XLNet:运行机制及和Bert的异同比较 - 知乎
目录
1 XLNet引入了自回归语言模型及自编码语言模型
1.1 自回归语言模型(Autoregressive LM)
概念:
优点:
缺点:
1.2 自编码语言模型(Autoencoder LM)
概念:
优点:
缺点:
1.3 XLNet的思想及改进
1.3.1 能不能在自回归语言模型中,引入双向语言模型呢?(看上去仍是单向的输入和预测模式,但内部已经引入当前单词的上下文信息)XLNet是怎么做的?这也是它的主要理论创新,开启了自回归语言模型引入下文的思路
1.3.2 XLNet的主要改进点
1.3.3 哪些因素在起作用?
1.3.4 XLNet相比bert有哪些优势
2 与bert预训练过程的异同
2.1 XLNet对于阅读理解类任务,相对bert,性能有极大提升
2.2 其他类型的nlp任务,相对bert,效果有提升但是幅度不大
3 XLNet对nlp应用任务的影响
XLNet在自回归语言模型中,通过PLM引入了双向语言模型。也就是在预训练阶段,采用attention掩码的机制,通过对句子中单词的排列组合,把一部分下文单词排到上文位置。
PLM预训练目标、更多更高质量的预训练数据,transformerXL的主要思想。这就是XLNet的三个主要改进点,这使XLNet相比bert在生成类任务上有明显优势,对于长文档输入的nlp任务也会更有优势。
XLNet的实验可以看出,对于阅读理解类任务相对bert有极大提升,transformerXL的引入肯定是起了较大的作用,但由于数据差异没有抹平,所以无法确定是否是模型差异带来的效果差异。对于其他的nlp任务,效果有幅度不大的提升,同样无法确定这种性能提升来自于那个因素。其中磨平了数据规模因素的实验,可以发现,PLM和transformerXL确实带来了收益。
XLNet在长文档和生成类任务比较有优势,在优势领域的应用结果值得期待,以及在这些任务上的进一步改进模型。
从实验数据看,在某些场景下,XLNet相对bert确实有很大幅度的提升。
1 XLNet引入了自回归语言模型及自编码语言模型
1.1 自回归语言模型(Autoregressive LM)
概念:
根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词。典型:GPT ELMo
优点:
其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。
缺点:
只能利用上文或者下文的信息,不能同时利用上文和下文的信息
1.2 自编码语言模型(Autoencoder LM)
概念:
Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
优点:
能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文
缺点:
输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的。DAE吗,就要引入噪音,[Mask] 标记就是引入噪音的手段,这个正常。
1.3 XLNet的思想及改进
在第一个预训练阶段,XLNet相对bert要解决两个问题:
- mask标记带来的两阶段不一致问题
- 预训练阶段中,被mask的单词是条件独立的,而有时候这些单词之间是有关系的
自回归语言模型天然适合生成类NLP任务,但不能同时利用上下文信息
自编码语言模型能利用上下文适合理解类的NLP任务,但是存在两阶段不一致问题
1.3.1 能不能在自回归语言模型中,引入双向语言模型呢?(看上去仍是单向的输入和预测模式,但内部已经引入当前单词的上下文信息)XLNet是怎么做的?这也是它的主要理论创新,开启了自回归语言模型引入下文的思路
- XLNet仍遵循两阶段过程
- 改动预训练阶段,不采用自编码语言模型,而是采用自回归语言模型,无mask也就不存在不一致问题,且预训练阶段已经是标准的单向语言模型了
- 如何在单词的上文中引入下文的信息呢?
