深入理解java虚拟机(全章节完整)
文章目录
- 走近Java
-
- JDK、JRE与JVM之间的关系:
- 内存溢出的问题及解决
- jvm可视化监控工具
- Java的发展
- java技术体系
- Java虚拟机
-
- Sun Classic VM
- Exact VM
- HotSpot VM
- KVM
- JRockit
- J9
- Davik
- Microsoft JVM
- Azul VM Liquid VM
- Taobao VM
- Java虚拟机的内存管理
-
- 程序计数器
- 虚拟机栈
- 本地方法栈
- Java堆
- 方法区
- 运行时常量池
- 对象的创建
-
- 如何在堆中给对象分配内存
- 线程安全性问题
- 对象的结构
- 对象的访问定位
- 垃圾回收
-
- 判定垃圾对象
-
- 引用计数算法
- 可达性分析法
- 垃圾回收算法
-
- 标记清除算法
- 复制算法
- 标记整理算法
- 分代收集算法
- 垃圾收集器
-
- Serial收集器
- ParNew收集器
- Parallel收集器
- CMS收集器
- G1收集器
- 内存分配
-
- Eden区域
- 大对象直接分配到老年代
- 长期存活的对象分配到老年代
- 空间分配担保
- 逃逸分析与栈上分配
- 虚拟机工具
-
- jps
- Jstat
- jinfo
- jmap
- jhat
- jstack
- JConsole
-
- 内存监控
- 线程管理
- 死锁管理
- VisuaIVM
- 性能调优
-
- 案例一
- 案例二
- 类文件结构
-
- 无关性
- Class文件结构
- 魔数
- 常量池
- 访问标志access_flags
- 类索引
- 字段表集合
- 方法表集合
- 属性表集合
- 字节码指令
-
- 字节码与数据类型
- 加载与存储指令
- 运算指令
- 类型转换指令
- 对象创建与访问指令
- 操作数栈管理指令
- 控制转移指令
- 方法调用
- 异常处理指令
- 类加载机制
-
- 类加载的时机
- 加载
- 校验
- 准备
- 解析
- 初始化
- 类加载器
- 双亲委派模型
- 虚拟机字节码执行引擎
-
- 运行时的栈帧结构
- 局部变量表
- 操作数栈
- 动态连接
- 方法返回地址
- 方法调用–解析
- 方法调用–分派
走近Java
JDK、JRE与JVM之间的关系:
JDK全程为Java SE Development Kit(Java开发工具),提供了编译和运行Java程序所需的各种资源和工具,包括:JRE+java开发工具。
JRE全称为Java runtime environment(Java运行环境),包括:虚拟机+java的核心类库。
JVM是运行Java程序的核心虚拟机。

内存溢出的问题及解决
public class Main {
public static void main(String[] args) {
List<Demo> demoList = new ArrayList<>();
while(true) {
demoList.add(new Demo());
}
}
}
class Demo{
}
12345678910111213
如上面代码所示,不断向堆内存中加入对象,会造成异常:Exception in thread “main” java.lang.OutOfMemoryError: Java heap space,运行过程中计算机内存不断上升直到报错。

