flink DataStream API 官网整理-1.13
1. 版本说明
本文档内容基于 flink-1.13.x,其他版本的整理,请查看本人博客的 flink 专栏其他文章。
2. 事件时间
2.1. 生成 Watermark
在本节中,你将了解 Flink 中用于处理事件时间的时间戳和 watermark 相关的 API。有关事件时间,处理时间和摄取时间的介绍,请参阅事件时间概览小节。
2.1.1. Watermark 策略简介
为了使用事件时间语义,Flink 应用程序需要知道事件时间戳对应的字段,意味着数据流中的每个元素都需要拥有可分配的事件时间戳。其通常通过使用 TimestampAssigner API
从元素中的某个字段去访问/提取时间戳。
时间戳的分配与 watermark 的生成是齐头并进的,其可以告诉 Flink 应用程序事件时间的进度。其可以通过指定 WatermarkGenerator 来配置 watermark 的生成方式。
使用 Flink API 时需要设置一个同时包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy。WatermarkStrategy 工具类中也提供了许多常用的 watermark 策略,并且用户也可以在某些必要场景下构建自己的 watermark 策略。
WatermarkStrategy 接口如下:
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T> {
/**
* 根据策略实例化一个可分配时间戳的 {@link TimestampAssigner}实例
*/
@Override
TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);
/**
* 根据策略实例化一个 watermark 生成器。
*/
@Override
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
如上所述,通常情况下不用实现此接口,而是使用 WatermarkStrategy 工具类中通用的 watermark策略,或者使用这个工具类将自定义 **TimestampAssigner **与 **WatermarkGenerator **进行绑定。例如,你想要要使用有界无序(bounded-out-of-orderness)watermark 生成器和一个 lambda 表达式作为时间戳分配器,则可以按照如下方式实现:
java:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event, timestamp) -> event.f0);
scala:
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withTimestampAssigner(new SerializableTimestampAssigner[(Long, String)] {
override def extractTimestamp(element: (Long, String), recordTimestamp: Long): Long = element._1
})
其中 TimestampAssigner 的设置与否是可选的,大多数情况下,可以不用去特别指定。例如使用 Kafka 或 Kinesis 数据源时,可以直接从 Kafka/Kinesis 数据源记录中获取时间戳。
稍后我们将在自定义WatermarkGenerator 小节学习 WatermarkGenerator 接口。
注意:时间戳和 watermark 都是从 1970-01-01T00:00:00Z 起的 Java 纪元开始,并以毫秒为单位。
2.1.2. 使用 Watermark 策略
WatermarkStrategy 可以在 Flink 应用程序中两个地方使用:第一种是直接在数据源上使用,第二种是在非数据源之后使用。
第一种方式相比会更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息。使用这种方式,数据源通常可以更精准地跟踪 watermark,整体 watermark 生成将更精确。直接在源上指定 WatermarkStrategy 意味着你必须使用特定数据源接口,参阅 Watermark策略与 Kafka连接器以了解如何使用 Kafka Connector,以及有关每个分区的 watermark 是如何生成以及工作的。
仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy):
java:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<MyEvent> stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo);
DataStream<MyEvent> withTimestampsAndWatermarks = stream
.filter( event -> event.severity() == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>);
withTimestampsAndWatermarks
.keyBy( (event) -> event.getGroup() )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
scala:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream: DataStream[MyEvent] = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter())
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream
.filter( _.severity == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>)
withTimestampsAndWatermarks
.keyBy( _.getGroup )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) => a.add(b) )
.addSink(...)
使用 WatermarkStrategy 去获取流并生成带有时间戳的元素和 watermark 的新流时,如果原始流已经具有时间戳或 watermark,则新指定的时间戳分配器将覆盖原有的时间戳和 watermark。
2.1.3. 处理空闲数据源
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark。我们称这类数据源为空闲输入或空闲源。在这种情况下,当其他分区仍然发送事件数据的时候就会出现问题。由于下游算子watermark 的计算方式是取所有不同的上游并行数据源 watermark的最小值,所以其 watermark 将不会发生任何变化。
为了解决这个问题,可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态。WatermarkStrategy 为此提供了一个工具接口:
java:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
scala:
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1))
2.1.4. 自定义 WatermarkGenerator
TimestampAssigner 是一个可以从事件数据中提取时间戳字段的简单函数,我们无需详细查看其实现。但是 WatermarkGenerator 的编写相对就要复杂一些了,我们将在接下来的两小节中介绍如何实现此接口。WatermarkGenerator 接口代码如下:
/**
* {@code WatermarkGenerator} 可以基于事件或者周期性的生成 watermark。
* 注意:WatermarkGenerator 将以前互相独立的 {@code AssignerWithPunctuatedWatermarks} 和 {@code AssignerWithPeriodicWatermarks} 一同包含了进来。
*/
@Public
public interface WatermarkGenerator<T> {
/**
* 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,或基于事件数据本身去生成 watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 周期性的调用,也许会生成新的 watermark,也许不会。
* 调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。
*/
void onPeriodicEmit(WatermarkOutput output);
}
watermark 的生成方式本质上是有两种:周期性生成和标记生成。
周期性生成器通常通过 onEvent() 观察传入的事件数据,然后在框架调用 onPeriodicEmit() 时发出 watermark。
标记生成器将查看 onEvent() 中的事件数据,并等待检查在流中携带 watermark 的特殊标记事件或打点数据。当获取到这些事件数据时,它将立即发出 watermark。通常情况下,标记生成器不会通过 onPeriodicEmit() 发出 watermark。
接下来,我们将学习如何实现上述两类生成器。
2.1.4.1. 自定义周期性 Watermark 生成器
周期性生成器会观察流事件数据并定期生成 watermark(其生成可能取决于流数据,或者完全基于处理时间)。
生成 watermark 的时间间隔(每 n 毫秒)可以通过 ExecutionConfig.setAutoWatermarkInterval(...) 指定。每次都会调用生成器的 onPeriodicEmit() 方法,如果返回的
watermark 非空且值大于前一个 watermark,则将发出新的 watermark。
如下是两个使用周期性 watermark 生成器的简单示例。注意:Flink 已经附带了 BoundedOutOfOrdernessWatermarks,它实现了 WatermarkGenerator,其工作原理与下面的 BoundedOutOfOrdernessGenerator 相似。可以在这里参阅如何使用它的内容。
java:
/**
* 该 watermark 生成器可以覆盖的场景是:数据源在一定程度上乱序。
* 即某个最新到达的时间戳为 t 的元素将在最早到达的时间戳为 t 的元素之后最多 n 毫秒到达。
*/
class BoundedOutOfOrdernessGenerator extends WatermarkGenerator[MyEvent] {
val maxOutOfOrderness = 3500L // 3.5 秒
var currentMaxTimestamp: Long = _
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
currentMaxTimestamp = max(eventTimestamp, currentMaxTimestamp)
}
override def onPeriodicEmit(): Unit = {
// 发出的 watermark = 当前最大时间戳 - 最大乱序时间
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
/**
* 该生成器生成的 watermark 滞后于处理时间固定量。它假定元素会在有限延迟后到达 Flink。
*/
class TimeLagWatermarkGenerator extends WatermarkGenerator[MyEvent] {
val maxTimeLag = 5000L // 5 秒
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
// 处理时间场景下不需要实现
}
override def onPeriodicEmit(): Unit = {
output.emitWatermark(new Watermark(System.currentTimeMillis() - maxTimeLag));
}
}
scala:
/**
* 该 watermark 生成器可以覆盖的场景是:数据源在一定程度上乱序。
* 即某个最新到达的时间戳为 t 的元素将在最早到达的时间戳为 t 的元素之后最多 n 毫秒到达。
*/
class BoundedOutOfOrdernessGenerator extends WatermarkGenerator[MyEvent] {
val maxOutOfOrderness = 3500L // 3.5 秒
var currentMaxTimestamp: Long = _
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
currentMaxTimestamp = max(eventTimestamp, currentMaxTimestamp)
}
override def onPeriodicEmit(): Unit = {
// 发出的 watermark = 当前最大时间戳 - 最大乱序时间
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
/**
* 该生成器生成的 watermark 滞后于处理时间固定量。它假定元素会在有限延迟后到达 Flink。
*/
class TimeLagWatermarkGenerator extends WatermarkGenerator[MyEvent] {
val maxTimeLag = 5000L // 5 秒
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
// 处理时间场景下不需要实现
}
override def onPeriodicEmit(): Unit = {
output.emitWatermark(new Watermark(System.currentTimeMillis() - maxTimeLag));
}
}
2.1.4.2. 自定义标记 Watermark 生成器
标记 watermark 生成器会观察流事件数据并在获取到带有 watermark 信息的特殊事件元素时发出 watermark。
一下是实现标记生成器的方法,当事件带有某个指定标记时,该生成器就会发出 watermark:
java:
public class PunctuatedAssigner implements WatermarkGenerator<MyEvent> {
@Override
public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {
if (event.hasWatermarkMarker()) {
output.emitWatermark(new Watermark(event.getWatermarkTimestamp()));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 上面已经实现了对每个事件发出水印,所以这儿无需任何操作
}
}
scala:
class PunctuatedAssigner extends WatermarkGenerator[MyEvent] {
override def MyEvent(event: MyEvent, eventTimestamp: Long, output: WatermarkOutput): Unit = {
if (event.hasWatermarkMarker()) {
output.emitWatermark(new Watermark(event.getWatermarkTimestamp()))
}
}
override def onPeriodicEmit(output: WatermarkOutput): Unit = {
// 上面已经实现了对每个事件发出水印,所以这儿无需任何操作
}
}
注意:可以针对每个事件去生成 watermark。但是由于每个 watermark 都会在下游做一些计算,因此过多的 watermark 会降低程序性能。
2.1.5. Watermark 策略与 Kafka 连接器
当使用 Apache Kafka连接器作为数据源时,每个 Kafka 分区可能有一个简单的事件时间模式(递增的时间戳或有界无序)。然而,当使用 Kafka 数据源时,多个分区常常并行使用,因此交错来自各个分区的事件数据就会破坏每个分区的事件时间模式(这是Kafka 消费者客户端所固有的)。
在这种情况下,你可以使用 Flink 中可识别 Kafka 分区的 watermark 生成机制。使用此特性,将在 Kafka 消费端内部针对每个 Kafka 分区生成 watermark,并且不同分区 watermark 的合并方式与在数据流 shuffle 时的合并方式相同。
例如,如果每个 Kafka 分区中的事件时间戳严格递增,则使用时间戳单调递增按分区生成的 watermark 将生成完美的全局 watermark。注意,我们在示例中未使用 TimestampAssigner,而是使用了 Kafka 记录自身的时间戳。
下图展示了如何使用单 kafka 分区 watermark 生成机制,以及在这种情况下 watermark 如何通过 dataflow 传播。
java:
FlinkKafkaConsumer<MyType> kafkaSource = new FlinkKafkaConsumer<>("myTopic", schema, props);
kafkaSource.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(20)));
DataStream<MyType> stream = env.addSource(kafkaSource);
scala:
val kafkaSource = new FlinkKafkaConsumer[MyType]("myTopic", schema, props)
kafkaSource.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(20)))
val stream: DataStream[MyType] = env.addSource(kafkaSource)

2.1.6. 算子处理 Watermark 的方式
一般情况下,在将 watermark 转发到下游之前,需要算子对其触发的事件进行完全处理。例如,WindowOperator 将首先计算该 watermark 触发的所有窗口数据,当且仅当由此 watermark
触发计算,并将计算所有结果数据转发到下游之后,watermark 才会被发送到下游。换句话说,由于此 watermark 的出现而产生的所有数据元素都将在此 watermark 之前发出。
相同的规则也适用于 TwoInputStreamOperator。但是,在这种情况下,算子当前的 watermark 会取两个输入的最小值。
详细内容可查看对应算子的实现:OneInputStreamOperator#processWatermark、TwoInputStreamOperator#processWatermark1 和 TwoInputStreamOperator#processWatermark2。
2.1.7. 可以弃用 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 了
在 Flink 新的 WatermarkStrategy, TimestampAssigner 和 WatermarkGenerator的抽象接口之前,Flink 使用的是 AssignerWithPeriodicWatermarks和 AssignerWithPunctuatedWatermarks。你仍可以在 API 中看到它们,但建议使用新接口,因为其对时间戳和 watermark 等重点的抽象和分离很清晰,并且还统一了周期性和标记形式的 watermark 生成方式。
2.2. 内置 Watermark 生成器
如生成Watermark 小节中所述,Flink 提供的抽象方法可以允许用户自己去定义时间戳分配方式和 watermark 生成的方式。可以通过实现 WatermarkGenerator 接口来实现上述功能。
为了进一步简化此类任务的编程工作,Flink 框架预设了一些时间戳分配器。本节后续内容有举例。除了开箱即用的已有实现外,其还可以作为自定义实现的示例以供参考。
2.2.1. 单调递增时间戳分配器
周期性 watermark 生成方式的一个最简单的特例就是你给定的数据源中数据的时间戳是严格升序的。在这种情况下,当前时间戳可以直接作为 watermark,因为后续到达数据的时间戳不会比当前的小。
注意:在 Flink 应用程序中,如果是并行数据源,则只要求并行数据源中的每个单分区数据源任务时间戳递增即可,不需要所有分区中的数据时间戳整体严格递增。例如,设置每一个并行数据源实例都只读取一个 Kafka 分区,则时间戳只需在每个 Kafka 分区内递增即可。Flink 的 watermark 合并机制会在并行数据流进行分发(shuffle)、联合(union)、连接(connect)或合并(merge)时生成正确的 watermark。
java:
WatermarkStrategy.forMonotonousTimestamps();
scala:
WatermarkStrategy.forMonotonousTimestamps()
2.2.2. 数据之间存在最大固定延迟的时间戳分配器
另一个周期性 watermark 生成的典型例子是,watermark 滞后于数据流中最大(事件时间)时间戳一个固定的时间量。该示例可以覆盖的场景是你预先知道数据流中的数据可能遇到的最大延迟。例如,在测试场景下创建了一个自定义数据源,并且这个数据源产生数据的时间戳在一个固定范围之内。Flink 针对上述场景提供了 **boundedOutfordernessWatermarks **生成器,该生成器将 **maxOutOfOrderness **作为参数,该参数代表在计算给定窗口的结果时,允许元素被忽略计算之前延迟到达的最长时间。其中延迟时长就等于 t_w - t ,其中 t 代表元素的(事件时间)时间戳,t_w 代表前一个 watermark 对应的(事件时间)时间戳。如果 lateness > 0,则认为该元素迟到了,并且在计算相应窗口的结果时默认会被忽略。有关使用延迟元素的详细内容,请参阅有关允许延迟的文档。
java:
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
scala:
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
3. 状态与容错
3.1. 使用状态
在本章节,你将会学习如何使用flink提供的API来编写有状态的应用程序。在学习本章节前请先查看StatefulStreamProcessing来学习有状态流处理的相关概念。
3.1.1. Keyed DataStream
如果想使用 keyed state,需要先在一个 DataStream 上指定一个特殊的 key ,该 key 用来对状态进行分区,并且在流中记录他们。你可以在 java/scala 中使用 keyBy(KeySelector) 或者是在 Python API 中使用 key_by(KeySelector) 函数来对 DataStream 分区。上述方法将会产生一个 KeyedStream ,然后就可以在 KeyedStream 上使用 keyed state 了。
一个 key selector 函数会将单个记录作为输入,然后返回那个记录的 key 。 key 可以是任何类型,但是必须是确定性的计算结果。也就是说,对于同一个记录,调用多次 selector 函数,返回的 key 都是一样的结果。
flink 的数据模型并不是基于 k-v 对的,因此,我们无需将数据物理的包装成为 key 和 value 。key 是"虚拟的",他们被定义为:通过真实的数据调用函数产生结果 key ,然后对分组操作进行指导。
下面是一个例子,展示使用 key selector 函数来简单的返回对象的属性:
java:
public class WC {
public String word;
public int count;
public String getWord() {
return word;
}
}
DataStream<WC> words = [...];
KeyedStream<WC> keyed = words.keyBy(WC::getWord);
scala:
case class WC(word: String, count: Int)
val words: DataStream[WC] = // [...]
val keyed = words.keyBy( _.word )
python:
words = # type: DataStream[Row]
keyed = words.key_by(lambda row: row[0])
元组key和key表达式
flink 提供了两种可供选择的方式定义 key :元组的 key 和 key 表达式(java/scala API,目前不支持python API)。你可以指定元组的属性索引或者是使用表达式来选择对象的属性。我们不建议使用这些工具,可以参考DataStream的javadoc来学习他们。使用 KeySelector 函数是更优的选择:使用 java lambda 表达式更简单,而且在运行时还有不错的性能。
3.1.2. 使用 Keyed State
keyed state 接口提供了不同类型状态的访问接口,这些状态都和当前输入数据的 key 进行绑定。换句话说,这些状态仅可在 KeyedStream 上使用,在Java/Scala API上可以通过 stream.keyBy(...) 得到 KeyedStream,在Python API上可以通过 stream.key_by(…) 得到 KeyedStream。
接下来,我们会介绍不同类型的状态,然后介绍如何使用他们。所有支持的状态类型如下所示:
-
ValueState
: 保存一个可以更新和检索的值(如上所述,每个值都对应当前输入数据的 key,因此算子接收到的每个 key 都可能对应一个值,这个算子接收到的数据一共有多少个key,就可能有多少个值)。 这个值可以通过 update(T)进行更新,通过T value()进行检索。 -
ListState
: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T)或者addAll(List添加元素,通过) Iterable获得整个列表。还可以通过get() update(List覆盖当前的列表。) -
ReducingState
: 保存一个单值,表示添加到状态的所有值的聚合。接口与 ListState 类似,但使用 add(T)增加元素,会使用提供的 ReduceFunction 进行聚合。 -
AggregatingState
add(IN)添加的元素会用指定的 AggregateFunction 进行聚合。 -
MapState
put(UK,UV)或者putAll(Map添加映射。 使用) get(UK)检索特定 key。 使用entries(),keys()` 和 `values()分别检索映射、键和值的可迭代视图。你还可以通过isEmpty()来判断是否包不含任何键值对。
所有类型的状态还有一个 clear() 方法,清除当前 key 下的状态数据,这个key指的是当前输入元素的 key。
请牢记,这些状态对象仅用于与状态交互。状态本身不一定存储在内存中,还可能在磁盘或其他位置。另外需要牢记的是从状态中获取的值取决于输入元素所代表的 key。因此,在不同 key 上调用同一个方法,可能得到不同的值。
必须先创建一个 StateDescriptor,才能获取到对应的状态句柄。该对象保存了状态名称(可以创建多个状态,并且它们必须具有唯一的名称以便可以引用它们)、状态所持有值的类型,并且可能包含用户指定的函数,例如ReduceFunction。根据不同的状态类型,可以创建ValueStateDescriptor,ListStateDescriptor, AggregatingStateDescriptor, ReducingStateDescriptor 或 MapStateDescriptor。
状态通过 RuntimeContext 进行访问,因此只能在 rich functions 中使用。请参阅这里获取相关信息。RichFunction 中的 RuntimeContext 提供了如下方法:
- ValueState getState(ValueStateDescriptor)
- ReducingState getReducingState(ReducingStateDescriptor)
- ListState getListState(ListStateDescriptor)
- AggregatingState
- MapState
下面是一个 FlatMapFunction 例子,展示如何使用状态:
java:
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* 操作ValueState。第一个属性是数量,第二个属性是sum和。
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// 访问state value值
Tuple2<Long, Long> currentSum = sum.value();
// 更新count数量
currentSum.f0 += 1;
// 将输入的value值累加到第二个属性
currentSum.f1 += input.f1;
// 更新state状态
sum.update(currentSum);
// 如果count数量到达2,发射平均值,并且清空state状态
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // state状态名称
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() { // 类型信息
}));
sum = getRuntimeContext().getState(descriptor);
}
}
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
// 将会输出(1,4) 和 (1,5)
scala:
class CountWindowAverage extends RichFlatMapFunction[(Long, Long), (Long, Long)] {
private var sum: ValueState[(Long, Long)] = _
override def flatMap(input: (Long, Long), out: Collector[(Long, Long)]): Unit = {
// 访问state状态value值
val tmpCurrentSum = sum.value
// 如果状态值之前没被初始化,则将为null
val currentSum = if (tmpCurrentSum != null) {
tmpCurrentSum
} else {
(0L, 0L)
}
// 更新count数量
val newSum = (currentSum._1 + 1, currentSum._2 + input._2)
// 更新state状态
sum.update(newSum)
// 如果count到达2,则发射平均值并清空state状态
if (newSum._1 >= 2) {
out.collect((input._1, newSum._2 / newSum._1))
sum.clear()
}
}
override def open(parameters: Configuration): Unit = {
sum = getRuntimeContext.getState(
new ValueStateDescriptor[(Long, Long)]("average", createTypeInformation[(Long, Long)])
)
}
}
object ExampleCountWindowAverage extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.fromCollection(List(
(1L, 3L),
(1L, 5L),
(1L, 7L),
(1L, 4L),
(1L, 2L)
)).keyBy(_._1)
.flatMap(new CountWindowAverage())
.print()
// 将会输出(1,4) 和 (1,5)
env.execute("ExampleKeyedState")
}
这个例子实现了一个简单的计数窗口。 把元组的第一个元素当作 key(在示例中都 key 都是 “1”)。 该函数将出现的次数以及总和存储在 “ValueState” 中。 一旦出现次数达到 2,则将平均值发送到下游,并清除状态重新开始计算。注意,flink会为每个不同的key(输入值元组中第一个元素)保存一个单独的值。
3.1.2.1. 状态有效期 (TTL)
任何类型的 keyed state 都可以有有效期 (TTL)。如果配置了 TTL 且状态值已过期,flink就会尽最大可能清除对应的值。
所有集合状态类型都支持单元素的 TTL。这意味着list列表和map映射中的每个元素都将独立到期。
在使用状态 TTL 前,需要先构建一个 StateTtlConfig 配置对象。然后把配置传递到 state descriptor 中启用 TTL 功能:
java:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
scala:
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build
val stateDescriptor = new ValueStateDescriptor[String]("text state", classOf[String])
stateDescriptor.enableTimeToLive(ttlConfig)
TTL 配置有以下几个选项:
-
newBuilder 的第一个参数表示数据的有效期,是必选项。
-
TTL 的更新策略(默认是
OnCreateAndWrite):-
StateTtlConfig.UpdateType.OnCreateAndWrite- 仅在创建和写入时更新 -
StateTtlConfig.UpdateType.OnReadAndWrite- 读取时也更新
-
-
数据在过期但还未被清理时的可见性配置如下(默认为
NeverReturnExpired):-
StateTtlConfig.StateVisibility.NeverReturnExpired- 不返回过期数据 -
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp- 会返回过期但未清理的数据NeverReturnExpired 情况下,过期数据就像不存在一样,不管是否被物理删除。这在不能访问过期数据的场景下非常有用,比如敏感数据。
ReturnExpiredIfNotCleanedUp 在数据被物理删除前都会返回。
-
注意:
-
状态上次的修改时间会和数据一起保存在 state backend 中,因此开启该特性会增加状态数据的存储大小。 Heap state backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,RocksDB state backend 会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节。
-
暂时只支持基于 processing time 的 TTL。
-
尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,否则会遇到 “StateMigrationException”。
-
TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效。
-
当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null。如果用户值序列化器不支持 null,可以用 NullableSerializer 包装一层。
-
State TTL 当前在 PyFlink DataStream API 中还不支持。
3.1.2.1.1. 过期数据的清理
默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,同时会有后台线程定期清理(如果 StateBackend 支持的话)。可以通过 StateTtlConfig 配置关闭后台清理:
java:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.disableCleanupInBackground()
.build();
scala:
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.disableCleanupInBackground
.build
可以按照如下所示配置更细粒度的后台清理策略。当前的实现中 HeapStateBackend 依赖增量数据清理,RocksDBStateBackend 利用压缩过滤器进行后台清理。
3.1.2.1.1.1. 全量快照时进行清理
启用全量快照时进行清理的策略可以减少整个快照的大小。当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据。该策略可以通过 StateTtlConfig 配置进行配置:
java:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();
scala:
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot
.build
这种策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效。
注意:这种清理方式可以在任何时候通过 StateTtlConfig 启用或者关闭,比如在从 savepoint 恢复时。
3.1.2.1.1.2. 增量数据清理
增量式清理状态数据,在状态访问或/和处理时进行。如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器。每次触发增量清理时,从迭代器中选择已经过期的数进行清理。
该特性可以通过 StateTtlConfig 进行配置:
java:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build();
scala:
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build
该策略有两个参数。第一个是每次清理时检查状态的条目数,在每个状态被访问时触发。第二个参数表示是否在处理每条记录时触发清理。 Heap backend 默认会检查 5 条状态,并且关闭在每条记录时触发清理。
注意:
-
如果没有 state 访问,也没有处理数据,则不会清理过期数据。
-
增量清理会增加数据处理的耗时。
-
现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
-
如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,从而防止并发修改问题,因此会增加内存的使用。但异步快照则没有这个问题。
-
对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
3.1.2.1.1.3. 在 RocksDB 压缩时清理
如果使用 RocksDB state backend,则会启用 Flink 为 RocksDB 定制的压缩过滤器。RocksDB 会周期性的对数据进行合并压缩从而减少存储空间。Flink 提供的 RocksDB 压缩过滤器会在压缩时过滤掉已经过期的状态数据。
该特性可以通过 StateTtlConfig 进行配置:
java:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();
scala:
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build
Flink 处理一定条数的状态数据后,会使用当前时间戳来检测 RocksDB 中的状态是否已经过期,可以通过 StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries) 方法指定处理状态的条数。时间戳更新的越频繁,状态的清理越及时,但由于压缩会有调用 JNI 的开销,因此会影响整体的压缩性能。 RocksDB backend 的默认后台清理策略会每处理 1000 条数据进行一次。
可以通过配置开启 RocksDB 过滤器的 debug 日志:log4j.logger.org.rocksdb.FlinkCompactionFilter=DEBUG
注意:
-
压缩时调用 TTL 过滤器会降低速度。TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。 对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查。
-
对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器,从而确定下一个未过期数据的位置。
-
对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
3.1.2.2. DataStream 状态相关的 Scala API
除了上面描述的接口之外,Scala API 还在 KeyedStream 上对 map() 和 flatMap() 访问 ValueState 提供了一个更便捷的接口。用户函数能够通过 Option 获取当前 ValueState 的值,并且返回即将保存到状态的值。
val stream: DataStream[(String, Int)] = ...
