ClickHouse进阶(十五):Projection投影

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
个人主页:含各种IT体系技术,IT贫道_大数据OLAP体系技术栈,Apache Doris,Kerberos安全认证-CSDN博客
订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. Projection投影介绍
2. 创建Projection投影测试
3. explain验证是否使用Projection优化
4. Projection支持预聚合
5. 删除Projection投影
6. Projection投影总结
在使用clickhouse MergeTree引擎时,如果某张MergeTree表建表排序规则如下:
order by A,B,C那么通常过滤查询Where A很快,但是Where C会慢一些。
此外,我们在使用物化视图时,经常基于一张底表构建许多物化视图,以帮助更进一步提升查询性能、降低数据分析开销,例如:
#创建普通MergeTree 表作为底表
create table personinfo(id UInt32,name String,age UInt32,score UInt32) engine = MergeTree() order by id;
#基于以上底表创建统计平均年龄物化视图表
create materialized view t_view1 engine = Log as select sum(age)/count(name) as avg_age from personinfo;
#基于以上底表创建统计每人总分数物化视图表
create materialized view t_view2 engine = Log as select name,sum(score) as total_score from personinfo group by name;
#向表personinfo中插入以下数据
insert into personinfo values (1,'zs',18,100),(2,'ls',19,200),(3,'ww',20,300),(4,'zs',18,400),(5,'ls',19,500),(6,'ww','20',600);
#查询t_view1与t_view2两张物化视图结果
node1 :) select * from t_view1;
┌─avg_age─┐
│ 19 │
└─────────┘
node1 :) select * from t_view2;
┌─name─┬─total_score─┐
│ ls │ 700 │
│ ww │ 900 │
│ zs │ 500 │
└──────┴─────────────┘以上构建的物化视图实际上在clickhouse中相当于是独立的表,也会单独存储在数据目录“/var/lib/clickhouse/data/${DB}”中:
![]()
既然物化视图也是独立的表,那么就存在与原表数据一致性问题,如果物化视图很多,维护起来也是问题。
目前使用clickhouse我们遇到以上不完美的地方,总结下来就是:
- MergeTree只支持一种排序规则
- 物化视图不够智能
1. Projection投影介绍
clickhouse Projection功能的出现完美解决了以上两点不完美。Projection(投影)指一组列的组合,可以按照与原表不同的排序存储,并且支持聚合函数查询,可以将Projection看成一种更加智能的物化视图,与物化视图一样本质也是用空间换时间,其具备以下特点:
- part-level存储:
相比普通物化视图是一张独立的表,Projection 物化的数据就保存在原表的分区目录中,支持明细数据的普通Projection和预聚合Projection。
- 无感使用,自动命中:
可以对一张 MergeTree 创建多个 Projection ,当执行 Select 语句的时候,能根据查询范围,自动匹配最优的 Projection 提供查询加速。如果没有命中 Projection,就直接查询底表。
- 数据同源、同生共死:
因为物化的数据保存在原表的分区,所以数据的更新、合并都是同源的,也就不会出现不一致的情况了。
2. 创建Projection投影测试
下面我们通过案例来测试Projection的使用性能,示例如下:
#向MySQL 库ck_db中导入 song表,数据量为17万左右,在clickhouse库mysql_ck_db中会有对应的物化引擎表,这时在clickhouse默认default库中执行如下语句,将song表数据导入到default.song_info表中
node1 :) create table song_info engine=MergeTree() order by source_id partition by status as select * from mysql_ck_db.song;
#没有Projection的时候,查询非主键name列
node1 :) select name from song_info where name = '独家女孩';
