第二课 Flink 安装部署、环境配置及运行应用程序(1)
视频地址 【Apache Flink 入门教程】3. Flink 安装部署、环境配置及运行应用程序_哔哩哔哩_bilibiliApache Flink China 社区出品,Apache Flink 教程第二弹《Flink 安装部署、环境配置及运行应用程序》讲师:沙晟阳(阿里巴巴高级开发工程师), 视频播放量 18981、弹幕量 302、点赞数 114、投硬币枚数 43、收藏人数 218、转发人数 21, 视频作者 Apache_Flink, 作者简介 官方微信号:Ververica2019微信公众号:Apache Flink,相关视频:【尚硅谷】大数据Apache Doris教程(基于实际开发环境安装部署配置),『Git』知道这些就够了,尚硅谷Jenkins视频教程(从安装部署到环境搭建),大数据从入门到精通 完整版共1000节(上部),大数据自学精品教程Flink从入门到精通【大数据自学系列教程】,P6.Linux项目实训-搭建LAMP服务器(Apache安装、配置与测试),黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,全网首套基于Python语言的spark教程,Flink 1.13 从安装部署到项目实战【大数据自学系列——课堂实录】,环境搭建与配置 | Apache配置安装运行与解决端口占用问题,kafka和flink的入门到精通 https://www.bilibili.com/video/BV1wb41177T7
https://www.bilibili.com/video/BV1wb41177T7
这些内容基本是按照文档来走的,按照文档进行安装和运行,基本不会有什么错,一些问题自己解决一下就好了,然后总结下文档中的内容并记录中间出现的一些问题。
我下载的源码是1.15.1视频中有些出入,使用的运行环境是虚拟机Ubuntu 系统
Flink开发环境部署和配置
1、开发环境部署和配置
需要安装的环境有Java,Maven,Git其中至于用来干什么的应该不用细说,一般Java开发都是有这些环境其中需要注意的是Java版本需要Java8 或者Java8 以上 Maven版本需要使用Maven 3 推荐版本为Maven 3.2.5 (这是两年前的文档现在不一定适用,如果出现问题可以作为解决问题的思路)
在国内使用Maven 大家一般都修改镜像地址但是呢这次还要添加一个镜像具体信息如下
nexus-aliyun *,!jeecg,!jeecg-snapshots,!mapr-releases Nexus aliyun http://maven.aliyun.com/nexus/content/groups/public mapr-public mapr-releases mapr-releases https://maven.aliyun.com/repository/mapr-public
2、下载源码
去git上搜一下克隆下来或者直接下载zip包本地解压都行,文档中也给了地址
3、代码编译
在目录按需求执行下边命令
# 删除已有的 build,编译 flink binary
# 接着把 flink binary 安装在 maven 的 local repository(默认是~/.m2/repository)中
mvn clean install -DskipTests
# 另一种编译命令,相对于上面这个命令,主要的确保是:
# 不编译 tests、QA plugins 和 JavaDocs,因此编译要更快一些
mvn clean install -DskipTests -Dfast
# 删除已有的 build,编译 flink binary
mvn clean package -DskipTests
# 另一种编译命令,相对于上面这个命令,主要的确保是:
# 不编译 tests、QA plugins 和 JavaDocs,因此编译要更快一些
mvn clean package -DskipTests -Dfast
#如果你需要使用指定 hadoop 的版本,可以通过指定“-Dhadoop.version”来设置,编译命令如下:
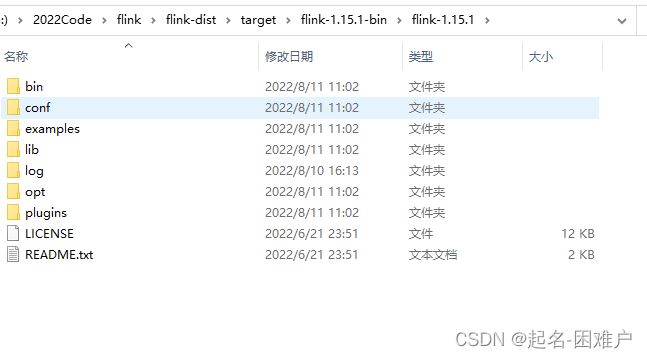
mvn clean install -DskipTests -Dhadoop.version=2.6.1成功以后可以在flink-dist/target/目录看到打包完毕的包和文件
4、开发环境准备
文档中指出
推荐使用 IntelliJ IDEA IDE 作为 Flink 的 IDE 工具。不建议使用 Eclipse IDE,主 要原因是 Eclipse 的 Scala IDE 和 Flink 用 scala 的不兼容。
具体安装IDEA就不说了,安装完IDEA以后还需要安装Scala plugin(file->settings->Plugins->搜Scala->install),检查Maven配置(file->settings->Build, Execution, Deployment -> Build Tools -> Maven)是否和你本来设置的一致包括Maven Home 位置、settingfile文件和local repository位置。接着导入代码就可,还需要添加代码风格检查包括Java和Scala的
Flink 在编译时会强制代码风格的检查,如果代码 风格不符合规范,可能会直接编译失败。对于需要在开源代码基础上做二次开发的同学,或者有 志于向社区贡献代码的同学来说,及早添加 checkstyle 并注意代码规范,能帮你节省不必要的修 改代码格式的时间。
5、点击试一试
导入代码以后需要maven install一下可能会花亿点点时间,耐心等待。
完成以后运行org.apache.flink.streaming.examples.windowing.WindowWordCount.java这个看看能不能成功,
这是一个统计单词的例子
运行Flink应用
1. 基本概念
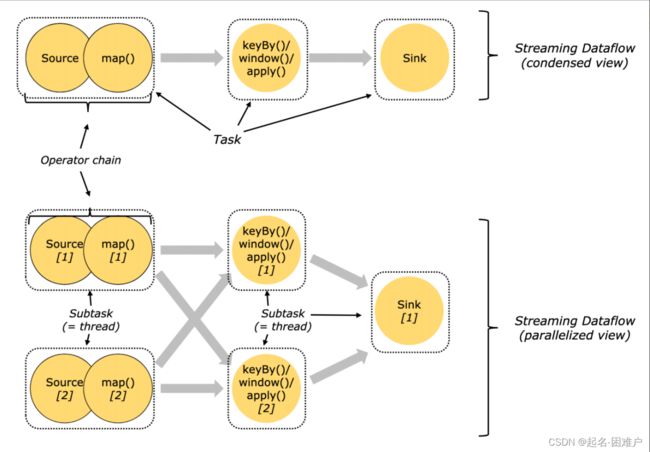
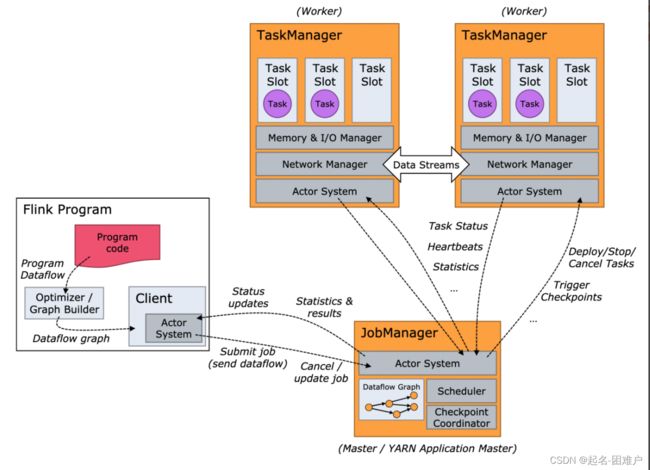
处理数据最小的单位是task(相当于是线程)主要分为三类,处理source map()的,进行keyBy()/window()/apply()的,sink的;(我的理解是三类数据源接收是一类,数据分析是一类,数据输出是一类,不知道对不对),但是整个系统的运行是需要管理程序来调配资源和分配任务去运行这些程序所以就需要设置Manager(管理者),但是到现在为止还是在单机上的假设,再扩充一点思维到多机 ,这个Manager功能就需要分级,因为我们任务管理需要一个统一任务管理员(Job Manager)去分配任务,子程序或者子机器接收到任务自己内部的Manager(TaskManager)处理就行了,所以我自己的理解就是
一个客户端发布一个job给JobManager 收到任务以后进行分解并把job分解为task发布给TaskManage,Task Manager收到task以后就分配给TaskSolt进行执行。并把运行状态报告给JobManager。当然他们的功能远比这要强大复杂,我这只是一个简单粗浅的理解。
2、运行环境的准备
Flink资源可以去下载也可以直接使用前边打包好的文件,前边说过我使用的是Ubuntu的虚拟机来执行的,需要把资源放入到虚拟机上,还有就是呢需要配置Java的环境变量版本要求和前边一样。
进到目录下执行./bin/start-cluster.sh
然后jps看看有没有启动StandaloneSessionClusterEntrypoint和TaskManagerRunner,有的话单机启动就完成了直接访问8081端口就能进入到管理页面
这里有三个注意点
1、因为我是使用远程访问的所以需要修改下配置才可以访问,修改conf/flink-conf.yaml 中的
rest.bind-address: 0.0.0.0
