RISC-V OS(老师的OS) 基于 汪辰老师的视频笔记
前言
- 最后面没写完,以后再补。。。
RISC-V OS
RVOS 介绍
操作系统定义
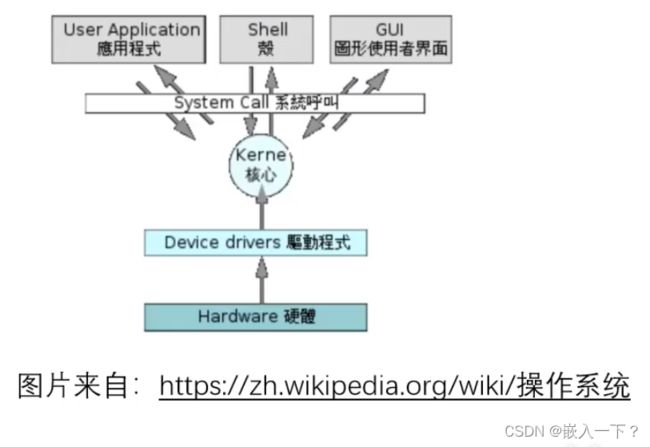
- 操作系统(英语:Operating System,缩写:OS)是一组系统软件程序:
- 主管并控制计算机操作、运用和运行硬件、软件资源。
- 提供公共服务来组织用户交互。
- 操作系统有广义和狭隘之分
- 狭义:内核
- 广义:发行包 = 内核 + 一组软件
操作系统的分类
| 分类 | 特点 | 应用场景 | RISC-V ISA 对其支持 |
|---|---|---|---|
| 裸机系统(Bare Metal) | 非常小,没有明显的分层设计,没有通用性。通常为单任务+中断系统 | 微型控制器,简单外设,简单实时任务。 | 简单的 Machine模式支持。 |
| 实时操作系统(Real-Time Operating Systems) | 中等规模,支持多任务,具备一定的通用性,和通用性相比更加强调实时性。 | 比较复杂的多任务和实时场景,丰富的外设。 | Machine + User; 或许需要支持物理内存保护(Physical Memory Protection,PMP)。 |
| 高级操作系统(Rich Operating Systems) | 大型规模,强调用户体验或者复杂通用性。 | 智能手持设备,PC工作站,云计算服务器… | Machine + Supervisor + User,需要支持虚拟机内存机制。 |

典型的 RTOS 介绍
FreeRTOS
FreeRTOS(https://www.freereos.org/)是一个很流行的应用在嵌入式设备上的实时操作系统内核。诞生于2003年。采用MIT许可证发布。
- 设计小巧,整个核心代码只有 3 到 4 个 C 文件
- 可读性强,易维护,大部分的代码都是C语言编写,很少的部分采用汇编语言。
- 支持优先级多线程(threads)、互斥锁(mutex)、信号量(semaphore)和软件计时器(software timer),支持低功耗处理以及一定程度的内存保护。
- 支持多种平台架构,包括ARM,x86,RISC-V等。
- 已经被移植到多款微处理器上。
RT-Thread
RT-Thread(https://www.rt-thread.org/)“是一个集实时操作系统(RTOS)内核、中核间组件和开发者社区于一体的技术平台,…也是一个组件完整丰富、高度可伸缩、简易开发、超低功耗、高安全性的物联网操作系统”。诞生于2006年。采用 Apache 2.0 许可证发布。
- 面向对象的实时内核;
- 8、32、256个优先级的多线程调度。对于同优先级线程使用时间片轮转调度法;
- 提供信号量、也提供互斥量以防止优先级反转;
- 支持其他高效的通信方式,比如邮箱、消息队列和事件标志;
- 支持静态内存分配方法,也支持线程安全的动态内存管理;
- 对高层应用提供设备框架。
- 支持多种平台架构,包括ARM,MISP,X86,Xtensa,C-Sky,RISC-V等
- 几乎支持市场上所有主流MCU和Wi-Fi芯片。
课程项目简介
RVOS
RVOS (https://github.com/plctlab/riscv-operating-system-mooc)是一个用于教学演示的操作系统内核。诞生于 2021年。采用 BSD 2-Clause 许可证发布。
- 设计小巧,整个核心有效代码~1000行;
- 可读性强,易维护,绝大部分代码为C语言,很少部分采用汇编;
- 演示了简单的内存分配管理实现;
- 演示了可抢占多线程调度实现,线程调度采用轮转调度法;
- 演示了简单的任务互斥实现;
- 演示了软件定时器实现;
- 演示了系统调用实现(M + U 模式);
- 支持 RV32;
- 支持QEMU - virt平台。
Hello RVOS
系统引导过程
硬件的一些基本概念
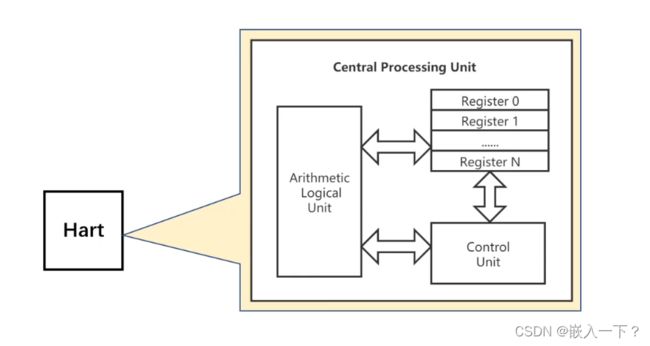
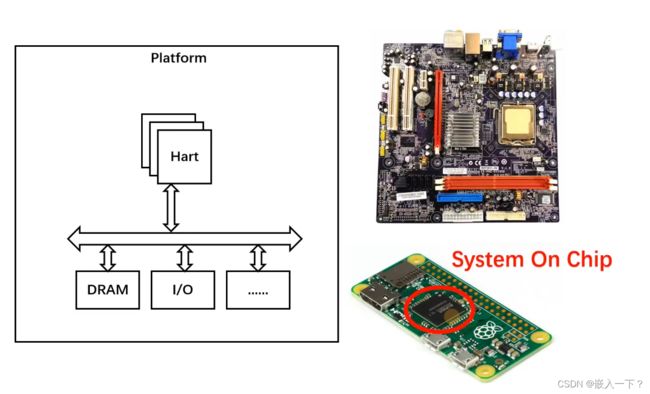
系统引导过程介绍
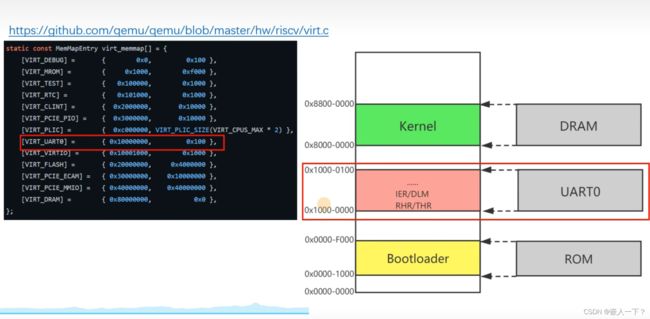
在qemu模拟器上,有8个Hart核
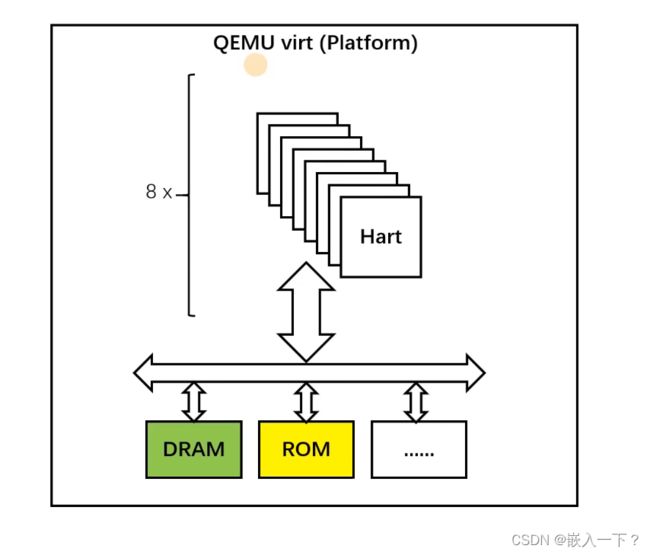
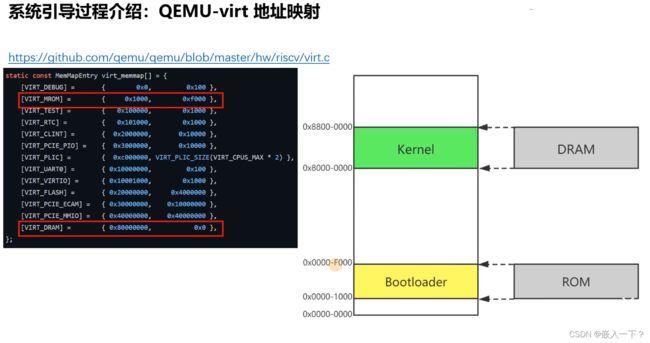
上电之后,系统自动运行到 Bootloader 的起始地址 0x0000 1000上去,然后在Booltloader 中,做一些硬件初始化之后就会跳到 Kernel 的地方。
在make中的 -Kernel 就是告诉模拟器,把代码加载到 Kernel 上,然后当跳转到Kernel时,就可以运行编写的代码了。
-Ttext = 0x8000 0000,就是告诉静态链接器,静态链接的指令的起始地址,从0x8000 0000开始。