可以通过添加参数-XX:+HeapDumpOnOutOfMemoryError -Xms20m -Xmx20m 来输出堆存储快照,在项目目录下出现名为java_pid24672.hprof的文件。如果想解析该文件,需要下载Eclipse提供的解析器MemoryAnalyzer,下载地址为:https://www.eclipse.org/mat/downloads.php 通过该软件打开java_pid24672.hprof文件可以看到内存的实际应用情况,判断内存溢出原因。
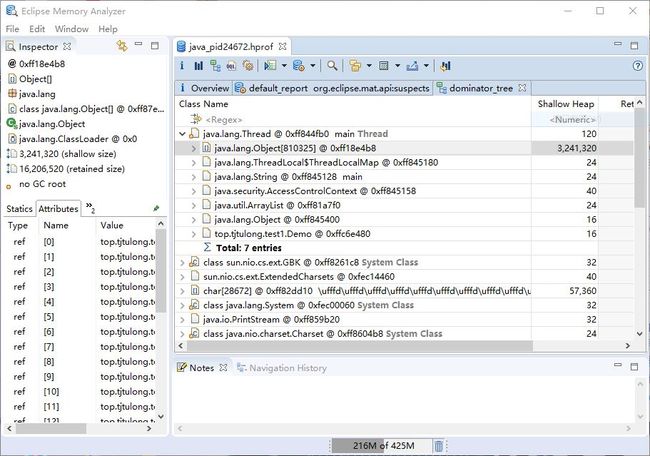
jvm可视化监控工具
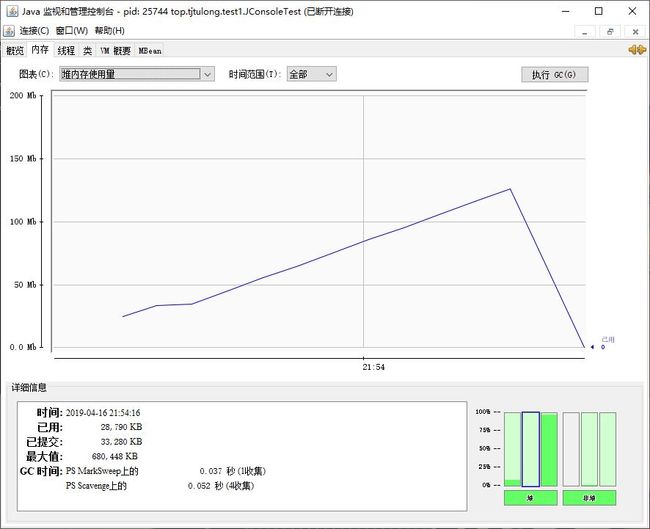
jdk自带可视化监控工具,在目录C:\Program Files\Java\jdk1.8.0_171\bin下,直接在命令行输入jconsole即可运行,源代码在tools.jar包中。
运行如下代码,不断向集合中加入元素,堆内存不断增大:
public class JConsoleTest {
public byte[] b1 = new byte[128 * 1024];
public static void main(String[] args) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("start...");
fill(1000);
}
private static void fill(int n) {
List<JConsoleTest> jlist = new ArrayList<>();
for(int i = 0;i < n;i++) {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
jlist.add(new JConsoleTest());
}
}
}
1234567891011121314151617181920212223242526
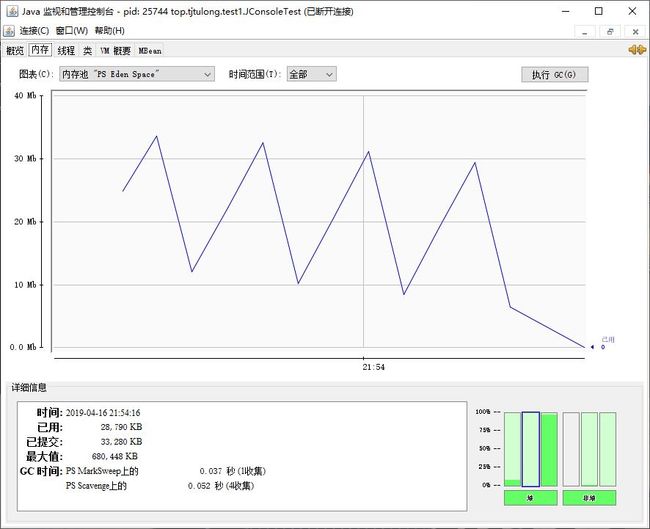
同时可以看出Eden区呈折线变化,这是由于垃圾回收机制的回收作用。
Java的发展
Java之父:詹姆斯·高斯林
最早语言为Oak,用于嵌入式系统,没有成功;
1995年互联网发展,改名为Java,开始火爆,提出Write once run anywhere的原则;
1996年1月 发布JDK1.0,jvm为Sun Classic VM;
1996年5月 首届JavaOne大会;
1997年2月 JDK1.1(内部类、反射、jdbc、javabean、rmi);
1998年 JDK1.2 发布J2Se J2EE J2ME swing jit Hotspot VM;
2000年5月 JDK1.3 Timer Java2d;
2002年2月 JDK1.4 Struts Hibernate Spring 正则表达式 NIO 日志 Xml解析器;
2004年9月 JDK1.5(tiger) 自动装箱拆箱 泛型 注解 枚举 增强for 可变参数 Spring2.X;
2006年 JDK6 JavaSe JavaEE JavaME 提供脚本语言支持 支持http服务器api;
2009年 Java7 Jigsaw模块化 Orical74亿收购Sun;
2014年 Java8 Lambda表达式 函数式接口 方法引用 默认方法 Stream;
2017年 Java9 模块化
java技术体系
- Java程序设计语言
- 各硬件平台上的Java虚拟机
- Class文件格式,可以自己设计语言,自己编写编译器,生成相同的class文件即可
- Java API
- 第三方的Java类库
Java虚拟机
关于Jit编译器和解释器和关系,见博客:https://www.cnblogs.com/insistence/p/5901457.html
Sun Classic VM
已经淘汰,是世界上第一款商用虚拟机,只能使用纯解释器(没有JITJust in time编译器)的方法来执行Java代码。
Exact VM
Exact Memory Management 准确式内存管理;
编译器和解释器混合工作以及两级即时编译器。
HotSpot VM
热点代码技术,使用最多的虚拟机产品,并非由Sun公司开发。官方JDK均采用HotSpot VM。
KVM
kilobyte 简单、轻量、高度可移植,在手机平台运行,运行速度慢。
JRockit
BEA公司开发,是世界上最快的Java虚拟机,专注于服务端应用,全部靠编译器执行。
J9
IBM开发 原名:IBM Techn0ology for Java Virtual Machine IT4j
Davik
不是java虚拟机,寄存器架构而不是栈结构,执行dex(dalvik Executable)文件。
Microsoft JVM
只能运行在windows下面。
Azul VM Liquid VM
高性能的java虚拟机,在HotSpot基础上改进,专用的虚拟机。
Taobao VM
淘宝公司开发
Java虚拟机的内存管理
分为线程共享区和线程独占区
[外链图片转存失败(img-V7Ylnqch-1565436450667)(http://picture.tjtulong.top/虚拟机内存.png)]
程序计数器
程序计数器(处于线程独)占区是一个非常小的内存空间,它可以看成是当前线程所执行的字节码的行号指示器。此区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。如果线程执行的是java方法,这个计数器记录的是正在执行的虚拟字节码指令的地址。如果正在执行的是native方法,那么这个计数器的值为undefined。
注:java中没有goto,为保留字
虚拟机栈
虚拟机栈描述的是Java方法执行的动态内存模型。
栈帧: 每个方法执行都要创建一个栈帧,方法执行完毕,栈帧销毁。用于存储局部变量表,操作数栈,动态链接,方法出口等。
局部变量表:存放编译期可知的各种基本数据类型,引用类型,局部变量表的大小在编译期便已经可以确定,在运行时期不会发生改变。
栈的大小:如果栈满了,StackOverFlowError,递归调用很常见。
public class Hello {
public static void main(String[] args) {
test();
}
public static void test() {
System.out.println("start......");
test();
}
}
// 报错Exception in thread "main" java.lang.StackOverflowError
123456789101112
本地方法栈
本地方法栈为虚拟机执行native方法服务
Java堆
java虚拟机最大的内存区域,存放对象实例,也是垃圾收集器管理的主要区域,分为新生代(由Eden 与Survivor Space 组成)和老生代,可能会抛出OutOfMemoryError异常。

方法区
存储虚拟机加载的类信息(类的版本、字段、方法、接口),常量,静态常量,即时编译后的代码等数据,也可能会抛出OutOfMemoryError异常。
方法区与永久代实际并不等价,对于HotSpot中才有永久代的概念。
运行时常量池
每一个运行时常量池都在java虚拟机的方法区中分配。
例如在Java中字符串的创建会在常量池(方法区中StringTable:HashSet)中进行:
public class Changliang {
public static void main(String[] args) {
// s1与s2是相等的,为字节码常亮
String s1 = "abc";
String s2 = "abc";
// s3创建在堆内存中
String s3 = new String("abc");
// intern方法可以将对象变为运行时常量
// intern是一个native方法
System.out.println(s1 == s3.intern()); // true
}
}
1234567891011121314
直接内存:jdk1.4中增加了NIO,可以分配堆外内存(系统内存替代用户内存),提高了性能。
对象的创建
一个对象创建的过程为:

如何在堆中给对象分配内存
两种方式:指针碰撞和空闲列表。我们具体使用的哪一种,就要看我们虚拟机中使用的是什么垃圾回收机制了,如果有压缩整理,可以使用指针碰撞的分配方式。
指针碰撞:假设Java堆中内存是绝对规整的,所有用过的内存度放一边,空闲的内存放另一边,中间放着一个指针作为分界点的指示器,所分配内存就仅仅是把哪个指针向空闲空间那边挪动一段与对象大小相等的举例,这种分配方案就叫指针碰撞
空闲列表:有一个列表,其中记录中哪些内存块有用,在分配的时候从列表中找到一块足够大的空间划分给对象实例,然后更新列表中的记录,这就叫做空闲列表。
线程安全性问题
在两个线程同时创建对象时,可能会造成空间分配的冲突,解决方案有:线程同步(但执行效率过低)或给每一个线程单独分配一个堆区域TLAB Thread Local Allocation Buffer(本地线程分配缓冲)。
对象的结构
Header(对象头)
- 自身运行时数据(32位~64位 MarkWord):哈希值、GC分代年龄、锁状态标志、线程持有锁、偏向线程ID、偏向时间戳
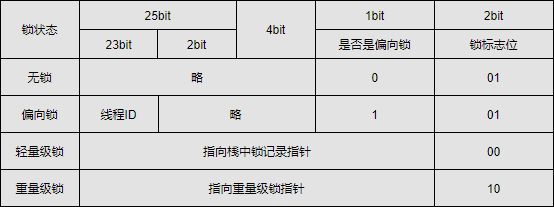
- 类型指针(什么类的实例)
InstanceData:数据实例,即对象的有效信息,相同宽度(如long和double)的字段被分配在一起,父类属性在子类属性之前。
Padding:占位符填充内存
对象的访问定位
对象的访问定位有两种方式:句柄访问和直接指针访问
句柄访问:Java堆中会划分出一块内存来作为句柄池,引用变量中存储的就是对象的句柄地址,而句柄中包含了对象实例数据和类型数据各自的具体地址信息。一个句柄又包含了两个地址,一个对象实例数据,一个是对象类型数据(这个在方法区中,因为类字节码文件就放在方法区中)。
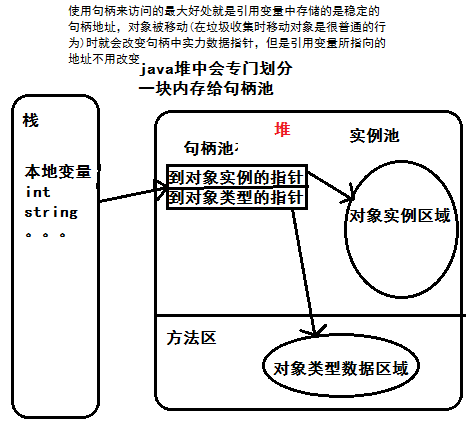
直接指针访问:引用变量中存储的就直接是对象地址了,在堆中不会分句柄池,直接指向了对象的地址,对象中包含了对象类型数据的地址。HotSpot采用直接定位
垃圾回收
对于一般Java程序员开发的过程中,不需要考虑垃圾回收。
- 如何判定对象为垃圾对象;
- 引用计数法
- 可达性分析法
- 如何回收垃圾对象;
- 回收策略(标记清除、复制、标记整理、分带收集算法)
- 常见的垃圾回收器(Serial、Parnew、Cms、G1)
- 何时回收垃圾对象。
判定垃圾对象
引用计数算法
在对象中添加一个引用计数器,当有地方引用这个对象的时候,引用计数器的值就加1,当引用失效的时候(变量记为null),计数器的值就减1。但Java虚拟机中没有使用这种算法,这是由于如果堆内的对象之间相互引用,就始终不会发生计数器-1,那么就不会回收。
测试:两个对象相互引用
public class Count {
private Object instance;
public Count() {
// 占据20M内存
byte[] m = new byte[20 * 1024 *1024];
}
public static void main(String[] args) {
Count c1 = new Count();
Count c2 = new Count();
c1.instance = c2;
c2.instance = c1;
// 断掉引用
c1 = null;
c2 = null;
//垃圾回收
System.gc();
}
}
12345678910111213141516171819202122
打印垃圾回收简易信息的参数:-verbose:gc
打印详细:-verbose:gc -XX:+PrintGCDetails
输出:[GC (System.gc()) [PSYoungGen: 22476K->680K(38400K)] 42956K->21168K(125952K), 0.0008355 secs]可以看出对象被回收,因此Java不使用引用计数算法。
可达性分析法
此算法的核心思想:通过一系列称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称为“引用链”,当一个对象到GC Roots没有任何的引用链相连时(从GC Roots)到这个对象不可达)时,证明此对象不可用。

可作为GC Roots的对象:
- 虚拟机栈
- 方法区的类属性所引用的对象
- 方法区中常量所引用的对象
- 本地方法栈中引用的对象
垃圾回收算法
标记清除算法
先标记出要回收的对象(一般使用可达性分析算法),再去清除,但会有效率问题和空间问题:标记的空间被清除后,会造成我的内存中出现越来越多的不连续空间,当要分配一个大对象的时候,在进行寻址的要花费很多时间,可能会再一次触发垃圾回收。
复制算法
堆:
- 新生代
Eden 伊甸园
Survivor 存活期
Tenured Gen 老年区 - 老年代
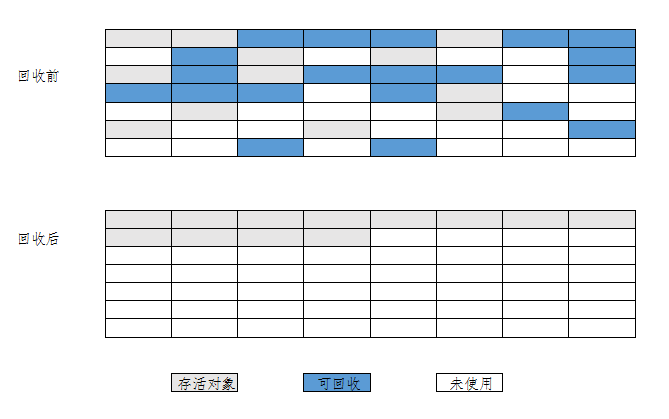
复制算法是将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,浪费较大。复制算法的执行过程如下图所示:

现在的商业虚拟机都采用这种收集算法来回收新生代,IBM公司的专门研究表明,新生代中的对象98%是“朝生夕死”的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性的复制到另外一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性的复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存为整个新生代容量的90%(80%+10%),只有10%的内存会被“浪费”。

标记整理算法
对于老年代,回收的垃圾较少时,如果采用复制算法,则效率较低。标记整理算法的标记操作和“标记-清除”算法一致,后续操作不只是直接清理对象,而是在清理无用对象完成后让所有存活的对象都向一端移动,并更新引用其对象的指针。
很显然,整理这一下需要时间,所以与标记清除算法相比,这一步花费了不少时间,但从长远来看,这一步还是很有必要的。
分代收集算法
针对不同的年代进行不同算法的垃圾回收,针对新生代选择复制算法,对老年代选择标记整理算法。
垃圾收集器
Java的应用很广,内存区域也很多,可以使用不同的垃圾收集器。
Serial收集器
单线程垃圾收集器、最基本、发展最悠久。它的单线程的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。偶尔用在桌面应用中。