val counts: DataStream[(String, Int)] = stream
.keyBy(_._1)
.mapWithState((in: (String, Int), count: Option[Int]) =>
count match {
case Some(c) => ( (in._1, c), Some(c + in._2) )
case None => ( (in._1, 0), Some(in._2) )
})
3.1.3. Operator State
Operator State (or non-keyed state) 会将状态绑定到算子实例的一个并行度。kafka 连接器就是一个很好的案例,该连接器使用了flink的Operator State。kafka消费者的每个并行度实例都包含一个主题分区的位移信息表来作为它的Operator State。
当算子并行度发生变化时,Operator State接口支持在算子的多并行度之间重新分发状态,该重分发有不同的操作类型。
在典型的有状态flink应用程序中是不需要Operator State的,Operator State通常用于source/sink实现,或者是某个算子没有key,而且state可以被分区。
注意:Operator State在Python API中不支持。
3.1.4. Broadcast State
Broadcast State是Operator State的一个特殊类型,他会将一个流中的记录广播到下游算子的所有分区,因此下游算子的所有分区都包含相同的状态。该状态可以在第二个流中的记录被处理时访问。举个例子,比如现在有一个低频率的流数据,并且里面包含的是一组规则,使用该状态就可以把他们分发到另一个流的所有并行度。广播状态不同于其他的状态:
-
他是map格式。
-
他仅可用于一个输入为广播流,另一个为非广播流的情况
-
一个算子可以有多个不同名称的广播流
注意:广播状态在Python API中不支持。
3.1.5. 使用 Operator State
用户可以通过实现 CheckpointedFunction 接口来使用 operator state。
3.1.5.1. CheckpointedFunction
CheckpointedFunction 接口提供了访问 non-keyed state 的方法,需要实现如下两个方法:
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;
进行 checkpoint 时会调用snapshotState()。用户自定义函数初始化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复。因此 initializeState() 不仅需要实现定义不同状态类型的初始化,也需要实现状态恢复的逻辑。
当前 operator state 以 list 的形式存在。这些状态是一个可序列化对象的List集合,彼此独立,方便在改变并发后进行状态的重新分配。换句话说,这些对象是重新分配 non-keyed state 的最细粒度。根据状态的不同访问方式,有如下几种重新分配的模式:
-
Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成。当作业恢复或重新分配的时候,整个状态会按照算子的并行度进行均匀分配。比如说,算子 A 的并行度为 1,包含两个元素 element1 和 element2,当并发读增加为 2 时,element1 会被分到并发 0 上,element2 则会被分到并发 1 上。
-
Union redistribution: 每个算子保存一个列表形式的状态集合。整个状态由所有的列表拼接而成。当作业恢复或重新分配时,每个算子都将获得所有的状态数据。list集合包含大量的元素,则不要使用该特性。checkpoint的元数据会对list集合的每个元素存储一个offset位移,如果List包含大量的元素,可能会导致RPC帧过大,或者是内存溢出。
下面的例子中的 SinkFunction 在 CheckpointedFunction 中进行数据缓存,然后统一发送到下游,这个例子演示了列表状态数据的 event-split 重分发。
java:
public class BufferingSink implements SinkFunction<Tuple2<String, Integer>>, CheckpointedFunction {
private final int threshold;
private transient ListState<Tuple2<String, Integer>> checkpointedState;
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void invoke(Tuple2<String, Integer> value, Context contex) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() >= threshold) {
for (Tuple2<String, Integer> element : bufferedElements) {
// 将数据写出
}
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for (Tuple2<String, Integer> element : bufferedElements) {
checkpointedState.add(element);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>("buffered-elements", TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {
}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
if (context.isRestored()) {
for (Tuple2<String, Integer> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
scala:
class BufferingSink(threshold: Int = 0) extends SinkFunction[(String, Int)] with CheckpointedFunction {
@transient
private var checkpointedState: ListState[(String, Int)] = _
private val bufferedElements = mutable.ListBuffer[(String, Int)]()
override def invoke(value: (String, Int), context: Context): Unit = {
bufferedElements += value
if (bufferedElements.size >= threshold) {
for (element <- bufferedElements) {
// send it to the sink
}
bufferedElements.clear()
}
}
override def snapshotState(context: FunctionSnapshotContext): Unit = {
checkpointedState.clear()
for (element <- bufferedElements) {
checkpointedState.add(element)
}
}
override def initializeState(context: FunctionInitializationContext): Unit = {
val descriptor = new ListStateDescriptor[(String, Int)]("buffered-elements", TypeInformation.of(new TypeHint[(String, Int)]() {})
)
checkpointedState = context.getOperatorStateStore.getListState(descriptor)
if (context.isRestored) {
for (element <- checkpointedState.get().asScala) {
bufferedElements += element
}
}
}
}
initializeState 方法接收一个 FunctionInitializationContext 参数,用来初始化 non-keyed state 的 “容器”。该容器是 ListState ,用于在 checkpoint 时保存 non-keyed state 对象。
和 keyed state 类似,StateDescriptor 会包括状态名字、以及状态类型相关信息。
java:
ListStateDescriptor<Tuple2<String, Integer>> descriptor = new ListStateDescriptor<>("buffered-elements", TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {
}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
scala:
val descriptor = new ListStateDescriptor[(String, Long)]("buffered-elements", TypeInformation.of(new TypeHint[(String, Long)]() {}))
checkpointedState = context.getOperatorStateStore.getListState(descriptor)
调用不同的获取状态对象的接口,会使用不同的状态分配算法。比如 getUnionListState(descriptor) 会使用 union redistribution 算法,而 getListState(descriptor) 则简单的使用even-split redistribution 算法。
当初始化好状态对象后,我们通过 isRestored() 方法判断是否从之前的故障中恢复回来,如果该方法返回 true 则表示从故障中进行恢复,然后执行接下来的恢复逻辑。
正如代码所示,BufferingSink 初始化时,恢复回来的 ListState 的所有元素会添加到一个局部变量中,供下次 snapshotState() 时使用,然后清空 ListState,再把当前局部变量中的所有元素写入到 checkpoint 中。
另外,我们同样可以在 initializeState() 方法中使用 FunctionInitializationContext 初始化 keyed state。
3.1.5.2. 带状态的 Source Function
带状态的数据源比其他的算子需要注意更多东西。为了保证更新状态以及输出的原子性(用于支持 exactly-once 语义),用户需要在发送数据前获取数据源的全局锁。
java:
public static class CounterSource extends RichParallelSourceFunction<Long> implements CheckpointedFunction {
/**
* 当前位移,支持恰好一次语义
*/
private Long offset = 0L;
/**
* 任务取消的标记
*/
private volatile boolean isRunning = true;
/**
* 我们的状态对象
*/
private ListState<Long> state;
@Override
public void run(SourceContext<Long> ctx) {
final Object lock = ctx.getCheckpointLock();
while (isRunning) {
// 输出和状态更新是原子操作
synchronized (lock) {
ctx.collect(offset);
offset += 1;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
state = context.getOperatorStateStore().getListState(new ListStateDescriptor<>("state", LongSerializer.INSTANCE));
// 恢复我们之前存储的状态数据
for (Long l : state.get()) {
offset = l;
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
state.clear();
state.add(offset);
}
}
scala:
class CounterSource extends RichParallelSourceFunction[Long] with CheckpointedFunction {
@volatile
private var isRunning = true
private var offset = 0L
private var state: ListState[Long] = _
override def run(ctx: SourceFunction.SourceContext[Long]): Unit = {
val lock = ctx.getCheckpointLock
while (isRunning) {
// 输出和状态更新是原子操作
lock.synchronized({
ctx.collect(offset)
offset += 1
})
}
}
override def cancel(): Unit = isRunning = false
override def initializeState(context: FunctionInitializationContext): Unit = {
state = context.getOperatorStateStore.getListState(new ListStateDescriptor[Long]("state", classOf[Long]))
for (l <- state.get().asScala) {
offset = l
}
}
override def snapshotState(context: FunctionSnapshotContext): Unit = {
state.clear()
state.add(offset)
}
}
如果想获取 checkpoint 成功消息的算子信息,可以参考 org.apache.flink.api.common.state.CheckpointListener 接口。
3.2. 广播状态模式
你将在本节中了解到如何实际使用 broadcast state。想了解更多有状态流处理的概念,请参考 Stateful StreamProcessing。
3.2.1. 提供的 API
在这里我们使用一个例子来展现 broadcast state 提供的接口。假设存在一个数据流,流中的元素是具有不同颜色与形状的图形数据,我们希望在相同颜色图形中寻找满足一定顺序模式的图形对(比如在红色的图形里,有一个长方形跟着一个三角形)。同时,我们希望寻找的规则也会随着时间而改变。
在这个例子中,我们定义两个流,一个流包含图形(Item),具有颜色和形状两个属性。另一个流包含特定的规则(Rule),代表希望寻找的规则。
在图形流中,我们需要首先使用颜色将流进行进行分区(keyBy),这能确保相同颜色的图形会流转到相同的并行度。
// 将图形使用颜色进行划分
KeyedStream<Item, Color> colorPartitionedStream = itemStream
.keyBy(new KeySelector<Item, Color>() {...
});
对于规则流,它应该被广播到所有的下游 task 中,下游 task 应当存储这些规则并根据它寻找满足规则的图形对。下面这段代码会完成:
-
将规则广播给所有下游 task;
-
使用 MapStateDescriptor来描述并创建 broadcast state 在下游的存储结构
// 一个 map descriptor,它描述了用于存储规则名称与规则本身的 map 存储结构 MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<String, Rule>( "RulesBroadcastState", BasicTypeInfo.STRING_TYPE_INFO, TypeInformation.of(new TypeHint<Rule>() { })); // 广播流,广播规则并且创建 broadcast state BroadcastStream<Rule> ruleBroadcastStream = ruleStream .broadcast(ruleStateDescriptor);
最终,为了使用规则来筛选图形流,我们需要:
-
将两个流关联起来
-
完成我们的模式识别逻辑
为了关联一个非广播流(keyed 或者 non-keyed)与一个广播流(BroadcastStream),我们可以调用非广播流的方法 connect(),并将 BroadcastStream 当做参数传入。这个方法的返回参数是 BroadcastConnectedStream,具有类型方法 process(),传入一个特殊的 CoProcessFunction 来书写我们的模式识别逻辑。具体传入 process() 的是哪个类型取决于非广播流的类型:
-
如果流是一个 keyed 流,那就是 KeyedBroadcastProcessFunction 类型;
-
如果流是一个 non-keyed 流,那就是 BroadcastProcessFunction 类型。
在我们的例子中,图形流是一个 keyed stream,所以我们书写的代码如下:
connect() 方法需要由非广播流来进行调用,BroadcastStream 作为参数传入。
DataStream<String> output = colorPartitionedStream
.connect(ruleBroadcastStream)
.process(
// KeyedBroadcastProcessFunction 中的类型参数表示:
// 1. keyed stream 中的 key 类型
// 2. 非广播流中的元素类型
// 3. 广播流中的元素类型
// 4. 结果的类型,在这里是 string
new KeyedBroadcastProcessFunction<Color, Item, Rule, String>() {
// 模式匹配逻辑
}
);
3.2.1.1. BroadcastProcessFunction 和 KeyedBroadcastProcessFunction
在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,我们需要实现两个方法。processBroadcastElement() 方法负责处理广播流中的元素,processElement() 方法负责处理非广播流中的元素。两个子类型定义如下:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
}
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception;
}
需要注意的是 processBroadcastElement() 负责处理广播流的元素,而 processElement() 负责处理另一个流的元素。两个方法的第二个参数(Context)不同,均有以下方法:
-
得到广播流的存储状态:
ctx.getBroadcastState(MapStateDescriptor -
查询元素的时间戳:
ctx.timestamp() -
查询目前的Watermark:
ctx.currentWatermark() -
目前的处理时间(processing time):
ctx.currentProcessingTime() -
产生旁路输出:
ctx.output(OutputTagoutputTag, X value)
在 getBroadcastState() 方法中传入的 stateDescriptor 应该与调用 .broadcast(ruleStateDescriptor) 的参数相同。
这两个方法的区别在于对 broadcast state 的访问权限不同。在处理广播流元素这端,是具有读写权限的,而对于处理非广播流元素这端是只读的。
这样做的原因是:**Flink 中是不存在跨 task 通讯的。**所以为了保证 broadcast state 在所有的并发实例中是一致的,我们在处理广播流元素的时候给予写权限,在所有的 task 中均可以看到这些元素,并且要求对这些元素处理是一致的, 那么最终所有 task 得到的 broadcast state 是一致的。
processBroadcastElement() 的实现必须在所有的并发实例中具有确定性的结果。
同时,KeyedBroadcastProcessFunction 在 Keyed Stream 上工作,所以它提供了一些 BroadcastProcessFunction 没有的功能:
-
processElement() 的参数 ReadOnlyContext 提供了方法能够访问 Flink 的定时器服务,可以注册事件定时器(event-time timer)或者处理时间的定时器(processing-time timer)。当定时器触发时,会调用
onTimer()方法,提供了 OnTimerContext,它具有 ReadOnlyContext 的全部功能,并且提供:-
查询当前触发的是一个事件时间还是处理时间的定时器
-
查询定时器关联的key
-
-
processBroadcastElement() 方法中的参数 Context 会提供方法
applyToKeyedState(StateDescriptor,KeyedStateFunction)。
这个方法使用一个 KeyedStateFunction 能够对 stateDescriptor 对应的 state 中所有 key 的存储状态进行某些操作。
注册一个定时器只能在 KeyedBroadcastProcessFunction 的 processElement() 方法中进行。在 processBroadcastElement() 方法中不能注册定时器,因为广播的元素中并没有关联的
key。
回到我们当前的例子中,KeyedBroadcastProcessFunction 应该实现如下:
new KeyedBroadcastProcessFunction<Color, Item, Rule, String>() {
// 存储部分匹配的结果,即匹配了一个元素,正在等待第二个元素
// 我们用一个数组来存储,因为同时可能有很多第一个元素正在等待
private final MapStateDescriptor<String, List<Item>> mapStateDesc =
new MapStateDescriptor<>(
"items",
BasicTypeInfo.STRING_TYPE_INFO,
new ListTypeInfo<>(Item.class));
// 与之前的 ruleStateDescriptor 相同
private final MapStateDescriptor<String, Rule> ruleStateDescriptor =
new MapStateDescriptor<>(
"RulesBroadcastState",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(new TypeHint<Rule>() {
}));
@Override
public void processBroadcastElement(Rule value,
Context ctx,
Collector<String> out) throws Exception {
ctx.getBroadcastState(ruleStateDescriptor).put(value.name, value);
}
@Override
public void processElement(Item value,
ReadOnlyContext ctx,
Collector<String> out) throws Exception {
final MapState<String, List<Item>> state = getRuntimeContext().getMapState(mapStateDesc);
final Shape shape = value.getShape();
for (Map.Entry<String, Rule> entry :
ctx.getBroadcastState(ruleStateDescriptor).immutableEntries()) {
final String ruleName = entry.getKey();
final Rule rule = entry.getValue();
List<Item> stored = state.get(ruleName);
if (stored == null) {
stored = new ArrayList<>();
}
if (shape == rule.second && !stored.isEmpty()) {
for (Item i : stored) {
out.collect("MATCH: " + i + " - " + value);
}
stored.clear();
}
// 不需要额外的 else{} 段来考虑 rule.first == rule.second 的情况
if (shape.equals(rule.first)) {
stored.add(value);
}
if (stored.isEmpty()) {
state.remove(ruleName);
} else {
state.put(ruleName, stored);
}
}
}
}
3.2.2. 重要注意事项
这里有一些 broadcast state 的重要注意事项,在使用它时需要时刻清楚:
-
没有跨 task通讯:如上所述,这就是为什么只有在 (Keyed)-BroadcastProcessFunction 中处理广播流元素的方法里可以更改 broadcast state 的内容。 同时,用户需要保证所有 task 对于 broadcast state 的处理方式是一致的,否则会造成不同 task 读取 broadcast state 时内容不一致的情况,最终导致结果不一致。
-
broadcast state 在不同的 task 的事件顺序可能是不同的:虽然广播流中元素的过程能够保证所有的下游 task 全部能够收到,但在不同 task 中元素的到达顺序可能不同。 所以
broadcast state 的更新不能依赖于流中元素到达的顺序。 -
所有的 task 均会对 broadcast state 进行 checkpoint:虽然所有 task 中的 broadcast state 是一致的,但当 checkpoint 来临时所有 task 均会对 broadcast state 做 checkpoint。这个设计是为了防止在作业恢复时同时读取同一文件造成文件热点。当然这种方式会造成 checkpoint 一定程度的写放大,放大倍数为 p(=并行度)。Flink 会保证在恢复状态/改变并发的时候数据没有重复且没有缺失。在作业恢复时,如果与之前具有相同或更小的并行度,所有的 task 都会读取之前已经 checkpoint 过的 state。在增大并发的情况下,原先的task 会读取本身的 state,多出来的并发(p_new - p_old)会使用轮询调度算法读取之前 task 的 state。
-
不使用 RocksDB state backend: broadcast state 在运行时保存在内存中,需要保证内存充足。这一特性同样适用于所有其他 Operator State。
3.3. checkpoint
Flink 中的每个方法或算子都可以是有状态的(阅读 working withstate 了解更多)。状态化的方法在处理单个 元素/事件 的时候会存储数据,从而使状态成为使各个类型的算子更加精细的重要部分。
为了状态容错,Flink 需要为状态添加 checkpoint(检查点)。Checkpoint 使得 Flink 能够恢复状态和数据在流中的位置,从而向应用提供和无故障执行时一样的语义。
容错文档 中介绍了 Flink 流计算容错机制内部的技术原理。
3.3.1. 前提条件
Flink 的 checkpoint 机制会和持久化存储进行交互,以读写流和状态。一般需要:
-
一个能够回放一段时间内数据的持久化数据源,例如持久化消息队列(Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub等)或文件系统(HDFS、 S3、 GFS、 NFS、 Ceph 等)。
-
存放状态的持久化存储,通常为分布式文件系统(比如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
3.3.2. 开启与配置 Checkpoint
默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒。
Checkpoint 其他的属性包括:
-
checkpoint存储:可以设置本地存储来进行checkpint快照的持久化。默认情况下,flink使用JobMamager的heap内存。在生产环境下,要求使用分布式文件系统。查看checkpoint存储来获取更多有关任务和集群存储选项的配置信息。
-
精确一次(exactly-once)与至少一次(at-least-once):可以向
enableCheckpointing(long interval, CheckpointingMode mode)方法中传入一个模式来选择使用两种保证等级中的哪一种。对于大多数应用来说,精确一次是较好的选择。至少一次可能与某些延迟超低(始终只有几毫秒)的应用关联较大。 -
checkpoint 超时:如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃。
-
checkpoints 之间的最小时间:该属性定义两次 checkpoint 之间需要间隔多久,以确保流应用在 checkpoint 之间有足够的间隔时间。如果设置为 5000,无论 checkpoint 持续时间与间隔是多久,在前一个 checkpoint 完成时的至少五秒后会才开始下一个 checkpoint。
-
使用"checkpoints 之间的最小时间"来配置应用会比 checkpoint 间隔容易很多,因为"checkpoints 之间的最小时间"在 checkpoint的执行时间超过平均值时不会受到影响(例如如果目标的存储系统忽然变得很慢)。
-
该值起作用,需要设置并发 checkpoint 数目为一。
-
-
checkpoint 可容忍连续失败次数:该属性定义可容忍多少次连续的 checkpoint 失败。超过这个阈值之后会触发作业错误 fail over。默认次数为"0",这意味着不容忍 checkpoint 失败,作业将在第一次 checkpoint 失败时fail over。
-
并发 checkpoint 的数目: 默认情况下,在上一个 checkpoint 未完成(失败或者成功)的情况下,系统不会触发另一个 checkpoint。这确保了拓扑不会在 checkpoint 上花费太多时间,从而影响正常的处理流程。不过允许多个 checkpoint 并行进行是可行的,对于有确定的处理延迟(例如某方法所调用比较耗时的外部服务),但是仍然想进行频繁的 checkpoint 去最小化故障后重跑的 pipelines 来说,是有意义的。
- 该选项不能和"checkpoints 间的最小时间"同时使用。
-
externalized checkpoints: 你可以配置周期存储 checkpoint 到外部系统中。Externalized checkpoints 将他们的元数据写到持久化存储上,并且在 job 失败的时候不会被自动删除。在这种方式下,如果你的 job 失败,你将会有一个现有的 checkpoint 去恢复。更多的细节请看 Externalized checkpoints的部署文档。
-
优先从 checkpoint 恢复(prefer checkpoint for recovery):该属性确定 job 是否在最新的 checkpoint回退,即使有更近的 savepoint 可用,这可以潜在地减少恢复时间(checkpoint 恢复比 savepoint 恢复更快)。
-
非对齐checkpoints: 可以开启非对齐checkpoint以在出现反压的情况下大幅减少checkpointing的时间。只有在恰好一次的checkpoint和并发checkpoint数目为1时可用。
java:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 1000ms 触发一次 checkpoint
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置两次 checkpoints 之间停留 500 毫秒
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 开启 externalized checkpoints,以使 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 开启实验性的 非对称checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();
// 设置checkpoint外部存储路径
env.getCheckpointConfig().setCheckpointStorage("hdfs://my/checkpoint/dir");
scala:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 每 1000ms 触发一次 checkpoint
env.enableCheckpointing(1000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 设置两次 checkpoints 之间停留 500 毫秒
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 开启 externalized checkpoints,以使 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// 开启实验性的 非对称checkpoints
env.getCheckpointConfig.enableUnalignedCheckpoints()
// 设置checkpoint外部存储路径
env.getCheckpointConfig.setCheckpointStorage("hdfs://my/checkpoint/dir")
3.3.2.1. 相关的配置选项
可以在conf/flink-conf.yaml 中设置更多的默认值(完整教程请阅读 配置)。
| Key | 默认值 | 类型 | 描述 |
|---|---|---|---|
| state.backend.incremental | false | Boolean | 如果可用的话,是否开启增量式checkpoint。对于增量式checkpoint,只有和上次checkpoint不同的装填会被存储,而不会全量的状态存储。开启该选项之后,web UI界面,或者是通过rest API获取到的数据,只代表增量checkpoint的大小,而不是全量checkpoint的大小。有些状态后端可能不支持增量式的checkpoint,并且忽略该选项。 |
| state.backend.local-recovery | false | Boolean | 是否状态后端进行本地恢复。默认情况下该选项是禁用的。本地恢复目前只支持keyed状态后端。目前,MemoryStateBackend不支持本地恢复,并且会忽略该选项。 |
| state.checkpoint-storage | (none) | String | checkpoint状态的存储实现。可以通过名称或者是CheckpointStorageFactory的类型来指定实现。如果指定了工厂实现类名称,则它的无参构造和CheckpointStorageFactory#createFromConfig(ReadableConfig, ClassLoader)方法将会被调用。 |
| state.checkpoints.dir | (none) | String | 指定flink支持的文件系统的目录,以存储checkpoint的数据文件和元数据。存储路径必须能够被所有参与的程序或节点(比如所有的TaskManager和JobManager)访问。 |
| state.checkpoints.num-retained | 1 | Integer | 可以保留的成功的checkpoint的最大数量。 |
| state.savepoints.dir | (none) | String | savepoint的默认路径。状态后端写入savepoint的文件系统路径(HashMapStateBackend, EmbeddedRocksDBStateBackend)。 |
| state.storage.fs.memory-threshold | 20 kb | MemorySize | 状态数据文件的最小size。所有小于该值的状态块都内联存储在根检查点元数据文件中。该配置的最大的内存阈值为1MB。 |
| state.storage.fs.write-buffer-size | 4096 | Integer | checkpoint流写入文件系统的默认写入大小。实际的写入缓冲大小将由该配置的最大值和 state.storage.fs.memory-threshold 配置共同决定。 |
| taskmanager.state.local.root-dirs | (none) | String | 该配置参数定义存储文件状态的根目录,以进行本地恢复。本地恢复目前只支持keyed状态后端。目前,MemoryStateBackend 不支持本地恢复,并且会忽略该配置。 |
3.3.3. 选择一个 State Backend
Flink 的 checkpointing机制会将 timer 以及 stateful 的 operator 进行快照,然后存储下来,包括连接器(connectors),窗口(windows)以及任何用户自定义的状态。Checkpoint 存储在哪里取决于所配置的 State Backend(比如 JobManager memory、 file system、 database)。
默认情况下,checkpoint 保存在 JobManager 的内存中。为了合适地持久化更大的状态,Flink 支持各种各样的途径去存储 checkpoint 状态到其他的状态后端。通过 StreamExecutionEnvironment.setStateBackend(...) 来配置所选的状态后端。
阅读 statebackends 来查看在 job 范围和集群范围上可用的状态与选项的更多细节。
3.3.4. 迭代作业中的状态和 checkpoint
Flink 现在为没有迭代(iterations)的作业提供了一致性的处理保证。在迭代作业上开启 checkpoint 会导致异常。为了在迭代程序中强制进行 checkpoint,用户需要在开启 checkpoint
时设置一个特殊的标志: env.enableCheckpointing(interval, CheckpointingMode.EXACTLY_ONCE, force = true)。
请注意在迭代边上游走的记录(以及与之相关的状态变化)在故障时会丢失。
3.4. 可被查询的状态
使用较少,先不做整理。
3.5. 状态后端
Flink 提供了多种 state backends,用于指定状态的存储方式和位置。
状态可以位于 Java 的堆内或堆外内存,取决于指定的 state backend,Flink 也可以自己管理应用程序的状态。为了让应用程序可以维护非常大的状态,Flink 可以自己管理内存(如果有必要可以溢写到磁盘)。默认情况下,所有 Flink Job 会使用配置文件 flink-conf.yaml 中指定的 state backend。
但是,配置文件中指定的默认 state backend 会被 Job 中指定的 state backend 覆盖,如下所示。
关于可用的 state backend 更多详细信息,包括其优点、限制和配置参数等,请参阅部署和运维的相应部分。
java:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(...);
scala:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStateBackend(...)
