001 A Comprehensive Survey of Privacy-preserving Federated Learning(便于寻找:FedAvg、垂直联邦学习的基本步骤)
这是我看的第一篇关于联邦学习的论文,综述文章,让我对联邦学习有了初步的了解。
A Comprehensive Survey of Privacy-preserving Federated Learning: A Taxonomy, Review, and Future Directions https://doi.org/10.1145/3460427
https://doi.org/10.1145/3460427
下图用表格的形式将联邦学习中隐私保护相关论文进行了罗列,主要是为了对比表现这篇综述涵盖内容的全面。
目前关于联邦学习的研究方向如下:
①提高联邦学习的效率和效果;(通信效率)
②提高联邦学习面对旨在破坏联邦学习模型完整性和降低模型性能攻击的安全性;(鲁棒性)
③提高对隐私数据的保护。(隐私保护)
联邦学习的概念:在本地数据集上训练本地模型,并在这些本地客户之间交换参数(e.g.模型权重或梯度),以实现全局模型。(在客户端培训阶段,模型参数是交换的,而数据集是不共享的;培训完成后,受训的模型将被客户共享并用于推理)
在联邦学习中主要有两个主要角色:
①保存其本地数据集的客户端;
②一个不需要访问客户端数据集就能协调整个训练过程和更新全局模型的服务器。
步骤:
①在服务器端初始化联邦学习;
②客户端的本地培训和更新;
③服务器端全局模型聚合和更新。
一个著名算法:FedAvg(浅浅说一句:这是个初代代码,可以有很多改进之处。)

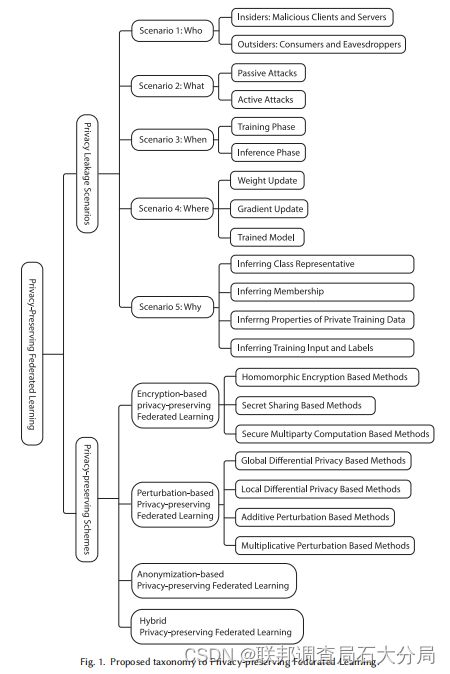
分类:
①水平数据分区(水平联邦学习)
feature相同 id不同
训练过程:
•步骤1:服务器初始化模型参数和超参数,并将计算任务分配给选定的客户端。
•步骤2:选定的客户端培训他们的本地模型并使用隐私保护技术处理经过训练的模型参数,然后将这些参数发送到服务器。
•步骤3:服务器通过(例如采用加权平均)来执行安全聚合。
•步骤4:服务器将聚合的参数发送回客户端。
•步骤5:客户端解密接收到的参数并更新他们的本地模型。
交换的参数类型:模型权重或梯度
对模型权重而言:
优点:不需要频繁的同步 有对更新损失的容忍
缺点:没有收敛的保证
对模型梯度而言:
优点:准确的梯度信息和保证收敛
缺点:通信成本和连接的需要 需要一个可靠的通信
点对点架构(Peer-to-Peer Architecture):
也被称为去中心化联邦学习。相对于客户机-服务器架构来说,它没有中央服务器。
在该体系结构中,每个客户端使用其本地数据集在本地训练机器学习模型,并使用从其他客户端接收到的模型信息更新其模型;然后客户机将更新后的模型信息发送给其他客户机。因此,该FL体系结构中信息泄露的预防重点在于客户端之间的安全通信,可以通过采用基于公钥的加密方案等安全技术来实现。此外,由于没有中央服务器,因此应该提前提供协议来协调培训过程。有两种协议:循环传输和随机传输。
•循环传输。在这个协议中,客户端被组织成一个循环链{C1, C2、…Cn}。客户端C1将当前的模型更新发送给客户端C2。端C2接收从C1获取模型信息,并使用其本地更新接收到的模型信息数据集,然后将更新后的模型信息发送给它的下一个客户C3。当三满足条件时,训练过程停止。
•随机传输。在该协议中,客户端随机选择一个概率相等的客户端Ci将其模型信息发送给Ci, Ci从Ck接收模型信息和使用其本地数据集更新接收到的模型信息,然后随机选择客户机Cj,并将更新后的模型信息发送给Cj。这个过程在n个客户端中同时执行,直到满足终止条件。
②垂直数据分区(垂直联邦学习)
id相同 feature不同
有第三方协调架构(Architecture with Third-party Coordinator)