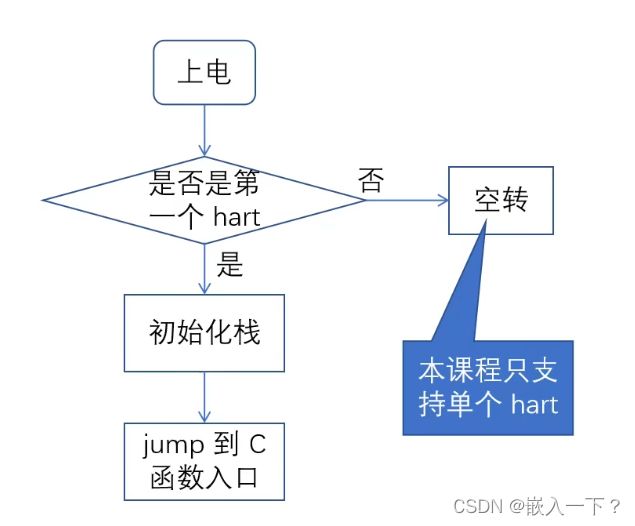
引导程序要做哪些事情
- 如何判断是当前 hart是不是第一个 hart
- 如何初始化栈
- 如何跳转到 C 语言的执行环境
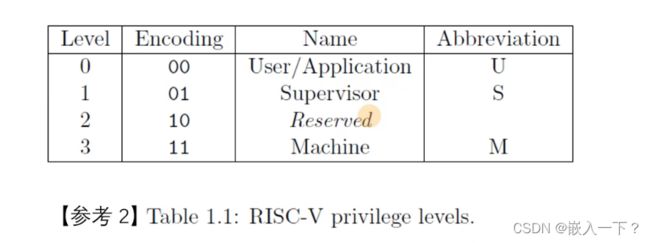
重提 Control and Status Registers(CSRs)
- 除了所有 Level 下都可以访问的通用寄存器之外,每个Level都有自己对应的一组寄存器。
- 高 Level 可以访问低 Level 的 CSR ,反之不可以。
- ISA Specification (“Zicsr” 扩展)定义了特殊的 CSR 指令来访问这些 CSR。
Machine 模式下的 CSR 列表

mhartid

- 该 CSR 只读
- 包含了运行当前指令的 hard 的ID
- 多个 hard 的 ID 必须是唯一的,且必须有一个 hard 的 ID 值为0(第一个 hard 的 ID)
CSR指令
- CSRRW(Read/Write CSR)
- CSRRS(Read and Set bits in CSR)
- CSRRC(Read and Clear bits in CSR)
- CSRRWI/CSRRSI/CSRRCI 和以上三个命令的区别是用 5 bit 的无符号立即数(zero-extending)代替了 rs1.
- opcode 取值 SYSTEM (值为 1110011)。

CSRRW(Atomic Read/Write CSR)
| 语法 | CSRRW RD, CSR, RS1 | |
|---|---|---|
| 例子 | csrrw rd, csr, rs1 | t6 = mscratch; mscratch = t6 |
-
CSRRW 先读出 CSR 中的值,将其 XLEN 位的宽度进行“零扩展(zero-extend)”后写入 RD,然后将RS1中的值写入 CSR。
-
以上两个步骤以“原子性(atomically)(在一条指令里面完成,是不可以被打断的)”方式完成。
-
如果 RD 是 X0,则不对 CSR 执行读操作。
-
伪指令:
pseudoinstruction Base Instruction Meaning csrw csr, rs csrrw x0, csr, rs Write CSR
CSRRS(Atomic Read and Set Bits in CSR)
| 语法 | CSRRS RD, CSR, RS1 | |
|---|---|---|
| 例子 | csrrs x5, mie, x6 | x5 = mie; mie |= x6 |
-
CSRRS 先读出 CSR 中的值,将其按 XLEN 位的宽度进行“零扩展(zero-extend)”后写入 RD;然后逐个检查 RS1 中的值,如果某一位 为 1 则对 CSR 的对应位 置1,否则保持不变。
-
以上两个步骤以“原子性(atomically)”方式完成。
-
伪指令:
pseudoinstruction Base Instruction Meaning csrr rd, csr csrrs rd, csr, x0 Read CSR
判断是否是第一个hart

“Hello,RVOS!”
UART 的硬件连接方式
红线是串口
一般串口通信至少需要三跟线(RS232、TTL):RX、TX、GND,地线是用来确定基准电压的,从基准电压,来判断两个信号线的电平。当然还有用两个线的情况(RS485差分信号)。

UART 的特点
- UART(Universal Asynchronous Receiver and Transmitter)
- 串行:相对于并行,串行是按位来进行传递,即一位一位的发送和接收。波特率(baud rate),每秒传输的二进制位数,单位为 bps(bit per second)。
- 异步:相对于同步,异步数据传输的过程中,不需要时钟线,直接发送数据,但需要约定通讯协议格式。
- 全双工:相对于单工和半双工,全双工指可以同时进行收发两方的数据传递。
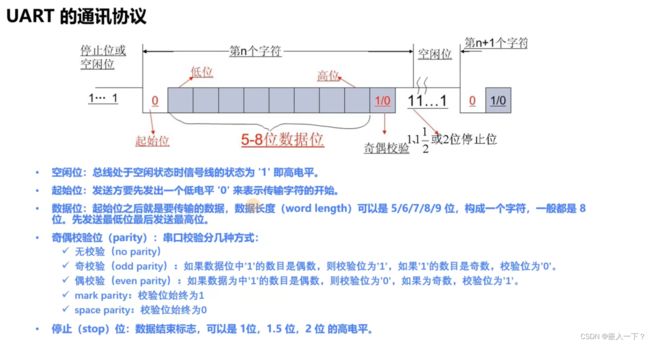
UART 的通讯协议
-
空闲位:总线处于空闲状态时信号线的状态为 ‘1’ 即高电平。
-
起始位:发送方要先发出一个低电平 ‘0’ 来表示传输字符的开始。
-
数据位:起始位之后就是要传输的数据,数据长度(word length)可以是 5/6/7/8/9 位,构成一个字符,一般都是8位。先发送最低位最后发送最高位。
-
奇偶校验位(parity):串口校验几种方式:
-
无校验(no parity)
-
奇校验(odd parity):如果数据位中 ‘1’ 的数目是偶数,则校验位为 ‘1’,如果 ‘1’ 的数目是奇数,校验位为 ‘0’。
-
偶校验(even parity):如果数据位中 ‘1’ 的数目是偶数,则校验位为 ‘0’,如果为奇数,校验位为 ‘1’。

-
mark parity:校验位始终为 1
-
space parity:校验位始终为 0
-
-
停止(stop)位:数据结束标志,可以是 1位,1.5位,2位 的高电平。
NS16550a 编程接口介绍
uart0 寄存器解释
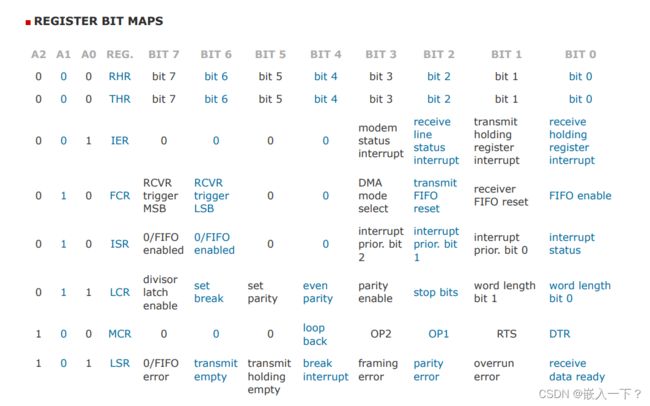
要访问、设置 uart0,首先得对其寄存器有所了解,对于uart0来说,每 1bit 地址,都有对应的一个或多个寄存器,每 1bit 可以访问 1Byte 的空间,可以通过 [uart0 + 对应位偏移地址](偏移地址范围在 0 ~ 7(2^3)之间),寻找到对应的位,来访问、设置这些寄存器。

-
第0bit:
- RHR、THR都是位于 uart0 的第0位偏移地址,读写都用该位寄存器,使用时注意不要同时使用。
- RHR寄存器(读取模式下),是用来接收数据的,当LSR寄存器的 第0bit 置位为1时,说明有数据进来,此时该寄存器中有数据,可以读取出来,并手动把 LSR 第0bit 清0 。
- THR寄存器(写入模式下),是用来发送数据的,当需要发送数据时,访问该寄存器,把需要发送的数据写入其中,就可以发送写入的数据,不过有一个前提就是LSR寄存器访问空间的第 5bit 为零才可以发送出去。
- DLL寄存器(写入模式下),是用来设置对于晶振除法分频值的,除出来的值当作波特率使用。这里只能设置除法分频值的低8位,当且仅当LCR的 第7bit 为1时,可设置该寄存器。
-
第1bit:
-
IER寄存器(写入模式下),用于使能中断,有 4 个中断,调制解调器状态中断、接收线路状态中断、发送保持寄存器中断、接收保持寄存器中断,分别为寄存器的 bit3、bit2、bit1、bit0,设置对应位为1使能该中断。
-
DLM寄存器(写入模式下),是用来设置对于晶振除法分频值的,除出来的值当作波特率使用。这里只能设置除法分频值的高8位,当且仅当LCR的 第7bit 为1时,可设置该寄存器。

-
-
第2bit:
- FCR寄存器(写入模式下),FIFO(队列)控制寄存器:
- 第7bit:数据接收器 触发 高位
- 第6bit:数据接收器 触发 低位
- 第3bit:DMA模式设置
- 第2bit:发送队列复位
- 第1bit:接收队列复位
- 第0bit:队列使能
- ISR寄存器(读取模式下),中断状态寄存器:
- 第7bit:FIFO使能状态寄存器
- 第6bit:FIFO使能状态寄存器
- 第3bit:中断优先级位2
- 第2bit:中断优先级位1
- 第1bit:中断优先级位0
- 第0bit:中断状态
- FCR寄存器(写入模式下),FIFO(队列)控制寄存器:
-
第3bit:
-
LCR寄存器,线路控制:
-
第7bit:波特锁存器 1使能
-
第6bit:中断控制位。当设置为1时,它会导致传输中断条件(TX被强制为低状态)。
-
第5bit:强制奇偶校验始终为1或0。当此位设置为1时,如果LCR-4为1,则奇偶校验将始终为0,如果LCR-4为0,则奇偶性将始终为1。
-
第4bit:如果启用了奇偶校验(LCR BIT 3)LCR BIT 4选择偶数或奇数格式。0奇数;1偶数。
-
第3bit:可通过该位选择奇偶校验或无奇偶校验。 0无;1发送时生成奇偶校验,接收时检查奇偶校验。
-
第2bit:停止位的数量可以由该位指定。