3.6. 状态数据结构升级
Apache Flink 流应用通常被设计为永远或者长时间运行。
与所有长期运行的服务一样,应用程序需要随着业务的迭代而进行调整。应用所处理的数据 schema 也会随着进行变化。
此页面概述了如何升级状态类型数据的 schema 。目前对不同类型的状态结构(ValueState、ListState 等)有不同的限制。
请注意,此页面的信息只与 Flink 自己生成的状态序列化器类型序列化框架相关。也就是说,在声明状态时,状态描述符不可以配置为使用特定的 TypeSerializer 或 TypeInformation ,在这种情况下,Flink 会推断状态类型的信息:
ListStateDescriptor<MyPojoType> descriptor =
new ListStateDescriptor<>(
"state-name",
MyPojoType.class);
checkpointedState = getRuntimeContext().getListState(descriptor);
在内部,状态是否可以进行升级取决于用于读写持久化状态字节的序列化器。简而言之,状态数据结构只有在其序列化器正确支持时才能升级。这一过程是被 Flink 的类型序列化框架生成的序列化器透明处理的(下面 列出了当前的支持范围)。
如果你想要为你的状态类型实现自定义的 TypeSerializer 并且想要学习如何实现支持状态数据结构升级的序列化器,可以参考 自定义状态序列化器。本文档也包含一些用于支持状态数据结构升级的状态序列化器与 Flink 状态后端存储相互作用的必要内部细节。
3.6.1. 升级状态数据结构
为了对给定的状态类型进行升级,你需要采取以下几个步骤:
-
对 Flink 流作业进行 savepoint 操作。
-
升级程序中的状态类型(例如:修改你的 Avro 结构)。
-
从 savepoint 恢复作业。当第一次访问状态数据时,Flink 会判断状态数据 schema 是否已经改变,并进行必要的迁移。
用来适应状态结构的改变而进行的状态迁移过程是自动发生的,并且状态之间是互相独立的。 Flink 内部首先会检查新的序列化器相对比之前的序列化器是否有不同的状态结构;如果有,则使用之前的序列化器读取状态数据字节到对象,然后使用新的序列化器将对象回写为字节。
更多的迁移过程细节不在本文档谈论的范围;可以参考文档。
3.6.2. 数据结构升级支持的数据类型
目前仅支持 POJO 和 Avro 类型的 schema 升级 。因此,如果你比较关注于状态数据结构的升级,目前强烈推荐使用 Pojo 或者 Avro 状态数据类型。
我们有计划支持更多的复合类型;更多的细节可以参考 FLINK-10896。
3.6.2.1. POJO 类型
Flink 基于下面的规则来支持 POJO类型结构的升级:
-
可以删除字段。一旦删除,被删除字段的前值将会在将来的 checkpoints 以及 savepoints 中删除。
-
可以添加字段。新字段会使用类型对应的默认值进行初始化,比如 Java 类型。
-
不可以修改字段的声明类型。
-
不可以改变 POJO 类型的类名,包括类的命名空间。
需要注意,只有从 1.8.0 及以上版本的 Flink 生产的 savepoint 进行恢复时,POJO 类型的状态才可以进行升级。 对 1.8.0 版本之前的 Flink 是没有办法进行 POJO 类型升级的。
3.6.2.2. Avro 类型
Flink 完全支持 Avro 状态类型的升级,只要数据结构的修改是被 Avro的数据结构解析规则认为兼容的即可。
一个例外是,如果新的 Avro 数据 schema 生成的类无法被重定位或者使用了不同的命名空间,在作业恢复时状态数据会被认为是不兼容的。
3.6.3. Schema迁移限制
flink的schema迁移有一些限制,以此来保证正确性。用户在使用自定义序列化器,或者是有状态的算子api时,需要了解这些迁移限制,以保证操作是安全的。
3.6.3.1. 不支持key的schema升级
不能改变key的结构,否则会导致不确定的行为。比如,如果一个POJO类被用于key,然后某个属性被删除,在任务从checkpoint恢复时,就会出现多个之前key不同,但现在相同的多个独立key。flink没有办法去合并这些相同的值。
另外,RocksDB状态后端依赖于对象二进制数据标识,而不是hashCode方法。任何对于key对象结构的改变都会导致不确定的行为。
3.6.3.2. kryo不能用于schema升级
当使用kryo时,框架无法验证是否进行了任何不兼容的更改。
3.7. 自定义状态序列化
暂不做翻译
4. 用户自定义函数
大多数操作都需要用户自定义 function。本节列出了实现用户自定义 function 的不同方式。还会介绍 Accumulators(累加器),可用于深入了解你的 Flink 应用程序。
java:
实现接口
最基本的方法是实现提供的接口:
class MyMapFunction implements MapFunction<String, Integer> {
public Integer map(String value) {
return Integer.parseInt(value);
}
};
data.map(new MyMapFunction());
匿名类
你可以将 function 当做匿名类传递:
data.map(new MapFunction<String, Integer> () {
public Integer map(String value) { return Integer.parseInt(value); }
});
Java 8 Lambdas
Flink 在 Java API 中还支持 Java 8 Lambdas 表达式。
data.filter(s -> s.startsWith("http://"));
data.reduce((i1,i2) -> i1 + i2);
Rich functions
所有需要用户自定义 function 的转化操作都可以将 rich function 作为参数。例如,你可以将下面代码
class MyMapFunction implements MapFunction<String, Integer> {
public Integer map(String value) { return Integer.parseInt(value); }
};
替换成
class MyMapFunction extends RichMapFunction<String, Integer> {
public Integer map(String value) { return Integer.parseInt(value); }
};
并将 function 照常传递给 map transformation:
data.map(new MyMapFunction());
Rich functions 也可以定义成匿名类:
data.map (new RichMapFunction<String, Integer>() {
public Integer map(String value) { return Integer.parseInt(value); }
});
scala:
Lambda Functions
正如你在上面的例子中看到的,所有的操作同可以通过 lambda 表达式来描述:
val data: DataSet[String] = // [...]
data.filter{ _.startsWith("http://") }
val data: DataSet[Int] = // [...]
data.reduce { (i1,i2) => i1 + i2 }
// or
data.reduce { _ + _ }
Rich functions
所有将 lambda 表达式作为参数的转化操作都可以用 rich function 来代替。例如,你可以将下面代码
data.map { x => x.toInt }
替换成
class MyMapFunction extends RichMapFunction[String, Int] {
def map(in: String): Int = {
in.toInt
}
};
并将 function 传递给 map transformation:
data.map(new MyMapFunction())
Rich functions 也可以定义成匿名类:
data.map (new RichMapFunction[String, Int] {
def map(in: String):Int = { in.toInt }
})
除了用户自定义的 function(map,reduce 等),Rich functions 还提供了四个方法:open、close、getRuntimeContext和 setRuntimeContext。这些方法对于参数化 function (参阅 给 function传递参数),创建和最终确定本地状态,访问广播变量(参阅 广播变量),以及访问运行时信息,例如累加器和计数器(参阅 累加器和计数器),以及迭代器的相关信息(参阅 迭代器)有很大作用。
4.1. 累加器和计数器
累加器是具有加法运算和最终累加结果的一种简单结构,可在作业结束后使用。
最简单的累加器就是计数器: 你可以使用 Accumulator.add(V value) 方法将其递增。在作业结束时,Flink 会汇总(合并)所有部分的结果并将其发送给客户端。在调试过程中或在你想快速了解有关数据更多信息时,累加器作用很大。
Flink 目前有如下内置累加器。每个都实现了 累加器 接口。
-
IntCounter , LongCounter 和 DoubleCounter : 有关使用计数器的示例,请参见下文。
-
直方图 : 离散数量的柱状直方图实现。在内部,它只是整形到整形的映射。你可以使用它来计算值的分布,例如,单词计数程序的每行单词的分布情况。
4.1.1. 使用累加器
首先,在需要使用累加器的用户自定义的转换 function 中创建一个累加器对象(此处是计数器)。
private IntCounter numLines = new IntCounter();
其次,你必须在 rich function 的 open() 方法中注册累加器对象。也可以在此处定义名称。
getRuntimeContext().addAccumulator("num-lines", this.numLines);
现在你可以在操作 function 中的任何位置(包括 open() 和 close() 方法中)使用累加器。
this.numLines.add(1);
最终整体结果会存储在由执行环境的 execute() 方法返回的 **JobExecutionResult **对象中(当前只有等待作业完成后执行才起作用)。
myJobExecutionResult.getAccumulatorResult("num-lines")
单个作业的所有累加器共享一个命名空间。因此你可以在不同的操作 function 里面使用同一个累加器。Flink 会在内部将所有具有相同名称的累加器合并起来。
关于累加器和迭代的注意事项:当前累加器的结果只有在整个作业结束后才可用。我们还计划在下一次迭代中提供上一次的迭代结果。你可以使用 聚合器 来计算每次迭代的统计信息,并基于此类统计信息来终止迭代。
4.1.2. 定制累加器
要实现自己的累加器,你只需要实现累加器接口即可。如果你认为自定义累加器应随 Flink 一起提供,请尽管创建 pull request。
你可以选择实现 Accumulator 或 SimpleAccumulator 。
Accumulator
5. 算子
5.1. 概述
算子会转换一个DataStreams为另一个DataStreams,程序可以联合多个转换,最终形成负责的数据流拓扑。
该章节将会讲述基本的转换算子、有效的物理分区、以及flink的算子链接。
5.1.1. DataStream转换
5.1.1.1. Map
DataStream → DataStream
接收一个元素并且产生一个元素,下面的示例是将输入流接收到的值变为原来的两倍:
java:
DataStream<Integer> dataStream = ;//...
ataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
scala:
dataStream.map { x => x * 2 }
5.1.1.2. FlatMap
DataStream → DataStream
接收一个元素,产生零个、一个、或多个元素。下面的示例是将语句分割为单词:
java:
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)
throws Exception {
for (String word : value.split(" ")) {
out.collect(word);
}
}
});
scala:
dataStream.flatMap { str => str.split(" ") }
5.1.1.3. Filter
DataStream → DataStream
对每个元素执行一个返回boolean的函数,保留返回true的那些元素。下面的示例是过滤(不要)为0的值:
java:
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
scala:
dataStream.filter { _ != 0 }
5.1.1.4. KeyBy
DataStream → KeyedStream
逻辑上将一个流拆分为多个分区,相同key的所有记录将会被分配给相同的分区。flink内部的keyBy()函数是通过hash来实现分区的。有两种不同的方式来指定分区key。
java:
dataStream.keyBy(value -> value.getSomeKey());
dataStream.keyBy(value -> value.f0);
scala:
dataStream.keyBy(_.someKey)
dataStream.keyBy(_._1)
下面两种情况不能作为key:
-
如果一个POJO类没有重写
hashCode()函数,而且依赖于Object.hashCode()实现。 -
任何类型的数组类型。
5.1.1.5. Reduce
KeyedStream → DataStream
"滚动"reduce算子,作用在keyed数据流上。合并当前元素和上次合并的值,并且输出新的值。下面的示例为sum累加。
java:
keyedStream.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2)
throws Exception {
return value1 + value2;
}
});
scala:
keyedStream.reduce { _ + _ }
5.1.1.6. Window
KeyedStream → WindowedStream
窗口可以被定义在一个已经分区的KeyedStream流上。根据一些特性(比如最新到达的5秒的数据),窗口会将数据根据每个key进行分区。也就是说,这5秒钟接收到的所有数据,有多少个key,就有多少个窗口,窗口的个数和key的个数绑定,而不是接下来窗口函数的并行度相关。查看 windows 来获取窗口更完整的描述。
java:
dataStream
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)));
scala:
dataStream
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
5.1.1.7. WindowAll
DataStreamStream → AllWindowedStream
窗口可以被定义在常规数据流上。根据一些特性(比如最新到达的5秒的数据)来对流中的每一个元素进行分组。查看windows 来获取窗口更完整的描述。
所有的记录都将被收集到一个task中,也就是并行度为1,然后传输给 windowAll 算子。
java:
dataStream
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
scala:
dataStream
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
5.1.1.8. Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream
将一个通用函数用于整个窗口,下面的示例是对窗口的元素进行自定义求和操作。
如果使用了windowAll转换,则需要提供一个 AllWindowFunction 函数。
java:
// 四个泛型分别为:输入、输出、key、窗口
windowedStream.apply(new WindowFunction<Tuple2<String, Integer>, Integer, Tuple, Window>() {
public void apply(Tuple tuple,
Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t : values) {
sum += t.f1;
}
out.collect(new Integer(sum));
}
});
// 提供一个AllWindowFunction作用在non-keyed窗口流
// 三个泛型分别为:输入、输出、窗口
allWindowedStream.apply(new AllWindowFunction<Tuple2<String, Integer>, Integer, Window>() {
public void apply(Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t : values) {
sum += t.f1;
}
out.collect(sum);
}
});
scala:
windowedStream.apply { WindowFunction }
// 提供一个AllWindowFunction作用在non-keyed窗口流
allWindowedStream.apply { AllWindowFunction }
5.1.1.9. WindowReduce
WindowedStream → DataStream
提供一个reduce函数作用在窗口上,然后返回一个聚合值。
java:
windowedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
/**
* ReduceFunction的核心方法,合并类型相同的两个值为一个值。该方法将会连续作用与分组中的所有值,直到最后剩下一个值。
* @param value1 需要合并的第一个值
* @param value2 需要合并的第二个值
* @return 两个输入值的聚合结果
*/
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<String, Integer>(value1.f0, value1.f1 + value2.f1);
}
});
scala:
windowedStream.reduce { _ + _ }
5.1.1.10. Union
DataStream → DataStream
合并两个或多个数据流,然后创建一个新的流,包含所有流中的所有元素。注意:如果将一个数据流自身进行合并,你将会在结果流中获取两次原始流中的每个元素。
java:
dataStream.union(otherStream1, otherStream2, ...);
scala:
dataStream.union(otherStream1, otherStream2, ...);
5.1.1.11. Window Join
DataStream,DataStream → DataStream
根据给定的key和一个公共窗口,将两个数据流join起来。
java:
dataStream
.join(otherStream)
// where中指定第一个输入流的key,equalTo中指定第二个输入流的key
.where(x -> x).equalTo(y -> y)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
// join函数的接口。通过指定的key来连接两个数据集中的元素。该函数在会被每个join的元素对调用一次。
// 默认默认情况下,该join和SQL中的"inner join"语义一样,这意味着,如果某个key没有被同时包含在两个数据集的话,则对应的元素将会被过滤。
// join函数是join操作的一个可选项。如果没有提供JoinFunction,则算子的返回值将会是一个二元组的序列,元组中的元素是JoinFunction调用时接收到的元素。
.apply(new JoinFunction() {
/**
* join方法,每个被join到一起的元素对都会调用一次该方法
* @param first 第一个输入流的元素
* @param second 第二个输入流的元素
* @return 两个元素的操作结果
*/
@Override
public Object join(Object first, Object second) throws Exception {
return null;
}
});
scala:
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply { ... }
5.1.1.12. Interval Join
KeyedStream,KeyedStream → DataStream
在指定的的时间间隔内通过共同的key来join两个keyed stream流的e1和e2元素,时间范围为:e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound。
java:
// 下面的示例中,将会join两个流,并且满足该条件: key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // 低界限和高界限
.lowerBoundExclusive() // 可选
.upperBoundExclusive() // 可选
.process(new IntervalJoinFunction() {
...
});
scala:
// 下面的示例中,将会join两个流,并且满足该条件: key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // 低界限和高界限
.upperBoundExclusive() // 可选
.lowerBoundExclusive() // 可选
.process(new IntervalJoinFunction() {
...
});
5.1.1.13. Window CoGroup
DataStream,DataStream → DataStream
通过给定的key和公共窗口Cogroups两个数据流。
java:
dataStream.coGroup(otherStream)
// where指定给第一个输入流的key,equalTo指定第二个输入流的key
.where(x -> x).equalTo(y -> y)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
// CoGroup函数的接口。CoGroup函数会将两个原始数据集中通过相同key分组的数据子集"join"到一起。
// 如果某个key在一个原始数据集中出现,但是没有在另一个原始数据集中出现,则另一个分组数据子集为空。
.apply(new CoGroupFunction() {
/**
* 对于每个key,都会调用一次该方法
* @param first 第一个输入流的记录迭代器
* @param second 第二个输入流的记录迭代器
* @param out 收集返回元素的收集器
*/
@Override
public void coGroup(Iterable first, Iterable second, Collector out) throws Exception {
}
});
scala:
dataStream.coGroup(otherStream)
// where指定给第一个输入流的key,equalTo指定第二个输入流的key
.where(_).equalTo(_)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
// CoGroup函数的接口。CoGroup函数会将两个原始数据集中通过相同key分组的数据子集"join"到一起。
// 如果某个key在一个原始数据集中出现,但是没有在另一个原始数据集中出现,则另一个分组数据子集为空。
.apply(new CoGroupFunction[String, String, String] {
/**
* 对于每个key,都会调用一次该方法
* @param first 第一个输入流的记录迭代器
* @param second 第二个输入流的记录迭代器
* @param out 收集返回元素的收集器
*/
override def coGroup(first: lang.Iterable[String], second: lang.Iterable[String], out: Collector[String]): Unit = {
}
})
5.1.1.14. Connect
DataStream,DataStream → ConnectedStream
连接两个数据流,并且保留他们的类型。连接操作允许在两个流之间共享状态。
java:
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...
ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
scala:
val someStream: DataStream[Int] = ...
val otherStream: DataStream[String] = ...
val connectedStreams = someStream.connect(otherStream)
5.1.1.15. CoMap, CoFlatMap
ConnectedStream → DataStream
在连接数据流上执行简单的map和flatMap操作。
java:
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});
scala:
connectedStreams.map(
(_: Int) => true,
(_: String) => false
)
connectedStreams.flatMap(new CoFlatMapFunction[Int, String, Boolean] {
override def flatMap1(value: Int, out: Collector[Boolean]): Unit = {
}
override def flatMap2(value: String, out: Collector[Boolean]): Unit = {
}
}
5.1.1.16. Iterate
DataStream → IterativeStream → ConnectedStream
在一个工作流中创建一个"带有反馈"的循环,将一个算子的输出重定向到之前的某个算子,这对于不断更新模型的算法非常有用。下面的代码从一个流开始,并连续地应用迭代体。大于0的元素被发送回反馈通道,其余的元素被转发到下游。
java:
IterativeStream<Long> iteration = initialStream.iterate();
DataStream<Long> iterationBody = iteration.map (/*do something*/);
DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value > 0;
}
});
// 关闭迭代。此方法定义迭代程序的结束部分,该部分将反馈到迭代的开始。
// 流迭代的一个常见使用模式是使用输出分割将关闭数据流的一部分发送到头部。
iteration.closeWith(feedback);
DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value <= 0;
}
});
scala:
val iteration: IterativeStream[Long] = initialStream.iterate
val iterationBody: DataStream[Long] = iteration.map /*do something*/
val feedback: DataStream[Long] = iterationBody.filter(new FilterFunction[Long]() {
@throws[Exception]
override def filter(value: Long): Boolean = {
return value > 0
}
})
// 关闭迭代。此方法定义迭代程序的结束部分,该部分将反馈到迭代的开始。
// 流迭代的一个常见使用模式是使用输出分割将关闭数据流的一部分发送到头部。
iteration.closeWith(feedback)
val output: DataStream[Long] = iterationBody.filter(new FilterFunction[Long]() {
@throws[Exception]
override def filter(value: Long): Boolean = {
return value <= 0
}
})
5.1.2. 物理分区
flink也提供了通过下面的低级函数来精确控制经过转化之后的数据流分区。
5.1.2.1. 自定义分区
DataStream → DataStream
使用自定义分区来对每个元素选择目标分区。
java:
DataStreamSource<Long> dataStream = env.fromElements(1L);
DataStream<Long> longDataStream = dataStream.partitionCustom(new Partitioner<Long>() {
@Override
public int partition(Long key, int numPartitions) {
return 0;
}
}, new KeySelector<Long, Long>() {
@Override
public Long getKey(Long value) throws Exception {
return value;
}
});
scala:
val dataStream = env.fromElements(1L)
val longDataStream = dataStream.partitionCustom(new Partitioner[Long] {
override def partition(key: Long, numPartitions: Int): Int = 0
}, new KeySelector[Long, Long]() {
override def getKey(value: Long): Long = value
})
5.1.2.2. Random Partitioning
DataStream → DataStream
对元素进行随机分区分布。
java:
dataStream.shuffle();
scala:
dataStream.shuffle()
5.1.2.3. Rescaling
DataStream → DataStream
轮询分区所有元素作为一个子集到下游算子。当你想有一个 pipelines 时这会非常有用,比如,扇出source的每个并行度实例数据,作为一个子集来进行分发,但是并不像进行完全的重平衡,以避免消耗更大的成本。取决于其他的配置值,比如TaskManager的slot,该分区方式仅会在本地进行数据传输,而不会通过网络传输。
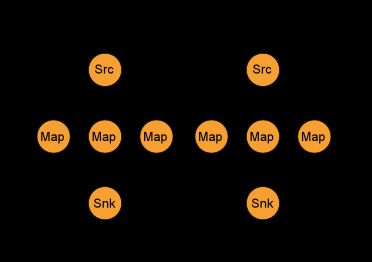
下游算子接收上游算子发送数据的子集取决于上游和下游的并行度关系。比如,如果上游算子并行度为2,下游算子并行度为6,此时上游第一个并行度算子将会分发元素到下游算子的三个并行度,上游另一个并行度算子将会分发元素到下游的其他三个并行度。另外,如果上游算子并行度为6,下游算子并行度为2,则上游3个并行度将会分发数据到下游的一个并行度,上游另外3个并行度将会分发数据到下游的另外3个并行度。
在上游和下游并行度不是彼此倍数关系的时候,下游不同算子将会接收到来自上游不同并行度数量的数据。
下图显示的是上游并行度为2,下游并行度为6的情况。
java:
dataStream.rescale();
scala:
dataStream.rescale
5.1.2.4. Broadcasting
DataStream → DataStream
广播元素到每个分区。
java:
dataStream.broadcast();
scala:
dataStream.broadcast
5.1.3. 算子链和资源组
将两个算子链接在一起能使得它们在同一个线程中执行,从而提升性能。Flink 默认会将能链接的算子尽可能地进行链接(例如,两个 map 转换操作)。此外,Flink 还提供了对链接更细粒度控制的 API 以满足更多需求。
如果想对整个作业禁用算子链,可以调用 StreamExecutionEnvironment.disableOperatorChaining()。下列方法还提供了更细粒度的控制。需要注意的是,这些方法只能在 DataStream 转换操作后才能被调用,因为它们只对前一次数据转换生效。例如,可以 someStream.map(\...).startNewChain() 这样调用,而不能 someStream.startNewChain() 这样。
一个资源组对应着 Flink 中的一个 slot 槽,更多细节请看slots 槽。你可以根据需要手动地将各个算子隔离到不同的 slot 中。
5.1.3.1. 开始新的chain
从该算子开始一个新的chain。两个map算子将会chain,但是flinker算子并不会和第一个map算子chain。
java:
someStream.filter(...).map(...).startNewChain().map(...);
scala:
someStream.filter().map().startNewChain.map()
5.1.3.2. 禁用chain
不chain map算子。
java:
someStream.map(\...).disableChaining();
scala:
someStream.map(\...).disableChaining()
5.1.3.3. 设置slot共享组
对一个算子设置slot共享组。flink可以将使用相同slot共享组的算子放到同一个slot中,然后把没有slot共享组的算子放到其他slot中,该操作可以被用于隔离slot。如果所有的source都在同一个slot共享组中,则会从输入操作继承slot共享组。默认的slot共享组名称为"default",算子可以显式的调用 slotSharingGroup("default") 函数将自己放到共享组中。
java:
someStream.filter(\...).slotSharingGroup(\"name\");
scala:
someStream.filter(\...).slotSharingGroup(\"name\")
5.2. 窗口
窗口是处理无限流的核心。窗口将流且分为固定大小的"桶",然后我们就可以在这些"桶"上运行计算。下面将介绍flink提供的窗口函数,以及程序员如何使用他们。
常见的flink窗口程序结构如下所示。第一个片段展示的是keyed流,第二个展示的non-keyed流,他们唯一的不同就是keyed流需要调用keyBy(…)函数,然后调用window(…)函数,而non-keyed流调用windowAll(…)函数。剩下的介绍也都是按照这个结构来说明的。
Keyed Windows
stream
.keyBy(...) <- 通过keyBy函数,将non-keyed流转化为keyed流
.window(...) <- 必选: "assigner",分配器
[.trigger(...)] <- 可选: "trigger" (或使用默认触发器)
[.evictor(...)] <- 可选: "evictor" (或不指定驱逐器)
[.allowedLateness(...)] <- 可选: "lateness" (或者为0)
[.sideOutputLateData(...)] <- 可选: "output tag" (或不对迟到数据指定侧边流)
.reduce/aggregate/apply() <- 必选: "function",窗口函数
[.getSideOutput(...)] <- 可选: "output tag",获取侧边流
Non-Keyed Windows
stream
.windowAll(...) <- 必选: "assigner",分配器
[.trigger(...)] <- 可选: "trigger" (或使用默认分配器)
[.evictor(...)] <- 可选: "evictor" (或不指定驱逐器)
[.allowedLateness(...)] <- 可选: "lateness" (或为0)
[.sideOutputLateData(...)] <- 可选: "output tag" (或不对迟到数据指定侧边流)
.reduce/aggregate/apply() <- 必选: "function",窗口函数
[.getSideOutput(...)] <- 可选: "output tag",获取侧边流
如上所述,中括号[]中的是可选的。这表示flink允许你根据自己的需要来自定义自己的窗口逻辑。
5.2.1. 窗口生命周期
概括来说,窗口在属于他的第一元素到达时被创建,并且在时间(时间或处理时间)到达他的结束时间加用户指定的允许迟到(具体查看Allowed Lateness)的时间之后完成并被移除。flink保证只移除基于时间的的窗口类型,而不移除其他类型的窗口,比如全局窗口global windows(查看 Window Assigners)。比如,基于事件时间策略创建一个不重叠(或者是滑动)的5分钟大小的窗口,并且允许迟到1分钟,则当一个时间在12:00到12:05之间的元素到达时,flink就会创建对应的窗口,并且当水印超过12:05时,flink就会移除该窗口。
另外,每个窗口都有一个触发器(查看 [Triggers]{.underline})和一个窗口函数(ProcessWindowFunction, ReduceFunction, 或AggregateFunction)(查看WindowFunctions)。窗口函数包含一个处理对于窗口内所有内容的处理逻辑,当窗口满足触发器指定的条件时,窗口就会执行窗口函数。触发策略就像是"当窗口内元素数量超过4",或者是"当水印超过了窗口的结束时间"。触发器也可以决定在窗口被创建和移除期间的任何时间去清除窗口的元素,该清除只会清除窗口内的元素,而不会清除窗口的元数据,这意味着新的数据仍然可以被添加到该窗口。
也可以指定一个驱逐器(查看Evictors),驱逐器可以在窗口函数执行之前(或/和)窗口函数执行之后移除元素。
接下来我们将阐述上述组件的更多细节。首先阐述上面片段中必要的部分(see Keyed vs Non-Keyed Windows, Window Assigner,and Window Function),然后阐述可选部分。
5.2.2. Keyed和Non-Keyed窗口
在定义窗口之前,第一件事是决定你的流应该是keyed,还是non-keyed。使用keyBy(…)函数将会切分你的无限流为逻辑keyed流,如果没有调用keyBy(…)函数,你的流将不是keyed流。
对于keyed流来说,接收到的元素的任何属性都可以被用于key(查看here)。操作keyed流,将允许你的窗口计算通过多个子作业在多个并行度中执行,每个逻辑keyed流将会独立于其他流进行处理。相同key的所有元素将会被发送到同一个并行度。
对于non-keyed流来说,原始流将不会被且分为多个逻辑流,所有窗口逻辑将会在单个作业中执行,比如并行度为1.
5.2.3. 窗口分配器(Assigners)
在决定了你的流为keyed或者是non-keyed之后,下一步就是决定窗口分配器。窗口分配器决定怎么将元素分配给窗口。该操作通过在keyed流上调用window(…)函数,或者是通过在non-keyed流上调用windowAll函数来实现。
窗口分配器的职责是分配每个元素到一个或多个窗口。flink提供了很多预定义的窗口分配器来满足一些常见的需求,比如滚动窗口、滑动窗口、会话窗口、全局窗口。也可以通过扩展WindowAssigner 类来实现自定义窗口分配器。所有的内置窗口分配器(除了全局窗口)都基于时间类分配元素,时间可以是处理时间或事件时间。请查看event time章节来学习更多处理时间和事件时间之间的不同,以及水印是如何生成的。
基于时间的窗口通过一个开始时间(包含)和一个结束时间(不包含)来共同决定窗口的大小。在代码层面,当使用基于时间的窗口时,flink提供了 TimeWindow 对象,该对象包含查询开始和结束时间的方法,并且包含一个额外的 maxTimestamp() 方法来返回该窗口内允许的最大时间戳。
接下来,我们将讲解flink预定义的窗口分配器,以及他们是如何被用于DataStream程序。接下来的图片展示每种分配器是如何工作的。紫色的圆圈代表流中的元素,这些元素通过一些key来分区(下图中是user1、user2、user3)。x轴表示程序时间。
5.2.3.1. 滚动窗口
滚动窗口分配器会将每个元素分配到一个指定大小的窗口内。滚动窗口有固定的大小,并且不会重叠。比如,如果你指定一个窗口时间为5分钟的窗口,则会如下图所示,每5分钟就开启一个新的窗口。

下面的代码片段展示如何使用滚动窗口。
java:
DataStream<T> input = ...;
// 事件时间滚动窗口
input
.keyBy( < key selector >)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation > ( < window function >);
// 处理时间滚动窗口
input
.keyBy( < key selector >)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation > ( < window function >);
// 事件时间滚动窗口,并且延迟-8小时
input
.keyBy( < key selector >)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation > ( < window function >);
scala:
val input: DataStream[T] = ...
// 事件时间滚动窗口
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// 处理时间滚动窗口
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// 事件时间滚动窗口,并且延迟-8小时
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
时间间隔可以通过使用Time.milliseconds(x), Time.seconds(x), Time.minutes(x)等来指定。
在上面展示的最后一个例子中,滚动窗口分配器接受了一个可选的参数,该参数用于改变窗口的偏移量。比如,如果不指定偏移量,一小时的滚动窗口将和epoch时间对齐,然后你就可以得到类似1:00:00.000 - 1:59:59.999, 2:00:00.000 - 2:59:59.999 之类的窗口。如果想改变窗口的偏移量,就可以指定一个offset值。当指定offset为15分钟时,则会得到类似 1:15:00.000 -
2:14:59.999, 2:15:00.000 - 3:14:59.999 之类的窗口。偏移量一个很重要的用例就是决定窗口的时区。比如,在中国,你可以指定offset值为Time.hours(-8)。
5.2.3.2. 滑动窗口
滑动窗口将会把元素分配给一个固定长度的窗口。类似于滚动窗口,滑动窗口的大小也是通过窗口size参数来配置。一个可选的窗口滑动参数来决定滑动窗口什么时候开始。也即是说,如果滑动时间小于窗口大小,则滑动窗口可能会重叠,在这种情况下,元素就会被分配到多个窗口。
比如,你指定窗口时间为10分钟,滑动时间为5分钟,在这种情况下,每5分钟就会得到一个包含最近10分钟内达到的元素,如下图所示。

下面的代码片段展示如何使用滑动窗口。
java:
DataStream<T> input = ...;
// 基于事件时间的滑动窗口
input
.keyBy( < key selector >)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation > ( < window function >);
// 基于处理时间的滑动窗口
input
.keyBy( < key selector >)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation > ( < window function >);
// 基于处理时间的滑动窗口,并指定偏移量为-8小时
input
.keyBy( < key selector >)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation > ( < window function >);
scala:
val input: DataStream[T] = ...
// 基于事件时间的滑动窗口
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// 基于处理时间的滑动窗口
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// 基于处理时间的滑动窗口,并指定偏移量为-8小时
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
时间间隔可以通过使用Time.milliseconds(x), Time.seconds(x), Time.minutes(x)等来指定。
在上面展示的最后一个例子中,滑动窗口分配器接受了一个可选的参数,该参数用于改变窗口的偏移量。比如,如果不指定偏移量,30 分钟的滑动窗口将和epoch时间对其,然后你就可以得到类似1:00:00.000 - 1:59:59.999, 1:30:00.000 - 2:29:59.999之类的窗口。如果想改变窗口的偏移量,就可以指定一个offset值。当指定offset为15分钟时,则会得到类似1:15:00.000 -
2:14:59.999, 1:45:00.000 - 2:44:59.999之类的窗口。偏移量一个很重要的用力就是决定窗口的时区。比如,在中国,你可以指定offset值为Time.hours(-8)。
5.2.3.3. 会话窗口
会话窗口会分配一组元素到一个活跃的会话中。会话窗口不会重叠,并且没有固定的开始和结束时间,这就是和滚动窗口、滑动窗口之间的差异。相反,会话窗口在指定时间间隔内没有接收到元素时关闭。比如,遇到了不会越的时间间隙。会话窗口可以通过配置一个静态的会话间隙或者是一个会话间隙提取器函数来决定不活跃的周期长度。当该周期到期时,当前会话关闭,之后的元素被分配到新的会话窗口。

下面的代码片段展示如何使用会话窗口。
java:
DataStream<T> input = ...;
// 基于事件时间的会话窗口,并指定静态间隙
input
.keyBy( < key selector >)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation > ( < window function >);
// 基于事件时间的会话窗口,并指定动态间隙
input
.keyBy( < key selector >)
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隙
}))
.<windowed transformation > ( < window function >);
// 基于处理时间的会话窗口,并指定静态间隙
input
.keyBy( < key selector >)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation > ( < window function >);
// 基于处理时间的会话窗口,并指定动态间隙
input
.keyBy( < key selector >)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隙
}))
.<windowed transformation > ( < window function >);
scala:
val input: DataStream[T] = ...
// 基于事件时间的会话窗口,并指定静态间隙
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// 基于事件时间的会话窗口,并指定动态间隙
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// 决定并返回会话间隙
}
}))
.<windowed transformation>(<window function>)
//基于处理时间的会话窗口,并指定静态间隙
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// 基于处理时间的会话窗口,并指定动态间隙
input
.keyBy(<key selector>)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// 决定并返回会话间隙
}
}))
.<windowed transformation>(<window function>)
静态间隙可以通过使用Time.milliseconds(x), Time.seconds(x), Time.minutes(x)等来指定。
动态间隙通过实现 SessionWindowTimeGapExtractor 接口来指定。
因为会话窗口没有固定的开始和结束时间,这和滚动窗口、滑动窗口不同。在flink内部,会话窗口算子会为每个到达的记录创建一个窗口,并在他们到达定义的间隙的时候合并他们。为了可合并,会话窗口算子要取一个合并触发器和合并窗口算子,比如ReduceFunction, AggregateFunction,或ProcessWindowFunction。
5.2.3.4. 全局窗口
全局窗口分配器会将所有具有相同key的元素分配到同一个全局窗口中。这个窗口模型只可用于提供了自定义触发器的情况。否则不会触发任何计算,因为全局窗口没有一个自然的结束,因此我们无法处理聚合的元素。

下面的代码片段展示如何使用全局窗口:
java:
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>);
scala:
val input: DataStream[T] = ...
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>)
5.2.4. 窗口函数
在定义了窗口分配器之后,我们需要指定在每个窗口上执行的计算,这就是窗口函数的职责。一旦系统认为一个窗口已经准备好了处理数据(查看triggers来了解flink怎么决定窗口是否做好了准备),则窗口函数就会被用于处理每个窗口(可能是keyed之后的)中的元素。
窗口函数可以是ReduceFunction, AggregateFunction, 或 ProcessWindowFunction中的任意一个。前两个函数执行效率更高(查看State Size章节),因为flink可以对每个窗口中的元素进行增量聚合计算,当窗口中的元素到达时就进行计算。ProcessWindowFunction 函数会提供一个迭代器,用来迭代窗口中包含的所有元素,并且提供一个可以获取窗口元数据的对象。
ProcessWindowFunction 窗口函数的执行效率和其他窗口函数是不一样,因为在调用函数之前,flink必须将所有元素缓存到窗口内。该行为可以通过ProcessWindowFunction 和ReduceFunction/AggregateFunction 来结合使用,以达到增量聚合计算窗口元素以及获取窗口元数据的目的,下面将给出他们的使用案例。
5.2.4.1. ReduceFunction
ReduceFunction 函数包含两个输入元素,然后聚合产生一个输出元素,并且输出和输入元素类型完全一致。flink使用ReduceFunction 来增量聚合窗口中的元素。
下面是ReduceFunction 的使用案例:
java:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});
scala:
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
上面的案例用来计算窗口中所有元组元素第二个元素的sum和。
5.2.4.2. AggregateFunction
AggregateFunction 函数是ReduceFunction 函数的一般化版本,并且有三个泛型:输入类型(IN)、累加器类型(ACC)、输出类型(OUT)。输入类型是输入元素的类型,并且AggregateFunction 包含一个用于将输入元素累加到累加器的方法。该接口也包含创建初始化累加器的方法、合并连个累加器为一个累加器的方法、从累加器提取输出值(类型为OUT)的方法。
下面是是AggregateFunction 使用案例:
java:
/**
* 累加器用来保存运行过程中的sum值和数量。getResult方法用来计算平均值。
*/
private static class AverageAggregate implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate());
scala:
/**
* 累加器用来保存运行过程中的sum值和数量。getResult方法用来计算平均值。
*/
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) = (a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate)
上面的案例用来计算窗口中元素第二个属性的平均值。
5.2.4.3. ProcessWindowFunction
ProcessWindowFunction 函数提供一个包含窗口中所有元素的迭代器、可以访问时间和状态信息的 Context 上下文对象,该函数比其他窗口函数更加灵活。该函数会降低性能和使用更多的资源消耗,因为元素无法立即被增量式地累加,而是被缓存到窗口内部,直到窗口确定已经准备好了处理。
下面是ProcessWindowFunction 的源码:
java:
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> implements Function {
/**
* 计算窗口中所有元素,并且输出0个或多个元素。
*
* @param key 该窗口被计算时,所有元素的key。
* @param context 该窗口的context上下文对象。
* @param elements 窗口中的所有元素的迭代器。
* @param out 用于发射元素的收集器。
* @throws Exception 函数可能会抛出异常,用来停止程序,并触发重启。
*/
public abstract void process(
KEY key,
Context context,
Iterable<IN> elements,
Collector<OUT> out) throws Exception;
/**
* 包含窗口元数据的context对象
*/
public abstract class Context implements java.io.Serializable {
/**
* 返回被触发计算的窗口对象。
*/
public abstract W window();
/**
* 返回当前处理时间。
*/
public abstract long currentProcessingTime();
/**
* 返回当前事件时间的水印值。
*/
public abstract long currentWatermark();
/**
* 每个key和每个窗口的状态访问器。
* 注意:如果使用了per-window状态,则必须实现ProcessWindowFunction#clear(Context)方法来清理状态。
*/
public abstract KeyedStateStore windowState();
/**
* 每个key的全局状态访问器。
*/
public abstract KeyedStateStore globalState();
}
}
scala:
abstract class ProcessWindowFunction[IN, OUT, KEY, W <: Window] extends Function {
/**
* 计算窗口中所有元素,并且输出0个或多个元素。
*
* @param key 该窗口被计算时,所有元素的key。
* @param context 该窗口的context上下文对象。
* @param elements 窗口中的所有元素的迭代器。
* @param out 用于发射元素的收集器。
* @throws Exception 函数可能会抛出异常,用来停止程序,并触发重启。
*/
def process(
key: KEY,
context: Context,
elements: Iterable[IN],
out: Collector[OUT])
/**
* 包含窗口元数据的context对象
*/
abstract class Context {
/**
* 返回被触发计算的窗口对象。
*/
def window: W
/**
* 返回当前处理时间。
*/
def currentProcessingTime: Long
/**
* 返回当前事件时间的水印值。
*/
def currentWatermark: Long
/**
* 每个key和每个窗口的状态访问器。
*/
def windowState: KeyedStateStore
/**
* 每个key的全局状态访问器。
*/
def globalState: KeyedStateStore
}
}
参数key是调用keyBy()函数时通过指定的KeySelector来提取的key。
下面是ProcessWindowFunction 函数的使用案例:
java:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in : input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
scala:
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]) = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
上面ProcessWindowFunction 的案例用来计算窗口中元素的数量。另外窗口函数还增加了窗口信息的输出。
注意,使用ProcessWindowFunction 来简单聚合类似于数量的计算是很低效的。下个章节展示如何使用将 ProcessWindowFunction 与 ReduceFunction / AggregateFunction 结合使用,以此来进行增量计算,并且增加 ProcessWindowFunction 额外信息输出。
5.2.4.4. ProcessWindowFunction 增量式聚合
ProcessWindowFunction 可以通过连接一个ReduceFunction,或AggregateFunction 来增量计算到达窗口的元素。当窗口结束时,ProcessWindowFunction 函数将被用于计算累加的结果。该特性允许ProcessWindowFunction函数增量计算窗口,并且提供额外的窗口元数据信息访问。
也可以使用以前的WindowFunction 来代替ProcessWindowFunction 来进行增量窗口聚合。
5.2.4.4.1. 使用ReduceFunction 增量窗口聚合
下面的案例展示如何使用增量的 ReduceFunction 函数结合 ProcessWindowFunction 函数来返回窗口中的最小事件,并且返回窗口的开始时间。
java:
DataStream<SensorReading> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
// ReduceFunction函数定义
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() < r2.value() ? r1 : r2;
}
}
// ProcessWindowFunction函数定义
private static class MyProcessWindowFunction extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));
}
}
scala:
val input: DataStream[SensorReading] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(
(r1: SensorReading, r2: SensorReading) => { if (r1.value > r2.value) r2 else r1 },
( key: String,
context: ProcessWindowFunction[_, _, _, TimeWindow]#Context,
minReadings: Iterable[SensorReading],
out: Collector[(Long, SensorReading)] ) =>
{
val min = minReadings.iterator.next()
out.collect((context.window.getStart, min))
}
)
5.2.4.4.2. 使用AggregateFunction增量窗口聚合
下面的案例展示如何使用增量的 AggregateFunction 函数结合 ProcessWindowFunction 函数来计算平均值,并且返回窗口所属的key。
java:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate(), new MyProcessWindowFunction());
// 函数定义
/**
* 累加器用来保存运行时的sum和和数量。getResult方法计算平均值
*/
private static class AverageAggregate implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
private static class MyProcessWindowFunction extends ProcessWindowFunction<Double, Tuple2<String, Double>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<Double> averages,
Collector<Tuple2<String, Double>> out) {
Double average = averages.iterator().next();
out.collect(new Tuple2<>(key, average));
}
}
scala:
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate(), new MyProcessWindowFunction())
// 函数定义
/**
* 累加器用来保存运行时的sum和和数量。getResult方法计算平均值
*/
class AverageAggregate extends functions.AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
class MyProcessWindowFunction extends ProcessWindowFunction[Double, (String, Double), String, TimeWindow] {
def process(key: String, context: Context, averages: Iterable[Double], out: Collector[(String, Double)]) = {
val average = averages.iterator.next()
out.collect((key, average))
}
}
5.2.4.5. 在ProcessWindowFunction 中访问每个窗口状态
除了访问keyed state 状态(就像其他rich函数一样)之外, ProcessWindowFunction 还可以访问当前处理的窗口的其他keyed state状态。下面是对每个窗口状态的不同角度的解释:
-
定义了窗口算子的窗口:可能是1小时的滚动窗口,或者是滚动2小时,滑动1小时的窗口。
-
针对给定key的窗口实例:可能是对于用户id xyz的从12:00到13:00的时间窗口。如果有大量的key,任务会根据当前的处理以及事件进入的时间来创建很多窗口。也就是说,对于每个key,都会存在一个窗口实例。
如果我们处理了1000个不同的key的事件,并且他们都包含在[12:00, 13:00]的时间窗口中,则任务会创建1000个窗口实例,并且每个窗口都有他们自己的窗口状态。
process()函数的Context对象上有两个方法来访问两种类型的状态:
-
globalState():访问不属于窗口的keyed状态。
-
windowState():访问属于窗口的keyed状态。
如果能确定同一个窗口会被多次触发,就像是延迟数据触发窗口一样,或者是你自定义了窗口触发器,用来提前触发窗口,则该特性是非常有用的。在这种情况下,你就可以将提前触发或者是触发的次数信息放到每个窗口状态中。
5.2.4.6. WindowFunction (过时)
在一些情况下,也可以使用WindowFunction,而不是ProcessWindowFunction 。WindowFunction 是旧版本的ProcessWindowFunction 实现,只提供了少量的上下文信息,不像 ProcessWindowFunction ,没有更多的新特性,比如每个窗口的keyed状态。该接口将在未来某个时间被移除。
下面是WindowFunction 的签名:
java:
public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function, Serializable {
/**
* 执行窗口函数,并输出0个或多个元素。
*
* @param key 该窗口的key。
* @param window 该窗口的window对象。
* @param input 该窗口被计算时的所有元素。
* @param out 发射元素的收集器。
* @throws Exception 该函数可能会抛出异常,将程序失败,然后触发重启。
*/
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception;
}
scala:
trait WindowFunction[IN, OUT, KEY, W <: Window] extends Function with Serializable {
/**
* 执行窗口函数,并输出0个或多个元素。
*
* @param key 该窗口的key。
* @param window 该窗口的window对象。
* @param input 该窗口被计算时的所有元素。
* @param out 发射元素的收集器。
* @throws Exception 该函数可能会抛出异常,将程序失败,然后触发重启。
*/
def apply(key: KEY, window: W, input: Iterable[IN], out: Collector[OUT])
}
使用案例如下:
java:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
scala:
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction())
5.2.5. 触发器
触发器决定窗口何时调用窗口函数。每个窗口分配器都提供了一个默认的触发器。如果默认触发器不满需要,则可以使用trigger(…)函数来自定义触发器。
触发器接口包含5个方法,用于针对不同的事件来做出反应:
-
onElement():有元素被添加到窗口时调用。
-
onEventTime():当被注册的事件时间定时器触发时调用。
-
onProcessingTime():当被注册的处理时间定时器触发时调用。
-
onMerge():该方法和有状态的触发器相关,当他们对应的窗口合并时,该方法会合并两个触发器的状态,比如:会话窗口。
-
clear():在删除相应的窗口时用于执行清理工作。
针对上面的方法,需要注意两件事;
-
前三个方法通过返回TriggerResult对象来表示他们的处理结果,结果可以是下面的中的某一个:
-
CONTINUE:不做任何事。
-
FIRE:触发计算。
-
PURGE:清理窗口中的元素。
-
FIRE_AND_PURGE:触发计算,计算完毕之后清理窗口中的元素。
-
-
这些方法中的任何一个都可以被用于注册处理时间或事件时间定时器来执行更丰富的操作。
5.2.5.1. Fire and Purge
一旦触发器发现窗口已经准备好执行窗口函数,他就会触发执行,比如返回 FIRE 或者 FIRE_AND_PURGE 。这是窗口算子发射当前窗口结果的信号。指定了 ProcessWindowFunction 函数的窗口会对所有元素执行 ProcessWindowFunction 函数(也可能会在执行完 evictor 驱逐器之后执行)。指定 ReduceFunction 或 AggregateFunction 函数窗口将会简单的发射聚合的结果。
当触发器执行时,返回值可以是 FIRE 或 FIRE_AND_PURGE 。 FIRE 会继续保持该窗口的内容, FIRE_AND_PURGE 会移除窗口的内容。默认情况下,已经实现的触发器会简单的 FIRE ,而不会删除窗口状态。
Purging 将会简单的删除窗口的内容,并且完好无损的保存任何和窗口、触发器相关的元数据。
5.2.5.2. 默认触发器和窗口分配器
窗口分配器的默认触发器适用于大多数情况。比如,所有的事件时间窗口分配器都将 EventTimeTrigger 作为默认触发器。该触发器在水印超过窗口结束时间时触发窗口函数执行。
GlobalWindow 的默认触发器为 NeverTrigger ,该触发器永远不会触发窗口函数执行。因此,当你使用 GlobalWindow 时,必须自定义触发器。
当通过trigger()函数来指定触发器时,将会覆盖默认的窗口触发器。比如,如果你对 TumblingEventTimeWindows 指定了 CountTrigger ,则该窗口只会通过事件数量来触发,而不会根据事件时间来触发。如此一来,如果你想同时通过时间和数量来触发,则必须自定义触发器。
5.2.5.3. 内建和自定义触发器
flink提供了一些内建触发器。
-
EventTimeTrigger :基于处理的事件时间和水印触发。
-
ProcessingTimeTrigger :基于处理时间触发。
-
CountTrigger :当元素的数量达到窗口指定的限制时触发。
-
PurgingTrigger :将另一个触发器作为参数,并将其转化为清理触发器。
如果需要实现自定义触发器,则需要继承Trigger抽象类。注意,该API还在评估中,可能会在未来的flink版本中发生变化。
5.2.6. evictor驱逐器
flink的窗口模型允许指定除窗口分配器和触发器之外的一个可选evictor驱逐器。可以通过使用 evictor(…) 方法来完成。驱逐器可以在窗口触发之前 和/或 之后来移除窗口中的元素。为了实现该目标,驱逐器接口包含两个方法:
/**
* 可选,删除元素。窗口函数执行之前被调用。
*
* @param elements 窗口中当前包含的元素。
* @param size 窗口中当前元素的数量。
* @param window window对象
* @param evictorContext 驱逐器的上下文对象。
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* Optionally evicts elements. Called after windowing function.
