = k
def forward(self, logits, target, mask=None):
"""
Args:
logits: model's output, shape of [batch_size, num_cls]
target: ground truth labels, shape of [batch_size]
Returns:
shape of [batch_size]
"""
batchsize, seqlen, vocab_size = logits.size()
logits = logits.view(batchsize * seqlen, vocab_size)
probs = torch.softmax(logits, dim=-1) # BS*V
target = target.contiguous().view(-1, 1).long() # BS*1
pos_prob = probs.gather(1, target) # BS*1
# 正样本概率
neg_prob, neg_idx = torch.topk(probs, self.k) # BS * K
# 负样本概率 BS
# Contrastive Probability Optimization Objective
# 正样本概率-负样本概率,求均值
# 如果正样本在前k个,则负样本是K-1个,反之,负样本为K个
expand_pos_idx = target.expand(-1, self.k)
not_equals = expand_pos_idx != neg_idx
not_equals_num = torch.sum(not_equals, dim=-1)
expand_pos_pob = pos_prob.expand(-1, self.k)
minus_porb_sum = torch.sum(expand_pos_pob - neg_prob, dim=-1)
# 正样本概率-正样本的概率等于0,只是除数不一样
batch_loss = - minus_porb_sum / not_equals_num
loss = batch_loss.mean()
return loss从公式5看,loss可能存在负数