-
第1、0bit:这两个比特指定要发送或接收的字长度。

-
-
-
第4bit:MCR寄存器,调制解调器控制,不解释。
-
第5bit:
- LSR寄存器,线路状态:
- 第7bit:为1时,FIFO中至少有一个奇偶校验错误、成帧错误或中断指示符。读取LSR时清除。
- 第6bit:发送保持寄存器为空。在FIFO模式下,每当发送器FIFO和发送移位寄存器为空时,该位设置为1。
- 第5bit:为1时,发送器保持寄存器(或FIFO)为空。CPU可以加载下一个字符。
- 第4bit:为1时,接收器接收到中断信号(RX在一个字符时间帧内为低)。
- 第3bit:为1时,收到帧错误。接收的数据没有有效的停止位。
- 第2bit:为1时,奇偶校验错误。接收数据没有正确的奇偶校验信息
- 第1bit:为1时,溢出错误。在接收保持寄存器被清空之前保留的一个字符,或者如果FIFO被启用,则只有在FIFO已满并且下一个字符在移位寄存器中被完全接收之后,才会发生溢出错误。请注意,移位寄存器中的字符被覆盖,但不会被传输到FIFO。
- 第0bit:为1时,数据已被接收并保存在接收保持寄存器或FIFO中。
- LSR寄存器,线路状态:
-
第6bit:MSR寄存器,调制解调器状态,不解释。
-
第7bit:SPR寄存器,高速暂存存储器,不解释。

NS16550a 的初始化

void uart_init()
{
// 失能中断
uart_write_reg(IER, 0x00)
// 设置波特率。如果我们关心除数,这里只是一个演示,
// 但对于我们的目的[QEMU-virt],这实际上没有什么作用。
//
// 请注意,除数寄存器DLL(最小除数锁存器)和DLM(最大除数锁紧器)
// 具有与接收器/发送器和中断使能寄存器相同的基址。
// 为了改变基址指向的内容,我们通过将1写入除数锁存访问位(DLAB)
// 来打开“除数锁”,该位是行控制寄存器(LCR)的位索引7。
//
// 关于波特率值,请参见[1]“波特率生成器编程表”。
// 当1.8432 MHZ晶体时,我们使用38.4K,因此对应的值是3。
// 由于除数寄存器是两个字节(16位),因此我们需要将3(0x0003)的值
// 拆分为两个字节,DLL存储低字节,DLM存储高字节。
// 获取当前LCR寄存器的值
uint8_t lcr = uart_read_reg(LCR);
// 设置LCR寄存器,除数锁存器使能
uart_write_reg(LCR, lcr | 0x80);
// 设置晶振分频值,分频之后的就是波特率。
uart_write_reg(DLL, 0x03);
uart_write_reg(DLM, 0x00);
// 继续设置异步数据通信格式。
// -字长数:8位
// -停止位数:字长为8位时为1位
// -无奇偶校验
// -无中断控制
// -禁用波特锁存器
lcr = 0;
uart_write_reg(LCR, lcr | 0x03);
}
NS16550a 的数据读写
- UART 工作方式位全双工,分发送(TX)和接收(RX)两个独立的方向进行数据传输。
- 对数据的 TX/RX 有两种处理方式:
- 轮询处理方式
- 中断处理方式
LSR 第 5bit 判断是否空闲,若是空闲,则把数据赋值给 THR 发送出去。

// 发送一个字符,返回 THR 状态
int uart_putc(char ch)
{
// 等待可以发送数据c
while ((uart_read_reg(LSR) & LSR_TX_IDLE) == 0);
return uart_write_reg(THR, ch);
}
// 等待接收一个字符,返回接收的字符
int uart_getc(void)
{
// 等待接收到数据
while ((uart_read_reg(LSR) & LSR_RX_READY) == 0);
return uart_read_reg(RHR);
}
内存管理

对内存进一步的管理,实现动态的分配和释放
内存管理分类
- 自动管理内存 - 栈(stack)
- 静态内存 - 全局变量/静态变量
- 动态管理内存 - 堆(heap)
内存映射表(Memory Map)
对于 0x8000 0000 到 0x8800 0000 这块内存,可以大致分为heap、.bss、.data、.rodata、.text 这5段。

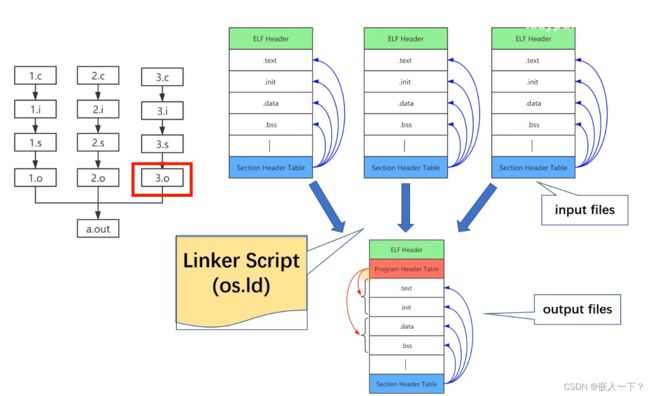
Linker Script 链接脚本
# 原来是只有指定链接器到对应的地址0x8000 0000
${CC} ${CFLAGS} -Ttext=0x80000000 -o os.elf $^
# |
# ⬇
# 现在通过链接器文件,把需要配置的都放在文件里面
${CC} ${CFLAGS} -T os.ld -o os.elf $^
-
GNU ld 使用 Linker Script 来描述和控制链接过程。
-
Linker Script 是简单的纯文本文件,采用特定的脚本描述语言编写。
-
每个 Linker Script 中包含有多条命令(Command)
-
注释采用 “/*” 和 “*/”括起来
-
gcc -T os.ld …
-
更多语法见【参考1】

ENTRY
| 语法 | ENTRY(symbol) |
|---|---|
| 例子 | ENTRY(_start) |
- ENTRY 命令用于设置“入口点(entry point)”,即程序中执行的第一条指令。
- ENTRY 命令的参数是一个符号(symbol)的名称。
OUTPUT_ARCH
| 语法 | OUTPUT_ARCH(bfdarch) |
|---|---|
| 例子 | OUTPUT_ARCH(“riscv”) |
- OUTPUT_ARCH 命令指定输出文件所适用的计算机体系架构。
MEMORY
| 语法 | MEMORY { name[(attr)]: ORIGIN = origin, LENGTH = len … } |
| 例子 | MEMORY { rom(rx): ORIGIN = 0, LENGTH = 256K ram(!rx): org = 0x40000000, l = 4M } |
- rom 为内存区域
- [(attr)] 用于指定是否为 未在链接器脚本中 显式映射的 input section 使用特定的内存区域。
- 这里我们分配“w”(可写)、“x”(可执行)和“a”(可分配)。
- 我们使用“!”将“r”(只读)和“i”(已初始化)反转。
- ORIGIN 用于指示起始地址
- LENGTH 内存区域大小。
- MEMORY 用于描述目标机器上内存区域的位置、大小和相关。
SECTIONS
| 语法 | 例子 |
|---|---|
| SECTIONS { section-command section-command } |
SECTIONS { . = 0x10000; .text : {*(.text)} . = 0x80000000; .data : {*(.data)} .bss : {*(.bss)} }>ram |
- 这里的 “. = 地址值” 是指定一个地址位置,例如 . = 0x10000 就是指定地址到0x10000,然后后面跟个 .text : {*(.text)} 就是把 .text 的文本节 放到该地址位置处,里面的*(.text)就是包含所有输入文件的 .text section。
- SECTIONS 告诉链接器如何将 input section 映射到 output section ,以及如何将 optput sections 放置在内存中。
- sections - command 除了可以是对 out section 的描述外还可以是符号赋值命令等其他形式。
PROVIDE
| 语法 | PROVIDE(symbol = expression) |
| 例子 | PROVIDE(_text_start = .) |
- 可以在 Linker Script 中定义符号(Symbols)
- 每个符号包括一个名字(name)和一个对应的地址值(address)
- 在代码中可访问这些符号,等同于访问一个地址。
通过符号获取各个 output sections 在内存中的地址范围
在 os.ld 文件中定义了各个内存区域的开始地址和结束地址。
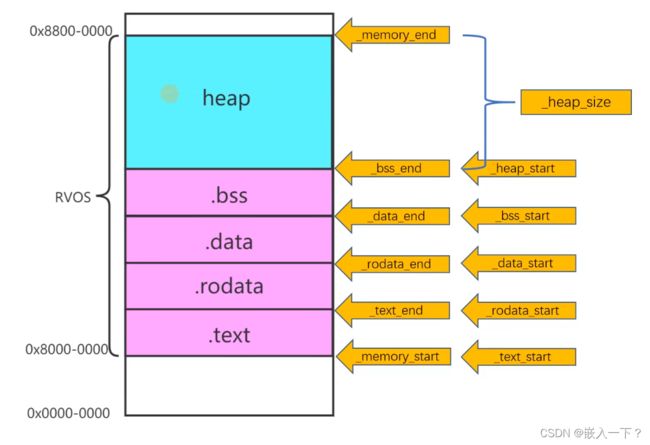
从 Linker Script 到 Code
在汇编语言中通过标号把地址值存在其中,然后调用标号获取各个地址值,这个标号相当于C语言中的全局变量。