* 可选,删除元素。窗口函数执行之后被调用。
*
* @param elements 窗口中当前包含的元素。
* @param size 窗口中当前元素的数量。
* @param window window对象
* @param evictorContext 驱逐器的上下文对象。
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
evictBefore() 函数包含的删除逻辑将在窗口函数触发之前执行,evictAfter() 函数会在窗口函数触发之后执行。在窗口函数执行之前被删除的元素并不会被他执行。
flink提供了三个预实现的驱逐器:
-
CountEvictor:保留窗口中用户指定数量的元素,并且丢弃窗口中缓存的前面的元素。
-
DeltaEvictor:提供一个 DeltaFunction 和一个阈值,计算窗口缓冲区中最后一个元素与每个剩余元素之间的增量,并删除增量大于或等于阈值的元素。
-
TimeEvictor:对于给定的窗口,以毫秒为interval参数,然后所有元素中找到最大的时间戳max_ts,并删除所有时间戳小于 max_ts - interval 的元素。
默认情况下,所有预实现的驱逐器将会在窗口函数调用之前执行他们的逻辑。
指定驱逐器将会阻塞任何预聚合,窗口中的所有元素必须在执行计算之前,先通过驱逐器。这意味着包含驱逐器的窗口将会创建更多的状态。
flink不保证窗口中元素的顺序。这意味着,尽管驱逐符可以从窗口的开头删除元素,但这些元素并不一定是最先或最后到达的元素。
5.2.7. 允许迟到
当使用事件时间窗口时,可能会遇到迟到的数据,比如,flink用来追踪事件时间的水印已经超过了所属窗口的结束时间戳。查看事件时间和迟到数据章节来获取更多flink如何处理事件时间的信息。
默认情况下,当水印超过窗口的结束时间时会直接丢弃迟到元素。然而,flink允许对窗口算子指定一个最大的允许迟到时间。允许迟到指定元素在被丢弃之前,最多可以迟到多长时间,默认值为0。元素到达时,水印已经超过了窗口结束时间,但元素时间只要小于水印加允许迟到的时间,该元素依然会被添加到窗口内。取决于使用的触发器,迟到但未被丢弃的元素可能会再次触发窗口计算。这就是事件时间触发器的使用场景。
为了实现该目的,flink会保持窗口的状态,直到超过了允许迟到的时间。一旦超过了允许迟到的时间,flink将会移除窗口,并删除他的状态,就像窗口生命周期章节描述的一样。
默认情况下,允许迟到的时间为0,这意味着在水印之后到达的元素将会被丢弃。
下面是指定允许迟到的案例:
java:
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.<windowed transformation>(<window function>);
scala:
val input: DataStream[T] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.<windowed transformation>(<window function>)
当使用 GlobalWindows 窗口分配器时,任何数据都不会迟到,因为全局窗口的结束时间为Long.MAX_VALUE。
5.2.7.1. 从侧边流获取迟到数据
使用flink的侧边流特性,就可以获取数据流中由于迟到被丢弃的数据。
首先需要调用 sideOutputLateData(OutputTag) 函数来收集窗口流中的迟到数据,然后,就可以在窗口算子的结果中获取侧边流。
java:
final OutputTag<T> lateOutputTag = new OutputTag<T>("late-data"){};
DataStream<T> input = ...;
SingleOutputStreamOperator<T> result = input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.sideOutputLateData(lateOutputTag)
.<windowed transformation>(<window function>);
DataStream<T> lateStream = result.getSideOutput(lateOutputTag);
scala:
val lateOutputTag = OutputTag[T]("late-data")
val input: DataStream[T] = ...
val result = input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.sideOutputLateData(lateOutputTag)
.<windowed transformation>(<window function>)
val lateStream = result.getSideOutput(lateOutputTag)
5.2.7.2. 迟到元素的处理
当指定允许迟到时间大于0时,在水印超过了窗口的结束时间时,窗口也会保持他的内容。这种情况下,当迟到但不会被丢弃的数据到达时,就会触发窗口的另一次计算。这些触发叫做延迟触发,他们通过迟到元素来触发,这是他们和主触发,也就是第一次触发的差异。在会话窗口中,延迟触发会进一步导致窗口的聚合,他们会填补两个已经存在的窗口之间的间隙。
通过延迟触发得到的结果数据应该通过更新前面的计算结果来处理。比如,你的数据量可能对相同的计算产生多个结果。取决于你的应用程序,你需要保存一个账号下多个重复的结果,或者是对他们去重。
5.2.8. 处理窗口结果
窗口算子的结果也是 DataStream,窗口算子的信息将不会保留到结果元素中,因此,如果你想将窗口的元数据信息保存下来,你需要自定义 ProcessWindowFunction 来将元数据信息保存到结果元素中。在结果元素上设置的唯一相关信息是元素的时间戳。该时间戳是允许窗口处理的最大时间戳,该值是结束时间-1,因此窗口不包含窗口结束时间。注意,该规则对事件时间窗口和处理时间窗口都有效。比如,在窗口算子之后,元素通常有一个时间戳,该时间戳可以是事件时间,也可以是处理时间。对于处理时间窗口,该值没有特殊意义,但是对于事件时间窗口,结合水印与窗口的交互,可以实现具有相同窗口大小的连续窗口算子操作。
5.2.8.1. 水印和窗口交互
在阅读该章节之前,你需要先阅读事件[时间和水印]{.underline}章节。
当水印到达窗口算子时会触发两件事:
-
当窗口最大时间戳(窗口结束时间-1)小于新水印时触发所有窗口的计算。
-
水印传递到下游算子。
5.2.8.2. 连续的窗口算子
如上所述,窗口算子结果数据流时间戳的计算方式以及水印与窗口交互的方式允许将连续的窗口算子串在一起。当你想要执行两个连续的窗口算子,并且两个窗口使用不同的key,但仍然希望来自上游窗口的元素最终出现在下游窗口时,这将会非常有用。示例如下;
java:
DataStream<Integer> input = ...;
DataStream<Integer> resultsPerKey = input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new Summer());
DataStream<Integer> globalResults = resultsPerKey
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new TopKWindowFunction());
scala:
val input: DataStream[Int] = ...
val resultsPerKey = input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new Summer())
val globalResults = resultsPerKey
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new TopKWindowFunction())
在这个案例中,第一个算子的时间窗口[0, 5)的结果也将在第二个时间窗口[0, 5)中结束。第一个窗口计算每个key的sum,然后在第二个窗口计算Top-k元素。
5.2.9. 状态大小
窗口可以定义很长的时间周期(比如:天、周、月),然后累计大量的key。在估计窗口计算需要的存储要求时,需要注意以下几点:
-
flink会对每个窗口中的每个元素创建一个副本。在这种情况下,滚动窗口将会对每个元素保留一个副本(一个元素只属于一个窗口,直到后面被删除)。相反,滑动窗口将会对每个元素创建好几个副本,因此,1天的窗口,滑动1秒是比较差的选择。
-
ReduceFunction 和 AggregateFunction 函数会显著减少存储需求,他们会更早的聚合元素,并且在每个窗口中保留一个值。相反,仅仅使用 ProcessWindowFunction 函数则会累计所有的元素。
-
使用驱逐器会阻止任何预聚合,因为窗口中所有的元素都必须在触发计算之前经过驱逐器。
5.3. Joing
5.3.1. Window Join
window join 会将两个流内位于相同窗口中,并且有共同 key 的的元素 join 起来,窗口可以使用 window assigner 定义,并且两个流中的元素均会被处理。
当符合 join 标准时,两个流中的元素均会被自定义的 JoinFunction 或 FlatJoinFunction 处理,并且发射结果值。
常用方式总结如下:
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
语法的一些注意点:
- 创造的来自两个流中成对的元素组合行为就像 inner-join,这意味着一个流中的元素,如果他在另一个流中没有找到对应的元素进行 join,则该元素将不会被连接处理。
- 那些被 join 的元素会将他们各自窗口的最大时间戳作为自己的时间戳。比如,一个将
[5, 10)作为边界的窗口,会将 9 作为 join 元素的时间戳。
下面的章节中,我们将会使用一些案例情景来展示不同的窗口会有怎样的 join 行为。
5.3.1.1. Tumbling Window Join
当使用滚动窗口 join 时,在同一个滚动窗口内,并且拥有相同 key 的元素将会成对的组合,并且被一个 JoinFunction 或 FlatJoinFunction 函数处理。因为该行为就像是 inner join,因此在滚动窗口中,如果一个流中的元素在另一个流中没有对应的元素,则该元素将不会被发射。

注意,上图演示中,去掉了 equalTo 函数,也就是没有指定 join 条件,所有所有元素都会进行连接。
如上图所说,我们定义了一个 2 毫秒的滚动窗口,之后会产生如 [0,1], [2,3], ... 的窗口。改图展示了每个窗口中所有元素产生的成对组合将会被 JoinFunction 处理。注意, [6,7] 窗口将不会发射任何元素,因为下面橙色流中元素 ⑥ 和 ⑦ 在上面绿色流中找不到任何存在的元素进行 join 。
Java
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
Scala
mport org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream.join(greenStream)
.where(elem => /* select key */)
.equalTo(elem => /* select key */)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply { (e1, e2) => e1 + "," + e2 }
5.3.1.2. Sliding Window Join
当使用滑动窗口 join 时,所有有共同 key 和共同滑动窗口的元素将会被 join 为成对的组合,并且被 JoinFunction 或 FlatJoinFunction 函数处理。如果在当前滑动窗口中的一个流中的元素在另一个流中找不到相对应的元素,则该元素不会被发射。注意有些元素可能会在一个滑动窗口中 join,但并不会在另一个滑动窗口中 join。
上例中,我们使用了大小为 2 毫秒,并且滑动为 1 毫秒的滑动窗口,之后会产生 [-1, 0],[0,1],[1,2],[2,3], … 这些滑动窗口。在 x 轴下面的 join 之后的元素将会被每个滑动窗口中的 JoinFunction 函数处理。从上图可以看到,橙色的元素 ② 和绿色的元素 ③ 在 [2,3] 窗口中 join 到了一起,但是并没有在 [1,2] 窗口中 join 到一起。
Java
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
Scala
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream.join(greenStream)
.where(elem => /* select key */)
.equalTo(elem => /* select key */)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply { (e1, e2) => e1 + "," + e2 }
5.3.1.3. Session Window Join
当使用会话窗口时,在“组合”履行了会话标准的所有拥有相同 key 的元素时,他们将会 join 为成对的组合,并且被 JoinFunction 或 FlatJoinFunction 函数处理。在使用 inner join 时,如果会话窗口中的只有一个流中有元素,则该元素并不会被发射。

上图是定义了间隙至少为 1 毫秒的会话窗口 join,上图中有三个会话,前两个会话中两个流中的元素将会进行 join 然后被 JoinFunction 函数处理,第三个会话,由于在绿色的流中没有元素,所以 ⑧ 和 ⑨ 将不会进行 join 。
Java
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
Scala
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream.join(greenStream)
.where(elem => /* select key */)
.equalTo(elem => /* select key */)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply { (e1, e2) => e1 + "," + e2 }
5.3.2. Interval Join
我们将两个流称为 A 和 B。ineterval join 会将两个流中拥有相同 key 的元素进行 join,其中 B 流元素的时间戳和 A 流中的元素时间戳具有一定的相关性。
上述时间戳关系也可以通过表达式来表示:b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] 或 a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound。
流 A 和流 B 中的元素 a 和 b 会共享同一个 key。下边界和上边界都可以为正值或负值,并且下边界通常小于等于上边界。interval join 目前只支持 inner join。
当一对元素被 ProcessJoinFunction 函数处理时,这两个元素将会被分配最大的时间戳,时间戳可以通过 ProcessJoinFunction.Context 访问。
interval join 当前只支持事件时间。

在上面的例子中,我们将橙色的流和绿色的流进行 join ,并且指定下边界为 -2 毫秒,上边界为 +1 毫秒。默认情况下,两个边界均会被包含,但是可以通过调用 .lowerBoundExclusive() 和 .upperBoundExclusive 函数来改变这个行为。
上例中的流 join 关系可以通过该表达式来表示:orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound 。
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound
Java
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
Scala
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
...
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream
.keyBy(elem => /* select key */)
.intervalJoin(greenStream.keyBy(elem => /* select key */))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process(new ProcessJoinFunction[Integer, Integer, String] {
override def processElement(left: Integer, right: Integer, ctx: ProcessJoinFunction[Integer, Integer, String]#Context, out: Collector[String]): Unit = {
out.collect(left + "," + right);
}
});
});
5.4. Process Function
5.4.1. 概述
ProcessFunction 函数是底层流处理算子,通过它可以访问所有非循环流程序的基础构建模块:
- 事件(流元素)
- 状态(容错,一致性,只可用于 keyed 流)
- 时间(事件时间和处理时间,只可用于 keyed 流)
ProcessFunction 可以被看作为一个可以访问 keyed 状态和定时器的 FlatMapFunction 函数,它会通过反射处理输入流中到达的每一个元素。
对于状态容错,FlatMapFunction 可以通过 RuntimeContext 来访问 flink 的 keyed state,就像其他有状态函数访问 keyed 状态的方式一样。
定时器可以通过处理时间或事件时间来定义,每次调用 processElement(...) 函数时,都可以获取到一个 Context 对象,可以通过该对象的 TimerService 来访问元素的事件时间戳。TimerService 可以使用事件时间或处理时间来注册回调实例。当使用事件时间定时器时,onTimer(...) 方法将会在当前水印到达或超过定时器的时间戳时被调用;当使用处理时间定时器时,``onTimer(…)` 方法将会在标准时间到达指定时间时被调用。在调用期间,定时器创建的所有属于某个 key 的状态将会再次被定时器操作。
如果你想访问 keyed 状态和定时器,你必须在一个 keyed 流上调用
ProcessFunction函数:
stream.keyBy(...).process(new MyProcessFunction())
5.4.2. 底层Joins
为了在两个输入流上实现底层操作,应用程序可以使用 CoProcessFunction 或 KeyedCoProcessFunction 函数。该函数有两个函数: processElement1(...) 和 processElement2(...) 来分别处理两个不同输入流中的元素。
实现底层 join ,可以按照以下步骤:
- 在一个或两个输入流上创建一个状态对象
- 在输入流元素到达时更新状态
- 在其他输入流元素到达时,访问状态,然后输出 join 的结果
比如,你想将客户数据和金融贸易进行 join,并且将消费者数据保存到状态中。如果你关心在遇到无序事件时是否有完整和确定的连接,则可以使用计时器在客户数据流的水印超过交易时间时进行评估并发出交易的 join。
5.4.3. 案例
在下面的例子中, KeyedProcessFunction 函数对每个 key 都保留一个计数器,并且每过一分钟(按事件时间计算)都会在不更新该 key 的情况下发射一个 key/计数器 对:
- 计数器、key 和最新更新时间会存储到
ValueState中,这些都属于同一个 key 范围内 - 对于每条数据,
KeyedProcessFunction函数会增加计数器数值,并且设置最新更新时间戳 - 函数也会在未来一分钟调度一个回调(按事件时间计算)
- 在每次回调时,都会检查回调的时间戳和计数器存储的最新更新时间戳,如果匹配的话,则会发射 key/计数器(比如,在那一分钟内没有更新的更新)
下面这个简单的案例通过会话窗口来实现,我们使用
KeyedProcessFunction函数来说明它提供的基础模式。
Java
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction.Context;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction.OnTimerContext;
import org.apache.flink.util.Collector;
// the source data stream
DataStream<Tuple2<String, String>> stream = ...;
// 在 keyed stream 上调用 prcess function
DataStream<Tuple2<String, Long>> result = stream
.keyBy(value -> value.f0)
.process(new CountWithTimeoutFunction());
/**
* 状态中保存的数据类型
*/
public class CountWithTimestamp {
public String key;
public long count;
public long lastModified;
}
/**
* 包含了计数器和时间 ProcessFunction 实现
*/
public class CountWithTimeoutFunction
extends KeyedProcessFunction<Tuple, Tuple2<String, String>, Tuple2<String, Long>> {
/** 这个 process function 函数保存的状态 */
private ValueState<CountWithTimestamp> state;
@Override
public void open(Configuration parameters) throws Exception {
state = getRuntimeContext().getState(new ValueStateDescriptor<>("myState", CountWithTimestamp.class));
}
@Override
public void processElement(
Tuple2<String, String> value,
Context ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
// 检索当前计数器
CountWithTimestamp current = state.value();
if (current == null) {
current = new CountWithTimestamp();
current.key = value.f0;
}
// 更新状态的计数
current.count++;
// 将数据的事件时间戳设置为状态的时间戳
current.lastModified = ctx.timestamp();
// 将状态写回
state.update(current);
// 根据当前事件时间,调度下个 60 秒之后的定时器
ctx.timerService().registerEventTimeTimer(current.lastModified + 60000);
}
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
// 获取被调度定时器对应 key 的状态
CountWithTimestamp result = state.value();
// 检查这是一个过时的定时器还是最新的定时器
if (timestamp == result.lastModified + 60000) {
// emit the state on timeout
out.collect(new Tuple2<String, Long>(result.key, result.count));
}
}
}
Scala
import org.apache.flink.api.common.state.ValueState
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.util.Collector
// the source data stream
val stream: DataStream[Tuple2[String, String]] = ...
// 在 keyed stream 上调用 prcess function
val result: DataStream[Tuple2[String, Long]] = stream
.keyBy(_._1)
.process(new CountWithTimeoutFunction())
/**
* 状态中保存的数据类型
*/
case class CountWithTimestamp(key: String, count: Long, lastModified: Long)
/**
* 包含了计数器和时间 ProcessFunction 实现
*/
class CountWithTimeoutFunction extends KeyedProcessFunction[Tuple, (String, String), (String, Long)] {
/** 这个 process function 函数保存的状态 */
lazy val state: ValueState[CountWithTimestamp] = getRuntimeContext
.getState(new ValueStateDescriptor[CountWithTimestamp]("myState", classOf[CountWithTimestamp]))
override def processElement(
value: (String, String),
ctx: KeyedProcessFunction[Tuple, (String, String), (String, Long)]#Context,
out: Collector[(String, Long)]): Unit = {
// 初始化或 检索/更新 状态
val current: CountWithTimestamp = state.value match {
case null =>
CountWithTimestamp(value._1, 1, ctx.timestamp)
case CountWithTimestamp(key, count, lastModified) =>
CountWithTimestamp(key, count + 1, ctx.timestamp)
}
// 将状态写回
state.update(current)
// 根据当前事件时间,调度下个 60 秒之后的定时器
ctx.timerService.registerEventTimeTimer(current.lastModified + 60000)
}
override def onTimer(
timestamp: Long,
ctx: KeyedProcessFunction[Tuple, (String, String), (String, Long)]#OnTimerContext,
out: Collector[(String, Long)]): Unit = {
state.value match {
case CountWithTimestamp(key, count, lastModified) if (timestamp == lastModified + 60000) =>
out.collect((key, count))
case _ =>
}
}
}
在 flink 1.4.0 之前,当调用处理时间计数器时,
ProcessFunction.onTimer()方法会设置当前的处理时间为事件时间戳。该行为是很隐秘的,而且很难被用户察觉到。然而这并不理想,因为处理时间时间戳是不确定的,而且无法与水印保持一致。除此之外,用户实现的逻辑取决于这个错误的时间戳很可能是无意中的错误,因此我们决定修复该错误。在 1.4.0 之后的版本,flink 任务使用该错误的事件时间戳将会导致失败,并且用户应该调整他们的任务为正确的逻辑。
5.4.4. KeyedProcessFunction
KeyedProcessFunction 是 ProcessFunction 方法的扩展,该函数可以通过他的 onTimer(...) 方法来访问 key 对应的定时器。
Java
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception {
K key = ctx.getCurrentKey();
// ...
