迁移学习中的常见技巧:微调(fine-tuning)
目录
一:回顾
二:微调
2.1
热狗识别
获取数据集
定义和初始化模型
微调模型
所有项目代码+UI界面
一:回顾
上一篇我们理解了深度学习中的跟RestNet结构很相似的网络——DenseNet,它是一种密集连接卷积神经网络,由李沐等人于2017年提出。与ResNet等传统卷积神经网络不同,DenseNet中每个层都直接与前面的所有层相连,这种直接的密集连接架构有助于信息和梯度在网络中的流通,从而在训练中提高了梯度的稳定性和减缓了梯度消失的问题。此外,DenseNet还具有较少的参数和更快的训练速度,这是因为它可以通过减少特征图的数量来降低计算量。这一节介绍深度学习中迁移学习的技术——微调。
二:微调
前面的一些章节介绍了如何在只有6万张图像的Fashion-MNIST训练数据集上训练模型。 我们还描述了学术界当下使用最广泛的大规模图像数据集ImageNet,它有超过1000万的图像和1000类的物体。 然而,我们平常接触到的数据集的规模通常在这两者之间。
假如我们想识别图片中不同类型的椅子,然后向用户推荐购买链接。 一种可能的方法是首先识别100把普通椅子,为每把椅子拍摄1000张不同角度的图像,然后在收集的图像数据集上训练一个分类模型。 尽管这个椅子数据集可能大于Fashion-MNIST数据集,但实例数量仍然不到ImageNet中的十分之一。 适合ImageNet的复杂模型可能会在这个椅子数据集上过拟合。 此外,由于训练样本数量有限,训练模型的准确性可能无法满足实际要求。
为了解决上述问题,一个显而易见的解决方案是收集更多的数据。 但是,收集和标记数据可能需要大量的时间和金钱。 例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究资金。 尽管目前的数据收集成本已大幅降低,但这一成本仍不能忽视。
另一种解决方案是应用迁移学习(transfer learning)将从源数据集学到的知识迁移到目标数据集。 例如,尽管ImageNet数据集中的大多数图像与椅子无关,但在此数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。 这些类似的特征也可能有效地识别椅子。
2.1
-
在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
-
向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
-
在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。

当目标数据集比源数据集小得多时,微调有助于提高模型的泛化能力。
热狗识别
让我们通过具体案例演示微调:热狗识别。 我们将在一个小型数据集上微调ResNet模型。该模型已在ImageNet数据集上进行了预训练。 这个小型数据集包含数千张包含热狗和不包含热狗的图像,我们将使用微调模型来识别图像中是否包含热狗。
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l获取数据集
我们使用的热狗数据集来源于网络。 该数据集包含1400张热狗的“正类”图像,以及包含尽可能多的其他食物的“负类”图像。 含着两个类别的1000张图片用于训练,其余的则用于测试。
解压下载的数据集,我们获得了两个文件夹hotdog/train和hotdog/test。 这两个文件夹都有hotdog(有热狗)和not-hotdog(无热狗)两个子文件夹, 子文件夹内都包含相应类的图像。
#@save
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
data_dir我们创建两个实例来分别读取训练和测试数据集中的所有图像文件。
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
train_imgs,test_imgs,train_imgs[1][0]下面显示了前8个正类样本图片和最后8张负类样本图片。正如所看到的,图像的大小和纵横比各有不同。
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""Plot a list of images.