- XLNet在预训练阶段,引入permutation language model的训练目标,通过对句子中单词排列组合,把一部分下文单词排到上文位置中。做法思想是,采用attention掩码的机制:当前输入句子是X,要预测的第i个单词,i前面的单词位置不变,但是在transformer内部,通过attention mask,把其他没有被选到的单词mask掉,不让他们在预测单词的时候发生作用,看上去就是把这些被选中用来做预测的单词放在了上文位置了。
- 具体实现是用“双流自注意力模型”,基本思想如上所述,这个思想也可以有其他的具体实现方式,来达成让预测单词i时可以看到下文单词的目标
- 双流自注意力机制:
- 内容流自注意力:就是标准transformer的计算过程,主要是引入了query流自注意力(用来代替bert的mask标记的,query流直接忽略预测单词的输入,只保留位置信息,用参数w来代表位置的embedding编码)
- 双流自注意力机制:
1.3.2 XLNet的主要改进点
- 通过PLM预训练目标,吸收了bert的双向语言模型
- 更多更高质量的预训练数据,吸收了GPT2的核心
- 解决长文档NLP应用不友好的问题,吸收了transformer XL的主要思想
1.3.3 哪些因素在起作用?
(XLNet实验部分并没有充分说明,这些因素各自发挥了多大作用,尤其是在和bert对比的时候,如果没有把数据规模这个变量磨平进行比较,是无法看出模型差异导致的性能差异的,所以最后一组实验磨平了数据规模差异后信息量更大的)
- PLM训练目标,在自回归LM模式下,采取具体手段融入双向语言模型
- transformer-XL:相对位置编码以及分段RNN机制。对长文档任务很有帮助
- 加大了预训练阶段使用的数据规模,gpt2.0路线
1.3.4 XLNet相比bert有哪些优势
- 因为维持了表面的单向语言模式,对于生成类任务能在表面单向的的前提下,又隐含了上下文信息,相比bert有明显优势
- 因为引入了transformer XL机制,对长文档输入的NLP任务也会更有优势
2 与bert预训练过程的异同
- XLNet在预训练机制中引入PLM这个新的预训练目标
- bert采用mask标记的方式
区别主要在于,一个显示mask,一个将mask的过程藏在了transformer内部
bert采用mask标记,在输入侧隐藏部分单词,让其在预测中不发挥作用,而利用上下文的其他单词去预测某个被mask的单词
XLNet则通过attention mask机制,在transformer内部随机mask部分单词(mask的单词比例与当前单词在句子中的位置有关,位置越靠前,被mask掉的比例越高),让这些被mask的单词在预测某个单词的时候不发生作用
- 无mask标记也就解决了,两阶段不一致问题
- XLNet说的mask掉的单词之间的关系,其实是不重要的,因为训练数据足够大的话,总有其他例子能学会这些单词的相互依赖关系
2.1 XLNet对于阅读理解类任务,相对bert,性能有极大提升

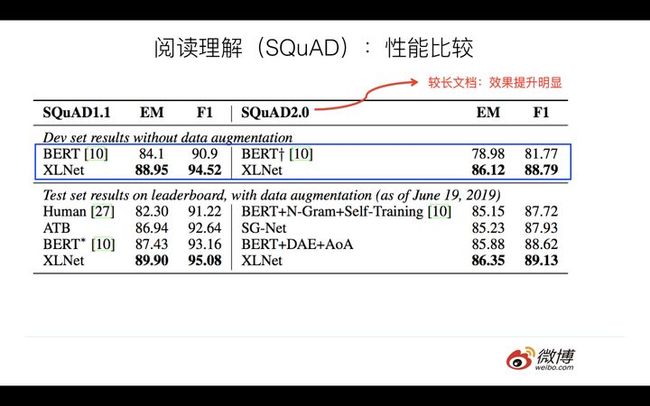