}
Scala
override def onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT]): Unit = {
var key = ctx.getCurrentKey
// ...
}
5.4.5. 定时器
两种类型的定时器(处理时间和事件时间)都有 TimerService 在内部维护,并且在队列中排队等待执行。
TimerService 会每个 key 和时间戳对应的重复定时器,每个 key 和时间戳最多只有一个定时器。如果通过一个时间戳注册了多个定时器, onTimer() 方法也只会被调用一次。
flink 会同步调用 onTimer() 和 processElement() 方法,因此用户无需担心并发修改状态会有问题。
5.4.5.1. 容错
定时器具有容错功能,而且也和应用程序的状态一样拥有 checkpoint。在失败恢复,或从 savepoint 重启应用时,定时器也会恢复。
本应该恢复之前触发的处理时间定时器,将会被立即触发。该现象可能会在应用程序失败恢复或从 savepoint 重启时发生。
定时器会进行异步 checkpoint,除了合并 rocksDB 状态/增量快照/基于内存的定时器(将会在
FLINK-10026解决)这三种情况。注意,太多的定时器会增加 checkpoint 的时间,因为定时器也是 checkpoint 状态的一部分。查看下面的 “定时器合并” 章节来了解如何减少定时器的数量。
5.4.5.2. 定时器合并
因为 flink 对每个 key 和时间戳只会保留一个定时器,所以可以通过降低计时器的精度来减少计时器的数量。
对于1秒的计时器时间戳(事件或处理时间),可以将目标时间舍入到整秒。计时器将最多提前1秒触发,而且不会晚于请求的毫秒精度。因此,每个 key 和以秒为单位的时间戳最多有一个计时器。
Java
long coalescedTime = ((ctx.timestamp() + timeout) / 1000) * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);
Scala
al coalescedTime = ((ctx.timestamp + timeout) / 1000) * 1000
ctx.timerService.registerProcessingTimeTimer(coalescedTime)
因为事件时间定时器只会在水印到达时触发,因此你可以通过使用当前的水印来调度和合并对应下一个水印的定时器:
Java
long coalescedTime = ctx.timerService().currentWatermark() + 1;
ctx.timerService().registerEventTimeTimer(coalescedTime);
Scala
val coalescedTime = ctx.timerService.currentWatermark + 1
ctx.timerService.registerEventTimeTimer(coalescedTime)
定时器也可以通过以下方式被停止和移除:
停止一个处理时间定时器:
Java
long timestampOfTimerToStop = ...
ctx.timerService().deleteProcessingTimeTimer(timestampOfTimerToStop);
Scala
val timestampOfTimerToStop = ...
ctx.timerService.deleteProcessingTimeTimer(timestampOfTimerToStop)
停止一个事件时间定时器:
Java
long timestampOfTimerToStop = ...
ctx.timerService().deleteEventTimeTimer(timestampOfTimerToStop);
Scala
val timestampOfTimerToStop = ...
ctx.timerService.deleteEventTimeTimer(timestampOfTimerToStop)
如果没有通过给定的时间戳注册的定时器,则停止该定时器将不会有任何影响。
5.5. 异步I/O
本文讲解 Flink 用于访问外部数据存储的异步 I/O API。 对于不熟悉异步或者事件驱动编程的用户,建议先储备一些关于 Future 和事件驱动编程的知识。
提示:这篇文档 FLIP-12: 异步 I/O 的设计和实现 介绍了关于设计和实现异步 I/O 功能的细节。
5.5.1. 对于异步I/O操作的需求
在与外部系统交互(用数据库中的数据扩充流数据)的时候,需要考虑与外部系统的通信延迟对整个流处理应用的影响。
简单地访问外部数据库的数据,比如使用 MapFunction,通常意味着同步交互: MapFunction 向数据库发送一个请求然后一直等待,直到收到响应。在许多情况下,等待占据了函数运行的大部分时间。
与数据库异步交互是指一个并行函数实例可以并发地处理多个请求和接收多个响应。这样,函数在等待的时间内可以发送其他请求和接收其他响应。至少等待的时间可以被多个请求摊分。大多数情况下,异步交互可以大幅提高流处理的吞吐量。

注意:只提高 MapFunction 的并行度在有些情况下也可以提升吞吐量,但是这种做法通常会导致非常高的资源消耗:更多的并行 MapFunction 实例意味着更多的 Task、更多的线程、更多的 Flink 内部网络连接、更多的与数据库的网络连接、更多的缓冲和更多程序内部协调的开销。
5.5.2. 先决条件
如上节所述,正确地实现数据库(或 键/值 存储)的异步 I/O 交互需要数据库客户端支持异步请求,目前许多主流数据库都提供了这样的客户端。
如果没有这样的客户端,可以通过创建多个客户端并使用线程池处理同步调用的方法,将同步客户端转换为有限并发的客户端。然而,这种方法通常比正规的异步客户端效率要低。
5.5.3. 异步 I/O API
Flink 的异步 I/O API 允许用户在流处理中使用异步请求客户端。API 处理与数据流的集成,同时还能处理好顺序、事件时间和容错等。
在具备异步数据库客户端的基础上,实现数据流转换操作与数据库的异步 I/O 交互需要以下三部分:
- 实现分发请求的
AsyncFunction函数 - 获取数据库交互的结果并发送给
ResultFuture的 回调 函数 - 将异步 I/O 操作应用于
DataStream作为DataStream的一次转换操作。
下面是基本的代码模板:
Java
// 这个例子使用 Java 8 的 Future 接口(与 Flink 的 Future 相同)实现异步请求和回调。
/**
* 实现 'AsyncFunction' 用于发送请求和设置回调。
*/
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** 能够利用回调函数并发发送请求的数据库客户端 */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// 发送异步请求,接收 future 结果
final Future<String> result = client.query(key);
// 设置客户端完成请求后要执行的回调函数
// 回调函数只是简单地把结果发给 future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// 显示地处理异常。
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// 创建初始 DataStream
DataStream<String> stream = ...;
// 应用异步 I/O 转换操作
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
Scala
/**
* 实现 'AsyncFunction' 用于发送请求和设置回调。
*/
class AsyncDatabaseRequest extends AsyncFunction[String, (String, String)] {
/** 能够利用回调函数并发发送请求的数据库客户端 */
lazy val client: DatabaseClient = new DatabaseClient(host, post, credentials)
/** 用于 future 回调的上下文环境 */
implicit lazy val executor: ExecutionContext = ExecutionContext.fromExecutor(Executors.directExecutor())
override def asyncInvoke(str: String, resultFuture: ResultFuture[(String, String)]): Unit = {
// 发送异步请求,接收 future 结果
val resultFutureRequested: Future[String] = client.query(str)
// 设置客户端完成请求后要执行的回调函数
// 回调函数只是简单地把结果发给 future
resultFutureRequested.onSuccess {
case result: String => resultFuture.complete(Iterable((str, result)))
}
}
}
// 创建初始 DataStream
val stream: DataStream[String] = ...
// 应用异步 I/O 转换操作
val resultStream: DataStream[(String, String)] =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100)
重要提示: 第一次调用 ResultFuture.complete 后 ResultFuture 就完成了。 后续的 complete 调用都将被忽略。
下面两个参数控制异步操作:
- Timeout: 超时参数定义了异步请求发出多久后未得到响应即被认定为失败,它可以防止一直等待得不到响应的请求。
- Capacity: 容量参数定义了可以同时进行的异步请求数。即使异步 I/O 通常带来更高的吞吐量,但执行异步 I/O 操作的算子仍然可能成为流处理的瓶颈。 限制并发请求的数量可以确保算子不会持续累积待处理的请求进而造成积压,而是在容量耗尽时触发反压。
5.5.3.1. 超时处理
当异步 I/O 请求超时的时候,默认会抛出异常并重启作业。 如果你想处理超时,可以重写 AsyncFunction#timeout 方法。
5.5.3.2. 结果的顺序
AsyncFunction 发出的并发请求经常以不确定的顺序完成,这取决于请求得到响应的顺序。 Flink 提供两种模式控制结果记录以何种顺序发出。
- 无序模式: 异步请求一结束就立刻发出结果记录。 流中记录的顺序在经过异步 I/O 算子之后发生了改变。当使用 处理时间 作为基本时间特征时,这个模式具有最低的延迟和最少的开销。 此模式使用
AsyncDataStream.unorderedWait(...)方法。 - 有序模式: 这种模式保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同。为了实现这一点,算子将缓冲当前结果记录直到这条记录前面的所有记录都发出(或超时)。由于记录或者结果要在 checkpoint 的状态中保存更长的时间,所以与无序模式相比,有序模式通常会带来一些额外的延迟和 checkpoint 开销。此模式使用
AsyncDataStream.orderedWait(...)方法。
5.5.3.3. 事件时间
当流处理应用使用事件时间时,异步 I/O 算子会正确处理 watermark。对于两种顺序模式,这意味着:
-
无序模式: Watermark 既不超前于记录也不落后于记录,即 watermark 建立了顺序的边界。 只有连续两个 watermark 之间的记录是无序发出的。 在一个 watermark 后面生成的记录只会在这个 watermark 发出以后才发出。 在一个 watermark 之前的所有输入的结果记录全部发出以后,才会发出这个 watermark。
这意味着存在有 watermark 的情况下,无序模式 会引入一些与有序模式 相同的延迟和管理开销。开销大小取决于 watermark 的频率。
-
有序模式: 连续两个 watermark 之间的记录顺序也被保留了。开销与使用处理时间 相比,没有显著的差别。
请记住,摄入时间 是一种特殊的事件时间,它基于数据源的处理时间自动生成 watermark。
5.5.3.4. 容错保证
异步 I/O 算子提供了完全的精确一次容错保证。它会将正在处理的异步请求的记录保存在 checkpoint 中,在故障恢复时重新触发请求。
5.5.3.5. 实现提示
在实现使用 Executor(或者 Scala 中的 ExecutionContext)和回调的 Futures 时,建议使用 DirectExecutor,因为通常来说回调的工作量很小,DirectExecutor 避免了额外的线程切换开销。回调通常只是把结果发送给 ResultFuture,也就是把它添加进输出缓冲。从这里开始,包括发送记录和与 chenkpoint 交互在内的繁重逻辑都将在专有的线程池中进行处理。
DirectExecutor 可以通过 org.apache.flink.runtime.concurrent.Executors.directExecutor() 或 com.google.common.util.concurrent.MoreExecutors.directExecutor() 获得。
5.5.3.6. 警告
Flink 不以多线程方式调用 AsyncFunction
我们想在这里明确指出一个经常混淆的地方:AsyncFunction 不是以多线程方式调用的。 只有一个 AsyncFunction 实例,它被流中相应分区内的每个记录顺序地调用。除非 asyncInvoke(...) 方法快速返回并且依赖于(客户端的)回调, 否则无法实现正确的异步 I/O。
例如,以下情况导致阻塞的 asyncInvoke(...) 函数,从而使异步行为无效:
- 使用同步数据库客户端,它的查询方法调用在返回结果前一直被阻塞。
- 在
asyncInvoke(...)方法内阻塞等待异步客户端返回的 future 类型对象
目前,出于一致性的原因,AsyncFunction 的算子(异步等待算子)必须位于算子链的头部
根据 FLINK-13063 给出的原因,目前我们必须断开异步等待算子的算子链以防止潜在的一致性问题。这改变了先前支持的算子链的行为。需要旧有行为并接受可能违反一致性保证的用户可以实例化并手动将异步等待算子添加到作业图中并将链策略设置回通过异步等待算子的 ChainingStrategy.ALWAYS 方法进行链接。
6. 数据源
注意: 当前文档所描述的为新的数据源 API,在 Flink 1.11 中作为 FLIP-27 中的一部分引入。 该新 API 仍处于 BETA 阶段。
(从 Flink 1.11 开始)大多数现有的 source 连接器尚未使用此新 API 实现,仍旧使用之前的 API,也就是基于 SourceFunction 的实现的 API。
当前页面所描述的是 Flink 的 Data Source API 及其背后的概念和架构。 如果您对 Flink 中的 Data Source 如何工作感兴趣,或者您想实现一个新的数据 source,请阅读本文。
如果您正在寻找预定义的 source 连接器,请查看连接器文档.
6.1. Data Source 原理
核心组件
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
- 分片(Split) 是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
- 源阅读器(SourceReader) 会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的
SourceOperators并行运行,并产生并行的事件流/记录流。 - 分片枚举器(SplitEnumerator) 会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
Source 类作为API入口,将上述三个组件结合在了一起。

流处理和批处理的统一
Data Source API 以统一的方式对无界流数据和有界批数据进行处理。
事实上,这两种情况之间的区别是非常小的:在有界/批处理情况中,枚举器生成固定数量的分片,而且每个分片都必须是有限的。但在无界流的情况下,则无需遵从限制,也就是分片大小可以不是有限的,或者枚举器将不断生成新的分片。
6.1.1. 示例
以下是一些简化的概念示例,以说明在流和批处理情况下 data source 组件如何交互。
请注意,以下内容并没有准确地描述出 Kafka 和 File source 的工作方式,出于说明的目的,部分内容被简化处理。
有界 File Source
Source 包含待读取目录的 URI/路径(Path),以及一个定义了如何对文件进行解析的 格式(Format)。在该情况下:
- 分片是一个文件,或者是文件的一个区域(如果该文件格式支持对文件进行拆分)。
- SplitEnumerator 将会列举给定目录路径下的所有文件,并在收到来自 reader 的请求时对分片进行分配。一旦所有的分片都被分配完毕,则会使用 NoMoreSplits 来响应请求。
- SourceReader 则会请求分片,读取所分配的分片(文件或者文件区域),并使用给定的格式进行解析。如果当前请求没有获得下一个分片,而是 NoMoreSplits,则会终止任务。
无界 Streaming File Source
这个 source 的工作方式与上面描述的基本相同,除了 SplitEnumerator 从不会使用 NoMoreSplits 来响应 SourceReader 的请求,并且还会定期列出给定 URI/路径下的文件来检查是否有新文件。一旦发现新文件,则生成对应的新分片,并将它们分配给空闲的 SourceReader。
无界 Streaming Kafka Source
Source 将具有 Kafka Topic(亦或者一系列 Topics 或者通过正则表达式匹配的 Topic)以及一个 反序列化器(Deserializer) 来反序列化记录(record)。
- 分片是一个 Kafka 主题分区。
- SplitEnumerator 会连接到 broker 从而列举出已订阅的主题中的所有分区,枚举器可以重复此操作以检查是否有新的主题或分区。
- SourceReader 使用 KafkaConsumer 读取所分配的分片(Topic Partition),并使用提供的 反序列化器 反序列化记录。由于流处理中分片(Topic Partition)大小是无限的,因此 reader 永远无法读取到数据的尾部。
有界 Kafka Source
这种情况下,除了每个分片(Topic Partition)都会有一个预定义的结束偏移量,其他与上述相同。一旦 SourceReader 读取到分片的结束偏移量,整个分片的读取就会结束。而一旦所有所分配的分片读取结束,SourceReader 也就终止任务了。
6.2. Data Source API
本节所描述的是 FLIP—27 中引入的新 Source API 的主要接口,并为开发人员提供有关 Source 开发的相关技巧。
6.2.1. Source
Source API 是一个工厂模式的接口,用于创建以下组件。
- Split Enumerator
- Source Reader
- Split Serializer
- Enumerator Checkpoint Serializer
除此之外,Source 还提供了 Boundedness(有界性) 特性,从而使得 Flink 可以选择合适的模式来运行 Flink 任务。
Source 实现应该是可序列化的,因为 Source 实例会在运行时被序列化并上传到 Flink 集群。
6.2.2. SplitEnumerator
SplitEnumerator 被认为是整个 Source 的“大脑”。SplitEnumerator 的典型实现如下:
-
SourceReader的注册处理 -
SourceReader的失败处理SourceReader失败时会调用addSplitsBack()方法。SplitEnumerator 应当收回已经被分配,但尚未被该SourceReader确认(acknowledged)的分片。
-
SourceEvent的处理SourceEvents是SplitEnumerator和SourceReader之间来回传递的自定义事件。可以利用此机制来执行复杂的协调任务。
-
分片的发现以及分配
SplitEnumerator可以将分片分配到SourceReader从而响应各种事件,包括发现新的分片,新SourceReader的注册,SourceReader的失败处理等
SplitEnumerator 可以在 SplitEnumeratorContext 的帮助下完成所有上述工作,其会在 SplitEnumerator 的创建或者恢复的时候提供给 Source。 SplitEnumeratorContext 允许 SplitEnumerator 检索到 reader 的必要信息并执行协调操作。 而在 Source 的实现中会将 SplitEnumeratorContext 传递给 SplitEnumerator 实例。
SplitEnumerator 的实现可以仅采用被动工作方式,即仅在其方法被调用时采取协调操作,但是一些 SplitEnumerator 的实现会采取主动性的工作方式。例如,SplitEnumerator 定期寻找分片并分配给 SourceReader。 这类问题使用 SplitEnumeratorContext 类中的 callAsync() 方法比较方便。下面的代码片段展示了如何在 SplitEnumerator 不需要自己维护线程的条件下实现这一点。
class MySplitEnumerator implements SplitEnumerator<MySplit> {
private final long DISCOVER_INTERVAL = 60_000L;
/**
* 一种发现分片的方法
*/
private List<MySplit> discoverSplits() {...}
@Override
public void start() {
...
enumContext.callAsync(this::discoverSplits, splits -> {
Map<Integer, List<MockSourceSplit>> assignments = new HashMap<>();
int parallelism = enumContext.currentParallelism();
for (MockSourceSplit split : splits) {
int owner = split.splitId().hashCode() % parallelism;
assignments.computeIfAbsent(owner, new ArrayList<>()).add(split);
}
enumContext.assignSplits(new SplitsAssignment<>(assignments));
}, 0L, DISCOVER_INTERVAL);
...
}
...
}
6.2.3. SourceReader
SourceReader 是一个运行在 Task Manager 上的组件,用于处理来自分片的记录。
SourceReader 提供了一个拉动式(pull-based)处理接口。Flink 任务会在循环中不断调用 pollNext(ReaderOutput) 轮询来自 SourceReader 的记录。pollNext(ReaderOutput) 方法的返回值指示 SourceReader 的状态。
MORE_AVAILABLE- SourceReader 有可用的记录。NOTHING_AVAILABLE- SourceReader 现在没有可用的记录,但是将来可能会有记录可用。END_OF_INPUT- SourceReader 已经处理完所有记录,到达数据的尾部。这意味着 SourceReader 可以终止任务了。
pollNext(ReaderOutput) 会使用 ReaderOutput 作为参数,为了提高性能且在必要情况下,SourceReader 可以在一次 pollNext() 调用中返回多条记录。例如,有时外部系统的工作粒度为批。而一个批可以包含多个记录,但是 source 只能在批的边界处设置 Checkpoint。在这种情况下,SourceReader 可以一次将一个批中的所有记录通过 ReaderOutput 发送至下游。
然而,除非有必要,SourceReader 的实现应该避免在一次 pollNext(ReaderOutput) 的调用中发送多个记录。 这是因为对 SourceReader 轮询的任务线程工作是在一个事件循环(event-loop)中进行的,且不能被阻塞。
在创建 SourceReader 时,相应的 SourceReaderContext 会提供给 Source,而 Source 则会将相应的上下文传递给 SourceReader 实例。SourceReader 可以通过 SourceReaderContext 将 SourceEvent 传递给相应的 SplitEnumerator 。Source 的一个典型设计模式是让 SourceReader 发送它们的本地信息给 SplitEnumerator,后者则会全局性地做出决定。
SourceReader API 是一个底层(low-level) API,允许用户自行处理分片,并使用自己的线程模型来获取和移交记录。为了帮助实现 SourceReader,Flink 提供了 SourceReaderBase 类,可以显著减少编写 SourceReader 所需要的工作量。
强烈建议连接器开发人员充分利用 SourceReaderBase 而不是从头开始编写 SourceReader。更多详细信息,请阅读下面的 SplitReader API 部分。
6.2.4. Source 使用方法
为了通过 Source 创建 DataStream,需要将 Source 传递给 StreamExecutionEnvironment。例如,
Java
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Source mySource = new MySource(...);
DataStream<Integer> stream = env.fromSource(
mySource,
WatermarkStrategy.noWatermarks(),
"MySourceName");
...
Scala
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val mySource = new MySource(...)
val stream = env.fromSource(
mySource,
WatermarkStrategy.noWatermarks(),
"MySourceName")
...
6.3. SplitReader API
核心的 SourceReader API 是完全异步的, 但实际上,大多数 Sources 都会使用阻塞的操作,例如客户端(如 KafkaConsumer)的 poll() 阻塞调用,或者分布式文件系统(HDFS, S3等)的阻塞 I/O 操作。为了使其与异步 Source API 兼容,这些阻塞(同步)操作需要在单独的线程中进行,并在之后将数据提交给 reader 的异步线程。
SplitReader 是基于同步读取/轮询 Source 的高级API,例如 file source 和 Kafka source 的实现等。
核心是上面提到的 SourceReaderBase 类,其使用 SplitReader 并创建提取器(fetcher)线程来运行 SplitReader,该实现支持不同的线程处理模型。
6.3.1. SplitReader
SplitReader API 只有以下三个方法:
- 阻塞式的提取
fetch()方法,返回值为 RecordsWithSplitIds。 - 非阻塞式处理分片变动
handleSplitsChanges()方法。 - 非阻塞式的唤醒
wakeUp()方法,用于唤醒阻塞中的提取操作。
SplitReader 仅需要关注从外部系统读取记录,因此比 SourceReader 简单得多。 请查看这个类的 Java 文档以获得更多细节。
6.3.2. SourceReaderBase
常见的 SourceReader 实现方式如下:
- 有一个线程池以阻塞的方式从外部系统提取分片。
- 解决内部提取线程与其他方法调用(如
pollNext(ReaderOutput))之间的同步。 - 维护每个分片的水印(watermark)以保证水印对齐。
- 维护每个分片的状态以进行 Checkpoint。
为了减少开发新的 SourceReader 所需的工作,Flink 提供了 SourceReaderBase 类作为 SourceReader 的基本实现。 SourceReaderBase 已经实现了上述需求。要重新编写新的 SourceReader,只需要让 SourceReader 继承 SourceReaderBase,而后完善一些方法并实现 SplitReader。
6.3.3. SplitFetcherManager
SourceReaderBase 支持几个开箱即用的线程模型,取决于 SplitFetcherManager 的行为模式。 SplitFetcherManager 创建和维护一个分片提取器(SplitFetchers)池,同时每个分片提取器使用一个 SplitReader 进行提取。它还会决定如何分配分片给分片提取器。
例如,如下所示,一个 SplitFetcherManager 可能有固定数量的线程,每个线程对分配给 SourceReader 的一些分片进行抓取。

以下代码片段实现了此线程模型。
/**
* 一个SplitFetcherManager,它具有固定数量的分片提取器,
* 并根据分片 ID 的哈希值将分片分配给分片提取器。
*/
public class FixedSizeSplitFetcherManager<E, SplitT extends SourceSplit>
extends SplitFetcherManager<E, SplitT> {
private final int numFetchers;
public FixedSizeSplitFetcherManager(
int numFetchers,
FutureNotifier futureNotifier,
FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,
Supplier<SplitReader<E, SplitT>> splitReaderSupplier) {
super(futureNotifier, elementsQueue, splitReaderSupplier);
this.numFetchers = numFetchers;
// 创建 numFetchers 个分片提取器.
for (int i = 0; i < numFetchers; i++) {
startFetcher(createSplitFetcher());
}
}
@Override
public void addSplits(List<SplitT> splitsToAdd) {
// 根据它们所属的提取器将分片聚集在一起。
Map<Integer, List<SplitT>> splitsByFetcherIndex = new HashMap<>();
splitsToAdd.forEach(split -> {
int ownerFetcherIndex = split.hashCode() % numFetchers;
splitsByFetcherIndex
.computeIfAbsent(ownerFetcherIndex, s -> new ArrayList<>())
.add(split);
});
// 将分片分配给它们所属的提取器。
splitsByFetcherIndex.forEach((fetcherIndex, splitsForFetcher) -> {
fetchers.get(fetcherIndex).addSplits(splitsForFetcher);
});
}
}
使用这种线程模型的 SourceReader 可以像下面这样创建:
public class FixedFetcherSizeSourceReader<E, T, SplitT extends SourceSplit, SplitStateT>
extends SourceReaderBase<E, T, SplitT, SplitStateT> {
public FixedFetcherSizeSourceReader(
FutureNotifier futureNotifier,
FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,
Supplier<SplitReader<E, SplitT>> splitFetcherSupplier,
RecordEmitter<E, T, SplitStateT> recordEmitter,
Configuration config,
SourceReaderContext context) {
super(
futureNotifier,
elementsQueue,
new FixedSizeSplitFetcherManager<>(
config.getInteger(SourceConfig.NUM_FETCHERS),
futureNotifier,
elementsQueue,
splitFetcherSupplier),
recordEmitter,
config,
context);
}
@Override
protected void onSplitFinished(Collection<String> finishedSplitIds) {
// 在回调过程中对完成的分片进行处理。
}
@Override
protected SplitStateT initializedState(SplitT split) {
...