os.ld 翻译解释
/*
* rvos.ld
* 用于输出到RVOS的链接器脚本
*/
/*
* https://sourceware.org/binutils/docs/ld/Miscellaneous-Commands.html
* OUTPUT_ARCH 命令指定特定的输出计算机体系架构。
* “riscv”是64位和32位RISC-V目标的架构名称。
* 我们将在调用gcc时使用-march=rv32ima
* 和-mabi=ilp32来进一步完善这一点。
*/
OUTPUT_ARCH( "riscv" )
/*
* https://sourceware.org/binutils/docs/ld/Entry-Point.html
* ENTRY命令用于设置“入口点”,这是程序中要执行的第一条指令。
* ENTRY命令的参数是一个符号名称,这里是start.S中定义的“_start”。
*/
ENTRY( _start )
/*
* https://sourceware.org/binutils/docs/ld/MEMORY.html
* MEMORY 命令描述目标中内存块的位置和大小。
* MEMORY 的语法为:
* MEMORY
* {
* name [(attr)] : ORIGIN = origin, LENGTH = len
* ......
* }
* 每行定义一个内存区域。
*
* 每个内存区域必须在 MEMORY 命令中具有不同的名称。
* 这里我们只定义了一个名为“ram”的区域。
* “attr”字符串是一个可选的属性列表,
* 用于指定是否为 未在链接器脚本中 显式映射的 input section 使用特定的内存区域。
* 这里我们分配“w”(可写)、“x”(可执行)和“a”(可分配)。
* 我们使用“!”将“r”(只读)和“i”(已初始化)反转。
*
* “ORIGIN”用于设置内存区域的起始地址。
* 这里我们将它放在0x8000_0000的开头,
* 因为这是QEMUvirt机器开始执行的地方。
* 最后,LENGTH=128M告诉链接器,我们有128兆字节的RAM。
* 链接器将再次检查此项,以确保所有内容都可以匹配。
*/
MEMORY
{
ram (wxa!ri) : ORIGIN = 0x80000000, LENGTH = 128M
}
/*
* https://sourceware.org/binutils/docs/ld/SECTIONS.html
* SECTIONS命令告诉链接器如何将输入部分映射到输出
* 以及如何将输出部分放置在内存中。
* SECTIONS命令的格式为:
* SECTIONS
* {
* sections-command
* sections-command
* ......
* }
*
* 每个sections命令可以是以下命令之一:
* (1) ENTRY 命令
* (2) a symbol assignment
* (3) an output section 描述
* (4) an overlay 描述
* 我们这里只演示 (2) & (3).
*
* 我们使用PROVIDE命令来定义符号常量。
* https://sourceware.org/binutils/docs/ld/PROVIDE.html
* PROVIDE关键字可用于定义符号常量。
* 语法为 PROVIDE(symbol = expression).
* 例如: "_text_start", "_text_end" ... 将在 mem.S 中使用.
* 请注意句点“.”告诉链接器将符号(例如 _text_start)
* 设置为当前位置(“.” = 当前内存位置)。
* 当我们添加内容时,当前内存位置会改变。
*/
SECTIONS
{
/*
* 我们将在.text输出部分中布局所有文本部分,
* 从.text开始。括号前的星号(“*”)
* 表示与所有输入对象文件的.text section 匹配。
*/
.text : {
PROVIDE(_text_start = .); /*给当前位置起一个符号别名*/
*(.text .text.*) /* 引用input section中的所有.text 和 .text.* */
PROVIDE(_text_end = .);
} >ram
.rodata : {
PROVIDE(_rodata_start = .);
*(.rodata .rodata.*)
PROVIDE(_rodata_end = .);
} >ram
.data : {
/*
*.=ALIGN(4096)告诉链接器将当前内存位置与4096字节对齐。
* 这将插入填充字节,直到当前位置与4096字节边界对齐。
* 这是因为我们的分页系统的分辨率是4096字节。
*/
. = ALIGN(4096);
PROVIDE(_data_start = .);
/*
* sdata和data本质上是一样的。我们不需要区分sdata和data。
*/
*(.sdata .sdata.*)
*(.data .data.*)
PROVIDE(_data_end = .);
} >ram
.bss :{
/*
* https://sourceware.org/binutils/docs/ld/Input-Section-Common.html
* 在大多数情况下,输入文件中的COMMON符号将放置在输出文件的“bss”部分中。
*/
PROVIDE(_bss_start = .);
*(.sbss .sbss.*)
*(.bss .bss.*)
*(COMMON)
PROVIDE(_bss_end = .);
} >ram
/* 获取ram的起始地址 */
PROVIDE(_memory_start = ORIGIN(ram));
/* 获取ram的结束地址 */
PROVIDE(_memory_end = ORIGIN(ram) + LENGTH(ram));
/* 获取 heap 的起始地址 */
PROVIDE(_heap_start = _bss_end);
/* 获取 heap 的结束地址 */
PROVIDE(_heap_size = _memory_end - _heap_start);
}
实现Page级别的内存分配和释放
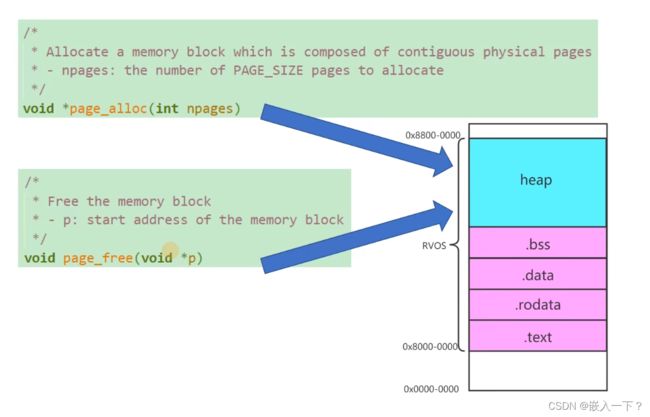
需求分析:基于 Page 实现动态内存分配
- 申请内存接口 page_alloc
- 释放内存接口 page_free
- 一个 page 为 4k
数据结构设计
- 链表方式
- 数组方式
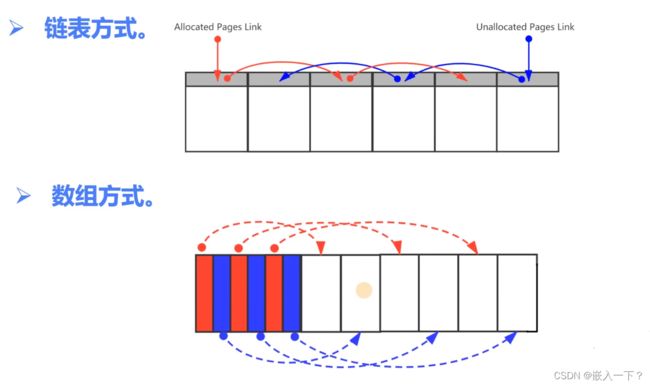
以下只展示数组实现
数组方式实现
- 堆内存分配,管理区和存储区。
- 预留 8 * PAGE_SIZE 的管理部分大小。
- 按照 page 的大小进行对齐

Page 描述符数据结构设计
- 是否被分配。
- 是否是被分配区域的最后一块内存。

Page 分配和释放接口设计
void *page_alloc(int npages)
- 先通过 描述符指针1 找到未被分配的块
- 再通过 描述符指针2 观察是否符合指定大小
- 符合则分配,不符合则继续往下寻找。

void page_free(void *p)
- 通过分配内存与起始地址的偏移量之差
- 算出中间隔了几个 page
- 再通过相隔的 page的个数
- 加上描述符起始地址, 来找到对应的 Page 描述符地址
- 释放 Page 描述符 对于这块地址的分配
- 然后查 page 描述符 是否是 分配的整体 的最后的一块
- 不是的话继续往后释放

内存管理与保护
-
物理内存保护(Physical Memory Protection,PMP)
- 允许M模式指定U模式可以访问的内存地址。
- 支持 R/W/X,以及 Lock。

-
虚拟内存(Virtual Memory)
- 需要支持 Supervisor Level
- 用于实现高级的操作系统特性(Unix/Linux)
- 多种映射方式 Sv32/Sv39/Sv48

上下文切换和协作式多任务
多任务与上下文
任务的概念(tesk)
任务是一条执行流,用于执行代码逻辑。
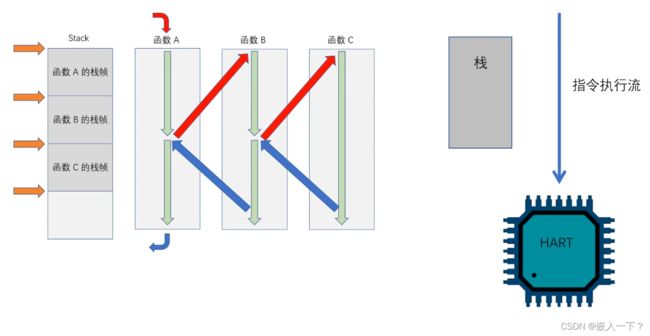
多任务的概念(Multitask)
多任务是多条执行流,可以是多核多任务,也可以是单核多任务。
多核多任务就是,不同的核执行不同的执行流;
单核多任务就是,一个核轮流执行不同的执行流。


任务上下文的概念(Context)
实现多任务切换,轮流执行。
在任务切换前,备份当前任务状态(如把寄存器内容保存起来),并恢复下一个任务之前的状态。

协作式多任务的设计与实现
协作式多任务和抢占式多任务
- 协作式多任务(Cooperative Multitasking):协作式环境下,下一个任务被调度的前提是当前任务主动放弃处理器。
- 抢占式多任务(Preemptive Multitasking):抢占式环境下,操作系统完全决定任务调度方案,操作系统可以剥夺当前任务对处理器的使用,将处理器提供给其他任务。
协作式多任务和设计思路
ra存储运行的位置,通过改变mscratch寄存器存储指向任务上下文的地址,变换不同任务执行。
假如先是TASK A执行,执行一条指令,就会把一条指令放到Context A中的ra,直到运行到call switch_to,保存下一条指令的地址,并调用switch_to函数,然后save previous context(保存上一个上下文),然后switch context(转换环境,找到其他任务),此时CPU中的mscratch改变,然后通过mscratch指针restore next context(还原下一个上下文),假如下一个是TASK B,则会根据TASK B上下文上的ra,跳转到TASK B上该指令处,然后继续运行。

协作式多任务的关键实现
进来先交换 t6和 mscratch,观察mscratch之前是否有值,若是没有,则之前没有调度过,则不保存上下文(因为没有上文),直接获取下文的状态,然后调度跳转到下文。