ParNew收集器
可多线程收集垃圾,收集新生代,使用收集算法

Parallel收集器
多线程收集垃圾,收集新生代,使用收集算法。Parallel收集器更关注系统的吞吐量,可以通过参数来打开自适应调节策略。
吞吐量:CPU用于运行用户代码的时间与CPU消耗的总时间的比值。
吞吐量 = (执行用户代码时间)/(执行用户代码时间+垃圾回收占用时间)
-XX:MaxGCPauseMillis 垃圾收集器最大停顿的时间,但最大停顿时间过短必然会导致新生代的内存大小变小,垃圾回收频率变高,效率可能降低。
-XX:CGTIMERatio 吞吐量大小(0-100),默认为99。
CMS收集器
Concurrent Mark Sweep,采用标记-清除算法,用于老年代,常与ParNew协同工作。优点在于并发收集与低停顿。
注:并行是指同一时刻同时做多件事情,而并发是指同一时间间隔内做多件事情
工作过程
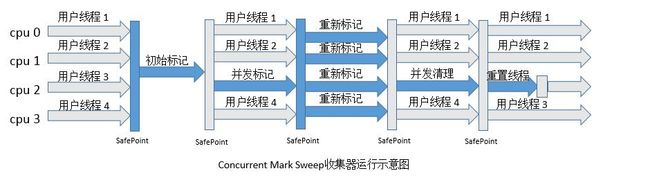
- 初始标记
标记老年代中所有的GC Roots对象和年轻代中活着的对象引用到的老年代的对象,时间短; - 并发标记
从“初始标记”阶段标记的对象开始找出所有存活的对象; - 重新标记
用来处理前一个阶段因为引用关系改变导致没有标记到的存活对象,时间短; - 并发清理
清除那些没有标记的对象并且回收空间。
缺点:占用大量的cpu资源、无法处理浮点垃圾、出现Concurrent MarkFailure、空间碎片。
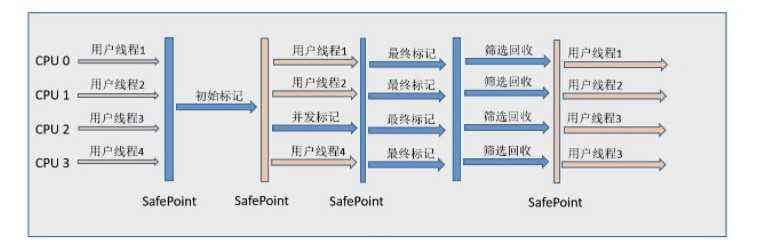
G1收集器
G1(Garbage First)垃圾收集器是当今垃圾回收技术最前沿的成果之一,早在JDK7就已加入JVM的收集器大家庭中,成为HotSpot重点发展的垃圾回收技术。
优势:并行(多核CPU)与并发;
分代收集(新生代和老年代区分不明显);
空间整合;
限制收集范围,可预测的停顿。
步骤:初始标记、并发标记、最终标记和筛选回收。
内存分配
原则:
- 优先分配到Eden
\2. 大对象直接分配到老年代
\3. 长期存活的对象分配到老年代
\4. 空间分配担保
\5. 动态对象的年龄判断
Eden区域
-verbose:gc -XX:+PrintGCDetails 表示输出虚拟机中GC的详细情况。
默认使用Parallel收集器(服务器),Serial收集器(客户端),服务器和客户端可以通过java -version查看。也可以通过-XX:+UseSerialGC设置收集器。
-Xms20M -Xmx20M -Xmn10M设置内存大小大小为20M,新生代大小为10M。
-XX:SurvivorRatio=8设置eden 与survuvor 的比值大小 8:1
public class Eden {
public static void main(String[] args) {
// -verbose:gc -XX:+PrintGCDetails -XX:+UseSerialGC -Xms20M -Xmx20M -Xmn10M -XX:SurvivorRatio=8
byte[] b1 = new byte[2 * 1024 * 1024];
byte[] b2 = new byte[2 * 1024 * 1024];
byte[] b3 = new byte[2 * 1024 * 1024];
byte[] b4 = new byte[4 * 1024 * 1024]; //第一次Minor回收
System.gc();
}
}
123456789101112
GC日志:
[GC (Allocation Failure) [DefNew: 7291K->557K(9216K), 0.0051010 secs] 7291K->6701K(19456K), 0.0069568 secs] [Times: user=0.00 sys=0.02, real=0.01 secs]
[Full GC (System.gc()) [Tenured: 6144K->6144K(10240K), 0.0017958 secs] 10957K->10793K(19456K), [Metaspace: 2699K->2699K(1056768K)], 0.0020720 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K, used 4813K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 58% used [0x00000000fec00000, 0x00000000ff0b3708, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
tenured generation total 10240K, used 6144K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 60% used [0x00000000ff600000, 0x00000000ffc00030, 0x00000000ffc00200, 0x0000000100000000)
Metaspace used 2705K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 297K, capacity 386K, committed 512K, reserved 1048576K
1234567891011
JVM优先把对象放入Eden区,当Eden区放不下了后(2 * 3 = 6M),通过分配担保机制放入老年代6M(Minor GC),再把最后一个4M放入新生代。
大对象直接分配到老年代
我们认为大对象不是朝生夕死的,如果放在新生代,则需要不断移动,性能较差。
-XX:PretenureSizeThreshold=6M 设置大文件大小。
public class Old {
public static void main(String[] args) {
byte[] b1 = new byte[7 * 1024 * 1024];
}
}
12345
7M大于设置的大文件的大小(6M),直接放入老年代。
tenured generation total 10240K, used 7168K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 70% used [0x00000000ff600000, 0x00000000ffd00010, 0x00000000ffd00200, 0x0000000100000000)
123
长期存活的对象分配到老年代
-XX:MaxTenuringThreshold最大年龄,默认为15;
Age 1 + 1 + 1 使用年龄计数器。
空间分配担保
-XX:+HandlePromotionFailure 开启
-XX:-HandlePromotionFailure 禁用
取之前每一次回收晋升到老年代对象容量的平均值大小作为经验值,与老年代的剩余空间进行比较,决定是否FullGC来让老年代腾出更多空间。
逃逸分析与栈上分配
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
1234567
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。如果想要StringBuffer sb不逃出方法,可以写成:return sb.toString();
虚拟机工具
Sun公司自带了许多虚拟机工具,在bin目录下,其exe文件所依赖的源码在tools.jar包下,利用jar包中的文件可自己开发。
jps
Java process status
可查看本地虚拟机唯一id lvmid (local virtual machine id):

可以加入参数:
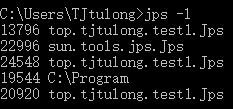
jps -m 运行时传入主类的参数;
jps -v 虚拟机参数;
jps -l 运行的主类全名 或者jar包名称;
也可以一块使用 jsp -mlv。
Jstat
监视虚拟机运行时的状态信息,包括监视类装载、内存、垃圾回收、jit编译信息。官方文档有操作命令:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html
jstat -gcutil 3344 1000 10 每隔1000毫秒执行一次 10次

注:元空间的本质和永久代类似,都是对jvm规范中的方法区的实现。不过元空间与永久代之间最大的区别是:元空间并不在虚拟机中,而是使用本地内存。因此在默认情况下,元空间的大小仅受本地内存限制。
jinfo
实时查看和调整虚拟机的各项参数

第一条指令为:是否启用Serial垃圾回收,输出-,表示不启用;
第二条指令为:是否启用G1垃圾回收,输出+,表示启用。
jmap
命令jmap是一个多功能的命令。它可以生成 java 程序的 dump 文件, 也可以查看堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
可实现与-XX:+HeapDumpOnOutOfMemoryError相同的效果
jhat
JVM heap Analysis Tool(分析堆)十分占据内存与CPU,使用较少。
jstack
生成线程快照,定位线程长时间停顿的原因,命令格式为:
jstack [option] vmid
可以通过Thread.getAllStackTraces()方法获取StackTraceElement,来代替jstack方法。
public class Jstack {
public static void main(String[] args) {
Map<Thread, StackTraceElement[]> m = Thread.getAllStackTraces();
for(Map.Entry<Thread, StackTraceElement[]> en:m.entrySet()) {
Thread t = en.getKey();
StackTraceElement[] v = en.getValue();
System.out.println("Thread name is " + t.getName());
for(StackTraceElement s : v) {
System.out.println("\t" + s.toString());
}
}
}
}
123456789101112131415
JConsole
JConsole是一种基于JMX的可视化监视、管理工具可进行内存管理、线程管理、查看死锁等。
内存监控
Jconsole管理内存相当于可视化的jstat命令,具体操作见第一节。
线程管理
线程页签的功能相当于可视化的jstack命令,遇到线程停顿时可以使用这个页签进行监控分析。分别对IO阻塞、死循环和线程阻塞进行了测试。
public class ThreadTest {
// 线程死循环演示
public static void createBusyThread() {
new Thread(new Runnable() {
@Override
public void run() {
while(true) {
;
}
}
},"while_true").start();
}
// 线程锁等待演示
public static void createLockThread(final Object lock) {
new Thread(new Runnable() {
@Override
public void run() {
synchronized(lock) {
try {
lock.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
},"wait").start();
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
sc.next();
createBusyThread();
sc.next();
Object obj = new Object();
createLockThread(obj);
}
}
123456789101112131415161718192021222324252627282930313233343536373839404142
对于IO阻塞:这种等待是Runnable状态的,只消耗很小的CPU资源。

对于死循环:这种等待是Runnable状态的,但是消耗大量CPU资源
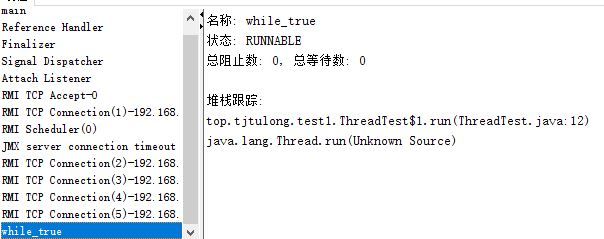
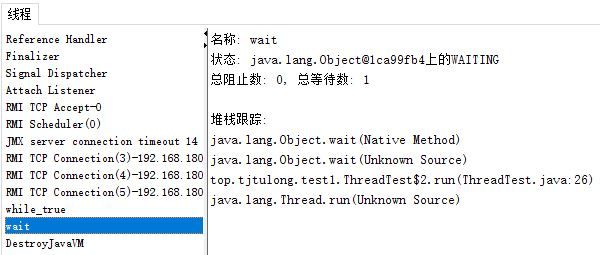
对于线程等待:这种等待是waiting状态的。
死锁管理
public class DeadLock {
static class SynAddRunnable implements Runnable{
int a,b;
public SynAddRunnable(int a,int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
// TODO Auto-generated method stub
synchronized(Integer.valueOf(a)) {
synchronized(Integer.valueOf(b)) {
System.out.println(a + b);
}
}
}
}
public static void main(String[] args) {
for(int i = 0;i < 100;i++) {
new Thread(new SynAddRunnable(1,2)).start();
new Thread(new SynAddRunnable(2,1)).start();
}
}
}
123456789101112131415161718192021222324252627
Integer.valueOf()方法将返回常量池中的对象,因此在循环200次的过程中,很有可能在线程切换的过程中造成死锁。出现线程死锁后,点击Jconsole线程面板上的“检测到死锁按钮”,将出现一个新的死锁页面:
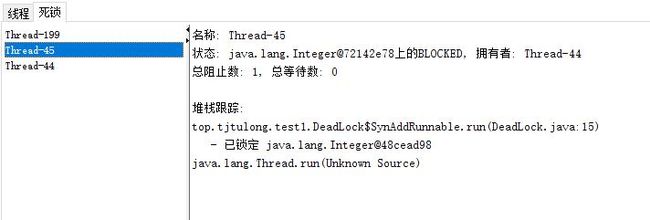
可以看到Thread-45线程正在等待被另一个线程Thread-44持有的Integer对象。
VisuaIVM
VisuaIVM(All-in-One Java Troubleshooting Tool)是一款免费的,集成了多个 JDK 命令行工具的可视化工具,它提供强大的分析能力,对 Java 应用程序做性能分析和调优。这些功能包括生成和分析海量数据、跟踪内存泄漏、监控垃圾回收器、执行内存和 CPU 分析,同时它还支持在 MBeans 上进行浏览和操作。是目前为止功能最强大的运行监测和故障处理工具。
性能调优
知识 + 工具 + 数据 + 经验
案例一
背景:绩效考核系统,会针对每一个考核员工生成一个各考核点的考核结果,形成一个Excel文档,供用户下载。文档中包含用户提交的考核点信息以及分析信息,Excel文档由用户请求的时候生成,下载并保存在内存服务器一份。64G内存。
问题:经常有用户反映长时间卡顿的问题。
处理思路:
- 优化SQL(无效)
- 监控CPU
- 监控内存发现经常发生Full GC 20-30s
运行时产生大对象(每个教师考核的数据WorkBook),直接放入老年代,MinorGC不会去清理,会导致FullGC,且堆内存分配太大,时间过长。
解决方案:部署多个web容器,每个web容器的堆内存4G,单机TomCat集群。
案例二
背景:简单数据抓取系统,抓取网络上的一些数据,分发到其它应用。
问题:不定期内存溢出,把堆内存加大,无济于事,内存监控也正常。
处理方法:NIO使用了堆外内存,堆外内存无法垃圾回收,导致溢出。
类文件结构
无关性
Java语言选择了与操作系统和机器指令集无关的、平台中立的格式作为程序编译后的储存格式。Java虚拟机提供的语言无关性是指虚拟机不关心Class的来源是何种语言,只要能生成Class文件就够了。可以使用Binary Viewer等软件读取二进制文件。

Class文件结构
Java class文件是8位字节的二进制流,数据项按顺序存储在class文件中,相邻的项之间没有任何间隔,这样可以使class文件紧凑。占据多个字节空间的项按照高位在前的顺序分为几个连续的字节存放。在class文件中,可变长度项的大小和长度位于其实际数据之前。这个特性使得class文件流可以从头到尾被顺序解析,首先读出项的大小,然后读出项的数据。Class文件中有两种数据结构:无符号数和表。可以对比xml、json,二进制文件没有空格和换行,节省空间,提高性能,但放弃了可读性。

魔数
每个Java class文件的前4个字节被称为它的魔数(magic number):0xCAFEBABE。魔数的作用在于,可以轻松地分辨出Java class文件和非Java class文件。
class文件的下面4个字节包含了主、次版本号。对于Java虚拟机来说,版本号确定了特定的class文件格式,通常只有给定主版本号和一系列次版本号后,Java虚拟机才能够读取class文件。如52对应JDK1.8。
常量池
constant_pool_count和constant_pool
constant_pool_count:两个字节表示常量池的长度,编号从1开始;
CP_info:每个常量池入口都从一个长度为一个字节的标志开始(tag),这个标志指出了列表中该位置的常量类型。JDK 1.7以后共有14种不相同表结构的数据。
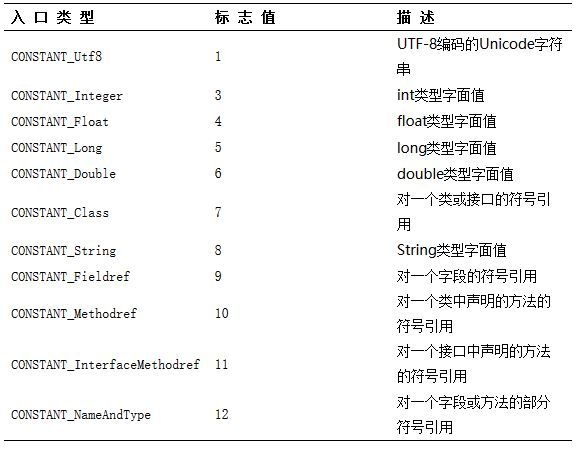
还可以通过javap -verbose Demo.class命令来分析class文件。
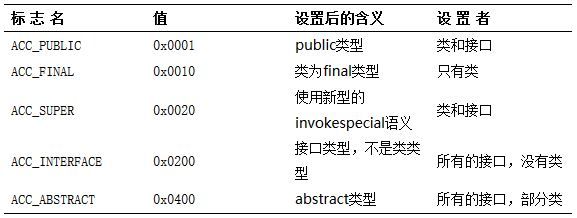
访问标志access_flags
紧接常量池后的两个字节称为access_flags,它展示了文件中定义的类或接口的几段信息,包括这个Class是类还是接口;是否定义为public类型;是否为abstrct类型;在access_flags中所有未使用的位都必须由编译器置0,而且Java虚拟机必须忽略它。
类索引
接下来的两个字节为this_class项,它是一个对常量池的索引。在this_class位置的常量池入口必须为CONSTANT_Class_info表。该表由两个部分组成——标签和name_index。标签部分是一个具有CONSTANT_Class值的常量,在name_index位置的常量池入口为一个包含了类或接口全限定名的CONSTANT_Utf8_info表。
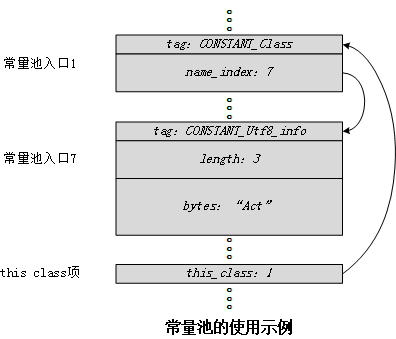
父类索引与接口索引集合同理。
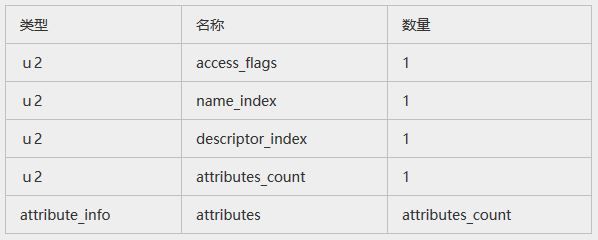
字段表集合
紧接在interfaces后面的是对在该类或者接口中所声明的字段的描述。首先是名为fields_count的计数,它是类变量和实例变量的字段的数量总和。在这个计数后面的是不同长度的field_info表的序列(fields_count指出了序列中有多少个field_info表)。在fields列表中,不列出从超类或者父接口继承而来的字段。字段表结构如下图所示:
方法表集合
紧接着fields后面的是对在该类或者接口中所声明的方法的描述。只包括在该类或者接口中显式定义的方法。

