关系代数的问题与尝试(3)序运算与离散化
本文来自北京润乾软件技术有限公司董事长蒋步星在清华大数据产业联合会的讲座。
下面说序运算和离散化的问题。
人对有序计算是天然关心的。因为人最关心变化的东西,如果一个东西老不变,他不关心。这个东西变了,比昨天怎么样,比去年怎么样,他就会很关心,这个时候序运算就很重要了。
但是关系代数沿用了数学上的无序集合的概念,导致早期SQL没有办法直接做序运算。其实SQL的运算体系是完备的,它可以生成序号再去JOIN来实现序运算。
比如计算一只股票涨了多少钱,用早期SQL写出来是这样的:
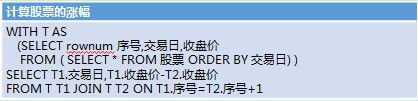
对于一个用C++或JAVA的程序员会觉得这不可思议,这个运算怎么要写得这么麻烦,但它就是这样。先用一个子查询生成序号,然后再拿这个临时表跟自己JOIN,用序号跟另一个序号加1连接,也就是某天跟昨天连接起来了,然后才能算出比上期。
这个设计,说它反人类都不过分。
2003年ANSI做了一个新SQL标准,增加了窗口函数,比上期运算不再反人类了,写起来就简单多了。

窗口函数允许引用相邻记录的信息,这就好多了。但不是所有数据库对窗口函数的支持都够好,ORACLE做得比较好,而业界很流行的开源数据库MySQL就不支持。
SQL无序还表现在它的计算过程无序。过程无序其实有个好处,就是容易并行,计算之间没有依赖性。但有些计算如果可以控制过程会简单许多。
比如我们想计算一支股票最长连续上涨了多少天,思路很简单,先清0,涨一天加一,不涨了再清零,最后取最大的那个数。
但SQL不是这么思维的:

这个句子我想了很久才搞出来,它的原理是把交易日分组,涨了就和前一天是同一组,跌了就换一个组,然后分组汇总计数找出最大的组。对于无序的SQL要凑出这个组就需要几层嵌套再加累积才能搞出来。
这也是我的招聘考题,但是我没有指望应聘者能短时间内做出来,而是写出这个句子问应聘者它想算什么,解释它的原理。
有序运算还和离散性相关,SQL有集合的概念,记录、对象的概念都有,但是关系代数没有设计游离记录的表示方式,也就是缺乏离散性,这又会造成麻烦。
比如我要找年龄最大的人,而不是最大的年龄:

SQL要用一个子查询,先把最大的年龄的找出来,再找谁是这个年龄的,这是SQL的标准写法。
再看一个稍复杂的例子,我要计算股价最高的那三天的平均涨幅:

类似地,SQL要先算出股价最高的那三天,再把每一天的涨幅算出来,再挑出日期在刚才那些日子里的交易,这样绕一下。其实我找到最高的那三天,再找每一天的前一天,只要知道这六天数据就可以了。
缺乏离散性,分组运算就要强制聚合,每次分组完了就要聚合,分组结果就不可复用了。我们有时候分组并不是要聚合结果,而是要分组后的子集。
我们再看例子,有哪些股票连涨了三天,其实这个蛮实用的,我看历史上涨了三天第四天还涨的股票比例有多高,可以指导我买股票。
SQL这个算法又比较绕。

常规思路是先按股票先分组,运算就简化成一支股票的事情了,但SQL的分组不可复用,你必须在一个句子中把分组和序运算一起解决,到处要加上partition,而且算连涨三天,你要跟昨天、前天比,想算连涨第四天时,你就要写四行,连涨N天就不知道怎么做了。
关系代数强调集合性,但缺乏离散性,离散性和有序运算又是结合在一起的。显然集合性也很重要,我们就需要一个既有离散性又有集合性的运算模型,它可以很好地支持批量的有序计算。
其实在数据库发明之前的那些高级语言的离散性都比较好,说白了就是数组,象C++,JAVA都有很好的离散性。但高级语言的集合性又不好,集合性要求动态语言,因为经常需要针对集合的每个成员做同样的运算,这些运算在编译型的高级语言中要表现为函数指针,用起来很不方便,而在SQL这类解释语言中表现为表达式,很方便。
我们希望把这两点结合起来,在关系代数中引入离散性及有序集合。数据的运算不仅跟数据本身有关,还和它在集合中的位置有关,你设计的这个形式语言要能够让你引用和描述数据以及它的位置,它的前一个、后一个等等。我把这种运算称为离散集合运算。

有了离散集合的运算,刚才那些问题都很好容易解决了。
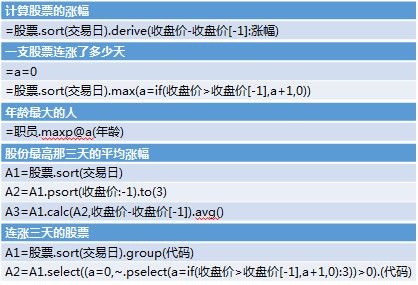
这是我们做的一个程序设计语言,这里我没有学SQL的风格让它像英语,还是把它形式化,反正是程序人员使用。
在这个体系下,上面那些运算都不困难,而且很直观,其实按照自然思维去写就完了。自己减自己的上一天就是涨幅;连涨了多少天,大了+1,否则就清零。我找到最高的三天的位置,对照位置算涨幅。有序离散性和集合运算结合起来,会让很多运算写起来轻松得多。
不只是写起来轻松,有序化还有很多别的应用。
我们可以提供按位置分组的功能,或者按相邻数据分组,SQL只有等值分组,相等的值被分到一个组,但是我们有时需要按位置分组。比如一段日志文本,每三行一个单位,如果用SQL处理就比较头疼,而要是有按照位置分组,按行号除以三分组就可以得到每个完整的单位去处理。
还有的是不定行的,每一段单位日志会有一个边界标志。这个时候我们需要按照相邻的数据来分组,原始数据本身是有序的,我们走到一个边界标志就新分出一个组,支持有序运算时我能比较方便能定义出这种分组方式。同时有了离散性,我能获得每个组对应的子集,我并不是为了汇总,我是把子集合留着再做复杂运算。
我们经常要做用户行为分析,用户行为是个很复杂的事情。比如我想算一下哪些用户最近三周每周都有连续三天在线,这个运算挺复杂的,不太容易在数据库里面做出来,你要把数据读出来再写一个程序来算。大数据的时候,全读内存又装不下,但是如果没有有序的分组机制,就很难保证每次顺序地读入一个组的数据。用SQL原则上要遍历所有数据,加上索引会好很多,但还是要满表找。
有了有序分组机制后,可以事先把数据按用户排序,然后每次读入一组进行复杂运算,这种机制还容易实现并行计算,每个任务从数据某个点开始分配,计算某一片数据。传统的SQL体系很难高性能地做到这样。
顺便说一句,HADOOP的文件拆分方案也不支持有序分组拆分,处理不定行记录时很难并行。
另外关于连接运算的优化,在前面讲关联性时也说过。有序时可以用归并算法来做连接外键可以用指针或序号的办法优化。做分析时数据仓库的数据是只读的,可以事先把外键准备成序号。