主体代码
entry.S
# 保存所有 General-Purpose(GP) 寄存器到上下文中
# struct context *base = &ctx_task;
# base->ra = ra;
# ......
.macro reg_save base
sw ra, 0(\base)
sw sp, 4(\base)
sw gp, 8(\base)
sw tp, 12(\base)
sw t0, 16(\base)
sw t1, 20(\base)
sw t2, 24(\base)
sw s0, 28(\base)
sw s1, 32(\base)
sw a0, 36(\base)
sw a1, 40(\base)
sw a2, 44(\base)
sw a3, 48(\base)
sw a4, 52(\base)
sw a5, 56(\base)
sw a6, 60(\base)
sw a7, 64(\base)
sw s2, 68(\base)
sw s3, 72(\base)
sw s4, 76(\base)
sw s5, 80(\base)
sw s6, 84(\base)
sw s7, 88(\base)
sw s8, 92(\base)
sw s9, 96(\base)
sw s10, 100(\base)
sw s11, 104(\base)
sw t3, 108(\base)
sw t4, 112(\base)
sw t5, 116(\base)
# 这里没有将 t6 保存,因为这里的 宏变量base的值,是来自外面的t6
.endm
# 恢复所有 General-Purpose(GP) 寄存器到上下文中
# struct context *base = &ctx_task;
# ra = base->ra;
# ......
.macro reg_restore base
lw ra, 0(\base)
lw sp, 4(\base)
lw gp, 8(\base)
lw tp, 12(\base)
lw t0, 16(\base)
lw t1, 20(\base)
lw t2, 24(\base)
lw s0, 28(\base)
lw s1, 32(\base)
lw a0, 36(\base)
lw a1, 40(\base)
lw a2, 44(\base)
lw a3, 48(\base)
lw a4, 52(\base)
lw a5, 56(\base)
lw a6, 60(\base)
lw a7, 64(\base)
lw s2, 68(\base)
lw s3, 72(\base)
lw s4, 76(\base)
lw s5, 80(\base)
lw s6, 84(\base)
lw s7, 88(\base)
lw s8, 92(\base)
lw s9, 96(\base)
lw s10, 100(\base)
lw s11, 104(\base)
lw t3, 108(\base)
lw t4, 112(\base)
lw t5, 116(\base)
lw t6, 120(\base)
.endm
#有关 save/restore 的一些注意事项:
# -我们使用 mscratch 保存指向上一任务上下文的指针。
# 我们使用 t6 作为 reg_save/reg_store 的 “base”,
# 因为它是最底层的寄存器(x31),在加载过程中不会被覆盖。
.text
# void switch_to(struct context *next);
# a0 : 指向下一任务上下文的指针
.global switch_to
.align 4
switch_to:
csrrw t6, mscratch, t6 # 交换 t6 和 mscratch
beqz t6, 1f # 上一个任务可能为空,也就是说现在是第一次调用该函数
reg_save t6 # 保存上一个任务的上下文
# 保存我们交换到的实际t6寄存器
# mscratch
mv t5, t6 # t5指向当前任务的上下文
csrr t6, mscratch # 读取t6的值,给到mscratch
sw t6, 120(t5) # 以t5为base保存t6
1:
# 切换mscratch以指向下一个任务的上下文
csrw mscratch, a0
# 还原所有GP寄存器
# 使用t6指向新任务的上下文
mv t6, a0
reg_restore t6
# 进行实际的上下文切换。
ret
.end
sched.c
#include "os.h"
// 定义来自 entry.S
extern void switch_to(struct context *next);
#define MAX_TASKS 10
#define STACK_SIZE 1024
uint8_t task_stack[MAX_TASKS][STACK_SIZE];
struct context ctx_tasks[MAX_TASKS];
/*
* _top 用于存储有多少个任务
* _current 用于指向当前任务的上下文
*/
static int _top = 0;
static int _current = -1;
static void w_mscratch(reg_t x)
{
asm volatile
(
// 把 x0 的内容写入 mscratch 寄存器中
"csrw mscratch, %0"
:
: "r"(x)
);
}
void sched_init()
{
w_mscratch(0);
}
// 一种简单循环FIFO调度程序的实现
void schedule()
{
if(_top <= 0)
{
panic("Num of task should be greater than zero!");
return;
}
// 获取下一个该调度的任务
_current = (_current + 1) % _top;
struct context *next = &(ctx_tasks[_current]);
switch_to(next);
}
/*
* DESCRIPTION
* 新建一个任务
* - start_routin: 任务回调函数
* RETURN VALUE
* 0: success
* -1: if error occured
*/
int task_create(void (*start_routin)(void))
{
// 判断添加的任务数量是否超过限制的数量
if(_top < MAX_TASKS)
{
ctx_tasks[_top].sp = (reg_t)&task_stack[_top][STACK_SIZE - 1];
ctx_tasks[_top].ra = (reg_t)start_routin;
_top++;
return 0;
}
else
{
return -1;
}
}
/*
* DESCRIPTION
* task_yield()
* 使当前任务放开CPU,并运行新任务。
*/
void task_yield()
{
schedule();
}
/*
* a very rough implementaion, just to consume the cpu
* 软件的阻塞延时,只是为了卡住cpu
*/
void task_delay(volatile int count)
{
count *= 100000;
while (count--);
}
使用方法
// 通过 start_routin 创建新任务
// 传入的参数是一个 void(*)(void) 类型的函数
void user_task1(void);
task_create(user_task1);
// 通过 task_yield 放开当前任务,并切换任务到下一个任务去。
task_yield();
Trap 和 Exception
控制流(Control Flow)和 Trap
-
控制流(Control Flow)
- branch,jump
-
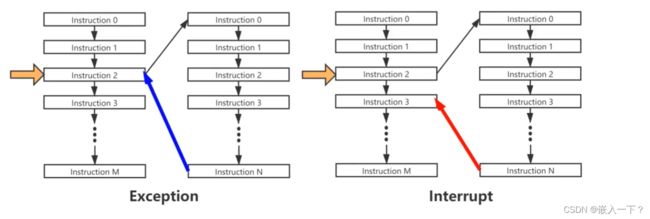
异常控制流(Exceptional Control Flow,简称 ECP)
- exception
- interrupt
-
RISC-V把 ECP 统称为 Trap
RISC-V Trap 处理中涉及的寄存器
| 寄存器 | 用途说明 |
|---|---|
| mtvec(Machine Trap-Vector Base-Address) | 它保存发生异常时处理器需要跳转到的地址。 |
| mepc(Machine Exception Program Counter) | 当 trap 发生时,hart 会将发生 trap 所对应的指令的地址值(pc)保存在 mepc 中。 |
| mcause(Machine Cause) | 当 trap 发生时,hart会设置该寄存器通知我们 trap 发生的原因。 |
| mtval(Machine Trap Value) | 它保存了 exception 发生时的附加信息:譬如访问地址出错时的地址信息、或者执行非法指令时的指令本身,对于其他异常,他的值为0。 |
| mstatus(Machine Status) | 用于跟踪和控制 hart 的当前操作状态(特别地,包括关闭和打开全局中断)。 |
| mscratch(Machine Scratch) | Machine 模式下专用寄存器,我们可以自己定义其用法,譬如用该寄存器保存当前在 hart 上运行的 task 的上下文(contrxt)的地址。 |
| mie(Machine Interrupt Enable) | 用于进一步控制(打开和关闭)software interrupt / timer interrupt / external interrupt |
| mip(Machine Interrupt Pending) | 他列出目前已发生等待处理的中断。 |
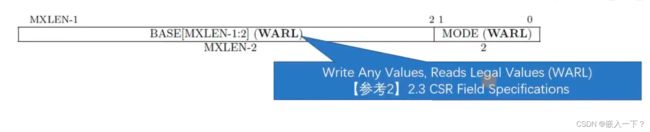
mtvec(Machine Trap-Vector Base-Address)
-
BASE:trep 入口函数的基地址,必须保证四字节对齐。
-
MODE:进一步用于控制入口函数的地址配置方式:
-
Direct:所有的 exception 和 interrupt 发生后 PC 都跳转到 BASE 指定的地址处。
-
在该模式下,中断或异常会跳转到 base 指向的函数,在函数中通过走分支的方式知道是哪种中断或异常。

-
-
Vectored:exception 处理方式同 Direct;但 interrupt 的入口地址以数组的方式排列。
-
在该模式下,base中为数组首地址,数组里面是不同的函数地址,然后通过不同的中断或异常对数组的偏移地址,执行不同的中断或异常函数。


-
-
mepc(Machine Exception Program Counter)

- 当 trap 发生时,pc会被替代为 mtvec 设定的地址,同时 hart 会设置 mepc 为当前指令或者下一条指令的地址,当我们需要退出trap时可以调用特殊的 mret 指令,该指令会将 mepc 中的值恢复到pc中(实现返回的效果)。
- 在处理 trap 的程序中我们可以修改 mepc 的值达到改变 mret 返回地址的目的。
mcause(Machine Cause)


-
当 trap 发生时,hart 会设置该寄存器通知我们 trap 发生的原因。
-
最高位 Interrupt 为1标识当前为 interrupt,否则是 exceotion。
-
剩余的 Exception Code 用于标识具体的 interrupt 或者 exception 的种类。

mstatus(Machine Status)


-
xIE(x=M/S/U):分别用于打开(1)或者关闭(0)M/S/U 模式下的全局中断。当 trap 发生时,hart 会自动将 xIE 设置为 0(防止在 tarp 发生的期间仍然发生 tarp)。
-
xPIE(x=M/S/U):当 trap 发生时用于保存 trap 发生之前的 xIE 值。
-
xPP(x=M/S):当 trap 发生时用于保存 trap 发生之前的权限级别值。注意没有UPP。
由于权限级别只能从低到高,S之前的只有S/U两种可能,所以SPP只占1bit;而MPP,之前M/S/U三种可能,所以占2bit。

-
其他标志位涉及内存访问权限、虚拟内存控制等,暂不考虑。
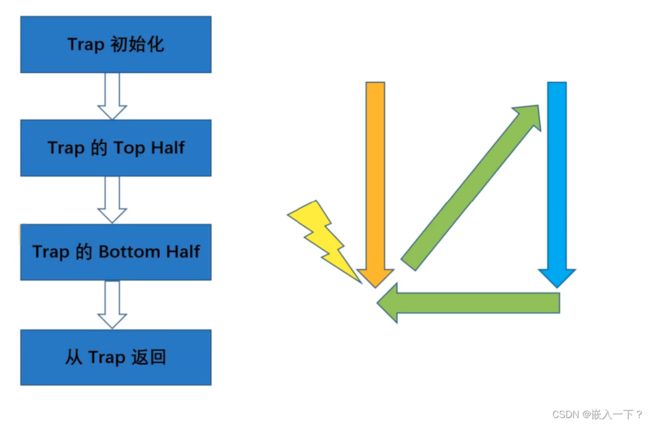
RISC-V Trap 处理流程
Trap 初始化
给 mtves 中断或异常 base 地址。