1 rows in set. Elapsed: 0.017 sec. Processed 177.31 thousand rows, 4.16 MB (10.68 million rows/s., 250.61 MB/s.)针对name列创建一个Projection,为特定的where字段加速,按照查询的需求生成有别于主键的另一种排序规则:
ALTER TABLE song_info ADD PROJECTION p1
(
SELECT
name,album
ORDER BY name
)注意:只有在创建Projection之后,再被写入的数据才会自动物化,对于历史数据需要执行如下命令手动触发物化:
ALTER TABLE song_info MATERIALIZE PROJECTION p1;我们可以执行如下命令查询物化是否完成:
SELECT
table,
mutation_id,
command,
is_done
FROM system.mutations AS m
where table = 'song_info';
以上完成后,我们可以进入到song_info数据目录:“/var/lib/clickhouse/data/default/song_info/”,发现生成新的数据目录:
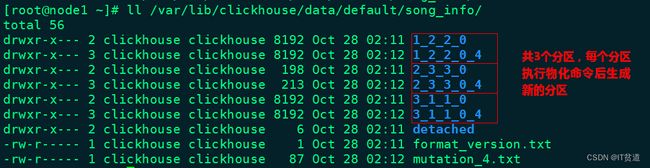
且每个分区对应的新目录中多了一个p1.proj子目录,进入到此子目录,我们发现与MergeTree表存储格式一样,如下:
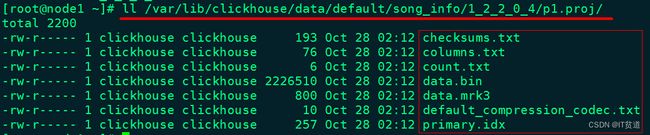
有了p1 projection后我们执行同样查询,首先需要设置参数开启projection功能:
SET allow_experimental_projection_optimization = 1;开启之后,重新执行原有的SQL,我们发现由原来扫码4.16M数据变成了扫描407Kb数据:
node1 :) select name from song_info where name = '独家女孩';
1 rows in set. Elapsed: 0.011 sec. Processed 17.08 thousand rows, 407.83 KB (1.60 million rows/s., 38.23 MB/s.)3. explain验证是否使用Projection优化
我们可以执行如下命令来查看执行的SQL是否使用了Projection功能:
node1 :)explain select name from song_info where name = '独家女孩'; 
如上,如果看到“MergeTree(with 0 projection p1)”代表使用了Projection优化。
4. Projection支持预聚合
projection同样支持预聚合,在没有优化的情况下,以下查询会全表扫描:
node1 :) select source,count(*) from song_info group by source;
7 rows in set. Elapsed: 0.011 sec. Processed 177.31 thousand rows, 886.58 KB (16.12 million rows/s., 80.60 MB/s.)创建另外一个Projection:
ALTER TABLE song_info ADD PROJECTION agg_p2
(
SELECT
source,
count(*)
GROUP BY source
)由于历史数据存在,需要手动触发下物化:
ALTER TABLE song_info MATERIALIZE PROJECTION agg_p2;执行完成之后,再次执行相同查询:
node1 :) select source,count(*) from song_info group by source;
7 rows in set. Elapsed: 0.009 sec.可以通过以上看出速度快了很多。
5. 删除Projection投影
我们可以执行如下命令删除Projection:
node1 :) ALTER TABLE song_info DROP PROJECTION p1;
node1 :) ALTER TABLE song_info DROP PROJECTION agg_p2;6. Projection投影总结
在使用Projection时,查询使用Projection的匹配规则如下:
- 设置SET allow_experimental_projection_optimization = 1
- 返回的数据行小于基表总数
- 查询覆盖的分区part超过一半
- Where必须是Projection定义中Group By的子集
- Group By必须是Projection定义中Group By的子集
- Select 必须是Projection定义中Select的子集
- 匹配多个Projection的时候,自动选取读取part最少的
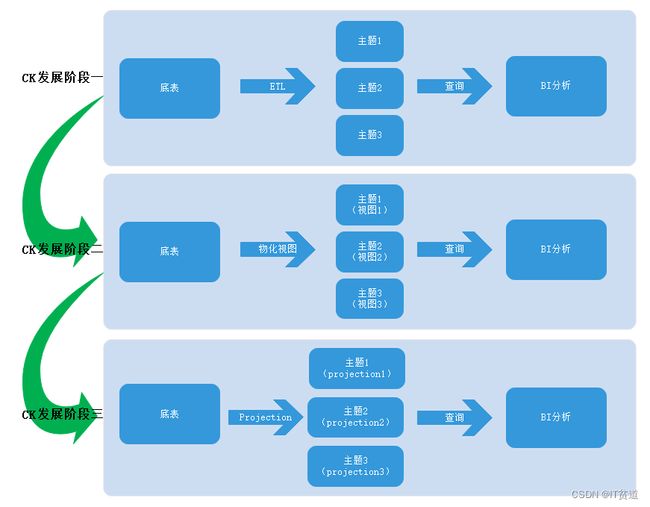
利用Projection,我们只需要面对一张表查询就行,即拥有了原来物化视图的性能,又免去了维护成本与数据一致性的问题,相信未来可以使用Projection替换物化视图。
如需博文中的资料请私信博主。