}
@Override
protected SplitT toSplitType(String splitId, SplitStateT splitState) {
...
}
}
SourceReader 的实现还可以在 SplitFetcherManager 和 SourceReaderBase 的基础上编写自己的线程模型。
6.4. 事件时间和水印
Source 的实现需要完成一部分事件时间分配和水印生成的工作。离开 SourceReader 的事件流需要具有事件时间戳,并且(在流执行期间)包含水印。有关事件时间和水印的介绍,请参见及时流处理。
旧版 SourceFunction 的应用通常在之后的单独的一步中通过
stream.assignTimestampsAndWatermarks(WatermarkStrategy)生成时间戳和水印。这个函数不应该与新的 Sources 一起使用,因为此时时间戳应该已经被分配了,而且该函数会覆盖掉之前的分片水印。
6.4.1. API
在 DataStream API 创建期间, WatermarkStrategy 会被传递给 Source,并同时创建 TimestampAssigner 和 WatermarkGenerator。
environment.fromSource(
Source<OUT, ?, ?> source,
WatermarkStrategy<OUT> timestampsAndWatermarks,
String sourceName)
TimestampAssigner 和 WatermarkGenerator 作为 ReaderOutput(或 SourceOutput)的一部分透明地运行,因此 Source 实现者不必实现任何时间戳提取和水印生成的代码。
6.4.1.1. 事件时间戳
事件时间戳的分配分为以下两步:
- SourceReader 通过调用
SourceOutput.collect(event, timestamp)将 Source 记录的时间戳添加到事件中。 该实现只能用于含有记录并且拥有时间戳特性的数据源,例如 Kafka、Kinesis、Pulsar 或 Pravega。 因此,记录中不带有时间戳特性的数据源(如文件)也就无法实现这一步了。 此步骤是 Source 连接器实现的一部分,不由使用 Source 的应用程序进行参数化设定。 - 由应用程序配置的
TimestampAssigner分配最终的时间戳。TimestampAssigner会查看原始的 Source 记录的时间戳和事件。分配器可以直接使用 Source 记录的时间戳或者访问事件的某个字段获得最终的事件时间戳。
这种分两步的方法使用户既可以引用 Source 系统中的时间戳,也可以引用事件数据中的时间戳作为事件时间戳。
注意: 当使用没有 Source 记录的时间戳的数据源(如文件)并选择 Source 记录的时间戳作为最终的事件时间戳时,默认的事件时间戳等于 LONG_MIN (=-9,223,372,036,854,775,808)。
6.4.1.2. 水印生成
水印生成器仅在流执行期间会被激活。批处理执行则会停用水印生成器,则下文所述的所有相关操作实际上都变为无操作。
数据 Source API 支持每个分片单独运行水印生成器。这使得 Flink 可以分别观察每个分片的事件时间进度,这对于正确处理事件时间偏差和防止空闲分区阻碍整个应用程序的事件时间进度来说是很重要的。

使用 SplitReader API 实现源连接器时,将自动进行处理。所有基于 SplitReader API 的实现都具有开箱即用(out-of-the-box)的分片水印。
为了保证更底层的 SourceReader API 可以使用每个分片的水印生成,必须将不同分片的事件输送到不同的输出(outputs)中:局部分片(Split-local) SourceOutputs。通过 createOutputForSplit(splitId) 和 releaseOutputForSplit(splitId) 方法,可以在总 ReaderOutput 上创建并发布局部分片输出。有关详细信息,请参阅该类和方法的 Java 文档。
7. 旁路输出
除了由 DataStream 操作产生的主要流之外,你还可以产生任意数量的旁路输出结果流。结果流中的数据类型不必与主要流中的数据类型相匹配,并且不同旁路输出的类型也可以不同。当你需要拆分数据流时,通常必须复制该数据流,然后从每个流中过滤掉不需要的数据,这个操作十分有用。
使用旁路输出时,首先需要定义用于标识旁路输出流的 OutputTag:
Java
// 这需要是一个匿名的内部类,以便我们分析类型
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
Scala
val outputTag = OutputTag[String]("side-output")
注意 OutputTag 是如何根据旁路输出流所包含的元素类型进行类型化的。
可以通过以下方法将数据发送到旁路输出:
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
你可以使用在上述方法中向用户暴露的 Context 参数,将数据发送到由 OutputTag 标识的旁路输出。这是从 ProcessFunction 发送数据到旁路输出的示例:
Java
DataStream<Integer> input = ...;
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = input
.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// 发送数据到主要的输出
out.collect(value);
// 发送数据到旁路输出
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});
Scala
val input: DataStream[Int] = ...
val outputTag = OutputTag[String]("side-output")
val mainDataStream = input
.process(new ProcessFunction[Int, Int] {
override def processElement(
value: Int,
ctx: ProcessFunction[Int, Int]#Context,
out: Collector[Int]): Unit = {
// 发送数据到主要的输出
out.collect(value)
// 发送数据到旁路输出
ctx.output(outputTag, "sideout-" + String.valueOf(value))
}
})
你可以在 DataStream 运算结果上使用 getSideOutput(OutputTag) 方法获取旁路输出流。这将产生一个与旁路输出流结果类型一致的 DataStream:
Java
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = ...;
DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);
Scala
val outputTag = OutputTag[String]("side-output")
val mainDataStream = ...
val sideOutputStream: DataStream[String] = mainDataStream.getSideOutput(outputTag)
8. 处理程序参数
几乎所有的 flink 程序,包括批和流,都有赖于外部的配置参数。他们被用于指定输入和输出的资源(比如路径或地址),系统参数(并行度,运行时配置),应用程序特殊参数(典型的就是被用于用户自定义函数)。
flink 提供了一个简单实用的 ParameterTool 来提供一些基础工具以解决上面说到的这些问题。请注意,并不是只能使用这里描述的 ParameterTool ,你也可以使用其他的框架,比如 Commons CLI 和 argparse4j 。
8.1. 从ParameterTool获取配置值
ParameterTool 提供了一些预定义的静态方法来读取配置,该工具内部保存了一个 Map 对象,因此他可以很简单的融入你自己的配置风格。
8.1.1. 从.properties文件获取
下面的方法将会读取一个 Properties 文件,然后提供 key/value 对:
String propertiesFilePath = "/home/sam/flink/myjob.properties";
ParameterTool parameter = ParameterTool.fromPropertiesFile(propertiesFilePath);
File propertiesFile = new File(propertiesFilePath);
ParameterTool parameter = ParameterTool.fromPropertiesFile(propertiesFile);
InputStream propertiesFileInputStream = new FileInputStream(file);
ParameterTool parameter = ParameterTool.fromPropertiesFile(propertiesFileInputStream);
8.1.2. 从命令行获取
下面的方式可以从命令行获取到类似于 --input hdfs:///mydata --elements 42 的参数。
public static void main(String[] args) {
ParameterTool parameter = ParameterTool.fromArgs(args);
// .. 常规代码 ..
8.1.3. 从系统配置获取
当启动一个 JVM 后,可以将系统配置传递给他: -Dinput=hdfs:///mydata。你也可以从这些系统配置初始化 ParameterTool 。
ParameterTool parameter = ParameterTool.fromSystemProperties();
8.2. 在程序中使用参数
现在你已经从一些地方获取到了参数,下面我们就可以通过各种方式使用他们了。
直接从 ParameterTool 中获取
ParameterTool 自己就有访问参数值的方法。
ParameterTool parameters = // ...
parameter.getRequired("input");
parameter.get("output", "myDefaultValue");
parameter.getLong("expectedCount", -1L);
parameter.getNumberOfParameters()
// .. 还有更多可用的方法
你可以在客户端提交的应用程序的 main() 方法中直接使用这些方法的返回值,比如,你可以向下面一样设置一个算子的并行度:
ParameterTool parameters = ParameterTool.fromArgs(args);
int parallelism = parameters.get("mapParallelism", 2);
DataSet<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).setParallelism(parallelism);
因为 ParameterTool 是序列化的,所以你可以在程序中传递它:
ParameterTool parameters = ParameterTool.fromArgs(args);
DataSet<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer(parameters));
然后在函数内部使用他获取从命令行传递的参数值。
8.2.1. 注册全局参数
在 ExecutionConfig 中注册的全局任务参数可以在 JobManager web 接口和所有用户定义的函数中作为配置值进行访问。
注册参数为全局参数:
ParameterTool parameters = ParameterTool.fromArgs(args);
// 设置执行环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(parameters);
在任何一个 rich 用户自定义函数中访问他们:
public static final class Tokenizer extends RichFlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
ParameterTool parameters = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
parameters.getRequired("input");
// .. do more ..
9. 测试
测试是每个软件开发过程中不可或缺的一部分, Apache Flink 同样提供了在测试金字塔的多个级别上测试应用程序代码的工具。
9.1. 测试用户自定义函数
通常,我们可以假设 Flink 在用户自定义函数之外产生了正确的结果。因此,建议尽可能多的用单元测试来测试那些包含主要业务逻辑的类。
9.1.1. 单元测试无状态、无时间限制的 UDF
让我们以以下无状态的 MapFunction 为例。
Java
public class IncrementMapFunction implements MapFunction<Long, Long> {
@Override
public Long map(Long record) throws Exception {
return record + 1;
}
}
Scala
class IncrementMapFunction extends MapFunction[Long, Long] {
override def map(record: Long): Long = {
record + 1
}
}
通过传递合适地参数并验证输出,你可以很容易的使用你喜欢的测试框架对这样的函数进行单元测试。
Java
public class IncrementMapFunctionTest {
@Test
public void testIncrement() throws Exception {
// 实例化你的函数
IncrementMapFunction incrementer = new IncrementMapFunction();
// 调用你实现的方法
assertEquals(3L, incrementer.map(2L));
}
}
Scala
class IncrementMapFunctionTest extends FlatSpec with Matchers {
"IncrementMapFunction" should "increment values" in {
// 实例化你的函数
val incrementer: IncrementMapFunction = new IncrementMapFunction()
// 调用你实现的方法
incremeter.map(2) should be (3)
}
}
类似地,对于使用 org.apache.flink.util.Collector 的用户自定义函数(例如 FlatMapFunction 或者 ProcessFunction),可以通过提供模拟对象而不是真正的 collector 来轻松测试。具有与 IncrementMapFunction 相同功能的 FlatMapFunction 可以按照以下方式进行单元测试。
Java
public class IncrementFlatMapFunctionTest {
@Test
public void testIncrement() throws Exception {
// 实例化你的函数
IncrementFlatMapFunction incrementer = new IncrementFlatMapFunction();
Collector<Integer> collector = mock(Collector.class);
// 调用你实现的方法
incrementer.flatMap(2L, collector);
// 使用正确的输出校验调用的 collector
Mockito.verify(collector, times(1)).collect(3L);
}
}
Scala
class IncrementFlatMapFunctionTest extends FlatSpec with MockFactory {
"IncrementFlatMapFunction" should "increment values" in {
// 实例化你的函数
val incrementer : IncrementFlatMapFunction = new IncrementFlatMapFunction()
val collector = mock[Collector[Integer]]
// 使用正确的输出校验调用的 collector
(collector.collect _).expects(3)
// 调用你实现的方法
flattenFunction.flatMap(2, collector)
}
}
9.1.2. 对有状态或及时UDF和自定义算子进行单元测试
对使用管理状态或定时器的用户自定义函数的功能测试会更加困难,因为它涉及到测试用户代码和 Flink 运行时的交互。 为此,Flink 提供了一组所谓的测试工具,可用于测试用户自定义函数和自定义算子:
OneInputStreamOperatorTestHarness(适用于DataStream上的算子)KeyedOneInputStreamOperatorTestHarness(适用于KeyedStream上的算子)TwoInputStreamOperatorTestHarness(f适用于两个DataStream的ConnectedStreams算子)KeyedTwoInputStreamOperatorTestHarness(适用于两个KeyedStream上的ConnectedStreams算子)
要使用测试工具,还需要一组其他的依赖项(测试范围)。
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-test-utils_2.11artifactId>
<version>1.13.6version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-runtime_2.11artifactId>
<version>1.13.6version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.11artifactId>
<version>1.13.6version>
<scope>testscope>
<classifier>testsclassifier>
dependency>
现在,可以使用测试工具将记录和 watermark 推送到用户自定义函数或自定义算子中,控制处理时间,最后对算子的输出(包括旁路输出)进行校验。
Java
public class StatefulFlatMapTest {
private OneInputStreamOperatorTestHarness<Long, Long> testHarness;
private StatefulFlatMap statefulFlatMapFunction;
@Before
public void setupTestHarness() throws Exception {
// 实例化用户自定义函数
statefulFlatMapFunction = new StatefulFlatMapFunction();
// 包装用户自定义函数为对应的算子
testHarness = new OneInputStreamOperatorTestHarness<>(new StreamFlatMap<>(statefulFlatMapFunction));
// 可选,配置执行环境
testHarness.getExecutionConfig().setAutoWatermarkInterval(50);
// open 测试工具(也会调用 RichFunction 函数的 open())
testHarness.open();
}
@Test
public void testingStatefulFlatMapFunction() throws Exception {
// 推送带有时间戳的元素到算子(也就是用户自定义函数)
testHarness.processElement(2L, 100L);
// 通过推进算子的带有水印的事件时间,以触发事件时间定时器
testHarness.processWatermark(100L);
// 通过直接推进算子的处理时间,以触发处理时间定时器
testHarness.setProcessingTime(100L);
// 回收发射的记录列表给断言
assertThat(testHarness.getOutput(), containsInExactlyThisOrder(3L));
// 回收发射到指定旁流输出的记录列表给断言(只用于 ProcessFunction)
//assertThat(testHarness.getSideOutput(new OutputTag<>("invalidRecords")), hasSize(0))
}
}
Scala
class StatefulFlatMapFunctionTest extends FlatSpec with Matchers with BeforeAndAfter {
private var testHarness: OneInputStreamOperatorTestHarness[Long, Long] = null
private var statefulFlatMap: StatefulFlatMapFunction = null
before {
// 实例化用户自定义函数
statefulFlatMap = new StatefulFlatMap
// 包装用户自定义函数为对应的算子
testHarness = new OneInputStreamOperatorTestHarness[Long, Long](new StreamFlatMap(statefulFlatMap))
// 可选,配置执行环境
testHarness.getExecutionConfig().setAutoWatermarkInterval(50);
// open 测试工具(也会调用 RichFunction 函数的 open())
testHarness.open();
}
"StatefulFlatMap" should "do some fancy stuff with timers and state" in {
// 推送带有时间戳的元素到算子(也就是用户自定义函数)
testHarness.processElement(2, 100);
// 通过推进算子的带有水印的事件时间,以触发事件时间定时器
testHarness.processWatermark(100);
// 通过推进算子的带有水印的事件时间,以触发事件时间定时器
testHarness.setProcessingTime(100);
// 回收发射的记录列表给断言
testHarness.getOutput should contain (3)
// 回收发射到指定旁流输出的记录列表给断言(只用于 ProcessFunction)
//testHarness.getSideOutput(new OutputTag[Int]("invalidRecords")) should have size 0
}
}
KeyedOneInputStreamOperatorTestHarness 和 KeyedTwoInputStreamOperatorTestHarness 可以通过为键的类另外提供一个包含 TypeInformation 的 KeySelector 来实例化。
Java
public class StatefulFlatMapFunctionTest {
private OneInputStreamOperatorTestHarness<String, Long, Long> testHarness;
private StatefulFlatMap statefulFlatMapFunction;
@Before
public void setupTestHarness() throws Exception {
// 实例化用户自定义函数
statefulFlatMapFunction = new StatefulFlatMapFunction();
// 包装用户自定义函数为对应的算子
testHarness = new KeyedOneInputStreamOperatorTestHarness<>(new StreamFlatMap<>(statefulFlatMapFunction), new MyStringKeySelector(), Types.STRING);
// open 测试工具(也会调用 RichFunction 函数的 open())
testHarness.open();
}
// 一些测试
}
Scala
class StatefulFlatMapTest extends FlatSpec with Matchers with BeforeAndAfter {
private var testHarness: OneInputStreamOperatorTestHarness[String, Long, Long] = null
private var statefulFlatMapFunction: FlattenFunction = null
before {
// 实例化用户自定义函数
statefulFlatMapFunction = new StateFulFlatMap
// 包装用户自定义函数为对应的算子
testHarness = new KeyedOneInputStreamOperatorTestHarness(new StreamFlatMap(statefulFlatMapFunction),new MyStringKeySelector(), Types.STRING())
// open 测试工具(也会调用 RichFunction 函数的 open())
testHarness.open();
}
// 一些测试
}
在 Flink 代码库里可以找到更多使用这些测试工具的示例,例如:
org.apache.flink.streaming.runtime.operators.windowing.WindowOperatorTest是测试算子和用户自定义函数(取决于处理时间和事件时间)的一个很好的例子。org.apache.flink.streaming.api.functions.sink.filesystem.LocalStreamingFileSinkTest展示了如何使用AbstractStreamOperatorTestHarness测试自定义 sink。具体来说,它使用AbstractStreamOperatorTestHarness.snapshot和AbstractStreamOperatorTestHarness.initializeState来测试它与 Flink checkpoint 机制的交互。
注意 AbstractStreamOperatorTestHarness 及其派生类目前不属于公共 API,可以进行更改。
9.1.2.1. 单元测试 Process Function
考虑到它的重要性,除了之前可以直接用于测试 ProcessFunction 的测试工具之外,Flink 还提供了一个名为 ProcessFunctionTestHarnesses 的测试工具工厂类,可以简化测试工具的实例化。考虑以下示例:
注意:要使用此测试工具,还需要引入上一节中介绍的依赖项。
Java
public static class PassThroughProcessFunction extends ProcessFunction<Integer, Integer> {
@Override
public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception {
out.collect(value);
}
}
Scala
class PassThroughProcessFunction extends ProcessFunction[Integer, Integer] {
@throws[Exception]
override def processElement(value: Integer, ctx: ProcessFunction[Integer, Integer]#Context, out: Collector[Integer]): Unit = {
out.collect(value)
}
}
通过传递合适的参数并验证输出,对使用 ProcessFunctionTestHarnesses 是很容易进行单元测试并验证输出。
Java
public class PassThroughProcessFunctionTest {
@Test
public void testPassThrough() throws Exception {
// 实例化用户自定义函数
PassThroughProcessFunction processFunction = new PassThroughProcessFunction();
// 包装用户自定义函数为对应的算子
OneInputStreamOperatorTestHarness<Integer, Integer> harness = ProcessFunctionTestHarnesses.forProcessFunction(processFunction);
// 推送带有时间戳的元素到算子(也就是用户自定义函数)
harness.processElement(1, 10);
// 回收发射的记录列表给断言
assertEquals(harness.extractOutputValues(), Collections.singletonList(1));
}
}
Scala
class PassThroughProcessFunctionTest extends FlatSpec with Matchers {
"PassThroughProcessFunction" should "forward values" in {
// 实例化用户自定义函数
val processFunction = new PassThroughProcessFunction
// 包装用户自定义函数为对应的算子
val harness = ProcessFunctionTestHarnesses.forProcessFunction(processFunction)
// 推送带有时间戳的元素到算子(也就是用户自定义函数)
harness.processElement(1, 10)
// 回收发射的记录列表给断言
harness.extractOutputValues() should contain (1)
}
}
有关如何使用 ProcessFunctionTestHarnesses 来测试 ProcessFunction 不同风格的更多示例,, 例如 KeyedProcessFunction,KeyedCoProcessFunction,BroadcastProcessFunction等,鼓励用户自行查看 ProcessFunctionTestHarnessesTest。
9.2. 测试 Flink 作业
9.2.1. JUnit 规则MiniClusterWithClientResource
Apache Flink 提供了一个名为 MiniClusterWithClientResource 的 Junit 规则,用于针对本地嵌入式小型集群测试完整的作业。 叫做 MiniClusterWithClientResource.
要使用 MiniClusterWithClientResource,需要添加一个额外的依赖项(测试范围)。
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-test-utils_2.11artifactId>
<version>1.13.6version>
<scope>testscope>
dependency>
让我们采用与前面几节相同的简单 MapFunction来做示例。
Java
public class IncrementMapFunction implements MapFunction<Long, Long> {
@Override
public Long map(Long record) throws Exception {
return record + 1;
}
}
Scala
class IncrementMapFunction extends MapFunction[Long, Long] {
override def map(record: Long): Long = {
record + 1
}
}
现在,可以在本地 Flink 集群使用这个 MapFunction 的简单 pipeline,如下所示。
Java
public class ExampleIntegrationTest {
@ClassRule
public static MiniClusterWithClientResource flinkCluster =
new MiniClusterWithClientResource(
new MiniClusterResourceConfiguration.Builder()
.setNumberSlotsPerTaskManager(2)
.setNumberTaskManagers(1)
.build());
@Test
public void testIncrementPipeline() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置测试环境
env.setParallelism(2);
// 值被收集到一个静态变量中
CollectSink.values.clear();
// 创建一个有自定义元素的流,并进行转化
env.fromElements(1L, 21L, 22L)
.map(new IncrementMapFunction())
.addSink(new CollectSink());
// 执行
env.execute();
// 校验结果
assertTrue(CollectSink.values.containsAll(2L, 22L, 23L));
}
// 创建一个测试 sink
private static class CollectSink implements SinkFunction<Long> {
// 必须是静态的
public static final List<Long> values = Collections.synchronizedList(new ArrayList<>());
@Override
public void invoke(Long value) throws Exception {
values.add(value);
}
}
}
Scala
class StreamingJobIntegrationTest extends FlatSpec with Matchers with BeforeAndAfter {
val flinkCluster = new MiniClusterWithClientResource(new MiniClusterResourceConfiguration.Builder()
.setNumberSlotsPerTaskManager(1)
.setNumberTaskManagers(1)
.build)
before {
flinkCluster.before()
}
after {
flinkCluster.after()
}
"IncrementFlatMapFunction pipeline" should "incrementValues" in {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 配置测试环境
env.setParallelism(2)
// 值被收集到一个静态变量中
CollectSink.values.clear()
// 创建一个有自定义元素的流,并进行转化
env.fromElements(1, 21, 22)
.map(new IncrementMapFunction())
.addSink(new CollectSink())
// 执行
env.execute()
// 校验结果
CollectSink.values should contain allOf (2, 22, 23)
}
}
// 创建一个测试 sink
class CollectSink extends SinkFunction[Long] {
override def invoke(value: Long): Unit = {
CollectSink.values.add(value)
}
}
object CollectSink {
// 必须是静态的
val values: util.List[Long] = Collections.synchronizedList(new util.ArrayList())
}
关于使用 MiniClusterWithClientResource 进行集成测试的几点备注:
- 为了不将整个 pipeline 代码从生产复制到测试,请将你的 source 和 sink 在生产代码中设置成可插拔的,并在测试中注入特殊的测试 source 和测试 sink。
- 这里使用
CollectSink中的静态变量,是因为Flink 在将所有算子分布到整个集群之前先对其进行了序列化。 解决此问题的一种方法是与本地 Flink 小型集群通过实例化算子的静态变量进行通信。 或者,你可以使用测试的 sink 将数据写入临时目录的文件中。 - 如果你的作业使用事件时间计时器,则可以实现自定义的 并行 源函数来发出 watermark。
- 建议始终以 parallelism > 1 的方式在本地测试 pipeline,以识别只有在并行执行 pipeline 时才会出现的 bug。
- 优先使用
@ClassRule而不是@Rule,这样多个测试可以共享同一个 Flink 集群。这样做可以节省大量的时间,因为 Flink 集群的启动和关闭通常会占用实际测试的执行时间。 - 如果你的 pipeline 包含自定义状态处理,则可以通过启用 checkpoint 并在小型集群中重新启动作业来测试其正确性。为此,你需要在 pipeline 中(仅测试)抛出用户自定义函数的异常来触发失败。
10. 实验功能
该章节描述 DataStream API 中的试验功能。试验功能还在评估中,可能是不稳定的,未完成的,也能在未来版本中有重大改变。
10.1. 将预分区数据流重解释为keyed流
我们可以将预分区的数据流重新解释为 keyed 流以避免 shuffle。
警告:被重新解释的数据流必须已经是完全预分区的流,该行为和 flink 的 keyBy 会将数据分区到一个 shuffle w.r.t. key-group 中一样。
该功能的一个用户案例为在两个任务之间进行物化 shuffle:第一个任务执行一个 keyBy shuffler 并且物化每个输出到一个分区中。第二个任务将迪哥任务作为 soruce,对于每个并行度实例,对应的从第一个任务创建的分区中读取数据。这些 source 现在可以被重新解释为 keyed 流,比如接受窗口。注意,这个技巧会使第二个作业尴尬地并行执行,但这对细粒度恢复方案很有帮助。
该重新解释功能提供过 DataStreamUtils 暴露:
static <T, K> KeyedStream<T, K> reinterpretAsKeyedStream(
DataStream<T> stream,
KeySelector<T, K> keySelector,
TypeInformation<K> typeInfo)
给予一个基础流,一个 key 选择器,和类型信息,这个方法就可以通过基础流创建一个 keyed 流。
代码示例:
Java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> source = ...