Trap 的 Top Half
Trap发生时,Hart 自动执行如下状态转换:
-
把 mstatus 的 MIE 值复制到 MPIE 中,清除 mstatus中的 MIE 标志位,效果是中断被禁止。
-
设置 mepc,同时PC被设置为 mtvec。(需要注意的是,对于exception,mepc 指向导致异常的指令;对于 interrupt,它指向被中断的指令的下一条指令的位置。)
-
根据 trap 的种类设置 mcause,并根据需要为 mtval 设置附加信息。
-
将 trap 发生之前的权限模式保存在 mstatus 的 MPP 域中,再把 hart 权限模式更改为 M(也就是说无论在任何 Level 下触发 trap,hart 首先切换到 Machine 模式)。
Trap 的 Bottom Half
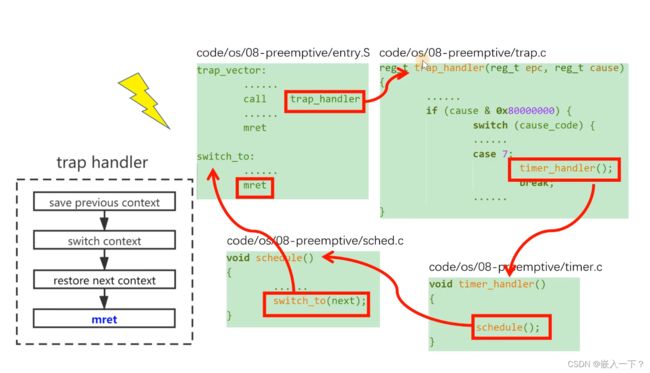
trap handler:软件需要做的事情
- 保存(save)当前控制流的上下文信息(利用 mscratch)。
- 调用 C语言的 trap handler 。
- 从 trap handler 函数返回,mepc 的值有可能需要调整。
- 恢复(restore)上下文的信息。
- 执行 MRET 指令返回到 trap 之前的状态。
trap_vector:
# 保存上下文(寄存器)。
csrrw t6, mscratch, t6 # 交换 t6 and mscratch
reg_save t6
# 保存实际的t6寄存器,我们将其交换到mscratch中
mv t5, t6 # t5指向当前任务的上下文
csrr t6, mscratch # 从mscratch读取t6
sw t6, 120(t5) # 以t5为基础保存t6
# 将上下文指针还原为mscratch
csrw mscratch, t5
# 调用 trap.c 中的 C语言的 trap handler
csrr a0, mepc # 把trap发生的地址给 trap_handler函数第1个参数
csrr a1, mcause # 把trap的种类给 trap_handler函数第2个参数
call trap_handler # 调用处理函数
# trap_handler 将通过a0返回返回地址。
csrw mepc, a0
# 恢复上下文(registers).
csrr t6, mscratch
reg_restore t6
# 回到 trap 前我们所做的一切。
mret
从 Trap 返回
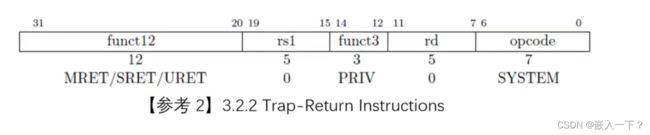
- 针对不同权限级别下如何退出 trap 有各自的返回指令 xRET(x = M/S/U)。
- 以在 M 模式下执行 mret 指令为例,会执行如下操作:
- 当前 Hart 的权限级别 = mstatus.MPP; mstatus.MPP = U(如果 hart 不支持 U 则为 M)(这里是恢复权限级别)。
- mstatus.MIE = mstatus.MPIE; mstatus.MPIE = 1(这里是重新打开中断开关,在之前中断处于打开状态下)。
- pc = mepc(这里是回到进入 Trap 之前的地方)。
外部中断设备

RISC-V 中断(Interrupt)的分类
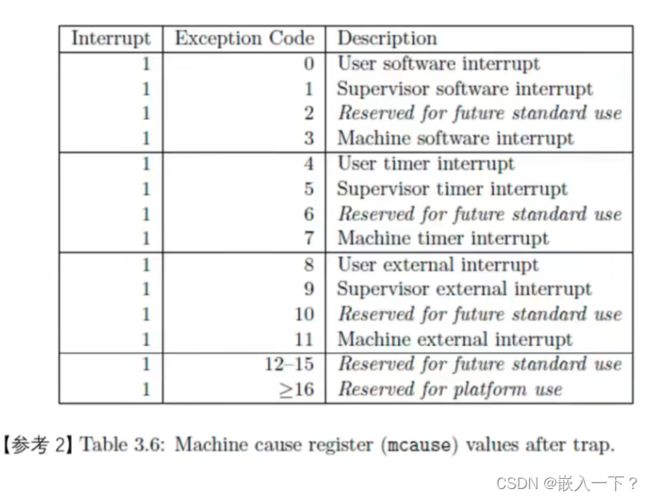
-
本地(Local)中断
- software interrupt
- timer interrupt
-
全局(Global)中断
- externel interrupt

RISC-V 中断编程中涉及的寄存器
| 寄存器 | 用途说明 |
|---|---|
| mtvec(Machine Trap-Vector Base-Address) | 它保存发生异常时处理器需要跳转到的地址。 |
| mepc(Machine Exception Program Counter) | 当 trap 发生时,hart 会将发生 trap 所对应的指令的地址值(pc)保存在 mepc 中。 |
| mcause(Machine Cause) | 当 trap 发生时,hart会设置该寄存器通知我们 trap 发生的原因。 |
| mtval(Machine Trap Value) | 它保存了 exception 发生时的附加信息:譬如访问地址出错时的地址信息、或者执行非法指令时的指令本身,对于其他异常,他的值为0。 |
| mstatus(Machine Status) | 用于跟踪和控制 hart 的当前操作状态(特别地,包括关闭和打开全局中断)。 |
| mscratch(Machine Scratch) | Machine 模式下专用寄存器,我们可以自己定义其用法,譬如用该寄存器保存当前在 hart 上运行的 task 的上下文(contrxt)的地址。 |
| mie(Machine Interrupt Enable) | 用于进一步控制(打开和关闭)software interrupt / timer interrupt / external interrupt |
| mip(Machine Interrupt Pending) | 他列出目前已发生等待处理的中断。 |
寄存器 mie、mip
-
mie(Machine Interrupt Enable):打开(1)或者关闭(0)M/S/U 模式下对应的 External/Timer/Software 中断

-
mip(Machine Interrupt Pending):获取当前 M/S/U 模式下对应的 External/Timer/Software 中断是否发生。

RISC-V 中断处理流程
中断发生时 Hart 自动执行如下状态切换
- 把 mstatus 寄存器的值复制到 MPIE 中,清除 mstatus 中的 MIE 标志位,效果是中断被禁止。
- 当前的 PC 的下一条指令地址被复制到 mepc 中,同时 PC 被设置为 mtvec 。注意如果我们设置
mtvec.MODE = vetcored,PC = mtvec.BASE + 4 * exception-code。 - 根据 interrupt 的种类设置 mcause,并根据需要为 mtval 设置附加信息。
- 将 trap 发生之前的权限保存在 mstatus 的 MPP 域中,再把 hart 权限模式更改为 M。

退出中断:编程调用 MRET 指令
- 以在 M 模式下执行 mret 指令为例,会执行如下操作:
- 当前 Hart 的权限级别 = mstatus.MPP; mstatus.MPP = U(如果 hart 不支持 U 则为 M)(这里是恢复权限级别)。
- mstatus.MIE = mstatus.MPIE; mstatus.MPIE = 1(这里是恢复中断开关到之前的状态)。
- pc = mepc(这里是回到进入 中断 之前的地方)。
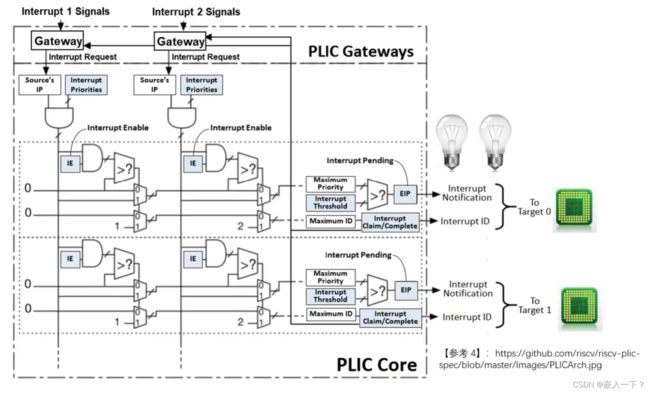
PLIC 介绍
因为外部中断只有一根输入线,所以引入了 PLIC(Platform-Level Interrupt Controller)平台中断控制器。