Defined in :numref:`sec_utils`"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
try:
img = d2l.numpy(img)
except:
pass
ax.imshow(img)
# ax.axes.get_xaxis().set_visible(False)
# ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
show_images(hotdogs + not_hotdogs, 2, 8, scale=3)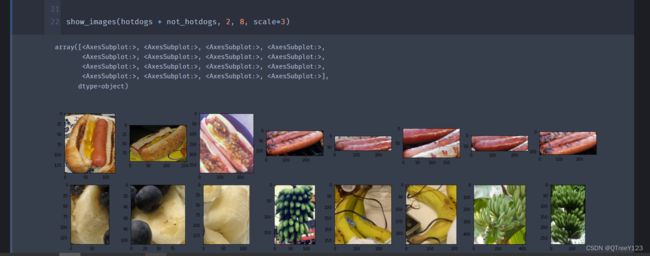
在训练期间,我们首先从图像中裁切随机大小和随机长宽比的区域,然后将该区域缩放为224×224输入图像。 在测试过程中,我们将图像的高度和宽度都缩放到256像素,然后裁剪中央224×224区域作为输入。(这是因为这些预训练的ResNet模型是在ImageNet数据集上训练的,而ImageNet数据集中的图像尺寸为224x224像素。)如果要使用预训练的ResNet模型,建议将输入图像调整为224x224像素以保持与模型训练时的一致性。如果要调整图像大小,可以使用图像处理库(如PIL、OpenCV等)中的相应函数进行调整。 此外,对于RGB(红、绿和蓝)颜色通道,我们分别标准化每个通道。 具体而言,该通道的每个值减去该通道的平均值,然后将结果除以该通道的标准差。
不过:对于自定义的ResNet模型或特定应用场景下,输入图像的大小可以根据需求进行调整。较小的图像尺寸可能会导致模型性能下降,而较大的图像尺寸可能会增加计算成本。因此,在选择输入图像大小时需要考虑模型的架构、任务要求和计算资源等因素。
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
train_augs,test_augs定义和初始化模型
我们使用在ImageNet数据集上预训练的ResNet-18作为源模型。 在这里,我们指定pretrained=True以自动下载预训练的模型参数。 如果首次使用此模型,则需要连接互联网才能下载。
pretrained_net = torchvision.models.resnet18(pretrained=True)
/home/d2l-worker/miniconda3/envs/d2l-zh-release-1/lib/python3.9/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
warnings.warn(
/home/d2l-worker/miniconda3/envs/d2l-zh-release-1/lib/python3.9/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or None for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing weights=ResNet18_Weights.IMAGENET1K_V1. You can also use weights=ResNet18_Weights.DEFAULT to get the most up-to-date weights.
warnings.warn(msg) 预训练的源模型实例包含许多特征层和一个输出层fc。 此划分的主要目的是促进对除输出层以外所有层的模型参数进行微调。 下面给出了源模型的成员变量fc。
pretrained_net.fc #Linear(in_features=512, out_features=1000, bias=True)
在ResNet的全局平均汇聚层后,全连接层转换为ImageNet数据集的1000个类输出。 之后,我们构建一个新的神经网络作为目标模型。 它的定义方式与预训练源模型的定义方式相同,只是最终层中的输出数量被设置为目标数据集中的类数(而不是1000个)。
在下面的代码中,目标模型finetune_net中成员变量features的参数被初始化为源模型相应层的模型参数。 由于模型参数是在ImageNet数据集上预训练的,并且足够好,因此通常只需要较小的学习率即可微调这些参数。
成员变量output的参数是随机初始化的,通常需要更高的学习率才能从头开始训练。 假设Trainer实例中的学习率为γ,我们将成员变量output中参数的学习率设置为10γ。
通过单独初始化最后一层参数,可以确保只有最后一层的参数会被优化器更新,而不会对预训练模型的其他数进行更新。这样可以更好地利用预训练模型的知识,同时针对新任务进行微调,提高模型在新任务上的性能
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)
Parameter containing:
tensor([[ 0.0967, -0.0945, 0.0391, ..., -0.0235, -0.0034, -0.0209],
