机器学习笔记--支持向量机
1、支持向量机概述
1.1 基本概念
支持向量机(Support Vector Machine,SVM ) 是一类按监督学习方式对数据进行二元分类 的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面 。
1.2 硬间隔、软间隔和非线性 SVM
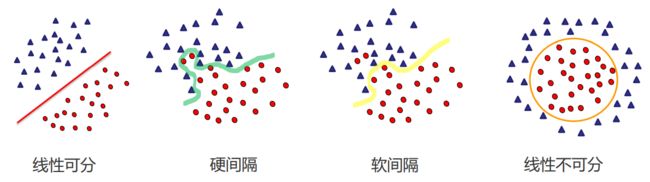
硬间隔指的就是完全分类准确,不能存在分类错误的情况。软间隔,就是允许一定量的样本分类错误。
1.3 算法思想
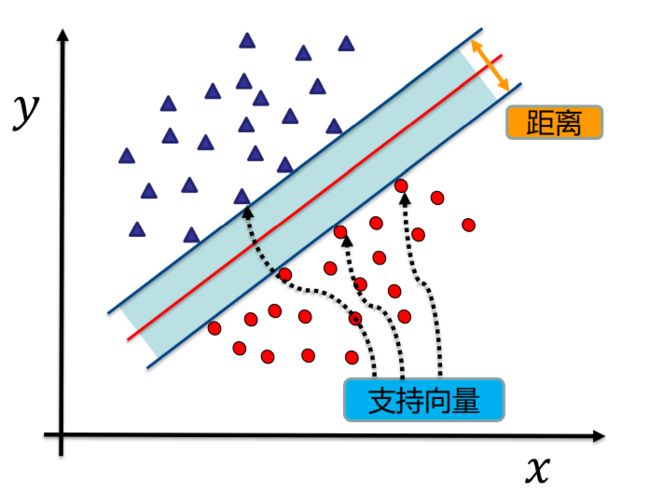
找到集合边缘上的若干数据(称为支持向量(Support Vector)),用这些点找出一个平面(称为决策面),使得支持向量到该平面的距离最大。
2、支持向量机求解
2.1 基础知识
(1)任意超平面均可用下面的线性方程来表示:
w T x + b = 0 w^{T} x+b=0 wTx+b=0
(2)二维空间点 (, )到直线 + + =0 的距离公式是:
∣ A x + B y + C ∣ A 2 + B 2 \frac{|A x+B y+C|}{\sqrt{A^{2}+B^{2}}} A2+B2∣Ax+By+C∣
推广到 n 维空间,点到超平面的距离为:
∣ w T x + b ∣ ∥ w ∥ \frac{\left|w^{T} x+b\right|}{\|w\|} ∥w∥ wTx+b
其中, ∥ w ∥ = w 1 2 + ⋯ w n 2 \|w\|=\sqrt{w_{1}^{2}+\cdots w_{n}^{2}} ∥w∥=w12+⋯wn2
2.2 计算求解
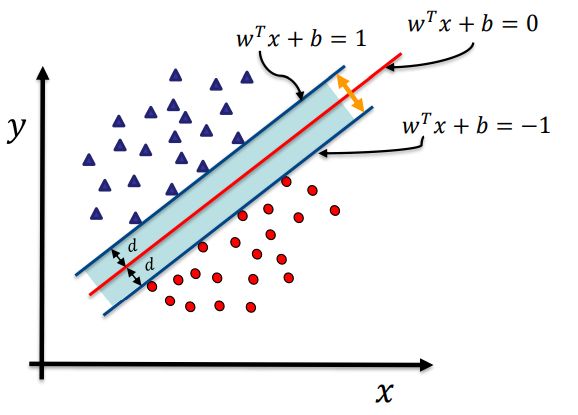
(1)如上图,根据定义我们可以知道,支持向量到超平面 w T x + b = 0 w^{T} x+b=0 wTx+b=0 的距离为 d ,则其他点到超平面的距离均大于 d 。
对于样本点 ( x i , y i ) (x_i, y_i) (xi,yi),若 y 1 = + 1 y_1= + 1 y1=+1 ,则 w T x + b > d w^{T} x+b > d wTx+b>d;若 y 1 = − 1 y_1= - 1 y1=−1 ,则 w T x + b < − d w^{T} x+b < -d wTx+b<−d。于是有
{ w T x + b ∥ w ∥ ≥ d y = + 1 w T x + b ∥ w ∥ ≤ − d y = − 1 \left\{\begin{array}{cc} \frac{w^{T} x+b}{\|w\|} \geq d & y=+1 \\ \\ \frac{w^{T} x+b}{\|w\|} \leq-d & y=-1 \end{array}\right. ⎩ ⎨ ⎧∥w∥wTx+b≥d∥w∥wTx+b≤−dy=+1y=−1
暂且令 d=1(之所以令它等于 1,是为了方便推导和优化
,且这样做对目标函数的优化没有影响,可以缩放变换),则上式可合并为
y ( w T x + b ) ≥ 1 y\left(w^{T} x+b\right) \geq 1 y(wTx+b)≥1
两个边界平面的间隔为:
γ = 2 ∥ w ∥ \gamma=\frac{2}{\|\boldsymbol{w}\|} γ=∥w∥2
欲找到最大间隔来划分超平面,也就是要找到满足约束的 ω \omega ω 和 b ,使 γ \gamma γ 最大。即
max w , b 2 ∥ w ∥ s.t. y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , … , m \begin{aligned} &\max _{\boldsymbol{w}, b} \frac{2}{\|\boldsymbol{w}\|} \\ \\ &\text { s.t. } y_{i}\left(\boldsymbol{w}^{\mathbf{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, m \end{aligned} w,bmax∥w∥2 s.t. yi(wTxi+b)⩾1,i=1,2,…,m