(假设诚实的第三方,比如政府)
步骤:
•步骤1:ID对齐。因为C1和C2两个数据集中有不同的id,垂直FL系统首先需要使用这些基于加密的ID对齐技术,在不暴露C1私有数据的情况下,确认公共id和C2。然后使用这些公共数据实例来训练垂直FL模型。
•步骤2:C3生成加密密钥对,并将公钥发送给C1和C2。
•步骤3:C1和C2加密他们的中间结果并交换这些信息。
•步骤4:C1和C2逐个计算加密梯度并添加一个掩码。C1也会计算加密的损失。然后,C1和C2将加密的结果发送给C3。
•步骤5:C3对接收到的结果进行解密,并将解密后的梯度和损失发送回C1和C2。然后,C1和C2解除梯度的掩码,并更新它们的模型参数。
没有第三方协调架构(Architecture without Third-party Coordinator)
步骤:
•步骤1:ID对齐。一个ID对齐技术,如参考文献[104]首先被用于确认C1和C2之间的公共id。然后,使用它们的公共数据实例
训练垂直FL模型。
•步骤2:C1生成加密密钥对,并将公钥发送给C2。
•步骤3:C1和C2初始化模型权重。
•步骤4:C1和C2分别计算它们的部分线性预测器,C2发送预测器结果给C1。
•步骤5:C1计算模型残差,对残差进行加密,发送给C2。
•步骤6:C2计算加密梯度,并将掩码梯度发送给C1。
•步骤7:C1解密掩码梯度并将其发送回C2。然后,C1和C2更新他们的模型。
③混合数据分区(迁移联邦学习)
都不同
基于实例的联邦迁移学习(instance-based FTL)
源域数据集中的一些已标记的实例可以被重新加权并重用用于目标域的训练。
水平联邦学习中,不同客户端的数据集分布可能不同,会导致这些数据集上的机器学习模型准确性下降。可以通过重新加权一些选定的数据实例然后重用他们训练模型来减轻分布差异。
垂直联邦学习中,不同客户目标可能不同,ID对齐可能会产生负面影响(负迁移)。可以通过使用重要性采样来缓解负迁移。
基于特征的联邦迁移学习(feature-based FTL)
最小化域的发散,学习目标域的“良好”特征表示,从而有效地将源域到目标域的转换知识编码。
水平联邦学习中,通过最小化客户端不同数据集之间的最大均值差异来获得特征表示。
垂直联邦学习中,通过最小化不同数据集中对齐实例的特征之间的距离来获得特征表示。
基于参数的联邦迁移学习(parameter-based FTL)
利用源域和目标域模型之间的共享参数或超参数的先验分布来有效编码转换知识。
水平联邦学习中,首先基于不同客户端的数据集训练共享全局模型,然后,每个客户端都可以在其局部数据集上使用预先训练好的全局模型对其本地模型进行微调。
垂直联邦学习中,首先使用在对齐实例上训练的预测模型来推断缺失的特征或标签用于未对齐的客户端数据实例,然后在拓展的数据集上进行训练,得到更精确的模型。

分布式机器学习(Distributed Machine Learning)
分布式计算和机器学习的结合,旨在加速大规模数据集的训练过程。
分为数据平行和模型平行
数据平行:将训练数据分区,分区数量等于局部节点数量。本地节点作为计算资源,在单个数据集上训练相同的模型,然后将本地模型参数发送到参数聚合器。
模型平行:将机器模型分区并分布到多个局部节点。然后,每个本地节点在整个数据集的副本上训练模型的一部分。部署一个聚合器来分配计算任务并聚合所有模型部件。
移动边缘计算(Mobile Edge Computing)
减少网络阻塞,通过计算任务进行到更接近边缘的客户端,从而实现快速为客户部署新的服务或应用进程。
分离学习(Split Learning)
一种分布式学习概念,使协作成为可能,不需要与中央服务器交换数据集。
隐私保护机器学习(Privacy-preserving Machine Learning)
基于同态加密的PPML、基于安全多方计算的PPML、基于差分隐私的PPML(在训练模型中加入噪声、在目标函数中加入噪声)