数据结构复习——线性表
判断依据:数据元素相同,数据元素具有线性关系
特征:起始节点没有直接前驱,只有直接后继;终止节点没有直接后继,只有直接前驱;其他节点有直接前驱也有直接后继。
存储结构:顺序存储和链式存储
顺序表
特点:存储位置要连续,不能有空,物理位置表示逻辑关系
优点:任意一个元素可以随机存取
e.g.多项式的顺序存储
只需要存储存在的系数。定义两个结构体,一个是定义数据元素,一个是用来定义线性表

该种定义方法是因为数据元素里面有好几个数据项
若数据元素只有一个数据项,例如一个数据元素是数组的一个元素则采用一个结构体即可
ElemType可以是int型,可以是char型
如果不愿改动,可以在结构体前定义typedef int ElemType

而数组又有两个定义形式:两个都是指的是数组的首地址

而动态分配是后来用如下方式分配内存空间:malloc开辟这么多空间后,由前面的ElemType定义这个空间属于什么数据类型,可以是int、float、自定义的,并定义为指针类型赋值给L.data,因为L.data也是指针


C++的动态存储分配:new一个int型的空间后,得到这个空间的地址并赋给指针p1

释放空间:

参数传递:
- 值传递:参数为整型、字符型等,形参不改变,改变的是实参
例如如下交换a、b的值,a和b的值传给了m与n,m与n交换后并没有返回给a、b,因此a与b的值并没有交换

- 传递地址:参数为指针变量、数组名、引用类型
指针变量为参数:
形参变化影响实参:P1指向a且存的是a的地址,同理P2,将P1与P2传给m与n,此时m与n也分别指向a与b,* 运算是指取指针变量的内容,于是得到了交换

形参变化不影响实参:前面同理,不同的是float *t,此时m指针指向b,而n指针指向a,如此交换对a与b的值不产生影响(a和b存放的东西还是没交换)

数组名作为参数:
对形参数组做的任何改变都可以影响实参数组。如下例b[]也可以写作*b,输出的结果是world

引用类型作参数:
如下例交换,a与m用同一块内存空间,b与n也是,因此交换m与n即交换a与b,同样对形参进行操作即是对实参进行操作

综上来说对于数据量较大的时候,引用类型时间与空间效率都很好,因为不用开辟新的内存空间,而指针变量作参数的时候还要将地址作为实参比较麻烦
如果说采用数组静态分配,使用元素时L.elem[],如果采用动态分配,则定义时要 Sqlist *L,且使用元素时要L->elem
顺序表操作:
先预定义操作中用到的常量与类型(自定义)

- 线性表的初始化(参数用引用)
形参用引用,则对形参的操作即是对实参的操作,使得操作简单。一般来说使用第一句和第三句即可,第二句为考虑实际应用写对于异常的处理

- 销毁线性表
如果线性表存在则删除

- 清空线性表
这里是逻辑清空,告诉计算机线性表里无元素,但是实际有,下次赋值时直接覆盖

- 求线性表长度

- 判断线性表是否为空

- 顺序表的取值(根据位置i存取相应位置数组元素)
因为a1存储在线性表中的0号位置,逻辑位置和物理位置差一

- 顺序表的查找
按值查找,顺序查找:从前往后,从线性表中查找与指定值相等的数据元素的位置

算法分析:采用ALS平均查找长度计算算法复杂度

- 顺序表的插入
插入步骤:先判断插入位置是否合法,以及顺序表是否已经满,若可插入则将n到第i个位置的元素依次往后移,空出第i个位置,将要插入的元素放在第i个位置,然后表长加一
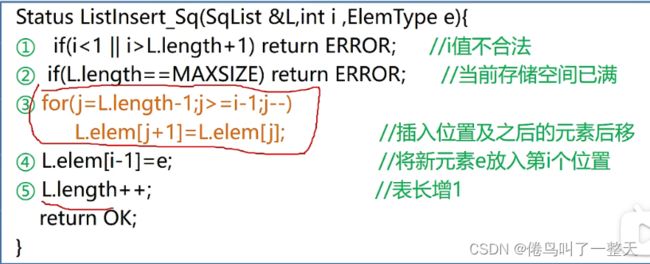
算法分析:插入在尾节点则无需移动,插入在头节点则全都需要后移