这等价于最小化 ∥ w ∥ 2 \|\boldsymbol{w}\|^{2} ∥w∥2,则上式改写为
min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , … , m \begin{aligned} &\min _{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \\ &\text { s.t. } y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, m \end{aligned} w,bmin21∥w∥2 s.t. yi(wTxi+b)⩾1,i=1,2,…,m
(2)用拉格朗日乘子法和KKT条件求解最优值:
该问题的拉格朗日函数可写为:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 + ∑ i = 1 m α i ( − y i ( w T x i + b ) + 1 ) L(w, b, \alpha)=\frac{1}{2}\|w\|^{2}+\sum_{i=1}^{m} \alpha_{i}\left(-y_{i}\left(w^{T} x_{i}+b\right)+1\right) L(w,b,α)=21∥w∥2+i=1∑mαi(−yi(wTxi+b)+1)
求导
{ ∂ ∂ w L ( w , b , α ) = w − ∑ i = 1 m α i y i x i = 0 ∂ ∂ b L ( w , b , α ) = ∑ i = 1 m α i y i = 0 \left\{\begin{array}{cc} \frac{\partial}{\partial w} L(w, b, \alpha)=w-\sum_{i=1}^{m} \alpha_{i} y_{i} x_{i}=0 \\ \\ \frac{\partial}{\partial b} L(w, b, \alpha)=\sum_{i=1}^{m} \alpha_{i} y_{i}=0 \end{array}\right. ⎩ ⎨ ⎧∂w∂L(w,b,α)=w−∑i=1mαiyixi=0∂b∂L(w,b,α)=∑i=1mαiyi=0
解得
{ w = ∑ i = 1 m α i y i x i ∑ i = 1 m α i y i = 0 \left\{\begin{array}{cc} w=\sum_{i=1}^{m} \alpha_{i} y_{i} x_{i} \\ \\ \sum_{i=1}^{m} \alpha_{i} y_{i}=0 \end{array}\right. ⎩ ⎨ ⎧w=∑i=1mαiyixi∑i=1mαiyi=0
再代入 L ( w , b , α ) L(w, b, \alpha) L(w,b,α),得
min w , b L ( w , b , α ) = 1 2 ∥ w ∥ 2 + ∑ i = 1 α i ( − y i ( w T x i + b ) + 1 ) = 1 2 w T w − ∑ i = 1 m α i y i w T x i − b ∑ i = 1 m α i y i + ∑ i = 1 m α i = 1 2 w T ∑ i = 1 m α i y i x i − ∑ i = 1 m α i y i w T x i + ∑ i = 1 m α i = ∑ i = 1 m α i − 1 2 ∑ i = 1 m α i y i w T x i = ∑ i = 1 m α i − ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) \begin{gathered} \min _{w, b} L(w, b, \alpha)=\frac{1}{2}\|w\|^{2}+\sum_{i=1} \alpha_{i}\left(-y_{i}\left(w^{T} x_{i}+b\right)+1\right) \\ =\frac{1}{2} w^{T} w-\sum_{i=1}^{m} \alpha_{i} y_{i} w^{T} x_{i}-b \sum_{i=1}^{m} \alpha_{i} y_{i}+\sum_{i=1}^{m} \alpha_{i} \\ =\frac{1}{2} w^{T} \sum_{i=1}^{m} \alpha_{i} y_{i} x_{i}-\sum_{i=1}^{m} \alpha_{i} y_{i} w^{T} x_{i}+\sum_{i=1}^{m} \alpha_{i} \\ =\sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \alpha_{i} y_{i} w^{T} x_{i} \\ =\sum_{i=1}^{m} \alpha_{i}-\sum_{i, j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right) \end{gathered} w,bminL(w,b,α)=21∥w∥2+i=1∑αi(−yi(wTxi+b)+1)=21wTw−i=1∑mαiyiwTxi−bi=1∑mαiyi+i=1∑mαi=21wTi=1∑mαiyixi−i=1∑mαiyiwTxi+i=1∑mαi=i=1∑mαi−21i=1∑mαiyiwTxi=i=1∑mαi−i,j=1∑mαiαjyiyj(xi⋅xj)
s.t. ∑ i = 1 m α i y i = 0 , α i ⩾ 0 , i = 1 , 2 , … , m \begin{array}{ll} \text { s.t. } & \sum_{i=1}^{m} \alpha_{i} y_{i}=0, \\ & \alpha_{i} \geqslant 0, \quad i=1,2, \ldots, m \end{array} s.t. ∑i=1mαiyi=0,αi⩾0,i=1,2,…,m
用 SMO 算法求解出 α i \alpha_i αi,最终得到超平面
f ( x ) = w T x + b = ∑ i = 1 m α i y i x i T x + b \begin{aligned} f(\boldsymbol{x}) &=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b \\ &=\sum_{i=1}^{m} \alpha_{i} y_{i} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}+b \end{aligned} f(x)=wTx+b=i=1∑mαiyixiTx+b
3、线性支持向量机(软间隔支持向量机)与松弛变量
在前面的讨论中,我们假设训练样本在样本空间或者特征空间中是线性可分的,但在现实任务中往往很难确定合适的核函数使训练集在特征空间中线性可分。
线性不可分意味着某些样本点 ( x i , y i ) (x_i, y_i) (xi,yi)不能满足间隔大于等于1的条件,样本点落在超平面与边界之间。为解决这一问题,可以对每个样本点引入一个松弛变量 ξ i ≥ 0 \xi_{i} \geq 0 ξi≥0,使得间隔加上松弛变量大于等于1,这样约束条件变为:
y i ( w T x i + b ) + ξ i ≥ 1 y_{i}\left(w^{T} x_{i}+b\right) +\xi_{i}\geq 1 yi(wTxi+b)+ξi≥1
也即
y i ( w T x i + b ) ≥ 1 − ξ i y_{i}\left(w^{T} x_{i}+b\right) \geq 1-\xi_{i} yi(wTxi+b)≥1−ξi
同时,对于每一个松弛变量 ξ i ≥ 0 \xi_{i} \geq 0 ξi≥0,支付一个代价 ξ i ≥ 0 \xi_{i} \geq 0 ξi≥0,目标函数变为