Platform-Level Interrupt Controller
从左边进来很多外设中断线(中断源),对于外设产生的中断,汇集到 PLIC 再进行对右边 cpu核 中断访问。
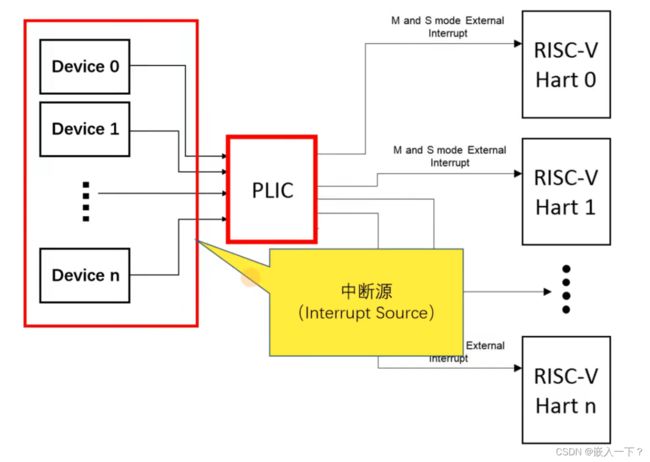
PLIC Interrupt Source
- Interrupt Souce ID 范围:1~53(0x35)
- 0预留不用
PLIC 编程接口 - 寄存器
-
RISC-V 规范规定,PLIC 的寄存器编址采用内存映射(memory map)方式。每个寄存器的宽度为 32-bit。
-
具体寄存器编址采用 base + offsset 的格式,且 base 由各个特定 platform 自己定义。针对 QEMU-virt,其 PLIC 的设计参考了 FU540-C000,base 为 0x0c000000。
#define PLIC_BASE 0x0c000000L // PLIC 基地址
Priority
| 可编程寄存器 | 功能描述 | 内存映射地址 |
|---|---|---|
| Priority | 设置某一路中断源的优先级。 | BASE + (interrupt-id)*4 |
- 每个 PLIC 中断源对应一个寄存器,用于配置该中断源的优先级。
- QEMU-virt 支持 7 个优先级。0 表示对该中断禁用中断。其余优先级,1最低,7最高。
- 如果两个中断源优先级相同,则根据中断源的 ID 值进一步区分优先级,ID 值越小的优先级越高。
#define PLIC_PRIORITY(id) (PLIC_BASE + (id)*4)
// 设置该中断打开
*(uint32_t *)PLIC_PRIORITY(UART0_IRQ) = 1;
Pending
| 可编程寄存器 | 功能描述 | 内存映射地址 |
|---|---|---|
| Pending | 用于指示某一路中断源是否发生。 | BASE + 0x1000 + ((interrupt-id)/32) |
- 每个 PLIC 包含2个32位的 Panding 寄存器,每一个bit对应一个中断源,如果为1表示该中断源上发生了中断(进入 Pending 状态),有待hart处理,否则表示该中断源上当前无中断发生。
- Pending 寄存器中断的 Pending 状态可以通过 claim方式清除。
- 第一个 Pending 寄存器的第 0 位对应不存在的 0 号中断源,其值永远为0。
Enable
| 可编程寄存器 | 功能描述 | 内存映射地址 |
|---|---|---|
| Enable | 针对某个 hart 开启或关闭某一路中断源。 | BASE + 0x2000 + (hart)*0x80 |
- 每个 Hart 有2个 Enable 寄存器(Enable1 和 Enable2)用于针对该Hart 启动或关闭某路寄存器
- 每个中断源对应 Enable 寄存器的一个 bit,其中 Enable1 负责1~31号中断源;Enable2 负责控制32~53号中断源。将对应的 bit 设置为1 表示使能该中断源,否则表示关闭该中断源。
#define PLIC_MENABLE(hart) (PLIC_BASE + 0x2000 + (hart)*0x80)
// 开启串口0中断
*(uint32_t *)PLIC_MENABLE(hart) = (1<<UART0_IRQ);
Threshold
| 可编程寄存器 | 功能描述 | 内存映射地址 |
|---|---|---|
| Threshold | 针对某个 hart 设置中断源优先级阈值 | BASE + 0x200000 + (hart)*0x1000 |
- 每个 Hart 有一个 Threshold 寄存器用于设置中断优先级的阈值。
- 所有小于或者等于(<=)该阈值的中断源即使发生了也会被 PLIC 丢弃。特别地,当阈值为 0 时允许所有中断源上发生的中断;但阈值为 7 时丢弃所有中断源上发生的中断。
#define PLIC_MTHRESHOLD(hart) (PLIC_BASE + 0x200000 + (hart)*0x1000)
// 允许所有中断源上发生的中断
*(uint32_t *)PLIC_MTHRESHOLD(hart) = 0;
Claim/Complete
| 可编程寄存器 | 功能描述 | 内存映射地址 |
|---|---|---|
| Claim/Complete | 详见下描述 | BASE + 0x200004 + (hart)*0x1000 |
- Claim 和 Complete 是同一个寄存器,每个 Hart 一个。
- 对该寄存器执行读操作称之为 Claim,即获取当前发生的最高优先级的中断源 ID。Claim 成功后会清除对应的 Pending 位。
- 对该寄存器执行写操作称之为 Complete。所谓 Complete 指的时通知 PLIC 对该路中断处理已经结束。
#define PLIC_MCLAIM (PLIC_BASE + 0x200004 + (hart)*0x1000)
#define PLIC_MCOMPLETE (PLIC_BASE + 0x200004 + (hart)*0x1000)
int plic_claim(void)
{
int hart = r_tp();
int irq = *(uint32_t *)PLIC_MCLAIM(hart);
return irq;
}
void pilc_complete(int irq)
{
int hart = r_tp();
*(uint32_t *)PLIC_MCOMPLETE(hart) = irq;
}
PLIC 编程接口 - 操作流程图
采用中断方式从 UART 实现输入
// 串口设备实现中断
/*
* enable receive interrupts.
*/
uint8_t ier = uart_read_reg(IER);
uart_write_reg(IER, ier | (1 << 0));
// 外部中断设备开启
void plic_init(void)
{
int hart = r_tp();
/*
* Set priority for UART0.
*/
*(uint32_t*)PLIC_PRIORITY(UART0_IRQ) = 1;
/*
* Enable UART0
*/
*(uint32_t*)PLIC_MENABLE(hart)= (1 << UART0_IRQ);
/*
* Set priority threshold for UART0.
*/
*(uint32_t*)PLIC_MTHRESHOLD(hart) = 0;
/* enable machine-mode external interrupts. */
w_mie(r_mie() | MIE_MEIE);
/* enable machine-mode global interrupts. */
w_mstatus(r_mstatus() | MSTATUS_MIE);
}
硬件定时器

RISC-V 定时器中断
- 本地(Local)中断
- software interrupt
- timer interrupt
- 全局(Global)中断
- external interrupt
RISC-V CLINT 介绍
Core Local INTerrupt
该设备可以产生两类中断,一类是软件中断,一类是定时器中断。

CLINT 编程接口 - 寄存器(Timer部分)
- RISC-V 规范规定,CLINT 的寄存器编址采用内存映射(memory map)方式。
- 具体寄存器编址采用 base + offsset 的格式,且 base 由各个特定 platform 自己定义。针对 QEMU-virt,其 CLINT 的设计参考了 SFIVE,base 为 0x20000000。
#define CLINT_BASE 0x20000000