DataStreamUtils.reinterpretAsKeyedStream(source, (in) -> in, TypeInformation.of(Integer.class))
.window(TumblingEventTimeWindows.of(Time.seconds(1)))
.reduce((a, b) -> a + b)
.addSink(new DiscardingSink<>());
env.execute();
Scala
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = ...
new DataStreamUtils(source).reinterpretAsKeyedStream((in) => in)
.window(TumblingEventTimeWindows.of(Time.seconds(1)))
.reduce((a, b) => a + b)
.addSink(new DiscardingSink[Int])
env.execute()
11. Scala API 扩展
为了在 Scala 和 Java API 之间保持一定的一致性,一些 Scala 的高级表达式特性在批处理和流处理中都被遗漏了。
如果你想使用 Scala 所有的表达式,可以选择通过隐式转换来扩展 Scala API。
为了使用所有可用的扩展,你只需要在 DataStream API 中增加一个简单的 import 即可:
import org.apache.flink.streaming.api.scala.extensions._
或者只单个导入你喜欢的扩展。
11.1. 接受部分功能
一般来说,DataStream API 不接受匿名模式匹配函数来解析 tuple、case class 或 collection,如下所示:
val data: DataStream[(Int, String, Double)] = // [...]
data.map {
case (id, name, temperature) => // [...]
// 上面这行或导致下面的编译:
// "The argument types of an anonymous function must be fully known. (SLS 8.5)"
}
这个扩展在 DataStream Scala API 中引入了新的方法,这些方法在扩展的 API 中有一一对应的关系,这些方法确实支持匿名模式匹配函数。
11.1.1. DataStream API
| Method | Original | Example |
|---|---|---|
| mapWith | map (DataStream) | data.mapWith { case (_, value) => value.toString } |
| flatMapWith | flatMap (DataStream) | data.flatMapWith { case (_, name, visits) => visits.map(name -> _) } |
| filterWith | filter (DataStream) | data.filterWith { case Train(_, isOnTime) => isOnTime } |
| keyingBy | keyBy (DataStream) | data.keyingBy { case (id, _, _) => id } |
| mapWith | map (ConnectedDataStream) | data.mapWith( map1 = case (_, value) => value.toString, map2 = case (_, _, value, _) => value + 1 ) |
| flatMapWith | flatMap (ConnectedDataStream) | data.flatMapWith( flatMap1 = case (_, json) => parse(json), flatMap2 = case (_, _, json, _) => parse(json) ) |
| keyingBy | keyBy (ConnectedDataStream) | data.keyingBy( key1 = case (_, timestamp) => timestamp, key2 = case (id, _, _) => id ) |
| reduceWith | reduce (KeyedStream, WindowedStream) | data.reduceWith { case ((_, sum1), (_, sum2) => sum1 + sum2 } |
| projecting | apply (JoinedStream) | data1.join(data2). whereClause(case (pk, _) => pk). isEqualTo(case (_, fk) => fk). projecting { case ((pk, tx), (products, fk)) => tx -> products } |
对于每个方法的更多语义信息,请看考 DataStream API 文档。
如果只使用该扩展,你可以增加该 import:
import org.apache.flink.api.scala.extensions.acceptPartialFunctions
for the DataSet extensions and
对与 DataSet 扩展:
import org.apache.flink.streaming.api.scala.extensions.acceptPartialFunctions
下面的片段展示如何一起使用这些扩展方法(使用 DataSet API):
object Main {
import org.apache.flink.streaming.api.scala.extensions._
case class Point(x: Double, y: Double)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds = env.fromElements(Point(1, 2), Point(3, 4), Point(5, 6))
ds.filterWith {
case Point(x, _) => x > 1
}.reduceWith {
case (Point(x1, y1), (Point(x2, y2))) => Point(x1 + y1, x2 + y2)
}.mapWith {
case Point(x, y) => (x, y)
}.flatMapWith {
case (x, y) => Seq("x" -> x, "y" -> y)
}.keyingBy {
case (id, value) => id
}
}
}
12. Java Lambda 表达式
java 8 引进了一些新的语言特性,以更快更清晰的进行编码。lambda 表达式这个特性,打开了函数式编程的大门。lambda 表达式可以使用简单的方式来实现函数,而无需声明额外或匿名类。
flink 的 Java API 所有点的算子都支持使用 lambda 表达式,然后,当 lambda 表达式使用 java 泛型时,你需要明确的声明类型信息。
该文档展示如何使用 lambda 表达式以及当前的限制。对于 flink API 的泛型指定,请看考 DataSteam API overview。
12.1. 案例和限制
下例展示如何使用 lambda 表达式来实现一个简单的,内联 map() 函数来求输入值的平方。输入 i 的类型和 map() 函数的额输出参数类型并不需要显示声明,他们会被 java 编译器自动推断。
env.fromElements(1, 2, 3)
// 返回 i 的平方
.map(i -> i*i)
.print();
flink 可以从 OUT map(IN value) 的方法签名自动提取结果的类型信息,因为 OUT 并不是通用类型,而是 Integer。
不幸的是,比如 flatMap() 函数,如果签名为 void flatMap(IN value, Collector ,将会被 java 编译器编译为 void flatMap(IN value, Collector out)。这将导致 flink 无法自动推断输出的类型信息。
flink 将会抛出类似如下的异常:
org.apache.flink.api.common.functions.InvalidTypesException: The generic type parameters of 'Collector' are missing.
In many cases lambda methods don't provide enough information for automatic type extraction when Java generics are involved.
An easy workaround is to use an (anonymous) class instead that implements the 'org.apache.flink.api.common.functions.FlatMapFunction' interface.
Otherwise the type has to be specified explicitly using type information.
在这种情况下,类型信息需要被显式指定,否则输出类型将会变成 Object,这将导致无效的序列化。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.util.Collector;
DataSet<Integer> input = env.fromElements(1, 2, 3);
// 必须指定 collector 的类型
input.flatMap((Integer number, Collector<String> out) -> {
StringBuilder builder = new StringBuilder();
for(int i = 0; i < number; i++) {
builder.append("a");
out.collect(builder.toString());
}
})
// 明确指定类型信息
.returns(Types.STRING)
// 打印:"a", "a", "aa", "a", "aa", "aaa"
.print();
相同的问题也会在使用 map() 函数返回一般类型时发生,方法签名为 Tuple2 的方法会被消除为 Tuple2 map(Integer value) ,如下例所示:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
env.fromElements(1, 2, 3)
.map(i -> Tuple2.of(i, i)) // 二元组属性没有类型信息
.print();
通常来说,这些问题可以通过多种方式解决;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
// 明确调用 .returns(...) 函数
env.fromElements(1, 2, 3)
.map(i -> Tuple2.of(i, i))
.returns(Types.TUPLE(Types.INT, Types.INT))
.print();
// 使用具体的类
env.fromElements(1, 2, 3)
.map(new MyTuple2Mapper())
.print();
public static class MyTuple2Mapper extends MapFunction<Integer, Tuple2<Integer, Integer>> {
@Override
public Tuple2<Integer, Integer> map(Integer i) {
return Tuple2.of(i, i);
}
}
// 使用匿名函数
env.fromElements(1, 2, 3)
.map(new MapFunction<Integer, Tuple2<Integer, Integer>> {
@Override
public Tuple2<Integer, Integer> map(Integer i) {
return Tuple2.of(i, i);
}
})
.print();
// 在该例中,也可以使用元组子类
env.fromElements(1, 2, 3)
.map(i -> new DoubleTuple(i, i))
.print();
public static class DoubleTuple extends Tuple2<Integer, Integer> {
public DoubleTuple(int f0, int f1) {
this.f0 = f0;
this.f1 = f1;
}
}
13. 项目配置
每个 flink 程序都会依赖 flink 库,最低限度,程序也依赖于 flink 的 API。很多程序还会依赖其他的连接器库,比如 kafka、cassandra 等等。当运行 flink 程序时,不管是分布式部署,还是在 IDE 的测试运行,flink 的运行库都必须可用。
13.1. Flink核心和程序依赖
就像大多数系统运行自定义程序一样,flink 有两种类型的依赖:
-
Flink 核心依赖:flink 自身是由一系列系统运行时需要的类和依赖,比如协调、网络、checkpoint、失败恢复、API、算子(比如窗口)、资源管理等。当 flink 程序启动时,必须提供这些 flink 运行时的核心类和依赖。
这些核心的类和依赖都打包在
flink-distjar 内,它是 flinklib目录下的一部分,也是基础 flink 容器镜像的一部分。这些依赖类似于 java 中包含String和List的核心依赖(比如rt.jar、charsets.jar等)。flink 核心依赖不包含任何连接器或库(CEP、SQL、ML 等),以避免默认将过多的依赖和类包含到 classpath。事实上,我们一直默认尽可能少的保持核心依赖到 classpath,以避免依赖冲突。
-
用户程序依赖:所有的连接器、格式、用户程序需要的库。
用户程序通常会打包为一个 jar 包,该 jar 包含程序的代码和需要的连接器和库依赖。
用户程序依赖不需要明确的包含 flink DataStream API 和运行时库,因为这些是 flink 核心依赖的一部分。
13.2. 设置项目基础依赖
每个 flink 程序都对 API 有最低限度的依赖。
当手动设置项目时,需要增加下面的依赖以使用 java/scala API。这儿展示的是 maven 语法,其他构建工具也需要相同的依赖,比如:Gradle、SBT 等。
Java
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.11artifactId>
<version>1.13.6version>
<scope>providedscope>
dependency>
Scala
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.11artifactId>
<version>1.13.6version>
<scope>providedscope>
dependency>
重要提示:请注意所有的这些依赖都需要设置他们的 scope 为 provided,这意味着他们需要编译,但是他们不应该被打包到项目最终的程序 jar 包文件中。这些依赖是 flink 的核心依赖,他们已经是 flink 的核心依赖,在任何环境中都已经是可用的了。
强烈建议保持依赖 scope 为 provided。如果他们没有被设置为 provided,则最终的 JAR 包会变得非常大,因为它包含了 flink 所有的核心依赖。最坏的情况是,包含到程序 jar 包文件内的 flink 核心依赖和一些你自己的依赖版本发生冲突,这样的话就需要通过反向类加载来解决了。
Intellij的一些注意点:为了在 IntelliJ IDEA 中运行程序,需要勾选 Include dependencies with "Provided" scope 选项。如果该选项不可用,比如 IntelliJ IDEA 版本较低,简单的解决方式是创建一个 test 来调用程序的 main() 方法。
13.3. 增加连接器和库依赖
很多程序需要指定连接器或库来运行,比如 kafka、cassandra 等连接器。这些连快将诶器并不是 flink 核心依赖的一部分,必须增加为程序的依赖。
下面展示将 kafka 连接器增加到依赖中(maven 语法):
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.13.6version>
dependency>
我们建议将程序代码和所有他的依赖都打包到 jar-with-dependencies 形式的程序 jar 包,该程序 jar 包可以提交到已经在运行的 flink 集群,或者是增加到 flink 程序的容器镜像中。
通过 Java 项目模板 or Scala 项目模板 创建的项目,在运行 mvn clean package 命令时,会自动配置包含程序的依赖到最终的程序 jar 包。对于没有通过这些模板创建的项目,我们建议增加 maven shade 插件(下面的附录中有展)来构建程序的 jar 包,以包含所有要求的依赖。
重要提示:对于 maven 和其他构建工具来说,为了正确的打包依赖到程序的 jar 包文件,这些程序依赖必须指定 scope 为 compile。
13.4. Scala版本
scala 版本之间是不二进制兼容的。由于这个原因,scala 2.11 的 flink 不可以使用 scala 2.12 。
所有依赖 Scala 的 Flink 依赖,都以对应的 Scala 版本作为包名后缀,比如 flink-streaming-scala_2.11。
只使用 java 开发的话,可以使用任何 scala 版本,使用 scala 开发的话,需要采用程序匹配的 scala 版本。
请参考 构建向导 来获取如何使用指定 scala 版本构建 flink 的更多细节。
scala 2.12.8 之后的版本和 2.12.x 版本是不二进制兼容的,不可以将 flink 项目从 2.12.x 升级超过 2.12.8。用户可以参考下面提到的 build guide 来本地构建 flink 程序为更新的 scala 版本。为了构建可以正常工作,用户在构建时需要添加 -Djapicmp.skip 来跳过二进制兼容检查。
查看 Scala 2.12.8 发布笔记 来获取更多细节,相关引用如下:
第二个修复为不二进制兼容:2.12.8 编译器省略了早期 2.12 编译器生成的确定方法。但是,我们相信这些方法从来没被用过,而且已经被编译的代码仍然会继续工作。查看 pull request description 来获取更多细节。
13.5. Hadoop依赖
常规规则:永远不需要在你的程序中直接添加 hadoop 依赖。唯一的例外是使用现有的 Hadoop 输入/输出格式与 Flink 的 Hadoop 兼容性包装依赖。
如果你想在 flink 中使用 hadoop,你需要在 flink 环境中包含 hadoop 依赖,而不是增加 hadoop 为程序的依赖。flink 将使用通过环境变量 HADOOP_CLASSPATH 指定的 hadoop 依赖,可以通过下面的方式设置:
export HADOOP_CLASSPATH=`hadoop classpath`
这么设计有两点原因:
- 一些 hadoop 与 flink 核心的交互,可能会在用户程序启动之前发生,比如为 checkpoint 设置 HDFS ,通过 hadoop 的 kerberrs 证书验证,或在 YARN 上部署。
- Flink 的反向类加载方法从核心依赖项中隐藏了许多传递依赖项,这不仅适用于 flink 自己的核心依赖,也适用于提供的 hadoop 依赖。适用这种方式,程序就可以使用一些依赖的不同版本并且在运行时不会发生依赖冲突,相信我们,这很重要,因为hadoop的依赖树非常大。
如果你在 IDE 开发或测试中需要 hadoop 依赖,比如访问 HDFS,请配置这些依赖的 scope 为 test 或 provided。
13.6. Maven
13.6.1. 要求
唯一的要求是使用Maven 3.0.4(或更高),并且已经安装了 Java 8.x。
13.6.2. 创建项目
从下面的命令中选择一个来创建一个项目:
Maven Archetypes
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.13.6
该命令允许你命名你新创建的程序,并且交互式地让你项目 groupId、artifactId和 package 名称。
Quickstart Script
$ curl https://flink.apache.org/q/quickstart.sh | bash -s 1.13.6
我们建议你将该项目导入到你的 IDE 来开发或测试它。IntelliJ IDEA 支持 maven 项目开箱即用。如果你使用 Eclipse, m2e 插件 允许导入 Maven 项目。一些 Eclipse 包默认包含了这个插件,有些要求你手动安装。
请注意:Java 的默认 JVM 堆内存对于 flink 来说太小,你需要手动增加堆内存。在 Eclipse中,选择 Run Configurations -> Arguments ,然后在 VM Arguments 输入框中输入: -Xmx800m。在 IntelliJ IDEA 中,建议通过 Help | Edit Custom VM Options 菜单改变 JVM 选项。查看 该页面 来获取细节信息。
13.6.3. 构建项目
如果你想构建或打包你的项目,可以在你的项目目录下直接运行 mvn clean package 命令。然后你将会找到一个 JAR 文件包含你的程序,你增加的连接器或库也会被添加为项目的依赖,JAR 包位置为:target/。
注:如果你使用了不同于 StreamingJob 的类作为程序的主类或终端,我们建议你在的对应的 pom.xml 文件中改变 mainClass 设置。通过这种方式,flink 可以直接从 JAR 文件运行程序而无需额外指定主类。
13.7. Gradle
13.7.1. 要求
唯一的要求是使用 Gradle 3.x(或更高),并且安装 Java 8.x 。
13.7.2. 创建项目
使用下面的命令来创建一个项目:
Gradle Example
build.gradle
buildscript {
repositories {
jcenter() // 这只适用于 Gradle 的 'shadow' 插件
}
dependencies {
classpath 'com.github.jengelman.gradle.plugins:shadow:2.0.4'
}
}
plugins {
id 'java'
id 'application'
// 通过 shadow 插件生成 fat JAR
id 'com.github.johnrengelman.shadow' version '2.0.4'
}
// artifact 配置
group = 'org.myorg.quickstart'
version = '0.1-SNAPSHOT'
mainClassName = 'org.myorg.quickstart.StreamingJob'
description = """Flink Quickstart Job"""
ext {
javaVersion = '1.8'
flinkVersion = '1.13-SNAPSHOT'
scalaBinaryVersion = '2.11'
slf4jVersion = '1.7.15'
log4jVersion = '2.17.1'
}
sourceCompatibility = javaVersion
targetCompatibility = javaVersion
tasks.withType(JavaCompile) {
options.encoding = 'UTF-8'
}
applicationDefaultJvmArgs = ["-Dlog4j.configurationFile=log4j2.properties"]
task wrapper(type: Wrapper) {
gradleVersion = '3.1'
}
// declare where to find the dependencies of your project
repositories {
mavenCentral()
maven { url "https://repository.apache.org/content/repositories/snapshots/" }
}
// 注意:我们不能使用 "compileOnly" 或 "shadow" 配置,因为我们不能在 IDE 中运行代码,或使用 "gradle run"。
// 我们现在也不能从 shadowJar 中排除传递的依赖,具体查看 https://github.com/johnrengelman/shadow/issues/159。
// 显式定义我们想要包含在 "flinkShadowJar" 配置中的库
configurations {
flinkShadowJar // 进入 shadowJar 中的依赖
// 一直排除这些(也包括传递的依赖),因为 flink 已经提供了他们
flinkShadowJar.exclude group: 'org.apache.flink', module: 'force-shading'
flinkShadowJar.exclude group: 'com.google.code.findbugs', module: 'jsr305'
flinkShadowJar.exclude group: 'org.slf4j'
flinkShadowJar.exclude group: 'org.apache.logging.log4j'
}
// 声明程序和测试代码使用的依赖
dependencies {
// --------------------------------------------------------------
// 编译时的依赖不是 shadow jar 的一部分,已经在 flink 的 lib 目录提供
// --------------------------------------------------------------
compile "org.apache.flink:flink-streaming-java_${scalaBinaryVersion}:${flinkVersion}"
// --------------------------------------------------------------
// 应该打包到 shadow jar 内的依赖,比如连接器。这些必须在 flinkShadowJar 配置中
// --------------------------------------------------------------
//flinkShadowJar "org.apache.flink:flink-connector-kafka_${scalaBinaryVersion}:${flinkVersion}"
compile "org.apache.logging.log4j:log4j-api:${log4jVersion}"
compile "org.apache.logging.log4j:log4j-core:${log4jVersion}"
compile "org.apache.logging.log4j:log4j-slf4j-impl:${log4jVersion}"
compile "org.slf4j:slf4j-log4j12:${slf4jVersion}"
// 在这儿增加测试依赖
// testCompile "junit:junit:4.12"
}
// 是仅编译的依赖在测试中可用:
sourceSets {
main.compileClasspath += configurations.flinkShadowJar
main.runtimeClasspath += configurations.flinkShadowJar
test.compileClasspath += configurations.flinkShadowJar
test.runtimeClasspath += configurations.flinkShadowJar
javadoc.classpath += configurations.flinkShadowJar
}
run.classpath = sourceSets.main.runtimeClasspath
jar {
manifest {
attributes 'Built-By': System.getProperty('user.name'),
'Build-Jdk': System.getProperty('java.version')
}
}
shadowJar {
configurations = [project.configurations.flinkShadowJar]
}
settings.gradle
rootProject.name = 'quickstart'
Quickstart Script
bash -c "$(curl https://flink.apache.org/q/gradle-quickstart.sh)" -- 1.13.6 _2.11
我们建议你将该项目导入到你的 IDE 来开发或测试它。IntelliJ IDEA 在安装 Gradle 插件后支持 Gradle 项目。Eclipse 想要支持 Gradle 项目,需要通过 Eclipse Buildship 插件, shadow 插件要求在最新的导入向导中指定的 Gradle 版本 >= 3.0。你也可以使用 Gradle’s IDE integration 通过 Gradle 来创建项目文件。
请注意:Java 的默认 JVM 堆内存对于 flink 来说太小,你需要手动增加堆内存。在 Eclipse中,选择 Run Configurations -> Arguments ,然后在 VM Arguments 输入框中输入: -Xmx800m。在 IntelliJ IDEA 中,建议通过 Help | Edit Custom VM Options 菜单改变 JVM 选项。查看 该页面 来获取细节信息。
13.7.3. 构建项目
如果你想构建或打包你的项目,可以在你的项目目录下直接运行 mvn clean package 命令。然后你将会找到一个 JAR 文件包含你的程序,你增加的连接器或库也会被添加为项目的依赖,JAR 包位置为:build/libs/。
注:如果你使用了不同于 StreamingJob 的类作为程序的主类或终端,我们建议你在的对应的 build.gradle 文件中改变 mainClassName 设置。通过这种方式,flink 可以直接从 JAR 文件运行程序而无需额外指定主类。
13.8. SBT
13.8.1. 创建项目
你可以通过下面的两种方法创建一个新项目:
SBT Template
$ sbt new tillrohrmann/flink-project.g8
Quickstart Script
$ bash <(curl https://flink.apache.org/q/sbt-quickstart.sh)
13.8.2. 构建项目
你可以简单的使用 sbt clean assembly 命令来构建你的项目,该命令会在 target/scala_your-major-scala-version/ 目录下创建一个名为 your-project-name-assembly-0.1-SNAPSHOT.jar 的 fat-jar。
13.8.3. 运行项目
你需要指定 sbt run 命令来运行你的项目。
默认情况下,该命令会在运行 sbt 的 JVM 中运行你的任务。为了在不同的 JVM 中运行你的任务,可以在 build.sbt 中增加下面的内容:
fork in run := true
13.8.3.1. IntelliJ
我们建议你使用 IntelliJ 来开发你的 flink 任务。为了开始开发,你需要导入你新创建的项目到 IntelliJ。你可以通过 File -> New -> Project from Existing Sources... 来实现,然后选择你项目的目录。之后 IntelliJ 会自动探测 build.sbt 文件,然后完成所有设置。
为了运行你的 flink 任务,监控与你选择 mainRunner 模块为运行/调试配置的 classpath。该设置可以保证所有设置为 provided 的依赖都会在执行期间可用。你可以从 Use classpath of module 中通过 Run -> Edit Configurations... 来配置运行/调试配置,
13.8.3.2. Eclipse
为了将新创建的项目导入到 Eclipse,你首先首先创建 eclipse 项目文件。该项目文件可以通过 sbteclipse 插件创建。在你的 PROJECT_DIR/project/plugins.sbt 文件中加入下面的内容:
addSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "4.0.0")
在 sbt 中,使用下面的命令创建 eclipse 项目文件
> eclipse
现在你就可以通过 File -> Import... -> Existing Projects into Workspace 导入项目到 eclipse,然后选择项目目录了。
13.9. 附录:构建依赖为jar包的模板
为了在构建项目 JAR 包时包含声明的所以连接器和库的依赖,你可以使用下面的 shade 插件定义:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>3.1.1version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305exclude>
<exclude>org.slf4j:*exclude>
<exclude>log4j:*exclude>
excludes>
artifactSet>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>my.programs.main.clazzmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>