树莓派人脸表情识别中期报告
目录
绪论
深度学习背景
paddle-数据集的选择
paddle-表情分类模型的选择
Paddle训练流程及结果
创建项目,挂载数据集
环境导入
os模块
numpy模块
pandas模块
matplotlib.pyplot
matplotlib.image
cv2
加载数据集
数据标注
数据集的定义及对数据的预处理
实例化数据集类
模型训练与优化
模型保存与预测
预测结果
部署流程及结果
部署模型保存
准备环境
准备PaddleLite推理库
linux基本操作
部署代码
结果与问题
总结与展望
中期成果总结
疑问
目标和展望
绪论
笔者由于种种原因,选择可以识别人脸情绪的智能眼镜作为暑期实习项目, 本项目选择运行终端为树莓派3B,以能够识别3种情绪以上、准确率为0.8以上为目标。初看本项目觉得十分困难,难以入手,涉及人工智能与嵌入式,以及边缘计算的知识,在老师的帮助下,一步步选择开发平台与工具进行学习,到中期已经可以有基础的结果。现将学习过程用中期报告的形式完整记录下来,便于笔者积累经验,后期查阅。
| 各阶段任务 | 起止日期 |
| 了解相关背景知识,看教学视频 | 2021.0628-2021.0711 |
| 选择训练模型,训练最优参数 | 2021.0712-2021.0725 |
| 部署,中期报告 |
2021.0726-2021.0808 |
| 优化 | 2021.0809-2021.0820 |
| 总结报告,准备答辩 | 2021.0823-2021.0903 |
深度学习背景
现在主流的深度学习框架有 TensorFlow、Torch 、Caffe、Theano、keras等,具体理解为我们在写代码时的import caffe, import tensorflow。这些深度学习框架降低了使用人工智能的门槛,开发者不再需要从复杂的神经网络开始编写代码,而是用现有的模型与函数来训练自己的最优模型参数,在工程实践上十分的高效。百度开发的开源深度学习框架PaddlePaddle拥有自己的高层API,有着直接在浏览器上运行、可选cpu或gpu模式、安装简便、丰富的开源资源、训练过程可视化以及EasyDL可直接生成最优模型的一些优点,同时为了学习与支持国产新技术,本项目选用PaddlePaddle,上手简单,方便高效。
paddle-数据集的选择
目前表情常用开源库,有以下几种:
KDEF与AKDEF(karolinska directed emotional faces)数据集,链接https://link.zhihu.com/?target=http%3A//www.emotionlab.se/kdef/
数据集创建用于心理和医学研究,使用柔和的光照,包含70个人,35个男性,35个女性,年龄在20至30岁之间。没有胡须,耳环或眼镜,且没有明显的化妆。7种不同的表情,每个表情有5个角度。总共4900张彩色图,尺寸为562*762像素。
RaFD数据集
链接:http://www.socsci.ru.nl:8180/RaFD2/RaFD?p=main
数据集包含20名白人男性成年人,19名白人女性成年人,4个白人男孩,6个白人女孩,18名摩洛哥男性成年人。总共8040张图,包含8种表情,5机位拍摄。
Fer2013数据集
链接: https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data
数据集包含26190张48*48灰度图,图片的分辨率比较低,共6种表情。