mtime
| 可编程寄存器 | 功能描述 | 内存映射地址 |
|---|---|---|
| mtime | real-time 计数器(counter) | BASE + 0xbff8 |
- 系统全局唯一,在 RV32 和 RV64 上都是64-bit。系统必须保证该计数器的值始终按照1个固定的频率递增。
- 上电复位时,硬件负责将 mtime 的值恢复为 0。
#define CLINT_MTIME (CLINT_BASE + 0xbff8)
mtimecmp
| 可编程寄存器 | 功能描述 | 内存映射地址 |
|---|---|---|
| mtimecmp | timer compare register | BASE + 0x4000 + (hart)*8 |
- 每一个 hart 一个 mtimecmp 寄存器,64-bit。
- 上电复位时,系统不负责设置 mtimecmp 的初值。
#define CLINT_MTIMECMP(hardid) (CLINT_BASE + 0x4000 + 8*(hartid))
// 定时器重装载函数
void timer_load(int interval)
{
// 获取 id 值
int id = r_mhartid();
// 重装载
*(uint64_t *)CLINT_MTIMECMP(id) =
*(uint64_t *)CLINT_MTIME + interval;
}
void timer_init()
{
timer_load(TIMER_INTERVAL);
......
}
void start_kernel(void)
{
......
timer_init();
......
while(1){};
}
CLINT 寄存器使用
- 当 mtime >= mtimecmp 时,CLINT 会产生一个 timer 中断。如果要使能该中断。需要保证全局中断打开并且 mie.MTIE 标志位置 1。
- 当 timer 中断发生时,hart 会设置 mip.MTIP,程序可以在 mtimecmp 中写入新的值清除 mip.MTIP。
void timer_handler()
{
......
timer_load(TIMER_INTERVAL);
}
void timer_init()
{
timer_load(TIMER_INTERVAL);
// 使能定时器中断
w_mie(r_mie() | MIE_MTIE);
// 使能全局中断
w_mstatus(r_mstatus() | MSTATUS_MIE);
}
reg_t trap_handler(reg_t epc, reg_t cause)
{
......
if(cause & 0x80000000)
{
switch(cause_code)
{
......
case 7:
// 跳转到定时器回调函数
timer_handler();
break;
......
}
}
......
}
CLINT 总体框架使用
- 初始化:清零mtime,对 mtimecmp 加等于上 INTERVAL,使能中断。
- 等待中断:mtime 会不断自增,当 mtime 计数值 >= mtimecmp 时,中断发生。
- 处理中断:执行中断任务,然后重装载 mtimecmp 寄存器,等待下一次中断。
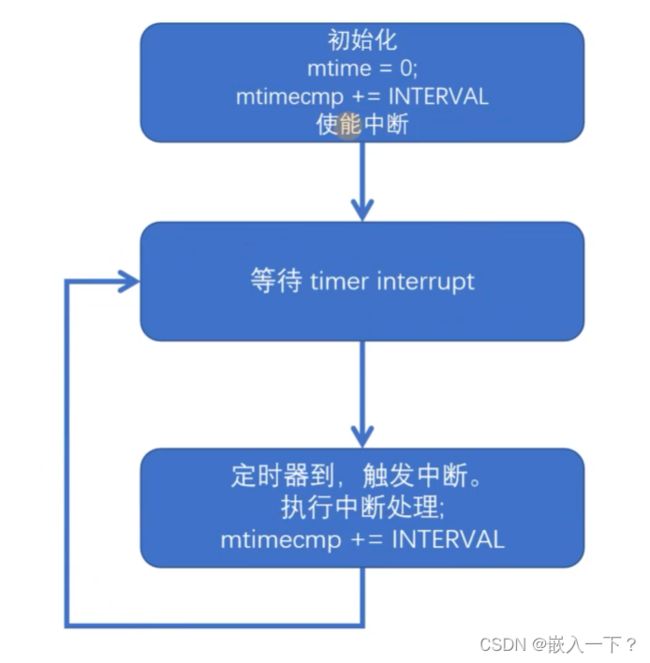
硬件定时器的应用
时间管理
生活中的时间管理,操作系统的时间管理。
时钟节拍(Tick)
- 操作系统中最小的时间单位。
- Tick 的单位(周期)由硬件定时器的周期决定(通常为 1 ~ 100ms)。
- Tick 周期越小,系统精度越高,但开销越大。
系统时钟
- 操作系统维护的一个整数计数值,记录着系统启动直到当前发生的 Tick 总数。
- 可用于维护系统的墙上时间,所以也称为系统时钟。
#define TIMER_INTERVAL CLINT_TIMERVAL_FREQ
static uint32_t _tick = 0;
void timer_init()
{
timer_load(TIMER_INTERVAL);
......
}
void timer_handler()
{
_tick++;
printf("tick: %d\n", _tick);
timer_load(TIMER_INTERVAL);
}
抢占式多任务
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZMkgadcZ-1683506485129)(C:\Users\yxy\AppData\Roaming\Typora\typora-user-images\image-20221207172135022.png)]
多任务系统的分类
- 协作式多任务(Cooperative Multitasking):协作式环境下,下一个任务被调度的前提是当前任务主动放弃处理器。
- 抢占式多任务(Preemptive Multitasking):抢占式环境下,操作系统完全决定任务调度方案,操作系统可以剥夺当前任务对处理器的使用,将处理器提供给其他任务。
抢占式多任务的设计
利用中断调用上下文切换。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2LRfGhTM-1683506485130)(C:\Users\yxy\AppData\Roaming\Typora\typora-user-images\image-20221207175122250.png)]
定时器中断发生调用定时器回调函数,然后调用上下文切换函数,然后跳转到后面的任务。
兼容协作式多任务
兼容 task_yield()
除了任务时间片结束主动切换任务,还有就是主动放弃cpu,需要用到软件中断(利用CLINT)。
CLINT 编程接口 - 寄存器(software interrupt 部分)
| 可编程寄存器 | 功能描述 | 内存地址映射 |
|---|---|---|
| MSIP | 最低位和 CSR mip.MSIP 对应 | BASE + 4 * (hart) |
- 每个 Hart 拥有一个 MSIP 寄存器。
- RISCV 规范规定,Machine 模式下的 mip.MSIP 对应到一个memory - mapped 的 控制寄存器。为此 QEMU-virt 提供MSIP,该 MSIP 寄存器为 32-bit,高 31 位不可用,最低位映射到 mip.MSIP。
- 具体寄存器编址采用 base + offset 的格式,且 base 由各个特定的 platform 自己定义。针对 QEMU-virt,其 CLINT 的设计参考了 SFIVE,base 为 0x20000000。
#define CLINT_MSIP(hartid) (CLINT_BASE + 4 * (hartid))
- 对 MSIP 写入 1 时触发 software interrupt,写入 0 表示对该中断进行应答。
void task_yield()
{
int id = r_mhartid();
*(uint32_t *)CLINT_MSIP(id) = 1;
}
任务同步和锁
并发(Concurrency)和同步
- 并发指多哥控制流同时进行
- 多处理器多任务(每个处理器一个任务)
- 单处理器多任务(一个处理器多个任务)
- 单处理器任务+中断(一个处理器执行任务,配合中断实现多个任务的处理)
- 同步是为了保证在并发执行的环境中各个控制流可以有效执行而采用的一种编程技术。
临界区、锁、死锁
临界区(Critical Section)
- 临界区:在并发的程序执行环境中,所谓临界区(Critical Section)指的是一个会访问共享资源(例如:一个共享设备或者一块共享存储内存)的指令片段,而且当这样的多个指令片段同时访问访问某个共享资源时可能会引发问题。
- 简单的说,就是几段程序需要访问一样的数据,来进行一个整体的判断,但是由于读取时间上的差异会导致数据的变化,这是需要维护在这段时间内的数据不会改变,所以需要临界区。
实现同步技术 - 锁
- 在并发环境下为了有效控制临界区的执行(同步),我们要做的是当有一个控制流进入临界区时,其他相关控制流必须等待。
- 锁是一种最常见的用来实现同步的技术。
- 不可睡眠的锁
- 可睡眠的锁
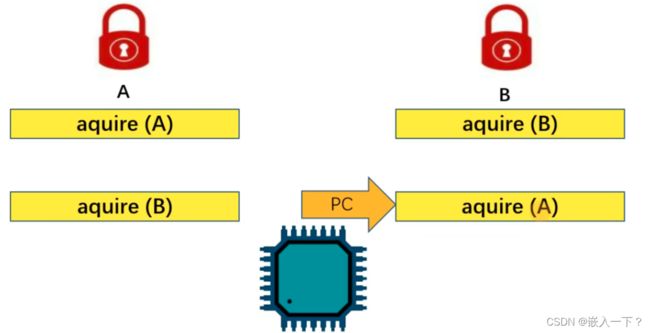
死锁(Deadlock)问题
-
什么是死锁以及死锁为何发生:
- 当控制流执行路径中会涉及多个锁,并且这些控制流执行路径获取(aquire)锁的顺序不同时就可能会发生死锁问题。
- 任务1锁住A,任务2锁住B,然后任务1需要锁住B,但是任务2已经锁住了B,于是等待解锁,此时任务2又想锁住任务A,但是任务1已经锁住了A,此时等待卡死。
-
如何解决死锁:
- 调整获取(aquire)锁的顺序,譬如保持一致。
- 尽可能防止任务在持有一把锁的同时申请其他的锁。
- 尽可能少用锁,尽可能减少并发。
自旋锁的实现
不可睡眠的锁,自旋锁(Spin Lock)
读取锁状态和上锁必须是原子性的。防止还没锁完时就换了一个线程,然后在另外一个线程上锁,回到原来的线程,之前获取的信息上还是没上锁,然后又锁一次,两个任务同时执行,出现问题。
需要原子性操作
void spin_lock(struct spinlock *lk)
{
while(__sync_lock_test_and_set(&lk->locked, 1) != 0);
}
loop:
lw a4, -20(s0)
li a5, 1
amoswap.w.aq a5, a5, (a4)
mv a3, a5
bnez a3, loop
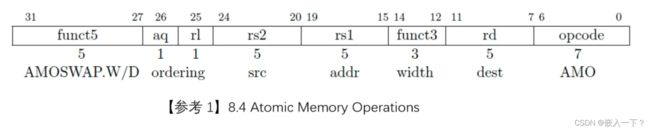
这里的自旋锁时关中断实现的,十分粗暴,所以会有以下
- 自旋锁的使用
- 自旋锁可以防止多个任务同时进入临界区(Critical Section)
- 在自旋锁保护的临界区中不能执行长时间的操作
- 在自旋锁保护的临界区中不能主动放弃CPU
其他同步技术
| 同步技术 | 描述 |
|---|---|
| 自旋锁(Spin Lock) | 如果一个任务试图获取一个已经被持有的自旋锁,这个任务就会进入忙循环(busy loops,即自旋)并等待,直到该所可用,否则该任务就可以立刻获得这个锁并继续执行。自旋锁可以防止多个任务同时进入临界区(Critical Section)。 |
| 信号量(Semaphore) | 信号量是一种睡眠锁,当任务请求的信号量无法获取时,就会让人物进入等待队列并且让任务睡眠。当信号量可以获取时,等待队列中的一个任务就会被唤醒捕获的信号量。 |
| 互斥锁(Mutex) | 互斥锁可以看作是对互斥信号量(count为1)的改进,是一种特殊的信号量处理机制。 |
| 完成变量(Completion Variable) | 一个任务执行某些工作时,另一个任务就在完全变量上等待,当前者完成工作,就会利用完全变量来唤醒所有在这个完全变量上等待的任务。 |
| … | … |
软件定时器
- 硬件定时器:芯片本身提供的定时器,一般由外部晶振提供,提供寄存器设置超时时间,并采用外部中断方式通知 CPU,参考第 12 章介绍。优点是精度高,但定时器个数受硬件芯片的设计限制。
- 软件定时器:操作系统中基于硬件定时器提供的功能,采用软件方式实现。扩展了硬件定时器的限制,可以 提供数目更多(几乎不受限制)的定时器;缺点是精度较低,必须是 Tick 的整数倍。
软件定时器的分类
- 按照定时器设定方式分:
- 单次触发定时器:创建后只会触发一次定时器通知事件,触发后 该定时器自动停止(销毁)
- 周期触发定时器:创建后按照设定的周期无限循环触发定时器通 知事件,直到用户手动停止。
- 按照定时器超时后执行处理函数的上下文环境分:
- 超时函数运行在中断上下文环境中,要求执行函数的执行时间尽可能短,不可以执行等待其他事件等可能导致中断控制路径挂起的操作。优点是响应比较迅速,实时性较高。
- 超时函数运行在任务上下文环境中,即创建一个任务来执行这个函数,函数中可以等待或者挂起,但实时性较差。
软件定时器的设计和实现
参照代码
软件定时器的优化
- 定时器按照超时时间排序
- 链表方式实现对定时器的管理
若是链表方法,则搜索时间比较长,可以采用跳表(Skip List)算法。
系统调用
系统模式:用户态和内核态
一般情况是在用户态,需要用到内核态的东西的时候切换到内核态。
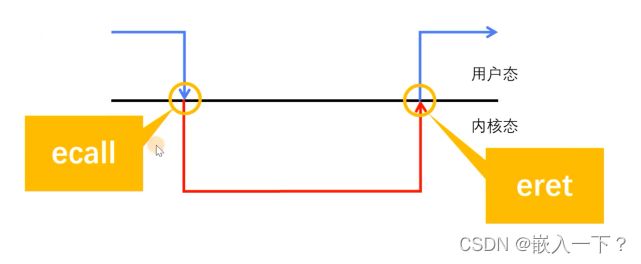
系统模式的切换

- ECALL 命令用于主动触发异常
- 根据调用 ECALL 的权限级别产生不同的 exception code
- 异常产生时 epc 寄存器的值存T放的是 ECALL 指令本身的地址。

因为是 machine 切换 user 的时候是异常进入,所以epc存储的值是,当前调用的地址,所以返回前要把地址往后自增到后一条指令上。
系统调用的执行流程
通过 ecall 到异常中,切换为 machine 执行对应的系统调用,然后,退出回到 user 态。
系统调用的传参
- 系统调用作为操作系统的对外接口,由操作系统的实现负责定义。参考 Linux 的系统调用,RVOS 定 义系统调用的传参规则如下:
- 系统调用号放在 a7 中
- 系统调用参数使用 a0 ~ a5
- 返回值使用 a
系统调用的封装
参照代码