- 顺序表的删除
删除步骤:先判断删除位置是否合法,如果合法就将删除后的元素依次往前移动,表长减一,删除成功后返回OK值

算法分析:删除尾节点则无需移动,删除头节点需要移动全部

链表:
逻辑次序与物理次序可以不相同,存储位置可以不连续
单链表:
每个节点可以分为数据域与指针域,头指针记录第一个元素的地址,单链表由头指针决定,因此可以用头指针命名,最后一个节点的指针域为空,即NULL=0

可带头节点也可以不带头节点 ,设置头节点可以让首元节点避免特殊的操作,头节点的数据域可以为空,也可以放链表长度,但头节点不算入长度中
采用结构体表示链表,指针域里的指针是指向下一个节点的,所以应用定义节点的类型来定义指针,表明指针是指向有数据域与指针域的下一个节点(嵌套定义)

通常定义链表定义头指针即可,所以不是用LNode,而定义节点的指针通常用LNode而不是LinkList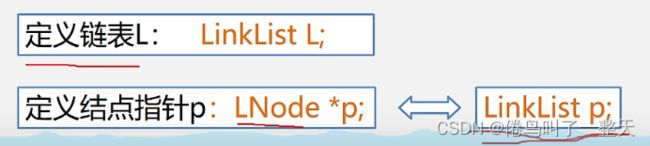
通常这样定义链表:用一个结构体定义数据类型,另一个结构体定义节点

- 空链表:
- 不带头节点:头指针为空
- 带头节点:头节点的指针域为空
- 初始化(带头节点):先生成新节点作为头节点,头指针L指向头节点,并将头节点的指针域置空

- 判断链表是否为空:头节点的指针域是否为空(头节点和头指针都在)

- 单链表的销毁:从头指针开始依次将所有节点释放,用p获得L的地址后销毁,销毁前L先获得下一个节点的地址即L=L->next,当最后p和L指向空时说明全部销毁


- 清空链表:依次释放所有节点,把头节点的指针域设置为空(头指针和头节点都在)
反复执行那里顺序不能颠倒,结束条件是p为NULL


- 求单链表表长:从首元节点开始依次计数所有节点,当p指向空节点时结束计数,关键步骤p=p->next表示指针移到下一个节点

- 从单链表中取第i个元素:从链表的头指针出发顺着链域搜索,知道搜索到第i个为止,还要注意特殊情况比如要取的i大于元素个数。用j做计数器当j==i时搜索结束

- 根据指定数据获取在单链表中的位置:从第一个节点起开始比较,如果相等则返回位置,如果都没有则返回0或者NULL

- 在第i个节点前插入值为e的新节点:首先找到第i-1个节点,然后生成值为e的新节点,将新节点的指针域指向i节点,将i-1节点的指针域指向新节点

- 删除第i个节点:首先找到第i-1个节点,修改i-1个节点的指针域,指向第i+1

- 单链表的建立
- 头插法:元素插入链表头部。首先建立空链表,先插入最后一个元素,插入倒数第二个元素n-1节点,修改头节点的指针和插入节点的指针,头节点的后面一大串接到新节点的后面,头节点接新节点

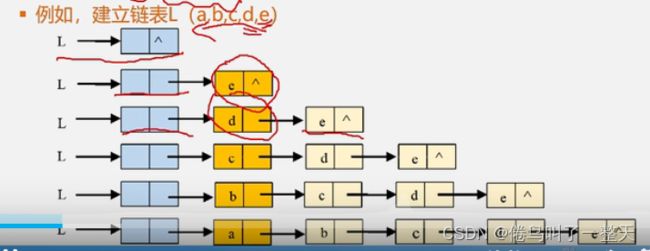
- 尾插法 :元素插在链表的尾部。建立空链表,尾指针r和头指针先指向头节点,在尾部插入新节点时尾指针后移

双链表:
每个节点有两个指针域和一个数据域,一个指向后继节点一个指向前驱节点


空链表:头节点的两个指针域都为空
循环链表:
首尾相接的链表

空链表:头节点的指针域指向自身
判断循环链表到头的条件是p!=L或者p->next!=L
表的操作通常是在首尾的位置进行

带尾指针循环链表的合并:p指针存Ta表头节点,Tb表头连接Ta表尾,Tb表尾连接Ta表头,释放Tb表头节点


双向循环链表:让头节点的前驱指针指向链表的最后一个节点,让最后一个节点的后继指针指向头节点
- 双向链表的插入:

各种链表的比较:

顺序表和链表比较:
