(未完成)【Redis专题】一线大厂Redis高并发缓存架构实战与性能优化
前言
在本章内容里,我希望大家还是要先看看【前置知识】的内容。按照我的大纲设计,我是想先给大家抛出一些大家比较陌生的,关于【Redis缓存问题以及缓存方案】的一些名词概念,再然后在正文【课程内容】里面给大家使用源码案例,然后优化演进的方式,逐步、尽可能地将【前置知识】中提到的这些内容给大家结合案例解释一下,帮助大家加深理解印象。
另外,说实在对于这个推演的过程理解还是有点门槛的,对于没有【并发意识】的同学来说,真的有点难度。我只能说我尽可能地,简单地给大伙讲解一下。
对了,我在推演过程中用到了【Redis分布式锁】,非常推荐大家看看我前面的文章《【Redis专题】大厂生产级Redis高并发分布式锁实战》,没有【并发意识】和【分布式锁】经验的同学墙裂建议看看,获取能得到那么一些灵感吧。
为什么要用Redis
听说,Redis、数据库、JVM级别扛并发能力如下:
| 层级 | Redis | Mysql | JVM |
|---|---|---|---|
| 扛并发能力 | Redis官宣单个节点10W+ | 主流说法数千到数万之间 | 百万级 |
解释一下:
- 这里说的扛并发能力是指,每秒同时做【读】操作的次数
- JVM级别其实是指内存级别,比如比较有名的:ecache
所以,你知道为什么要学,或者要用Redis了吗?
前置知识
在说缓存问题跟缓存方案之前,需要跟大家声明一句:没有绝对完美的方案,只有相对可靠的方案。别钻牛角尖哦同学们
一、缓存问题
1.1 缓存击穿
Q1:什么是缓存击穿?
答:也叫缓存失效。击穿,是指击穿了缓存,使得请求直达数据库,进而造成了数据库瞬间压力过大甚至挂掉。
记忆点:缓存中没有但是数据库有的数据
Q2:导致缓存击穿可能的原因是什么?
答:大量已存在的key同时失效。比如在电商场景下, 以前存在的做法是:批量上架一些热点商品到缓存中,由于批量操作,所以过期时间设置的一样。所以,在某些情况下造成:热点数据同时到达过期时间,接着大量用户进来。
Q3:缓存击穿如何解决?
答:批量添加缓存时,分散缓存过期时间(设置为一个时间段内的不同时间),避免相同时间段大量缓存失效。
给一个伪代码示例:
String get(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
//***设置一个过期时间(300到600之间的一个随机数)***
int expireTime = new Random().nextInt(300) + 300;
if (storageValue == null) {
cache.expire(key, expireTime);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
注意上面的过期时间。
1.2 缓存穿透
Q1:什么是缓存穿透?
答:缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上造成数据库短时间内承受大量请求而崩掉。
记忆点:缓存和数据库中都没有的数据
Q2:导致缓存穿透可能的原因是什么?
答:通常处于容错的考虑,存储层找不到数据不会写入都缓存层。正常情况是没问题的,可能导致缓存穿透的的情况如下:
- 自身业务代码或数据出现问题。这个比较难解释,但是楼主曾经在生产遇到过我一个同事,在一个定时器写了一个
while操作,反复获取一个不存在的数据(实际上是新增功能,上线时忘了准备一些初始化数据),导致死循环CPU超负荷运行,直接把系统搞炸了。(属于是自己玩自己了) - 一些恶意攻击、爬虫等造成大量空命中。通常是遭受外部攻击
Q3:缓存穿透如何解决?
答:有如下几点:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将keyvalue对写为key-空对象(不是null),缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。伪代码如下:
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
// 缓存空对象
cache.set(key, new TargetObject());
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
(注意:不同于网上其他版本,这里的建议是缓存一个空对象。为啥?说不出很好的理由。只能说,这算是一种比较好的规范。对于某些变量,给个有意义的初始值远比Null安全的多)
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
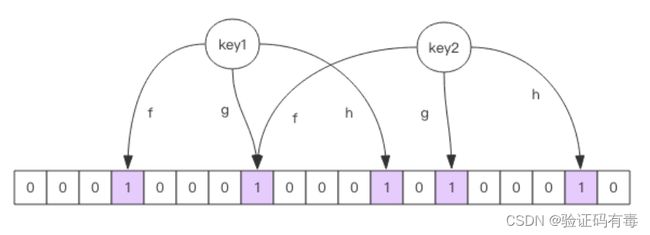
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀.
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组长度比较大,存在概率就会很大,如果这个位数组长度比较小,存在概率就会降低。(PS:总结一下:布隆过滤器认为这个key不存在那就一定不存在;布隆过滤器认为key存在,却不一定真的存在,只是极有可能存在。记住这一点,你基本上算是理解了布隆过滤器!!!)
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
(PS:重要的知识点说三遍)
(PS:重要的知识点说三遍)
(PS:重要的知识点说三遍)
布隆过滤器认为这个key不存在那就一定不存在;布隆过滤器认为key存在,却不一定真的存在,只是极有可能存在
在项目中使用Redisson实现布隆过滤器,引入依赖:
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.6.5version>
dependency>
测试代码:
package com.redisson;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小
bloomFilter.tryInit(100000000L,0.03);
//将test插入到布隆过滤器中
bloomFilter.add("test");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("test_1"));//false
System.out.println(bloomFilter.contains("test_2"));//false
System.out.println(bloomFilter.contains("test"));//true
}
}
但是正常来说,使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,这样才能起到过滤作用。布隆过滤器缓存过滤伪代码:(注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据)
// 第一步:初始化布隆过滤器
// 第一步:初始化布隆过滤器
// 第一步:初始化布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
bloomFilter.tryInit(100000000L,0.03); //初始化布隆过滤器:预计元素为100000000L,误差率为3%
// 第二步:预先把所有数据存入布隆过滤器
// 第二步:预先把所有数据存入布隆过滤器
// 第二步:预先把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
// 第三步:真正的使用场景了。Redis查询数据
// 第三步:真正的使用场景了。Redis查询数据
// 第三步:真正的使用场景了。Redis查询数据
String get(String key) {
// 先从布隆过滤器这一级缓存判断下key是否存在,防止缓存穿透
Boolean exist = bloomFilter.contains(key);
if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
// 缓存空对象
cache.set(key, new TargetObject());
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
1.3 缓存雪崩
Q1:什么是缓存雪崩?
答:缓存雪崩指的是缓存层支撑不住或宕掉后,流量会像奔逃的野牛一样,打向后端存储层,然后一层一层的滚雪球导致各个层宕机。由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务(比如超大并发过来,缓存层支撑不住,或者由于缓存设计不好,类似大量请求访问bigkey,导致缓存能支撑的并发急剧下降),于是大量请求都会打到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。
记忆点:缓存层撑不住,大量流量打向服务层,导致整体拒绝服务,或者级联宕机
Q2:导致缓存雪崩可能的原因是什么?
答:缓存层没有起到缓存作用,或者缓存作用没有达到预期。比如:
- 大量大key操作,长时间阻塞了Redis请求
Q3:缓存雪崩如何解决?
答:有如下几种方式:
- 保证缓存服务的高可用。比如搭建redis集群,使用Redis Sentinel或Redis Cluster
- 使用隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix组件,区分非核心数据和核心数据的处理方式
- 比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取
- 提前演练。在项目上线前, 演练缓存层宕掉后, 应用以及后端的负载情况以及可能出现的问题, 在此基础上做一些预案设定
二、缓存方案
2.1 普通缓存
基本介绍
查询数据时先查找缓存,如果有,则延长缓存时间并返回;如果没有,再去查找数据库,将查询的数据再写到缓存,同时设置过期时间。如果是静态热点数据,可以不设置缓存失效时间。
对应的伪代码:
public Target getTartget(String id) {
String key = getRedisKey(id);
String json = redisUtil.get(key);
if (StrUtil.isNotEmpty(json)) {
// 延长缓存时间
redisUtil.expire(key, 新的缓存时间);
return JSONObject.parse(json, Target.class);
}
Target target = dbUtil.get(id);
if (target != null) {
// 这里根据是否为热点数据,可以考虑是否要设置过期时间
redisUtil.set(key, JSONObject.toJSONString(target), 缓存时间);
}
return target;
}
2.2 冷热分离
基本介绍
在服务降级时,根据冷热数据做不同的处理。这个方案其实我们在上面【缓存雪崩】讲过大致的过程了。但是对于冷热数据需要大家自己根据业务去区分。这里给一点思路:
- 所谓冷数据:我们不常点击,不常使用的数据。例如美团APP,用户个人信息,就是冷数据;
- 所谓热数据:我们常点击,常使用的数据。还是美团APP。首页推广信息肯定是热数据,无论谁点开美团APP首页,显示的数据就是那些。如果这些数据每次都从数据库拿,那得多慢…
比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取
2.3 多级缓存
基本介绍
比如在redis前再加一级缓存JVM,一般是通过map存储数据。可以类似redis方案更新缓存,也可以使用redis的发布订阅功能、MQ、canal来实现与数据库的同步。也可以单独部署热点缓存系统,监测到热点数据主动同步到分布式系统中。
值得注意的是,因为多引入了一级缓存,那在分布式的情况下,势必需要通过通信的方式更新新的一级缓存(就像Redis集群使用gossip协议更新节点一样)。通信就势必存在时间消耗,进而导致:短期的数据不一致性。所以建议大家使用多级缓存时,就不要就觉绝对一致了,否则会增加更大的维护成本。
2.4 缓存预热
基本介绍
热点重建缓存时,通过双检锁重建缓存:先查询,不存在需要重建缓存,重建缓存逻辑加入分布式锁,仅有一个请求能重建缓存,重建完成后,后面的请求都能获取到数据了。
对应的伪代码:
public Target getTartget(String id) {
String key = getRedisKey(id);
String json = redisUtil.get(key);
if (StrUtil.isNotEmpty(json)) {
// 延长缓存时间
redisUtil.expire(key, 新的缓存时间);
return JSONObject.parse(json, Target.class);
}
// 获取分布式锁
RLock rLock = redisson.getLock(lockKey);
rLock.lock();
try {
// 由于我们在外层已经设置了分布式锁,所以我们知道的
// 只要有一个去查库,然后设置到缓存,其他的没必要再去查库了
// 通过双重检查,我们把原本n个查库的请求,转变成了1个查库,n-1查缓存
// 再次检查缓存
if (StrUtil.isNotEmpty(json)) {
// 延长缓存时间
redisUtil.expire(key, 新的缓存时间);
return JSONObject.parse(json, Target.class);
}
Target target = dbUtil.get(id);
if (target != null) {
// 这里根据是否为热点数据,可以考虑是否要设置过期时间
redisUtil.set(key, JSONObject.toJSONString(target), 缓存时间);
}
} finaly {
rLock.unlock();
}
return target;
}
通过上面的例子我们可以看到,通过【缓存预热】,或者说【双检索】思想,我们把原本n个查库的请求,转变成了1个查库,n-1个查缓存
*课程内容
同学们有没有一种感觉,目前我们Java技术栈,出现的各种中间件也好,框架也好,似乎都是为了【电商场景】服务的。太难了…
一、一个案例引发的思考(电商场景)
public class ProductService {
@Autowired
private ProductDao productDao;
@Autowired
private RedisUtil redisUtil;
@Autowired
private Redisson redisson;
public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24;
@Transactional
public Product create(Product product) {
Product productResult = productDao.create(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult), PRODUCT_CACHE_TIMEOUT , TimeUnit.SECONDS);
return productResult;
}
@Transactional
public Product update(Product product) {
Product productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult), PRODUCT_CACHE_TIMEOUT , TimeUnit.SECONDS);
}
public Product get(Long productId) throws InterruptedException {
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
// 先从缓存拿数据,有就直接返回
product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
product = productDao.get(productId);
if (product != null) {
redisUtil.set(productCacheKey, JSON.toJSONString(product), PRODUCT_CACHE_TIMEOUT, TimeUnit.SECONDS);
}
return product;
}
}
上面的例子很简单,就是CRUD而已。我想,大家对于Redis缓存,很多人的使用都止于上述几个get、create、update方法的使用了吧?反正博主我就是,啊哈哈

如果你也是这么写的话,我想问问大伙儿,你们有没有思考过这里面会存在什么问题没有?可以好好拿笔写一下。尽可能地写出来,也对自己是一种锻炼了(大家也是看过我【前置知识】的各种缓存问题跟方案介绍了,多少能写一点吧)。我个人能看到的问题有如下:(百万流量下)
create方法的缓存时间是固定的,在批量插入场景下,可能会出现批量缓存同时过期,造成【缓存击穿(失效)】现象get方法在成功拿到缓存数据返回之后,没有延长缓存时间。有可能出现【热点数据】,或者最近使用过的数据缓存过期,造成【缓存击穿(失效)】现象get方法在没有拿到缓存,去查询数据库的时候,可能存在大量请求同时请求数据库,数据库压力暴增get方法对于Redis跟数据库都不存在的数据没有防备,可能会造成【缓存穿透】现象- … … (目前我能想到的就这些了)
好了,问题已经发现了,那让我们一起学习一下,在大厂里面,是如何写这些代码的!
首先,还是希望大家时刻对背景有个简单的印象:
- 分布式,多个tomcat
- 多线程,高并发,动不动就百万流量,吹牛逼都很爽
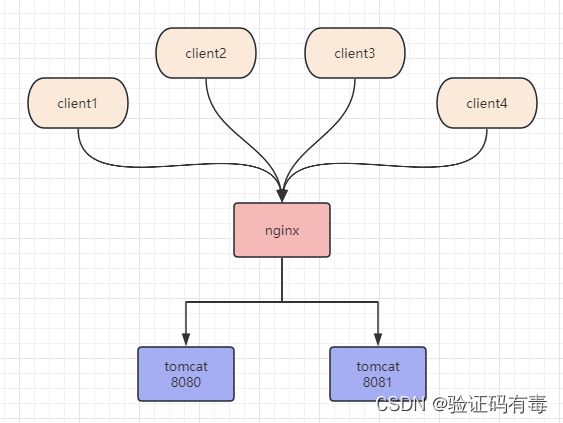
然后再附上一张,JD的主页:
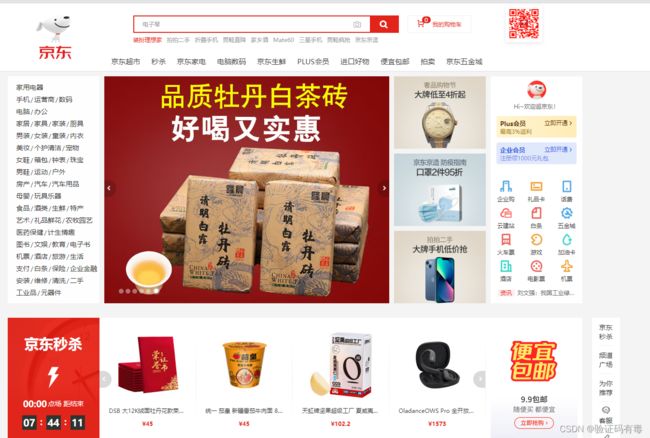
你们看上面吧,我们前面有简单分析过,像这种电商首页的数据,正常来说一定会缓存到Redis里面的,而且首页数据是超热数据,所以添加缓存的时候甚至不会设置过期时间。
二、优化方案的演进
上面那个版本
2.1 冷热分离方案推演
我们前面有大致介绍过【冷热分离】,这里重点在【冷】、【热】数据的区分。
学习总结
感谢
感谢我东哥的文章《一线大厂Redis高并发缓存架构实战与性能优化》