32、机器学习朴素贝叶斯
一、联合概率与条件概率
联合概率为所有条件均满足的概率p(A,B)
条件概率为在事件B发生的情况下事件A发生的概率p(A|B)
事件独立可推出p(A1,A2|B)=p(A1|B)p(A2|B)
贝叶斯公式: p ( C ∣ W ) = p ( W ∣ C ) p ( C ) p ( W ) p(C|W)=\frac{p(W|C)p(C)}{p(W)} p(C∣W)=p(W)p(W∣C)p(C),W为给定的特征值(词频),C为文档类型,可以理解为 p ( C ∣ F 1 , F 2 , . . . , ) = p ( F 1 , F 2 , . . . , ∣ C ) p ( C ) p ( F 1 , F 2 , . . . , ) p(C|F_1,F_2,...,)=\frac{p(F_1,F_2,...,|C)p(C)}{p(F_1,F_2,...,)} p(C∣F1,F2,...,)=p(F1,F2,...,)p(F1,F2,...,∣C)p(C)
p ( C ) p(C) p(C):每个文档类别的概率(该类文档词总数/所有文档词总数)
p ( W ∣ C ) p(W|C) p(W∣C)给定类别词出现的概率(改词出现次数/该类文档总词数)
p ( W ) p(W) p(W)为每个词在所有文档出现的频率

现有一篇被预测文档:出现了影院,支付宝,云计算,计算属于科技、娱乐的
类别概率?
科技:P(影院,支付宝,云计算 │科技)∗P(科技)= 8 100 ∗ 20 100 ∗ 63 100 ∗ ( 100 221 ) \frac{8}{100}∗\frac{20}{100}∗\frac{63}{100}∗(\frac{100}{221}) 1008∗10020∗10063∗(221100)=0.00456109
娱乐:P(影院,支付宝,云计算│娱乐)∗P(娱乐)= 56 121 ∗ 15 121 ∗ 0 121 ∗ ( 121 221 ) = 0 \frac{56}{121}∗\frac{15}{121}∗\frac{0}{121}∗(\frac{121}{221})=0 12156∗12115∗1210∗(221121)=0
如果词频列表里面有很多出现次数都为0,很可能计算结果都为零
解决方法:拉普拉斯平滑系数
P ( F 1 │ C ) = N i + α N + α m P(F1│C)=\frac{N_i+α}{N+αm} P(F1│C)=N+αmNi+α
α为指定的系数一般为1,m为训练文档中统计出的特征词个数
二、朴素贝叶斯
没有超参数、训练数据准确则模型准确,训练数据不准确则模型不准确
优点:来源于古典数数学模型,分类效果稳定。速度快,准确率高。对缺失数据不敏感,算法简单常用于文本分类。
缺点:先验概率 P ( F 1 , F 2 , . . . , F n ∣ C ) P(F_1,F_2,...,F_n|C) P(F1,F2,...,Fn∣C)的选择不恰当,会对结果造成影响。假设每个特征条件独立不太符合实际。依赖于训练集的统计结果。
from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report
###获取数据
news=fetch_20newsgroups(subset='all')
###分割训练集测试集
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target)
###将长文本转化为tfidf矩阵
tf=TfidfVectorizer()
x_train=tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test=tf.transform(x_test)
print(x_train.toarray())###x_train为sparse格式
###拟合模型
nb=MultinomialNB(alpha=1.0)
nb.fit(x_train,y_train)
y_pred=nb.predict(x_test)
##输出预测值和准确率
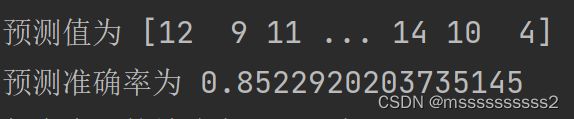
print('预测值为',y_pred)
y_score=nb.score(x_test,y_test)
print('预测准确率为',y_score)
##输出确率和召回率
print("每个类别的精确率和召回率:", classification_report(y_test, y_pred, target_names=news.target_names))
###获取数据
news=fetch_20newsgroups(subset='all')
###分割训练集测试集
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target)
###将长文本转化为tfidf矩阵
tf=TfidfVectorizer()
x_train=tf.fit_transform(x_train)
print(tf.get_feature_names())
```
```python
x_test=tf.transform(x_test)
print(x_train.toarray())###x_train为sparse格式

###拟合模型
nb=MultinomialNB(alpha=1.0)
nb.fit(x_train,y_train)
y_pred=nb.predict(x_test)
##输出预测值和准确率
print('预测值为',y_pred)
y_score=nb.score(x_test,y_test)
print('预测准确率为',y_score)
##输出确率和召回率
print("每个类别的精确率和召回率:", classification_report(y_test, y_pred, target_names=news.target_names))

三、精确率、召回率
混淆矩阵

精确率:预测结果为正例的样本中实际为正例的比例
召回率:实际结果为正例预测结果为正例的比例
f1-score:F1= 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l \frac{2*Precision*Recall}{Precision+Recall} Precision+Recall2∗Precision∗Recall