[-0.0810, -0.0671, -0.0952, ..., -0.0252, -0.0571, -0.0141]],
requires_grad=True)微调模型
首先,我们定义了一个训练函数train_fine_tuning,该函数使用微调,因此可以多次调用。替换全连接层和重新初始化权重的目的是为了适应特定任务和数据集,确保模型能够更好地进行训练和表现。
#@save
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
# 微调BERT中所需
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum#@save
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
# 微调BERT中所需
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
#@save
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率,比如,如果数据集目录下有一个 cat 目录和一个 dog 目录,那么 ImageFolder 类会自动将 cat 目录中的所有图像赋予标签 0,将 dog 目录中的所有图像赋予标签 1。
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):#该类会根据目录结构自动为数据集中的每个类别分配一个标签
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:#用来获取网络中除了最后一层(fc)全连接层的所有参数,即只获取所有卷积层、池化层等的参数,
params_1x = [param for name, param in net.named_parameters() if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
#因为它们的输入和输出都是一维向量(或矩阵),因此权重矩阵只需要一个二维矩阵即可描述整个层。相比之下,卷积层(Convolutional Layer)的输入和输出通常是三维张量
'lr': learning_rate * 10}],#全连接层通常具有更高的学习速率,等其他层而言。具有更少的权重参数可以减少计算量
lr=learning_rate, weight_decay=0.001)#对于具有不同学习速率需求的层,可以单独设置不同的学习速率,以提高训练效果。
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,#trainer优化器
devices) 首先,通过net.named_parameters()获取了网络中的所有参数,然后使用列表推导式params_1x = [param for name, param in net.named_parameters() if name not in ["fc.weight", "fc.bias"]]筛选出除了最后一层全连接层("fc.weight"和"fc.bias")以外的所有参数。这样得到的params_1x就是需要进行更新的参数列表,即所有卷积层、池化层等的参数。
net.named_parameters()会遍历net中的所有name not in ["fc.weight", "fc.bias"]]模块(包括子模块),并返回每个模块中的参数及其名称。返回的结果是一个生成器对象,可以通过迭代来访问每个参数及其名称。
我们使用较小的学习率,通过微调预训练获得的模型参数。
train_fine_tuning(finetune_net, 5e-5)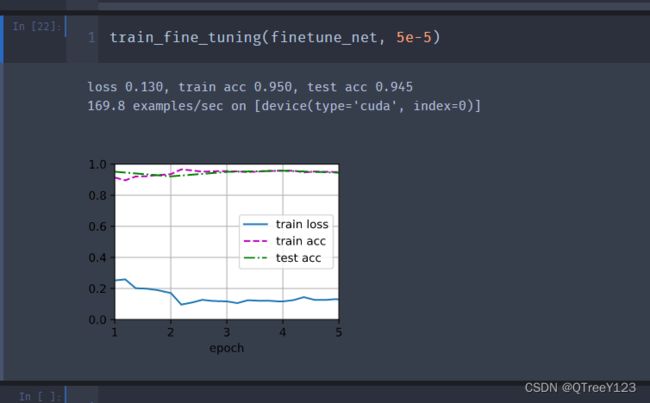
微调的步骤通常包括以下几个阶段:
-
加载预训练模型:首先,加载已经在大规模数据集上预训练好的模型,如ImageNet上预训练的卷积神经网络(如ResNet、VGG等)。
-
冻结一部分层:对于大多数情况,预训练模型的前几层是通用的特征提取器,这些层学习到的特征对于新任务也是有用的。因此,通常会冻结预训练模型的前几层,不对它们进行参数更新,保留它们学到的特征表示。
-
修改输出层:根据新任务的需求,修改模型的输出层,通常是替换最后一层全连接层(或分类器)的结构和输出维度,以适应新任务的类别数。
-
重新训练:在冻结了部分层并修改了输出层后,通过反向传播算法以较小的学习率对模型进行重新训练。这个过程中,只有被修改的层(通常是输出层)以及解冻的层的参数会被更新,其他层的参数仍然保持不变。
通过微调,模型可以利用预训练模型在大规模数据集上学到的通用特征,同时针对新任务进行特定的调整,以提高模型在新任务上的性能。微调的关键在于平衡预训练模型的知识与新任务的要求,并进行适当的参数更新。
所有项目代码+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章