CelebFaces Attributes Dataset (CelebA)数据集
链接:https://link.zhihu.com/?target=http%3A//mmlab.ie.cuhk.edu.hk/projects/CelebA.htmlCelebA
数据集包含200k名人照片,背景和姿态等多样性很强。
考虑到表情分类的任务,笔者没有选择以上数据集,因为背景和姿态的杂乱,以及分辨率较低,笔者在paddlepaddle上找到一个数据集,为分辨率256*256的灰度图,且数量合理,1235张人脸7种表情,部分内容如下。
链接:https://aistudio.baidu.com/aistudio/datasetdetail/100127
paddle-表情分类模型的选择
LeNet,一个用于处理手写识别的卷积网络。
AlexNet,层数8,卷积层数5,全连接层数3,引入Relu作为激励函数对抗梯度消失,最大池化层3*3区分于LeNet2*2效果更好,引入dropout学习机制,随机抛弃全连接层的部分神经连接以减少过拟合。此后,神经网络向更深更宽两个方向调优。
VGG,层数19,卷积层数16,全连接层数3,证明使用小卷积核,增加网络深度对于提升模型效果的有效性,有较好的*泛化能力(能够对未知的数据集也有较好的拟合效果。)但是参数很大,运算慢。
GoogLeNet ,层数22,卷积层数21,全连接层1,向LeNet致敬,引入了Inception模块,添加了辅助子loss单元,将loss加权,做反向传播,防止梯度消失,最后的全连接层使用平均池化层,前者对输入图像的大小有约束,后者则无。
ResNet ,层数152,卷积层数151,全连接层1,网络更深才会有更灵活的模拟能力,引入残差结构解决退化问题,也就是几层之后的feature map和之前的feature map作和,防止梯度消失和爆炸。
在学习Paddle的使用过程中,十二生肖例子使用了ResNet网络,运行时间极其的长,并且考虑到终端树莓派的内存限制,我们使用的网络及生成的模型自然是越小越好,那么必然层数就不能太高。在另一个示例柠檬分类中,网络的层数很少,既然它也是用于分类的,那么我们可以尝试用它来进行模型的训练。
network = paddle.nn.Sequential(
paddle.nn.Conv2D(3, 16 ,3),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2),
paddle.nn.Conv2D(16, 32, 3),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2),
paddle.nn.Conv2D(32, 64 ,3),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2),
paddle.nn.Conv2D(64, 32, 3),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2),
paddle.nn.Flatten(),
paddle.nn.Linear(6272, 7),
)Paddle训练流程及结果
创建项目,挂载数据集
环境导入
#环境导入
import os #对目录和文件进行读取及其他操作
import numpy as np #矩阵计算的函数库
import pandas as pd #数据分析包
import matplotlib.pyplot as plt #绘图模块