属性表集合
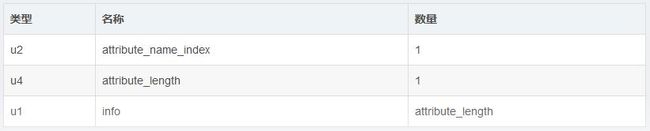
在Class文件、字段表、方法表中都可以携带自己的属性表集合。相对于其它表,属性表的限制相对较小,不再要求各个属性表有严格的顺序,可以写入自定义的属性信息,JVM也预定义了21项属性表。对于每个属性,它的名称需要从常量池中引入一个CONSTANT_Utf8_info类型的常量来表示,而属性值的结构则完全自定义,只需要一个u4的长度属性去说明属性值所占用的位数即可,一个属性表结构如下图所示:
字节码指令
Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码,Opcode)以及跟随其后的零至多个代表此操作所需参数(称为操作数,Operands)而构成。操作码的长度为1个字节,因此最大只有256条,是基于栈的指令集架构。
字节码与数据类型
在Java虚拟机的指令集中,大多数的指令都包含了其操作所对应的数据类型信息。iload中的i表示的是int。i代表对int类型的数据操作,l代表long,s代表short,b代表byte,c代表char,f代表float,d代表double,a代表reference。也有不包含类型信息的:goto与类型无关;Arraylength操作数组类型。
加载与存储指令
加载和存储指令用于将数据在栈帧中的局部变量表和操作数栈之间来回传输,这类指令包括:
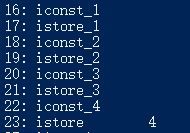
- 将一个局部变量加载到操作栈:iload
- 将一个数值从操作数栈存储到局部变量表:istore
- 将一个常量加载到操作数栈:bipush。
- 扩充局部变量表的访问索引的指令:wide
运算指令
运算或算术指令用于对两个操作数栈上的值进行某种特定运算,并把结果重新存入到操作栈顶。大体上算术指令可以分为两种:对整型数据进行运算的指令与对浮点型数据进行运算的指令,无论是哪种算术指令,都使用Java虚拟机的数据类型,由于没有直接支持byte、short、char和boolean类型的算术指令,对于这类数据的运算,应使用操作int类型的指令代替。
注:e = a + b + c + d +e,操作数栈的深度依然是2。
类型转换指令
类型转换指令可以将两种不同的数值类型进行相互转换,这些转换操作一般用于实现用户代码中的显示类型转换操作,或者用来处理字节码指令中数据类型相关指令无法与数据类型一一对应的问题。
宽化类型处理:int i= 1;long l = i;
窄化类型处理:User user = new User(); Object obj = user;
处理窄化类型转换时,必须显式地使用转换指令来完成,这些转换指令包括:i2b、i2c、i2s、l2i、f2i、f2l、d2i、d2l和d2f。
对象创建与访问指令
虽然类实例和数组都是对象,但Java虚拟机对类实例和数组的创建与操作使用了不同的字节码指令。对象创建后,就可以通过对象访问指令获取对象实例或者数组实例中的字段或者数组元素,这些指令如下:
- 创建类实例的指令:new;
- 创建数组的指令:newarray、anewarray、multianewarray;
- 访问类字段(static字段,或者称为类变量)和实例字段(非static字段,或者称为实例变量)的指令:getstatic、putstatic、getfield、putfield;
- 把一个数组元素加载到操作数栈的指令:baload、caload、saload、iaload、laload、faload、daload、aaload;
- 将一个操作数栈的值存储到数组元素中的指令:bastore、castore、sastore、iastore、fastore、dastore、aastore;
- 取数组长度的指令:arraylength;
- 检查类实例类型的指令:instanceof、checkcast。
class Demo
{
public static void main(String[ ] args){
User user = new User();
User[] users = new User[10];
int[] is = new int[10];
user.name = "hello";
String username = user.name;
}
}
class User{
String name;
static int age;
}
1234567891011121314151617
字节码指令为:
Code:
stack=2, locals=5, args_size=1
0: new #2 // class User
3: dup
4: invokespecial #3 // Method User."":()V
7: astore_1
8: bipush 10
10: anewarray #2 // class User
13: astore_2
14: bipush 10
16: newarray int
18: astore_3
19: aload_1
20: ldc #4 // String hello
22: putfield #5 // Field User.name:Ljava/lang/String;
25: aload_1
26: getfield #5 // Field User.name:Ljava/lang/String;
29: astore 4
31: return
1234567891011121314151617181920
操作数栈管理指令
如同操作一个普通数据结构中的堆栈那样,Java虚拟机提供了一些用于直接操作操作数栈的指令,包括:
- 将操作数栈的栈顶一个或两个元素出栈:pop、pop2;(不常用)
- 复制栈顶一个或两个数值并将复制值或双份的复制值重新压入栈顶:dup、dup2、dup_x1、dup2_x1、dup_x2、dup2_x2;
- 将栈最顶端的两个数值互换:swap。
控制转移指令
控制转移指令可以让Java虚拟机有条件或无条件地从指定的位置指令而不是控制转移指令的下一条指令继续执行程序,从概念模型上理解,可以认为控制转移指令就是在有条件或无条件地修改PC寄存器的值。如:goto等。
class Demo {
public static void main(String[ ] args){
int a = 10;
if(a > 10){
System.out.println(">10");
}else{
System.out.println(">=10");
}
}
}
1234567891011
字节码指令为:
Code:
stack=2, locals=2, args_size=1
0: bipush 10
2: istore_1
3: iload_1
4: bipush 10
6: if_icmple 20
9: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
12: ldc #3 // String >10
14: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
17: goto 28
20: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
23: ldc #5 // String >=10
25: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
123456789101112131415
方法调用
- invokevirtual:用于调用对象的实例方法,根据对象的实际类型进行分派(虚方法分派),这也是Java语言中最常见的方法分派方式。
- invokeinterface:用于调用接口方法,它会在运行时搜索一个实现了这个接口方法的对象,找出适合的方法进行调用。
- invokespecial:用于调用一些需要特殊处理的实例方法,包括实例初始化方法、私有方法和父类方法。
- invokestatic:用于调用类方法(static 方法)
异常处理指令
在Java程序中显示抛出异常的操作(throw语句)都由athrow指令来实现,除了用throw语句显示抛出异常情况之外,Java虚拟机规范还规定了许多运行时异常会在其他Java虚拟机指令检测到异常状况时自动抛出。而在Java虚拟机中,处理异常(catch语句)不是由字节码指令来实现的,而是采用异常表来完成的。
class Demo
{
public static void main(String[ ] args){
int a = 0;
throw new RuntimeException("Exception......");
}
}
12345678
字节码指令为:
Code:
stack=3, locals=2, args_size=1
0: iconst_0
1: istore_1
2: new #2 // class java/lang/RuntimeException
5: dup
6: ldc #3 // String Exception......
8: invokespecial #4 // Method java/lang/RuntimeException."":(Ljava/lang/String;)V
11: athrow
12345678910
类加载机制
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。JVM是懒加载(节约系统资源)。
类加载的时机