1 2 ∥ w ∥ 2 + C ∑ i = 1 m ξ i \frac{1}{2}\|w\|^{2}+C \sum_{i=1}^{m} \xi_{i} 21∥w∥2+Ci=1∑mξi
其中 C>0 为惩罚参数,C 值大时对误分类的惩罚增大,C值小时对误分类的惩罚减小,上式包含两层含义:使 1 2 ∥ w ∥ 2 \frac{1}{2}\|w\|^{2} 21∥w∥2尽量小即间隔尽量大,同时使误分类点的个数尽量小, C 是调和两者的系数。
跟线性可分求解的思路一致,同样这里先用拉格朗日乘子法得到拉格朗日函数,再求其对偶问题。
可以这样理解
- C 较大时,相当于 较小,可能会导致过拟合,高方差。
- C 较小时,相当于 较大,可能会导致低拟合,高偏差。
4、线性不可分支持向量机
4.1 核函数
在低维空间计算获得高维空间的计算结果,满足高维,才能在高维下线性可分。
我们需要引入一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在新的空间中线性可分。
这样我们就可以使用原来的推导来进行计算,只是所有的推导是在新的空间,而不是在原来的空间中进行,即用核函数来替换当中的内积。

用 ϕ ( x ) \phi(x) ϕ(x)表示将 x 映射后的特征向量,于是在特征空间中,划分超平面所对应的的模型可表示为:
f ( x ) = w T ϕ ( x ) + b f(x)=w^{T} \phi(x)+b f(x)=wTϕ(x)+b
于是有最小化函数
min w , b 1 2 ∥ w ∥ 2 , s.t. y i ( w T ϕ ( x i ) + b ) ≥ 1 ( i = 1 , 2 , … , m ) \min _{w, b} \frac{1}{2}\|w\|^{2}, \quad \text { s.t. } \quad y_{i}\left(w^{T} \phi\left(x_{i}\right)+b\right) \geq 1 \quad(i=1,2, \ldots, m) w,bmin21∥w∥2, s.t. yi(wTϕ(xi)+b)≥1(i=1,2,…,m)
其对偶问题为
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j ϕ ( x i ) T ϕ ( x j ) s.t. ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , … , m \begin{aligned} &\max _{\alpha} \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \phi\left(x_{i}\right)^{T} \phi\left(x_{j}\right) \\ &\text { s.t. } \sum_{i=1}^{m} \alpha_{i} y_{i}=0, \alpha_{i} \geq 0, \quad i=1,2, \ldots, m \end{aligned} αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjϕ(xi)Tϕ(xj) s.t. i=1∑mαiyi=0,αi≥0,i=1,2,…,m
这里会涉及到计算 ϕ ( x i ) T ϕ ( x j ) \phi\left(x_{i}\right)^{T} \phi\left(x_{j}\right) ϕ(xi)Tϕ(xj),即样本 x i x_i xi 和 x j x_j xj映射到特征空间后的内积,直接计算是十分困难的,于是有核函数
κ ( x i , x j ) = < ϕ ( x i ) , ϕ ( x j ) > = ϕ ( x i ) T ϕ ( x j ) \kappa\left(x_{i}, x_{j}\right)=<\phi\left(x_{i}\right), \phi\left(x_{j}\right)>=\phi\left(x_{i}\right)^{T} \phi\left(x_{j}\right) κ(xi,xj)=<ϕ(xi),ϕ(xj)>=ϕ(xi)Tϕ(xj)
则上式可写为
