2022年第一届HiPChips解读
High Performance Chiplet and Interconnect Architectures,2022年6月19日,第一届会议(连同第49界ISCA会议)于美国纽约举行。
第一届会议议程及slice:(HiPChips Chiplet Workshop @ ISCA Conference)[https://www.opencompute.org/events/past-events/hipchips-chiplet-workshop-isca-conference]
主题
- Chiplet-based accelerator level parallelism (ALP)
- Chiplet architecture for large scale system design
- Physical and logical inter-die interface design for heterogeneous architectures
- Coherent and non-coherent data sharing protocols via fast chiplet interconnection
- Chiplet architectures for in-memory computing and other emerging technologies
- ODSA-based 3D architecture for efficient ML acceleration
- Chiplet-based secure computing
- Power evaluation and performance modeling of chiplet architecture
- Software optimization framework with fast inter-chiplet network
- Chiplet topology aware ML optimizations
- Scheduling for massive heterogeneous chiplet-based processors
如何将数据在chiplets间划分,以及为了更高效的并行处理而优化数据迁移成为成功的关键。
议题
Memory Centric Computing
系统功耗的62.7%都花在数据迁移上。
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, and Onur Mutlu, "Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks"Proceedings of the 23rd International Conference on Architectural Support for Programming
Languages and Operating Systems (ASPLOS), Williamsburg, VA, USA, March 2018.
Chiplet-based Waferscale Computing
基于Chiplet的晶圆级计算
HALO: A Compiler Framework for Chiplet Architectures
异构架构的软件编译框架。阿里云从2017年开始投入建设的震旦异构计算开放平台(HALO/ODLA),因其可裁剪可扩展的轻量级接口、极简的内存足迹、和内禀的异构并行支持,非常适宜于作为小芯片加速系统的软硬协同计算平台。
研究者:Weiming Zhao, Weifeng Zhang

High-Bandwidth Density, Energy-Efficient, Short-Reach Signaling that Enables Massively Scalable Parallelism
能够大规模并行标量计算的高带宽密度、能效、短距的信号输出。讨论了off-chip和off-package的带宽极限,描述了大量数据传输场景下提高的chip-to-chip传输带宽的单端信号的输出方法,提出了在organic封装和PCB层级的方法 Ground-Referenced Signaling,在interposer层级使用Simultaneous Bidirectional Signaling;也说明了2.5D封装的chip-to-chip大带宽传输仍然存在数据传输功耗过大的挑战。
Speaker: John Wilson ( Nivida )
计算架构升级的目标:每watt增加的计算性能
封装外带宽的演变:

Heterogeneous Chiplet-based Architecture for In-Memory Acceleration of DNNs
用于DNN存内计算加速的异构chiplet架构。针对加速深度学习网络的计算,提出了一个新的chiplet架构——大小IMC核混合的异构,并就该架构构建了一套软件模拟环境SIAM,并集成了性能、面积评估工具。
Speaker:

大数据处理给硬件平台提出了更高的要求。
存内计算(IMC)为缓解冯诺伊曼瓶颈提供了可实现的方法。
基于crossbar的架构为深度学习网络的计算提供了很好的平台。
IMC加速器使用了一种权重值固定在片上的架构。因此IMC大芯片将因为更大的面积导致更多的功耗,因此2.5D封装的chiplet设计将是一个替代选项。
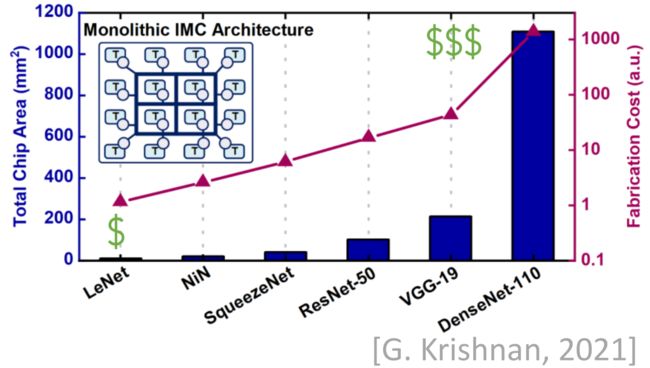
RRAM/SRAM的实践已经为基于chiplet的IMC架构进行了探索。
用户可以调试参数来对架构进行调整,包括映射、架构划分、IMC单元特征等。
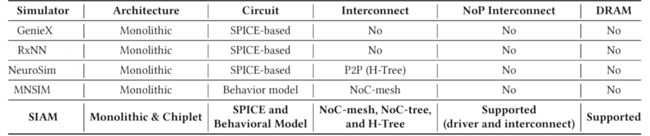
工作流程
将DNN参数、架构参数输入进SIAM,SIAM进行参数与资源的映射,包括片上互联和板级互联,并构建计算平台。评估工具对整体架构进行性能、延迟等特征评估。

SIAM的输入包括

SIAM的计算架构如下:
组件颗粒可细化到具体的IMC cell,层次跨度较广。

数据流

大小chiplet混合的架构

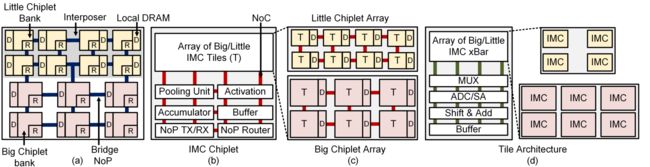
算法映射指在最大化IMC的使用率
集成较小IMC的小芯片群用于初始化或较小layer的计算,比较适合大数据迁移的场景;集成较大IMC的大芯片群用于更大更深的layer计算,比较适合小数据迁移的场景。
NoP用于将大数据传递到每个芯片群内。
同类型芯片相比
- 能效和面积

相关工作

Glass Interposer Integration of Logic and Memory Chiplets: PPA and Power/Signal Integrity Benefits
逻辑和memory chiplet的glass中间介质层。为2.5D和3D封装提出了一种新的中介介质层材料。
Speaker:
Pruek Vanna-iampikul, Serhat Erdogan, Mohanalingam Kathaperumal, Madhavan Swaminathan, and Sung Kyu Lim, Georgia Institute of Technology
Ram Gupta, Ravi Agarwal, Meta
Praveen Anmula, Kevin Reinbold, Siemens
Dual-Stripline Configuration for Efficient Signal Routing in the Bunch-of-Wires Interface
基于BoW接口的双条纹配置的高效信号路由方法。通过封装时两个die间的走线优化(Dual-Stripline configuration)通过封装的走线密度。
Speaker:
Shekar Geedimatla, Robin James Payyappillil, Devi Sreekumar, and Shalabh Gupta Department of Electrical Engineering, IIT Bombay, Mumbai – 400076, INDIA
BoW标准可以在基板上支持高密度的信号互联。
BoW的每个slice有16根信号,每根线提供16Gbps的传输带宽,一个slice最多提供256Gbps的带宽。

Chiplets’ march to AMD 3D V-Cache And Beyond
通往AMD 3D Vcache的chiplet之路
Speaker:
RAJA SWAMINATHAN, JOHN WUU
AMD Senior Fellow
其他链接
(“小芯片 大集成” 从软硬协同看Chiplet生态——ISCA 2022-HiPChips研讨会组织观察记)[https://mp.weixin.qq.com/s/IjkgsRREOxmm5X37zq_qEA]