# The address that the REST & web server binds to # By default, this is localhost, which prevents the REST & web server from # being able to communicate outside of the machine/container it is running on. # # To enable this, set the bind address to one that has access to outside-facing # network interface, such as 0.0.0.0. # rest.bind-address: 0.0.0.02、start-cluster.sh可以多次启动,但是重复启动以后只能成功启动多个TaskManagerRunner并不会有多个StandaloneSessionClusterEntrypoint
3、由于使用的Flink版本有差异所以管理页面也是有一些差异的
4、提交一个 Word Count 的任务,命令如下:
./bin/flink run examples/streaming/WordCount.jar 可以在管理页面上查看相关信息
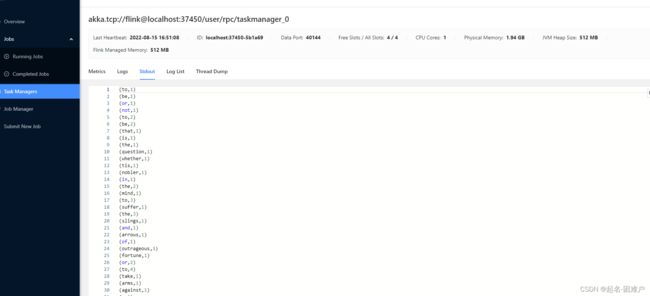
这个是管理页面直接看,而文件的位置在也可以找到
这个例子我们也可以使用自己本地文件作为数据输入
/bin/flink run examples/streaming/WordCount.jar --input ${your_source_file}然后就是一些启动配置的修改有一些内存设置、Task Manager数量的配置之类
5、日志查看和配置
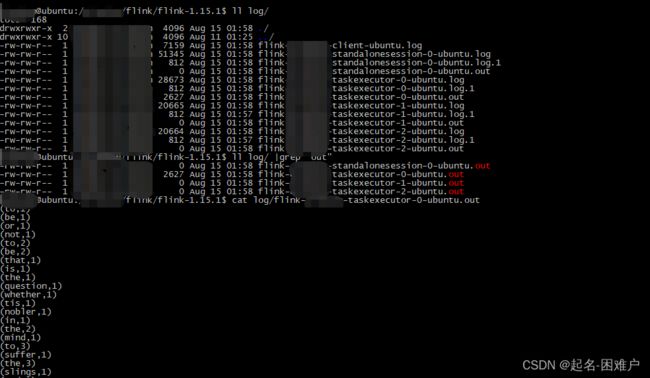
JobManager 和 TaskManager 的启动日志可以在 Flink 目录下的 log 子目录中找到,和前边的截图一样
log 目录中以“flink-${user}-standalonesession-${id}-${hostname}”为前缀的文件对应的即是 JobManager 的输出,其中有三个文件:
● flink-${user}-standalonesession-${id}-${hostname}.log:代码中的日志输出
● flink-${user}-standalonesession-${id}-${hostname}.out:进程执行时的 stdout 输出
● flink-${user}-standalonesession-${id}-${hostname}-gc.log:JVM 的 GC 的日志 log 目录中以“flink-${user}-taskexecutor-${id}-${hostname}”为前缀的文件对应的是 TaskManager 的输出,也包括三个文件,和 JobManager 的输出一致。
配置文件在conf目录下
其中:
● log4j-cli.properties:用 Flink 命令行时用的 log 配置,比如执行“flink run”命令
● log4j-yarn-session.properties:是用 yarn-session.sh 启动时命令行执行时用的 log 配置
● log4j.properties:无论是 standalone 还是 yarn 模式,JobManager 和 TaskManager 上用 的 log 配置都是 log4j.properties
这三个“log4j.*properties”文件分别有三个“logback.*xml”文件与之对应,如果想使用 logback 的同 学,之需要把与之对应的“log4j.*properties”文件删掉即可,对应关系如下:
● log4j-cli.properties -> logback-console.xml
● log4j-yarn-session.properties -> logback-yarn.xml
● log4j.properties -> logback.xml
需要注意的是,“flink-${user}-standalonesession-${id}-${hostname}”和“flink-${user}- taskexecutor-${id}-${hostname}”都带有“${id}”,“${id}”表示本进程在本机上该角色(JobManager 或 TaskManager)的所有进程中的启动顺序,默认从 0 开始。
内容太多了多机部署发准备再开一篇文章