其中,RACE和SQuAD 2.0是文档长度较长的阅读理解任务,任务难度也相对高。可以看出,在这两个任务中,XLNet相对 Bert_Large,确实有大幅性能提升(Race提升13.5%,SQuAD 2.0 F1指标提升8.6)。在Squad1.1上提升尽管稍微小些,F1提升3.9%,但是因为基准高,所以提升也比较明显。
说XLNet在阅读理解,尤其是长文档的阅读理解中,性能大幅超过Bert,这个是没疑问的。但是,因为XLNet融入了上文说的三个因素,所以不确定每个因素在其中起的作用有多大,而对于长文档,Transformer XL的引入肯定起了比较大的作用,Bert天然在这种类型任务中有缺点,其它两类因素的作用不清楚。感觉这里应该增加一个基准,就是Bert用与XLNet相同大小的预训练数据做,这样抹平数据量差异,更好比较模型差异带来的效果差异。当然,我觉得即使是这样,XLNet应该仍然是比Bert效果好的,只是可能不会差距这么大,因为XLNet的长文档优势肯定会起作用。
2.2 其他类型的nlp任务,相对bert,效果有提升但是幅度不大

GLUE是个综合的NLP任务集合,包含各种类型的任务,因为ensemble模式里面包含了各种花式的trick,所以重点看上面一组实验,这里比较单纯。从实验数据看,XLNet相对Bert也有性能提升,当然不像阅读理解提升那么大,而且性能提升比较大的集中在RTE,MNLI和COLA数据集合,其它任务提升效果还好。
当然,仍然不确定这种性能提升主要来自于XLNet的哪个因素,或者哪几个因素各自的贡献,尤其是如果Bert加大预训练数据规模后,两者性能差异有多大。感觉这里Transformer XL的因素可能发挥的作用不会太大,其它两个因素在起作用,但是作用未知,这里感觉应该补充其它实验。
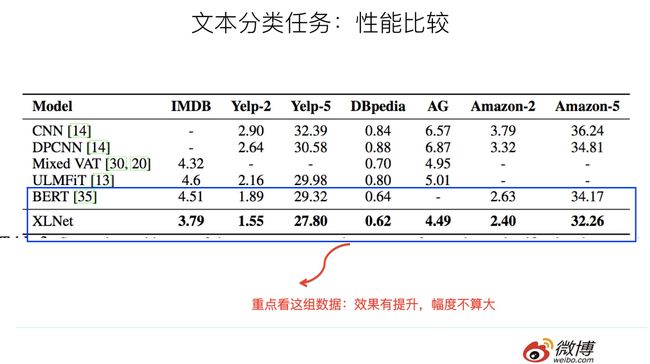
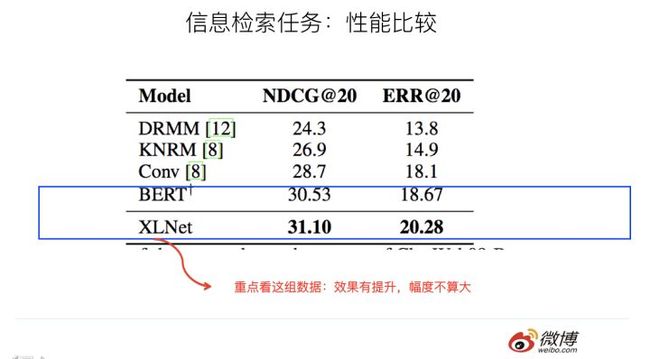
上面是文本分类任务和信息检索任务,可以看出,相对Bert,XLNet效果有提升,但是幅度不算大。仍然是上面的考虑,起作用的三个因素,到底哪个发挥多大作用,从数据方面看不太出来。
下面一组实验可以仔细分析一下,这组实验是排除掉上述第三个数据规模因素的实验的对比,就是说XLNet用的是和Bert相同规模的预训练数据,所以与Bert对比更具备模型方面的可比较性,而没有数据规模的影响。实验结果如下:
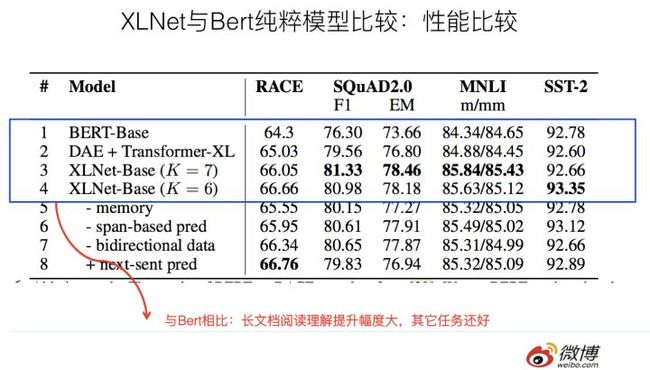
如果仔细分析实验数据,实验结果说明:
因为和Bert比较,XLNet使用相同的预训练数据。所以两者的性能差异来自于:Permutation Language Model预训练目标以及Transformer XL的长文档因素。而从中可以看出,DAE+Transformer XL体现的是长文档因素的差异,和Bert比,Race提升1个点,SQuAD F1提升3个点,MNLI提升0.5个点,SST-2性能稍微下降。这是Transformer XL因素解决长文档因素带来的收益,很明显,长文档阅读理解任务提升比较明显,其它任务提升不太明显。