import matplotlib.image as mpimg #图像基本操作模块,转换,通道等
import cv2 #图像处理库
import paddle
import warnings
warnings.filterwarnings('ignore') # 忽略 warningos模块
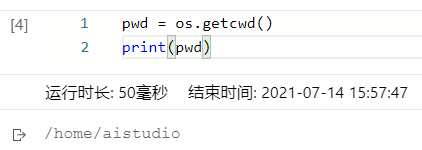
os.getcwd()函数,获取当前目录,工作目
os.name 函数,获取当前使用的操作系统,其中 'nt' 是 windows,'posix' 是 linux 或者 unix
os.remove()函数,删除指定文件, os.remove('file.txt')
os.removedirs()函数,删除指定目录,os.removedirs('file')
os.system()函数,运行shell命令。
os.mkdir()函数,创建一个新目录
os.chdir()函数,改变当前路径到指定路径,os.chdir('/home')
os.listdir()函数,返回指定目录下的所有目录和文件
numpy模块
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
pandas模块
python的一个数据分析包,提供了大量能使我们快速便捷地处理数据的函数和方法。
matplotlib.pyplot
绘图与显示图像模块。
matplotlib.image
也是对图像的一些操作,比如颜色转换。
cv2
计算机视觉,图像处理库。
加载数据集
!unzip -q -o data/data100127/images.zip
//如果上传压缩包为其他名字,替换掉images.zip即可
#查看挂载数据集
!ls /home/aistudio/data
结果 data100127,即为我们上传的images.zip数据标注
# 数据集根目录
DATA_ROOT = '/home/aistudio'
# 标签List
LABEL_MAP = get('LABEL_MAP') #get标签集的路径
# 标注生成函数
def generate_annotation(mode):
# 建立标注文件
with open('{}/{}.txt'.format(DATA_ROOT, mode), 'w') as f: #创建对应于mode的标注文件
# 对应每个用途的数据文件夹,train/valid/test
train_dir = '{}/{}'.format(DATA_ROOT, mode) #用于下面函数的参数
# 遍历文件夹,获取里面的分类文件夹
for path in os.listdir(train_dir): #在train_dir路径下的子路径,一一遍历
# 标签对应的数字索引,实际标注的时候直接使用数字索引
label_index = LABEL_MAP.index(path) #子路径7个分类,即1到7个子path,赋值给label_index
# 图像样本所在的路径
image_path = '{}/{}'.format(train_dir, path) #每个子路径分别在下面遍历一遍,如果没有这个变量,不好区分7条子路径的图像
# 遍历所有图像
for image in os.listdir(image_path): #遍历这个子路径的图像
# 图像完整路径和名称
image_file = '{}/{}'.format(image_path, image) #每张图像重新命名(排序命名)
try:
# 验证图片格式是否ok
with open(image_file, 'rb') as f_img: #二进制格式打开图片
image = Image.open(io.BytesIO(f_img.read()))
image.load()
f.write('{}\t{}\n'.format(image_file, label_index)) #将图像放入子路径
except:
continue
generate_annotation('train') # 生成训练集标注文件
generate_annotation('test') # 生成测试集标注文件数据集的定义及对数据的预处理
import paddle.vision.transforms as T
__all__ = ['FaceDataset']
# 定义图像的大小
image_shape = get('image_shape')
IMAGE_SIZE = (image_shape[1], image_shape[2])
print(IMAGE_SIZE)
class FaceDataset(paddle.io.Dataset):
"""
人脸表情数据集类的定义
"""
def __init__(self, mode='train'):
"""
初始化函数
"""
assert mode in ['train', 'test'], 'mode is one of train, test.' #判断参数合法性
self.data = []
"""
根据不同模式选择不同的数据标注文件
"""
with open('./{}.txt'.format(mode)) as f:
for line in f.readlines():
info = line.strip().split('\t')
if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])##切分成数组,每个数组包含图像的地址和labe
if mode == 'train':
self.transforms = T.Compose([
T.Resize(256), # 图像大小修改
# T.RandomCrop(IMAGE_SIZE), # 随机裁剪
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.515, 0.515, 0.515], std=[0.264, 0.264, 0.264]) # 图像归一化
])
else:
self.transforms = T.Compose([
T.Resize(256), # 图像大小修改
# T.RandomCrop(IMAGE_SIZE), # 随机裁剪
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.515, 0.515, 0.515], std=[0.264, 0.264, 0.264]) # 图像归一化
])
def __getitem__(self, index):
"""
根据索引获取单个样本
"""
image_file, label = self.data[index]
image = Image.open(image_file)
if image.mode != 'RGB':
image = image.convert('RGB')
image = self.transforms(image) ##得到预处理后的结果
