轻量化微调 Parameter-Efficient Fine-Tuning
导读
近年来,大规模预训练模型在自然语言处理任务上取得了巨大的成功。对预先训练好的语言模型进行微调是目前自然语言处理任务中的普遍范式,在许多下游任务上表现出了极好的性能。全参数微调,即对模型的所有参数进行训练,是目前将预训练模型应用到下游任务的最通用方法。
然而,全微调的一大弊病是对于每一个任务,模型均需要保留一份大规模的参数备份,在下游任务量很大时这种做法会相当昂贵。在预训练模型越来越大,不断逼近到千亿甚至万亿参数规模时,这种问题会被无限放大。
轻量化微调(Parameter-Efficient Fine-Tuning)应运而生,轻量化微调主要着眼于微调整个模型的少部分参数,并设法通过微调少部分参数在下游任务上得到接近全微调的性能,并解决上游任务与下游任务输入输出间可能存在的结构偏差问题。笔者整理了轻量化微调方向的经典论文以及近两年的最新进展,论文主要包含近年的主流轻量化微调方法,新型轻量化微调方法,轻量化微调应用以及统一的轻量化微调框架,欢迎大家批评和交流。
论文列表
1、Parameter-Efficient Transfer Learning for NLP Adapter(ICML 2019)
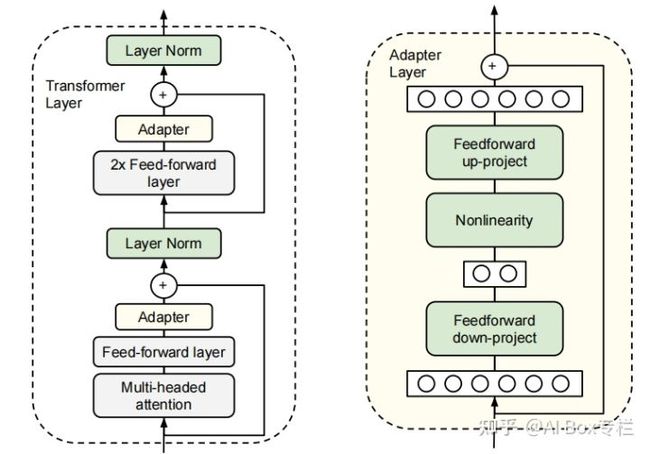
这项工作第一次提出了Adapter方法。在对预训练模型进行微调时,我们可以冻结在保留原模型参数的情况下对已有结构添加一些额外参数,对该部分参数进行训练从而达到微调的效果。作者采用Bert作为实验模型,在每个Transformer Block的Attention层以及两个全连接层后增加了一个Adapter结构,其总体结构如下:
Adapter结构有两个特点:较少的参数和在初始化时与原结构相似的输出。在实际微调时,由于采用了down-project与up-project的架构,在进行微调时,Adapter会先将特征输入通过down-project映射到较低维度,再通过up-project映射回高维度,从而减少参数量。Adapter-Tuning只需要训练原模型0.5%-8%的参数量,若对于不同的下游任务进行微调,只需要对不同的任务保留少量Adapter结构的参数即可。由于Adapter中存在残差连接结构,采用合适的小参数去初始化Adapter就可以使其几乎保持原有的输出,使得模型在添加额外结构的情况下仍然能在训练的初始阶段表现良好。在GLUE测试集上,Adapter用了更少量的参数达到了与传统迁移学习方法接近的效果。
2、Prefix-Tuning: Optimizing Continuous Prompts for Generation(ACL 2021)
本文是斯坦福大学在ACL2021的一篇工作。作者提出了一种前缀微调的方法,与GPT-3通过自然语言指令提示模型生成输出的Prompting方法不同的是,作者采用连续的任务相关向量作为输入前缀,在微调时不训练模型参数,只训练这些前缀向量,并利用这些连续可训练的Prefix Embedding提示模型生成正确的输出。下图是该方法分别在自回归模型和编码器-解码器模型中的表示:

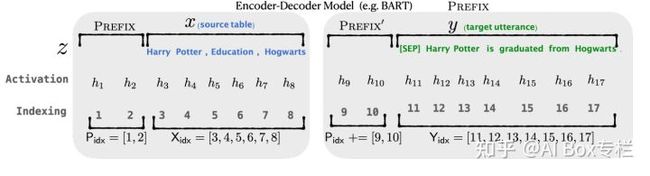
在训练时,Prefix-Tuning的优化目标与正常微调相同,但只需要更新前缀向量的参数。作者发现直接更新前缀向量的参数会导致训练的不稳定与结果的略微下降,因此采用了重参数化的方法,通过一个若干较小的前缀向量经过单层MLP生成正常规模的前缀向量,其形式化表示如下:
![]()
训练完后,用于重参数化的较小前缀向量会被丢弃,只保留目标前缀向量的参数。
作者采用了Table-To-Text与Summarization作为实验任务,在Table-To-Text任务上,Prefix-Tuning在优化相同参数的情况下结果大幅优于Adapter,并与全参数微调几乎相同。而在Summarization任务上,Prefix-Tuning方法在使用2%参数与0.1%参数时略微差于全参数微调,但仍优于Adapter微调。
3、GPT Understands, Too(Arxiv 2021.3.18)
本文提出了P-tuning方法,通过自动的搜索方法在连续空间中搜索合适的Prompt向量,并弥合了GPT模型与自然语言理解任务之间的差距。类似Prefix-Tuning,P-tuning也采用连续的可训练向量作为预训练模型输入,并通过梯度下降方法优化Prompt向量。
与Prefix-Tuning不同的是,P-tuning并不仅仅将Prompt安置在输入的前缀部分,而是采用合适的Template去对模型进行提示,并通过梯度下降训练连续的Prompt表示去得到最佳的Prompting效果。其结构如下所示:
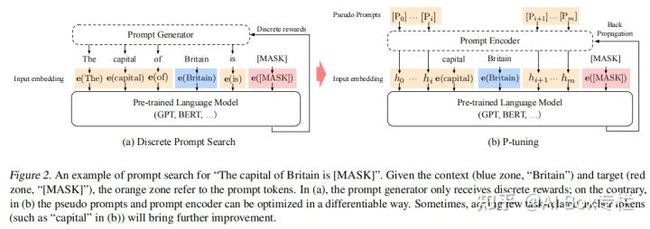
如果对各个prompt向量采用随机初始化,由于理想的目标向量(即左图中的离散prompt)在预训练后已经变得高度离散化了,在采用梯度下降的优化时很容易陷入局部最优。同时作者认为直觉上prompt embeddings(即右图中的连续prompt)应该是相互依赖的,需要采用一些方法来增加prompt之间的相关性。因此作者使用了一个由双向LSTM与双层MLP组成的Prompt Encoder进行映射,形式化表示如下所示:
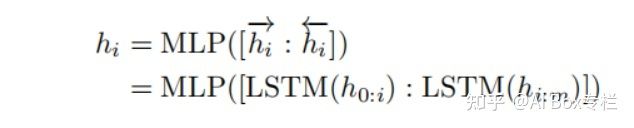
作者在两个自然语言理解数据集:LAMA knowledge probing和SuperGlue上进行了测试,并取得了接近甚至优于BERT的效果。同时作者通过实验说明了P-tuning的方法也可以帮助BERT在相关任务上有所提升。
4、The Power of Scale for Parameter-Efficient Prompt Tuning(EMNLP 2021)
本文是谷歌在EMNLP 2021上的一篇工作,这篇工作延续了Prompt-Tuning的思想,采用连续的Soft Prompt进行训练,并冻结了模型的其他所有参数。与Prefix-Tuning与P-Tuning不同的是,作者没有采用任何的Prompt映射层(即Prefix-Tuning中的重参数化层与P-Tuning中的Prompt Encoder),而是直接对Prompt Token对应的Embedding进行了训练。
作者采用T5模型作为实验backbone,并将所有的任务均重新建模为text-to-text的生成任务。T5采用了Span Corruption,恢复被打乱或是被masked的句子,这样会导致模型的输入输出均是不是自然的语言文本,使得少量参数的Prompt-Tuning方法无法弥合预训练任务和下游任务之间的差距。由此,作者针对T5做了以下改动。
- 直接采用Span Corruption进行下游任务的测试
- 采用Span Corruption,但在输入文本前加上任务相关的Sentinel前缀
- 对T5继续进行一小段时间的监督训练,但采用LM的训练目标,即给定一段文本前缀,并根据前缀文本生成符合自然语言的后续文本。这样是为了使得T5能够有一定的输出自然语言的能力。
作者在SuperGlue测试集上进行了实验,其实验结果如下:
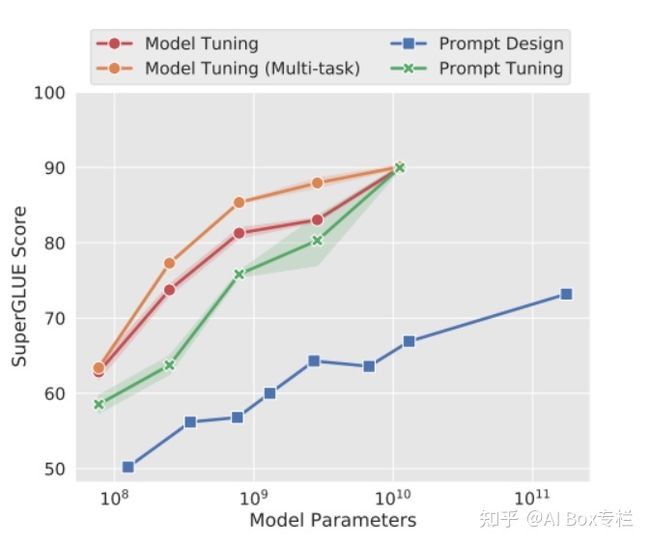
可以看到,随着模型规模的增大,Prompt-Tuning的效果不断接近,在参数量足够大时几乎与Model-Tuning的效果一致,且在任意模型规模下都显著优于人工设计离散的Prompting方法。
5、LoRA Low-Rank Adaptation of Large Language Models(ICLR 2022)
本文是微软在ICLR2022上投稿的一篇工作。作者提出了一种基于一种新的基于低秩矩阵优化的微调方法LoRA,可以在下游任务微调时将训练参数量减少到接近原来的万分之一,并几乎不会伤害到预训练模型在下游任务上的性能。
文章首先指出了此前的轻量化微调方法的不足。对于Adapter-Tuning方法,由于在模型中添加了额外的结构,尽管Adapter采用了Down-Project与Up-Project的方法减少参数量,多余的结构仍会拖慢模型在进行推理时的速度。对于Prompt-Tuning方法,Prompt的训练常常是不稳定的,同时在输入序列中添加Prompt Token也会一定程度上降低输入的有效序列长度,从而影响到模型性能。
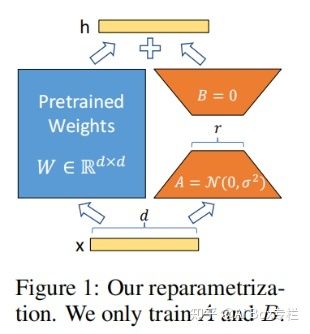
LoRA通过对矩阵的“低秩参数”进行优化克服了以上问题。神经网络通常包含大量的全连接层,并通过执行矩阵乘法来完成前向传播。这些全连接层中的参数矩阵往往是满秩的,[1]证明了预训练语言模型的参数中往往有一个较低的“本质维度”,即使待优化的参数矩阵被映射到一个较小的子空间内也能保持优秀的学习能力。在这样的前提下,作者希望只对参数矩阵中低秩的部分进行优化,并将原矩阵的优化过程表示成一个低秩矩阵的优化过程:
![]()
这样,我们可以将前向传播过程表示成以下形式:

其中,A,B是低维的矩阵。采用这样的变换后,待优化的参数规模就从原本的参数规模变成了低维矩阵的参数规模,大大减少了参数量。作者在实验过程中,用零矩阵初始化B,而用一个随机的高斯分布初始化A。整个流程如下:
作者使用LoRA分别在RoBERTa,DeBERTa,GPT-2与GPT-3上分别做了实验。LoRA在只使用极少数参数的情况下取得了接近全参数微调的结果。在1750亿参数的GPT-3上,LoRA只优化了3770万参数,即在WikiSQL,MNLI-m和SAMSum数据集上取得了超过全参数微调的效果,证明了该方法的正确性。
6、Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators(ACL 2021)
这篇工作提出了一种新型的模型压缩与轻量化微调方案-MPOP。MPOP的思想来自于物理上量子多体问题中的MPO分解方法。给定一个矩阵,MPO分解可以将矩阵表示为若干个张量的乘积,如下所示:
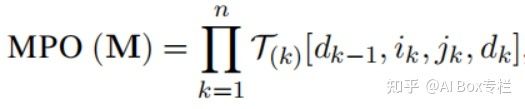
基于这种方法,我们可以对参数矩阵进行分解,并将中间的张量定义为中间张量(central tensor),其余位置的张量定义为辅助张量(auxiliary tensors)。由于MPO分解的特性,中间张量的参数量远大于辅助张量,因此作者猜想中间张量存储着预训练模型的核心语言学信息,而对于下游任务的适应只需要训练低参数量的辅助张量即可,如下图所示:

除此之外,作者采用连接键截断的方式实现了对原始矩阵的低秩近似,并推算出重建原参数矩阵的误差上界,如下图所示:


最终,作者在ALBERT上采用GLUE数据集进行了实验,在微调参数量降低了91%的情况下,在除MNLI任务外均取得了超过全参数微调的结果。
7、Y-Tuning: An Efficient Tuning Paradigm for Large-Scale Pre-Trained Models via Label Representation Learning ACL2021(ACL 2022 ARR)
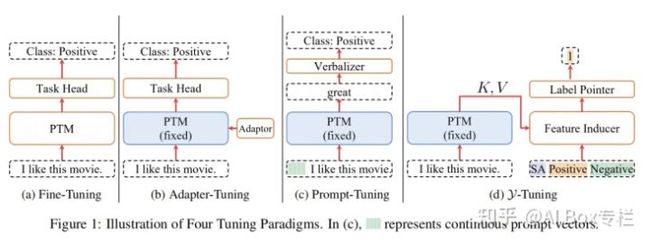
这项工作提出了一种基于标签的映射方法,与主流轻量化微调方法不同的是,Y-Tuning完全冻结了整个预训练模型,而在下游任务中对不同的下游任务学习通过标签映射学习到对应的标签特征。换言之,Y-Tuning完全不再进行feature-representation的学习,转而学习比one-hot更加复杂的label-representation。Y-Tuning的优势可以总结如下:
- 参数轻量化的:Y-Tuning只需要对最后的标签映射层进行训练,而不需要对预训练模型进行任何更新,训练的参数量大大减少。
- 训练轻量化的:预训练模型不需要记录任何梯度相关信息,大幅降低了时间和存储消耗。
- 推理轻量化的:推理过程中,所有不同任务的数据均可以通过一次前向传播得到其编码表示。
- 鲁棒的:预训练模型本身不会进行任何调整,因此很难通过下游任务的对抗数据去对模型进行攻击。
- 安全的:通过对标签进行编码隐藏了标签本身的信息,从而降低数据泄露的可能性。
Y-Tuning的架构如下:
作者使用BART和RoBERTA模型在GLUE数据集上进行了实验。实验表明Y-Tuning的效果相较传统的完全冻结预训练模型的方法有显著提升,且速度与全参数微调的方法有6倍以上的提升。但是最终的效果与全参数微调还是有一定的差距。
8、Composable Sparse Fine-Tuning for Cross-Lingual Transfer(ACL 2022 ARR)
本文是剑桥大学在2022ACL ARR上投稿的一篇工作,主要提出了一种基于lottery ticket假说的Sparse Fine-Tuning方法,在减少微调参数量的同时在跨语言任务迁移上取得了优于此前方法的效果。
Lottery-ticket假设在一个参数矩阵内,只有一小部分参数的更新对学习有帮助,这些参数就称为lottery ticket。本文采用的剪枝方法Lottery-ticket Sparse Fine-Tuning(LT-SFT)是指:在一轮训练后,按一定的比例通过一个mask对更新较小的参数进行剪枝,将它们恢复为原来的预训练权重,而保留其他更新较大的参数。最后经过多轮训练后,模型只有一小部分的参数真正得到了更新。
跨语言任务的迁移是也是通过LT-SFT完成的,对于某一目标语言语料,首先利用预训练MLM目标函数通过LT-SFT方法进行训练,得到对应的稀疏差异矩阵(即参数的更新量),称为Language SFT。对于某一任务,通过在源语言(通常是英语)上在对应的下游任务上采用LT-SFT进行训练,再次得到对应的差异矩阵,称为Task SFT。最终我们直接将这些SFT相加,即得到了一个跨语言迁移的模型,模型在目标语言上也得到了在源语言上进行下游任务的能力。整个模型的框架如下:

作者在四个下游任务上进行了实验:词性标注(POS),句法分析(DP),命名实体识别(NER)和自然语言推理(NLI)。作者在35种不同的语言(通常是数据集较少的不常见语种)上进行了训练,并且相比原来该任务的Baseline-基于Adapter的MAD-X方法有了很大的提升。
9、Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning(EMNLP 2021)
本文是EMNLP2021上的一篇工作。作者从参数更新的角度提出了一种基于子网络的Child-Tuning方法,通过仅更新原网络的部分参数来缓解大规模预训练模型在相对小规模的下游任务数据上训练时的过拟合问题,并相比传统微调方法有明显性能提高。
标准的全参数微调往往会存在不稳定和泛化性能差的问题,此前的工作已经证明了微调往往不需要对整个网络进行微调,而仅仅需要微调部分参数即可。Child-Tuning通过更新网络中的子网络来实现这一点。Child-Tuning首先会根据一定的策略找到参数矩阵中的子网络,并生成对应的掩码矩阵。在计算完梯度后,根据掩码只对自网络对应的参数进行更新,而其他参数保持不变。Child-Tuning方法与剪枝方法不同在于,它并不会使某个非自网络的参数失效,而只是停止对它的更新。因此Child-Tuning只在梯度反向传播时起作用,而在前向传播时不做任何改变,其方法可以表示为下图:
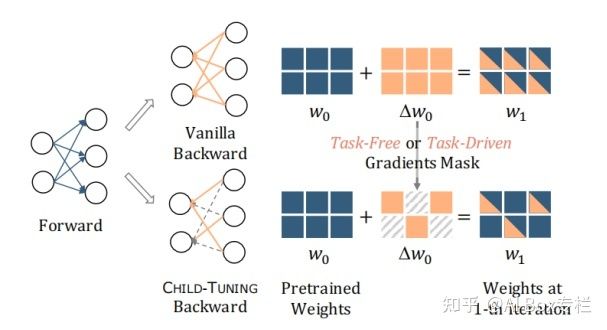
作者提出了两种Child-Tuning的变种:任务无关Child-Tuning-F与任务相关Child-Tuning-D。对于任务无关Child-Tuning-F,由于与下游任务无关,只需要通过采样伯努利分布得到一个随机的掩码矩阵即可。对于任务相关Child-Tuning-D,作者通过费希尔信息矩阵(FIM)来计算各个参数对下游任务的重要程度,并根据该策略调整每次迭代的掩码矩阵。
作者采用BERT-large, XLNet-large,RoBERTa-large和ELECTRA-large模型在GLUE的四个基准任务上进行了实验,Child-Tuning相较全参数微调方法都有提高,同时也提高了模型的泛化能力,说明了该方法的有效性。
10、Towards a Unified View of Parameter-Efficient Transfer Learning(ICLR 2022)
本文是CMU在ICLR2022上的一篇工作。作者主要探索了Prefix-Tuning,Adapter和LoRA方法,分析了这些目前主流的轻量化微调方法间的联系与差异,并将它们均视作去学习在模型中特定隐层状态的轻量化微调方法,并提出了一个统一的轻量化微调框架将这些方法进行了集成。
作者采用了对输入的计算过程来表示各个轻量化微调方法的差异,对于Adapter,它的计算过程如下:

其中h表示待修改的隐藏表征,而x表示子模块的直接输入。对于Prefix-Tuning方法,经过一系列的变换,Prefix-Tuning方法可以表示如下:

LoRA通过微调一个低秩的矩阵来达到轻量化微调的效果,它也可以表示成类似的形式:

经过上述分析,作者发现了三种方法之间的本质计算形式都是相似的,并可以将三种方式均表示成对模型隐状态的修改,并将这些方法统一在同一个框架内,如下图所示:

作者采用BART-Large的多语种模型变种mBART-Large和RoBERTa-Base分别在文档摘要,跨语种翻译,自然语言推理与情感分类数据集上进行了测试。最优的集成方案的效果要优于此前所有的轻量化微调方法,并且十分接近全参数微调的效果。
参考文献
[1] Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning.
[2] The Power of Scale for Parameter-Efficient Prompt Tuning
[3] Parameter-Efficient Transfer Learning for NLP Adapter
[4] The Power of Scale for Parameter-Efficient Prompt Tuning
[5] LoRA Low-Rank Adaptation of Large Language Models
[6] Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
[7] Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
[8] Towards a Unified View of Parameter-Efficient Transfer Learning
[9] Composable Sparse Fine-Tuning for Cross-Lingual Transfer