文本处理算法_第四天:文本处理流程——分词

分词工具的使用
我们在前一篇文章中介绍过文本处理流程,主要包括分词、文本预处理(无用标签、特殊符号、停用词、大写转小写)、标准化、特征提取、建模、系统评估。今天我们介绍在自然语言处理(NLP)中的文本处理流程中的第一个环节:分词处理。以下是我们分词常用的库,具体如图所示:

其中我们用的最多的中文分词就是Jieba分词工具。我们直接可以在黑屏终端安装;直接按win+R打开黑屏终端;如图所示:并且在其终端输入以下代码:
pip 
由于我已经安装该库,所以显示如下;jieba库支持三种分词模式;具体是指:
1、精确模式,试图将句子最精确地切开,适合文本分析;
2、全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
3、搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
并且还支持繁体分词、自定义词典(经常用到)、MIT 授权协议。我们通过一句话来大致给大家介绍jieba分词的使用。例如我们用jieba库分这句话“我想称为一名合格的NLP算法工程师”。
# 首先让我们导入jieba库
其分词结果入下图:
很明显与我们常说的思路不相符合,应该将“合格的”分在一起;“NLP算法”为一起。因此,我们只需要将这两个词汇通过jieba.add()加入jieba库即可使用。具体实现如下:
jieba添加词汇到库后的分词效果如下:
以上就是jieba分词库的使用,更多的分词库的相关使用,请查看python机器学习库教程——结巴中文分词。这篇文章写得特别详细。
算法一:最大匹配算法(MM)
最大匹配算法是分词中常用的算法之一。其中包括前向最大匹配算法、后向最大匹配算法。其思路均差不多,只不过前向最大匹配算法是从前往后分词;而后向匹配算法是从后往前匹配。
1、前向最大匹配算法
首先,我们分词的目的是将一段中文分成若干个词语,前向最大匹配就是从前向后寻找在词典中存在的词。例如,我们要划分“我们经常有意见分歧”,首先我们假设Max_len = 5,即假设单词的最大长度为5。再假设我们现在词典中存在的词有:
词库:[“我们”, “经常”,“常有”, “有意见”,“有意”, “意见”, “分歧”,“我”,“们”, “经”,“常”,“有”,“意”,“见”]
现在,我们用前向最大匹配算法来划分这句话。例:我们经常有意见分歧(max_len = 5),具体实现过程如下:
第一轮: 取子串 “我们经常有”,正向取词,如果匹配失败,每次去掉匹配字段最后面的一个字。
1、我们经常有”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“我们经常”。
2、我们经常”,扫描词典中的4字单词,没有匹配,变为“我们经”。
3、“我们经”,扫描词典中的3字单词,没有匹配, 变为“我们”。
4、“我们”,扫描词典中的2字单词,匹配成功,输出“我们”,输入变为“经常有意见分歧”。
第二轮 取子串“经常有意见”
1、“经常有意见”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“经常有意”。
2、“经常有意”,扫描词典中的4字单词,没有匹配,子串长度减 1 变为“经常有”。
3、“经常有”,扫描词典中的3字单词,没有匹配,子串长度减 1 变为“经常”。
4、“经常”,扫描词典中的2字单词,有匹配,输出“经常”,输入变为“有意见分歧”。
……以此类推,直到输入长度为0时,扫描终止。最终,前向最大匹配算法得出的结果为:我们 / 经常 / 有意见 / 分歧为了提高代码运算时间,我只提取了其中的一小部分作为测试集合训练集。我们用到的训练集和测试集均来自这里(data,提取码为95if)。这是训练集、测试集:

我们将数据集保存在同目录的data文件下,代码结构如图所示:
具体用python代码实现如下:
test_file 具体分词的结果保存在了result中,其效果图如图所示:

2、后向匹配算法
与前向最大匹配算法类似,只是方向相反,即从后向前寻找词典中存在的词并输出。我们还是以前面的 “我们经常有意见分歧“ 为例,词库还是原来的词库,max_len = 5。其过程如下:
第一轮: 取子串 “有意见分歧”,后向取词,如果匹配失败,每次去掉匹配字段最前面的一个字。
1、“有意见分歧”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“意见分歧”。
2、意见分歧”,扫描词典中的4字单词,没有匹配,变为“见分歧”。
3、“见分歧”,扫描词典中的3字单词,没有匹配, 变为“分歧”。
4、“分歧”,扫描词典中的2字单词,匹配成功,输出“分歧”,输入变为“我们经常有意见”。
第二轮: 取子串“经常有意见”
1、“经常有意见”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“常有意见”。
2、“经常有意见”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“常有意见”。
3、“经常有意见”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“常有意见”。
……以此类推,直到输入长度为0时,扫描终止。最终,后向最大匹配算法得出的结果为:我们 / 经常 / 有意见 / 分歧。由此可知,前向最大匹配和后向最大匹配的结果是一致的,当然这不是绝对的。因为词库如果分的细一点,很有可能导致两种遍历的方式不同,导致其结果不同。还是之前的训练集和测试集。我们实现代码如下:
test_file 我们把结果保存到data/result2.txt中,具体效果如图所示:

最大匹配算法的优点在于易于实现,切且简单粗暴,很容易达到分词的效果。但是其缺点也很明显,不能实现句子的细分;只能得到局部最优解;效率低下;时间复杂度过高。关键最为重要的一点就是不能消除歧义,其分词完全取决于词典,词典的好坏直接决定着分词的结果,根本没有考虑到语义的问题,因此接下来,我们从语义的角度出发去分词。但是最大匹配算法是运用的贪心算法。
考虑语义(Language Module)
文本处理中的分词考虑的就是语义,这是一个比较高层次的问题。因此,首先是输入 —>生成所有可能分词---->**选择其中匹配度最高的。**其中这个工具就是语言模型。计算这种语言模型我们有很多中方法,其中包括LM、CRF以及HMM等。不过独立分布是最简单的。但是存在的一个问题就是要分两步,首先就是要列出所有的分词情况,第二步就是选取出可能性最高的分词结果给返回。这样就造成时间复杂度很高。效率极其的低下,因此我们应该提高效率。我们可以引进一种利用动态规划的算法—viterbi算法。
维特比算法(Viterbi Algorithm)
维特比算法 (Viterbi algorithm) 是机器学习中应用非常广泛的动态规划算法,在求解隐马尔科夫、条件随机场的预测以及seq2seq模型概率计算等问题中均用到了该算法。实际上,维特比算法不仅是很多自然语言处理的解码算法,也是现代数字通信中使用最频繁的算法。在介绍维特比算法之前,先回顾一下隐马尔科夫模型,进而介绍维特比算法的计算步骤。
以下为一个简单的隐马尔科夫模型,如下图所示:
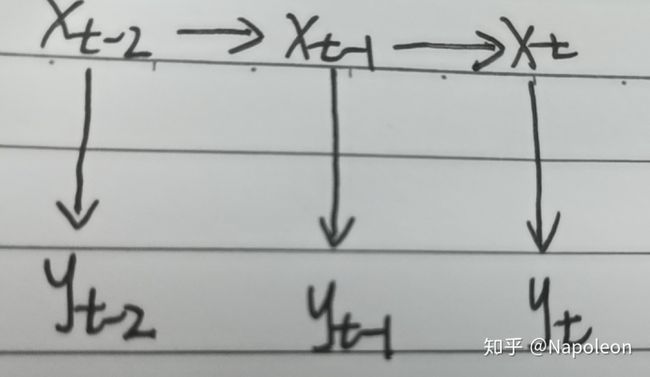
其中x = (x1, x2, …, xN) 为隐状态序列,y = (y1, y2, …, yN) 为观测序列,要求的预测问题为:

在隐马尔科夫链中,任意时刻t下状态的值有多个,以拼音转汉字为例,输入拼音为“yike”可能有的值为一棵,一刻或者是一颗等待,用符号xij表示状态xi的第j个可能值,将状态序列按值展开,就得到了一个篱笆网了,这也就是维特比算法求解最优路径的图结构:

隐马尔科夫的预测问题就是要求图中的一条路径,使得该路径对应的概率值最大。 对应上图来讲,假设每个时刻x可能取的值为3,如果直接求的话,有3^N的组合数,底数3为篱笆网络宽度,指数N为篱笆网络的长度,计算量非常大。维特比利用动态规划的思想来求解概率最大路径(可理解为求图最短路径),使得复杂度正比于序列长度,复杂度为O(N⋅D⋅D), N为长度,D为宽度,从而很好地解决了问题的求解。维特比算法的基础可以概括为下面三点:
1、如果概率最大的路径经过篱笆网络的某点,则从开始点到该点的子路径也一定是从开始到该点路径中概率最大的。
2、假定第i时刻有k个状态,从开始到i时刻的k个状态有k条最短路径,而最终的最短路径必然经过其中的一条。
3、根据上述性质,在计算第i+1状态的最短路径时,只需要考虑从开始到当前的k个状态值的最短路径和当前状态值到第i+1状态值的最短路径即可,如求t=3时的最短路径,等于求t=2时的所有状态结点x2i的最短路径加上t=2到t=3的各节点的最短路径。
为了纪录中间变量,引入两个变量sigma和phi,定义t时刻状态为i的所有单个路径 (i1, i2, …, it) 中最大概率值(最短路径)为
其中it表示最短路径,Ot表示观测符号,lamda表示模型参数,根据上式可以得出变量sigma的递推公式:
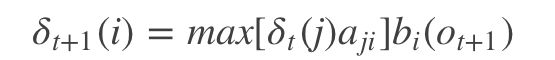
其中i = 1, 2, …, N; t = 1, 2, … , T-1,定义在时刻t状态为i的所有单个路径 (i1, i2, …, it, i) 中概率最大的路径的第t-1个结点为:

根据上面的两个定义下面给出维特比算法具体内容:
输入为模型和观测状态分别为:
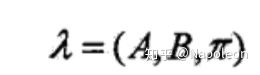
输出为求出最优路径:
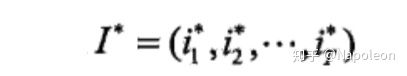
步骤为:(1) 初始化各参数:
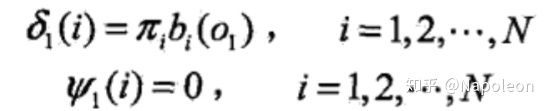
(2) 根据上式进行递推,对t=2, 3, …, T

(3) 最后的终止状态(T状态)计算:
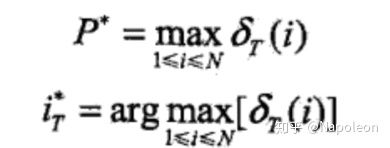
最优路径的回溯,对t=T-1, T-2,…, 1
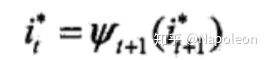
最后求得最优路径为:
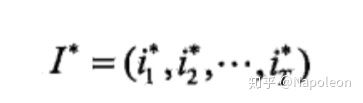
接下来我们用python将其实现:
import 运行效果如图所示

以上就是维特比算法的推导过程和代码实现,不过需要我们清楚的是维特比算法用到的就是典型的动态规划(DP),与我们之前的最大匹配算法截然不同,大大提高了效率。
贪心算法 VS. 动态规划
二者之间有着本质的区别,通俗地讲:贪心算法只能看到局部最优,看不到全局最优,而动态规划可以看到全局最优。贪心算法的选择策略即贪心选择策略,通过对候选解按照一定的规则进行排序,然后就可以按照这个排好的顺序进行选择了,选择过程中仅需确定当前元素是否要选取,与后面的元素是什么没有关系。动态规划的选择策略是试探性的,每一步要试探所有的可行解并将结果保存起来,最后通过回溯的方法确定最优解,其试探策略称为决策过程。主要不同:两种算法的应用背景很相近,针对具体问题,有两个性质是与算法选择直接相关的,最优子结构性质和贪心选择性质。最优子结构性质是选择类最优解都具有的性质,即全优一定包含局优,上一次选择最短路线的例子已经对此作了说。在贪心算法中,作出的每步贪心决策都无法改变,因为贪心策略是由上一步的最优解推导下一步的最优解,而上一部之前的最优解则不作保留。并且,每一步的最优解一定包含上一步的最优解。而在动态规划算法中,全局最优解中一定包含某个局部最优解,但不一定包含前一个局部最优解,因此需要记录之前的所有最优解。动态规划的关键是状态转移方程,即如何由以求出的局部最优解来推导全局最优解。也就是说,把一个复杂问题分解成一块一块的小问题,每一个问题得到最优解,再从这些最优解中获取更优的答案。
总结
总之,本文是通过对自然语言处理中的文本流程处理的放第一个环节——分词做了详细的介绍,从刚开始的应用合适的库到两大算法的介绍:分别是最大匹配算法和维特比算法。其中还分别用python将其实现。指出了最大匹配算法的一些缺陷,最重要的就是没有考虑到语义的问题。后来我们又引进了语言模型,最后通过维特比算法来很好的解决了分词的问题。由于最大匹配算法用到的是贪心算法,而维特比算法用到的是动态规划算法。因此,我们最后简单介绍了贪心算法和动态规划的区别。通过以上的介绍,我们初步掌握了NLP文本处理中的第一步:分词,接下来我们介绍其他流程。向着一个合格的NLP工程师迈进。
参考文献
[1]结巴中文分词
[2]中文分词之最大匹配算法
[3]维特比(Viterbi)算法详解
[4]动态规划算法和贪心算法的区别与联系