return image, np.array(label, dtype='int64') ##label要将int类型转成numpy
def __len__(self):
"""
获取样本总数
"""
return len(self.data)实例化数据集类
train_dataset = FaceDataset(mode='train')
valid_dataset = FaceDataset(mode='test')
模型训练与优化
#优化函数
def create_optim(parameters):
step_each_epoch = get('total_images') // get('batch_size')
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=get('LEARNING_RATE.params.lr'),
T_max=step_each_epoch * EPOCHS)
return paddle.optimizer.Momentum(learning_rate=lr,
parameters=parameters,
weight_decay=paddle.regularizer.L2Decay(get('OPTIMIZER.regularizer.factor'))) #正则化来提升精度
# 模型训练配置
model.prepare(create_optim(network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy()) # 评估指标
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
paddle.set_device('cpu')
time1 = time.clock()
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
valid_dataset, # 评估数据集
epochs=EPOCHS, # 总的训练轮次
batch_size=BATCH_SIZE, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
save_dir='./chk_points/', # 分阶段的训练模型存储路径
callbacks=[visualdl]) # 回调函数使用
print(time1, "seconds process time!")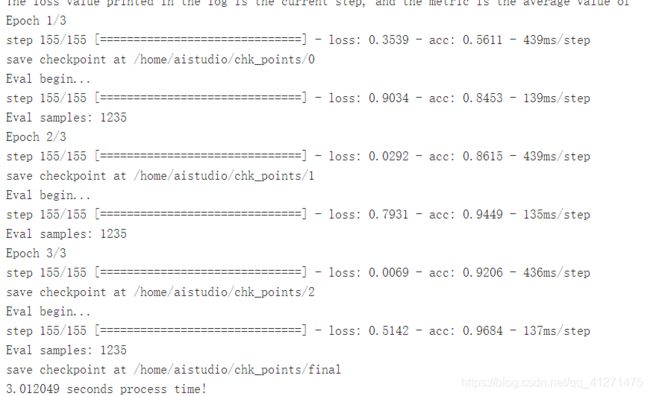
准确率0.9684,loss0.5142小于1,模型良好。
模型保存与预测
model.save('ouput_model') //模型存储
# 模型封装
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')])
# 训练好的模型加载
model_2.load('ouput_model')
# 模型配置
model_2.prepare()
# 执行预测
result = model_2.predict(predict_dataset)预测结果

预测了6张图片都是正确的。
部署流程及结果
部署模型保存
- 使用opt工具将Paddle模型转化成Paddle Lite nb模型 这里已经将opt工具作为数据集形式上传到了Notebook中,只需执行如下代码即可完成模型转化。