而通过XLNet进一步和DAE+Transformer XL及Bert比,这一点应该拆解出Permutation Language Model和Mask的方式差异。可以看出:XLNet相对DAE+Transformer XL来说,Race进一步提升1个点左右;SQuAD进一步提升1.8个点左右,NMLI提升1个点左右,SST-B提升不到1个点。虽然不精准,但是大致是能说明问题的,这个应该大致是PLM带来的模型收益。可以看出,PLM还是普遍有效的,但是提升幅度并非特别巨大。
如果我们结合前面Race和SQuAD的实验结果看(上面两组实验是三个因素的作用,后面是排除掉数据量差异的结果,所以两者的差距,很可能就是第三个因素:数据规模导致的差异,当然,因为一个是Bert_base,一个是Bert_Large,所以不具备完全可比性,但是大致估计不会偏离真实结论太远),Race数据集合三因素同时具备的XLNet,超过Bert绝对值大约9个多百分点,Transformer因素+PLM因素估计贡献大约在2到4个点之间,那么意味着预训练数据量导致的差异大概在4到5个点左右;类似的,可以看出,SQuAD 2.0中,预训练数据量导致的差异大约在2到3个点左右,也就是说,估计训练数据量带来的提升,在阅读理解任务中大约占比30%到40%左右。
如果从实验结果归纳一下的话,可以看出:XLNet综合而言,效果是优于Bert的,尤其是在长文档类型任务,效果提升明显。如果进一步拆解的话,因为对比实验不足,只能做个粗略的结论:预训练数据量的提升,大概带来30%左右的性能提升,其它两个模型因素带来剩余的大约70%的性能提升。当然,这个主要指的是XLNet性能提升比较明显的阅读理解类任务而言。对于其它类型任务,感觉Transformer XL的因素贡献估计不会太大,主要应该是其它两个因素在起作用。
3 XLNet对nlp应用任务的影响
- 对于Bert长文档的应用,因为Transformer天然对长文档任务处理有弱点,所以XLNet对于长文档NLP任务相比Bert应该有直接且比较明显的性能提升作用,它在论文中也证明了这点。所以,以后长文档类型的NLP应用,XLNet明显跟Bert比占优势。当然,你说我把Transformer XL的因素引入Bert,然后继续在Bert上做改进,明显这也是可以的。
- 对于生成类的NLP任务,到目前为止,尽管出了一些改进模型,但是从效果看,Bert仍然不能很好地处理。而因为XLNet的预训练模式天然符合下游任务序列生成结果,所以按理说能够直接通过引入XLNet来改进生成类NLP任务的效果。所以,这点估计是XLNet会明显占优势的一个领域。
- 可以预计的是,很快我们就会看到XLNet在文本摘要,机器翻译,信息检索…..等符合上述XLNet应用领域特点和优势领域的应用结果,以及在这些任务上的进一步改进模型。当然,这个有点比手速的意思,有意者请尽快动手把结果扔出来。
https_zhuanlan.zhihu.com/?url=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F70257427