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j κ ( x i , x j ) s.t. ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , … , m \begin{aligned} &\max _{\alpha} \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \kappa\left(x_{i}, x_{j}\right) \\ &\text { s.t. } \sum_{i=1}^{m} \alpha_{i} y_{i}=0, \alpha_{i} \geq 0, \quad i=1,2, \ldots, m \end{aligned} αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjκ(xi,xj) s.t. i=1∑mαiyi=0,αi≥0,i=1,2,…,m
求解后得到
f ( x ) = w T ϕ ( x ) + b = ∑ i = 1 m α i y i ϕ ( x i ) T ϕ ( x j ) + b = ∑ i = 1 m α i y i κ ( x i , x j ) + b \begin{aligned} f(x) &=w^{T} \phi(x)+b \\ &=\sum_{i=1}^{m} \alpha_{i} y_{i} \phi\left(x_{i}\right)^{T} \phi\left(x_{j}\right)+b \\ &=\sum_{i=1}^{m} \alpha_{i} y_{i} \kappa\left(x_{i}, x_{j}\right)+b \end{aligned} f(x)=wTϕ(x)+b=i=1∑mαiyiϕ(xi)Tϕ(xj)+b=i=1∑mαiyiκ(xi,xj)+b
常用的核函数有:
- 线性核函数
K ( x i , x j ) = x i T x j K\left(x_{i}, x_{j}\right)=x_{i}^{T} x_{j} K(xi,xj)=xiTxj
即该向量机不适用核函数 - 多项式核函数
K ( x i , x j ) = ( x i T x j ) d K\left(x_{i}, x_{j}\right)=\left(x_{i}^{T} x_{j}\right)^{d} K(xi,xj)=(xiTxj)d
- 高斯核函数
K ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 δ 2 ) K\left(x_{i}, x_{j}\right)=\exp \left(-\frac{\left\|x_{i}-x_{j}\right\|}{2 \delta^{2}}\right) K(xi,xj)=exp(−2δ2∥xi−xj∥)
4.2 SVM 使用准则
(1)SVM 的超参数
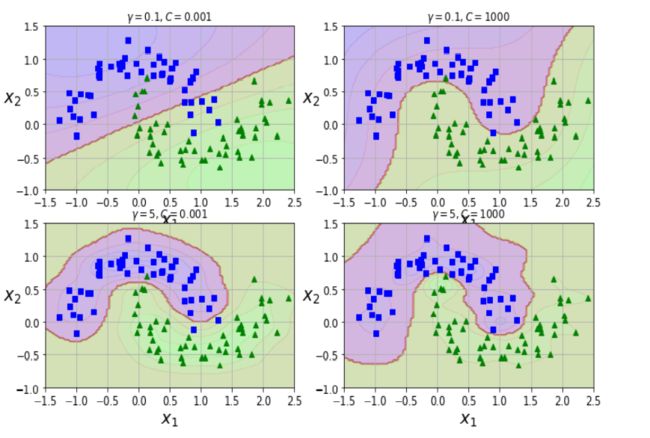
-
越大,支持向量越少,值越小,支持向量越多。
-
C = 1 / λ C=1/\lambda C=1/λ较大时,相当于较小,可能会导致过拟合,高方差;
-
C = 1 / λ C=1/\lambda C=1/λ较小时,相当于较大,可能会导致低拟合,高偏差;
-
较大时,可能会导致低方差,高偏差;
-
较小时,可能会导致低偏差,高方差。
(2)SVM 使用准则
n为特征数,m为训练样本数。
-
如果相较于 m 而言,n 要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
-
如果 n 较小,而且 m 大小中等,例如 n 在 1-1000 之间,而 m 在 10-10000 之间,使用高斯核函数的支持向量机。
-
如果 n 较小,而 m 较大,例如 n 在 1-1000 之间,而 m 大于 50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。