!pip install paddlelite==2.9
!paddle_lite_opt --model_file=output.pdmodel --param_file=output.pdiparams --optimize_out==face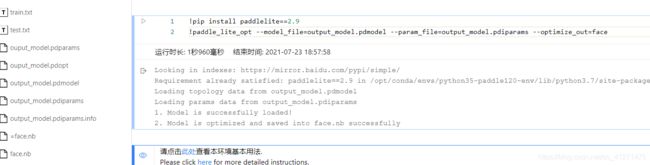
准备环境
- C++准备环境:
主要安装OpenCV3.2.0(推荐3.2)与CMake3.10
sudo apt-get update sudo apt-get install gcc g++ make wget unzip libopencv-dev pkg-config wget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gz tar -zxvf cmake-3.10.3.tar.gz cd cmake-3.10.3 ./configure make sudo make install
也可以选择python部署,但是C++运算速度会更快些。
准备PaddleLite推理库
树莓派3blinux32位使用如下推理库,extra.tar含有模型的flatten算子。
下载网址:https://github.com/PaddlePaddle/Paddle-Lite/releases/

uname -a 命令可知系统位数。
下载下来如图

linux基本操作
pwd //现在所在目录
ls //当前目录查看
ls -la //listall,全部文件列出来
tree xxx/ //将xxx文件夹以树结构展开内容(相对路径)
cd 路径 //去某个文件夹(路径)
cd - //回到上一个目录
cd ../ //当前目录的上一层目录
cd /xxxs //进入xxxs目录下
cd //回到家目录 = cd ~
mkdir //创建文件夹
alias xxx = 'xxxxxxx' //简化操作,本次登录生效
vim .zshrc //文件中写入上式,则永久生效
vim //文本编辑器,打开一个文件
vim a.c //不存在则创建一个a.c文件
/xxx //在vim普通模式下查询xxx, n-next,N-last
yy //yank,vim普通模式下粘贴
p //paste,vim普通模式下粘贴
2yy //复制两行
2dd //删除两行
G //vim普通模式下跳到最后一行
gg //跳到第一行
dG //从当前删除到最后一行
x //删除单个字符
: //vim中进入命令模式, set paste可忽略复制格式
i //小写i进入编辑模式,小写o跳到下一行
: visplit //命令模式下左右分屏,control+w切换分屏
:q //命令模式下退出文件编辑,会询问是否保存
:wq //命令模式下保存并退出文件编辑
:q! //直接退出不保存不询问
esc //退出命令模式
man //查询 man vim查询vim用法(which是另一种查询)
man -f vim //查询vim所在章节(7个)
man 3 printf //查询3章节中的printf
man -k printf //查询带有printf的函数,比如asprintf
tldr //too long dont read,简版man手册,需下载
sudo apt upgrate
sudo apt install tldr部署代码
其他需要的文件及代码如下图
images文件夹存放用来预测的图片:
models文件夹存放我们在aistudio最后保存的nb文件,模型参数文件及模型框架文件:
lable.txt用来存放预测标签:
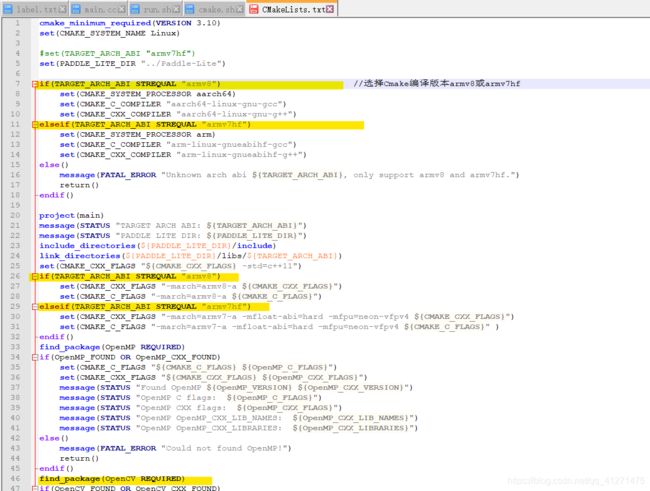
CMakeLists.txt 配置编译版本:
cmake.sh执行文件,执行语句 sh cmake.sh,包括一些命令,会生成一个build文件夹:
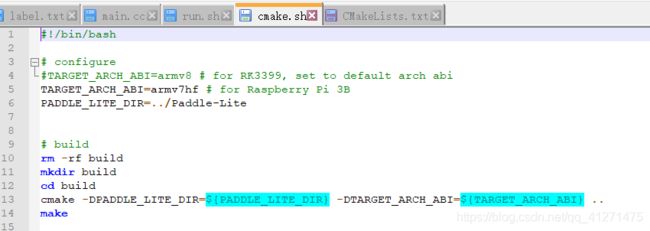 第六行输入Paddle-Lite路径。
第六行输入Paddle-Lite路径。
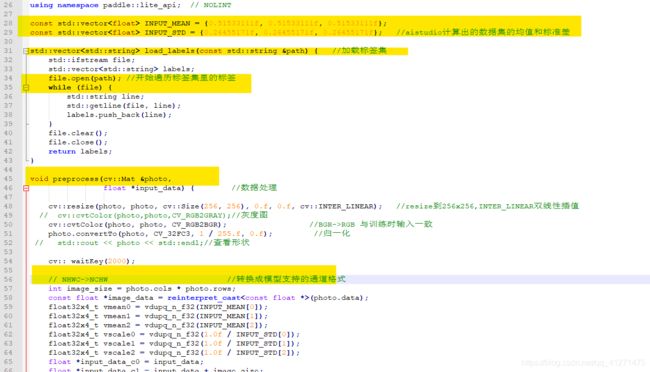
main.cc文件,处理图像,执行预测,照片或摄像头模式:
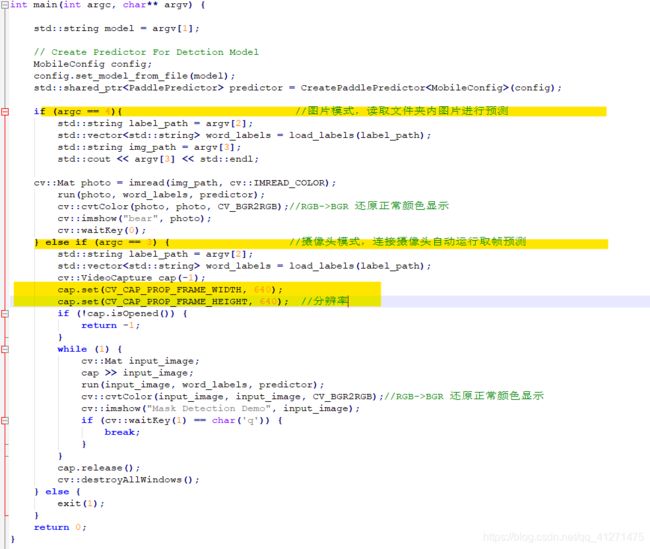
run.sh文件,填写预测图片的名字,一一对应:
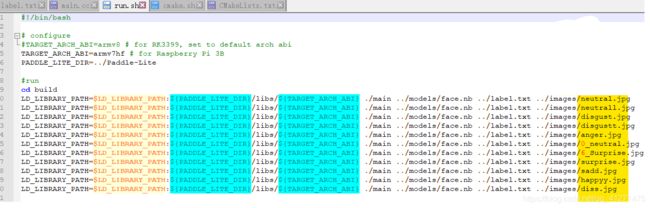 执行sh cmake.sh 后执行sh run.sh,即可得到运行结果,注意main.cc文件每次有改动后都要重新sh cmake.sh一下。
执行sh cmake.sh 后执行sh run.sh,即可得到运行结果,注意main.cc文件每次有改动后都要重新sh cmake.sh一下。
结果与问题
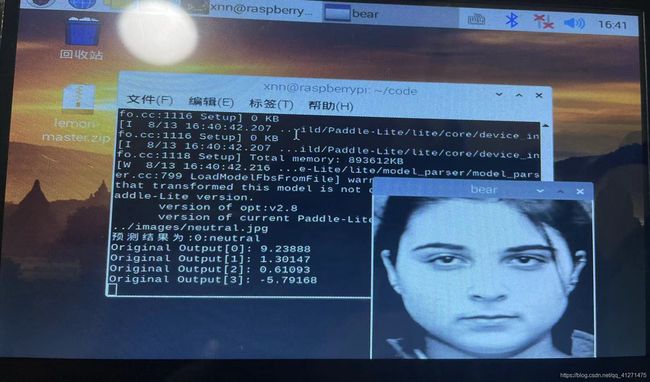
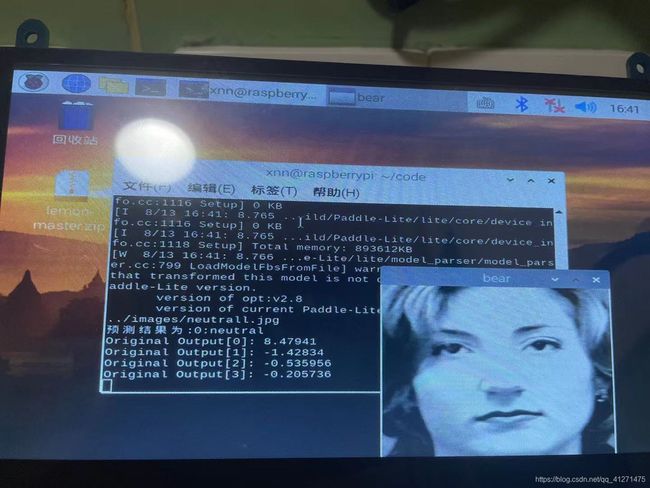
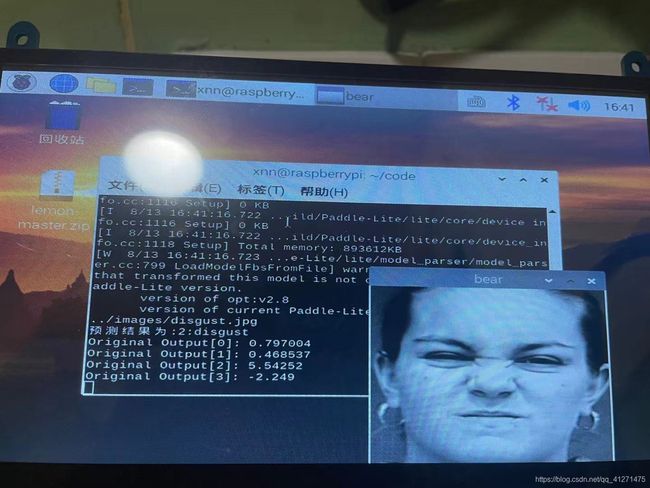
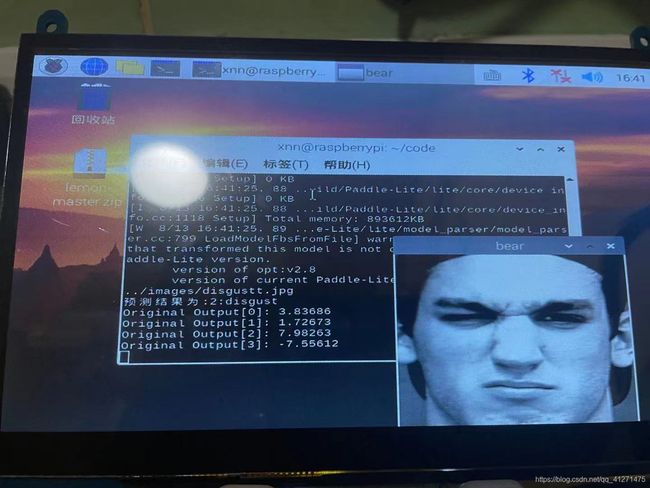
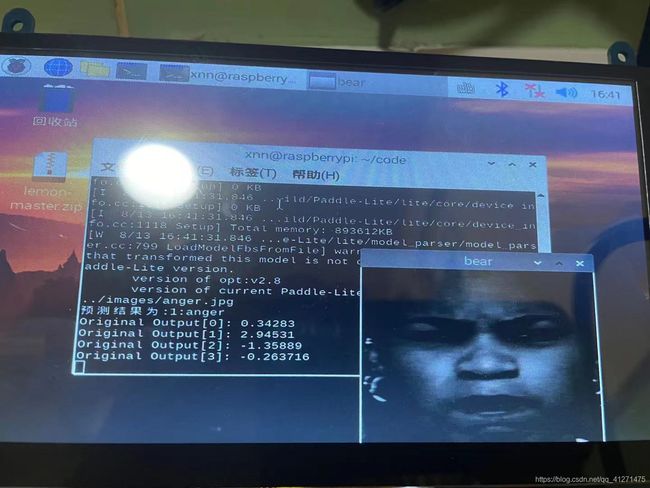
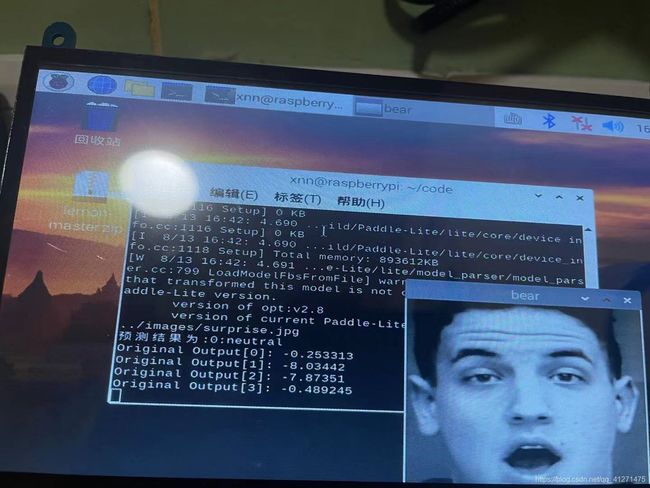
在paddle平台上随机选择了6张图片预测都是正确的,然而在树莓派端运行却有一张是预测错误的,另外使用手机拍摄的我的照片预测也是不准确的。使用摄像头实时预测的结果也是很糟糕。
这也是因为数据集的内容并不具有背景和角度的多样性,与老师交流后决定再添加一个人脸检测的模型,这样表情分类的模型就只用判断人脸检测框出来的人脸部分了。
总结与展望
中期成果总结
在老师、学弟还有百度paddle平台的帮助下,完成了在paddle上人脸表情识别的任务,并离线部署在了树莓派上,学到了树莓派的操作知识以及嵌入式AI的流程,受益匪浅,为接下来的学习做了铺垫。
疑问
树莓派实现了离线智能预测的功能,具体想要实现智能识别情绪的眼镜,是不是有两种思路,一种需要相比树莓派组件更小的芯片、摄像头和显示屏,另一种则是边缘计算,虽然在EasyDL公开课上了解到了百度的一些边缘计算的硬件,比如药物分类、智能垃圾分类,但是对边缘计算的概念还是很模糊,老师讲过智能手表就是一种边缘计算,手表用来向服务器传输一些信息,服务器处理后传输回智能手表,手表再实现一个显示的功能,虽然手表只是摄像头或者传感器读取了一个数据,然后显示屏显示了一个数据,但是还是在联网状态下的。相比第一种思路,是不是边缘计算无法实现离线呢。
目标和展望
这几天在尝试将EasyDL上训练出来的一个人类检测的模型部署在树莓派上,因为看不懂Cmake文件,困难多多,因为路径问题,报错日志都是空白的。
接下来要学习Cmake的知识,尽力将这个模型也添加到我们的项目中。
深度学习分类网络的发展历史 - 窗户 - 博客园 (cnblogs.com)