加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,但解析阶段则不一定,它在某些情况下可以在初始化阶段之后再开始。
虚拟机规范严格规定了有且只有五种情况必须立即对类进行“初始化”:
- 使用new关键字实例化对象的时候、读取或设置一个类的静态字段的时候,已经调用一个类的静态方法的时候。
- 使用java.lang.reflect包的方法对类进行反射调用的时候,如果类没有初始化,则需要先触发其初始化。
- 当初始化一个类的时候,如果发现其父类没有被初始化就会先初始化它的父类。
- 当虚拟机启动的时候,用户需要指定一个要执行的主类(就是包含main()方法的那个类),虚拟机会先初始化这个类;
- 使用Jdk1.7动态语言支持的时候的一些情况。
public class Parent {
static {
System.out.println("父类加载...");
}
}
public class Child extends Parent{
static {
System.out.println("子类加载...");
}
public static void main(String[] args) {
System.out.println("子类运行...");
}
}
运行结果:
父类加载...
子类加载...
子类运行...
123456789101112131415161718192021
除此之外所有引用类的方式都不会触发初始化称为被动引用,下面是3个被动引用例子:
- 通过子类引用父类静态字段,不会导致子类初始化
- 通过数组定义引用类,不会触发此类的初始化
public class SuperClass {
static {
System.out.println("SuperClass(父类)被初始化了。。。");
}
public static int value = 66;
}
public class Subclass extends SuperClass {
static {
System.out.println("Subclass(子类)被初始化了。。。");
}
}
public class Test1 {
public static void main(String[] args) {
// 1:通过子类调用父类的静态字段不会导致子类初始化
// System.out.println(Subclass.value);//SuperClass(父类)被初始化了。。。
// 2:通过数组定义引用类,不会触发此类的初始化
SuperClass[] superClasses = new SuperClass[3];
// 3:通过new 创建对象,可以实现类初始化,必须把1下面的代码注释掉才有效果不然经过1的时候类已经初始化了,下面这条语句也就没用了。
//SuperClass superClass = new SuperClass();
}
}
123456789101112131415161718192021222324252627
- 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用定义常量的类,因此不会触发定义常量的类的初始化。
加载
加载过程:
- 通过类型的完全限定名,产生一个代表该类型的二进制数据流(没有指明从哪里获取、怎样获取,是一个非常开放的平台),加载源包括:文件(Class文件,Jar文件)、网络、计算生成(代理$Proxy)、由其它文件生成(jsp)、数据库中;
- 解析这个二进制数据流为方法区内的运行时数据结构;
- 创建一个表示该类型的java.lang.Class类的实例,作为方法区这个类的各种数据的访问入口。
校验
验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。从整体上看,验证阶段大致上会完成4个阶段的校验工作:文件格式、元数据、字节码、符号引用。可以通过设置参数略过。
准备
准备阶段正式为类变量分配内存并设置变量的初始值。这些变量使用的内存都将在方法区中进行分配。注:这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
初始值通常是数据类型的零值;对于:public static int value = 123,那么变量value在准备阶段过后的初始值为0而不是123,这时候尚未开始执行任何java方法,把value赋值为123的动作将在初始化阶段才会被执行。对于:public static final int value = 123;编译时Javac将会为value生成ConstantValue(常量)属性,在准备阶段虚拟机就会根据ConstantValue的设置将value赋值为123。
解析
解析阶段是虚拟机将常量池中的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。
符号引用(Symbolic References): 符号引用以一组符号来描述所引用的目标,符号可以是符合约定的任何形式的字面量,符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。
直接引用(Direct References): 直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用与虚拟机实现的内存布局相关,引用的目标必定已经在内存中存在。
初始化
到了初始化的阶段,才是真正开始执行类中定义的Java程序代码。
- 初始化阶段是执行类构造器
()
public class InitTest1 {
static {
i = 0; //给变量赋值可以正常编译
System.out.println(i); //编译器提示:“非法向前引用”
}
static int i = 1;
}
123456789
- 父类中定义的静态语句块要优于子类的变量赋值操作。
- 如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生产
() - 虚拟机会保证一个类的
() () ()
类加载器
对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性。如果两个类来源于同一个Class文件,只要加载它们的类加载器不同,那么这两个类就必定不相等。
启动类加载器(Bootstrap ClassLoader): 这个类加载器负责将存放在\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。getClassLoader()方法返回null。
扩展类加载器(Extension ClassLoader): 这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
应用程序类加载器(Application ClassLoader): 这个类加载器由sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
双亲委派模型
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。这里类加载器之间的父子关系一般不会以继承的关系来实现,而都是使用组合的关系复用父类加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。

使用双亲委派模型来组织类加载器之间的关系,有一个显而易见的好处就是java类随着它的类加载器一起具备了一种带有优先级的层次关系。
双亲委派模型的实现:
protected synchronized Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
//1 首先检查类是否被加载
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
//2 没有则调用父类加载器的loadClass()方法;
c = parent.loadClass(name, false);
} else {
//3 若父类加载器为空,则默认使用启动类加载器作为父加载器;
c = findBootstrapClass0(name);
}
} catch (ClassNotFoundException e) {
//4 若父类加载失败,抛出ClassNotFoundException 异常后
c = findClass(name);
}
}
if (resolve) {
//5 再调用自己的findClass() 方法。
resolveClass(c);
}
return c;
}
123456789101112131415161718192021222324
java.lang.ClassLoader 的 loadClass() 实现了双亲委派模型的逻辑,因此自定义类加载器一般不去重写它,但是需要重写 findClass() 方法。
虚拟机字节码执行引擎
运行时的栈帧结构
栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每一个方法从调用开始至执行完成的过程,都对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。

局部变量表
局部变量表是一组变量值存储空间,用于存放方法参数和方法内定义的局部变量。局部变量表的容量以变量槽(Variable Slot)为最小单位。 一个Slot可以存放一个32位以内(boolean、byte、char、short、int、float、reference和returnAddress)的数据类型,reference类型表示一个对象实例的引用。对于64位的数据类型(long和double),虚拟机会以高位对齐的方式为其分配两个连续的Slot空间,是线程安全的。
为了节省栈帧空间,局部变量Slot可以重用,方法体中定义的变量,其作用域并不一定会覆盖整个方法体。如果当前字节码PC计数器的值超出了某个变量的作用域,那么这个变量的Slot就可以交给其他变量使用。这样的设计会带来一些额外的副作用,比如:在某些情况下,Slot的复用会直接影响到系统的收集行为。
操作数栈
操作数栈(Operand Stack)是一个后入先出栈。当一个方法执行开始时,这个方法的操作数栈是空的,在方法执行过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是出栈/入栈操作。
动态连接
每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接;
方法返回地址
方法退出的过程实际上等同于把当前栈帧出栈,因此退出时可能执行的操作有:恢复上层方法的局部变量表和操作数栈,把返回值(如果有的话)压入调用者栈帧的操作数栈中,调整PC计数器的值以指向方法调用指令后面的一条指令等。
方法调用–解析
方法调用并不等同于方法的执行,方法调用阶段的唯一任务就是确定被调用方法的版本(继承和多态)。
“编译期可知,运行期不可变”的方法(静态方法和私有方法),在类加载的解析阶段,会将其符号引用转化为直接引用(入口地址)。这类方法的调用称为解析(Resolution)
方法调用–分派
静态分派最典型的应用就是方法重载。
在运行期根据实际类型确定方法执行版本的分派过程称为动态分派。最典型的应用就是方法重写。
Java语言的静态分派属于多分派类型,动态分派属于单分派类型。